
はじめに
株式会社AI Shiftでバックエンドエンジニアをしている木村です。
今回は生成AI活用アプリ開発ゼミでの活動として作成したアプリケーションについて書きたいと思います。
経緯
サイバーエージェント社内でゼミ制度というものがあり、私は生成AI活用アプリ開発ゼミに所属しています。
生成AI活用アプリ開発ゼミでは『生成AIを使って何かおもしろいもの作ろうぜ』という目的の元、アイデアを形にするため経費を使って楽しく個人開発をしております。(もちろんいつか会社に大きく還元するぞという気持ちです)
ゼミ制度はメインの仕事とは別で業務時間を使って研究テーマに沿った活動する制度です。
制度自体の詳細はこちら。
開発の目的
以前から会議での議論をもっと効率的にできないかという思いがあり、LLMを使って解決できないかと考えました。もう少し詳細にすると以下のようになります(問題特定と解決策が入り乱れていますが)。
- 議論をリアルタイムに可視化する
- 会議中の参加者の認知を助けるもの
- 文字よりは図
- (重要なところはホワイトボードやmiroに書きながら話すことで理解が深まったということは多くの人が経験あると思います )
- グラフィックレコーディングに近い
- 少し前に話したことも参加者が把握しやすくなる
- 議論を構造化する
- 反対意見や補足などの関係性の可視化
- 議論の全体像と現在位置を把握
- 議題がそれても元に戻れるようにする
アプリケーションとしては以下の手順で実現できるのではないかと考えました。(大枠の機能としては)
- 音声を受け取る
- 受け取った音声をリアルタイムに文字起こし
- 文字起こしした文章を図に変換
まずは図の形式の検討
候補と検討結果
LLMは基本テキストの生成なので図をテキストで表現できる形式を候補に考え、画像生成AIもどういう出力になるのか検討しました。
まずはコードを書かずに会議の文字起こし結果からWeb版のChatGPTなどで以下の形式を出力してみました。
- PlantUML, Mermaid
- 表現力がもう少し欲しい
- 作成できる図の形式がコンポーネント図やフローチャートなど図が限定される
- レイアウト崩れはしにくい
- LLMではなくDALL-E3などの画像生成AI
- 一見それっぽいが、よく見ると議事録を反映してくれない
- 文字が苦手
- 会議中に図をアップデートしていきたいが毎回異なる画像が出力される
- SVG
- SVGとは
- <line>や<rect>などのタグで表せられるドロー系の画像データ
- 各タグは開始位置の情報と大きさの情報などを持つ
- 線、矩形、円など自由に作図できる
- テキストなので差分更新可能
- SVGとは
DALL-E3で出力してみた結果
プロンプトに議事録とグラフィックレコーディングのように図にするよう指示しました。
文字(特に日本語)が苦手なので厳しいです。
FLUX.1で出力してみた結果
先ほどと同じように議事録をグラフィックレコーディングのように図にするようなプロンプトで出力。
こちらはさらにグラフィックレコーディングっぽいです。
議事録の内容はほとんど反映されませんでした…
gpt-4oでSVGを生成した結果
<svg xmlns="http://www.w3.org/2000/svg" width="1000" height="800">
<!-- 背景 -->
<rect width="100%" height="100%" fill="white" />
<!-- タイトル -->
<text x="50%" y="50" font-size="24" text-anchor="middle" fill="black">会議議事録</text>
<!-- 話題1: 録音に関する懸念 -->
<rect x="50" y="100" width="400" height="60" fill="#FFD700" />
<text x="60" y="130" font-size="18" fill="black">録音による緊張感と収録の難しさ</text>
<!-- 話題2: 保育施設に関する意見 -->
<rect x="50" y="180" width="400" height="60" fill="#ADD8E6" />
<text x="60" y="210" font-size="18" fill="black">奈良市保育施設での子育ての困難</text>
<!-- 話題3: Azure OpenAIサービスの運用 -->
<rect x="50" y="260" width="400" height="60" fill="#90EE90" />
<text x="60" y="290" font-size="18" fill="black">Azure OpenAIサービスの運用に関する懸念</text>
<!-- 話題4: AIコネクターの運用 -->
<rect x="50" y="340" width="400" height="60" fill="#FFA07A" />
<text x="60" y="370" font-size="18" fill="black">AIコネクターの運用とロードバランスの課題</text>
<!-- 話題5: プロンプトの検証 -->
<rect x="50" y="420" width="400" height="60" fill="#FFB6C1" />
<text x="60" y="450" font-size="18" fill="black">LLMプロンプトの検証と無駄の削減</text>
<!-- 結論 -->
<text x="50" y="520" font-size="18" fill="black">全体として、AI運用の見直しとプロンプトの最適化が重要な課題として浮上。</text>
</svg>
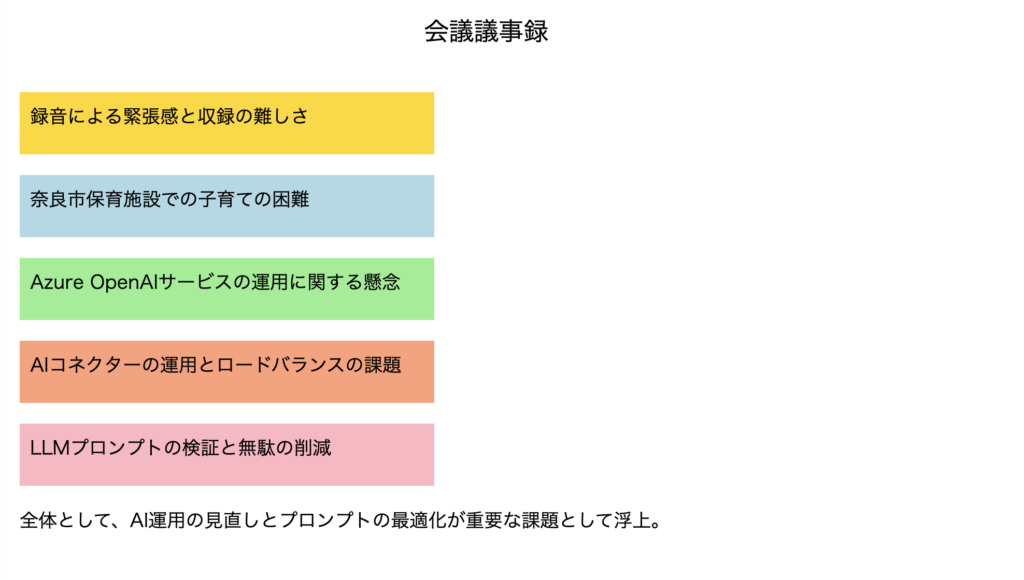
※奈良市保育=慣らし保育。参加者が揃うまでの近況報告です。
Claude 3.5 SonnetでSVGを生成した結果
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 800 600">
<style>
text { font-family: sans-serif; }
.title { font-size: 24px; font-weight: bold; }
.subtitle { font-size: 18px; font-weight: bold; }
.content { font-size: 14px; }
</style>
<!-- 背景 -->
<rect width="100%" height="100%" fill="#f0f0f0"/>
<!-- タイトル -->
<text x="400" y="40" class="title" text-anchor="middle">議事録まとめ</text>
<!-- 主要トピック1: AIコネクター -->
<circle cx="200" cy="150" r="80" fill="#ff9999"/>
<text x="200" y="140" class="subtitle" text-anchor="middle">AIコネクター</text>
<text x="200" y="160" class="content" text-anchor="middle">リソース管理</text>
<text x="200" y="180" class="content" text-anchor="middle">サブスクリプション</text>
<!-- 主要トピック2: プロンプトエンジニアリング -->
<circle cx="600" cy="150" r="80" fill="#99ff99"/>
<text x="600" y="140" class="subtitle" text-anchor="middle">プロンプト</text>
<text x="600" y="160" class="content" text-anchor="middle">エンジニアリング</text>
<text x="600" y="180" class="content" text-anchor="middle">検証と効果測定</text>
<!-- サブトピック1: リージョン管理 -->
<rect x="50" y="250" width="150" height="100" rx="20" fill="#ffcc99"/>
<text x="125" y="290" class="subtitle" text-anchor="middle">リージョン管理</text>
<text x="125" y="310" class="content" text-anchor="middle">使用制限</text>
<text x="125" y="330" class="content" text-anchor="middle">プロダクト別</text>
<!-- サブトピック2: MTベンチマーク -->
<rect x="250" y="250" width="150" height="100" rx="20" fill="#99ccff"/>
<text x="325" y="290" class="subtitle" text-anchor="middle">MTベンチマーク</text>
<text x="325" y="310" class="content" text-anchor="middle">効果測定</text>
<text x="325" y="330" class="content" text-anchor="middle">8カテゴリ評価</text>
<!-- サブトピック3: プロンプト検証 -->
<rect x="450" y="250" width="150" height="100" rx="20" fill="#cc99ff"/>
<text x="525" y="290" class="subtitle" text-anchor="middle">プロンプト検証</text>
<text x="525" y="310" class="content" text-anchor="middle">効果あり/なし</text>
<text x="525" y="330" class="content" text-anchor="middle">タスク依存</text>
<!-- サブトピック4: 今後の課題 -->
<rect x="650" y="250" width="150" height="100" rx="20" fill="#ffff99"/>
<text x="725" y="290" class="subtitle" text-anchor="middle">今後の課題</text>
<text x="725" y="310" class="content" text-anchor="middle">継続的な検証</text>
<text x="725" y="330" class="content" text-anchor="middle">知見の蓄積</text>
<!-- 結論 -->
<path d="M400,400 L350,500 L450,500 Z" fill="#ff99cc"/>
<text x="400" y="470" class="subtitle" text-anchor="middle">結論</text>
<text x="400" y="490" class="content" text-anchor="middle">賢くLLMを活用</text>
<text x="400" y="510" class="content" text-anchor="middle">継続的な改善</text>
<!-- 連結線 -->
<line x1="200" y1="230" x2="125" y2="250" stroke="#333" stroke-width="2"/>
<line x1="200" y1="230" x2="325" y2="250" stroke="#333" stroke-width="2"/>
<line x1="600" y1="230" x2="525" y2="250" stroke="#333" stroke-width="2"/>
<line x1="600" y1="230" x2="725" y2="250" stroke="#333" stroke-width="2"/>
</svg>
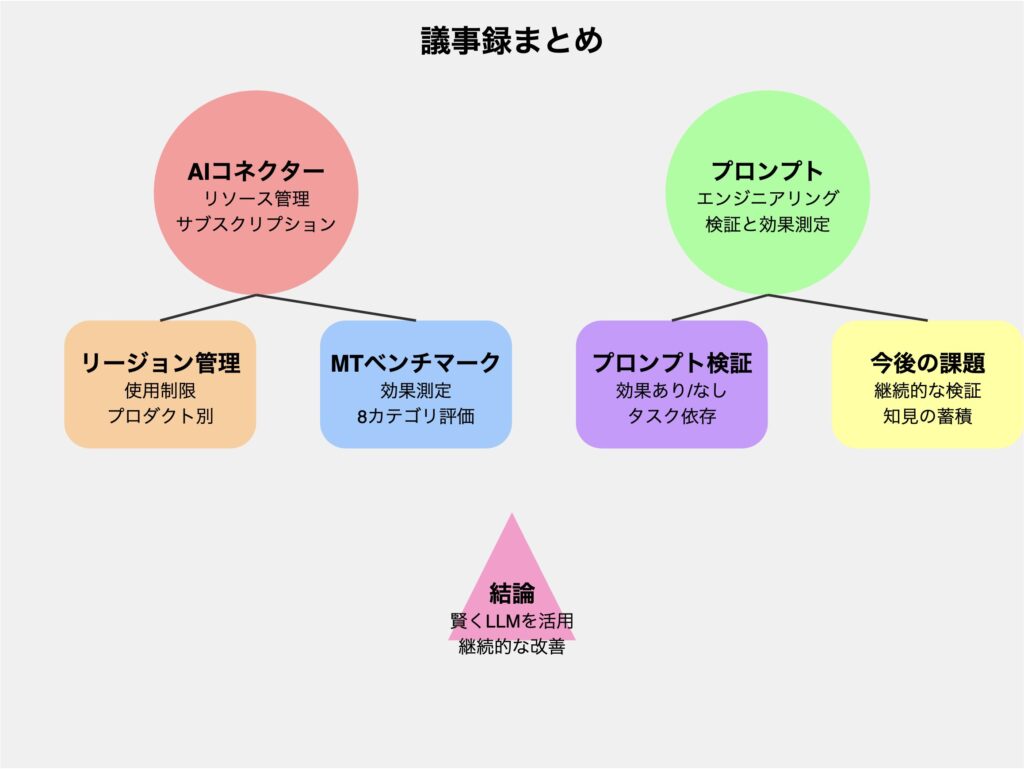
こちらのほうが情報量が多く、関係性も表現されています。
図の出力形式の決定
比較検討した結果、形式はSVGで、LLMはClaude3.5 Sonnectを使うことにしました。
LLMの比較では情報の構造化とSVGのフォーマットの正しさでClaude3.5 Sonnectがよさそうでした。
参考 : LLMのモデル比較
| モデル | 出力されるSVGの質 | INPUT($)/1M token | OUTPUT($)/1M token | Max Output token | Context Window |
|---|---|---|---|---|---|
| gpt-4o (2024-08-06) | 情報の構造化は単純 SVGのフォーマット違反になることもあった |
$2.50 | $10.00 | 16,384 | 128,000 |
| Claude 3.5 Sonnet | より構造化させている フォーマット違反やレイアウト崩れが少ない(感覚) |
$3.00 | $15.00 | 8,192 | 200,000 |
アプリケーションの全体像
以下の流れで処理します。
- 音声取得 (Streaming)
- 文字起こし (Streaming)
- SVG生成
音声入力は常時受け付けつつGoogleSTTに送り、ある程度のまとまりで文字起こし結果を受け取ります。
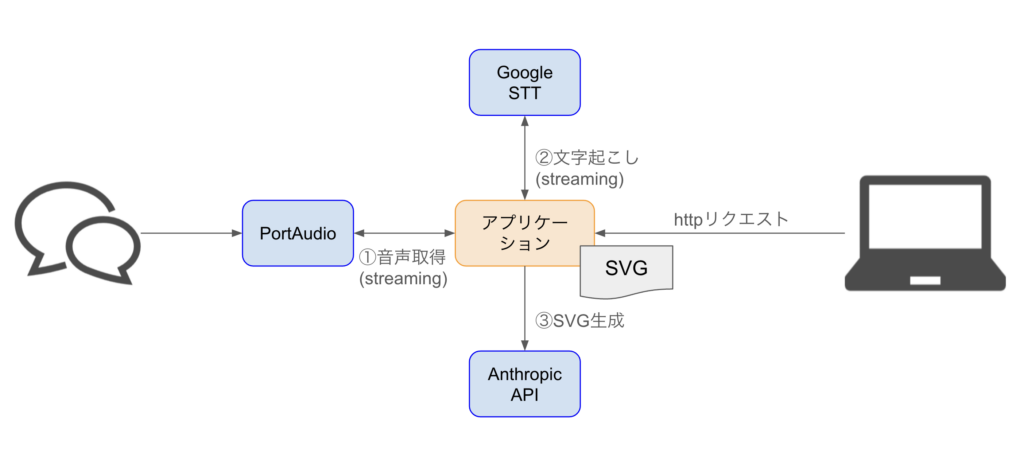
①音声取得
今回はPortAudioを使いました。PortAudioはオープンソースのオーディオ入出力ライブラリで、PCのマイクの音をプログラムから取得できたりPCにBlackHoleなどの仮想オーディオデバイスをインストールすればPCのオーディオ出力をプログラムから取得できます。
Zoom会議に入室して仮想オーディオ経由で音声を取得すればZoom会議の音声も取得できます。ただし、オーディオ出力を横取りする形になるで自分が音声を聞けなくなります…
サンプルがあって実装しやすそうだったのとテストしやすそうだったのでいったんこれを採用しました。
将来的にオーディオ入力は複数対応して選べるようにするつもりです。
PortAudioの初期化
※実装はGolangで行いました
audioStream := make(chan []byte)
go func() {
// PortAudioの初期化
err := portaudio.Initialize()
if err != nil {
log.Fatal(err)
}
defer portaudio.Terminate()
// 音声入力ストリームの作成
stream, err := portaudio.OpenDefaultStream(channels, 0, sampleRate, framesPerBuffer, func(in []int16) {
audioStream <- convertToBytes(in)
})
if err != nil {
log.Fatal(err)
}
defer stream.Close()
// ストリームの開始
if err := stream.Start(); err != nil {
log.Fatal(err)
}
defer stream.Stop()
// ストリームを実行し続ける
select {}
}()
/*
import (
"bytes"
"encoding/binary"
"github.com/gordonklaus/portaudio"
"log"
)
const (
sampleRate = 16000
framesPerBuffer = 1024
channels = 1
)
func convertToBytes(in []int16) []byte {
buf := new(bytes.Buffer)
for _, v := range in {
binary.Write(buf, binary.LittleEndian, v)
}
return buf.Bytes()
}
*/
②文字起こし(streaming)
Google STTを使いました。Sreamingの音声をリアルタイムに文字起こしできるので便利です。
Google STTの初期化
// GoogleSTT Streamの作成
client, err := speech.NewClient(ctx, option.WithCredentialsFile("conf/xxxxxx.json"))
if err != nil {
log.Printf("Failed to create client: %v", err)
}
defer client.Close()
sttStream, err := client.StreamingRecognize(ctx)
if err != nil {
log.Printf("Failed to create sttStream: %v", err)
return nil, err
}
// 設定を送信
req := &speechpb.StreamingRecognizeRequest{
StreamingRequest: &speechpb.StreamingRecognizeRequest_StreamingConfig{
StreamingConfig: &speechpb.StreamingRecognitionConfig{
Config: &speechpb.RecognitionConfig{
Encoding: speechpb.RecognitionConfig_LINEAR16,
SampleRateHertz: 16000,
LanguageCode: "ja-JP",
},
InterimResults: true,
},
},
}
if err := sttStream.Send(req); err != nil {
log.Fatalf("Failed to send config request: %v", err)
}
/*
import (
"context"
"log"
speech "cloud.google.com/go/speech/apiv1"
"cloud.google.com/go/speech/apiv1/speechpb"
)
*/
オーディオ入力をGoogleSTTに流す
go func() {
audioStream := portaudio.GetAudioStream() // 音声データを取得する関数
for {
audioData := <-audioStream
if err := sttStream.Send(&speechpb.StreamingRecognizeRequest{
StreamingRequest: &speechpb.StreamingRecognizeRequest_AudioContent{
AudioContent: audioData,
},
}); err != nil {
log.Printf("Failed to send audio data: %v", err)
}
}
}()
文字起こし結果の受信
Google STTの結果でIsFinalが来たらGoogle STTの文字起こしが確定したタイミングなので、それを切れ目にして文字起こしから図に起こすようにしました。
for {
resp, err := sttStream.Recv()
if err == io.EOF {
break
}
if err != nil {
log.Printf("Failed to receive response: %v", err)
// STTが切れたら再接続(最大305秒)
// 省略
continue
}
for _, result := range resp.Results {
if result.Stability >= 0.9 {
// 確定ではないが確度が高いときの処理
}
if result.IsFinal {
for j, alt := range result.Alternatives {
// 文字起こし結果が確定したときの処理
}
}
}
}goルーチンとチャネルのおかげで楽に音声入力をGoogleSTTに渡す実装ができました。
③図の生成
プロンプト
const systemPrompt = `あなたは優れたグラフィックレコーダーです。以下のルールに従ってユーザー入力の議事録をグラフィックレコーディングの図としてSVGを生成してください。返答は以下のフォーマットのJSONでプレーンテキストで返してください。
## 出力JSONフォーマット
{
"svg_elements":[
"",
],
"svg_base":{
"width":"",
"height":"",
"viewBox":"",
}
"images":[
"x":"",
"y":"",
"width":"",
"height":"",
"title":"",
"prompt":"",
"target_entity_id":""
]
}
## 最重要ルール
- 1回の返答で必ずSVGと全ての画像の両方を出力してください。
- 前回生成されたSVGがあればそれを参照し、新しい要素を追加 してください
- 生成するSVGは外枠のsvgタグを除いた要素のリストを生成してください
- 生成するSVG要素は必ず1つのタグで1つのsvg_elements要素としてください
- 生成するSVGは出力用JSONに入れる前提で適切にエスケープしてください。
- 議事録は追加の差分のみユーザー入力に入ります
- 前回生成されたSVGがあればそれを基準にし、入力の議事録に対応した追加の要素のみを返してください
- 背景のようなrectタグは生成しないでください
- SVG内のテキストコンテンツは日本語を基本にしてください。
- 重要なエンティティにはイラストを生成して添えてください
- SVG内のテキストコンテンツで改行する場合はtspanタグを使用してy位置を変えてください。また不要な"\n"が含まれている場合は除去してください
- SVGのcircle要素の縦位置はyではなくcyを使ってください
- SVGの各要素にはid属性を付与してください
## グラフィックレコーディングに関するルール
### レイアウト
- SVGのviewBoxの初期値を1000x800に設定- エンティティ・セクションが増えてきたらsvgの縦サイズを増やす
- svgタグのwidth, height, viewBoxの値はsvg_baseに出力してください
- タイトルを上部中央に配置
### 図形
- 主要ポイントは一言のテキストで表しエンティティとして円または四角形で囲む
- そのときテキストが図形からはみ出さないよう注意する
- エンティティのまとまりをセッションとして矩形で囲み短いテキストを添える
- エンティティは濃い色、セッションは薄い色を塗る
### イラスト
- イラストはエンティティを補足するためのものである
- イラストは画像生成AIに生成させるために以下の情報を出力してください
- title : イラストのタイトル(英語)
- prompt : 画像生成AIに渡すプロンプト(英語)
- x : イラストのx座標
- y : イラストのy座標
- width : イラストの幅
- height : イラストの高さ
- target_entity_id : イラストが従属するエンティティのID
- 画像の配置はこちらでやるのでSVG内には絶対にタグ等は配置しないでください
### 構造化
- エンティティ同士の関係を線や矢印とテキストで示す
- 因果関係
- 類似性
- 階層関係
- 対立関係
- 過去・現在・未来などの時系列
- セクション間も関係性があれば矢印とテキストで示す
`生成される様子(動画)
※音声なし、4倍速
上段に文字起こしした文字列を表示し、文字起こし結果がある程度たまったらSVGの図を生成しています。
LLMでの処理
基本的にはClaudeに上記プロンプトで処理を投げています。以下試行錯誤した点を挙げておきます。
- 発言の履歴と生成結果の履歴をすべてLLMに投げるほうが綺麗な図になるが、早々にContext windowから溢れてしまうので、今回だけの発言と最新の生成結果だけをLLMに投げるようにした。
- Function Calling (ClaudeではTools)も試したが画像生成用プロンプトは生成されてSVGは生成されないなどあった
- 前段として発言内容を要約すると作図が少し安定した
補足 : イラスト生成
まだ実験段階ですが補助的な役割でイラストも生成しています。
`- イラストは画像生成AIに生成させるために以下の情報を出力してください
- title : イラストのタイトル(英語)
- prompt : 画像生成AIに渡すプロンプト(英語)
- x : イラストのx座標
- y : イラストのy座標
- width : イラストの幅
- height : イラストの高さ
- target_entity_id : イラストが従属するエンティティのID`
プロンプトのこの部分と出力JSONフォーマットで画像生成に必要な情報をLLMで生成しています。
生成されたpromptからDALL-E3などの画像生成APIを利用してみましたが生成まで時間がかかるため以下の手段で実装しました。
- アイコン配布サイトからアイコン画像約3000個を取得(MITライセンス)
- アイコン画像にはカテゴリ/タイトルが付いているので、そのすべての文字列をOpenAI EmbeddingAPIを使ってベクトル化して保存
- 生成されたpromptも同じようにベクトル化して保存済みをベクトル群から近いアイコンがあればそれを表示
感想と今後の展望
5ヶ月間メインの仕事とは別に少しずつ進めてローカルで一通り動くところまでできました。途中からは作るのが楽しくなって土日もコードを書いていました。
ただ、『開発の目的』に書いたことの達成まではまだ距離があるので、来期以下を改善していこうと思います。
- 作図として理想状態を考える
- いったん動かすことを目的にできることを積み上げてきたが、どういう図だと目的を達成できるか理想から考える
- 情報アーキテクチャの観点でデザイナの人に聞いてみる
- いったん動かすことを目的にできることを積み上げてきたが、どういう図だと目的を達成できるか理想から考える
- 図に関する課題を解消
- 矢印と図形が重なる
- 会議が長くなるとレイアウトが崩れやすい
- イラストの生成位置が不安定
- 図の形式が単調
- 配布できる形式にする
- アプリケーションアイコンから起動できるようにする
- UIを作る
- Zoom等の音声を直接取得できるようにする
- SVGの表示をブラウザ経由ではなくアプリケーション内で完結させる
おわりに
お読みいただきありがとうございました。次回記事を書くときにはアプリケーションを配布できてるよう開発していきたいと思います。