
この記事は CyberAgent Developers Advent Calendar 2024 8日目の記事です。また、 自由入力解像度対応 Detection Transformer を錬成するトリック の続編です。
CyberAgent AI Lab の Agent Development チームで対話エージェント・ロボットの研究開発に従事しているリサーチエンジニアの兵頭です。 CyberAgent の Developer Experts としても、Labの研究活動だけではなく事業横断的に全社を技術で支援しています。
すべてのエッセンスを盛り込むといつも数十万文字超の長大な記事を書いてしまいバックエンドのブログシステムを破壊してしまうため、今回はデモコードなどをすべて排除して一年分の成果をできるかぎりコンパクトにまとめ、行間の質量を高めます。
1. 取り組んだタスク
2Dエージェントやロボット側から見た「人」の行動把握とトラッキングを行うために、1桁 ms オーダーの高速で高精度な物体検出モデルが必要になることがあります。今回は最近リリースされた Detection Transformer モデルである RT-DETRv2 [1] に自作のデータセットを学習させてモデルを生成しました。まずは生成されたモデルの性能をご理解いただくために、サンプルの検出結果をご覧ください。
ロボットと対峙する人の状態をリアルタイムに推定するために、全身、頭部、顔、目、鼻、口、耳、右手、左手、足、属性、顔向き8方向の情報を取得して簡易的にトラッキングするための物体検出モデルを生成しました。このモデルは、実環境のエッジ処理で稼働させる前提のため、軽量で、なおかつあらゆる環境ノイズ(モーションブラー、デフォーカスブラー、逆光、ハレーション、低照度、極近距離〜極遠距離)に適応する必要が有ります。



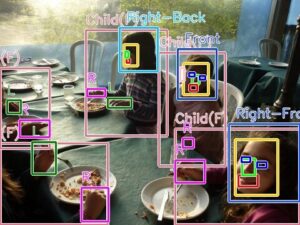
CNNだから。。。とか Transformerだから。。。とか、特定のアーキテクチャに偏って信仰しているつもりは全くありませんので良いものは積極的に使います。したがって、一般的に処理は重たいが精度は高め、と認知されているであろう Transformer がどれほど実運用に値するかをベンチマークしておこうと考えました。
2. 既存の公開データセットの問題点
モデルのトレーニングに使用できる様々な公開データセットがありますが、複数のデータセットを実際に目視で確認して感じた問題点は概ね下記のとおりです。どの問題点もデータセット間でほぼ共通していますが、ひとつのデータセットが全ての問題点を内在しているわけではありません。
- データ量が多すぎる
- 背景のバリエーションが少ない
- ノイズのバリエーションが少ない
- 距離のバリエーションが少ない
- 俯角・仰角のバリエーションが少ない
- 小さなオブジェクトにラベルが付与されていない
- 付与されているラベルが誤っている
- 物体検出用ラベルの場合はラベルの位置が正解の位置から大きくズレている
- オブジェクトが存在していない場所にラベルが付与されている
- 実装して実用するうえで有益な特徴を意識してラベル付けがなされていない
このような品質が低いデータセットを使用して学習されたモデルはバリデーションの結果がモデルの本来の性能を正しく評価できていない、ということを容易に想像できます。したがって、私は論文の見かけ上のベンチマークに全く興味がありません。
3. 自力アノテーションによるデータセット作成
CNNとTransformerの純粋なアーキテクチャ間の性能を比較するため、MS-COCO のサブセットである COCO-Hand [2] というデータセットの全ての画像に対して一人で手作業で再アノテーションして公開データセットの品質を完全に担保することにしました。今更ではありますがシングルモーダルの画像のみで押し切ります。再アノテーションをするうえでの方針は下記のとおりです。
- 目視で識別可能なオブジェクトは一つも取りこぼさずアノテーションを付与する
- 使用しているアノテーションツール(CVAT [3])でアノテーション可能な最も小さいサイズ 3×3 ピクセルまでは必ずアノテーションする
- クラスごとのアノテーション数に偏りが出ることは一切意識しない
- Small (< 32×32), Medium (32×32 〜 96×96), Large (> 96×96) の3サイズができるだけ多く網羅されるように意識する(この方針は画像セットに依存します)
- ピクセルレベルで無駄なマージンが入ることを一切許容しない
- ピクセルレベルで境界より小さい範囲のアノテーションを一切許容しない
- 高強度のモーションブラーやハレーション、暗がりの状態でも必ずアノテーションする
全てのパターンを網羅しているわけではありませんが、上記の基準を完璧に遵守したうえで実際にアノテーションした様子を 60FPS で 57秒 の動画にしました。使用した画像はノイズがほとんどありませんが、対象オブジェクトのサイズがとても小さく、一般的にはアノテーション難易度がとても高い画像です。 480x360 のサイズの画像に 2,611個 のアノテーションを施しています。動画が見やすくなるように 960x720 の縦横2倍のサイズに引き伸ばしていますが、実際のアノテーションはこの半分のサイズの画像に対して実施しています。なお、動画はレスポンシブデザインの影響で環境によっては最大サイズで表示できません。
実際のサイズのアノテーション済み画像は下図のとおりです。実寸大の画像はPC用ブラウザでの閲覧を推奨します。

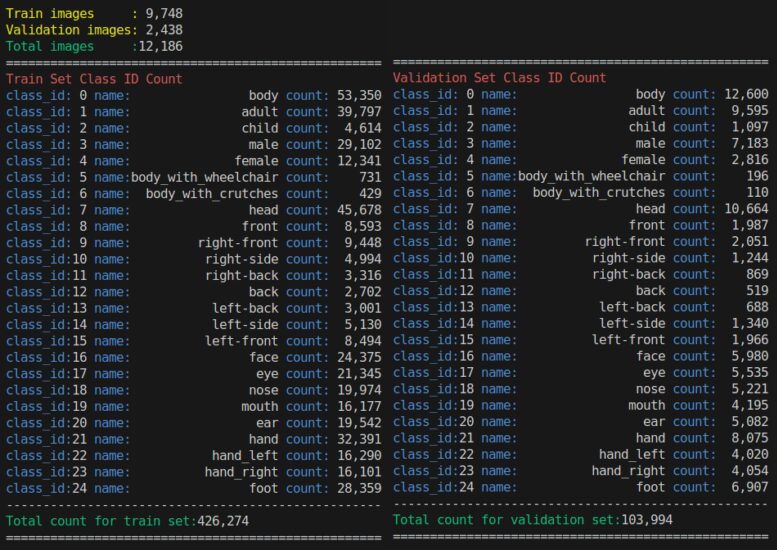
全ての画像セットに対してアノテーションしたクラスと各クラスのアノテーション数は下図です。合計 12,186枚 の画像に対して、530,268個 のアノテーションを一年掛けて手作業で付与しました。流行りの VLM や ViT (例えば DINOv2 [4]) などを使用してオートアノテーションすれば良いのでは? ということを考える方がいらっしゃるかもしれませんが、性能が低すぎて使い物になりません。現実を直視したほうが良いと思います。
※ NVIDIA A100 80GB x1 でギリギリ学習可能なデータ量です。ここから 2クラス〜3クラス 追加すると VRAM が 80GB では足りなくなります。次回からは GH200 96GB x1 にランクアップしようと考えています。
アノテーションの真髄 をまとめたプレゼンテーションに関しては Lab のブログとして後日公開予定ですのでそちらをご覧ください。
4. Detection Transformer の性能
ではようやく本題の Transformer の検出性能を見てみます。前の章までで作成したデータセットを使用して生成した RT-DETRv2 の検出性能です。
前提条件は、
- Face-Detector-1MB-with-landmark [5] から引用したテスト用画像を使用
- テスト用画像の解像度は 1600×898
- RT-DETRv2 のバリアントは最も検出性能が高い X サイズ、モデル内部のクエリ数は 1,250、モデル内部の処理解像度は 640×640
- モデルは、顔を含む全身各部位の25クラス [6] を学習
です。
- 入力画像

- 出力結果
大部分は正しく検出できていそうです。ただ、思いの外それほど性能が高くないように見えます。

5. CNN vs Detection Transformer
では、思い切った比較をしてみます。Transformer は CNN よりもベース性能が高いと思われがちですが、実際に比較してみるとどうなるでしょうか。
- 1MB CNN vs RT-DETRv2-X
わずか 1MB のファイルサイズの CNN の出力結果が左、300MB のファイルサイズの Transformer の出力結果が右です。CNN側は自由入力解像度の処理に対応したモデルですが、RT-DETRv2側は内部的に 640×640 にリスケールして処理されている点に注意が必要です。ただ、誰が見ても分かるレベルで CNN より Transformer の検出力が劣っているのが分かります。わかりやすいポイントは、より奥のほうの人の顔を検出できているか、できていないかです。
| 1MB CNN | RT-DETRv2-X 1,250query |
 |
|
- YOLOv9-E vs RT-DETRv2-X
RT-DETRv2 と同じデータセットで学習した YOLOv9-E [7] [8] という最も強力なCNN 1280×736 が左、RT-DETRv2 640×640 が右です。スコア閾値は同じ値に設定して比較していますが、CNN 側には後処理にNMSが含まれており RT-DETRv2 側にはNMSが含まれていません。もともと、Detection Transformerの設計上の売りのポイントにNMSを使用しなくても良いこと、という文言が論文にうたわれていますが、汎用性の観点ではかなりネガティブな結果が出ていることが明らかです。モデルの内部処理でのアスペクト比による影響はのちほど検証します。ちなみに、YOLOv9-E と RT-DETRv2 の Trainセット と Valセット は1枚違わず完全に一致させた状態で学習しています。
| YOLOv9-E | RT-DETRv2-X, 1,250query |
 |
|
過検出しているように見えるかもしれませんが状況はそんなに単純ではありません。そう思いたくなるのも分かりますが、実際に私のリポジトリのモデルとサンプル画像で試していただくことをおすすめします。YOLOv9側の出力をNMSでフィルタリングしたあとの最終出力バウンディングボックス数は 2,778個 でした。一応、最遠方に映り込んでいるであろう頭部部分をクローズアップしてみました。100m ほど離れている壁のポスターの頭部や、ガラス張りの奥に居る人の頭部まで検出できているようです。この距離感になってくると対象がほぼ点に等しいです。

学習の条件が異なると比較がフェアではありませんので、念の為 YOLOv9 と RT-DETRv2 の学習条件のうち、影響が軽微なオーグメンテーションの設定を除く学習条件と学習後の mAP を下記に記載しておきます。ここで示しておきたいのは、どちらのモデルも同じ画像セットを使用しているうえに 640x640 にリサイズして学習される設定になっているということです。つまり、上図のテスト画像を使用した場合は明らかに RT-DETRv2 のほうが分解能が低いということです。そして最も重要なことは、単純に mAP の数値の高低のみを見て運用時の性能を判断するのは誤りだということです。
| 項目 | YOLOv9-E | RT-DETRv2-X 1,250query |
| 学習 (train) 時の解像度 | 640×640 | 640×640 |
| 検証 (validation) 時の解像度 | 640×640 | 640×640 |
| 学習後のmAP | 60.7 | 65.0 |
| Params | 57.3M | 76.0M |
| FLOPS | 189.0G | 259.0G |
RT-DETRv2 の論文にうたわれている MS-COCO によるベンチマークが下図です。確かに精度も速度もCNNを凌駕していますし、私の手元のベンチマークでも相対比較では同じ傾向が出ています。YOLOv9 が比較対象に挙がっていませんが、数値上の性能は RT-DETRv2 のほうが高くなりましたので間違ってはいません。しかし、何か釈然としないものがあります。
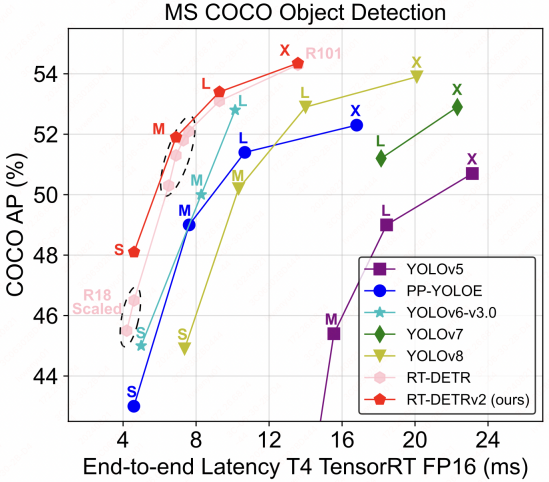
引用: RT-DETRv2 Fig
6. Transformerのクエリ数による性能変化
先程比較に使用した RT-DETRv2 は 640×640 の入力解像度、1,250クエリで学習していました。ここで、Transormerの特性上 1,250クエリ「しか」処理できない、つまり、1,250インスタンス「しか」処理できないという部分が大きく影響している可能性があるため、念のため2倍のクエリ数 2,500クエリの設定でモデルを再定義して学習し比較してみました。画像内には少なくとも数百人が映り込んでいます。結果的には、クエリ数を大幅に増やすと隠れ層などの処理のキャパシティを超えてしまい、かえって悪影響を及ぼしているように見えます。
| YOLOv9-E | RT-DETRv2-X, 2,500query |
|
 |

7. アスペクト比の変更による性能変化
自由入力解像度に対応可能なCNNと学習時に指定した解像度以外には対応できないTransformerとの比較はフェアではありませんので、Transformer側のアスペクト比がほぼ 1:1 になるように画像を左右に分断し、800x898 のほぼ正方形の状態にしてみるとどうなるでしょうか。結果は下図のとおりです。
| RT-DETRv2-X, 2,500query, Aspect ratio 1:1, Batch.1 | RT-DETRv2-X, 2,500query, Aspect ratio 1:1, Batch.2 |
 |
 |
アスペクト比がいびつになった状態のまま推論したときよりも明らかに検出精度が向上しているのが分かります。YOLOv9の入力画像の縮小率は 横0.80倍、縦0.82倍、RT-DETRv2の入力画像の縮小率は 横0.80倍、縦0.71倍 です。 この比較はまだフェアではありませんが、YOLOv9-E の検出性能の小指の先にも及んでいません。 なお、RT-DETRv2 側を 1280×736 で再学習して比較したいところですが、学習コスト(学習時間と必要VRAM容量)が高過ぎて手軽に検証するには非現実的で、投じたコストに対して得られる性能向上のメリットが見合わないと判断したため検証をスキップします。おそらく VRAM は 320GB ほど必要です。
8. 推論速度
最後に、推論速度の観点で比較しておきます。前の章の比較基準と同一条件で比較します。したがって、Transformer側の計算コストが著しく低く優位な状態で比較されていることに注意が必要です。なお、YOLOv9 と RT-DETRv2 の両方のモデルには前処理をマージ済みです。また、YOLOv9 側だけNMSの処理をマージ済みで End-to-End のモデルにしています。
検証環境
CPU: Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz
GPU: NVIDIA RTX3070 8GB
onnxruntime-gpu: 1.18.1
CUDA: 12.5
TensorRT: 10.6.0.26-1+cuda12.6
| 検証条件 | YOLOv9-E | RT-DETRv2-X 1,250query |
| 入力解像度 | 1280×736 | 640×640 |
| 推論ランタイム | onnxruntime-gpu TensorRT EP | onnxruntime-gpu TensorRT EP |
| 推論回数 | 10 | 10 |
| NMS | あり | なし |
計測結果は下記のとおりです。YOLOv9のほうの入力解像度が大幅に大きいため検証するまでもなく不利な比較をしていますが、CNNのほうは入力解像度のスケーリングに柔軟に対応できて精度を維持することができているという点では、運用の柔軟性が高い代わりにまっとうな計算コストが掛かるということが分かると思います。下表の推論時間は 10回 推論したときの 1回 あたりの平均推論時間です。
| YOLOv9-E | RT-DETRv2-X 1,250query |
| 69.31ms | 9.79ms |
では、YOLOv9 側の入力解像度を 640×640 に変更し、NMSを無効化して比較してみます。下記の条件です。
| 検証条件 | YOLOv9-E | RT-DETRv2-X 1,250query |
| 入力解像度 | 640×640 | 640×640 |
| 推論ランタイム | onnxruntime-gpu TensorRT EP | onnxruntime-gpu TensorRT EP |
| 推論回数 | 10 | 10 |
| NMS | なし | なし |
下記の結果になりました。NMSが無い YOLOv9 はとても速いです。
| YOLOv9-E | RT-DETRv2-X 1,250query |
| 10.20ms | 9.79ms |
では、YOLOv9 側のNMSを有効化して比較してみます。下記の条件です。
| 検証条件 | YOLOv9-E | RT-DETRv2-X 1,250query |
| 入力解像度 | 640×640 | 640×640 |
| 推論ランタイム | onnxruntime-gpu TensorRT EP | onnxruntime-gpu TensorRT EP |
| 推論回数 | 10 | 10 |
| NMS | あり | なし |
下記の結果になりました。注意点は、YOLOv9側は NMS の処理コストがモデル本体の推論コストと同じぐらい高いため、検出対象が多くなってくると遅くなることです。
| YOLOv9-E | RT-DETRv2-X 1,250query |
| 20.17ms | 9.79ms |
9. まとめ
データセットを本物に仕上げたうえで CNN と Transformer の精度と速度の観点で簡易的に比較してみましたが、この結果を受けて一概に CNN < Transformer だと言い切れなくなったのではないでしょうか。テストに使用したモデルの対応入力解像度が大きく異なったまま比較していますので、比較が全くフェアではないことは十分理解したうえであえて検証しています。ただ、モデルを利用する状況に応じて適切なアーキテクチャを選択するということはとても重要です。論文には一切うたわれていないことではありますが、モデルを利用する立場においてはデータの品質とアーキテクチャ選定の重要性をご理解いただけたのではないかと思います。最後に念の為補足しておきますが、比較的小さな解像度なおかつ検出対象のオブジェクト数が概ね 100未満 の画像で比較した場合は Transformer の検出性能のほうが格段に高くなります。Transformer は明らかにスケーリングに弱く運用の柔軟性が低いです。Transformerは速くて性能が高いので素晴らしいですが、 Attention Is All You Need とは全く思えなかったです。
職人芸はすぐに駆逐されるでしょう。そんなことは分かっていますし歴史が物語っています。だからこそ「芸」の部分に本質的な価値を見出してはおらず、永久に陳腐化しない「極みデータ」をひたすら蓄積し、スケールさせていくことに価値を感じています。「日本人はクレイジー。」と言わしめる圧倒的なものを1つでも世に残していきたいですね。
10. 付録
- https://github.com/PINTO0309/PINTO_model_zoo/tree/main/460_RT-DETRv2-Wholebody25
- https://github.com/PINTO0309/RT-DETR
- Nextチャレンジ – Object × Pose Detection CNN

11. 引用
- [1] https://github.com/lyuwenyu/RT-DETR
- [2] http://vision.cs.stonybrook.edu/~supreeth/COCO-Hand.zip
- [3] https://github.com/cvat-ai/cvat
- [4] https://github.com/facebookresearch/dinov2
- [5] https://github.com/Linzaer/Ultra-Light-Fast-Generic-Face-Detector-1MB
- [6] https://github.com/PINTO0309/PINTO_model_zoo/tree/main/460_RT-DETRv2-Wholebody25#2-annotation
- [7] https://github.com/WongKinYiu/yolov9
- [8] https://github.com/PINTO0309/PINTO_model_zoo/tree/main/459_YOLOv9-Wholebody25