
AI事業本部でデータサイエンティストをしている杉山(@ysugiyama)と須ヶ﨑(@sugasaki)と干飯(@hosimesi)です。8月25日から8月29日にバルセロナで開催されたKDD 2024に現地参加してきましたので、その参加報告をさせていただきます。
今回はサイバーエージェントからの発表はなく、聴講という形での参加になりました。その中で興味深かった研究発表をいくつかピックアップして紹介します。詳細や他の研究についてはスライドを公開していますので、詳細が気になる方はこちらも参照してください。
▼スライド
目次
- KDDとは
- 研究紹介
- Tutorial/Workshops
- 本会議
- 現地の様子
- おわりに
KDDとは
KDD(Knowledge Discovery and Data Mining)はデータマイニング関連のトップカンファレンスで、今年で30回目の開催になります。会議はResearch TrackとApplied Data Science Trackに分かれており、研究者だけでなく、企業のデータサイエンティストや機械学習エンジニアの参加も多い学会となっています。会議は大きく以下のセッションで構成されており、今年はオフライン開催となりました。
- Tutorial/Workshops: ドメインに特化したワークショップ
- Key Session: 招待公演
- Oral Presentation: 口頭発表
- Poster Presentation: ポスター発表
- KDD cup: 企業主催のコンペティション
で構成されています。
参加者は2,284人で招待公演が12件、論文数が研究トラック: 411本(56セッション)、ADSトラック: 151本(24セッション)、ワークショップ: 30本、チュートリアル: 34本と、非常に規模の大きな学会となっています。
日本からの参加者も50人近くおり、Meet Upでの交流もありました。

研究紹介
全体的な傾向として、LLMと他の分野の組み合わせがとても多かったです。適用先はGraphデータ、時系列データ、テキストデータなどなんでもある印象を受けました。
Tutorial/Workshops
Tutorial: Multi-Armed Bandit Applications for Large Language Models
こちらのTutorialはLLM + Banditを組み合わせた実アプリケーションへの適用を目指しています(資料)。ここでは以下の2つの方向性から組み合わせを考えています。
- Bandit for LLM
- LLM for Bandit
Bandit for LLM
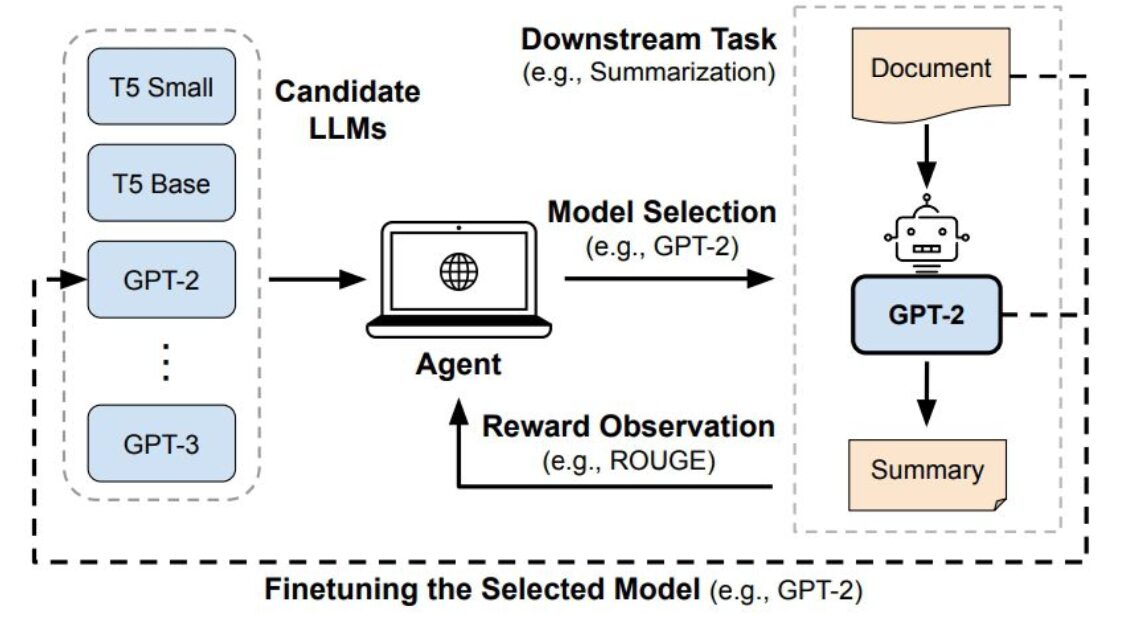
こちらの研究はLLMの選択にバンディットを用いようというモチベーションになっています。例えば、テキスト要約するタスクのLLM選択にバンディットを用いています。このテーマは私が業務で取り組んでいるチャットボットやボイスボットでも使えそうなアプローチであり、タスクの難易度の応じて良しなにアウトプットを出してくれることは運用コストは一定あるものの興味深かったです。
- 問題設定:LLMのモデル選択へのBanditの適用(テキスト要約)
- ポイント:
- 報酬はモデルの性能(何かしらのスコア)とコストの両方を考慮する
- alpha * 性能 – beta * コスト(alphaとbetaはハイパーパラメータ)
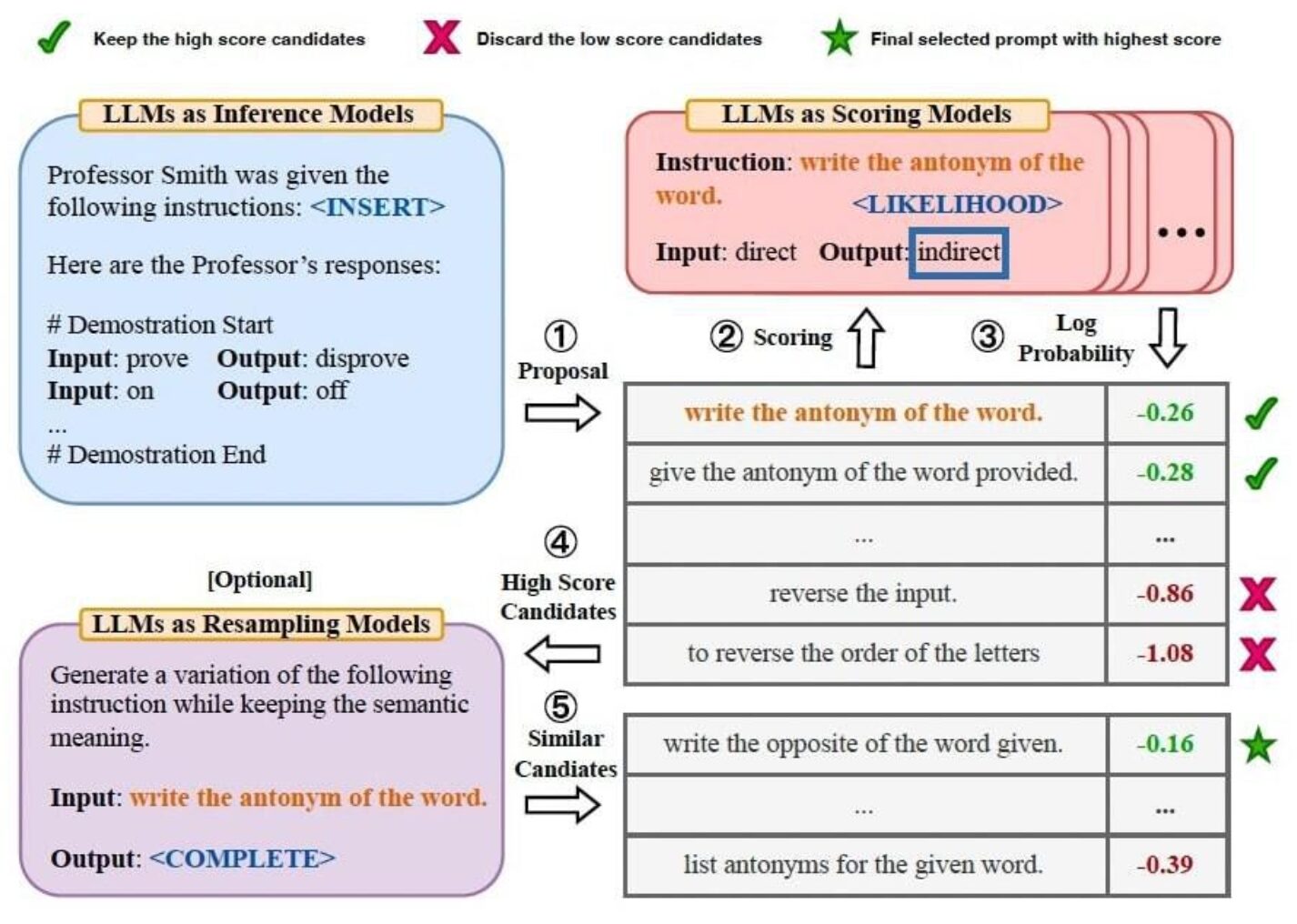
他にもプロンプトの最適化にバンディットを用いる研究もありました。
- 問題設定:LLMのモデル選択へのBanditの適用(テキスト要約)
- ポイント:
- LLMを関数とみなし、テキスト + プロンプトを入力とみなす
- CoTなどに拡張したものもある
- 流れ
- LLMに候補となるプロンプトを生成させる
- 出力の尤度&対数尤度をとる(APIなどで取れる)
- 高スコア(log確率の低いもの)を選択
- 候補の中から似ているプロンプトをLLMが選択
実アプリケーションへの展開時は運用可能性やtoo muchになっていないか検証する必要はありますが、使えそうなアプローチだなと思いました。
LLM for Bandit
こちらはコールドスタート問題をLLMを使って軽減させようというモチベーションの研究です。ECサイトなどでは、新しいユーザや新しいアイテムに対して、過去のデータがないため適切なレコメンドができないといったコールドスタート問題がおきます。この研究ではユーザのコンテキストや過去の行動データからLLMでユーザをシミュレーションしておくことでコールドスタート問題を軽減させようとします。LLMがユーザの嗜好に合わせて仮想的なフィードバックを提供し、アームを更新します。
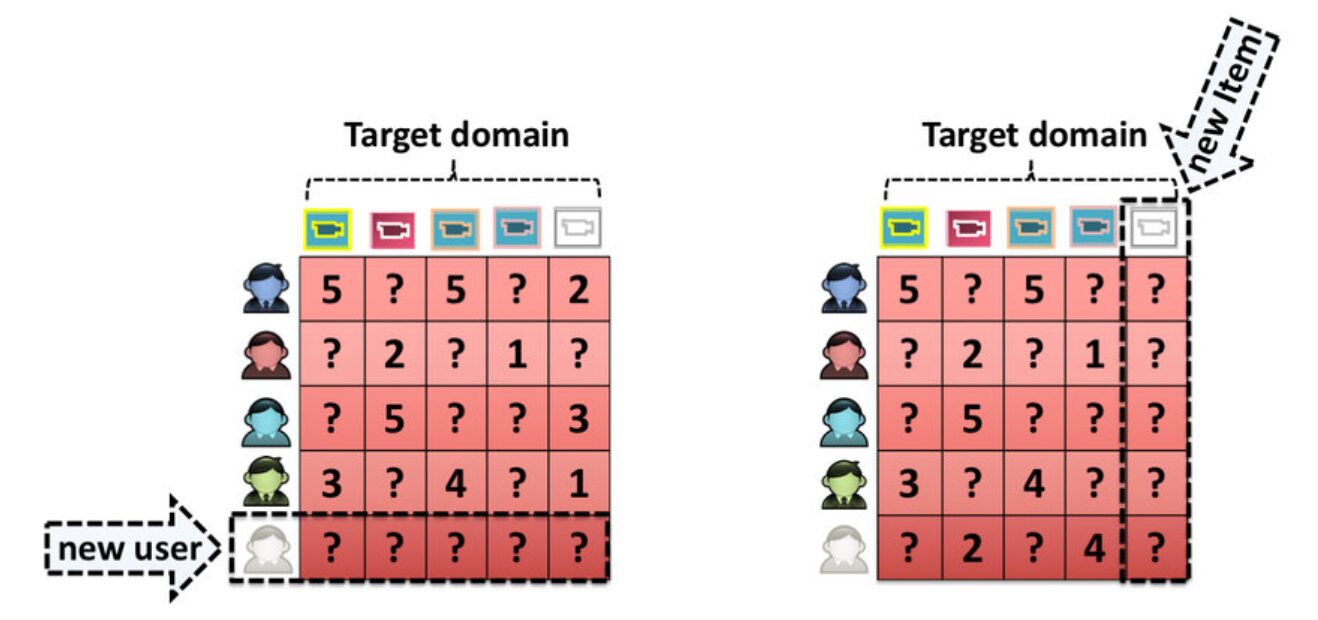
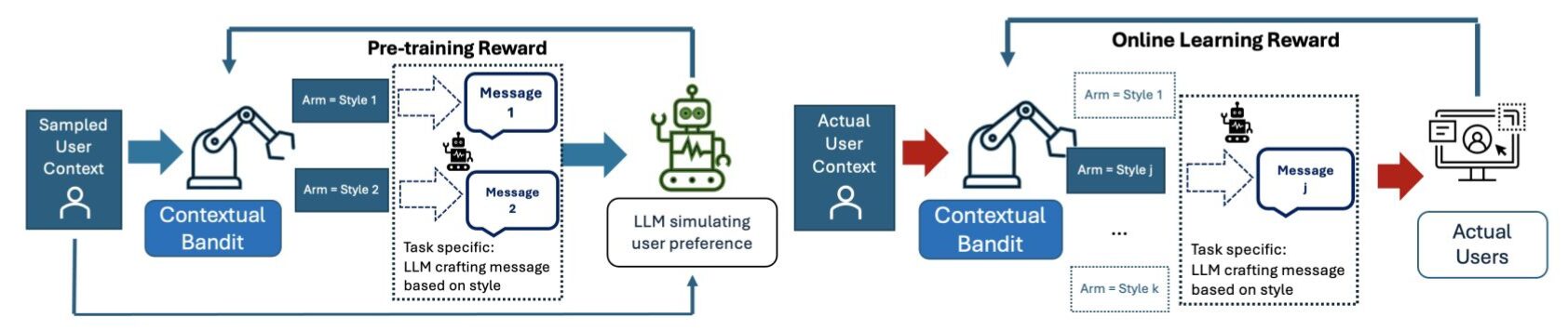
LLMをユーザのシミュレーションに使うアプローチはとても興味深く、適用先が広がる印象を受けました。
Workshops: The 13th International Workshop on Urban Computing (Urbcomp 2024)
このワークショップは都市データに特化したデータマイニングを対象としたものです。このワークショップでは、位置情報データと大規模言語モデル(LLM)を組み合わせたアプローチが数々発表されていました。直接的な言語データではない位置情報をLLMと組み合わせるために多くの工夫がなされており、非常に興味深い内容となっておりました。
本ワークショップで発表された興味深かった2つの論文をご紹介します:
1. Be More Real: Travel Diary Generation Using LLM Agents and Individual Profiles
この研究では、LLMを活用して都市の移動履歴の擬似データを生成する手法が提案されました。性別、年齢、収入、好みの交通手段といった詳細な個人属性を考慮することで、よりリアルな移動パターンの作成に成功しています。個人のペルソナに合わせたデータ生成が可能となり、プライバシーを考慮しつつ、都市計画や交通システムの改善に役立つデータを提供できる可能性が示されました。
2. PLM4Traj: Leveraging Pre-trained Language Models for Cognizing Movement Patterns and Travel Purposes from Trajectories
この論文では、時空間情報と地点情報(POI)の説明(自然言語)を同時にモデリングするためにLLMを用いた新しいアプローチが提案されました。数値データと自然言語の説明を組み合わせてLLMでエンベディングする手法が紹介され、移動パターンと通貨箇所についての定性的な説明を同時に考慮するという、定量と定性のかけ合わせが提案されていました。
本会議
Keynote session: From Word Prediction to Complex Skills: Compositional Thinking and Metacognition in LLMs
Sanjeev Arora氏(Princeton University)のKeynote sessionで、LLMはknowledge(知識)ではなく能力(skill)を用いて回答させることが重要という内容の話です。
「Knowledge」と「Skill」の例を挙げると、「1+1 =2」という問題に対して、学習内の『知識』から「1 + 1 = 2」をおうむ返しする(stochastic parrotといわれる)のか、数式として認識して学習によって得た足し算という『能力』を利用して解いた結果を返すのかという違いになります。
氏は、後者の『能力』を用いてLLMに回答させること、また、LLMに能力を学習させ、能力を利用することが重要であると述べていました。
また、複雑なタスクをLLMに解かせるためには、多くの『能力』をLLMが組み合わせる必要があり、どの『能力』を利用しどのように組み合わせるのかもLLM自体が推定できる必要があると述べました。これを「Metacognition」と呼んでおり、LLMにおけるこの能力が複雑なタスクをとけるかどうかを左右するとしています。
この能力はモデルのサイズに依存しており、GPT-4ではおおよそ5個の能力を組み合わせることができることが論文にて報告されております。
ADS Track: Know Your Needs Better: Towards Structured Understanding of Marketer Demands with Analogical Reasoning Augmented LLMs
マーケターが大規模言語モデル(LLM)を介して説明可能な顧客セグメントを生成できるシステムに関する論文になっています。
このシステムの特徴は以下の2点です:
- マーケターの要望をLLMでラベル化する機能
- 過去の類似要望から知識を抽出し、LLMで新たな抽出ルールを生成し提示する機能
上記の機能により、マーケターに対してText2SQLよりさらに直感的にセグメントを生成することが可能になり、この新しいアプローチが従来のマーケティング手法と比較して、クリック率(CTR)を大幅に向上させたと報告していました。
質疑にて、この成功の鍵は過去の実際のマーケターのニーズをまとめた独自のデータセットにあると述べていました。このデータセットを作成し、LLMを通じてクエリ可能にしたことが、システムの性能向上につながったようです。この発表を聞き、ファーストパーティデータはもちろんとして、ユーザーの思考やニーズをデータとして収集する、現在多くの研究対象のトピックとなっているRLHFなどの手法が、実運用上でも重要なポイントとなると感じました。
ADS Track: Learning to Rank for Maps at Airbnb
Airbnbでマップ上にある宿泊施設のランキングをどのように見せるべきか、リスト形式でのランキングとマップ上でのランキングで考えるべきことは違うのでは?という問いに対する研究です。
- 問題設定:予約数を最大させるためのマップ上でのランキング表示
- ポイント:
- リスト形式ではランキング上位の方がCTRは高い
- マップ形式では上位のリストにランク付けしても影響がない
- 予約数を最大化させるにはマップ上にピンが少なければ少ない方がいい選択肢を増やしつつ最適なマップへの表示数の問題をA/Bテストで評価
着眼点や検証方法などとても面白かったです。マップとリストのランキングに対する違いが面白いのでとてもおすすめです。
ADS Track: Chaining text-to-image and large language model: A novel approach for generating personalized e-commerce banners
ウォルマートのEコマースにて、ユーザーの購買履歴に基づいたパーソナライズされたバナー生成を行うことに関する論文です。
▼モチベーション
- 手動でパーソナライズしたコンテンツを生成することは限界があるため、実運用可能な形で自動生成を行いたい
▼提案手法
- 大規模言語モデル(LLM)と画像生成モデル(Stable Diffusion)を連携
- ユーザーの購買商品からLLMで商品属性とキーワードを抽出し画像生成プロンプトに変換
- このプロンプトをもとにStable Diffusionを利用してパーソナライズされたバナーを生成
▼評価
-
- ベンチマーク手法:商品名・カテゴリをそのままStable Diffusionのプロンプトに利用する
- BRISQUEスコア:提案手法の方が高品質になる傾向
- 人間による評価:提案手法の方が関連性の高い画像を生み出すこともあるが完全にアウトパフォームするわけではない
▼所感
私は普段、データを活用したプロダクト企画をメインの仕事としているため、実務目線でとても興味深い点がいくつかありました。
発表後に著者に、「元の商品写真に似ている」という類似度自体を何らかのモデルで評価することは試みたのか、お伺いしたところ以下のようなことを教えていただきました。
- 結論として、試しはしたが実運用としては上手くいかなった
- 「元の商品画像」と「生成された画像」のよくある違いは、キャビネットの取手の有無など詳細部分なことが多い
- そうした差は、全体的には微々たる差なのでスコア上は高く出るが、実際の消費者の購買体験からしたら受け入れられない差になりやすい
- そのため、実運用は人による評価に依存する現状
実際のプロダクトに活用しようとしたときのあと一歩埋まらない課題が垣間見える内容で、その後のランチなどでも生成AIを導入する際に実務面で乗り越える壁などを色々お話しさせて頂きました。
こうした課題があるから「だから生成AIは実務的には使えない」と切り捨てず、後から技術的に解決するだろうポイントを見極めて今できる設計を考えていくことが重要ということを改めて考えさせてもらえる良い機会になりました。
ADS Track: Enhancing Personalized Headline Generation via Offline Goal-conditioned Reinforcement Learning with Large Language Models
ユーザーの閲覧履歴等に基づいてパーソナライズされたニュースのヘッドラインを作成することに関する論文です。
▼モチベーション
- LLMを使ってパーソナライズされたコンテンツを生成したいが、様々な制約がある
- 特にユーザー情報を活用したニュースタイトルを作成する際には、倫理面やハルシネーションなどの課題を解決しながら生成できるようにしたい
▼提案手法
- ユーザーが過去にクリックした記事の情報などを自然言語のプロンプトとして構造化
- 以下の3つのファクタを報酬関数に含めたReinforcement Learning via Supervised Learning
- personalized + reality + sensitive
- realityはROUGE-1 + ROUGE-2 + ROUGE-Lで評価
▼評価
- 実際の金融レポートのデータセットにおいても、reality scoreが高いタイトルを生成可能
▼所感
一つ前の発表同様に実務目線で聞いていたのですが、ROUGE-1 + ROUGE-2 + ROUGE-Lを使っても、わずかな詳細が異なってしまうことはあるのではないか?ということが疑問として残りました。
上手く意図を伝えられなかった可能性が高いものの、著者の方にお伺いしたところ「現状のやり方でニュース本文との相関はかなり取れているから解決できる」というお話をして頂きました。
私の理解不足の可能性は多分にありそうですが、実運用に投入した際に、わずかでも数字に誤りがあるとレピュテーションリスクが高まるなどの課題もあるように感じており、こうしたアイデアをどうプロダクト作りに活かしていくか考えさせられるテーマでした。
KDD cup
KDDで開催されているデータ分析の大会で最近ではLLMに関わる大会が多い印象です。今年は以下の2つのコンペが開催されました。
- Amazon
- Meta
Amazonコンペでは現実世界のオンライン ショッピングの複雑さを模倣した包括的なベンチマークであるShopBenchを用いて、4つの主要なショッピングに関するタスクを解くコンペでした。
Track1:ショッピングコンセプトの理解
Track2:ショッピング知識の推論
Track3:ユーザー行動の整合性
Track4:多言語能力
MetaコンペではCRAGと呼ばれるRetrieval-Augmented Generation (RAG)システムを評価するためのベンチマークを用いて、5つのドメインと8つの質問タイプを通じてRAGシステムを評価するタスクです。
Track1:検索要約
Track2:ナレッジグラフとウェブ検索
Track3:エンドツーエンドの検索拡張生成
会場では各コンペの上位3チームによる解法の解説などもあり、参考になるアプローチが多くありました。
現地の様子
ここからは現地の様子を紹介します。
Keynote session等で使用されるホールは会場がかなり大きく、コンサートができるくらいの規模がありました。また会場も大きく、同時刻に10個くらいのセッションが並行して行われていました。

現地参加ならではの魅力として、他の参加者との交流が挙げられます。ポスター発表や休憩時間には、参加者と議論する機会があります。現地参加による交流では以下のようなものがありました。これらの時間では気軽にいろんな研究者や企業の方と話すことができます。
- Meet up
- 企業ブース
- ポスター発表
私たちも興味のあるMeet upやポスター発表に行き、有意義な議論や興味深い話を聞くことができました。
Meet up
特にMeet upでは同じ興味関心を持つ人とお話しすることが可能なので、期間中様々なMeet upに参加してみました。
その中でも個人的に学びが多く楽しかったのは、「A/Bテスト実践ガイド」の著者でもあるRon Kohavi氏などが主催していた“Product Experimentation MeetUp in Barcelona”です。
A/Bテストやサーベイの設計を含むプロダクトマネジメント・プロダクト改善をどのように科学的に行うか、Kohavi氏を含む3名の登壇者がLTをされた会です。
個人的にはItamar Gilad氏の発表がとても興味深かったです。
この発表まで寡聞にして存じ上げなかったのですが、モックを当てて顧客のFBKを回収するなど定性的な評価も含む“test”を“experiment”と区別して定義した上で、プロダクトの進捗を簡潔かつ定量的に評価できるバロメータを作成していました。
スタートアップや新規事業ではA/Bテストをやることが難しい場面が多々あります。私自身も普段新規事業でプロダクト作りをしており商品仮説の証明の段階で自分の中で感じている手応えや進捗を他の人にわかりやすく表現することに苦戦していたので、とても勉強になりました。


バルセロナの街並み
最後に、バルセロナの街並みを少しご紹介したいと思います。気候は暑いですがカラッとしており、とても過ごしやすかったです。会場は海の近くにあり、徒歩5分ほどでビーチまで出れます。また、会議終わりに有名なガウディ建築で観光名所のカサ・ミラやサグラダファミリアも見ることができました。
ご飯は生ハムやパエリアが有名だと思いますが、何を食べてもとても美味しく住みやすい街でした。




終わりに
今回サイバーエージェントからは3名の社員が現地参加しましたが、他の企業の方との交流ができたことはとてもいい経験になりました。国を問わず似たような経験を持っている方も多く、自身の業務に活かせそうなこともとても多かったです。
また、KDDはインダストリーの発表が多かったこともあり、すぐにでも自身のプロダクトで検証できそうなことが多かったです。これから、それぞれが今回のKDD参加を通して学んできたことを担当プロダクトに活かしていくとともに、来年KDDでの発表などにも挑戦していければと思います。
出典
- https://www.researchgate.net/publication/383260550_A_Tutorial_on_Multi-Armed_Bandit_Applications_for_Large_Language_Models