
はじめに
こんにちは!慶應義塾大学理工学研究科 修士1年の長嶋隼矢です。私はCA Tech Jobとして、極予測AIでのインターンシップに9月の1か月間参加し、広告クリエイター支援を目的としたAI技術を用いた広告素材の整合性評価の研究に取り組みました。この記事では、私がこの期間に取り組んだことについてご紹介します。
極予測AI
極予測AI 素材開発チームは、テキストや画像などのマルチモーダル生成技術を活用し、広告クリエイティブ制作の支援を行うことをミッションとしています。生成AI技術の研究開発に特化しており、大学や企業の研究所と連携しながら、最先端の技術を社会実装する役割を担っています。
取り組んだタスクについて
問題設定
今回のCA Tech Jobでは、広告素材における整合性の評価方法について研究を行いました。極予測AIを使った広告制作では、クリエイターは様々な素材を選び、AIによる効果予測をしながら効果の高いバナーを制作します。素材を選ぶ際には、さまざまな要素の整合性が重要視されますが、、それらを一つ一つ手作業で確認するのは非常に大変です。そこで、私たちはAIを活用して、適切な素材を推薦できるような評価手法の確立を目指しました。
整合性といっても、広告素材にはいくつかの異なる要素が絡んでおり、それぞれを適切に組み合わせる必要があります。例えば、背景画像と商品画像、キャッチコピーの間には、それぞれの関連性が求められます。ここでは、整合性を以下のようにいくつかの要素に分解して考えました。
- 背景画像
商品と無関係な背景が使用されていると、視覚的な違和感を与えることがあります。例えば、化粧品の広告に対して工業的な背景が使われている場合、ブランドイメージに合わず、訴求力が低下します。 - 商品画像
広告に使用される商品画像は必ず正しいものである必要があります。 - コピー
コピーの内容が商品の特性や訴求したい内容としっかりとマッチしているかどうかが重要です。例えば、若者向けのエナジードリンクに対して「リラックス効果抜群!」というコピーは、ターゲット層との整合性が取れず、効果的とは言えません。 - ターゲットとの整合性
広告がターゲットとする年齢層や性別に対して、素材が適切であるかを評価します。例えば、高齢者向けの商品広告に若者をモデルとして起用する場合、ターゲット層に対して訴求力が低くなります。 - レイアウト
画像とテキストの配置やバランスも重要な要素ですが、今回の研究ではレイアウトについては扱わないこととしました。
最初はターゲット層の性別や年齢を考慮しようとしましたが、これらのデータは広告媒体によって設定される粒度が異なり、一貫した評価を行うことが難しいと判断しました。そのため、今回はターゲット層との整合性については直接的な評価を行わず、背景画像、商品画像、コピーの整合性を中心に評価を行うことにしました。
また、レイアウトの整合性に関しても、ユーザーが実際にどう感じるかといったアノテーションデータの必要性を感じたことに加え、1か月という短期間ではスコープが広すぎるため、今回は扱わないことにしました。
最終的に、広告内素材間の整合性と、商品内容と広告の整合性の2点を数値化し、クリエイターにとって役立つ指標を提供することで、より効果的なクリエイティブを短時間で作成できるよう支援することを目指しました。

図1 広告素材における整合性の事例
関連研究
関連する研究として、Vision and Language Model (VLM) を用いたクロスモーダル検索の手法が挙げられます。特に、CLIP [Radford+, ICML21] は、画像とテキストのペアを学習し、両者の埋め込み表現を取得することで、画像とテキストの類似度を計算することが可能なモデルです。CLIPは、画像とテキストの対になったデータセットを用いて学習されており、その類似度計算によって視覚と言語の関係性を評価することができます。
また、DCNet [Kim+, AAAI21] では、参照画像とターゲット画像の差分を利用して、より頑健な視覚表現を取得することを目的とした手法が提案されています。これにより、従来のクロスモーダル検索において見落とされがちな微細な違いを捉えることが可能となり、検索精度を向上させています。
さらに、私が第二著者として関わった論文 [Kaneda+, RA-L24]では、物理世界における検索エンジンを用いて日常物体を特定するためのMultiRankItを提案しました。この手法では、自然言語の指示文をもとに、その指示文に適した対象物体を含む画像を検索します。また、検索対象となる物体に関連する情報を効果的に取得し、ランキング学習によって精度の高い検索結果を提供することを目指しています。
アプローチ
今回の整合性スコアを求めるタスクにおいて、私はVision & Languageの対照学習アプローチが有効だと考えました。その理由は以下の通りです。
- 正例データの容易な取得: 実際に配信された広告素材のデータは、整合性が取れているものとして「正例」として扱うことができるため、追加のアノテーションが不要です。
- 負例データの簡単な作成: 負例は、正例データの組み合わせをランダムに変えることで簡単に生成可能であり、また明示的にデータセットを作成する必要がないため、データ準備の負担が少なくなります。
- 類似度スコアの直接的な使用: Vision & Languageモデルを用いることで、画像とテキストの類似度を数値として出力でき、これをそのまま整合性のスコアとして扱えるため、評価方法とモデルの相性が良いです。
これらの点から、広告素材の整合性評価において、Vision & Languageモデルを活用することで、効率的に整合性を数値化し、クリエイターにとって有益な指標を提供できると考えました。
提案手法
今回の研究では、広告素材の整合性を広告レベルと商品レベルの2つのレベルで評価しました。以下では、それぞれを広告Lv.、商品Lv.と省略して表記します。
図2は、広告Lv.におけるモデルの構造を示しています。広告Lv. では、広告内のテキストと画像の整合性を評価しました。具体的には、広告からテキストとテキストなしの画像を抽出し、CLIPモデルを用いて両者の埋め込み表現を取得し、コサイン類似度を計算して整合性スコアを算出します。
図3では、商品Lv.におけるモデルの構造を示しています。商品Lv. では、広告とランディングページ(LP)の整合性を評価しました。LPから取得した画像とテキスト情報をMultimodal LLMであるGPT-4oを用いて要約し、商品の特徴を抽出します。これらの情報をCLIPを用いて埋め込み表現に変換し、広告との類似度を評価します。
これらの手法により、広告内および広告とLP間の整合性を効率的に数値化し、クリエイターやマーケターが素材選定を行う際の指標として活用できることを目指しました。
また、損失関数に関しては[Kaneda+, RA-L24]と同様に以下を用いました。
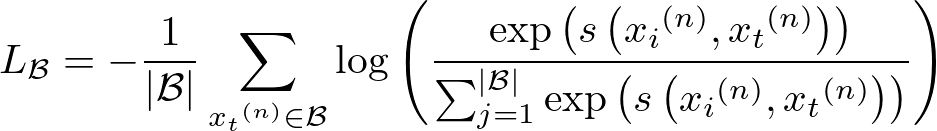
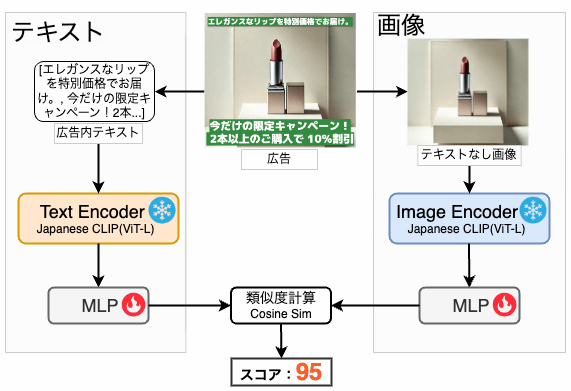
図2 広告Lv.における整合性評価のモデル構造
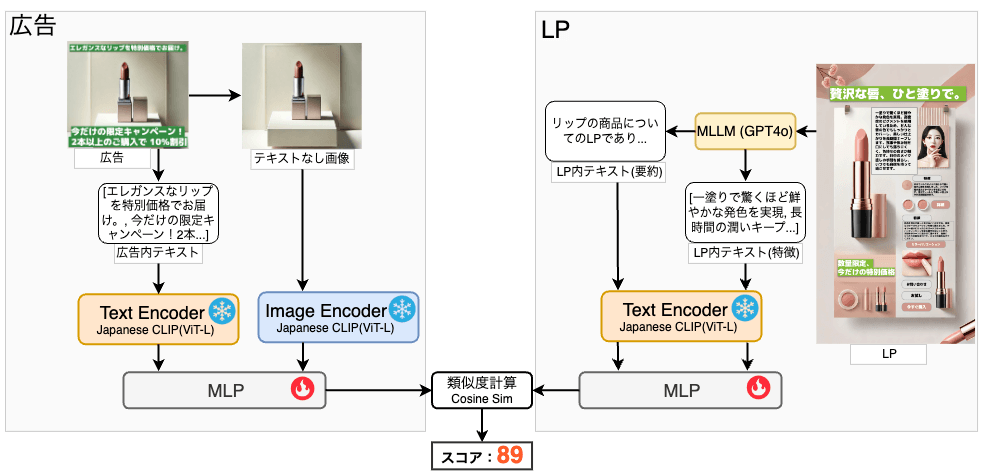
図3 商品Lv.における整合性評価のモデル構造
実験設定
今回の実験では、データセットを学習セット、検証セット、テストセットの3つに分割して評価を行いました。データの分割比率は以下の通りです。
- 学習セット: 70%
- 検証セット: 10%
- テストセット: 20%
訓練集合はモデルの学習に使用し、検証集合はハイパーパラメータの調整に、テスト集合はモデル性能の評価に使用しました。
実験結果
| [%] | Val MRR↑ | Val R@1↑ | Val R@5↑ | Val R@10↑ | Test MRR↑ | Test R@1↑ | Test R@5↑ | Test R@10↑ |
|---|---|---|---|---|---|---|---|---|
| 広告 Lv. | 30.4 | 19.0 | 43.1 | 53.9 | 22.4 | 12.7 | 32.3 | 42.2 |
| LP Lv. | 39.8 | 26.3 | 55.4 | 69.6 | 23.0 | 11.0 | 35.4 | 50.6 |
表1に定量的結果を示しています。評価指標として、MRR (Mean Reciprocal Rank) および Recall@K (K=1,5,10) を用いました。
MRRは以下のように定義されます。
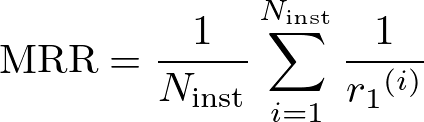
\text{MRR} = \frac{1}{N_{\text{inst}}} \sum_{i=1}^{N_{\text{inst}}} \frac{1}{{r_1}^{(i)}}
ここで、N_{\text{inst}}はテキストの数、{r_1}^{(i)}はランク付きリストにおける広告画像のランクを示します。
また、Recall@Kは以下のように定義されます。
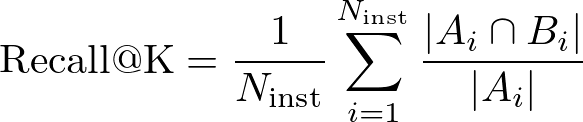
\text{Recall@K} = \frac{1}{N_{\text{inst}}} \sum_{i=1}^{N_{\text{inst}}} \frac{|A_i \cap B_i|}{|A_i|}
ここで、A_iは検索対象のサンプル集合、B_i は検索上位K個のサンプル集合を表します。
広告レベル整合性 (広告Lv.)
広告Lv.における定量的結果からは以下のことが言えます。
- Test Recall@10: 42.2%
- これは、テストセットの3000件のテキストの中から正しいものが上位10件に入る割合を示しています。
商品レベル整合性 (商品Lv.)
商品Lv.における定量的結果からは以下のことが言えます。
- Test Recall@10: 50.6%
- テストセットの500件のLPの中から適切なものが上位10件に入る割合を示しています。
これらの結果は、提案手法が広告内および広告とLP間の整合性を効率的に評価し、クリエイターが素材の組み合わせを選択する際の支援につながる可能性を示唆しています。しかし、実用化するには定性的な評価やエラー分析が必要であり、これらを通じてモデルの精度と信頼性を向上させることが求められます。
課題
今回の研究で取り組んだ広告Lv.と商品Lv.の整合性評価ですが、どちらも広告の効果を最大化するために重要な要素です。しかし、実際にデザインやマーケティングの現場で、どちらを優先すべきかといった指標がまだ明確に定義されていません。広告の訴求力を高めるためには、広告内の素材の整合性も大切ですし、ランディングページとの一貫性も欠かせません。今後、この問題を解決するための研究がさらに進められることが期待されます。
また、商品Lv.の評価を行う際に、ランディングページ(LP)の情報を取得する必要がありますが、LPをクロールできないサイトも多く存在し、その場合には整合性の評価が困難になります。この問題に対しては、別の手法やデータソースの検討が求められます。
さらに、整合性スコアが実際の評価基準とどれだけ一致しているかについても、まだ十分な検証が行われていません。例えば、広告のクリック率(CTR)やコンバージョン率(CVR)などのビジネス指標と、提案手法で得られた整合性スコアの相関を調査し、実務での有効性を確認することが今後の課題です。
感想
今回のインターンシップでは、短期間の中でデータセットの構築、モデルの学習、そして評価までを一通り経験することができました。特に、デザインの現場で整合性がどれほど重要か、そしてAIを用いた新しいアプローチがどのように活用できるかを学ぶことができた点は、とても有意義でした。
同時に、研究と実務のバランスを取ることの難しさも実感しました。理論的には最適な手法でも、実際の運用で問題が発生するケースがあり、これらをどのようにクリアしていくかが大きな課題です。今回得た知見を活かし、今後の自身の研究や実務での経験に繋げていきたいと思います。
総括
極予測AI 素材開発チームでの1か月間は、とても充実した時間でした。AIを使った素材評価の可能性に触れ、デザイン支援の新しいアプローチを見つけることができたのは、私にとって大きな収穫です。今回のインターンシップをもって、このタスクへの取り組みは一区切りとなりますが、今後も他の領域で得た知見を活かし、新たな課題に挑戦していきたいと思います。
最後に、この貴重な経験を支えてくださった極予測AI素材開発チームの皆さん、そしてサポートをしてくださった全ての方々に、心から感謝申し上げます。ありがとうございました!
参考文献
- [Radford+, ICML21] : A. Radford and W. Kim, “Learning Transferable Visual Models From Natural Language Supervision,” in ICML, 2021, pp. 8748–8763.
- [Kim+, AAAI21] : J.Kim, Y.Yu, et al., “Dual Compositional Learning in Interactive Image Retrieval,” in AAAI, vol. 35, no. 2, 2021, pp. 1771–1779.
- [Kaneda+, RA-L24] : K. Kaneda, S. Nagashima, et al., “Learning-To-Rank Approach for Identifying Everyday Objects Using a Physical-World Search Engine,” IEEE RA-L, vol. 9, no. 3, 2024.