
本記事は、10月29日〜30日にかけて開催した「CyberAgent Developer Conference 2024」において発表した「グローバル展開を見据えたサービスにおける機械翻訳プラクティス」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
神谷 優 (技術政策管轄 Developers Connect室 Manager・Software Engineer)
Developers Connect室マネージャー兼Tech DE&I Lead。2008年新卒入社後、AmebaやスマートフォンDivisionにて複数のサービス立ち上げに携わる。2015年以降3度の育休を挟みつつ、定額制音楽配信サービスAWAではソフトウェアエンジニアとして、子ども向けプログラミング事業のキュレオでは海外開発部門責任者として長くtoC開発に携わる。2024年2月よりDevelopers Connect室マネージャー。2022年Women Techmakers Ambassador就任。2024年Forbes JAPAN「Women In Tech 30」選出。
1.キュレオの海外展開について
グローバル展開を見据えたサービスにおける機械翻訳プラクティスと題しまして、技術政策管轄Developers Connect室の神谷が発表いたします。どうぞよろしくお願いいたします。
まず、私の所属について簡単にお話しします。私は現在、サイバーエージェント本体の技術政策管轄であるDevelopers Connect室に所属し、DevRel(Developer Relations)活動を行う組織のマネージャーを務めております。今回の発表は、前部署で担当していた子会社の株式会社キュレオでの海外開発グループの責任者としての経験をもとに、そこでの取り組みをプラクティスとして集大成し、お話しさせていただくものです。
ここ1年ほどで生成AIの波が到来し、大きな変化が生まれました。その前後で、私たちは2年半にわたりこのプロジェクトに取り組んでいました。本日は、Webサービスの翻訳現場で実際にどのような課題に直面し、それをどのように解決してきたかを、プラクティスの形でお話しできればと思っています。
では、まずキュレオについて、そしてその海外展開の背景についてお話しします。キュレオは、子ども向けのプログラミング学習サービスです。大きく分けて2つのコースを提供しており、1つは小学生を対象にした初級レベルのビジュアルプログラミングコース、もう1つは初級コースを修了した子どもたちを対象にした中級レベルのテキストプログラミングコースです。

このプロダクトは「QUREOプログラミング教室」という形で展開され、日本全国の塾や教室で教材として使用されています。現在、3200教室で展開されており、教室数では国内ナンバーワンのシェアを誇っています。
さて、本題に移りますが、日本で開発をスタートさせたQUREOを、後から英語化したプロジェクトについてお話ししたいと思います。国産のサービスを途中から英語対応させる際には、さまざまなタスクが発生しますので、その内容を簡単にご紹介いたします。

2. 取り組んできた翻訳作業
海外展開を進める上で、開発面でやるべきことは多岐にわたります。アプリケーションレイヤー、インフラ、データベースなど、すべての領域に対応が求められますが、今回はその中でも特に「データの翻訳作業」に焦点を当ててお話ししたいと思います。
今回の翻訳対象となったのは、キュレオの初級コースからです。この初級コースはさらに3つのサブコースに分かれており、「基礎コース」、「応用コース」、「タイピングコース」の順に翻訳を進めました。
翻訳が必要な箇所について具体的にご説明します。まず、最も想像しやすいのは、マスターデータ内のテキスト部分です。
このサービスのメインキャラクターである「アルゴ君」が、ガイドとしてプレイヤーに対話形式で指示を出します。「こうしてね」といったセリフが頻繁に登場し、これらもすべて翻訳する必要があります。また、ビジュアルプログラミングの特性上、コードブロックの中にテキストが含まれているため、その部分も翻訳対象です。
ブロックの名称も重要な要素です。たとえば、日本語では「もし」や「繰り返す」といったブロック名がありますが、これらをすべて英語にラベリングし直さなければなりません。
さらに、左下に示しているように、固有名詞の翻訳にも特別な対応が求められます。オリジナルのキャラクター名、背景名、サウンド名、効果音の名前など、多くの固有名詞が含まれており、これらを意味が通る形で翻訳する必要があります。
次に、画像も多くの翻訳対象を含んでいます。たとえば、操作説明を示すGIFアニメーションや、「正解のブロックはこうなる」という正解例を示す画像があり、これらもすべて翻訳する必要がありました。特に小学生向けの教材という特性上、ガイドの多くが絵や図を使って説明されているため、それらの画像にはすべて日本語のテキストが含まれています。その数は約1700枚に及びます。
また、全体のマスターデータのテキスト量は約40万文字に達しています。画像が1700枚もあるだけでなく、さらに動画やナレーションも翻訳対象に含まれます。
動画は合計で73本あり、これらのナレーションもすべて英語に翻訳する必要がありました。アルゴ君が話すセリフも含め、音声も英語化するため、字幕や吹き替えも必要になります。
これが全体の翻訳対象の概要です。ここまでご説明したように、非常に多岐にわたる翻訳作業を進めるにあたって、私たちはさまざまな工夫を凝らしてきました。この後は、その翻訳の歴史についてご紹介いたします。

最初の取り組みとして、基礎コースの翻訳を2022年1月から9月にかけて実施しました。この基礎コースは最も分量が多く、非常に重要なパートでした。初めの段階では、私たちは外注という方法を選択し、翻訳会社や制作会社、社内チームを総動員して開発に取り組みました。
しかし、外注を利用したことで、大量の依頼指示書の準備が必要となり、複数の外注先と社内のディレクションが同時進行する状況に直面しました。また、納品後には表記の揺れや誤訳といった問題が次々に発覚しました。画面にテキストを入れてみると意味が通じないことが判明するなど、確認作業や修正が想像以上に膨大になったのです。
私自身、こうした複数ラインでのディレクションは初めての経験で、特に大量の指示書作成は手動ではとても対応しきれなかったため、Google Apps Script(GAS)を活用して自動化を行いました。たとえば、日本語の書き起こしを翻訳し、それをナレーター用に整形して読み上げてもらう原稿を生成する作業も、GASを使って効率化しました。
スケジュール管理では、依存関係をNotionのタイムラインビューで可視化し、次々とディレクションを進めていく五月雨式の運用が必要でした。ただ、確認作業にまで気が回らなかった部分もあり、戻ってきた翻訳には多くの不一致が見つかりました。たとえば、キャラクターのアルゴ君が喋る内容がオブジェクト名と異なっていたり、変数名にスペルミスがあったりと、細かなミスが頻発しました。
ここで「Google翻訳やDeepLを使えば良かったのでは?」と思う方もいるかもしれません。実際、検討はしましたが、翻訳対象が非常に「癖のあるコンテンツ」だったため、機械翻訳では対応が難しいと判断しました。たとえば、「物知りダイスンに当たった。まで待ち。」という表現は、キャラクター名「物知りダイスン」と、プログラムの「○○まで待つ」というコードブロックが組み合わさったものです。また、「混ぜたものリスト」のように、リスト名と操作が組み合わさるケースもありました。こうした内容を機械翻訳すると、ひらがなの多用や文脈の不明瞭さが問題となり、意味が通じない場合が多かったのです。
また、チャプター名やサウンド名など、固有名詞が大量に含まれており、これらも機械翻訳では正確に処理できない部分でした。さらに、私がこのプロジェクトを担当した時期は、育休から復帰した直後で技術検証の余裕がなく、途中まで進んでいた外注の方針をそのまま引き継ぐことになりました。
こうしてなんとか基礎コースをリリースすることができました。その過程で得られたスキルは、主に語学力とGAS(Google App Script)を書く技術でした(笑)。確認作業の合間に省力化のためのスクリプトを書き続けるという半年間は、決して健全な運用とは言えないものでした。この経験を経て、私たちは戦略の見直しが必要であると判断しました。

3. 戦略の見直し
プロジェクトの目標としては、もちろんリリースを実現することが大きな目標ですが、それに加えて、安全で確実なリリースの仕組みを確立することも重要なポイントでした。また、私ともう一人のエンジニアが中心となって、制作確認作業を単なる「作業者」として行うのではなく、エンジニアリングの力で解決することを重視しました。モチベーションの維持のためにも、技術的なチャレンジを取り入れることが重要だと考え、戦略を見直しました。
次の目標として取り組んだのが応用コースです。このコースは基礎コースよりも若干量が少ないものの、より高度なプログラムに挑戦したい生徒向けに設計されています。設計図のような手順書に基づいて、選択肢を選びながらコーディングを進める仕組みになっています。
応用コースでは、いくつかの改善策を取り入れました。まず最初に、**テストケースの追加**です。これにより、データの品質を確保することを目指しました。具体的には、フロントエンドのエンジニアと協力し、テストケースを設計しました。目的は、ビジュアルプログラミングを構成するための「viewinfo」というデータ構造の品質を確保することでした。
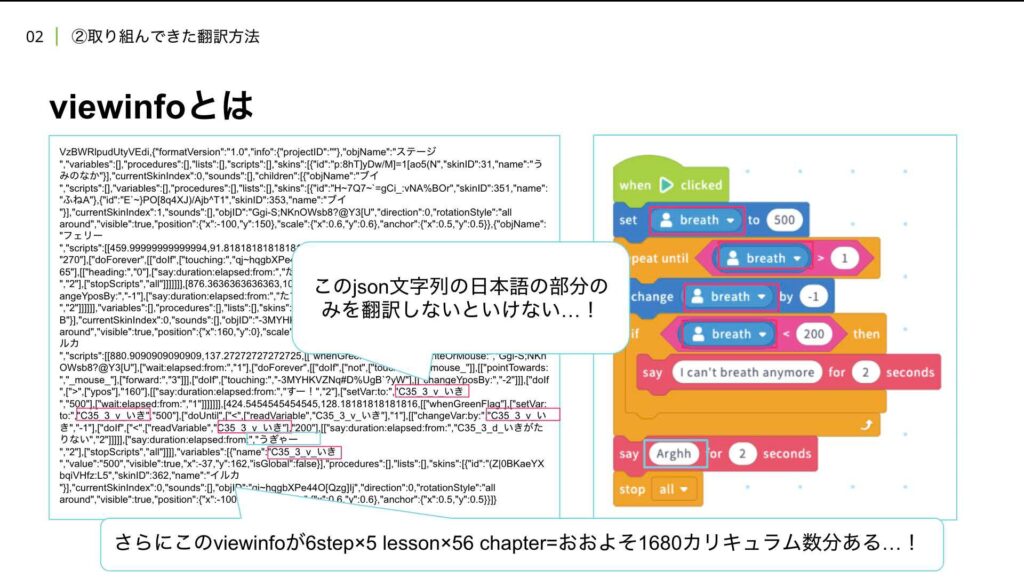
このviewinfoというのは、簡単に言えば、JSONのような構造を持つデータで、ビジュアルプログラムの裏側で使われています。ここに日本語の置換ミスが残っていると、たとえばキャラクターが画面上で日本語を喋り始めたり、誤った文字列が表示されるといった不具合が発生します。さらに、データを再投入する際にミスがあると、パースエラーが発生し、画面が真っ白になってしまうことも実際に起こりました。
viewinfoには、ビジュアルプログラミングの位置情報や画像情報など、多くの要素が含まれています。その中には、オブジェクト名などの固有名詞がオリジナルのまま記載されていることもあり、これらを正しく翻訳する必要があります。しかし、翻訳する必要があるのは、これらの特定の部分のみです。
この作業は、非常に手間がかかるものでした。なぜなら、対象となるカリキュラムが1680にものぼり、各データごとに正確な翻訳が求められるためです。これほどの量を手作業で対応するのは現実的ではないため、私たちはなんとか効率化する方法を模索しました。
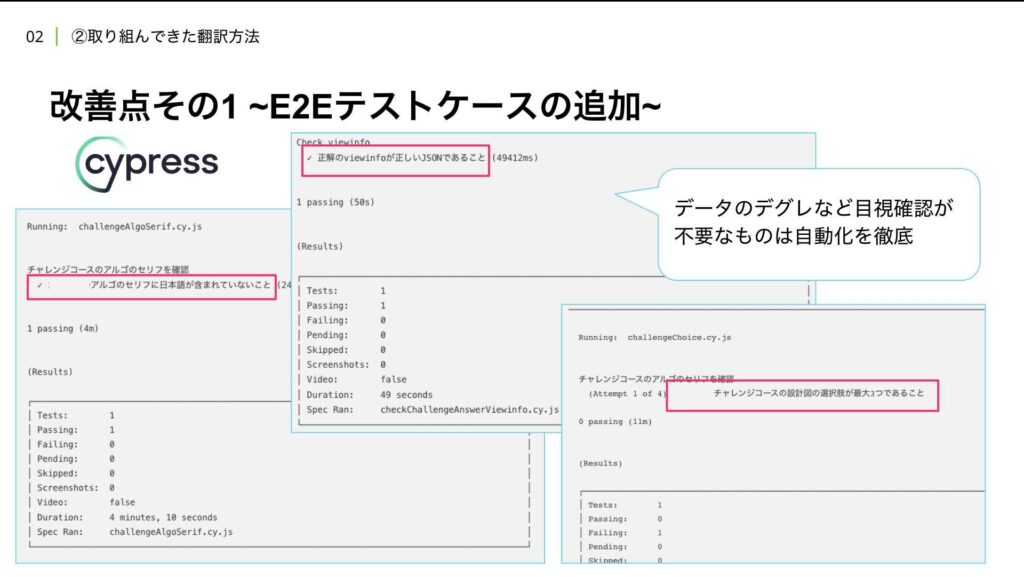
改善点の一つ目として取り組んだのが、Cypressというフロントエンドのテストツールを使った自動化です。データのデグレード(品質低下)や目視確認が不要な部分については、できる限り自動化を徹底しました。具体的には、テキスト内に日本語が含まれていないかどうかをチェックするテストを導入し、コードに変更を加えたらプルリクエストを作成し、そのタイミングで自動的にテストが走るように設定しました。これにより、JSON構造が正しいことを確認するなど、最低限の仕様を担保する体制を整えました。
また、応用コースの選択肢は最大3つまでという仕様があったため、こうした要件もCypressのテストケースに任せて自動でチェックできるようにしました。
さらに、最終確認作業の最適化にも取り組みました。Cypressには画面キャプチャの機能があり、この機能を活用しました。これまでは、翻訳されたデータを一つ一つ画面で確認し、違和感がないかを目視でチェックしていたため、非常に大変でした。いくら裏側の作業を自動化しても、最終的には責任者である私が目を通さずにリリースするわけにはいかないため、教材として成立しているかを確認する作業は不可欠でした。
この手作業を減らすため、Cypressで自動的に画面のキャプチャを取得し、メンバーに画像を格納してもらうフローに切り替えました。こうすることで、効率的に翻訳されたデータの確認が行えるようになりました。手作業が減り、負担が大きく軽減されました。
このように、自動化と効率化を進めることで、プロジェクトを「守りながら攻める」戦略で進行できました。その結果、オンスケジュールでのリリースが実現し、無事故での運用ができました。また、メンバーの技術的な成長も促進され、精神的な消耗が大幅に減ったことも大きな成果です。リソースの縮小も達成できたため、非常に良い結果を得られたと感じています。
次のステップでは、翻訳の作業自体をさらに効率化できないかと考えました。これまでに40万文字に及ぶデータセットを構築してきましたが、これは非常に貴重な資産です。このデータをただ翻訳するだけでなく、AIや機械学習(ML)を活用して有効に使えないかと模索しました。
そのため、次に検討を始めたのが**Google CloudのAutoML Translation**です。これから、その仕組みについてご説明いたします。
4.AutoML Translationやってみよう
この取り組みは2023年前半頃に行いました。AutoML TranslationはGoogle Cloudが提供する自動機械翻訳サービスで、さまざまなAutoML製品群の一つとして位置づけられています。このサービスの目的は、ユーザー自身のデータに基づいて高品質なカスタム機械翻訳モデルを構築することにあります。
この仕組みを見て、とても魅力的だと感じました。特に、一般的な機械翻訳では難しいとされる特定のコンテキストや専門分野における翻訳の精度を向上させられるという点に期待しました。もしこれがうまくいけば、私たちのような専門的な教材翻訳にとって非常に大きな効果が得られるはずだと考え、早速試してみることにしました。
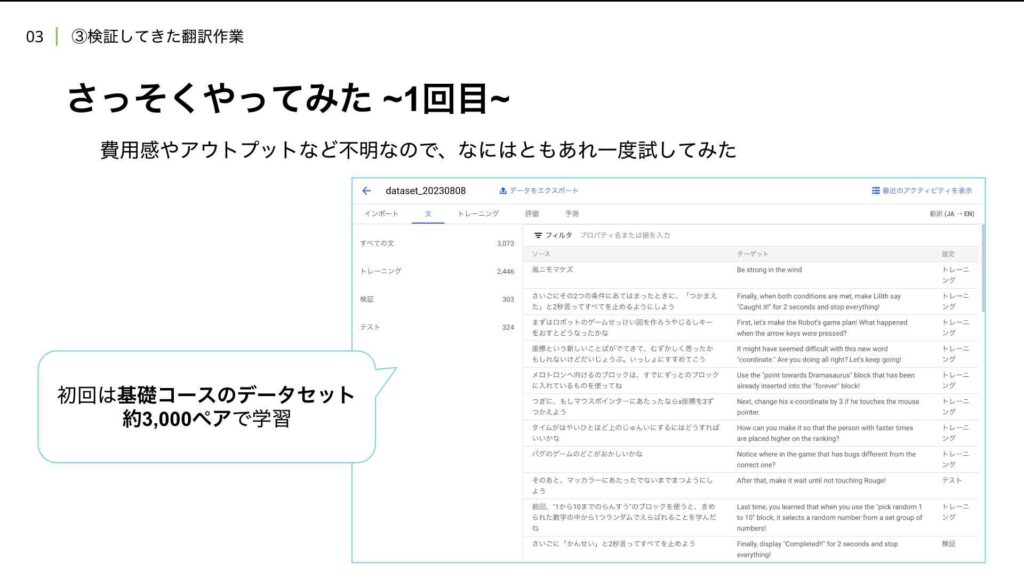
クラウドの機械学習製品に触れるのは初めてだったため、費用感やアウトプットの質、操作方法を把握する目的も含めて、基礎コースのデータセット約3000ペアを用いてテストを行いました。このデータをTSV形式でアップロードし、学習を進めるという手順です。
その結果、二つの大きな成果を得ることができました。一つ目は、翻訳の精度を判定する方法が得られたことです。学習後にBLUEスコアという指標が表示され、このスコアを使って翻訳モデルの性能を数値で評価できるようになりました。
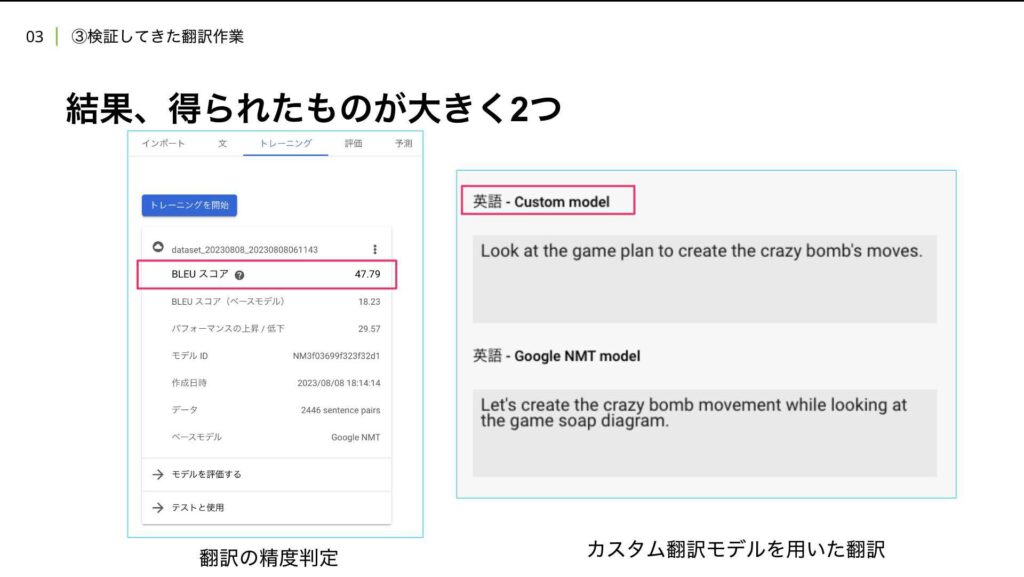
二つ目は、作成したカスタム翻訳モデルを実際に試せたことです。このモデルを使用することで、Googleの標準的なNMT(Neural Machine Translation)モデルとは異なり、私たちのデータに即した翻訳を提供できるようになります。右側の表に示しているように、上段が今回構築した英語のカスタムモデルで、下段がGoogleのNMTモデルです。
カスタムモデルを使うことで、特定の用語や文脈に応じた翻訳を実現でき、より質の高いアウトプットが得られることがわかりました。この検証は、私たちのプロジェクトにとって大きな一歩となりました。
AutoML Translationのカスタムモデルでは、学習したオリジナルの翻訳モデルを用いることで、より正確な翻訳を行うことができます。
例えば、「上のゲーム設計図を見ながらクレイジーボムの動きを作ろう」という日本語テキストを翻訳した際、カスタムモデルでは「設計図」の部分が正確に「game plan」と訳されました。しかし、通常のGoogle翻訳モデルでは「石鹸」と誤って解釈され、「soap」という不自然な翻訳結果が出てしまいました。これはAIが文脈を総合的に判断した結果かもしれませんが、意図したものとは異なる内容になってしまった例です。
また、「スーパーマウスJrやドクドクウオにあたると」といった、固有名詞が多く含まれるテキストでも、カスタムモデルは正確なスペルで返してきましたが、通常のモデルでは誤った表記が見られました。このような固有名詞の正確な翻訳は、カスタムモデルの強みであると実感しました。
この結果を踏まえ、さらに精度向上を目指して再度試すことにしました。最初の試行では、学習にそこそこの費用がかかることが判明したため、社内の機械学習の専門家に相談し、より効果的な学習データの準備を進めました。2回目の試行では、応用コースのデータセットを用い、5000ペアの翻訳データを収集して学習させました。学習データの調達には非常に苦労しましたが、何とか5000ペアを準備することができました。
その結果、BLUEスコアと呼ばれる翻訳精度の指標が著しく向上しました。BLUEスコアは、図に示されているように、時には人間が翻訳したものよりも高品質な翻訳を示すことがあり、非常に良い結果を得ることができました。
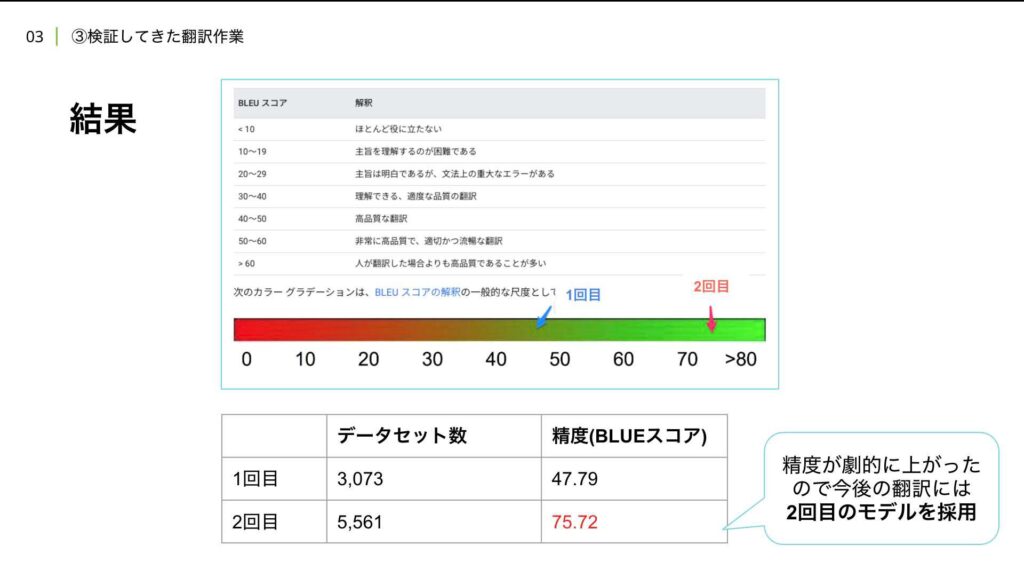
ただ、このスコアは、主に前後のテキストの整合性や、正確なワードの一致を評価するアルゴリズムに基づいています。そのため、人間が「流暢だ」と感じるかどうかとは必ずしもリンクしません。
とはいえ、これまで何の指標もない中で翻訳を進めていたことを考えると、BLUEスコアは非常に頼りになるものになりました。翻訳の品質を客観的に評価する心の支えとなる指標を得たことは大きな成果です。
さらに、この取り組みを進めていた時期は、ちょうどChatGPTが世間で大きな注目を集めていた頃でした。生成AI技術が急速に進化する中で、私たちも多言語対応を視野に入れ、Googleの製品だけでなくPaLM2も試してみることにしました。PaLM2は当時、リリース直後で多言語翻訳において非常に優秀だと評価されていたため、その性能を検証することにしました。
2023年後半になると、生成AIを本格的にプロダクション環境に取り入れたいと考え、翻訳作業にも活用を試みました。しかし、最初はどのように進めれば良いか分からず、いわゆる初期段階のプロンプトエンジニアリングに取り組むことにしました。具体的には、フューショットと呼ばれる形式を使い、目的と例を提示する形で、これまでカスタム翻訳モデル用に作成していたデータセットをプロンプト内に組み込みました。
例えば、「このテキストを英語にしてください」というように具体的な翻訳対象をプロンプトに設定して進めました。この時点で、通常のGoogle翻訳、PaLMなどのLLM(大規模言語モデル)、そしてAutoML Translationのカスタムモデルを比較しました。
Few-shotの効果により、PaLMを使った翻訳は多少カスタム翻訳モデルに近い結果が得られましたが、全体的には無難な訳が多いという印象でした。キュレオの翻訳は、目視で細かく確認した完全な答えなので、他のモデルと比較するとその完成度に差があると感じました。
さらに、AutoML TranslationとLLMを比較するのは難しいと気付きました。両者の仕組みが根本的に異なるためです。AutoML Translationでは、学習済みモデルを用いるために事前の学習コストがかかりますが、その後のAPI利用に関しては大量のリクエストをさばいても無料枠が大きく、コストパフォーマンスが高いです。一方で、GPTのようなLLMのAPI利用料金は高額であることが当時から指摘されていました。
PaLMも含めて検証したところ、翻訳タスクにおいては、特に英語の翻訳精度に大きな違いは見られませんでした。生成AIの進化が目覚ましい一方で、翻訳のようなタスクではコストメリットが最も大きなポイントであることが確認できました。
また、検証の一環として、多言語対応の可能性も探りました。これについてはブログにも詳しく書いていますのでご覧ください。
簡単にお話しすると、プロンプトに関しては、日本語と英語、日本語、英語、フランス語といった具合に、各言語を交互に入れる形式を採用しました。また、別の例として、日本語、英語、日本語、中国語というように、複数の言語で構成するプロンプトも試してみました。

これによって得られたアウトプットをどう評価するかが次の課題でした。当時はまだ明確な評価方法が分からなかったため、検証段階という位置付けで定性評価を行いました。具体的には、フランス語と中国語のネイティブスピーカーに協力をお願いし、彼/彼女らの主観に基づくフィードバックを得ました。
その結果、日本語からフランス語への翻訳については、PaLM2の方がやや優れていると感じられました。一方で、GPTはもう少し具体的な訳を提供し、PaLM2は少し一般的なニュアンスの訳に仕上がっていました。中国語に関しては、GPTが圧倒的に良いとの評価を得ました。特に、文末の「〜だね」というような感情的なニュアンスが含まれていて、友達同士の会話のような自然な訳ができていたとのことです。この評価は評価者の主観が関わるため、評価自体の難しさを実感しました。
このように、生成AIを使った多言語対応は新しい挑戦であり、まだ試行錯誤が必要な部分が多いと感じましたが、将来的な可能性を探る良いきっかけになりました。
そして、ついに2024年に入り、LLM(大規模言語モデル)の進化がさらに加速しています。GPT-4やGemini 1.5 Proなど、より自然な文章生成と高度な情報処理能力を持つモデルが次々と登場しています。私たちが資料を作っている間にも、新しいモデルが出てくるほどのスピード感で進化が進んでいます。
一方で、私の異動という業務上の事情から、このプロジェクトの引き継ぎを進める必要がありました。引き継ぎを進める中で、これまで注力してきた翻訳精度の向上とは別の大きな課題が明らかになってきました。それは、翻訳後にサービスへ組み込む際の最終確認作業です。
これまでも確認作業の煩雑さは認識していましたが、翻訳自体にフォーカスするあまり、その工程をどうにかする必要性に十分向き合っていなかったのです。責任者である自分が目視でチェックするという属人的な作業に頼ってしまっていた部分がありました。引き継ぎの過程で、このような作業体制が業務の効率化を阻んでいると再認識し、どう改善するべきかを考え始めました。
翻訳自体の精度向上だけでなく、翻訳後の確認作業を効率化し、脱属人化を目指す取り組みを進めました。
まず、左側に示しているのがシステムプロンプトの例です。ここでは、「あなたはプロの翻訳家です。子ども向けのプログラムサービスの翻訳を担当し、日本以外の子どもたちが自然に学べるよう、翻訳をチェックしてください」といった内容を指示します。また、将来展開予定の国や地域に合わせてプロンプトを調整します。
次に、ユーザープロンプトのポイントとしては、翻訳結果の評価を依頼することが主な指示になります。具体的には、評価対象のデータとして、これまで学習データセットとして使用してきた日英の翻訳例をコピペし、プロンプトに入力する形式です。
評価の観点も具体的に指示し、自然な訳か、誤訳があるか、固有名詞や文法の誤りがないか、といった要素を検証するよう求めます。また、評価結果は、各観点ごとに「◯」「×」「△」で表現するよう指定しました。
このプロンプト設計は、これまで自分自身で行っていた目視チェックの作業をAIに任せる試みです。特に固有名詞や表記揺れといったチェック項目を網羅的に指示することで、従来のテストケースを置き換えることが目的です。
その結果、GPT-4oを使うと、翻訳結果の表が返されます。各翻訳に対して自然な訳かどうかのコメントも入り、固有名詞の誤訳や表記揺れについての指摘が行われます。また、総評も含まれており、脱属人化の観点から見て非常に有用な結果が得られました。このプロンプトをソリューションとして提供できる段階に至りました。
さらに、このプロセスに至るまで、他にもさまざまな検証を行いました。例えば、複数のカスタム翻訳モデルを比較・評価し、各モデルの良し悪しを判断する試みも行いました。PDFを用いて評価結果を突っ込み、AIに分析させることで、どのモデルが適切か判断することも可能でした。この方法が非常に有効だと感じています。
最後に、今後の翻訳作業の展望について、私の個人的な見解をお話しします。

カスタム翻訳モデルの現状と今後についてお話しします。カスタム翻訳モデルの作成に必要な教師データについては、先ほどお話しした通り3000や5000といったデータセットを用意しましたが、実際には数万単位の正確なデータが必要になります。こうした学習データを準備するコストが非常に高いというのが現実です。
このような高品質なデータを整える作業は、機械学習に関わる人たちにとって共通の悩みであり、データの調達そのものが非常に大変な課題です。今後の展望としては、RAG(Retrieval-Augmented Generation)のように、事前にデータを大量に学習させるのではなく、リアルタイムで指示を与える形でLLMを活用することで、カスタム翻訳を実現する技術が進展することが期待されます。
また、今回触れきれませんでしたが、画像や動画の翻訳についても課題が残っています。これも非常に大変な作業ですが、最近はマルチモーダルAIの進化によって、画像や動画に埋め込まれたテキストの翻訳ができるようになりつつあります。例えば、画像をAIに入力して、適切な翻訳を含んだ動画で返してもらうといった未来も、そう遠くないかもしれません。
さらに、先ほどお話ししたCypressを使った自動キャプチャによる最終確認作業についても、今後は生成AIにそのチェックを任せることができるようになる可能性があると考えています。これにより、確認作業も脱属人化が進むでしょう。
加えて、業務用のLLMアプリケーションを構築することで、企業全体の運用効率がさらに高まると考えています。特に、LLMを翻訳の判断者(LLM as a Judge)として使うことで、人間の手を介さず高精度な翻訳の評価が可能になります。
また、翻訳モデルとしてのLLMの普及についても、専門家からの話を聞いています。実際にDeepLも最近、翻訳に使用するモデルを独自のLLMに切り替えたと報告されています。こうした動きは今後ますます加速していくでしょう。
最後に、今日の発表をまとめます。DeepLのような高性能な翻訳APIを使用する場合でも、用語集の登録や辞書プラグインが必要になります。これにより、表記揺れの問題を防ぎ、翻訳の一貫性を保てるようになります。また、生成AIを活用した確認作業の重要性も再認識しました。
ただし、トータルコストを考えると、外注する場合のコストやその後の運用コストも含め、バランスの取れた運用が求められます。これらがうまく機能すれば、英語以外の言語の翻訳でも同様に効果を発揮できると考えています。
このように、生成AIをうまく活用することで、翻訳と確認作業のコストを大幅に削減できる可能性が見えてきました。これからの翻訳業務において、さらなる効率化が期待されます。
本日はご視聴いただき、ありがとうございました。
