
CyberAgent の グループIT推進本部 / CIU 所属の近藤です。CIU は CyberAgent 社内のクラウド基盤である Cycloud の開発・運用を行っている組織で、簡単に言うと社内用の AWS や GCP みたいなモノです!私はその中でも IaaS のレイヤを主に担当していて、最近はストレージの移行みたいなことをやっています。
さて、私は24新卒エンジニア全体研修の L チームでインフラの部分を担当していました。ここでは研修で作成したSNSアプリのインフラ構成や工夫点について説明していきます。
全体構成
インフラの全体構成は以下のようになっています。
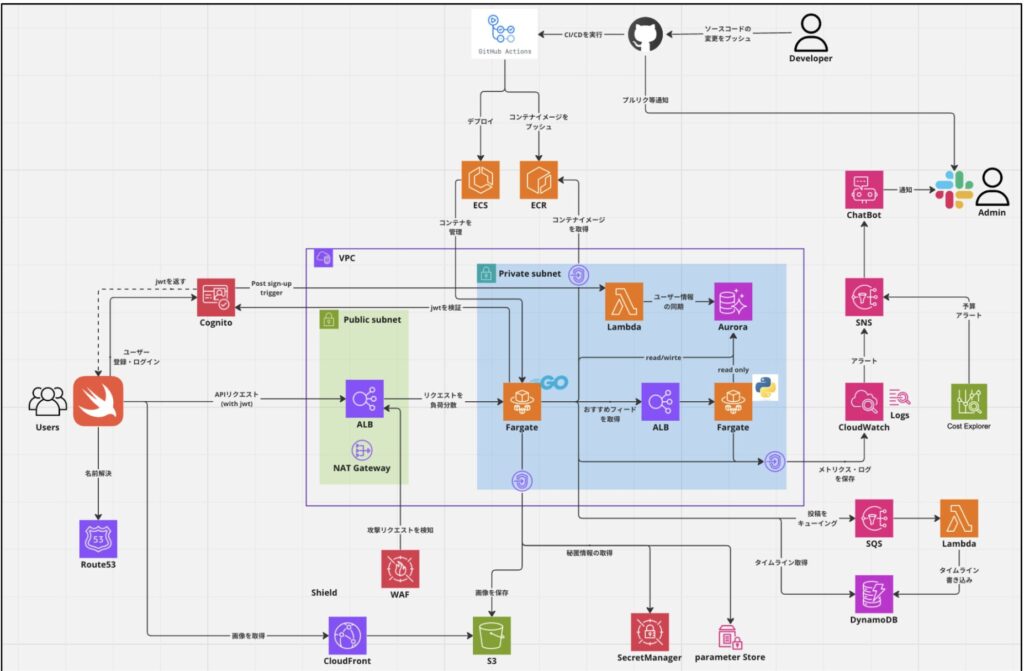
AWSの各サービスをどのように利用しているかや、各サービス間の関係をできる限りわかりやすく書いたつもりです。ここからは領域ごとに簡単に説明していきます。
アプリケーションサーバー
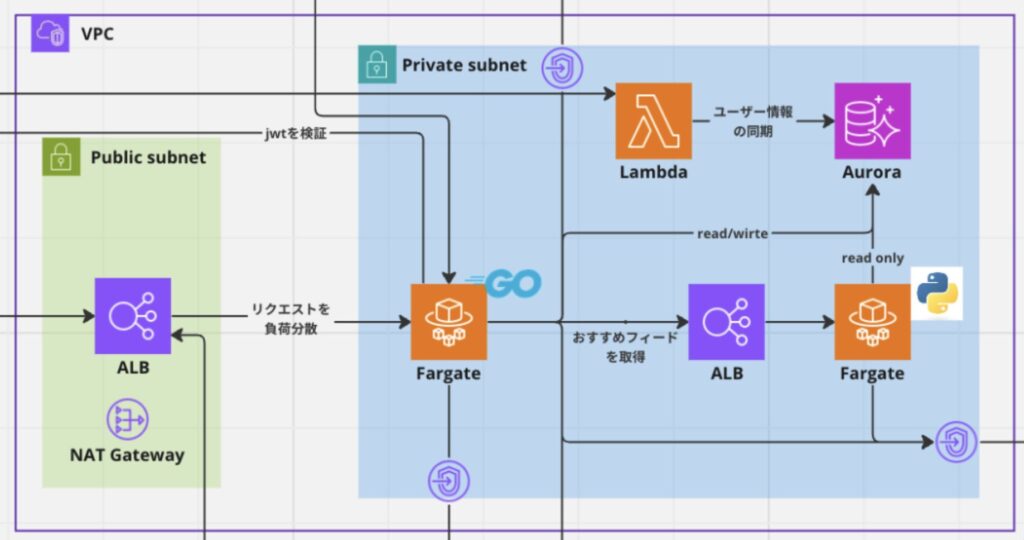
バックエンドのアプリケーションを動かすコンピュートリソースとしては ECS (Elastic Container Service) を用いました。ECS を選んだのは勇者ヒンメルならそうしたからです。ECS はコンテナアプリケーションをいい感じに管理してくれるやつで、タスク定義 (コンテナイメージや環境変数、リソース割り当てなど) とサービスを作ると外部からアクセス可能な Web アプリケーションの出来上がりです。あらかじめ作成しておいた ALB とサービスを紐づけることで、ALB からタスクへの負荷分散をやってくれます。
最初は App Runner というコンテナアプリケーションを超簡単に構築してくれるマネージドサービスも検討したのですが、以下の理由で使いませんでした。
- ECSに比べて柔軟性が低く機能不足
- ECS ですらかなり抽象化されていて使いやすいので、それをわざわざさらに抽象化して使うメリットが薄い
- インフラ専任の人員がいるので ECS の面倒を見れる
今回は API server として Go のアプリケーションと投稿レコメンド用の Python のアプリケーションの2種類のアプリケーションを接続して動かすため、2つのサービスを作成してその間を internal ALB で接続しました。また、クライアントから接続する Go の API server に接続するための ALB にはちゃんとカスタムドメインを紐づけています!
パブリックサブネットに置くのはクライアントのリクエストを受ける ALB のみにし、その他の ECS サービスや internal ALB はちゃんとプライベートサブネットに置くようにして、ネットワーク的にセキュアな構成をとっています。また ECS から AWS の VPC 外のサービスに接続する経路は VPC Endpoint を使用しており、インターネットに出ることなく AWS マネージドのネットワークを通るような構成にしていることで、セキュリティと性能の向上を図っています。
メインのデータベース
投稿やユーザーデータを保存するデータベースには Aurora Serverless v2 を使用しました。Aurora は AWS 独自の RDB (Relational Database) エンジンで、様々なデータベース製品と互換性があります。今回は mysql 互換のモノを使いました。
Aurora Serverless v2 はインスタンスの管理が不要でオートスケールもするという優れものらしいですが、今回は負荷かけるの禁止だったのでオートスケールするの見れなくて残念でした。あと Aurora のデータベースを作成してから起動完了するまで数十分くらいかかってイライラしました。何に時間がかかっているのか気になります。
認証
アプリケーションのユーザ認証には Cognito を用いました。Cognito は AWS のマネージド認証・認可サービスで、認証のためのユーザープール、認可のための ID プールというのがあり、今回はユーザープールのみを使用しています。
認証のマネージドサービスとしては Firebase の Authentication が使いやすいと思いますが、今回の研修のレギュレーションとして基本的に AWS のサービスを使うというものがったため、仕方なく Cognito を使いました。認証したユーザーの AWS リソースに対する認可をしたいとかの要件があったら Cognito も便利かもしれないですが、今回はそういったことはしてないので知りません。
Cognito は OAuth という認証・認可の標準的なプロトコルを利用しており、OAuth には用途に応じて幾つかのフローが存在します。今回はその中でも “リソースオーナー・パスワード・クレデンシャルズフロー” というなんかカッケェ名前のやつを採用しました。
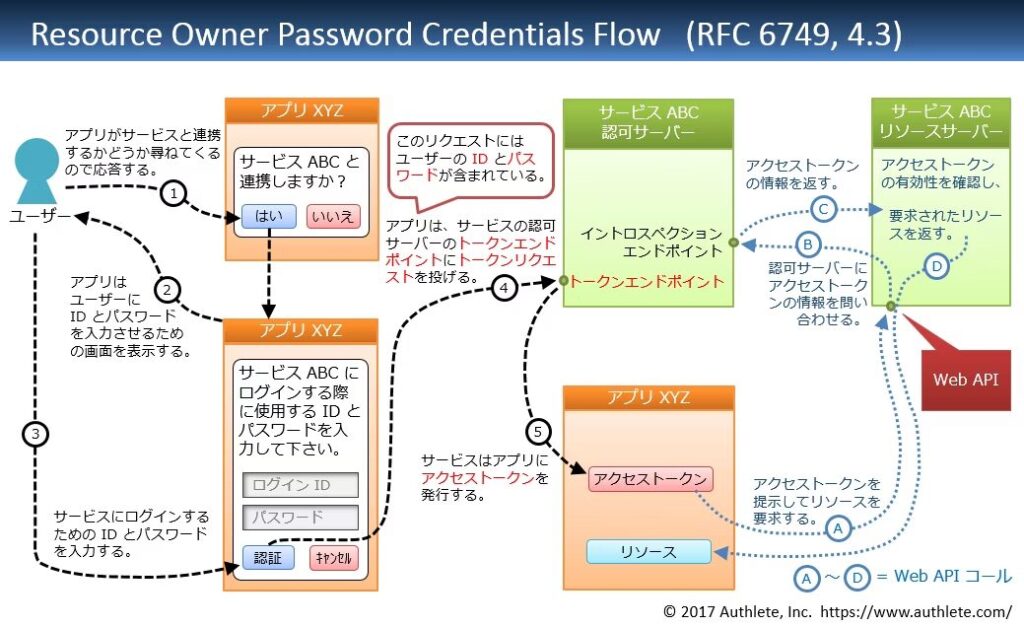
https://qiita.com/TakahikoKawasaki/items/200951e5b5929f840a1f#3-リソースオーナーパスワードクレデンシャルズフロー
フロー自体の説明は図に書いてある通りで、このフローを用いることでアプリケーション独自のログイン画面を利用することができるため採用しました。今回の場合は上図の認可サーバーが Cognito になる感じです。クライアントは Cognito からトークン (jwt) を受け取り、そのトークンを付けてバックエンドにリクエストを送り、バックエンドは受け取ったトークンを Cognito から受け取った公開鍵を用いて検証し、ユーザーを認証します。
また、今回はアプリケーションロジック上でもユーザーデータを扱いたかったため、Cognito とは別に RDB にもユーザーデータを保存していました。それにあたって Cognito 上に作成されたユーザーデータを RDB に同期する必要があったため、Cognito の Post sign-up trigger という機能を用いました。これは Cognito でユーザー登録が行われると、そのユーザーデータをペイロードにして Lambda 関数を実行してくれるというやつです。この Lambda 関数から Aurora の RDB に接続してユーザーデータを保存するようにしました。またこの Lambda 関数ではランダムなユーザーIDの生成も行なっています。

画像配信
投稿やプロフィール画像の静的ファイル配信は S3 + CloudFront のシンプルな構成を取りました。ユーザーから送られた画像データはアプリケーションサーバーから S3 に保存し、取得する際は CloudFront のドメイン + ファイル名 で取得するようになっています。
CloudFront のドメイン名もちゃんとカスタムドメインを取っています!
タイムライン
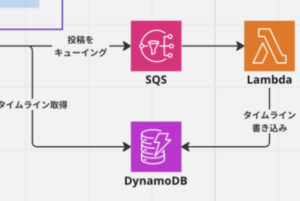
フォローユーザーの投稿一覧を取得する “タイムライン” 機能はパフォーマンスの観点から RDB ではなく DynamoDB を採用しました。ここら辺の構築はバックエンドの つっちー がやってくれて、SQS, Lambda を用いて投稿がポストされた際に DynamoDB にデータを高速に取得できる形で保存するようになっています。ここら辺の仕組みはよく考えられているのでぜひバックエンドの記事を見てみてください!
モニタリング
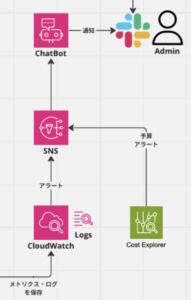
アプリケーションサーバーや RDB のモニタリングを CloudWatch を利用して行いました。アプリケーションサーバーはリソース使用率等のメトリクスやログの監視を行い、エラーログをチームの Slack チャンネルに通知する仕組みも構築しました。RDB はリソース使用率等の通常のメトリクスに加え、Aurora Performance Insights を有効にしました。これによって遅いクエリ等をダッシュボードから確認することができてちょっと便利でした。
また、今回はチームで API のレスポンスタイムやエラーレートの目標値を策定していたため、それらを計測・可視化するために Prometheus と Grafana を利用しました。
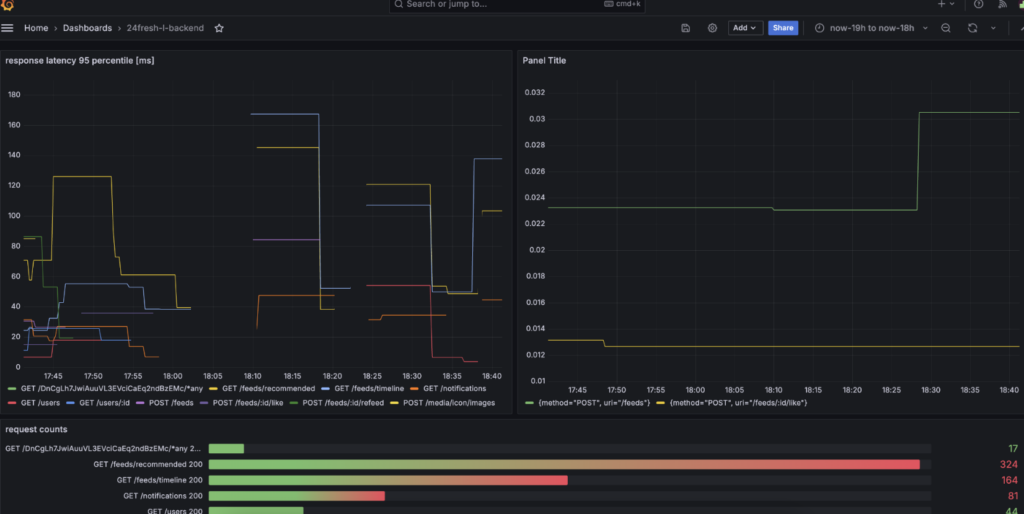
このようなダッシュボードを用いてメトリクスを確認し、最終的にチーム目標を満たす性能を達成することができました。ただし今回は負荷をかけることが禁止だったため、高負荷時の性能については測定できず残念でした。
セキュリティ
ネットワークの分離、暗号化通信、多層防御 (WAF等)、最小権限の原則 (IAM)、認証情報の秘匿化 (SSM Parameter Store, Secrets Manager)、適切な認証・認可 (Cognito) など、基本的なことはやったかなという感じです。
CyberAgent はセキュリティリスクを可視化する内製ツールである “RISKEN” を使用しており、研修でも AWS や GitHub の監視が行われていました。チームL では最終的に RISKEN のミドルレベル以上の脆弱性は全て無くすことができました。
研修の座学で習った コンテナイメージや Dockerfile のスキャンを CI に組み込んでみたりしたかったんですが、時間が足らずできなかったのが悔やまれます、、、
構成管理
インフラのリソースは大体 Terraform という IaC (Infrastructure as Code) ツールを使っています。IaC とはインフラのリソース定義をアプリケーションのようにソースコード化しようと言う手法で、これによりインフラリソースの可視性や再利用性が高まり、運用しやすくなります。そのような IaC を実現するツールとして代表的なものが、HashiCorp 社がメインで開発している Terraform という ソフトウェア なのです。最近 HashiCorp や Terraform は色々ありますね。どうなることやら。
リソース定義に際しては Terraform のモジュール機能を使用し、以下のようなディレクトリ構成で行いました。
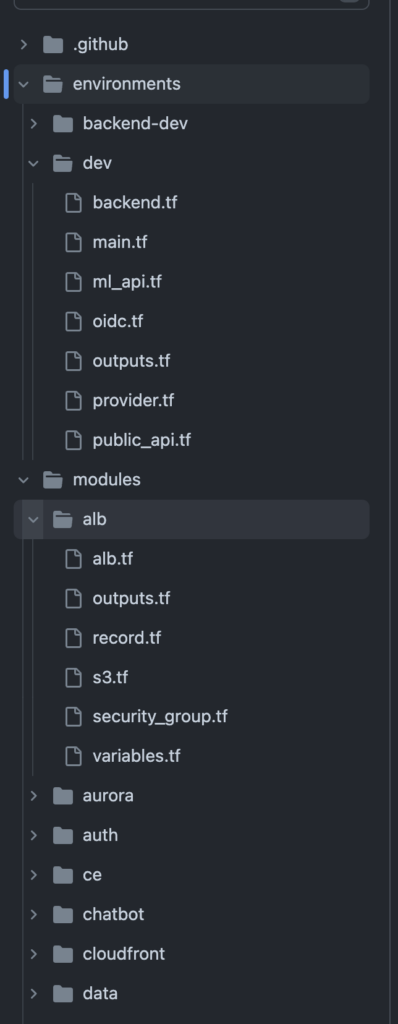
modules/ 配下に用途ごとの各モジュールを配置し、environments/ 配下に環境ごとのディレクトリを切り、その中でモジュールの呼び出しやその他のリソース定義を行っています。概ね Terraform 公式が提唱している Standard Module Structure に沿った形です。
最初は今回は環境1つしか作らないかななんて思っていたんですが、バックエンドとクライアントの繋ぎ込み開始後にバックエンドの開発中の機能の更新で壊れるのが心配ということがあり、急遽もう一つバックエンド検証用の環境を作るということがあったので、綺麗に使いまわせる形で作っておいて良かったなと思いました。
まとめ
チーム L のインフラについて紹介してきましたが、いかがでしたでしょうか?全体的に言えることとしては、特別なことはしてないけれどチーム目標の達成を支えるために必要なことを地道にやったんじゃないかと思います。まだまだ至らない部分も多かったですが、チームメンバが満足してくれるようなインフラ環境を構築できて嬉しい限りです。
最後まで読んでいただきありがとうございました!