
はじめに
はじめまして、慶應義塾大学の政策・メディア研究科(SFC)修士1年の内田克です。私は、10月CA Tech JOB(実践就業型インターンシップ)に参加しました。インターンでは、DPUにて、ベクトルデータベースの検証に取り組みました。このブログでは、インターンで取り組んだことについて紹介します。
参加動機
私は26年に卒業を予定しており、インターンを通して開発経験を積みたいということが、インターンを探し始めたきっかけでした。その中で、多くのユーザを抱えるプロダクトとサービスを提供しており、それを支えているトップクラスの技術力を有しているサイバーエージェントは、もちろん選択肢に入ってきました。
学部2年の頃から今に至るまで、私はデータベースに関する研究を行ってきました。インフラという括りで募集するインターンが多い中で、データ基盤という細かい粒度で募集がされており、自身の関心とマッチすると考えたため、エントリーしました。インターン内容の擦り合わせを行う面談など、インターンの選考が進んでいく中で、自身の関心を尊重してもらえているとも感じました。実際に、今回のインターンのタスクは、私が研究として取り組んでいるベクトルデータベースに関するものが選定され、インターンと研究に相乗効果が生まれ、大変満足しています。
配属チーム
今回のインターンでは、グループIT推進本部Data Product Unit(DPU)に配属されました。DPUは、各事業部/サービスで蓄積された大量のデータを分析や機械学習などを通じて効率的に活用できるようにするためのシステム基盤の開発・運用を担うチームになっています。DPUはサイバーエージェントグループ全体のデータ活用を促進し、事業成長に貢献しています。
インターンタスク
タスク背景: 社内AIチャット
サイバーエージェントでは、CyChatSDという名前で、社内向けに生成AIチャットサービスを運用しています。
CyChatSDの目的としては、ChatGPTのような一般的なチャットサービスが提供する汎用的なチャットボット、言語翻訳、プログラミング支援に加えて、労務や人事などの社内の制度に関する問い合わせに対応するということがあります。
これを実現しているのは、RAGという技術です。RAGというのは、LLMのテキスト生成に、外部情報の検索を組み合わせることで、回答範囲と回答精度を向上させる技術です。
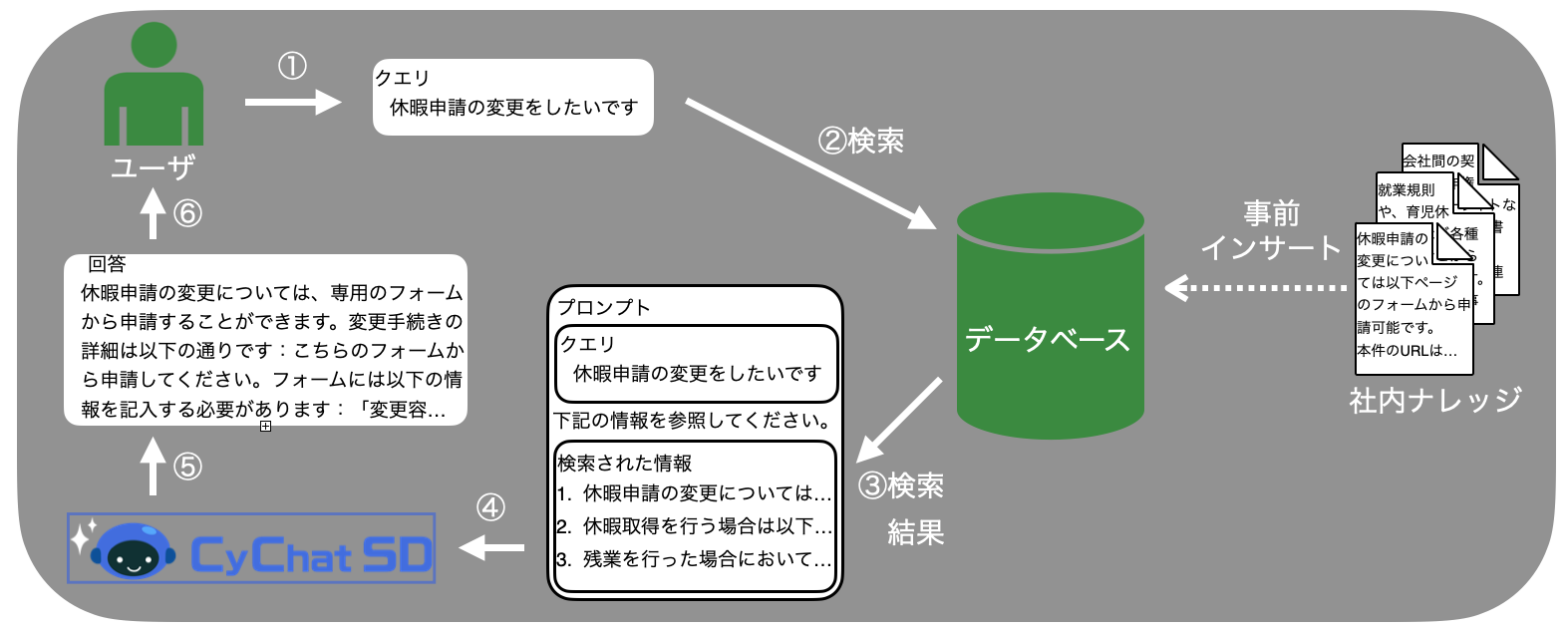
上図: CyChatSDに用いるRAGのイメージ
事前に、社内の制度などに関する情報をデータベースに格納しておきます。ユーザから問い合わせがあると、その問い合わせに関連する社内情報を検索します。ユーザの問い合わせに、検索された社内情報を加えて、LLMが推論を行うことで、LLMの学習データには入っていない社内情報に関する問い合わせに回答が可能になります。
RAGの機能を提供するにあたって、ユーザの問い合わせに対して、いかに関連がある社内ドキュメントを取得するかという、検索が担う役割は大きいです。一般的な方法としては、テキストをベクトルに変換して、検索を行います。テキストそのものでは類似度を計ることは難しいですが、似ているテキスト同士が近いベクトルに変換されるembedding modelを用いることで、ベクトルの距離でテキスト同士が類似しているかということが判断できるようになります。
RAGの機能を提供するにあたって、サイバーエージェントのCyChatSDでもベクトル検索を利用しています。社内ドキュメントをベクトルに変換し、AWS Lambdaのメモリ上で管理しています。ユーザから問い合わせがあると、ベクトル検索ライブラリAnnoyを用いて、ユーザの問い合わせテキストのベクトルに近いベクトルを検索します。検索されたベクトルに紐づく社内ドキュメントのテキストやその他メタ情報を、AWS DynamoDBから取得し、LLMが推論を行うという仕組みになっています。
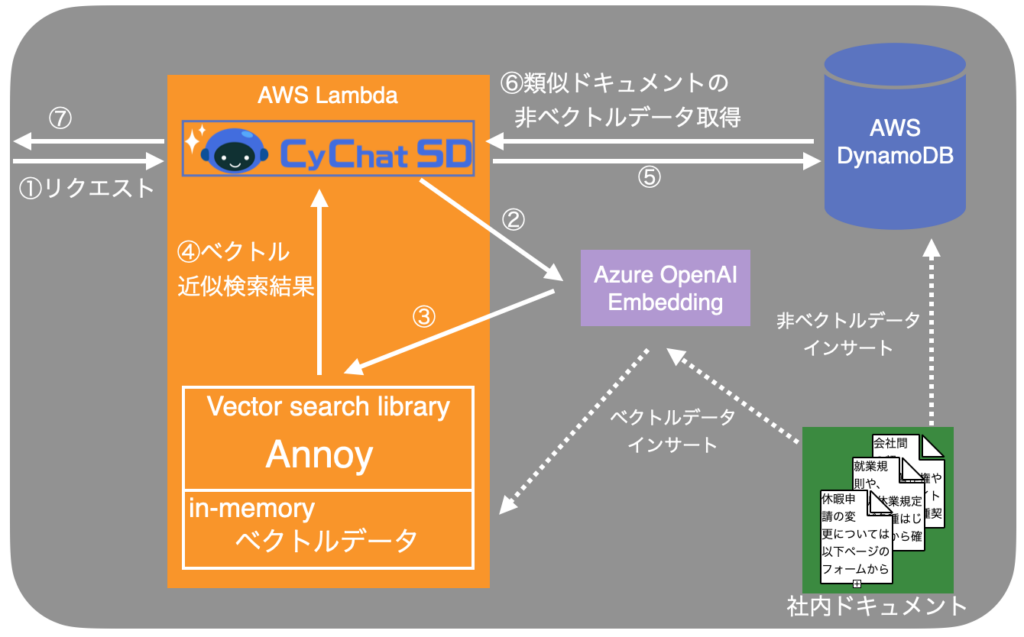 上図: CyChatSDにおけるRAGのアーキテクチャ
上図: CyChatSDにおけるRAGのアーキテクチャ
現行のシステムでは、社内ドキュメントをembeddingしたベクトルデータと、テキスト本体やその他メタ情報は別々に管理されています。このようなアーキテクチャは、いくつかの点において課題があります。
- ベクトル検索と非ベクトルデータ検索が別々に行われており、検索に時間がかかる
- ベクトルデータが永続化されていない
- リカバリ時に、全てのテキストを再度embeddingしてベクトルに変換する必要がある
- メモリの容量によって、扱えるベクトルデータのサイズが制限される
- 作成された日時で検索対象のドキュメントを絞るなどのフィルタリング検索の実装が困難
- 分散データ管理に対応しておらず、データサイズに応じたスケールアウトが不可能
これらの課題を克服するために、ベクトルデータベースへの移行が検討されています。今回のインターンでは、CyChatSDにベクトルデータベースを採用することが可能であるかということを検証しました。
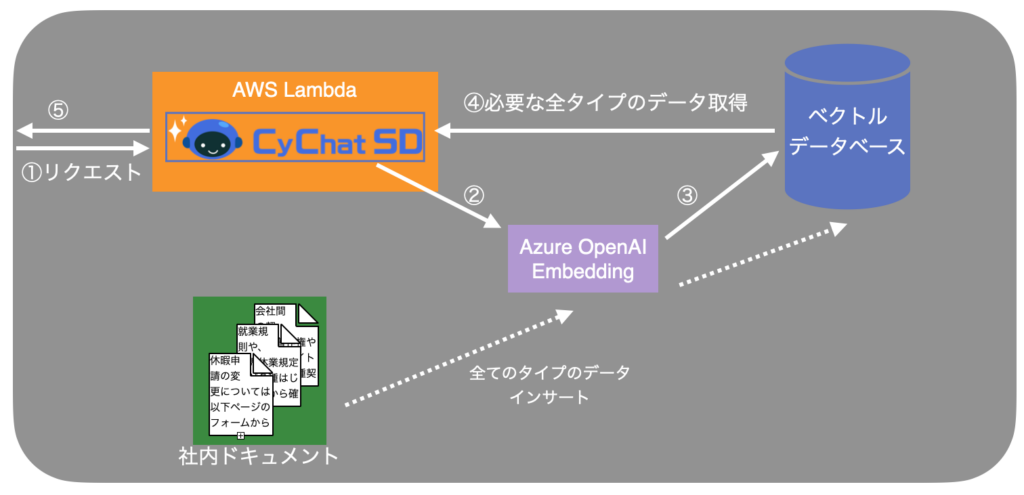
上図: ベクトルデータベース採用時の社内AIチャットにおけるRAGのアーキテクチャ
今回の検証では、SOTAであるMilvusというベクトルデータベースを対象として検証しました。Milvusに移行することで、下記の恩恵を得られることが期待できます。
- プライベートクラウドのマネージドKubernetesサービスAKEを利用可能
- Milvus Operatorを用いてKubernetesクラスタに容易にデプロイが可能
- 先述のAnnoyを用いた現行システムの課題を全て克服
実際の社内ナレッジを用いた検証
検証目的
MilvusをCyChatSDのシステムに採用した場合に、データベース性能と機能の面において問題ないかということを検証しました。
検証方法と検証項目
社内ナレッジに関する実際のデータを用意し、本番運用環境として想定しているAWS Lambdaからデータインサート性能と検索性能、加えてaliasという機能について検証プログラムを実装し、実行しました。
検証結果
データインサート
社内ナレッジに関する実際のデータを用いて、インサート性能の検証を行いました。インサートしたデータは、社内で今まで問い合わせがあった質問と回答の1490件です。
entity_id_field = FieldSchema(name="entity_id", dtype=DataType.INT64, is_primary=True) qid_field = FieldSchema(name="qid", dtype=DataType.ARRAY, max_capacity=5, element_type=DataType.VARCHAR, max_length=50) aid_field = FieldSchema(name="aid", dtype=DataType.ARRAY, max_capacity=5, element_type=DataType.VARCHAR, max_length=50) content_field = FieldSchema(name="content", dtype=DataType.VARCHAR, max_length=50000) vector_field = FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=dim) isquestion_field = FieldSchema(name="isquestion", dtype=DataType.BOOL) filename_field = FieldSchema(name="filename", dtype=DataType.VARCHAR, max_length=100) schema = CollectionSchema(fields=[entity_id_field, qid_field, aid_field, content_field, vector_field, isquestion_field, filename_field], auto_id=False, enable_dynamic_field=False)
定義したschema
質問あるいは回答のテキストデータとベクトルデータに加えて、その他メタ情報を扱っています。
1490件のインサートに、約71.5秒かかるという結果を得ました。実際の運用において、問題のない値でした。
ベクトル検索
先の検証でインサートされた1490件のデータに対して、ベクトル類似度検索を行った際の性能の検証を行いました。
client = MilvusClient( uri=CLUSTER_ENDPOINT, token=TOKEN ) search_params = { "metric_type": "COSINE", "params": {} } results = client.search( collection_name="milvus_test", data=[query_vector], limit=20, output_fields=["qid", "aid", "content", "isquestion","filename"], search_params=search_params, )
pymilvusを用いたベクトル検索実行例
CyChatSDで想定される質問を28個用意し、その質問例をembeddingしてベクトルに変換して、Milvusに対してベクトル検索を実行しました。検索結果が、回答である場合は、その回答に対応する質問をqueryというオペレーション(RDBでいうところのselectであり、テキストや数値などのベクトル以外の情報をフィルタ条件に指定して検索を行う操作)を用いて取得しています。
28個の質問を用いてtop-20検索と必要なqueryオペレーションを実行した場合の実行時間は合計で約2.9秒となりました。1つの質問に対して、約100msで必要な処理が全て完了するという結果を得ました。
aliasに関する検証
CyChatSDの運用においては、検索対象となるコレクション(RDBでいうところのテーブルであり、ユーザがデータを扱う単位)が変更されるということが想定されています。新しいembeddingを採用する場合には、全てのデータをembeddingし直して新たなコレクションを作成し、検索対象を切り替える必要があります。その際に、ダウンタイムが発生することや性能が低下することは望ましくありません。
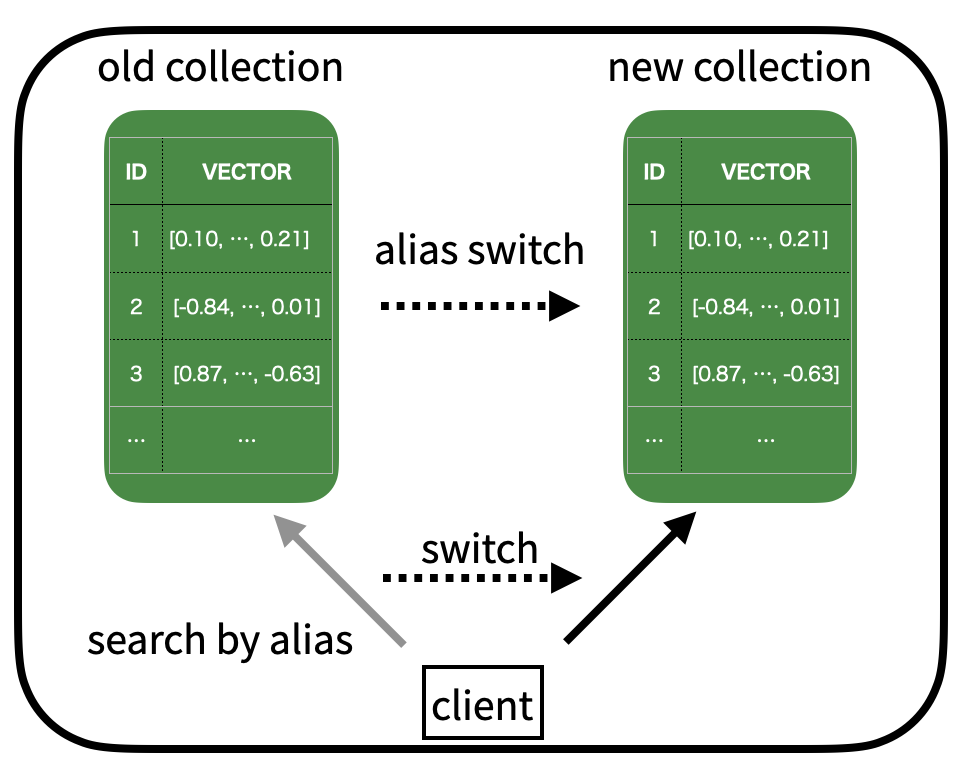
上図: Alias変更による検索対象コレクションの変更
検証方法としては、clientとなるプロセスから断続的にsearchのリクエストをMilvusに対して実行している最中に、別のコネクションを持つ別プロセスからaliasの切り替えを行うという方法を取りました。
結果としては、alias切り替え時に、類似ベクトルの検索を行うsearchリクエストが失敗するといった現象は確認されませんでした。alias切り替えにより、ダウンタイムなく即座に新しいコレクションに対するsearchリクエストが実行される仕様になっていることが確認できました。また、searchリクエストのqpsとlatencyも変化はありませんでした。
ベンチマークツールを用いた検証
検証目的
CyChatSDでは将来的にユーザ数やデータ量の増加が見込まれています。その際に、Milvusが運用に耐えうる性能を有しているか検証しました。加えて、運用するにあたって発生するバージョンアップグレードなどのメンテナンス業務の際の稼働や性能に関する検証も行いました。
検証方法
vectorDBBenchという、Milvusの開発を行っているzillizが提供しているベンチマークツールを用いて検証を行いました。vectorDBBenchでは、様々なワークロードを提供しており、Milvusに限らず多くのベクトルデータベースに対して、インサート性能、インデクシング性能、検索性能の検証が可能になっています。今回の検証では、1536次元の50kベクトルに対する類似ベクトル検索のqpsとlatencyの計測を行いました。
検証項目
CyChatSDの実際の運用を想定した検証として、下記の項目を検証しました。
- 同時接続数の変化による検索検証
- アップグレード時の検索性能
- インデックスを用いた場合の検索性能
検証環境
検証を行ったMivusクラスタは、プライベートクラウドのマネージドKubernetesサービスAKEにデプロイされたものになります。それぞれのコンポーネントのスペックは下記の通りです。
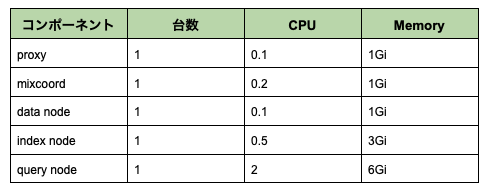
今回の検索性能の検証に関連するコンポーネントとしては、proxyとquery nodeになっており、検証に十分なcpuとmemoryリソースが確保されています。
検証結果
同時接続数に関する検証
CyChatSDでは、将来的にユーザ数の増加を見込んでいます。その際に、検索を行うベクトルデータベースも並列して処理を行う必要があります。その際に、性能の低下が発生することは望ましくありません。
今回の検証では、Milvusに対して、1~50の並列数で検索を行った際のqpsと99パーセンタイルのlatencyを計測しました。
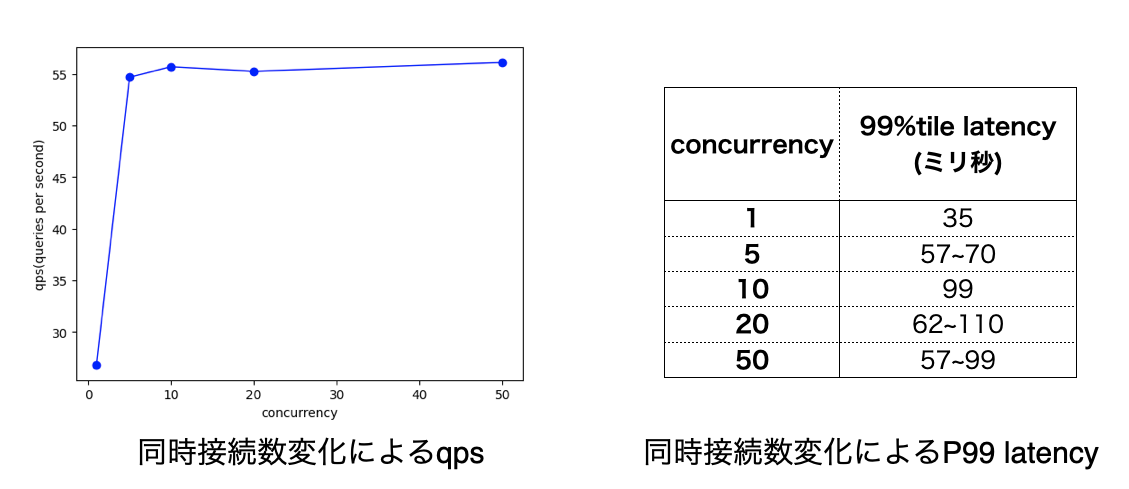
並列数が1の時に比べ、並列数が5以上の時の方がqpsが高くなるという結果を得ました。並列数が増加すると、qpsが悪化することは確認されませんでした。ただ、並列数が増加するにつれて、qpsもスケールすることを期待していましたが、そのような結果にはなりませんでした。cpuとmemoryリソースの使用状況を確認しても、余裕があったため、リソースとは別の要因がボトルネックになっていると考えています。こちらについては、さらなる調査が必要です。
99パーセンタイルlatencyについては、全体を通して少しばらつきがありますが、並列数が増加すると悪化するということは見受けられませんでした。
同時接続数に関する検証を行いましたが、将来的なユーザ数増加に十分対応できる性能をMilvusは提供しているという結論に至りました。
アップグレード時の検証
Milvusを運用するにあたって、将来的にMilvusのアップグレード作業が発生します。その際の稼働と性能を調査しました。
Milvusでは、rolling-upgradeという方式により、アップグレードを行うことが可能です。rolling-upgradeにより、Milvusを構成するコンポーネントを1つ1つ順番に、新しいものに入れ替えることで、ダウンタイムを削減しています。
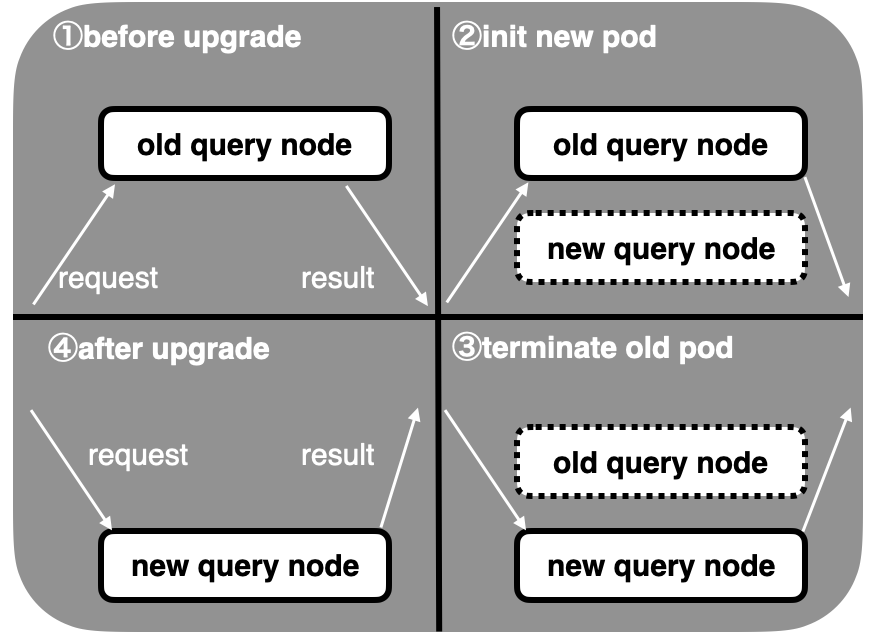
上図: rolling-upgradeにおける、検索を処理するquery nodeの更新時のイメージ
今回の検証では、Milvus 2.4.12からMilvus 2.4.13-hotfixへのアップグレードを行いました。
ベンチマークツールを用いて、アップグレード時の検索性能を計測しました。
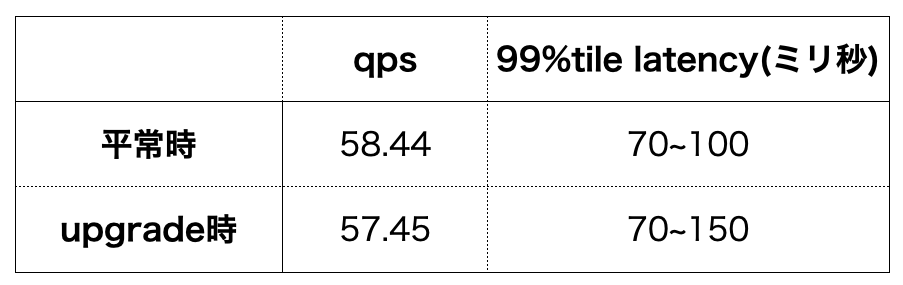
rolling-upgrade中に、ベクトル類似検索が失敗する事象は発生しませんでした。qpsとlatencyの性能についても、平常時に比べて顕著な低下は起こりませんでした。
一方で、queryというオペレーションを実行した際に、失敗している事象が確認されました。query操作は、RDBにおけるselectに相当する、テキストや数値などのベクトル以外の情報をフィルタ条件に指定して検索を行う操作です。
results = collection.query( expr = “entity_id in [2,4,6,8] and isquestion==true" )
pymilvusを用いて、entity_idからデータを取得するquery例
CyChatSDにおいては、ベクトル検索で得た質問から対応する回答をquery検索、回答から対応する質問をqueryで検索することが想定されています。この機能が、アップグレード中は使用できないことが確認できました。
Milvusのアップグレード中に、queryという操作が失敗する瞬間が確認された一方で、類似ベクトル検索はダウンタイムなく、平常時と同等の性能で実行できることが確認できました。
インデックスに関する検証
Milvusにおいては、ベクトル類似検索の際に、インデックスを用いることが可能です。インデックスを用いることで、類似検索の精度(recall)は落ちますが、検索性能を大幅に上昇させることが可能です。CyChatSDの将来的な運用においても、扱うデータ数が増加する場合、インデックスを用いることが検討されています。
今回の検証では、インデックスを用いないブルートフォース検索(FLAT)と量子化ベースのインデックスを用いた検索(IVF-FLAT)とグラフベースのインデックスを用いた検索(HNSW)を比較しました。検証したインデックスの詳細な説明は割愛しますが、どちらも広く使われているベクトル検索インデックスです。
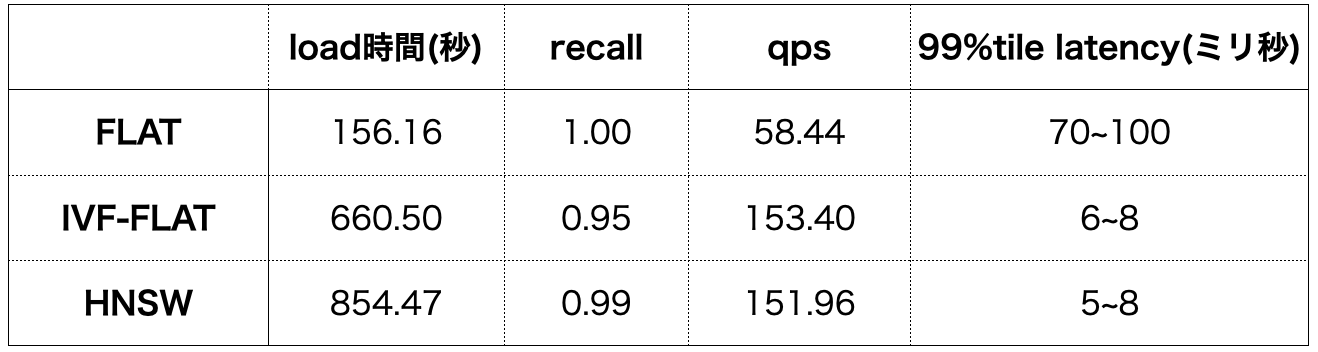
インデックスの作成に関する時間としては、load時間になります。load時間には、データのインサートとインデックス作成、メモリへのロードの時間が含まれます。50kのデータに対してのインデックス作成を含んだload時間は6分~9分という結果を得ました。当然、インデックスの作成を行わないFLATに比べると長い時間になりました。
一方で検索性能については、インデックスを用いないFLATに比べて、qpsは約3倍、latencyは約1/10と大幅な性能向上が見られました。
CyChatSDにおいて、将来的にデータ量が増加した場合は、インデックスの利用も積極的に考えられる結果となりました。
インターン振り返り
インターンのタスク
今回のインターンシップでは、実際の業務で求められるコードの可読性やチーム開発の方法を学び、実務でのスキル向上を目指しました。また、これまで研究してきたベクトルデータベースについて、運用の知見を得ることも重要な目標として掲げました。
インターンを通して、発生した問題について状況を整理し、チームメンバーに共有する力を培えたと感じています。また、参加前と比較すると、検証を行ったMilvusに関しての知識も格段に深まり、特に性能検証においては自分なりに試行錯誤を重ねたことで、多くの学びが得られました。
一方で、ベクトルデータベースの運用については初めての経験だったため、システムの運用環境やインフラ面に関して理解が不十分であることを痛感しました。特に、インフラ経験がなくKubernetesに触れたことがなかったため、初めての分散環境の構築や運用において戸惑う場面も多く、環境を把握するのに時間を要しました。また、コードの理解速度やプロダクトのバグを瞬時に特定する力が不足していると感じ、改善の余地があることを認識しました。
このインターンを通じて、研究だけでは得られない実務的なスキルや視点を得ると同時に、自分のインフラ知識や問題解決能力における課題も明確になりました。今後は、システム運用やインフラに関する知識も強化し、さらなる成長を目指していきたいと考えています。
サイバーエージェントの文化
インターン期間中は、配属されたDPUに限らず、多くの方とランチをご一緒することができました。お話させていただく中で総じて感じたことは、社員の方の多様性です。入社動機、大学時代の研究、入社してから関わったタスク、人生設計など多くの要素において、自身が想像していなかった背景を持っていらっしゃる方がたくさんいました。また、業務に関する話を聞く中で感じたことは、社員の裁量です。業務選定や進め方に至るまで、社員の方が自身の意思を持って、積極的に関わっているという印象を受けました。多様な背景を持っている社員が、裁量を持って業務に携わることで、多くの人を魅了するサイバーエージェントのプロダクトやサービスが創出されているということを肌身で感じる機会でした。