
AI事業本部 協業リテールメディアdivの林です。
私のチームでは広告配信システムを開発しており、配信実績のレポーティングをはじめとしたデータ変換のためにdbtを利用しています。
私のチームではdbtのUnit testsをシェルスクリプトを利用した仕組みによって実現していましたが、2024年5月にリリースされたdbt-core v1.8.0からUnit testsが公式でサポートされたため、既存のテストの仕組みを移行しました。
本記事では、dbt-core v1.8.0でサポートされたUnit testsの書き方と使い心地を紹介していきます。
なお、データウェアハウスはSnowflakeを前提としています。
dbtでのデータ品質の担保
dbtにはデータ品質を担保するための機能が大きく分けて3つあり、それぞれ実行対象や実行タイミングが異なるため役割が違います[1]。
Unit testsは行や列の具体的な値に対して責務を持ち、Model contractsは列名, 列のデータ制約など列の形式に関して責務を持ち、Data testsは列の許容値など列の値自体に責務を持ちます。Unit testsでは元データとそれに対してモデルを実行した際の具体的な期待値を確認し、Model contractsでは列名や列のデータ制約に問題がないか、Data testsでは値に異常がないかを確認するといった形です。
例えばクリック率CTR(%)を例にすると、Model contractsでCTRがFloat型であること、Data testsで0≤CTR≤100であることを担保し、Unit testsではImp100件とClick1件のデータがあった時にCTR=1.0になるかどうかを担保します。
これくらいの計算であれば Unit tests を使うモチベーションは低いですが、例えばCV数の集計では重複CVを排除したり集計期間を限定したり様々なロジックがあるのに加えてプロダクトの重要指標となるため、クエリのロジックをテストしたいモチベーションがあります。
移行前のUnit testsと課題
私のチームでは、dbtのクエリのロジックをテストするためにシェルスクリプトを利用していました。流れは以下です。
-
csvファイルの設置
モデルが依存するテーブルとモデル実行後に作成されるテーブルの期待値をcsv形式で用意し、後述するシェルスクリプトでファイルを読み込めるようなディレクトリ構成とファイル名にします。
例えば、dbt/dsp/click_count.sqlというモデルの重複クリックを排除するロジックをテストしたいとします。
dbt/seed/dsp/click_count/exclude_duplicate_click配下にこのモデルが依存するclick_logテーブルをcsv化したclick_log_exclude_duplicate_click.csvとモデル実行によって作成されるテーブルの期待値をcsv化したclick_count_exclude_duplicate_click.csvを配置します。 -
モデルの修正
テスト用のテーブルはテスト終了後に削除したいのでconfigのprehookに自作のマクロを追加します。
{{ config( ... pre_hook="{{ drop_table_if_is_test('CLICK_COUNT') }}" ) }} -
モデルの設定ファイルにテストのアサーションを記述
モデルによって作成されたテーブル(CLICK_COUNT)と期待値のテーブルを比較するアサーションをdbt_utilsのequalityで記述します。
version: 2 models: - name: click_count tests: - dbt_utils.equality: name: click_count_exclude_duplicate_click compare_model: ref('click_count_exclude_duplicate_click') -
シェルスクリプトを実行(ローカルまたはCIからの実行)
- 実際にSnowflakeに対してdbtのモデルを実行するため、既存のスキーマやテーブルをClone
- 「1. csvファイルの設置」で設置したファイルを読み込み、
dbt seedコマンドで対象スキーマにデータを流す dbt runコマンドでモデルを実行dbt testコマンドで「3. モデルの設定ファイルにテストのアサーションを記述」で書いたアサーションを実行- CloneしたテーブルをDrop
上記のような流れでテストをしていたのですが、以下のような課題がありました。
- シェルスクリプトでSnowflakeに接続するための仕組みが必要
- シェルスクリプトでcsvファイルを読み込んでSnowflakeに流すため、csvファイルの命名規則やディレクトリ構成に制約ができてしまう
- テスト失敗時、作成されたテーブルと期待するテーブルの差分が分からずデバッグがしにくい
- スキーマをCloneしたりdbtの実行を実際のSnowflake上で行うため、テストの実行時間が長く(自分たちのチームでは12分ほど)なってしまう
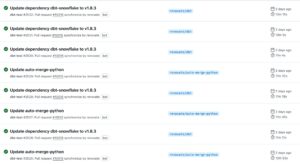
移行後のUnit tests
dbt-core v1.8.0以降のUnit testsでは以下のような流れになります。
-
csvファイルの設置
モデルが依存する元データとモデル実行後に作成されるテーブルの期待値をcsv形式で用意し、
後述しますが、csv以外にsqlやdict形式で書く方法もあります。dbt/tests/fixtures配下に設置します。 -
モデルの設定ファイルにテストの元データや期待値を記述
version: 2 models: - name: click_count config: database: "{{ env_var('ENVIRONMENT') }}_{{ env_var('PROJECT') }}_APP_DB" schema: "REPORT" sources: - name: tracking database: "{{ env_var('ENVIRONMENT') }}_{{ env_var('PROJECT') }}_RAW_DB" schema: TRACKING tables: - name: CLICK_LOG unit_tests: - name: exclude_duplicate_click model: click_count given: - input: source('tracking', 'CLICK_LOG') format: csv fixture: click_log_exclude_duplicate_click overrides: vars: execution_time: '2024-08-01 01:30:00' expect: format: csv fixture: click_count_exclude_duplicate_click - name: ... ... ... ...unit_testsというプロパティに対象モデルmodelと元データgiven, 期待値expectを書きます。dbt-core v1.8.0では元データの
input指定にはsourceもしくはrefしか指定することができません[2]。formatはdictでインラインで書くか、csvまたはsqlでインラインで書くかファイル化するかを選べます[3]。マクロや環境変数は上書きが可能です[4]。例えば環境変数から現在時刻を読み込んで現在時刻から1時間前までのデータを集計するようなモデルの場合、Unit testsでは現在時刻の環境変数を上書きしておくことで集計対象のデータを制御できます。
-
dbt testコマンドを実行
手順自体は移行前後でそれほど変わらないのですが、シェルスクリプトを使わなくて良くなった分、運用・メンテコストや認知コストが低くなりました。
移行後の使い心地
実際に数ヶ月運用してみて使い心地が良く、特に移行前の仕組みで感じていた課題を概ね解消することができました。
移行前の課題
- シェルスクリプトでSnowflakeに接続するための仕組みが必要
- シェルスクリプトでcsvファイルを読み込んでSnowflakeに流すため、csvファイルの命名規則やディレクトリ構成に制約ができてしまう
- テスト失敗時、作成されたテーブルと期待するテーブルの差分が分からずデバッグがしにくい
- スキーマをCloneしたりdbtの実行を実際のSnowflake上で行うため、テストの実行時間が長く(自分たちのチームでは12分ほど)なってしまう
移行後
- シェルスクリプトが不要になったのでSnowflakeに接続する仕組みやcsvファイルの命名規則などの制限がなくなった
- テスト失敗時に実行結果actualと期待値expectの差分が分かる
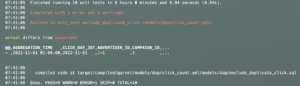
- 実行環境がSnowflake上ではなくなったため、スキーマのClone等も不要でテストの実行時間も短縮された(Unit tests自体は12分ほどから1分になった。lintの時間が長いので全体だと4分ほど。)
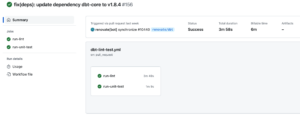
その他
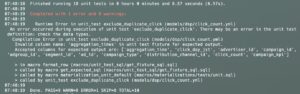
その他の嬉しいポイントとして、元データのinput指定にsourceもしくはrefを指定するため、dbt内部でその参照先テーブルに存在するカラムかどうかなどを確認してくれてテストデータがバリデーションされます。以下のように、元データのcsvに実際の参照先テーブルで存在しないカラム(aggregation_times)を入れるとエラーになってくれます。
一方で、少し使いにくさを感じているのがcsvデータのパースの処理で、例えば文字列型のカラムで実行後の期待値が空文字である場合、fixtures配下のcsvファイルの該当カラムに’’や””を指定しても空文字として認識してくれません。
これはGitHubのIsuueで既に議論がされており、空文字を期待値として使いたい場合はcsvではなくdictで書くしかないようです。
Users that need to represent blank strings for unit tests will need to use dict rather than csv for the format.
https://github.com/dbt-labs/dbt-core/issues/9881#issuecomment-2045286159
また、文字列型のカラムにJSON文字列を入れている場合、少なくともSnowflakeではクエリ実行結果をcsvファイルとしてダウンロードするとJSON文字列は以下のような形式になることがあります。
"""[{\\""column1\\"":value1,\\""column2\\"":value2},{\\""column3\\"":value3}]"""
しかし、これを元データのcsvファイルのカラムとして入れ、JSONとしてパースしてフィールドにアクセスしようとしても上手く扱えず、ダブルクォートを1つにしてあげると扱えるようになります。
まとめ
本記事では、dbt-core v1.8.0でサポートされたUnit testsの書き方と使い心地を紹介しました。
テストに必要な機能は概ね揃っていて、設定ファイルとデータを用意すれば気軽にテストできる便利な仕組みですので、是非皆さんもプロダクトに導入してみてください。
現在、協業リテールメディアdivでは積極的に採用活動を行っています。
以下のフォームからカジュアル面談を申し込めますので興味のある方はお気軽にお問い合わせください。
ご応募お待ちしております!
【協業リテールメディアDiv.】カジュアル面談フォーム | サイバーエージェントグループ
参考記事
[1]: dbt Labs: Unit tests vs. model contracts vs. data tests, 入手先〈https://docs.getdbt.com/blog/announcing-unit-testing#unit-tests-vs-model-contracts-vs-data-tests〉(2024).
[2]: dbt Labs: Input for unit tests, 入手先〈https://docs.getdbt.com/reference/resource-properties/unit-test-input〉(2024).
[3]: dbt Labs: Supported data formats for unit tests, 入手先〈https://docs.getdbt.com/reference/resource-properties/data-formats〉(2024).
[4]: dbt Labs: Unit test overrides, 入手先〈https://docs.getdbt.com/reference/resource-properties/unit-test-overrides〉(2024).