
本記事は、10月29日〜30日にかけて開催した「CyberAgent Developer Conference 2024」において発表された「生成AIの強みと弱みを理解して、生成AIがもたらすパワーをプロダクトの価値へ繋げるために実践したこと」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
黒澤 拓磨 (CA ADVANCE Vietnam Co., Ltd Hanoi DevCenter バックエンドエンジニア)
2021年度新卒入社。現在はハノイ開発拠点の立ち上げと、生成AIを活用したサイスケ(Cyber AI Scheduler)※の開発責任者を担当。
※収録時点ではAI Schedulerでしたが、社外向けリリース記事を出したタイミングでサービス名が変更されました。
生成AIの強みと弱みを理解して、生成AIがもたらすパワーをプロダクトの価値でつなげるために実践したことと題しましてHanoi DevCenterの黒澤が発表いたします。
皆さん、シン・チャオ
Hanoi DevCenter所属の黒澤と申します。今年で4年目になるバックエンドエンジニアで現在はベトナムで開発拠点の立ち上げと生成AIを活用したサイスケの開発をメインミッションとして働いています。余談になりますが、もし皆さんがベトナムに来る機会があればぜひ、ハロン湾に行ってみてください。絶景スポットがたくさんあってきっと素敵な思い出ができると思います。
早速ですが、この発表のゴールをお伝えさせてください。これから生成AIを活用したプロダクト開発に携わる方がサイスケの開発を追体験することで意思決定のヒントとなるノウハウやプラクティスを持ち帰ってもらうことを目標に、本日お話ししようと思っています。
具体的には、ここまでの開発において下した決断をやったことベースで振り返って、皆さんのプロダクト開発にも役立ちそうな学びを抽出してお伝えできたらいいなと考えています。

おそらく、たびたび登場してくる サイスケって何?という方が大半だと思います。まずは本日皆さんに開発を追体験していただくサイスケrについて紹介いたします。
1. サイスケの紹介
昨年の10月2日に、サイバーエージェント全社として生成AIを徹底活用していくためのアイデアコンテストが開催されました。賞金総額が1000万円を超えるイベントということもあり、社内から約2200件のアイデアが生まれました。

このコンテストで見事グランプリを受賞したアイデアが サイスケです。生成AIを予定調整に活用することで、めんどくさい予定調整を即時化し、優先されるべき予定がきちんと優先されている状態を作ることがこのアイデアの肝になります。
生成AI徹底活用コンテストを経て新設された、AIオペレーション室管轄としてサイスケの開発プロジェクトは始動いたしました。ちょうどそのタイミングで、新しい連携先を探していた私たちHanoi DevCenterが、開発メンバーとして参画することになりました。
今年の4月から開発が本格的にスタートし、約3ヶ月後の6月に社内向けにリリースしました。リリース後も引き続き、Ver.2.0のリリースに向けて絶賛開発中です。この約半年間の開発経験をいくつかのポイントに絞って振り返りながら、皆さんと一緒に生成AIを活用したプロダクト開発におけるベストプラクティスを考察していけたら嬉しいです。
皆さんにサイスケの開発を 追体験していただくために、時系列の古い順にお話していきたいと思います。
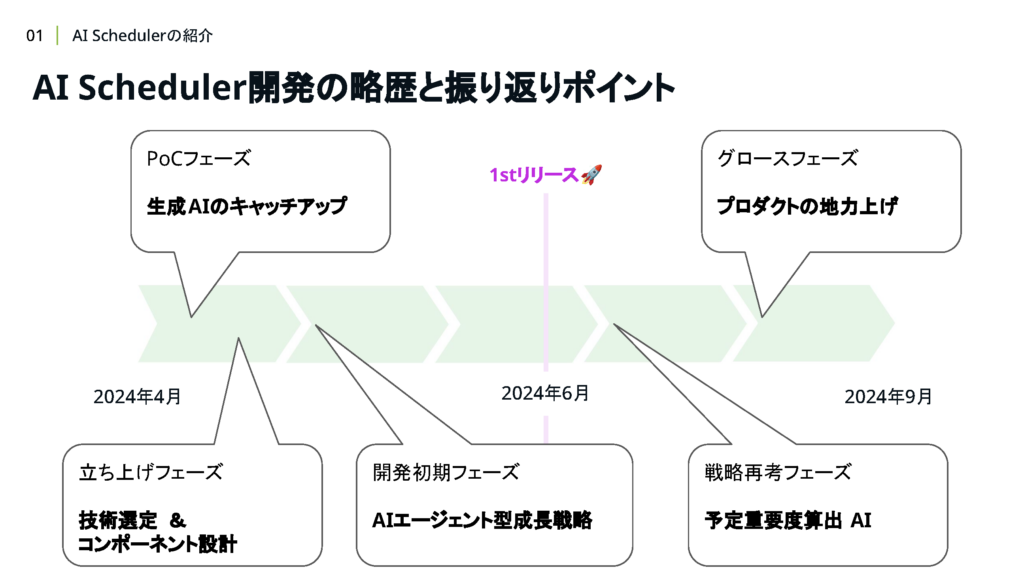
2. PoCフェーズ:生成AIのキャッチアップ
まずはプロジェクトが始まってすぐの POCフェーズです。前提知識としてチーム構成について触れさせてください。サイスケの開発チームは ビジネスメンバー1名、開発メンバー3名の少人数チームでスタートしています。また、開発メンバーは全員バックエンドエンジニアであり、生成AIに関する技術は未経験の状態でした。
そこでプロジェクトの初期フェーズとしては、生成AI技術へのキャッチアップと、自分たちの作ろうとしているプロダクトに生成AIをどのように使うのか明確にすることを目標にして進めることにしました。
次のスライドから、このフェーズで実際にやったことをピックアップして、うまくいったことや、こうすればもっとよかったことを考察していきます。まずはじめに、社内のリスキリング施策にチームメンバー全員で参加したことを取り上げます。この発表ではリスキリング施策について詳しく触れませんが気になる方は、友松さんの発表も併せてご視聴ください。
リスキリング施策参加により、チームメンバー全員の知識レベルが同じタイミングで一定以上のレベルに底上げすることに成功しました。

プロジェクトでの実践とリスキリングでの学びのサイクルが回せたことで、学んだことを実践ですぐに活用できることに加えて、チームメンバー全員で共通言語を使って会話できるようになったことが開発を進める上で、すごくプラスに働いたと感じています。
リスキリング施策により、基礎から着実に力をつけていけたと思う一方で、今思えばある程度知識のOverviewを作成して、自分たちのプロダクトで実現したいユースケースに焦点を当てて学習を進めた方が効率は良かったのではないかと考えています。
知識のOverviewとは具体的にどういうものかというと、まずは「生成AIとは?」といったざっくりとした外観をつかんだ上で、実際に世の中にある生成AIをベースにした プロダクトの事例を集めて分類します。
その事例の中から、自分たちのプロダクトに当てはめたときに、どの事例が近いかを判断するイメージです。
近しい事例が見つかりさえすれば、その事例が裏側でどんな技術を用いて開発されているのかを調べることで、学ぶべき技術の優先順位付けができると思います。
サイスケのケースでいうと、AIがユーザーの入力(自然言語)を解釈して自律的に必要な情報を集めたり予定調整をしたりといった明確な役割を持った上で振る舞ったりしてほしいというユースケースが、Agentという概念にすごくマッチしていました。
Agentを実現するための技術として、LangChainのAgentsや MicrosoftのAutoGenなどがあります。それらの技術を実際に使いながらコンセプトなどを学ぶことで、プロダクト開発に直結する技術のキャッチアップができたのではないかと考えています。
とはいえ、全体像が見えた上でこのように考えられるだけという話があるのも事実です。(リスキリング施策を通じて)体系だった学習をしたことで、基礎知識をしっかり身につけることができたと感じているので、あくまで参考程度に考えていただけたら嬉しいです。
続いてやったことの2つ目はStreamlitを用いたプレイグラウンド環境の整備です。Streamlitを使うことで、LLMアプリケーションで一般的なチャットでのUIを簡単にWeb上で実現できました。Streamlitの採用に至った理由でもあるのですが、当初からPoC環境は捨てられることを前提として作成しました。
捨てるコードであることをチーム内で共有することにより、PoCフェーズにおいて大切な「サクッと試してみてから考える」という心理的安全性を作れたのではないかと考えています。一方で今考えると、PoCフェーズでは生成AIへのキャッチアップと概念検証を混同して考えてしまったために、どんな状態になったら次のフェーズに進めるのか?という線引きが曖昧な状態で進んでしまったと反省しています。
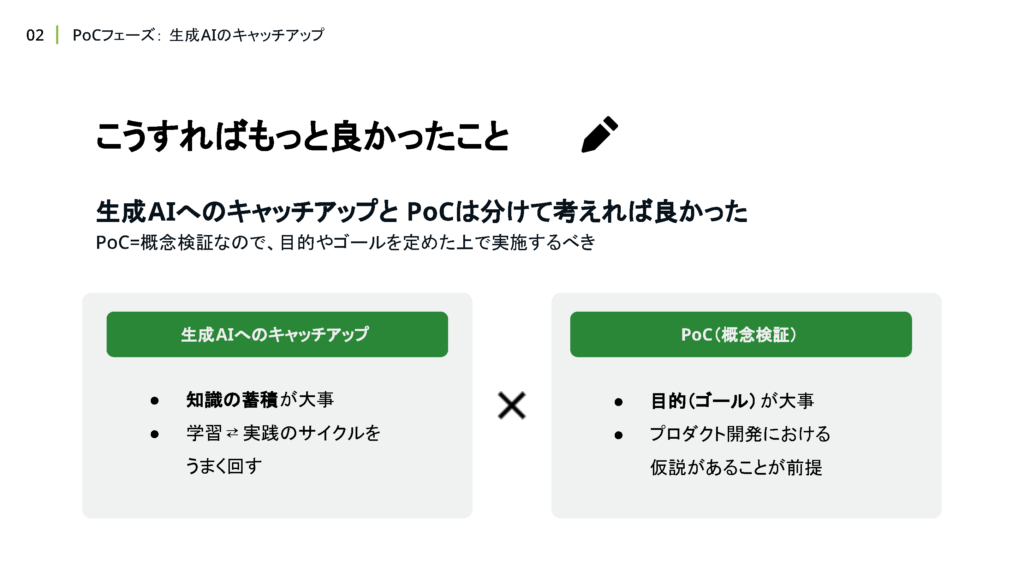
PoCの目的が明確でないと、いつまでもダラダラ開発が続けられてしまうので気をつけましょう。
最後にGitHub Codespacesを採用した話を取り上げます。
GitHub Codespacesを採用することでチームで統一された開発環境を簡単に共有することができます。また、ポートフォワード機能を活用したことでプルリクエスト単位で成果物の動作確認をする仕組みを簡単に構築することができました。
PoCの結果や新しい知識をシェアする手段としてすごく効率のいい仕組みだと考えます。ここまでで、PoCフェーズの開発を振り返って、PoCのゴールラインをきっちり定めておくことの重要性を学ぶことができました。
また、生成AIを最速でキャッチアップしてプロダクトに反映させるための自分なりのおすすめプラクティスも紹介しました。

3. 立ち上げフェーズ:技術選定&コンポーネント設計
続いてプロダクトの立ち上げフェーズを振り返っていきましょう。立ち上げフェーズで取り上げるトピックは、技術選定とコンポーネント設計です。まずはじめに、技術選定をする際に影響を与えた当時の背景を共有させてください。
開発メンバー全員、Goの開発経験が長く、できるだけGoを使いたいという考えがありました。そのため、LLM関連の技術も Goで開発を進めようと当初は検討しましたが、調査する中でLLM関連の技術は圧倒的に Pythonコミュニティの成長速度が速いということが分かりました。
チーム内で議論を重ねた結果、LangChainを採用することに決定しました。チームメンバーが新しい技術に対して前向きであったことと、リスキリング施策でメンバー全員が学んでいる技術であったことが主な選定理由です。
結果として、LLMアプリケーションにおける最新のベストプラクティスを実践できる状態が作れたので、LangChainに乗っかる決断をしてよかったなと感じています。
生成AIのようなまだ発展途上の技術を扱う場合は、現時点でのメンバーの技術スタックよりも、コミュニティの盛り上がりや、成長速度を優先して意思決定しておくことの方が、技術の成長に自分たちのプロダクトも追従していける土台が出来上がるので、良いのではないかと個人的には考えます。

一方で、私たちのチームでは特に、 Python と Go の言語仕様や思想の違いに戸惑うことが多かったのも事実です。プロジェクトのリスク許容度が重要であり、メンバーのマインドセットや皆さんの置かれている状況によっても重視にすべき点は変わるはずです。
ですが、生成AIという発展中の技術を活用するからこそ、少し勇気を持って普段とは違った視点での技術選定をしてみるのはいかがでしょうか。技術選定のトピックで、Azure OpenAIサービスの採用についても触れておこうと思います。
社内での活用事例があったことや、リスキリング施策でAzure環境が自由に使えたことなどの理由で、Azure OpenAI Serviceを選定しました。LangChainの選定理由ほどしっかり検討や議論をしたわけではありません。
その理由としては、LLMの成長スピードが非常に速く、現時点での最適解が見つかったとしても、近い将来で新しいモデルや技術が登場して最適解ではなくなる可能性が高いと予想したからです。技術検証や比較に労力をかけるのではなく、LLMの成長スピードに対応するために柔軟な技術選定ができる体制を作っておくことの方が大切だと判断しました。
その判断自体は振り返って正解だったと思う反面、柔軟な技術選定をするための基盤作りは しっかりしておくべきだったと反省しています。
当時はこの機能があること自体は分かっていなかったのですが、LangSmithのPairwise Evaluationを使うことで、LLMの違いによる生成結果の比較が簡単にできます。
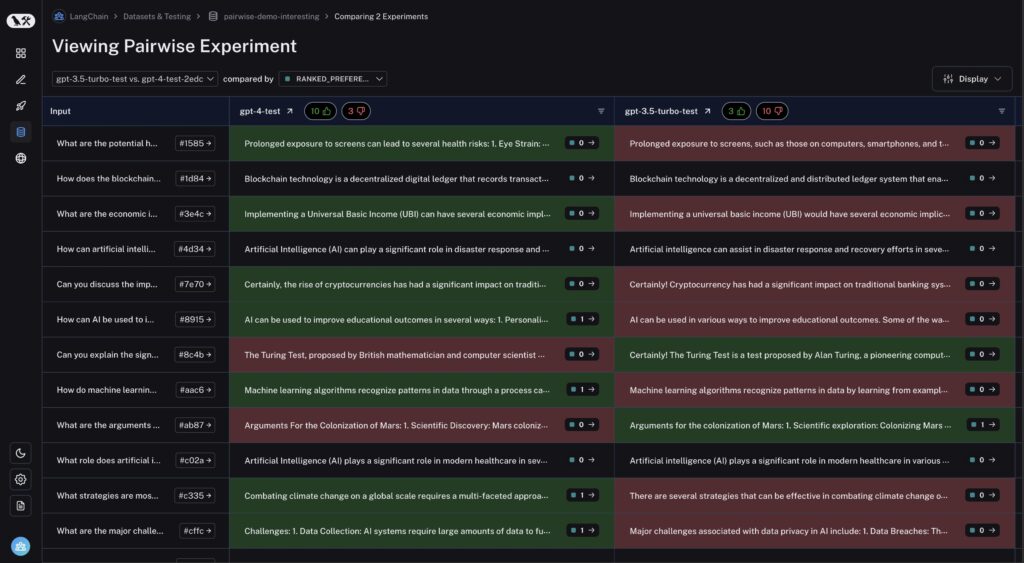
実際、この仕組みを整えていなかったことで、 GPT-4からGPT-4oへの移行時にアプリケーションの挙動がコントロール不能になり、闇雲にプロンプトチューニングして何とかするという苦い経験もしています。
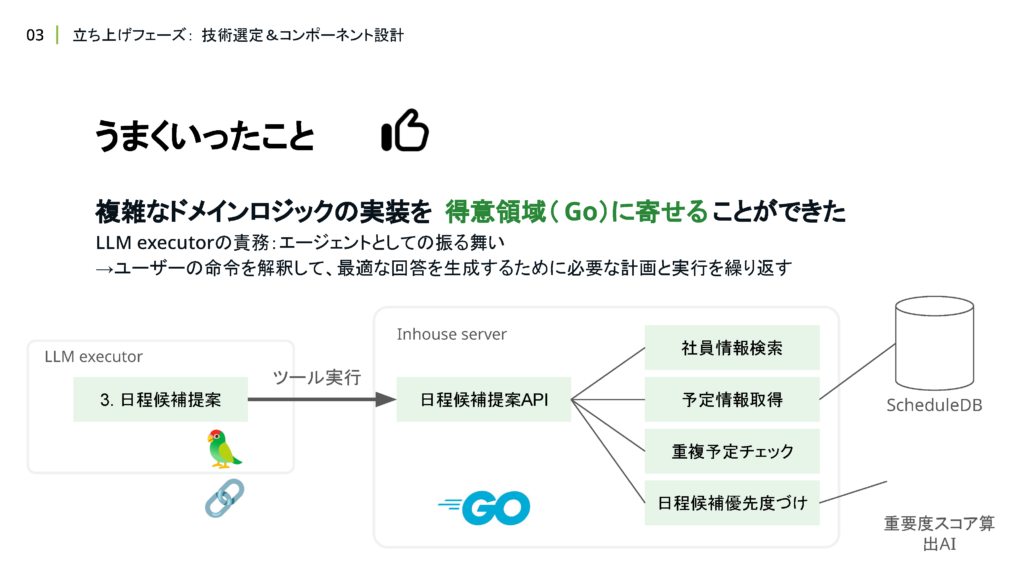
次に、コンポーネント設計において、LLM実行コンポーネントを切り分ける構成にした話をします。
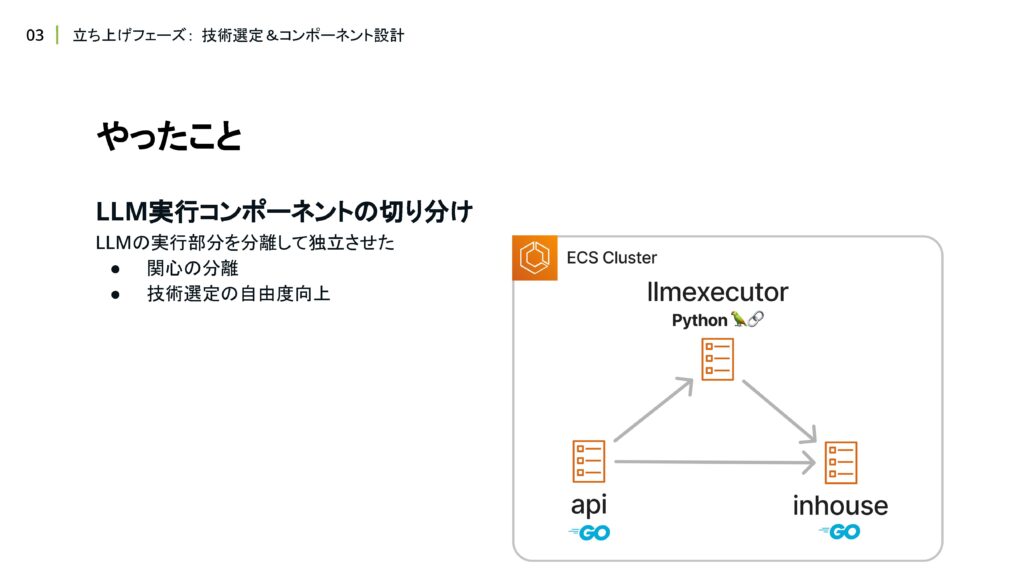
先ほどLangChainを採用するお話をしましたが、アプリケーションすべてを Pythonで書くのは避ける方法を考えました。理由としては、Pythonに精通したメンバーがいない状態ではあまりにもリスクが高いのと、チームメンバーの得意領域を活かせない問題が発生することが主な理由です。
そこでアプリケーションを責務ごとに分割し、LLMを実行する部分だけ Pythonを採用する構成にしました。LLM実行部分を切り出して、与える責務を明確化したことで、Agentとしての振る舞いのみを表現するシンプルなロジックに抽象化することができました。
予定情報の取得や、社員情報の検索、重複予定のチェックといった複雑なドメインロジックはAgentに与えるツールの内部に隠蔽したことで、Agentとして「ユーザーからの入力をハンドリングし、最適な回答を生成する」という単純なロジックの構築に集中させることができました。
LLMに提供するツールを切り出したことで、メンバーの得意領域であるGoを用いて複雑なドメインロジックの実装ができたのも良かったポイントです。
立ち上げフェーズでの技術選定とコンポーネント設計を経て、ソフトウェア開発で重要とされている不確実性の高いものに対して柔軟な変化ができる仕組みを作っておくことが、生成AIを活用したプロダクトにおいても 重要であることが分かりました。
4. 開発初期フェーズ:AIエージェント型成長戦略
次は開発初期フェーズに立てたAIエージェント型成長戦略について振り返ります。開発初期フェーズの段階では、すでにメンバー全員が生成AI徹底リスキリングを終えて、LangChainを扱えるようになっていました。
LangChainでできることをベースに、チーム内で議論した結果、予定調整に特化したAgentとして実装するのが良いのではないかという結論になりました。(前述の通り)
Agentを作るにしても、予定調整の業務フローを理解していないと、どんなAgentを構築すればいいかわからないと考えた私たちは、まずは、既存の業務フローを社員へのヒアリングを通して可視化しました。その上で、生成AIが介入することによって省略できるフローを見つけるなどの最適化を行うことで、サイスケとして実現したいAgentの振る舞いをフローチャート形式で可視化することに成功しました。
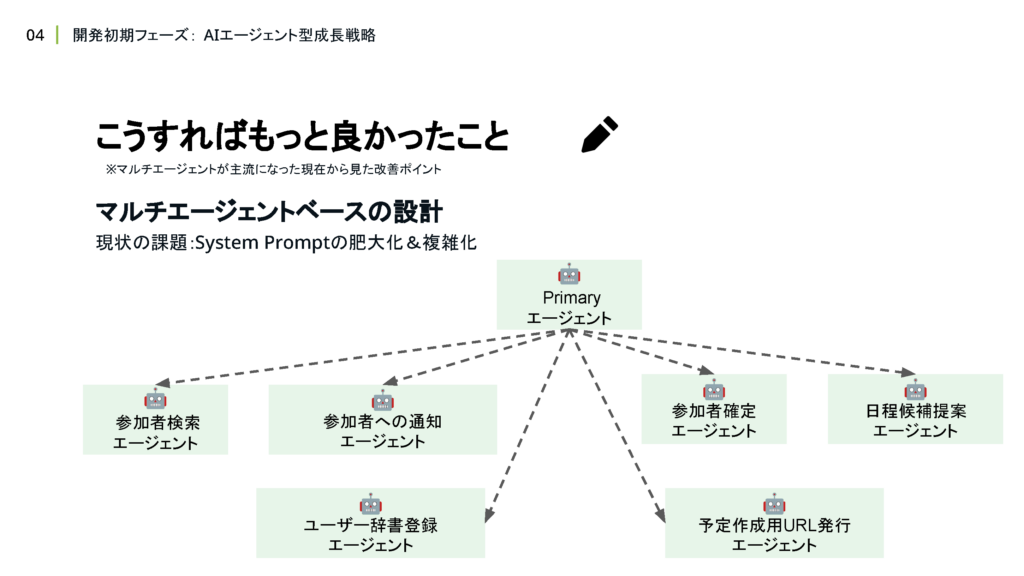
定義したサイスケにおける実現したい業務フローを、SystemPromptとして文章で表現する際に、ステップ形式でAgentとしての振る舞いを表現しました。
各ステップで表現されるべきドメインロジックはツール内部に隠蔽することで、Agentの役割としては、「ユーザーからの入力をもとにステップを推論すること」と、「ステップの実現に必要なツールを呼び出すこと」という、かなり抽象的でシンプルな責務のみに限定させるような設計にしました。
AIエージェントとして成長させる戦略を取る上で、はじめに業務フローの可視化とステップ化を行ったのは 成功したポイントだと考えています。Agentに与えるプロンプトをステップ形式にすることで、LLMの持つ”自然言語や文脈を理解して、次にとるべき行動を推論する力”を 最大限活用できるようになりました。
はじめにビジネスメンバーとすり合わせた業務フローをそのまま自然言語でプロンプトでも表現することで、認識齟齬が起きない状態が作れたというのも すごく大きな利点だと感じています。これはあくまでMulti-Agentが主流になった 現在から振り返った場合の改善ポイントですが、Multi-Agent型の成長戦略を取っていくとさらに良いのかなと考えています。
というのも、現状の課題としてシステムプロンプトが肥大化してメンテナンスがしづらくなってきているという課題があります。
Multi-Agentとして、各ステップに特化したAgentを用意してオーケストレーションするような設計にすれば、各ステップが複雑化したり、ステップの数が増えたりした場合でも、メンテナンス性を下げずに開発が続けられるようになるのではないかと考えています。
AIエージェント型の成長戦略を取ったことで、業務フローのステップ化とAgentの組み合わせの相性がいいことや、生成AIを活用した新時代のアプリケーションであっても、ドメイン知識を理解したり、可視化するスキルは重要であることを学ぶことができました。
これから生成AIを活用したプロダクト開発を始めるという方は、ぜひMulti-Agentとして成長させる戦略を立ててみることをお勧めします。
5. 戦略再考フェーズ:予定重要度算出AI
次はリリースを終え、次のマイルストーンを考えるフェーズで、構想を設計に落とし込んだ、予定重要度算出AIについてお話しします。もともとサイスケの掲げる目標の一つに「社内における需要度の高い予定の総量を増やす」という目標がありました。
リリース時点ではあえてスコープから外していた領域でしたが、次のマイルストーンでしっかり視野に入れて開発を進めていく方針になりました。当初は、生成AIのファインチューニングさえできれば、それなりに精度の高い計算ができると考えていました。
また、PoCフェーズで予定の重要度算出をLLMにやらせてみたところ、ルールを定義して教えてあげることで、それなりに望ましい回答が生成できていたので特に問題はないだろうとPoC時点では考えていました。
早速開発に向けてスタートしたいところでしたが、念のためAI Lab所属の機械学習エンジニアの方にアイデアを当てさせていただく機会をいただくことにしました。
相談した結果、LLMはアルゴリズムのような処理が苦手であることや、そもそもどういう予定が重要であるか自体もAIが考えられるようになったら、よりユニークな機能として提供できるのではないかというアドバイスをいただきました。
スペシャリストの方に直接アドバイスがいただける サイバーエージェントならではの環境に感謝しつつ、いただいたアドバイスを無駄にしないように、チームに持ち帰ってすぐ方針を改めました。
この時に相談に乗ってくださったAI Labの方とそのまま共同開発できる話にもなったので本当に相談してよかったなと思っています。
AI Labの方からのアドバイスを受けて予定重要度算出AIは、LLMではなく独自AIとして開発する方針に決定しました。
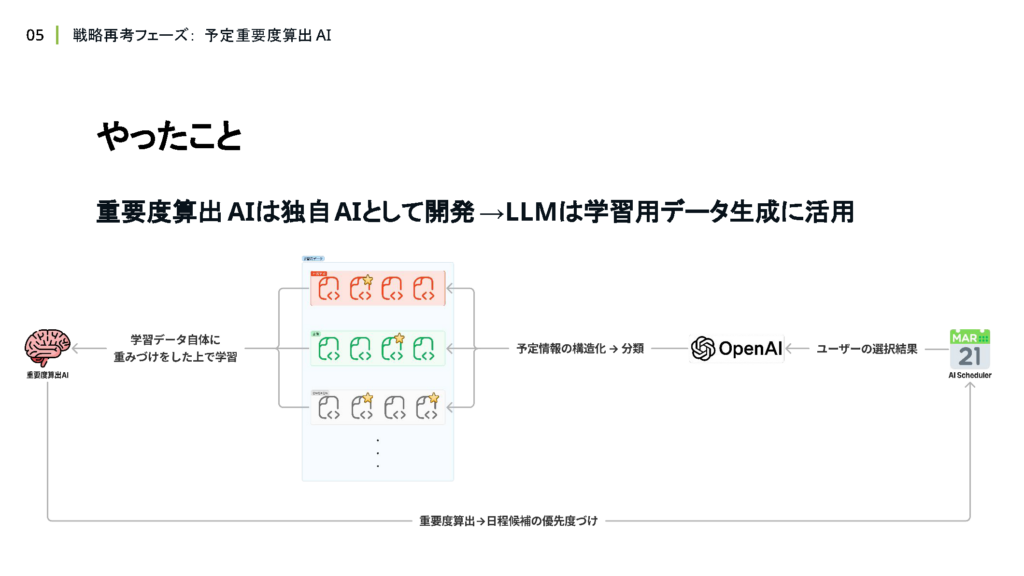
そして、LLMの活用方法として、学習用データの生成時に予定情報の構造化や、分類といった 前処理に使うという意思決定をしました。
生成AIを学習用データの生成に活用する設計にすることで、生成AIの強みである自然言語の処理能力を活用し、一貫性が保証できないユーザーによる入力データが構造化できるようになります。構造化した上で、事前にデータの分類やラベリングのような 前処理も行うことで学習時のノイズを軽減し、より精度の高い学習が可能になると考えています。
また、予定重要度算出AIを機能として独立させ、外部ツール化することにより、LLMのファインチューニングを行うことよりも、他の機能に影響を与えず、独立して成長させていけるようになったことも大きなメリットだと感じています。
LLMのファインチューニングでやろうとしていた場合、予定需要度算出AIに特化したAgentとしての振る舞いに最適化されてしまい、サイスケ全体としての挙動に 変化が生まれる可能性があります。サイスケにおいては、ファーストリリース時点では予定重要度算出AIに着手しない方針であったため、学習用データの蓄積方法やデータ形式について しっかり準備できていない状態になっていました。
機械学習やファインチューニングにおいて、学習用データの量はAIの精度を高める上で非常に重要になります。ファーストリリース時点から学習用データ蓄積の仕組みが整っていれば、今頃大量のデータが集まっていたことを考えると すごくもったいないなと感じています。
一旦、設計や方針が固まっていない場合であっても、学習用データとして使えそうなユーザーの行動ログなどは、Rawデータでもいいので保存しておくといいのではないかなと考えます。予定重要度算出AIの設計を通してファインチューニングに抱いていた幻想を捨て去ることができました。

汎用的に対応できるAIモデルとして開発されているLLMをファインチューニングするということは、ある専門領域や分野に特化させていくということを念頭に置きつつ、自分たちのプロダクトのユースケースに照らし合わせたときに、本当に採用すべきかどうかを判断するべきかなと個人的には考えます。
6. グロースフェーズ:プロダクト品質の向上
最後に、直近1ヶ月くらいのタイミングから、現在も取り組んでいるプロダクト品質の向上についてお話しします。
もともとプロダクト品質の向上のために取り組んでいたことが、全くなかったかというとそんなこともなく、ユーザーからのフィードバックを集めるための機能をリリースしたりDatadogによるメトリクスモニタリングの仕組みを構築したり、LangSmithでLLMのログやトレースを可視化したりしていました。
しかし、リリースからしばらく経ったタイミングから、急にユーザーからの不具合報告が増えるという事態が発生してしまいました。LangSmithでログを詳しく調べてみた結果、大半がLLMのハルシネーションや適切にツールを呼び出せないことが原因の、想定外挙動が発生していることがわかりました。
原因がわかったところで、当時 LLMのハルシネーションは、一定の確率で起こる仕方のないものという意識が強く、プロンプトチューニングでなんとか精度を向上させるしか方法がないと思い込んでしまっていました。
たとえプロンプトチューニングをしたとしても、その変更で実際にどれくらい回答精度が良くなったのかを測定できていなかったために、”もう一度不具合報告が上がってくるかどうか”を判断基準に持つことくらいしかできない状況でした。
そのようなオブザーバビリティの低い状態では心理的安全性がなく、できる限りLLMの精度に影響が出そうな部分は触らないようにするという雰囲気がチーム内に生まれてしまっていました。そのような状況を改善するために、LLMの回答精度を評価できる仕組みを作ろうと考えました。
ちょうどそれくらいのタイミングで、LangChainからLLMのテストに関するガイドラインがアナウンスされたので、そちらを参考にしながら評価基盤の設計を進めることにしました。

この発表では時間がなくこのガイドの詳しい説明は省略しますが、生成AIを活用したプロダクトを開発中の方にとっては必読の内容となっているのでぜひダウンロードして読んでみてください。
LangChainのガイドを参考にして、まずはLLMの評価をどのタイミングで、どんな評価がしたいのか、モチベーションの整理をしてみました。サイスケが抱える直近の課題感を鑑みると、本番リリース前のタイミングで リグレッションに気づいたり、プロンプトチューニングによりどれくらい精度が上がったのかチェックしたりといった、心理的安全性を高めるための評価が一番モチベーションとして高いことが分かりました。
さらに、本番稼働中のサービスがきちんと精度高く回答できているかのリアルタイムでモニタリングまでできていれば、自分たちだけで不具合に気づける仕組みができるのではないかと考えました。モチベーションを整理した上でこれから評価するためにもまずは現状を把握することがとても大切だと考えたため、まずはLLMの回答精度を可視化するところから始めようと考えました。あまり詳細の実装については時間がなくてお話ができませんが、LangSmithのどういった機能を用いて 評価基盤を構築しているのかを説明します。
まずはPromptsという機能を使ってSystemPromptのバージョン管理を行いました。LangSmithのPromptsを使うことでGitHubのようにSystemPromptのバージョン管理を実現でき、前のバージョンと最新のバージョンで どれくらい回答精度が向上したのか把握することができるようになりました。
次に紹介するのがDatasetとEvaluationの機能です。ざっくりと外観だけ説明すると、模範回答となるデータセットを蓄積し、それらを用いて、実際のLLMの回答結果と照らし合わせることで、回答精度の評価ができるという機能になります。LangChainが提供している いくつかの評価指標に加えて独自の評価指標を定義して評価することも可能となっています。
LLM評価基盤を設計・構築したことにより、開発と評価のサイクルを回せるようになったことが 大きな成果かなと考えています。開発とLLMの評価をセットで行う開発スタイルを私たちのチームではDevOpsをもじってDevEvalと名付けることにしました。(※現在ではLLMOpsという言葉が主流なようです)
LLMを基盤として活用するアプリケーションを構築する 昨今のアプリケーション開発において、LLMの回答精度を継続的に向上させていく取り組みは非常に重要なプラクティスだと考えます。現在、さらなるLLMの回答精度向上を目指して、Dynamic few-shot examplesというLangSmithの新機能の導入を検討しています。
この機能を使うことで、LLMがユーザーの入力を解釈した上で似たユースケースのデータセットを自ら見つけて、few-shot exampleとして利用してくれるようになります。こういった機能の登場により、新しいLLMの登場を待たずとも、LLMの回答精度を向上させられる仕組みを作っていけるのはすごく楽しいなと個人的には感じています。
LLMをベースとしたアプリケーションが スタンダードになっていく昨今においてはLLMの回答精度がこれからのアプリケーション開発における重要な指標になることは間違いないかなと確信しています。
7. まとめ
最後にまとめです。サイスケの開発を 追体験していかがでしたでしょうか。少しでも、皆さんがLLMを活用したアプリケーションの開発に携わる際のヒントになるような情報が ご提供できていたらすごく嬉しいです。
ご視聴いただきましてありがとうございました。
