
はじめまして!
24新卒としてAI事業本部DynalystのData Scienceチームに配属となった大塚皇輝です!
現在は主に広告オークションにおける入札戦略の最適化や、データ基盤の構築等を行っています。
本記事ではエンジニア新卒研修で実施された、約3週間のチーム開発研修での取り組みを紹介します。
自分の所属するチームではTwitterを模倣したモバイルアプリを作成しました。その中で自分はML/DS職(機械学習とデータサイエンス枠での採用)として、OpenAIのAPIをCIに組み込んだ自動コードレビュー機能の実装と、ユーザー投稿の推薦機能の実装に取り組みました。
開発時の状況
まず今回の研修には「AIの活用」が評価項目として存在していました。そこで、いわゆるAI的な処理を用いた機能を実装するにあたり、
- ML/DS職はチーム内で一人
- AI的な処理を用いた機能はプロダクトの品質というよりも付随機能としての役割が大きくチーム目標(後述)から乖離がある
- AI的な機能実装は往々にしてタスクが他領域にまたがるため、タスク量が暴発する可能性が高い
という状況から、最初はAIを用いた機能の実装は優先度を低く設定しました。お題として掲示されたSNSの作成の評価基準と、「必須要件に注力し質の高いプロダクトを完成させる」というチーム目標からも、機械学習を機能として組み込む優先度は低いという判断を行っていました。このような、Minimum Viable Productを可能な限り最速で作り、そこから機能を追加していく戦略は、3週間で作り切るという研修の関係上、うまく機能したと思っています。
一方でプロダクトの品質という点においては、開発者支援としてをAIを補助的に用いることで品質向上を図ることが出来ると考えました。そこで開発初期では、サービスに対する機能追加ではなく開発者支援の文脈でAIを活用しようと考え、CIに自動コードレビュー機能を追加することにしました。一通りこの機能の実装が片付いた後、自分自身はAI周りの実装では無く、主にAPIの実装やインフラ周りの実装を行っていました。周りのチームを見ていると、割とAPI実装にかかる工数が高く、自分達のチームに関しても例に漏れず、フロントエンド側が順調に進んでいる一方で、バックエンドの実装が遅れ気味だったので、若干焦りがありました。
私個人としては、GoとTerraformに関しては経験が少なく、チームメンバーに教わりつつ実装に取り組みました。自分の担当職域外の知見を得る機会は今後中々無いと思うので、この部分は研修を通して貴重な経験になりました。この時点では全く意識していなかったのですが、後々投稿内容の推薦機能を実装する際に、バックエンドの繋ぎこみやインフラの準備等で役に立つこととなりました。
AIによるコードレビュー
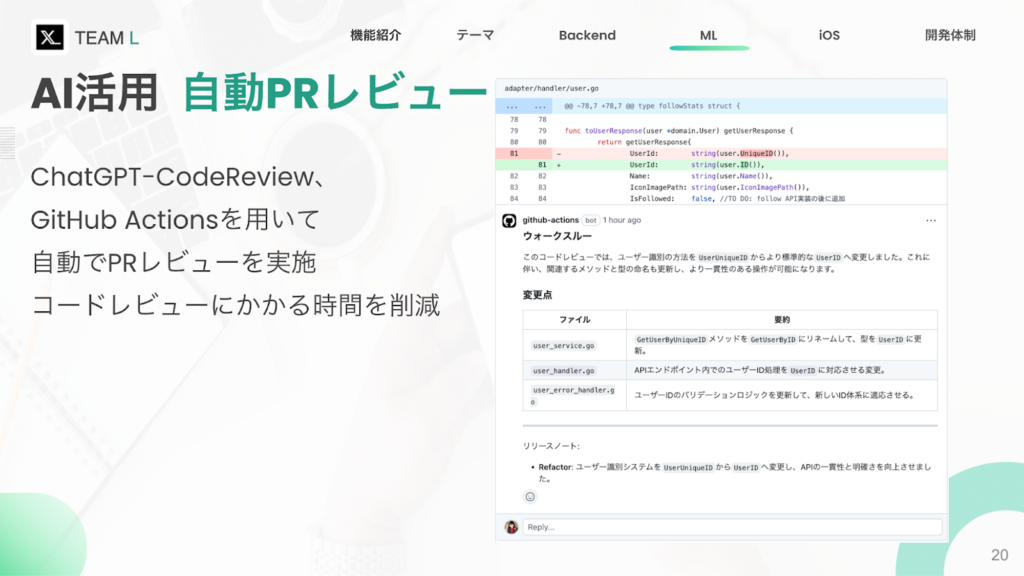
先述した通り、往々にしてAI関連機能の実装は、インフラからバックエンドまで影響範囲が拡大し、タスクが暴発してしまう傾向にあります。そのため、開発初期の段階で手を出すにはあまり適切ではないと考えていました。一方でお題として挙げられている「AIの活用」条件を満たす必要があったため、「なるべく実装においては影響範囲を小さくしつつ、周囲に与える影響としては大きくしたい」というモチベーションがありました。そこで、自動コードレビュー機能の実装を行うことにしました。コードレビュー機能であれば、自分の専門領域外であっても間接的に補助することが可能となり、加えてGithub ActionsのMerketplaceに既に実装済みのActionが多数存在したため、他領域に実装に影響を与えず、導入も容易だと考えました。
まずはじめに、自動コードレビューとしては恐らく一番の有名所であるCodeRabbitを使用しました。現在は有料化していたため、研修の制約上これそのものを使用することはできなかったのですが、Action自体はOpenAIのAPIキーがあれば使用できたため実際に使ってみることにしました。結果的にはPRのsummaryを出力してくれはするものの、レビューの詳細を確認するにはサービスに課金する必要がありました。サイトの説明を読み飛ばしていて、レビューコメントに関しては有料であることを見逃し手戻りを発生させてしまったんですが、一方でsummaryの内容的には的を得た回答をしていたので、自動コードレビュー自体は機能しそうな予感がありました。
そのため次には、ChatGPT-CodeReviewという別のActionを用いて検証しました。
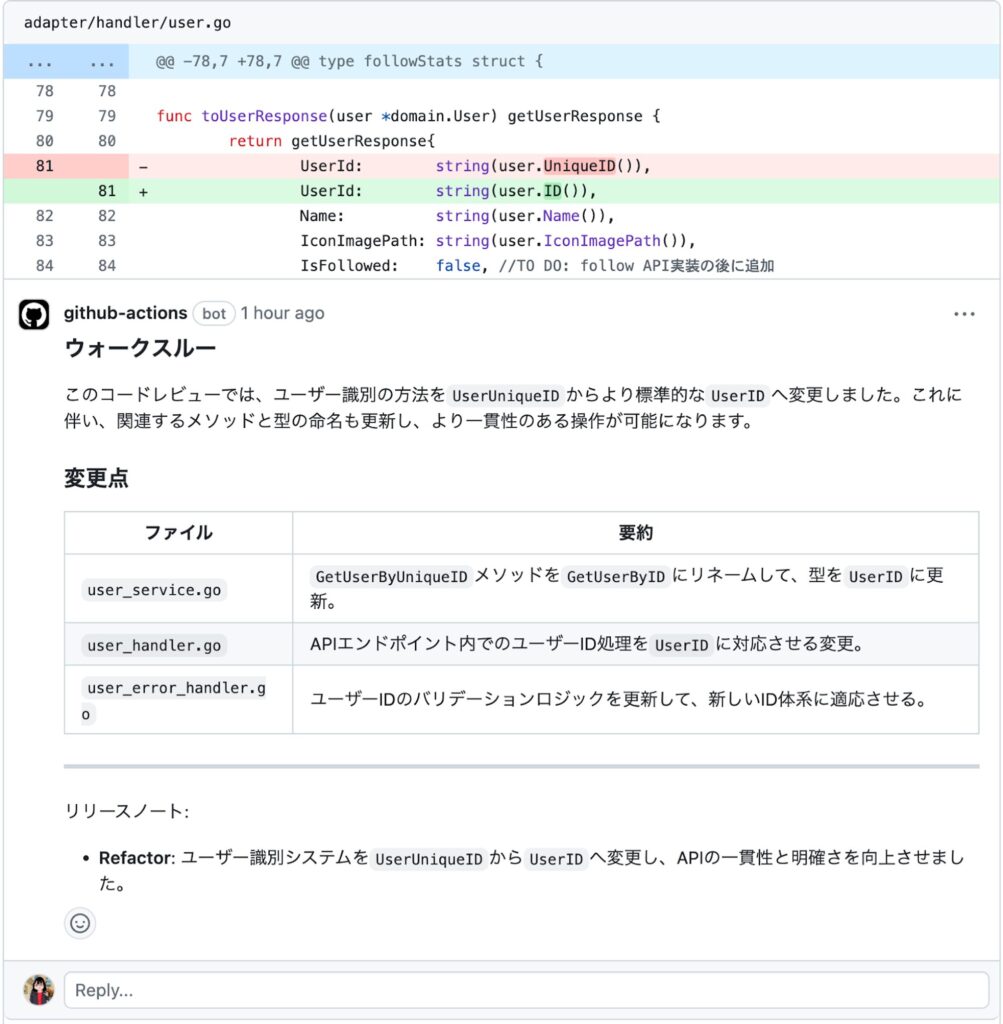
上記のようにレビューを出力してくれるものの、こちらはレビュー内容における精度がいまいちで、最終的に自動でレビューしてくれたとしてもチームとしてコメントを無視してしまう結果となりました。
この結果を通して
- レビューの信頼度
- レビューの頻度
の2つが満たされないと、自動レビューが実態として機能しないことがわかりました。
まずレビューの信頼度に関しては言わずもがなですが、人間が行うレビューはレビュワーに対する信頼感が前提にあると思います。基本的にレビューを行うのは、自分と同等かそれ以上の技術や経験を持っている方が行う場合が多いく、レビューに対して信頼度があるため、ほぼ確実にコメントの確認を行うと思います。一方でAIによるレビューの場合はそもそもの信頼度が怪しいことに加え、対人でないため対応が疎かになりがちになります。また、コミットがブランチにpushされるごとにレビューが実施されると、頻度が高く鬱陶しくなってしまう場合があり、結果的にこの場合も見逃されがちになります。このようなことから、自動コードレビューの導入にあたっては、開発者体験を意識した上で導入を進めなければ、定着に至らず結果的に無用の産物となりかねません。当たり前のことではありますが、開発者向けに導入するプロダクトとして、ただ導入すればいいという訳ではなく、開発者のUXに気を配りながら、実態として機能するように運用する必要があると思いました。
投稿推薦機能
当初研修の前半は上述したように、APIの実装等に注力していたんですが、予定より早く、最終発表の約1週間前におおよそ実装の目処が立ちました。「AIの利活用」という目標は達成してはいたものの、正直おまけ程度の実装になっていたため、チームメンバーから後押しもあり、投稿の推薦機能の実装に取り組むこととなりました。投稿推薦機能を実装するにあたっての懸念点は
- 実装に残された時間は約1週間
- 100ms以内でレスポンスを返すこと
- コールドスタート問題
がありました。
また効果的な推薦とは何かをユーザー起点で考えた結果、
- ユーザーの中で一番動作コストの高い行動は投稿である
- 投稿内容はユーザーの興味関心がある内容である
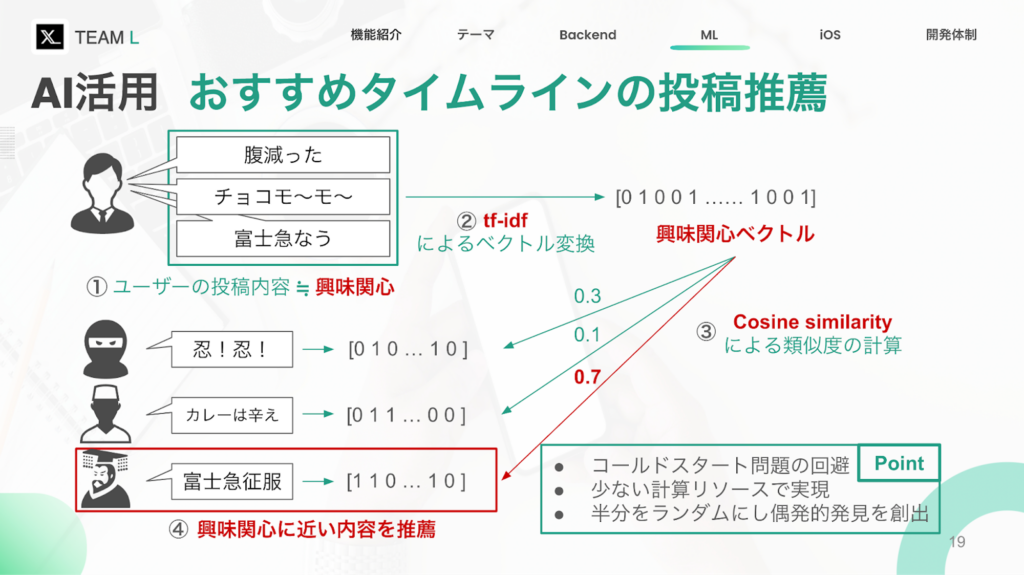
と仮定を置き、ユーザーの投稿内容に類似した投稿を推薦するという方針で実装を行うことにしました。まず最初に思いつく愚直な方法としては、いいね数で並べ替えて、多いものを推薦するという方法があります。当時の状況では、ユーザーがチーム内のテストユーザーしか存在しなかったため、いいね数で並べた場合、一定時間同じ投稿が上位表示され続けたり、おすすめ投稿ではなく人気投稿であって、ユーザーの興味がない可能性があることが考えられるため見送る結果となりました。
アルゴリズム策定
まず類似投稿を抽出するにあたって、自然言語で書かれた投稿内容の類似度をどのようにして図るかという問題があります。愚直な方法としては、ゲシュタルトパターンマッチングという方法があり、Pythonの標準ライブラリに組み込まれています(他にもLevenshteinというライブラリに、文字列の類似度計算に使える様々なアルゴリズムが実装されているので、興味があれば覗いてみると面白いかもしれません)。
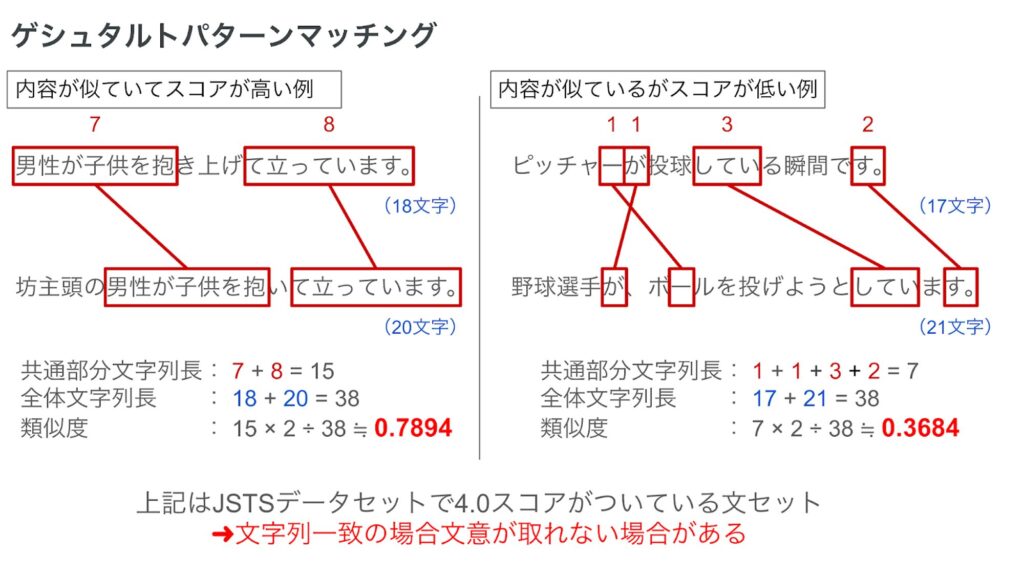
上記2つの文ペアは、JSTSと呼ばれる2文間の類似度を測定するためのデータセットから、類似度がともに4.0(最大値は5.0)とされている文章から引用しました。両方のペアの文意の一致率は同じはずですが、ゲシュタルトパターンマッチングの場合、類似度にかなりの差が出ます。スコアが低い右の文セットの場合、助詞や句点に対してマッチしており、野球というトピックに対してはマッチしていません。一般的に自然言語をそのまま使用して一致率を図った場合、助詞や句点など文章中に多く出現する語彙にマッチし、本来の興味関心といった部分に注目できない場合が多くあります。
そこで今度は文章を一旦ベクトルに変換し、ベクトルの類似度を図る方向性で考えます。自然言語をそのまま使用した場合と比べて、文字をベクトルに変換出来れば、より高度な数理演算の世界に持ち込みやすくなる、選択肢の幅が広がります。
今回の場合では
- 文章からベクトルに変換するアルゴリズム
- ベクトル間の類似度を図るアルゴリズム
の2つを考えることで、制約条件との兼ね合いを考えながら実験を行うことにしました。
文章からベクトルに変換

文章からベクトルに変換するというと、中々イメージしにくいですが、例えば文を単語単位に分割し、その出現個数を数える方法だと以下のようなベクトルに変換することができます。
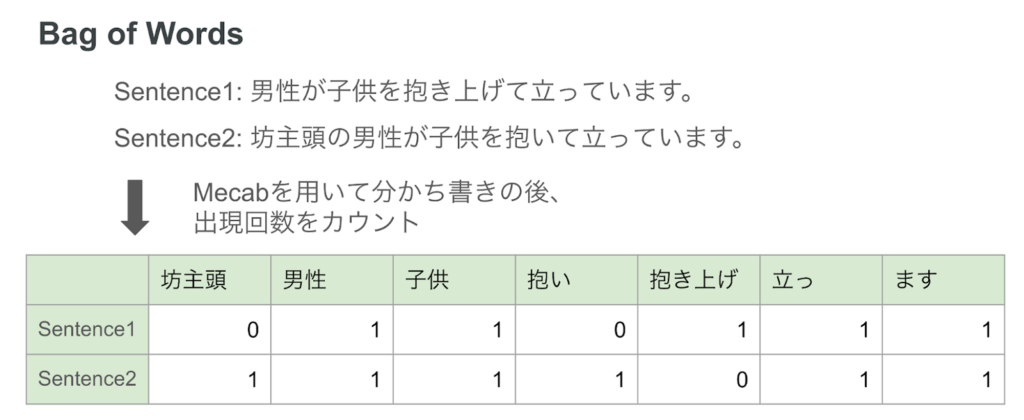
一応ベクトル化することはできますが、助詞や句点に対する制御がなされていません。そこで今回はTF-IDFという手法を用いてベクトル化を行いました。
TF-IDFとはTerm Frequency(単語の出現頻度、以下TF)とInverse Document Frequency(単語の重要度、以下IDF)を掛け合わせる手法で、若干定義にばらつきがあるものの、今回計算に使用したscikit-learnの実装では、IDFをsmoothしない場合以下のような定義になっています。

例えばSentence 2の「坊主頭」のTF-IDFを計算すると
TF: 1 / 6 = 0.167
IDF: log((1 + 2)/ 1) = 0.477
TF-IDF = TF * IDF = 0.167 * 0.477 = 0.079659
となります。
TFはある投稿に含まれる単語の出現頻度を表していて、前述した bag of wordsのカウントを用いた手法から、頻度を用いた手法に変換したようなものです。このままでは助詞等の出現頻度が高い単語に対してスコアが高くなってしまうため、IDFを用いて補正します。
IDFは投稿集合に対して、ある単語が含まれている投稿の数で割ることで、投稿に含まれる単語の内、頻繁に出現する単語に関してはスコアが低くなるようになります。これらをかけ合わせることで、文書の内容に着目したベクトルを作成できます。
他にもword2vecや、最近流行りの広義の意味でのLLMを用いた方法だと、Sentence BERTを用いたベクトル化や、OpenAIが出しているEmbeddings API Endpointを用いた方法などがあります。恐らくこちらを用いたほうが性能は高いと予想していましたが、プロダクトの品質目標としては、100ms以内にレスポンスを返すということをKPIとして設定していたため、推論速度の観点から導入候補から除外していました。
今回のブログ執筆あたって追加でJSTSのデータセットを用いて実行時間の計測をしてみました。データの作成に関しては、JSTSのtrainデータセットの上から10文ずつ選択した1つの集合を100セット準備しました。SetntenceBERTのモデルはHugging Faceにて公開されているsonoisa/sentence-bert-base-ja-mean-tokens-v2を用いました。
(word2vecとOpenAIのスコアを試したい)
実験結果は以下のようになりました。
| 0%ile | 50%ile | 90%ile | 95%ile | 100%ile | |
| TF-IDF | 0.001416 | 0.001520 | 0.002158 | 0.002360 | 0.004283 |
| SentenceBERT | 0.699072 | 0.945932 | 1.724319 | 2.491551 | 3.999277 |
今回採用したTF-IDFの95%ile実行時間が約0.002秒(2ms)に対して、大規模言語モデルの用いた場合の95%ile実行時間が約1.5秒という結果になりました。100ms以内レスポンスを返すという条件の場合、バックエンドサーバーと推論サーバー間の通信時間等も考慮すると、大規模言語モデルを用いた手法は向かないという結果になりました。
レスポンスタイムの悪化はユーザーの離脱率向上に寄与することが知られています。TF-IDF自体は古典的な手法であり、大規模言語モデルと比べるとタスク精度に関しては劣るかもしれませんが、推論スピードに対しては優位性があります。自然言語を用いた投稿推薦においては、リアルタイムでの返却を行う場合には、大規模言語モデルを用いるのは難しいのかもしれません。もし大規模言語モデルを用いる場合は、任意の時間で推論バッチを回し、推薦投稿ランキングをキャッシュしておき、そのランキングにフィルタリングやランダム性の付与を行う等の工夫が必要になると思われます(Two-stage Recommender SystemやTwitterのthe-algorithm等で調べてみると面白いかもしれません)。
次にベクトルの類似度判定を考えます。これも愚直な方法だとユークリッド距離や、マンハッタン距離を用いてベクトル間の距離を求めることができます。一方で機械学習ではベクトルの類似度を判定する場合はコサイン類似度が良く扱われます。
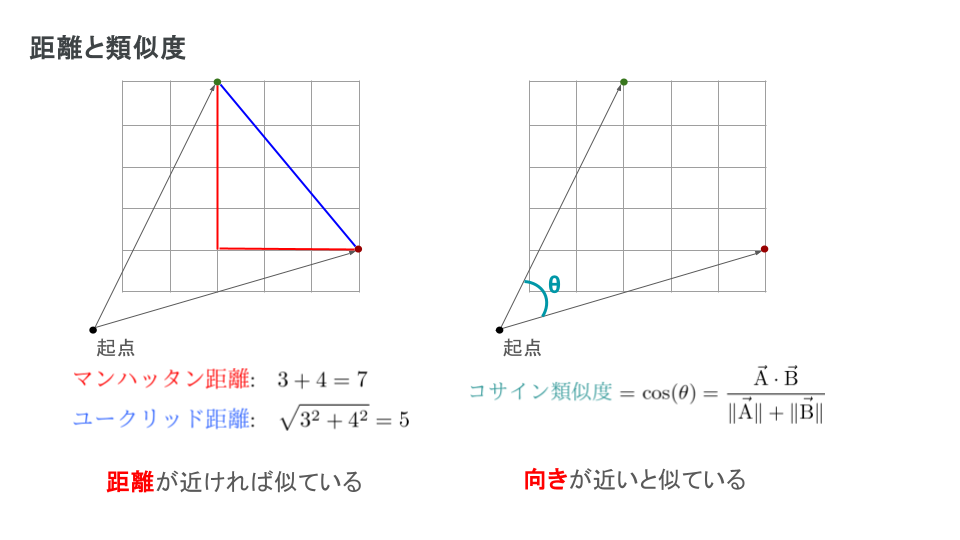
類似度計算の違いによる影響を説明するにあたって、以下のようなベクトルを想定します。
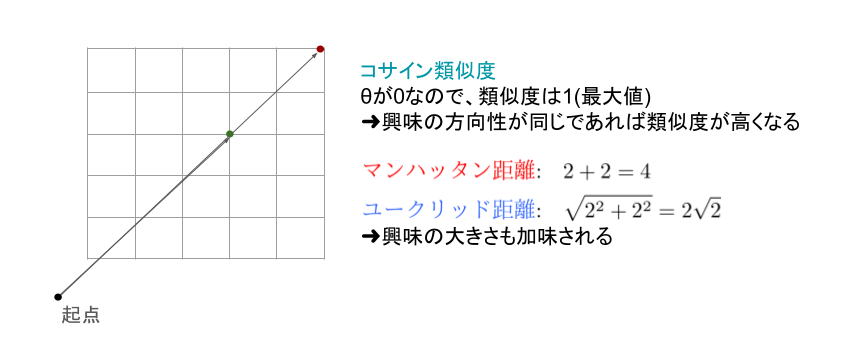
この場合、マンハッタン距離とユークリッド距離をそれぞれ計算すると4と2√2となりますが、コサイン類似度の場合はベクトルの成す角が0なため、類似度は1となります。このような結果から考えると、距離の場合は、ある内容に対する強弱に着目するのに対し、コサイン類似度の場合はある内容の傾向に着目してスコアが算出されます。加えて類似度は-1から1までの範囲で表されるのに対し、距離の場合は値の範囲が限定されないため、例えば投稿に含まれる単語数の影響が値に影響を及ぼしてしまう可能性があります。このような背景を考えると、内容の強弱よりも傾向に着目した類似度判定が適切と考え、今回はコサイン類似度を用いた判定を行うことにしました。
パフォーマンス・チューニング
投稿推薦において、一番最初に遭遇する問題としてコールドスタート問題というものがあります。初期状態では投稿数も少なく、ユーザーからのフィードバック機構も存在しないため、精度面での改良を施すのが難しくなっています。そこで今回はプロダクトの品質という面から、100ms以内のレスポンスタイムに抑えながら、推論に費やす時間の最大値を攻めるという方向でパフォーマンス・チューニングを実施しました。
投稿推薦の内部実装としては
- 推薦されるユーザーの投稿情報の取得
- 推薦に使用する、推薦されるユーザー以外の投稿情報の取得
- 1, 2 で取得した投稿内容のベクトル化
- ベクトルの類似度計算
- 類似度の高い投稿のIDを返却
となっています。
1, 2に関しては、取得する投稿量を制御することでデータの取得にかかる時間の削減と3,4の計算にかかる時間を短縮できます。加えてセレンディピティの誘発を期待して、推薦投稿の数に対して一定割合でランダムな投稿の返却を行うことにしました。最終的にはユーザーの直近5件の投稿を一つの文章として結合し、そのユーザーの投稿を除いた直近100件のデータに対して類似度計算を実施して、類似度の高い5件とランダムに選出した5件を返却する設定に落ち着きました。
思いの外データを取れなかったため、どこに時間がかかっているか調べてみました。先ほどのベクトル化の時間に加え、類似度の計算時間を図ってみると95%ileで約1msどほぼ無視できる時間しかかかっていませんでした。
この結果から、恐らく時間がかかっていた部分としては、ネットワークの通信部分、またはデータの取得部分と推測できます。レスポンスタイムの要件はバックエンドサーバーがrequestを受けてからresponseを返すまでの時間で設定していました。推論サーバーではサーバー間での責務の分離を考えて、投稿IDのみを返却し、投稿内容やそれに付随する情報の詰め込みはバックエンドサーバーで行っていました。
この場合、
- バックエンドサーバーから推論サーバーへの通信時間
- 推論サーバーがDBを読み込む時間
- 推論サーバーからバックエンドサーバーへの通信時間
- バックエンドサーバーが推論サーバーから返された投稿IDのデータをDBから読み込む時間
の大きく4つの通信時間がかかります。
仮に推論サーバーが返すデータをIDでは無く、付随情報まで詰め込んだ状態で返却した場合、4の通信時間が削減できます。加えて、Goでも tf-idfを計算するライブラリ等は存在しているため、バックエンドサーバー内で推薦ロジックを完結していた場合1, 2, 3の通信時間が削減できます。当初時間がかかりそうな部分を推論ロジックにかかる計算時間だと見積もっていたものの、実際はそこまでかかってなさそうです。そのため、インフラと連携しつつ、health check用のエンドポイントの通信時間を予め図っておき、ベンチマークにしておく等のアクションは開発初期の段階に行っておいても良かったのかなと思いました。Infra編の紹介記事でより詳細な説明がありますが、今回バックエンドサーバーと推論サーバーの間は内部ロードバランサーを用いて接続しています。他にもAWS Cloud Mapを用いて接続する方法等もあり、今回検証できてはいませんが、接続方法によるレイテンシの差分等も調べられると面白いのかなと思いました。
終わりに
今回のエンジニア研修や配属先の事業部研修を通して、自分よりも腕の立つ同期にたくさん出会うことができました。約3週間という短い期間でプロダクトをローンチできたというのは、各々の持つ技術力に加えて、チームとしてうまく動けたことの結果だと思います。僕個人としてもバックエンドの実装やインフラの構築含めて、チームメンバーから様々なことを吸収することができました。この研修で得た経験を活かして、配属後も成果を挙げていこうと思います!