
本記事は、10月29日〜30日にかけて開催した「CyberAgent Developer Conference 2024」において発表した「ABEMA のコンテンツ制作を最適化!生成 AI x クラウド映像編集システム」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
鈴木 寛史 (株式会社 AbemaTV Development Headquarters サーバーサイドエンジニア)
2022 年新卒入社後、株式会社 AbemaTV に配属。2024 年現在に至るまで ABEMA のコンテンツエンジニアリングチームにてしてコンテンツ管理や制作フローの最適化に関する開発に従事。
加藤 諒 (株式会社 AbemaTV Development Headquarters 機械学習エンジニア)
2022年新卒入社。機械学習エンジニアとしてAmebaブログに用いられる機械学習モデルの開発を経て、現在は「ABEMA」で動画解析基盤の開発や生成AIを活用したプロジェクトに従事。
1.ABEMAのコンテンツ制作
鈴木:こんにちは。ABEMAにおけるコンテンツ制作の最適化生成AIとクラウド映像編集システムと題しまして発表させていただきます。
はじめに自己紹介をさせてください。株式会社AbemaTV、コンテンツエンジニアリングにて、主に映像の制作ワークフローの最適化における開発を行っております。鈴木寛史と申します。
加藤:そして同じく株式会社AbemaTVで機械学習エンジニアとして、このセッションで後ほどご紹介するMedia Analyzerの開発をしている加藤亮と申します。
鈴木:ABEMAにおけるコンテンツ制作の概要について簡単にご説明します。次に具体的な事例として、スポーツのハイライト映像やニュースの記事制作において、どのように我々はこれらの政策フローを高速化・効率化したのかについてお話します。そして最後に、今後の展望についても触れていきたいと思っております。
前半は私、鈴木から。後半は加藤の方からお話しさせていただきます。
 ABEMAは登録不要で、いつでもどこからでも好きなタイミングで無料で作品を楽しむことができます。オリジナルのドラマや恋愛番組、アニメ、スポーツなど多彩なジャンルのコンテンツを24時間365日放送しています。ABEMAでは、生配信と好きな時にコンテンツを視聴できるオンデマンド配信の2つの形態で放送しています。これらの配信形態はジャンルごとに異なっておりますが、例えばスポーツやニュースは、生配信でリアルタイムにユーザーに最新情報を届けています。
ABEMAは登録不要で、いつでもどこからでも好きなタイミングで無料で作品を楽しむことができます。オリジナルのドラマや恋愛番組、アニメ、スポーツなど多彩なジャンルのコンテンツを24時間365日放送しています。ABEMAでは、生配信と好きな時にコンテンツを視聴できるオンデマンド配信の2つの形態で放送しています。これらの配信形態はジャンルごとに異なっておりますが、例えばスポーツやニュースは、生配信でリアルタイムにユーザーに最新情報を届けています。
これら2つのジャンルは、共通して時事性が高いという特性を持っており、情報の鮮度がそのままコンテンツの価値に直結しています。そのため、ユーザーにいち早く届ける速報性が非常に重要になってきます。

例えば皆さんも自然災害が発生した場合にその災害情報やスポーツファンであれば、試合の結果や進行状況などをすぐに知りたいと思うのではないでしょうか。
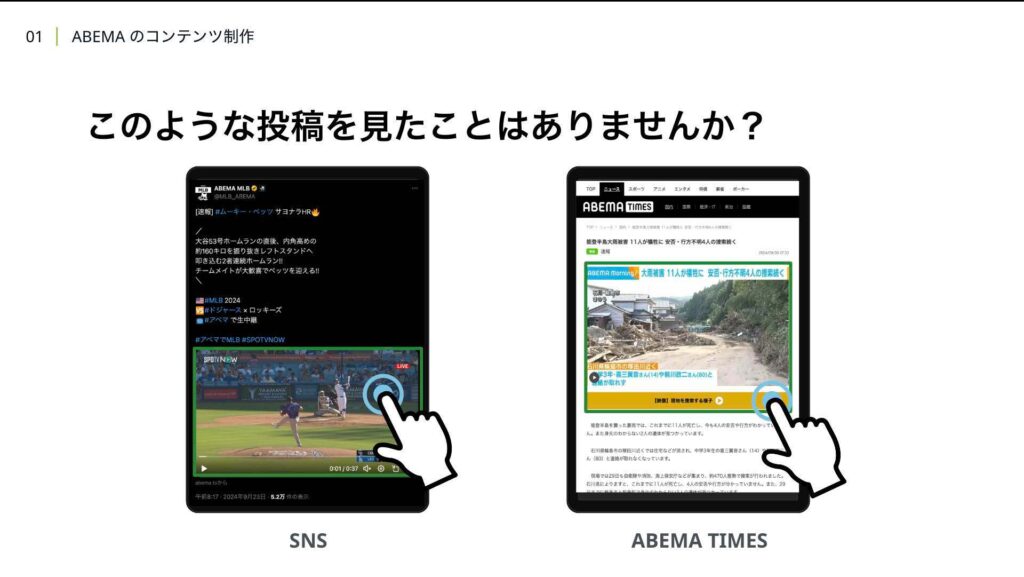
また話は変わるのですが、このような投稿をXなどのSNSで見たことはないでしょうか。投稿内に埋め込まれた映像や画像をクリックするとABEMAの生配信に飛ぶことができます。このように、ABEMAでは、より多くのユーザーに情報を届けるために、SNSや自社メディアを活用しています。例えば、大谷翔平のホームランなどの注目シーンや地震や津波などの自然災害が発生した場合に、そのシーンを切り出して、XやYouTubeなどのSNSや自社メディアのABEMA TIMESに投稿しています。
これにより、普段ABEMAを利用しないユーザーにも情報を届けることができ、投稿を見て興味を持ったユーザーが ABEMAの生配信を視聴するきっかけにもなります。今回私たちはこのSNS向けの映像記事のコンテンツ制作において1秒でも早くユーザーに届けるため公開までのワークフローの高速化に取り組みました。
さて、高速化するにあたって、どこがボトルネックになっているのかを 把握することは重要です。そのためには、現状のワークフローを理解する必要があります。そこで業務フローを可視化してみました。
はじめにスポーツのハイライト制作についてお話します。
2. スポーツハイライト制作の高速化
従来のハイライト制作における全体フローはこのようになっております。
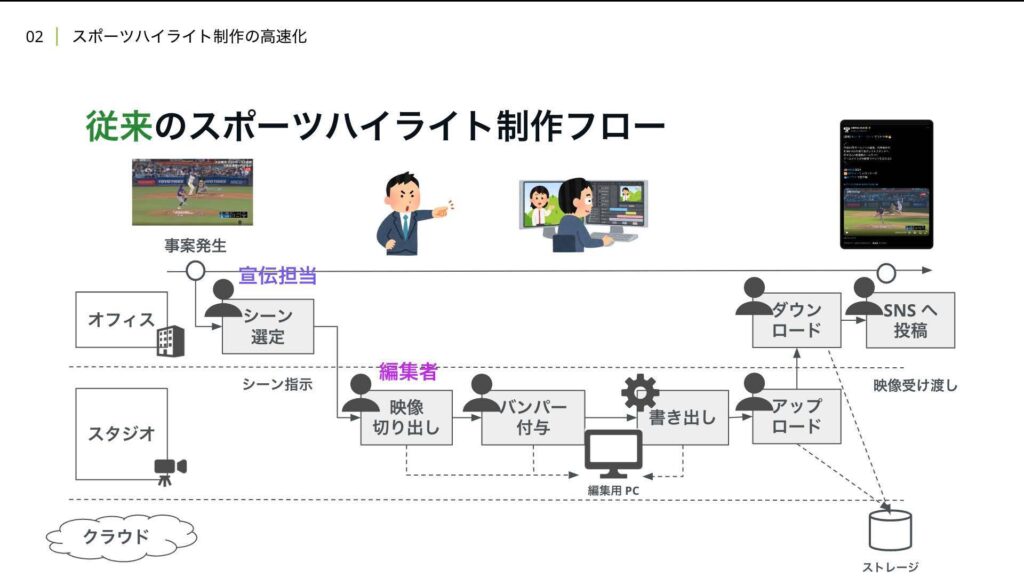
登場人物としては、シーンの選定や切り出し指示を行う宣伝担当と、指示を受けて実際の映像を切り出し編集する編集担当に分かれています。これは映像編集自体が高度な専門知識を要するなどの理由で分業をされています。
まず宣伝担当は生配信を見ながら、事案が発生したタイミングでSNSへ投稿するかどうかを選定します。投稿したいシーンがあった場合は、チャットツール等で使うシーンをスタジオにいる編集者に伝えます。
ここでなぜ編集者はスタジオにいるのかと疑問に思った方もいるかと思いますが、これは現状のアーキテクチャの都合上、ライブ映像をリアルタイムに受け取れるのが スタジオのみであるため、編集はスタジオにて行う必要がありました。そして指示を受けた編集者はABEMAで採用しているAdobe Premiere Proという映像編集ソフトで必要なシーンをカットします。
その後、バンパー広告と呼ばれるブランドの認知向上や宣伝などを目的とした6秒ほどの非常に短い映像を切り出したシーンの前後に入れています。この言葉には馴染みがないかもしれませんが「続きはABEMA」といったフレーズを一度は目にしたことがある方もいるのではないでしょうか。
これで必要な編集は完了し、最後に映像を最終制作物として書き出します。書き出し完了後に映像を宣伝担当に受け渡すためにGoogleドライブなどのクラウドストレージサービスにアップロードします。アップロード後にチャットツールで宣伝担当に映像を納品した旨を伝え、納品連絡を受けた宣伝担当は、 該当映像をダウンロードし、SNSに投稿します。
さて、このワークフローにおける速報性を 落としている課題は何でしょうか。
1つ目は、人による作業の遅延です。
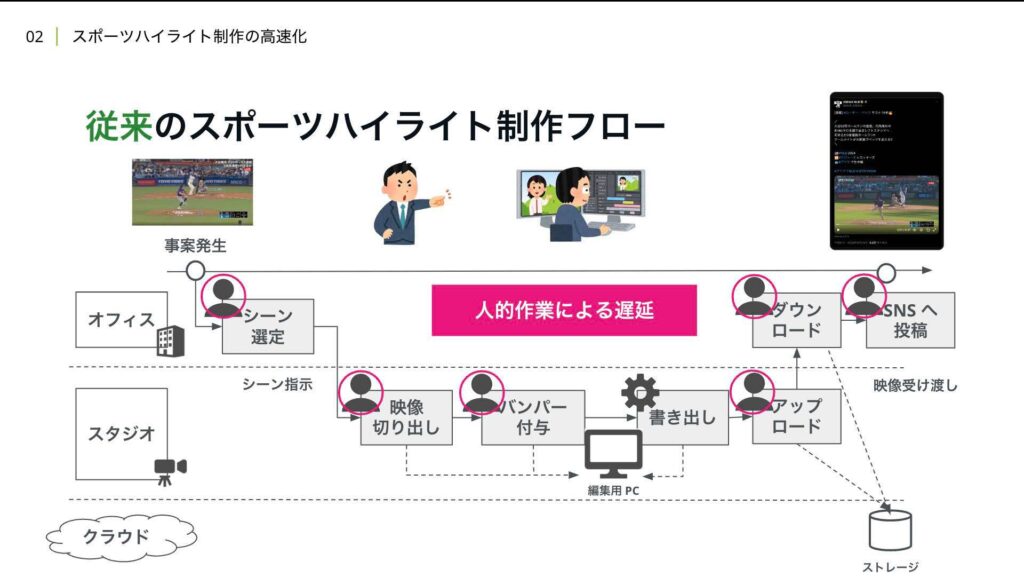
人間が作業できる速度には限界があり、さらに熟練度によっても作業スピードが変わってきます。また、オペレーションミスによる手戻りなども起こり得ます。
2つ目は映像の書き出し速度が、現場のデバイスのスペックに依存されているという問題です。現場によっては必ずしも高スペックのPCが用意できるとは限りません。
3つ目は、製作物の共有のための映像のアップロードとダウンロードによるネットワークの遅延です。
1分1秒でも早く上げたい中で、全体ワークフローの中でこれらが占める時間も無視できません。これらの課題に対して、我々は現場主体の作業から制作環境のクラウド化により解決しました。
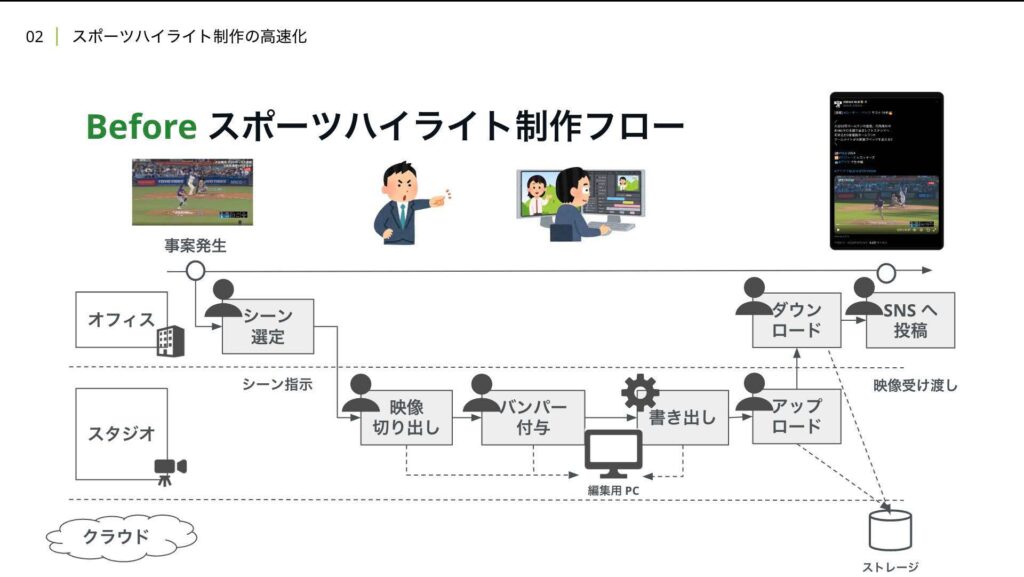
従来は全体ワークフローの中で、人による作業が占める割合がほとんどでしたが、クラウド化後はこのように人的作業をAIやシステムにより自動化することで作業ステップが激減し最終的に人間は選択と補正のみを行うだけでSNSへの投稿まで完結するワークフローを構築しました。
ではデモ映像をご覧ください。このようにAIによる検出やシーンをTimeline上に ハイライト検出として表示しています。
使いたいシーンを選択し、コピーペーストをすることでシーンを切り出すことができ、このようにバンパー映像を予め用意したテンプレートを選択するだけで、書き出し時に自動的に映像を結合してくれます。また最後に切り出したシーンをSNS公開ボタンから投稿するという流れになります。では、これらのワークフローをどのように実現しているかについてご説明します。
我々はクラウド上で映像編集可能なシステムであるビデオマスタリングコンソールVMCとAIを活用した動画解析基盤Media Analyzerの開発に取り組みました。
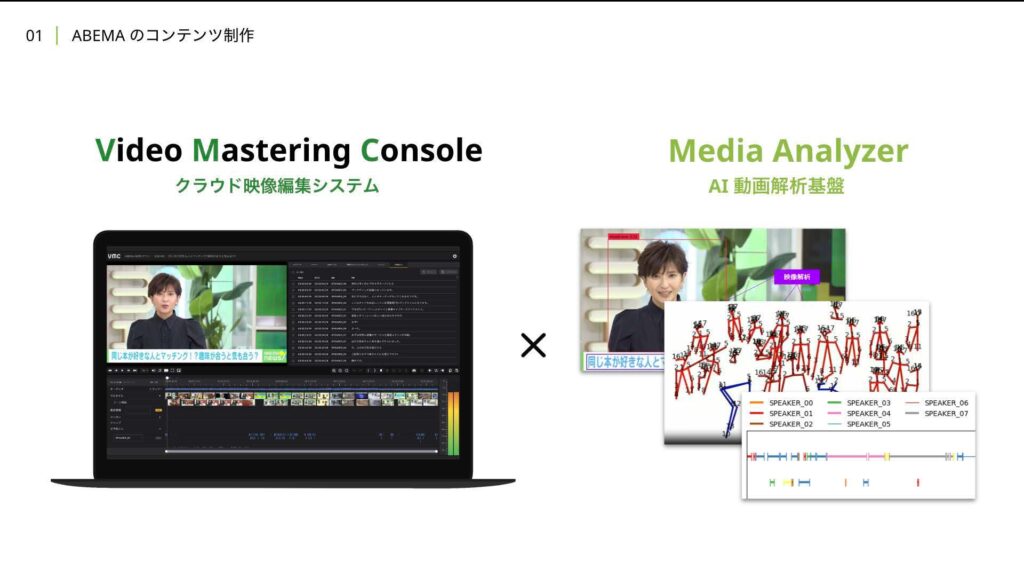 VMCはABEMAのビジネスプロセスに合わせたブラウザベースのカスタムUIです。映像編集、ディレクション、変換までが可能です。世の中には様々なソリューションがありますが既存のソフトウェアではABEMAのビジネスプロセスの要求を 満たせないことが多かったため、独自開発に至りました。Media Analyzerは動画や音声などのメディアデータを解析し意味のある時系列データとして構造化します。VMCと連携することで、人にも分かりやすい形で表示させています。
VMCはABEMAのビジネスプロセスに合わせたブラウザベースのカスタムUIです。映像編集、ディレクション、変換までが可能です。世の中には様々なソリューションがありますが既存のソフトウェアではABEMAのビジネスプロセスの要求を 満たせないことが多かったため、独自開発に至りました。Media Analyzerは動画や音声などのメディアデータを解析し意味のある時系列データとして構造化します。VMCと連携することで、人にも分かりやすい形で表示させています。
これらのシステムはより早く、より直感的に、より正確にというコンセプトで設計しました。簡易編集の自動化やAIによる提案を行うことで、効率的なコンテンツ制作を可能にしまた従来は編集において、高度な専門知識を要していましたが、誰でも学習せずとも捜査が行えるようになっています。そしてビデオのフレーム精度で、編集や切り出し指示が行えるようにすることで高品質なコンテンツを制作できます。それでは具体的なアーキテクチャについて見ていきましょう。
全体アーキテクチャはこのようになっております。

従来、映像はスタジオからしか受けることができず制作者は現場に向かう必要がありました。しかし、このシステムを構築するにあたり、ユーザー向けの生配信用のLive Encoderから出力を分岐させることで、スタジオの依存を排除しています。
また、映像はVMCでの編集作業をスムーズに行うために、軽量でかつ低解像度の映像をユーザー向けの高解像度の映像とは別に用意しています。映像がインジェストされると同時にMedia Analyzerに解析リクエストされます。その解析結果と映像をVMCで読み込みUIとして表示させユーザーが編集を行うとAPIにリクエストされます。
このAPIはサーバーレスサービスを活用することで、開発者の実装コストと運用負荷を削減しています。その後、APIを経由して、ソースのライブ映像から必要なシーンを切り出すワークフローが起動します。このワークフローは既に利用実績のあったAWS Step Functionsを採用しています。ここではマネージドな動画変換サービスであるAWS MediaConvertを活用することで強力なコンピューティングリソースを利用した高速なメディア処理を実現しています。
同時にバンパー映像の結合を行うことで、編集の作業工程を削減しているという工夫もしています。しかし、ここで実装していく上で、思わぬ問題が発生しました。それは、メディアコンバートの仕様で、必要なシーンを切り出す際の動画のトランスコード時間が、ソースのライブ映像の尺に依存してしまうという問題です。
例えば、1分程度のシーンを切り出すときでもソースファイルの尺が3時間であればトランスコードに3分もかかってしまいます。スポーツの試合は数時間に及んだり、ニュースにおいても、常時放送しているためそれ以上の時間がかかり得ます。3分と聞けば大したことのないように思えるかもしれませんが、各社 事案発生してからSNS公開するまでの時間が10分程度である中で動画の書き出しだけに3分もかかってしまうのは致命的な問題です。
ではなぜこのような問題が起こっているのでしょうか。まず、VMCでライブ映像として採用しているHLSについて説明します。

HLSは動画をリアルタイムにストリーミング配信する技術の一つで、特徴としては動画ファイルを10秒ほどの小さなセグメントファイルに分割して配信する点にあります。この方式により、ライブでは新しい映像がセグメントファイルとして次々と伝送されていきます。マニフェストファイルは、それらのセグメントファイルを再生するための指示書のようなもので、どのセグメントファイルを順番に読み込んで再生すればよいかについて記載されます。
このHLSから映像を切り出すことになるのですがメディアコンバとは指示書であるマニフェストファイルと切り出す範囲を入力として与えることで必要なセグメントファイルを勝手に見つけ出してくれ、切り出してくれます。
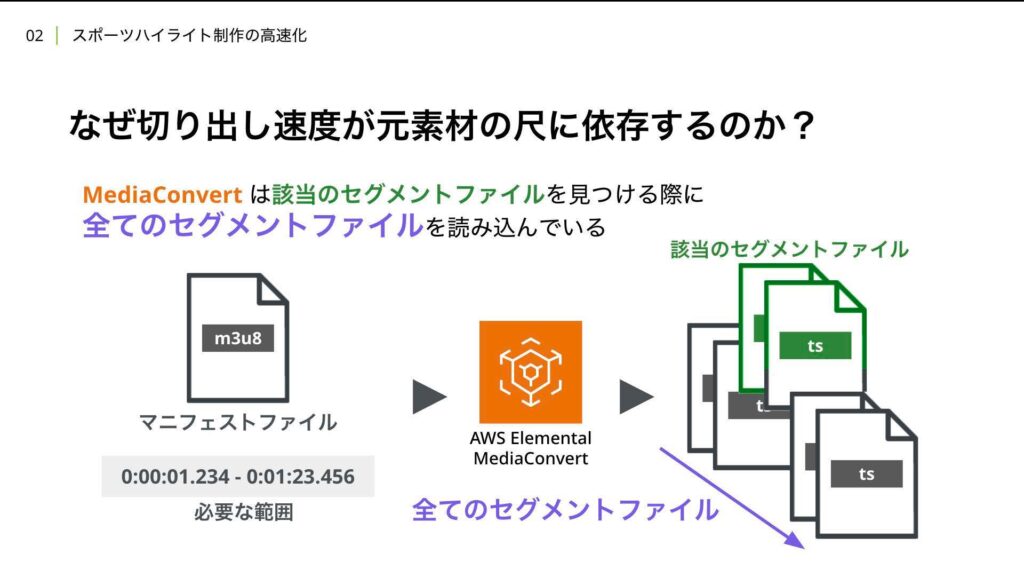
しかしここに問題があり、メディアコンバートはガイドのセグメントファイルを見つける際に、すべてのセグメントファイルを読み込んでしまうことで実際の動画変換処理以前に無駄な時間がかかってしまいます。これらの問題をどう解決したのか。それはシンプルで必要なセグメントファイルとその中の切り出したい位置を事前に計算することで不必要なファイルの読み込みを防ぎました。
これにより書き出し時間をソースの映像尺に依存せず、書き出し速度を30秒にまで短縮しています。こうすることで、高速な変換処理を実現しました。
ここからは加藤が発表させていただきます。このアーキテクチャ図の中で、右側はMedia Analyzerのアーキテクチャになっています。Media Analyzerでは映像の分割などを行うsplit。

それぞれに解析処理を行うmap、結果の集約を行うcollectの役割を持つ3つのコンポーネントでワークフローを構築しています。ここでmap部分が並列で処理されることにより、映像の解析をその映像自体の長さに依存せずに高速に行うことが可能になっています。
ここからはMedia Analyzerについてより詳しく説明していきます。先ほどのアーキテクチャ図では、縦に処理が流れていましたが、これはMedia Analyzerの部分のみを抜き出して、左から右に処理が流れています。
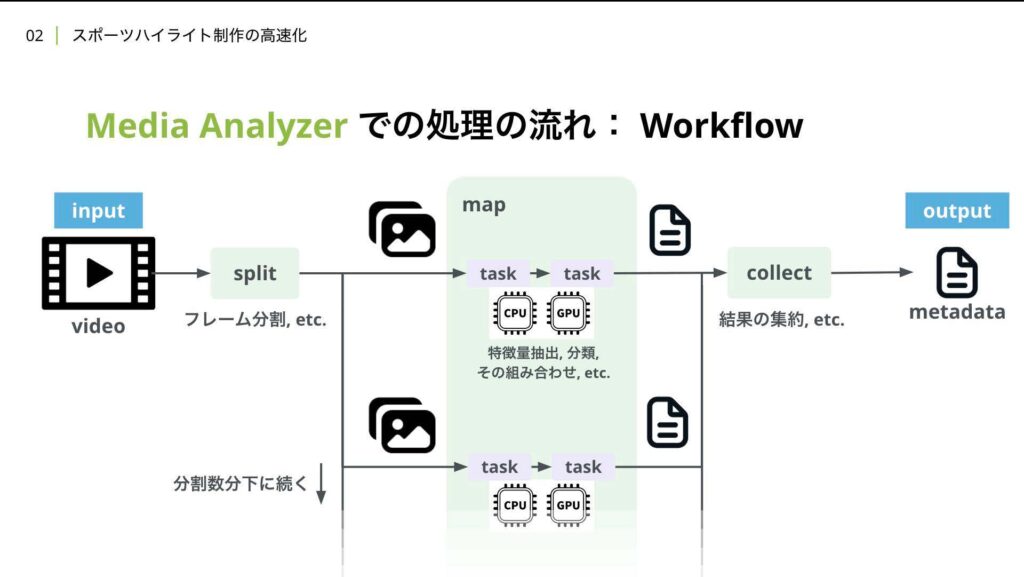
この一連の流れをワークフローと呼んでいます。Media Analyzerは動画、正確には動画が存在するURIなんですが、それを入力として受け取ります。その後は先ほど説明したようにsplit、map、collectの順でその動画を解析し、メタデータを付与します。
この図では解析ロジックが走るmapの中に特徴量抽出や分類などタスクをつなげることでワークフローを構築している様子を描いています。それぞれのタスクは必要であればGPUを載せたインスタンス上で実行され、それが並列的に行われます。
Media Analyzerではこのワークフローの構築に関してフレーム分割やジャンク分割を行うsplit、結果の集約を行うcollect、特徴量抽出など、主要な画像処理を行うタスク、また、ビデオのダウンロードや結果の出力といったVMCとの連携を基盤機能として用意しています。解析対象となるビデオとしては、契約内容に沿った全映像コンテンツにアクセス可能となっています。
これらの基盤機能を利用することで、開発者は実現したいワークフローの機能のうち、重要な解析ロジックの部分。新たに必要なタスクの中身のみを実装するだけでいいという状態になっています。
次にMedia Analyzerでの開発と実際にユーザーが利用するまでの流れを説明します。
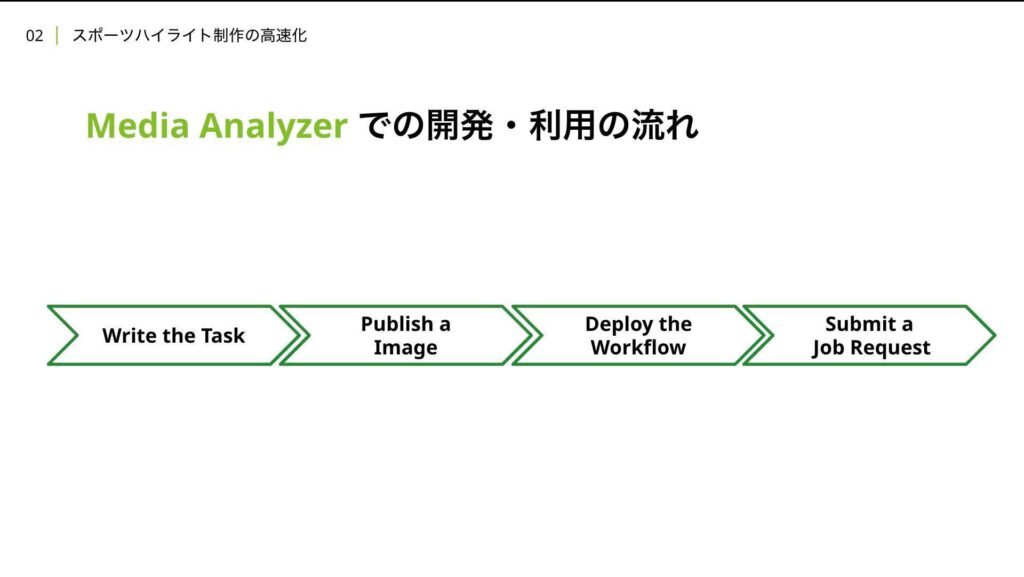 流れとしてはこれらのように新しく必要なタスクのコードを書きその後、Dockerイメージをパブリッシュし、新しいワークフローをデプロイ。ユーザーは実行ジョブのリクエストをMedia Analyzerに送ることで、Media Analyzerの機能を利用できます。
流れとしてはこれらのように新しく必要なタスクのコードを書きその後、Dockerイメージをパブリッシュし、新しいワークフローをデプロイ。ユーザーは実行ジョブのリクエストをMedia Analyzerに送ることで、Media Analyzerの機能を利用できます。
デモとして、例えば顔検出をするワークフローを追加したいとなったら、このようにフレーム画像から顔領域を検出するタスクを新たに開発します。これは真ん中のメイン関数の中でface_ditectionのモデルを使って推定していますね。
この中で見慣れないアーケファクトストアやモデルストアというものがありますが、これらはMedia Analyzerが基盤機能として開発者に提供しているモジュールで、アーティファクトストアの方は、ワークフローの中でできるタスクをまたぐ中間生成物を管理するものになっています。
ここでは、モデルの入力として使うフレーム画像や出力で出てくる顔領域が中間生成物として使われていますね。

このアーティファクトストアがあることによって、インスタンスが異なる別々のタスクでできた生成物も、保存や読み込みなどに煩わしい思いをせずに利用することができます。また、モデルストアは別途学習させた学習済みモデルを管理するもので、ここでは顔検出のモデルを読み込んでいます。
メイン関数の後半では、事前にsplitで分割されたフレーム群をmap内で振り分けられたインデックスに従って、それぞれ並列処理する上でのインスタンスの中で対応するフレーム画像を取得しています。それらに対してモデルを使って顔の領域を検出、その後アーティファクトストアを使ってその結果を中間生成物として保存しています。
こうして書いたタスクをパンツビルドというツールを用い、Dockerイメージをパブリッシュします。その後、クラウドフォーメーション形式で記述したYAMLファイルを使ってMedia Analyzer上で新しい機能を持つワークフローをデプロイします。赤でハイライトした部分がこの前の段階で新規開発したタスクの部分で、その前後のプリワークフロー。これは解析対象の動画をダウンロードしたり、splitコンポーネントとしてフレーム分割したりするものをまとめたものですね。
あとは Post-Over-Workflow。結果を集約してアップロードする部分です。これらは元から基盤機能として提供されているタスクとして組み合わせて使うことができます。ユーザーは出来上がったワークフローをこのように入力として解析したい動画を指定して使いたいワークフローを指定して
出力を指定して、出力できたかどうかを受け取る通知先を指定するようなジョブリクエストを送ることで、解析したい動画の結果を取得することができます。
 実際に開発しているワークフローの例としては、サッカーのハイライト生成があります。サッカーの動画を対象として、試合中にリプレイが挟まるようなシーンは良いシーンと捉え、その直前のシーンをハイライト候補に入れ、それらをAIを用いてイベント分類をします。こうしてできたラベル付けされたハイライト工法を、生成AIを用いてプロンプトに沿ったシーンを抽出できるようなワークフローを開発しています。
実際に開発しているワークフローの例としては、サッカーのハイライト生成があります。サッカーの動画を対象として、試合中にリプレイが挟まるようなシーンは良いシーンと捉え、その直前のシーンをハイライト候補に入れ、それらをAIを用いてイベント分類をします。こうしてできたラベル付けされたハイライト工法を、生成AIを用いてプロンプトに沿ったシーンを抽出できるようなワークフローを開発しています。
また、Timelineメタデータの共通スキーマも定義しています。時系列、時空間データを表現できるようになっていて、いつ どんなシーンがあったかといった ハイライト作成に使えるようなメタデータだけでなく今回のセッションでは講じている文字起こしのデータも共通のデータ構造で表現できるようになっています。
 これらVMCとMediaAnalyzerの開発時の工夫と活用により編集工程の自動化による制作速度の向上。AWS Media Convertによる変換速度の改善、AIのサジェスチョンによる 視認選定時間の短縮が速報性に関する効果として得られた他に、速報性以外の部分でも時間や場所を問わないコンテンツ制作が 可能となり切り出せるコンテンツ量が増加。自動化によりオペレーション品質も向上しました。
これらVMCとMediaAnalyzerの開発時の工夫と活用により編集工程の自動化による制作速度の向上。AWS Media Convertによる変換速度の改善、AIのサジェスチョンによる 視認選定時間の短縮が速報性に関する効果として得られた他に、速報性以外の部分でも時間や場所を問わないコンテンツ制作が 可能となり切り出せるコンテンツ量が増加。自動化によりオペレーション品質も向上しました。
次にニュース記事制作の効率化についても詳しく紹介します。先ほど自社メディアとして話にあれていた ABEMA TIMESを紹介しますとABEMAが運営するニュースメディアでヤフーニュースなど外部メディアにも 記事を公開しています。
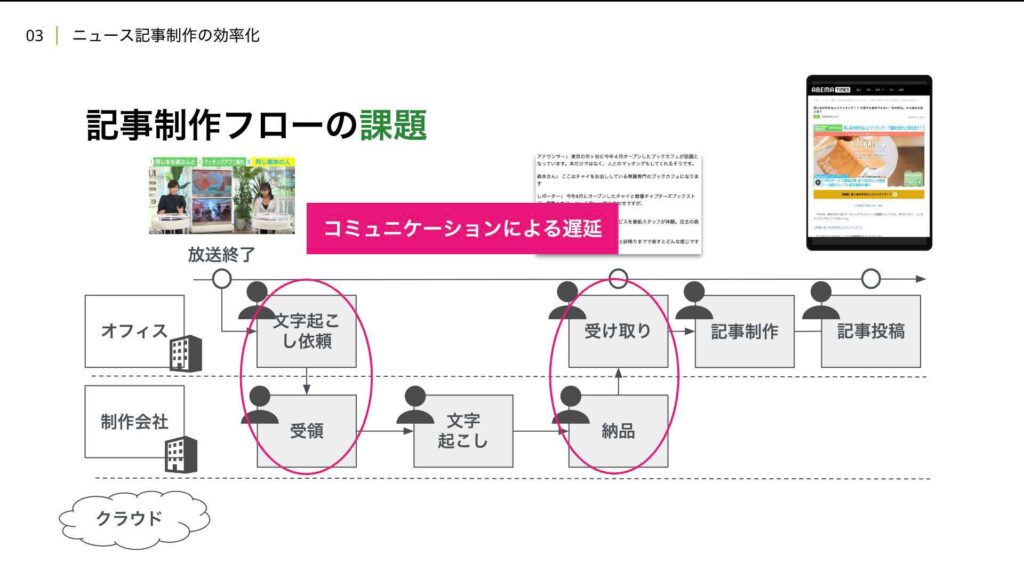
 先ほど説明した通り、SNSと同様に、 ABEMAの視聴ページへの動線としての役割も持っています。従来の記事制作フローでは、放送終了から文字起こし、記事制作、記事公開といった流れを踏むのですが、例えば手作業による遅延であったり、文字起こしを外部の制作会社に外注していると、コミュニケーションによる遅延が発生します。
先ほど説明した通り、SNSと同様に、 ABEMAの視聴ページへの動線としての役割も持っています。従来の記事制作フローでは、放送終了から文字起こし、記事制作、記事公開といった流れを踏むのですが、例えば手作業による遅延であったり、文字起こしを外部の制作会社に外注していると、コミュニケーションによる遅延が発生します。
このような課題を解決するために、AIによる自動文字起こしと 記事生成機能を開発し提供しています。
 これらの機能により、従来の記事制作フローが、このようにクラウドでの文字起こし生成と記事生成が組み込まれることによって、作業者は、生成された記事の確認や修正のみを行うだけで良くなります。こちらが実現した機能のデモ映像となります。左上のプレビューには、生成された字幕が字幕の長さとして適切で自然な位置で分割され、さらに画面上の文字と被らないように表示されます。字幕の色も話者ごとに分かれています。話者名も簡単に変更することができ、話者名のラベル付けのモデルの学習にも用いることができます。
これらの機能により、従来の記事制作フローが、このようにクラウドでの文字起こし生成と記事生成が組み込まれることによって、作業者は、生成された記事の確認や修正のみを行うだけで良くなります。こちらが実現した機能のデモ映像となります。左上のプレビューには、生成された字幕が字幕の長さとして適切で自然な位置で分割され、さらに画面上の文字と被らないように表示されます。字幕の色も話者ごとに分かれています。話者名も簡単に変更することができ、話者名のラベル付けのモデルの学習にも用いることができます。
記事生成部分はTimeline上で範囲を指定し、それをソースとした記事生成が可能で、記事のスタイルや長さ、利用するモデルなどを柔軟に変更可能です。次にアーキテクチャに関して説明します。
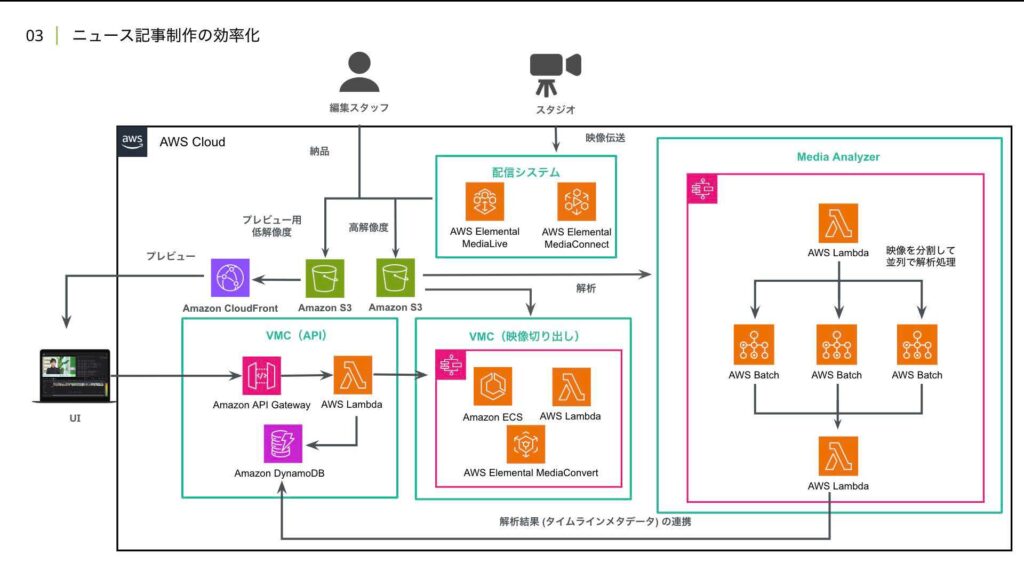
ただ、先ほど見せたアーキテクチャ図とほぼ同じになりますが、差分としては生配信だけではなく出来上がった映像に対するファイル納品も 同じアーキテクチャで実現できるように設計しました。また、先ほど説明したように、文字起こしや記事生成の機能はMedia Analyzerの基盤機能を活用し、そのロジックを実装するだけでいいという状態になっています。
具体的な文字起こしのロジックとしては最終的に字幕単位で話者、内容、字幕を表示する時間、字幕を表示する位置を推定する上で、このような流れで処理を行っています。自然な位置での単文分割は、一言が字幕で表示するには長いことが多いため入れている処理になります。
 また、記事生成はLLMを活用し、文字起こしをソースに文章のスタイルや長さを利用するモデルを選べるようにしています。ここで言う文章のスタイルというのは、例えば、インタビュー記事のような 一問一答のための文体やSNSの投稿を紹介するようなカジュアルな文体それぞれのことを指します。その文章のスタイルは、 既存のABEMA TIMESの記事群を用い、コンテキストに含むことで出力される文体をコントロールしています。
また、記事生成はLLMを活用し、文字起こしをソースに文章のスタイルや長さを利用するモデルを選べるようにしています。ここで言う文章のスタイルというのは、例えば、インタビュー記事のような 一問一答のための文体やSNSの投稿を紹介するようなカジュアルな文体それぞれのことを指します。その文章のスタイルは、 既存のABEMA TIMESの記事群を用い、コンテキストに含むことで出力される文体をコントロールしています。
また、生成に使う情報は、 ABEMAの動画の文字起こしか、過去のABEMA Timesの記事など、ABEMAのコンテンツのみを利用し、最後に人によるチェックも欠かさないことによりリスクを最小化しています。結果、1記事あたりの作業時間が短縮され、記事数の増加につながりました。実際に生成AIを活用した記事も、ABEMA Timesから閲覧することができます。また、この記事生成AIに関する話は、こちらの記事でお話しているので、よければ見ていただけると幸いです。
最後に今後の展望になります。我々は業界最速のSNS公開を目指していて、最終的には人間がチェックするだけでいい世界を作りたいと考えています。
そのために、例えば、過去の実績データを学習して、より見てもらえるようなシンセンス、動画構成、投稿文言すべてをAIがサジェストする機能や事案を自動で検出し、そのまま自動でSNS投稿のドラフトを生成して担当者にプッシュする機能、担当者は上がってくるドラフトをそのまま投稿するか否かを判断するだけでいい世界など、これらの実現に向けて引き続き邁進していきます。
今回のセッションは以上になります。ご静聴ありがとうございました。
