
はじめに
こんにちは。2024年4月に新卒バックエンドエンジニアとして入社したleetszyui、Yuma Tsuchidaです。
この記事は新卒エンジニア向けの研修の一環として行われた、約3週間にわたるハッカソン形式のチーム開発で最優秀賞を受賞した私たちのチームでの取り組みや技術工夫点などをまとめたものです。
詳しくはこちらをご覧ください。
以下では、バックエンドに関して私たちが創意工夫した点をご紹介します。
バックエンドのパフォーマンス改善
私たちはより良いユーザ体験を提供するには、待ち時間が少なく、エラーが起きにくいバックエンドである必要があると考え、パフォーマンス目標としてレスポンスタイムとエラーレートを組み込むことを決めました。
バックエンドのパフォーマンス目標として以下のように設定しました。
- レスポンスタイム: 100ms以内
- エラーレート: 0.01%以下
レスポンスタイムはRAILモデルをもとにユーザが満足できるであろう100msを設定し、エラーレートはユーザ満足度が落ちない、かつ自分達が目指せるラインの0.01%以下を設定しました。
以下では、パフォーマンス改善のための取り組みを紹介します。
メトリクスの可視化と監視
まず、パフォーマンス改善の第一歩として、リクエストの監視システムを導入しました。各エンドポイントごとにレスポンスタイムとエラーレートをPrometheusで収集し、Grafanaで可視化することで問題のあるエンドポイントを発見可能になりました。
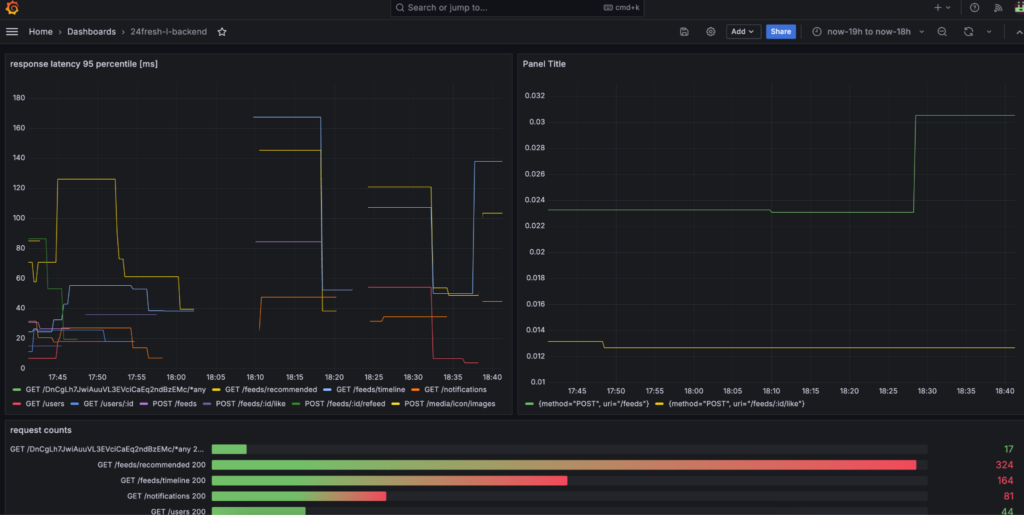
遅いエンドポイントの改善
可視化されたデータに基づき、特に遅いエンドポイントを特定し、改善を行いました。改善の例を2つ紹介します。
非同期処理によるレスポンスタイム向上
遅いエンドポイントの一つに画像アップロードがありました。
画像アップロードではユーザが送信した画像を同期的にS3に保存をしていましたが、この処理がレスポンスタイム目標の100msを超える場合が多く、改善の必要がありました。
そこで、サーバ側で画像を受け取ったあとS3にアップロードする処理を非同期にし、すぐにレスポンスを返すようにしました。これにより、機能要件を満たしつつ、ユーザ体験を損ねない改善につなげることができたと考えます。
タイムラインの高速化
次に、タイムラインの取得に関する改善です。タイムラインとは、フォローしているユーザの投稿を時系列順に表示する機能です。
初期案のタイムライン管理フロー
初期の案ではRDBを用いて、以下の手順でタイムラインを取得することを考えていました。
- フォローしているユーザの一覧を取得
- 各ユーザの最新の投稿を取得
- 投稿を時系列順に並べる
このアプローチでは、フォロー数に比例してデータベースへの読み込み回数も増加し、フォロー数が多い場合、タイムラインの取得に多くの時間を要してしまいます。
投稿の量にもよりますが、実際に100人のフォローしているユーザのタイムラインを取得する処理で要する時間を測定したところ、約2秒ほどかかっていました。
RDBを使う初期の構成ではデータベースへの多くの読み込み処理が発生し、特にフォロー数が多いユーザーの場合は高い負荷がかかっていました。そこで、DynamoDBを用いた新しいアプローチを採用しました。この方法ではタイムライン取得時に必要なデータベースへの読み込み処理を最小化させることで、タイムラインを高速に取得できるようになり、レスポンス時間を大幅に短縮させることができました。
尚、本構成は以下の記事を参考にしています。
CyberZ が Amazon DynamoDB を使用してフォロータイムラインの表示に必要な Read-Light 方式を実現した方法
DynamoDBを用いた新しいタイムライン管理フロー
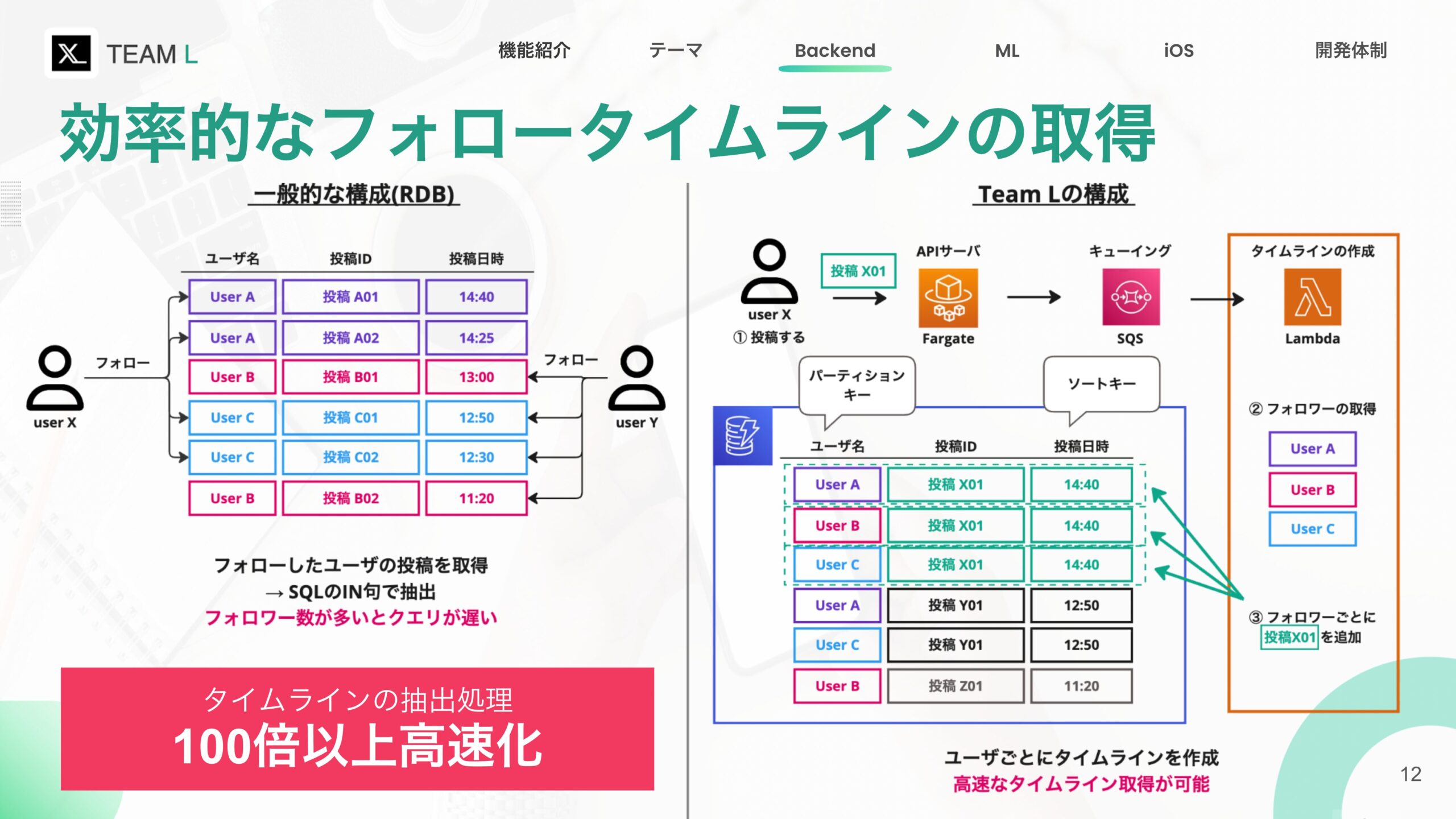
新しいアプローチ – DynamoDBの活用
新しいフローでは、以下のように処理が行われます。
- ユーザが投稿(APIサーバにリクエスト)
- APIサーバがSQSに投稿情報を追加
- LambdaでSQSから情報を取り出し、DynamoDBに書き込む
- 投稿したユーザをフォローするユーザを取得
- 投稿をDynamoDBに書き込む(パーティションキーとしてフォロワーのID、ソートキーとして投稿日時)
このように設計することで、あるユーザのタイムラインを取得したい場合、DynamoDBのパーティションキーとソートキーを指定するだけで、必要なデータを高速に取り出せるようになります。
注意点としてこの構成ではユーザごとのタイムラインをDynamoDBを使って管理するためWrite Heavyになります。しかし、これは投稿したときの処理が多くなるだけであり、取得するときには影響を及ぼさないと考え、この方法を採用しています。
この結果、レスポンスタイム100ms以下を達成し、最大約100倍の取得パフォーマンス改善を実現しました。
バックエンドのセキュリティ対策
セキュリティに関しては、OWASP Top10に準拠して開発を進めました。この基準を採用した理由は、OWASPが大規模なオープンコミュニティを持ち、Webアプリケーションのセキュリティにおける最も重大なリスクに関するガイダンスとして広く認知されているからです。

GoSec
まず、CI/CDでのSAST(静的アプリケーションセキュリティテスト)として、GoSecを採用しました。GoSecは、GoのAST(抽象構文木)とSSA(静的単一代入形式)コード表現をスキャンすることで、ソースコードのセキュリティ問題を調査してくれます。GoSecを採用するメリットとしては
- 導入が容易
- 一般的なセキュリティ要件を満たしている
などが挙げられます。
GitHub Actionsを使って、GoSecのセキュリティチェックを自動的に実行します。もしGoSecのチェックに失敗した場合、そのプルリクエストはマージできなくなるので、mainブランチのセキュリティが常に保たれます。
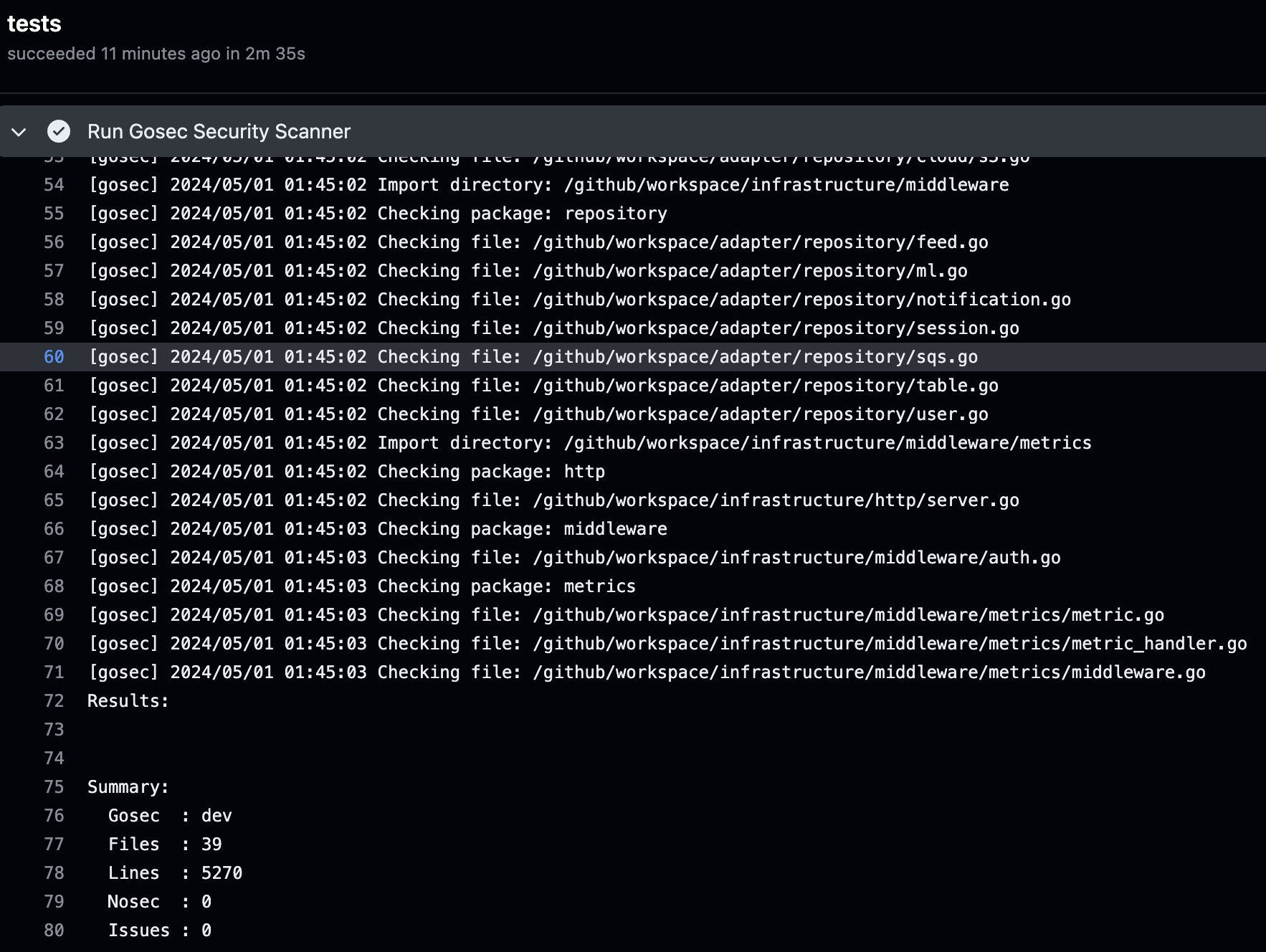
GoSecのGitHub Action
依存関係
OWASP Top10の「脆弱性のある古いコンポーネント」と「ソフトウェアとデータの完全性の失敗」に関しては、Dependabotを利用しました。Dependabotは、自動的にPR作成して、脆弱性のあるもしくは古い依存関係を指摘してくれます。
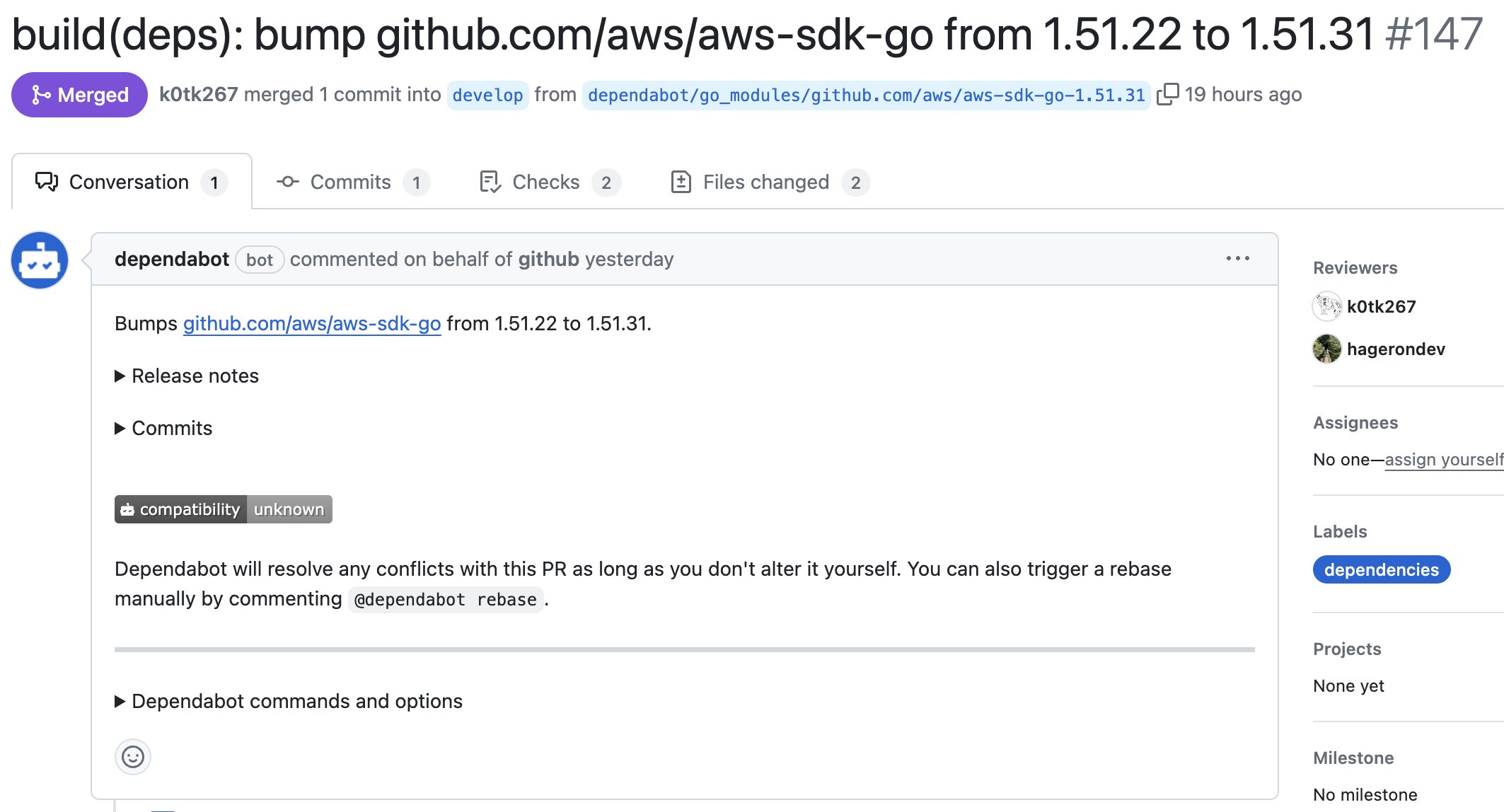
Dependabotによる自動作成PR
クリーンアーキテクチャの採用
バックエンドもクリーンアーキテクチャを採用しており、関心の分離を実現することにより将来の変更に強くなる以外、セキュリティ性の向上にも役に立てています。具体的には以下のメリットが挙げられます:
- データフローの明確化: データがシステムの各部分をどのように流れるかを明確に定義します。これにより、入力の検証、データのサニタイゼーション、出力のエスケープ処理といったセキュリティ対策を効果的に適用できます。不正なデータや攻撃コードがシステム内部に深く侵入するのを防ぎます。
- 依存性のルール: 外側のレイヤーが内側のレイヤーに依存しているが、その逆はありません。アプリケーションのビジネスロジック(最も重要な部分)が、外部要素(データベースやフレームワークなど)の変更によって影響を受けにくくなり、外部依存性に起因する脆弱性からビジネスロジックを守ることができます。
- 分離の原則: 関心の分離により、セキュリティ関連の懸念(認証など)を独立したコンポーネントやレイヤーに集中させることができます。セキュリティポリシーの一貫性と再利用性が向上し、セキュリティホールの発見と修正が容易になります。
- テスト容易性の向上: 各コンポーネントが独立しているため、ユニットテストや統合テストを行いやすくなります。セキュリティリスクを早期に特定し、修正することができます。
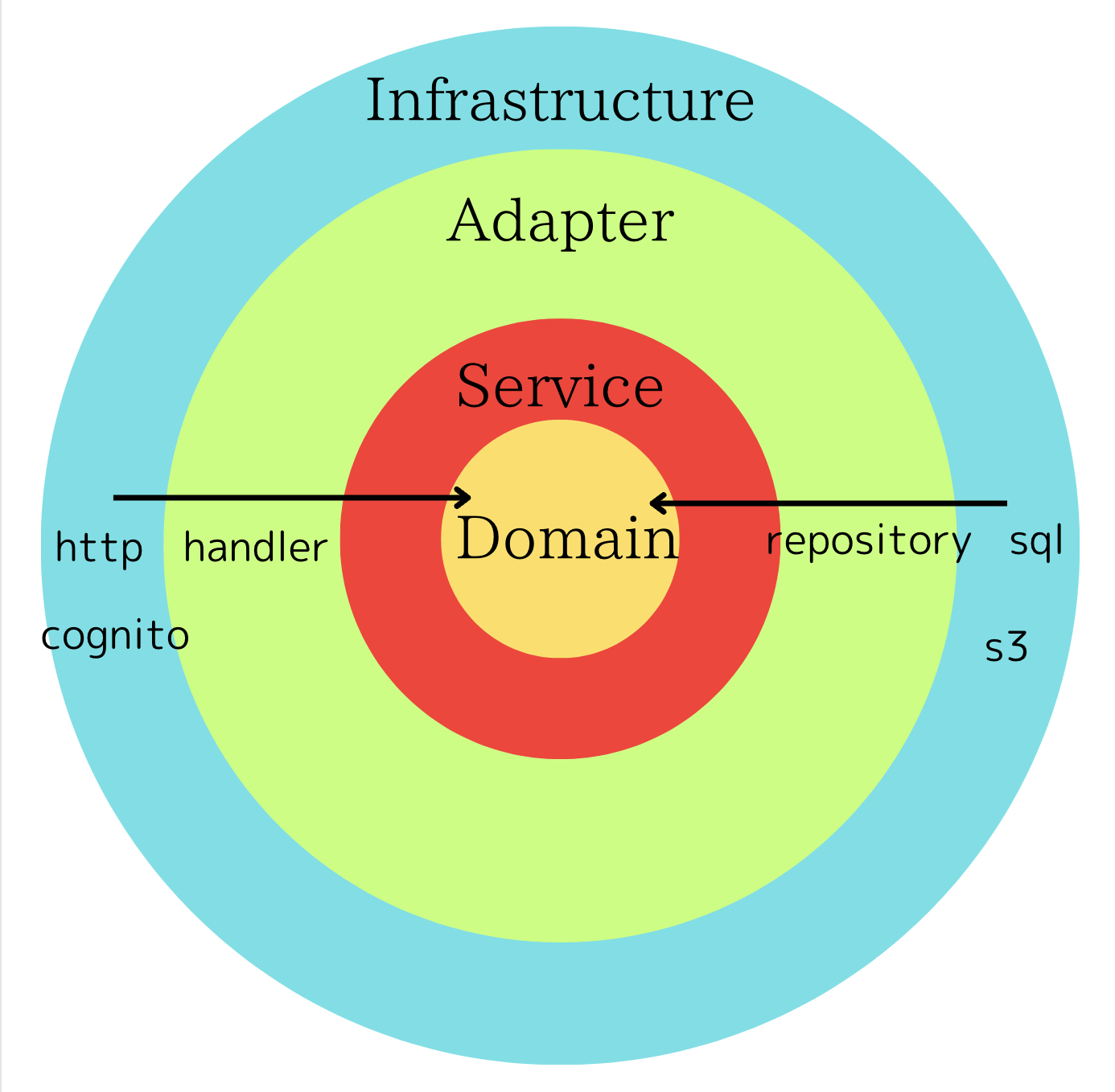
私たちのバックエンドのクリーンアーキテクチャ
SQLインジェクション
ORMとして採用したGORMは引数を自動的にエスケープするベストプラクティスがあり、私たちのバックエンドもそれに従っています。具体的には、GORMはプレースホルダーを使用したクエリの構築を行い、ユーザー入力を直接SQLクエリに組み込むことを防いでいます。
コードは以下のようになります:

GORMの公式ドキュメント
脆弱性診断
最後に、私たちはOWASP ZAPによる脆弱性診断を行い、セキュリティ要件がOWASP Top10に従っていることを確認しました。Highアラート 0 件、Mediumアラート 2 件という診断結果でした。もちろん、Mediumアラートは速やかに修正しました。

脆弱性診断の結果
終わりに
私たちのチームが取り組んだバックエンドのパフォーマンス改善とセキュリティ対策について紹介しました。
今回の経験を通じて学んだことを今後のプロジェクトにも活かし、より良いサービスの提供を目指していきたいと思います。
最後まで読んでいただきありがとうございました!