
はじめに
こんにちは!京都大学大学院情報学研究科 修士1回生の上林駿希です。私はCA Tech JOBとして、極予測TDでのインターンシップに1ヶ月間参加し、広告文生成モデルのハルシネーション抑制に取り組みました。この記事では、私がこの期間取り組んだことについてご紹介します。
極予測TDとは
極予測TDは、レスポンシブ検索広告(RSA)の広告文を自動生成する「広告テキスト自動生成AI」と広告効果を事前に予測する「効果予測AI」を掛け合わせることで、効果的なRSAを制作するプロダクトです。私は画像のようなキーワード(≒検索クエリ)に対応した見出し文と説明文を機械学習モデルにより生成する広告テキスト自動生成を行うチームに配属されました!(なお、画像は本稿のために作成したダミーの例です)
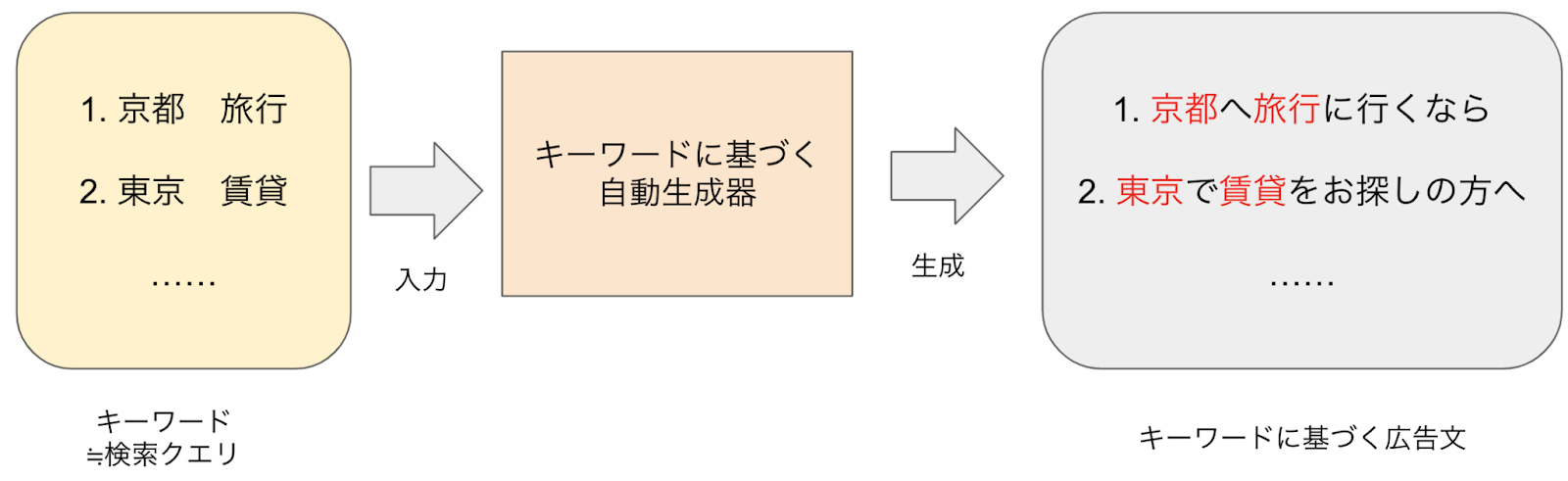
本インターンシップでは、広告テキスト自動生成の見出し文の生成に取り組みました。見出し文には検索されたキーワードが入っている方が広告としての効果が高いとされており、TDチームではキーワードに基づく見出し文の自動生成を行っています。この生成は、以下のようにキーワードと過去に配信済みのキーワードに基づく広告文のペアを事前学習済み言語モデルに学習させることで実現しています。
背景
チームに配属された際、以下のような課題がありました。
- 広告文生成の際にキーワードから推測できない単語が含まれる(以降ハルシネーション)
- 東京 賃貸 → 東京の渋谷区で賃貸をお探しの方へ
- キーワードから推測できない特定の企業名
- 学習データに含まれるキーワードと広告文のペアにも同様の問題が生じている
ここから、機械学習モデルがハルシネーションを生成するように学習している可能性が高く、学習データからハルシネーションを取り除くことでハルシネーションの生成を抑制できるのではないかと考えました。
今回のインターンにおける取り組み
本インターンでは大きく分けて以下の2点のタスクに取り組みました。
- ハルシネーションの検出精度の検証
-
-
- 評価データの構築
- LLMの比較評価
-
- 学習データを改善し、生成物を評価
-
- LLMで学習データをフィルタリング→フィルタリング結果で学習
- 生成結果に関する評価
ハルシネーション検出精度の検証
この章では、フィルタリングを行うLLM(大規模言語モデル)の性能を検証するためのデータ作成と、ハルシネーション検出能力の比較検証について説明します。
評価データ構築
以下の手法でデータを構築しました。
- 学習データから100件を抽出
- 事前にLLMでハルシネーションの有無を判別
- ハルシネーションあり、なしと判定されたケースを各50件抽出しデータの偏りを防止
- アノテータ4人によりアノテーション
- ハルシネーションあり、もしくはハルシネーションなしでアノテーション
- 以降 OK = ハルシネーションなし
- 以降 NG = ハルシネーションあり
- 正解は多数決で決定
- OKとNGが同数の場合は検証データから除外
- ハルシネーションあり、もしくはハルシネーションなしでアノテーション
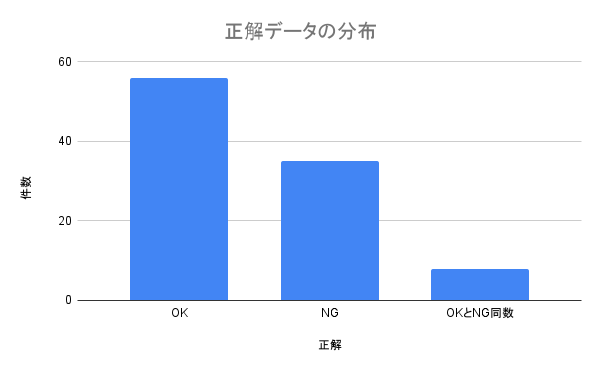
この結果、以下のような分布のデータが得られました。
検出精度におけるLLMの比較
ハルシネーション検出の評価データ作成とLLMの性能検証について、以下のように実施しました。
評価方法として、キーワードとキーワードに基づく広告文のペアに対して、LLMがハルシネーションの有無を判定する方式を採用しました。具体的には、GPT-4oとGPT-4o-miniの2つのモデルを使用し、それぞれの判定結果を人手で作成した正解データと比較して精度を評価しました。
LLMへの指示(プロンプト)では、以下のような評価基準を設定しました:
【NGと判定する場合】
- キーワードから推測できない名詞が追加されている 例:「事務 の 仕事」→「女性歓迎の事務のお仕事」
- キーワードに含まれていない企業名や具体的な事実、数値が含まれている
- 例:「東京 賃貸」→「東京のエアコン付きの賃貸」
【OKと判定する場合】
- キーワードから推測可能な名詞・動詞の追加
- 例:「静岡 アパート」→「静岡 アパート マンション」
- 例:「イラスト スクール」→「イラストを学ぶスクール」
- 商品名から自然に推測できる企業名の追加
- 例:「【固有の製品名】」→「Example社の【固有の製品名】」
- 主観的な表現や一般的な形容詞の追加
- 例:「貸し会議室」→「高級感あふれる貸し会議室」
また、LLMの出力を「OK」または「NG」の二値に限定し、few-shot learningを用いて出力フォーマットの統一と追加例の提示を行うことで、より正確な判定を目指しました。
上記の実験を行った結果、以下のような結果が得られ、GPT-4o-miniが最も精度の高いモデルとなりました。
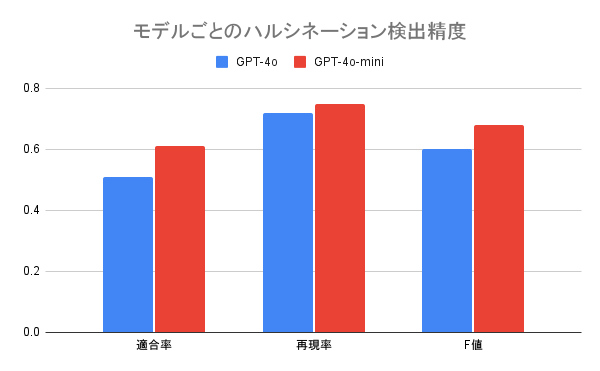
この結果から、本インターンにおいて学習データからのハルシネーションの除去にはGPT-4o-miniの採用を決定しました。
広告文生成の学習データ改善・生成物の評価
この章では、LLMを用いて学習データをフィルタリングする手法について説明します。加えて、フィルタリングされたデータで学習したモデル(提案手法)とフィルタリングされていないデータで学習したモデル(ベースライン)の生成結果を比較し、その結果について説明します。
学習データのフィルタリング
この章では元の手法をベースライン、学習データからハルシネーションを除去したものを提案手法と呼称します。LLMに学習データ(キーワードと広告文のペア)および先ほど検証で使用したOKかNGを判定するプロンプトを入力しました。この結果LLMがOKとしたもののみを学習データとすることで学習データのフィルタリングを実現します。この際、元の学習データが40720件だったのに対し、フィルタリング後の学習データは30230件となりました。
生成品質維持に関する検証
学習データのフィルタリングにより学習データが減少した悪影響を確認するため、生成物の品質がフィルタリングしない場合と比べてどのように変化するのか検証しました。検証のため生成結果が以下の条件を満たす割合を調べました。
- キーワード挿入率(All)
- キーワード内の単語が全て広告文に含まれている割合
- OKな例:熊本 旅行 → 熊本旅行なら
- NGな例:熊本 旅行 → 熊本へ行くなら
- キーワード内の単語が全て広告文に含まれている割合
- キーワード挿入率(Any)
- キーワード内の単語が一つでも広告文に含まれている割合
- OKな例:熊本 旅行 → 熊本旅行なら
- OKな例:熊本 旅行 → 熊本へ行くなら
- キーワード内の単語が一つでも広告文に含まれている割合
- 入稿規定(Regulation)
- Googleの入稿規定を守っている割合
- 文字数や特定の記号の不使用等
- Googleの入稿規定を守っている割合
上記の生成品質に関する評価の結果は以下のようになりました。
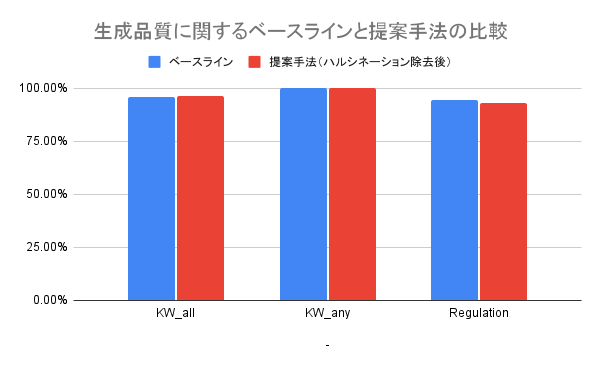
この結果から、学習データからハルシネーションを除去して学習を行っても生成品質は維持されることが示されました。
ハルシネーションの抑制に関する検証
学習データのフィルタリングによってハルシネーションが抑制されるのかの検証も行いました。この検証ではフィルタリングを行ったLLMおよび人手でハルシネーションの有無を以下のように評価しました。
- LLM判定OK率:LLMがハルシネーションでないと判定した割合
- フィルタリングを行なったLLMの意図に沿った生成ができるかどうか
- スコアが高い→さらに精度の高いLLMで除去を行った場合より高い効果が期待できる
- 判定にはGPT-4o-miniを使用
- 人手評価OK率
- 人間の目で見てハルシネーションが抑制されているかどうか
- スコアが高い → 現状の学習データのフィルタリングで高い効果が期待できる
- ベースライン / 学習データについてフィルタリングを行なった場合の生成結果を比較
- 100件のキーワードを抽出
- 各キーワードについてベースラインと提案手法それぞれの生成結果を確認
- 生成結果に関してOK / NG をアノテーション
- 4人のアノテーション結果から多数決で最終結果を算出
上記のLLMおよび人手での評価の結果は以下のようになりました。
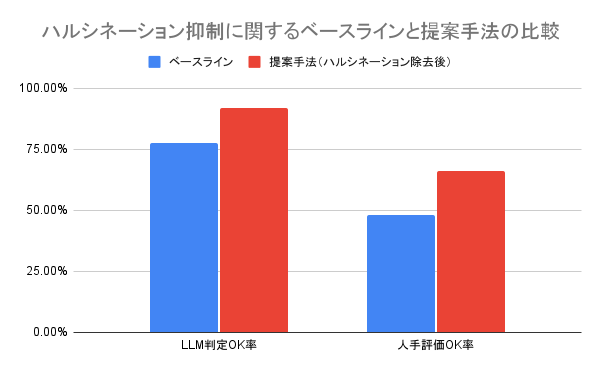
上記の結果からフィルタリングを行ったLLMの意図に従うこと、提案手法で実際にハルシネーションが抑制されることが示されました。実際に生成結果を確認すると、フィルタリング後のデータで学習したモデルの生成結果から特定の企業名が出現するケースやキーワードにない具体的な数字が出現するケースが減少していることが確認できました。しかし、提案手法にはベースラインと同様に与えられたキーワードを拡大解釈するケースも見られます。たとえば、「【特定の製品】 0円」というキーワードが与えられると「【特定の製品】が月額0円」と生成したり、「【アーティスト名】」というキーワードが与えられると「【アーティスト名】のDVDなら」と生成するケースがあります。
Future Work
ハルシネーションの抑制に関する検証におけるアノテーションにおいて以下のような分布が得られました。
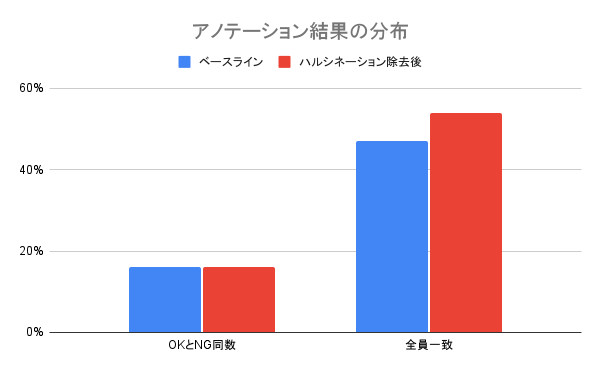
この分布から、OKとNGが同数となっているケースが20%弱、全員の意見が一致している割合も半分程度しかありません。これは現在のハルシネーションに関する定義が主観に依存する部分が大きく、ハルシネーションと感じるかどうかに個人差があるためと考えられます。そこで、ハルシネーションの定義をより細分化、ブラッシュアップしLLMも人間も判断しやすくすることが将来的に必要になると感じました。
まとめ
今回は、極予測TDにおける見出し文生成でのハルシネーション抑制を実装し、検証しました。具体的には、ハルシネーションの検出精度を検証した後、LLMを用いてハルシネーションを含むケースを除去しました。その除去後のデータで機械学習モデルを学習し、複数の評価項目でハルシネーションの生成が抑制されていることを確認しました。
技術的、知識的に至らぬ点も多々あったかと思いますが、トレーナーさんやメンターさんをはじめとしたチームの皆様に感謝を申し上げます。このような貴重な機会をいただき、本当にありがとうございました!