
株式会社サイバーエージェントでは生成AIはもちろんのこと、各領域においてのML活用のためにさまざまなデータを取り扱っています。 そのデータの価値を高めるアノテーションについて、量と質、拡張性、事業応用性を担保する上で意識している事を紹介します。
本記事は、11月7日に開催した「CA DATA NIGHT #5 〜生成AIのリアル:エンジニアが直面した課題と実践〜」において発表された「AIの血肉となるアノテーションデータのために大事にしている事」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
小林 拓磨(開発責任者)所属:AI事業本部 極事業部 新規プロダクトチーム
機械学習の基礎研究・バイオインフォマティクスの研究分野に従事し、金融系のデータを扱うフィンテックベンチャーを経て、2021年新卒入社。機械学習エンジニアとして極予測AIの予測エンジンの開発し、新規プロダクトの立ち上げ、データエンジニアリングから生成AIにおけるUIUX、領域広く担当。直近全社的なデータ活用施策として各事業部のデータ需要を調査中。猫が好き。
CA DATA NIGHT セッションの2番目として、「AIの地肉となるアノテーションデータのために大事にしていること」について、AI事業本部の極事業部に所属する小林拓磨が発表いたします。どうぞよろしくお願いいたします。アジェンダはこのような流れになっています。

ライトにお聞きいただきながら、各ポイントに注目していただければと思います。私は、バナーの自動生成チームで新規プロダクトのリードを担当しており、他にもカンファレンスのコンテンツ作成などのお手伝いをしています。普段の仕事は、特に決まったものはなく、幅広い業務をこなしています。趣味は旅行やワーケーションで、猫が好きです。
極事業部では、どのようなことをしているのかを簡単にご紹介します。リリースしている内容の中からピックアップしてきたものですが、主に広告予測エンジンを開発しています。弊社は広告代理業務を行っているため、お客様に対して効果的な広告クリエイティブを作成しています。そのプロセスの中で、広告の効果を最大化するための取り組みを行っています。

極事業部では、どのようなことをしているのかを簡単にご紹介します。リリースしている内容の中からピックアップしてきたものですが、主に広告予測エンジンを開発しています。弊社は広告代理業務を行っているため、お客様に対して効果的な広告クリエイティブを作成しています。そのプロセスの中で、広告の効果を最大化するための取り組みを行っています。
さらに、クリエイティブ領域においては、最近、生成系技術が盛り上がってきているという背景もあります。例えば、ChatGPTが登場する1年〜2年前から、広告コピーの生成に取り組んでおり、最近では化粧品の背景などを自動で生成する技術も開発しました。これらはカメラで撮影したものではなく、生成された画像です。特に注目すべき点は、ガラス瓶の透過表現です。後ろの背景が透過しつつ生成されているのですが、これは多くのベンダーでは実現できていない技術的にすごいポイントです。これについても宣伝をさせていただきました。
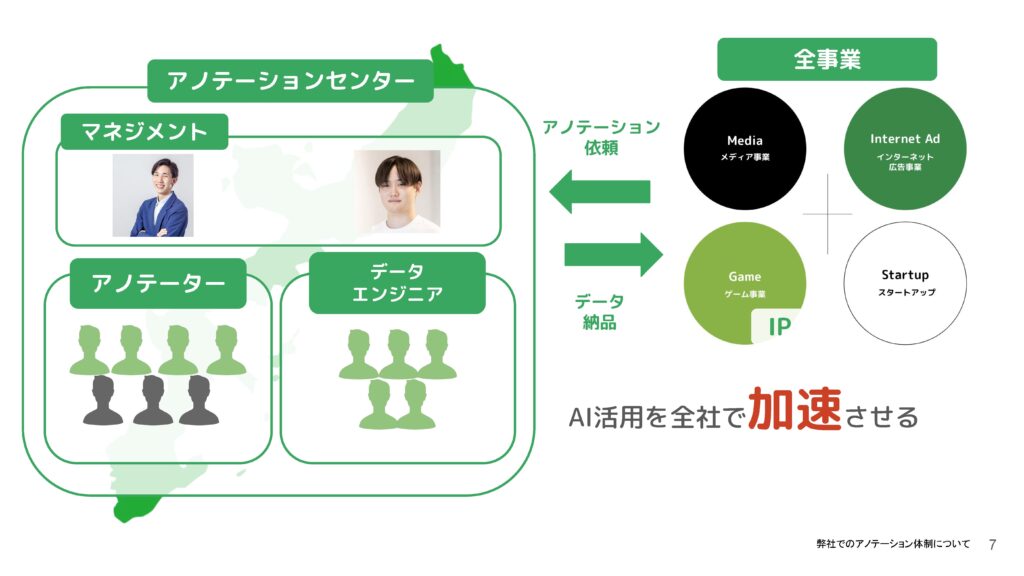
今回はアノテーションに焦点を当ててお話しします。弊社には沖縄に「シーエー・アドバンス」という組織があり、そこでアノテーターの皆さんがデータにアノテーションを施してくれています。データをお渡しし、そのデータにアノテーションをつける作業を一緒に行っています。弊社はメディア、ゲーム、広告、そしてクリエイティブなどの組織を持っており、その各分野で収集したデータにアノテーションを付け、AI活用の加速を目指して貴重なデータを作り上げています。

今日のテーマは、アノテーションを進めていく中で直面する「ブレ」についてです。案件を進めていくと、どうしてもアノテーションにブレが生じてしまい、「一致しない」「基準が異なる」といった問題が発生します。このようなブレが長期的に続くと、生成されるコンテンツのクオリティや、予測モデルのスコアリングに影響を与えてしまうため、このブレをなくすために何を大事にしているかをお話ししたいと思います。
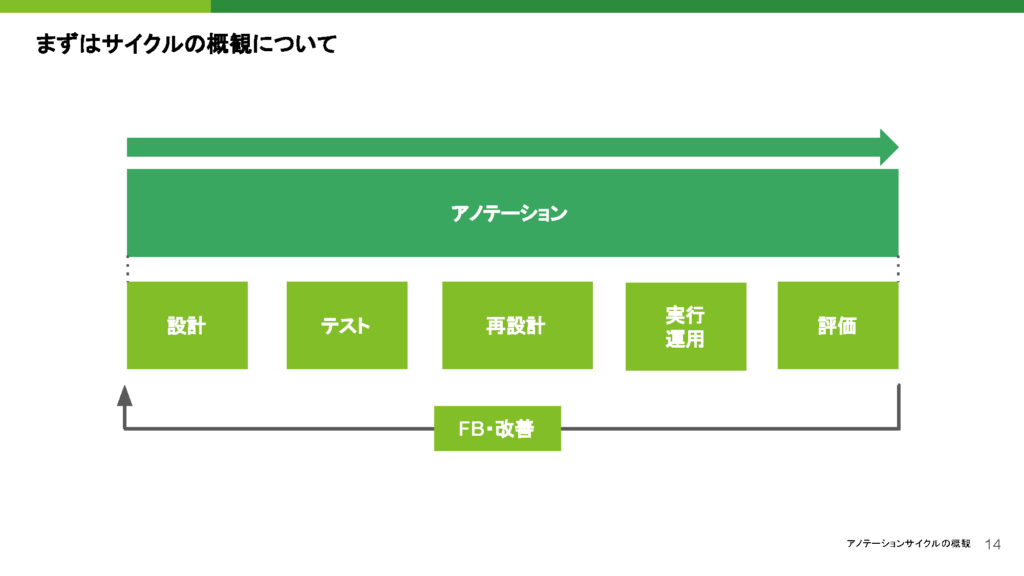
今回話す領域としては、実際にどのようなサイクルでアノテーションが進んでいるのか、そしてその中で何を大事にすべきかについてお話しします。
アノテーションの最終的な成果物は、こんな感じになると認識しています。個人的な見解としては、このような流れが一般的だと思います。それぞれのステップを一つずつ詳しくお話ししていきますが、まず最初に設計について触れます。例えば、猫の画像にアノテーションを施していく場合の例を挙げて説明します。

アノテーションと一口に言っても、実際にはタスク選定が重要です。同じ画像を使用する場合でも、何をつけるかにはさまざまな種類があることは皆さんご存知かと思います。例えば、猫の顔にセグメントを付ける、物体検知を行う、キャプションをつけるといった具合です。特にキャプションに関しては、最近ではVLM(ビジョン・ランゲージ・モデル)などの影響で、価値が高いデータとして注目されています。
このように、アノテーションの種類は多岐にわたります。そのため、タスク選定を目的に合わせてしっかりと行うことが重要です。ここまでは問題ないかと思いますが、さらに進んで、それぞれのタスクには流度が非常に多く存在するという点が次のポイントになります。
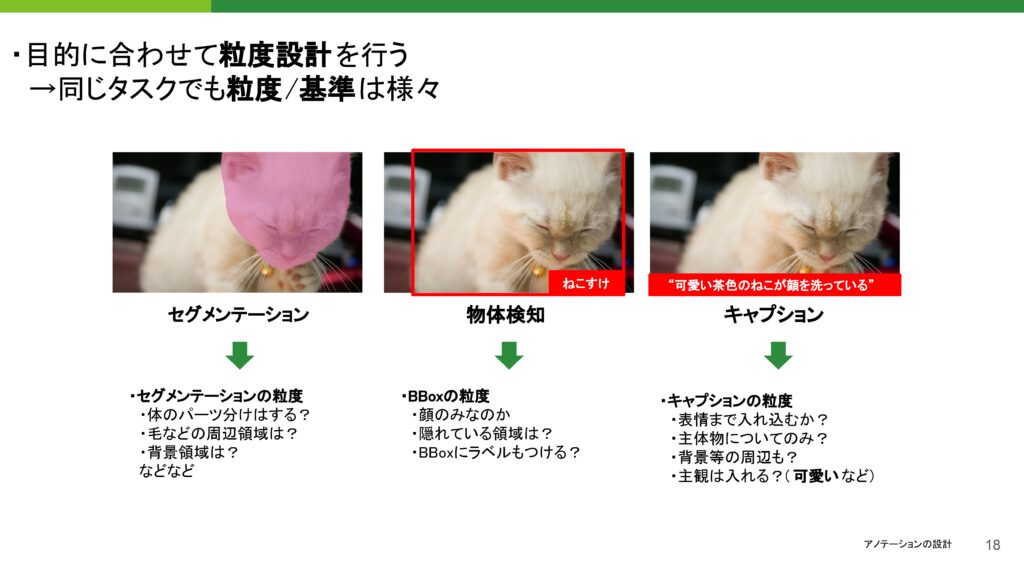
セグメンテーションのタスク一つを取っても、例えば体のパーツを分けるかどうか、毛の周辺領域まで取るべきか、背景領域を含めるかどうかなど、細かい判断が求められます。
また、キャプションをつける際も、どこまで細かくキャプションをつけるかが重要なポイントになります。出力として求める内容やタスクの目的に応じて、キャプションの内容をしっかり決めなければ、AIの反応が悪くなることがあります。例えば、表情を含めるかどうか、主体物を明確にするか、主観的な要素を加えるかといった点です。
なぜ表情の有無が重要かと言うと、例えば広告のクリエイティブ制作で「表情を悲しい表情にさせたい」「嬉しい表情にさせたい」といった生成モデルを作りたい場合、その目標に合った言葉(例えば「目をつぶって顔を洗っている」)をキャプションとして入れておかないと、モデルが反応しなくなります。画像と紐づける言葉はしっかり選定し、生成時に反応させたい言葉は必ず含めるようにしましょう。
さらに、スコアリングや姿勢、タグ付けに関しても、主観的な判断が必要です。このような基準や流度の部分には無限の選択肢があり、慎重に設定することが求められます。
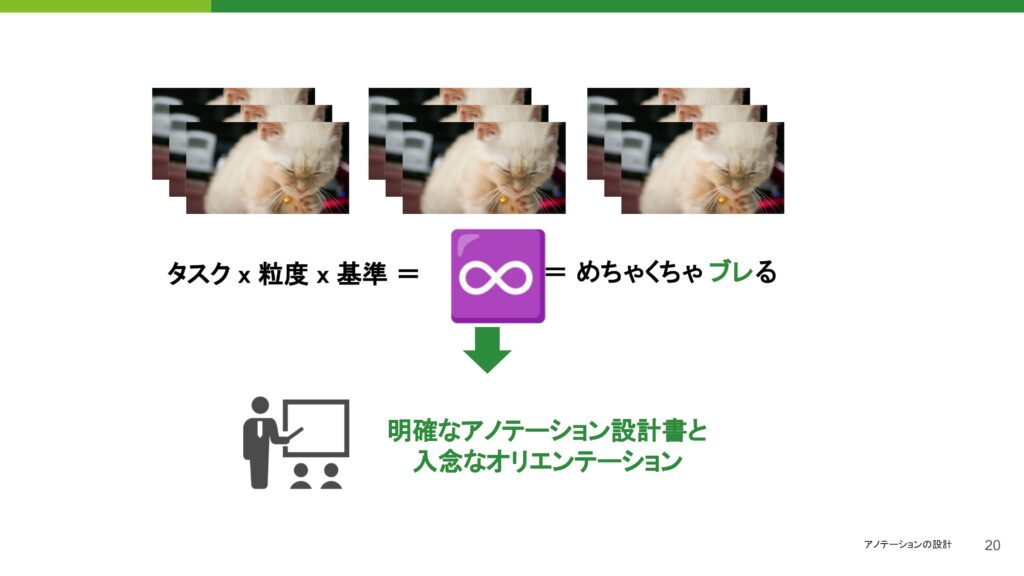
タスク、粒度、基準という要素が絡むと、パターンは無限に広がってしまいます。そのため、ただ単に依頼を出すだけでは、結果としてアノテーションがブレてしまうのは避けられません。これは当然のことです。そのため、明確なアノテーション設計書を作成し、入念にアノテーションを行うことが重要です。これらは一見当たり前のことのように思えるかもしれませんが、しっかりと注意を払って進めていくことが成功への鍵だと思います。やりたいこととアノテーションの流度をしっかりと紐づけることが、プロジェクトを成功に導くためのポイントだと考えています。
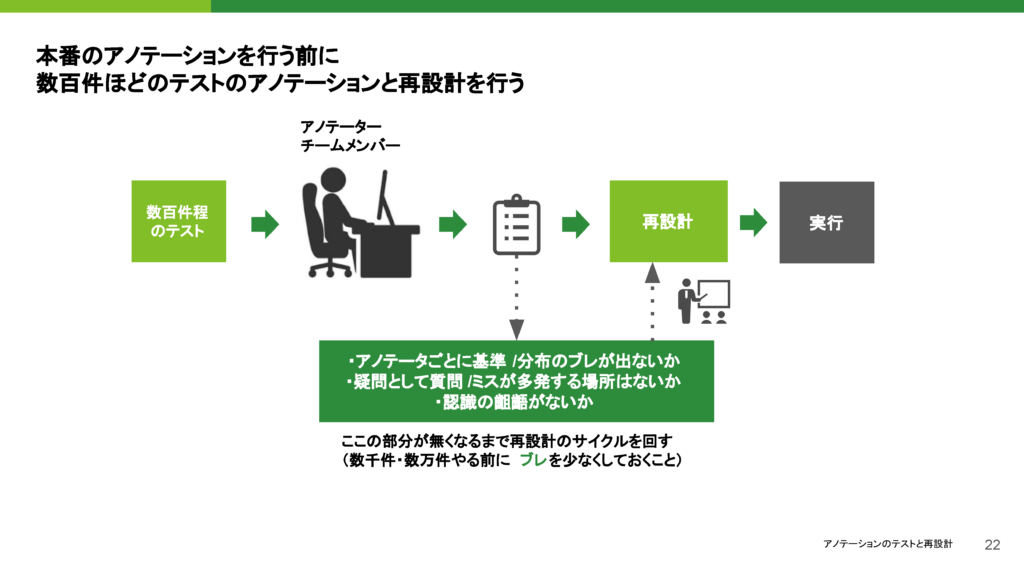
次の段階として、テストと再設計があります。ここでも、流度と基準に関しては、画像にアノテーションをつける際に設計書があると、どうしてもブレが生じやすくなります。そこで、最初に数万件のアノテーションを依頼する前に、まずは数百件を依頼し、アノテーションを実施した結果をサンプリングすることが重要です。このサンプリングを通じて、アノテーターごとの基準のブレや分布のブレがないかを確認します。
もしブレが生じる場合、それは設計書に甘さがあることが原因であることが多いです。例えば、基準が明確に定義されていない部分があれば、みんなが同じ基準で判断できないという問題が発生します。こうした場合、設計書を見直して、基準をより明確にする必要があります。また、アノテーターから質問が出ている場合も、設計書が不十分である証拠です。
そのため、アノテーターに同じ画像に2人、もしくは3人にアノテーションをつけてもらい、その結果が一致するかどうかを確認することが重要です。この一致を確認することで、設計書が適切であるかをチェックできます。このプロセスを通じて、設計書を再設計し、オリエンテーションを改めて行いながら、アノテーションの基準を整えていきます。
この段階が非常に重要であり、重たい作業ではありますが、ここでしっかりと整備することで、後々のアノテーションの質が大きく向上します。
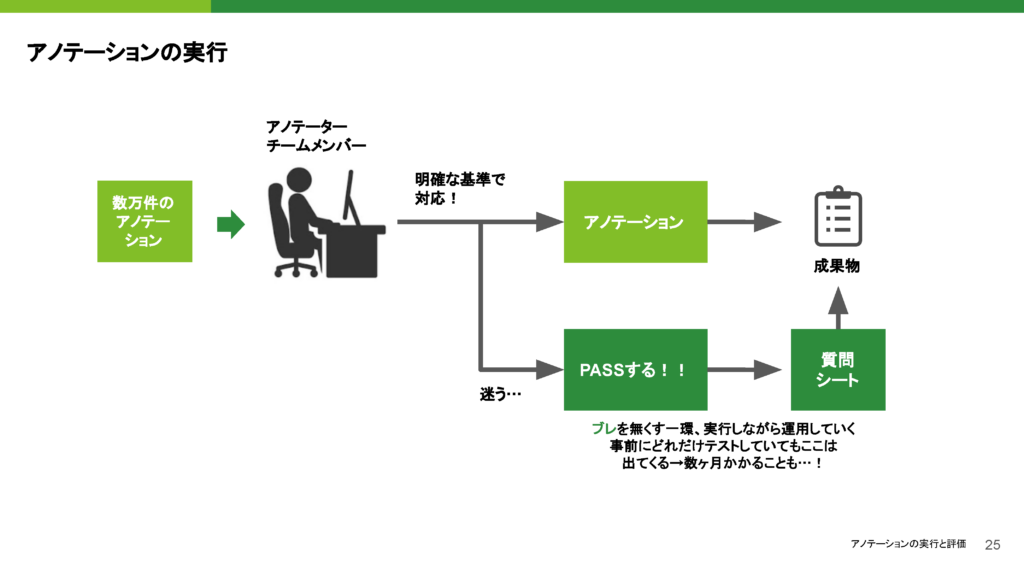
アノテーションの実行と評価のフェーズに入った際、基本的には設計に基づいて明確な基準でアノテーションが進められるはずですが、途中でアノテーターが迷ってしまう場面が発生することがあります。このような場合、迷った部分については、明確に指示を出す方が良いです。アノテーションを担当する方も、どうすべきか分からない場面では困ることがあると思います。そのため、この場合は「一旦パスする」という方法を取ります。迷った部分はリストに残しておき、後で基準を再確認し、ディスカッションを繰り返しながら決めていく形にします。
この基準の明確化には時間がかかることが多く、実際に私が担当した広告関連のアノテーションでは、基準が固まるまでに約3~4ヶ月かかりました。それほど時間をかけて基準を固めることが重要だと認識しています。このプロセスを経て、最終的に成果物として得られたデータは、さまざまなタスクで活用されています。
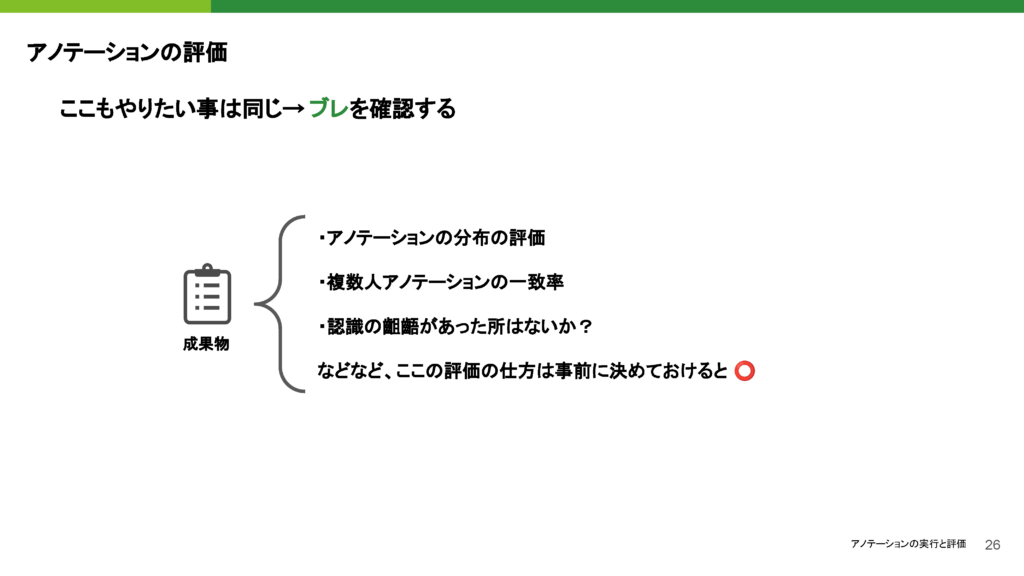
基本的には、アノテーションの進行中にブレが生じていないかを確認することが重要です。特に、アノテーションの分布の評価や、複数人でアノテーションを行っている場合には、一致率をチェックすることが大切です。一致率が低い場合、それが明らかであれば、そのデータはクリーニングして除外するか、再度アノテーションを依頼するべきです。この点については、ディスカッションを通じて判断することが求められます。
また、アノテーションがうまくいったものが納品されているかを確認する際、納品の基準として「一致率何%以上」を定めておくと良いでしょう。特に外注する場合、費用がかかるため、基準を事前に明確に決めて、先方にも伝えておくことが重要です。これにより、アノテーションの品質を担保することができます。
最も避けるべきなのは、大きな費用をかけて何万件ものアノテーションを行った結果、それが全く使えないという事態です。このようなことが起こらないように、しっかりとした基準と確認を行うことが大切です。

最終的な評価後のフィードバックについてですが、アノテーションの分布に関する話も含めて、フィードバックは重要です。特に、継続的なアノテーションが必要な場合、例えば継続学習を進めるためにアノテーションを引き続き行う場合には、精度が高いアノテーターを優先的にアサインすることが有効です。このようにして、アノテーションの精度を維持し、品質を向上させることができます。

最終的に評価した後のフィードバックについてです。フィードバックの際には、先ほど挙げたアノテーションの分布などの点についても考慮しつつ、継続的なアノテーションが必要な場合もあるかと思います。その場合、アノテーションの精度が高い担当者を優先的にアサインする方法があります。
また、アノテーション速度も重要な要素となります。アノテーションタスクにおいて、どの担当者が得意なのかを見極め、得意な担当者に優先的にアサインすることが効率的です。さらに、自動化できるアノテーション作業があれば、それは積極的に自動化してしまうことが効率化につながります。後ほど、この自動化の部分についても触れます。
これらのポイントに加えて、アノテーションのバリデーションに関しても重要です。理想的な設計やブレの排除を目指して進めてきましたが、現実的にはデータ収集や機械学習タスクにおいて、事業要求や最先端の研究の影響を受けることがあり、ブレが生じることも避けられない場合があります。
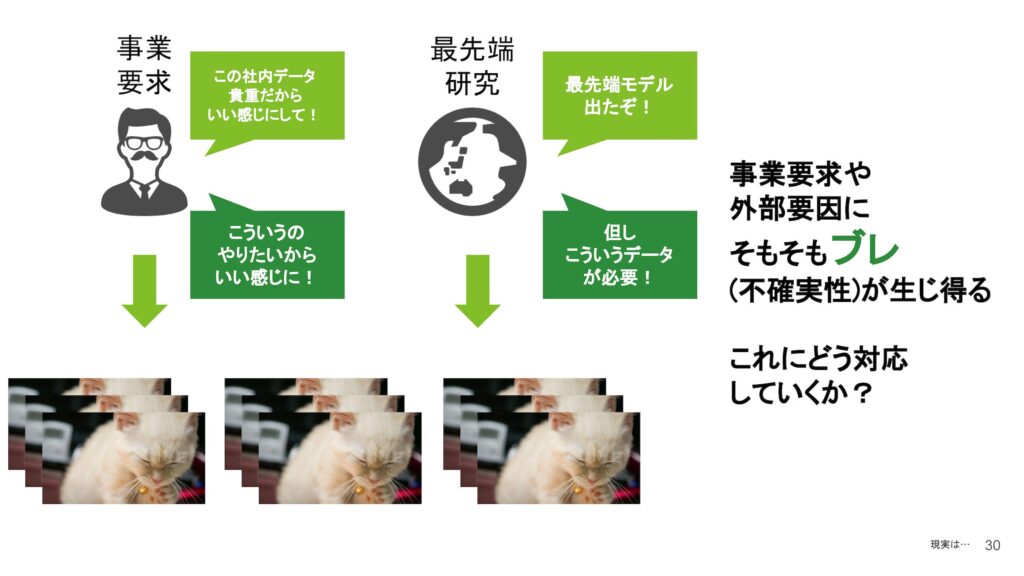
この社内データについては、弊社だけが持っているという状況なので、どう仕上げるかについてはすぐに対応が必要なこともあります。例えば、「今すぐにやりたいから、この感じで進めておいてほしい」といった依頼がよくあります。こうした事業の不確実性が大きいため、どのアノテーションを優先して行うか、またはどのように見据えておくべきかが非常に難しい部分です。
また、リサーチにおいては、最先端のモデルが登場した際に、「これには20万件のデータが必要です」と言われることもあります。このような場合、現実的にはかなり大きな課題となり、どのように対応するかが壁となって立ちはだかることがあります。
いくつかのケーススタディを紹介しましたが、最初のケースは比較的簡単なものであると言えます。
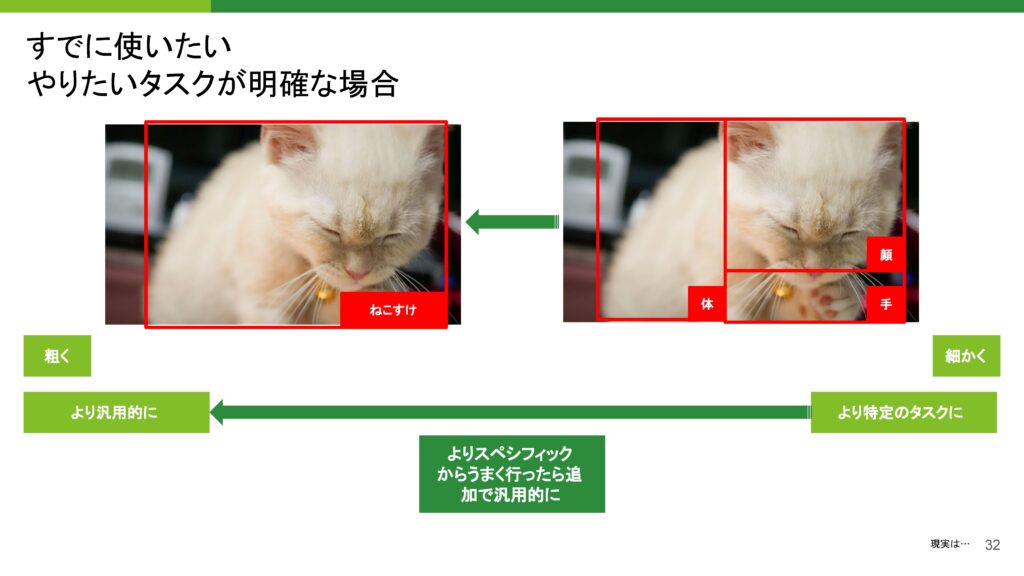
すでに使いたいやりたいタスクが明確な場合は、特定のタスクに特化して進めることができます。この場合、入力としてデータを入れ、出力として求める結果を得るために必要なアノテーションの特徴量(例えば顔や手など)を定義します。その上で、具体的な出力を求めることができるので、細かい流度からスタートするのが効果的です。このプロセスは比較的簡単に進められると思います。
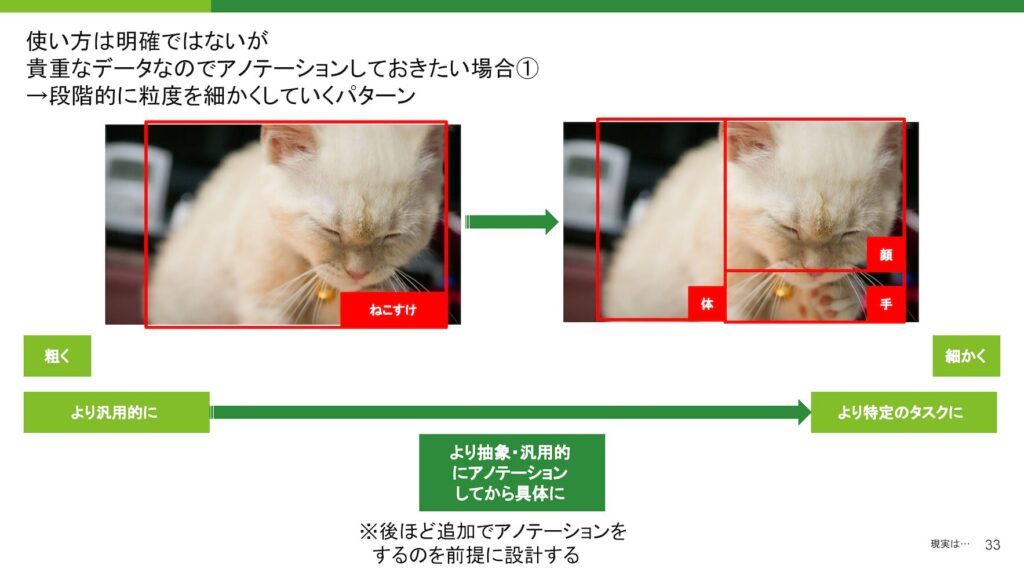
もう一つの難しいケースは、使い方が明確でないが、将来的に何かに活用できそうなデータをアノテーションしておいてほしいという依頼です。特に、AI事業本部などではこういったケースがよくあります。この場合、最初に汎用的にアノテーションをつけておき、その後、使いたいタスクが明確になった段階で流度を細かくしていくアプローチが有効です。
最初は、アノテーションをかなり抽象的に行い、後からそのデータに合わせて詳細なアノテーションを追加していきます。このように段階的に進めることで、最終的に目的に合ったデータを得ることができます。これは、同じタスク内での進め方として有効な方法です。
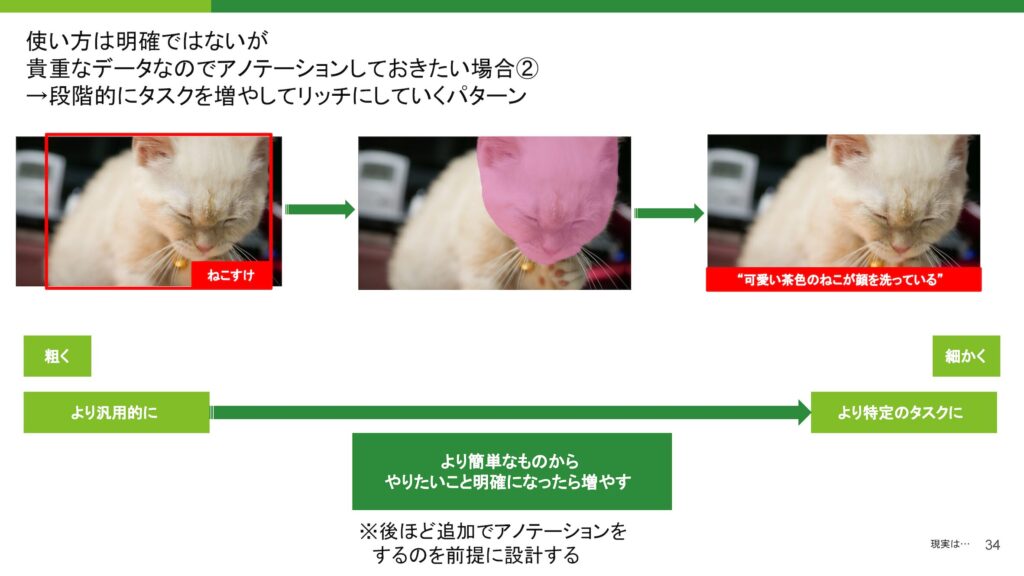
もう一つのケースは、タスク自体がそもそも分岐するパターンです。使い方が明確ではないけれども、様々な用途に活用できるようにアノテーションをつけておいてほしいという依頼が来た場合、最初に汎用的なアノテーションを行う方法も有効ですが、その際はより簡単なものから始めていくアプローチが適しています。
まずは、簡単なタスク、例えば検知系などから始めて、徐々にやりたいことが明確になった段階でアノテーションを増やしていくという形で進めることが良いでしょう。このように、段階的にアノテーションを追加することで、最終的に目的に合ったデータを得ることができます。

最終的な使い方とか事業ペースに合わせてうまくバランスしていくことが大事かなと思っています。

まとめとしては、アノテーションのブレをなくすためには、ほぼすべての工程に工夫を凝らす必要があります。最初は大変ですが、最初にしっかりと頑張れば、その後は比較的楽に進めることができるので、丁寧に取り組んでいきましょう。
また、ふんわりとしたオーダーが来た場合には、目的や段階に合わせてアノテーションの情報をリッチにしていくと良いと考えています。これでまとめとしては終了ですが、最後に少しだけ追加のチップスとして、どのような成果が得られたのかについても触れたいと思います。

これはかなりシンプルな成果の一例ですが、例えば、私たちAI事業本部は広告事業本部と連携し、広告に関連する予測エンジンを開発しています。その予測精度を最大化するために、また生成AIを活用するために、広告特化の日本語OCR(光学文字認識)モデルを構築しました。右側に示しているのは以前のOCRモデルですが、従来のモデルでは、日本語の縦書きに対応できなかったり、文字の認識精度が低かったりする問題がありました。
日本語には特有の縦書き文化があるため、縦書きの文字を正確に認識できないことは大きな課題でした。縦書きのテキストを一文で取りたいのに、従来のOCRではそれがうまくできなかったのです。この問題を解決するために、縦書きにも対応できるようにデータ設計をし、モデルを学習させていきました。
日本国内のデータには特有のニッチな要素が多く、海外の英語を前提にしたモデルでは対応できないケースもよくあります。そうした背景から、私たちは日本語データをしっかりと収集し、独自に対応できるモデルを開発しています。今後も、こうした成果物をリリースし続けることができると思っていますので、楽しみにしていてください。
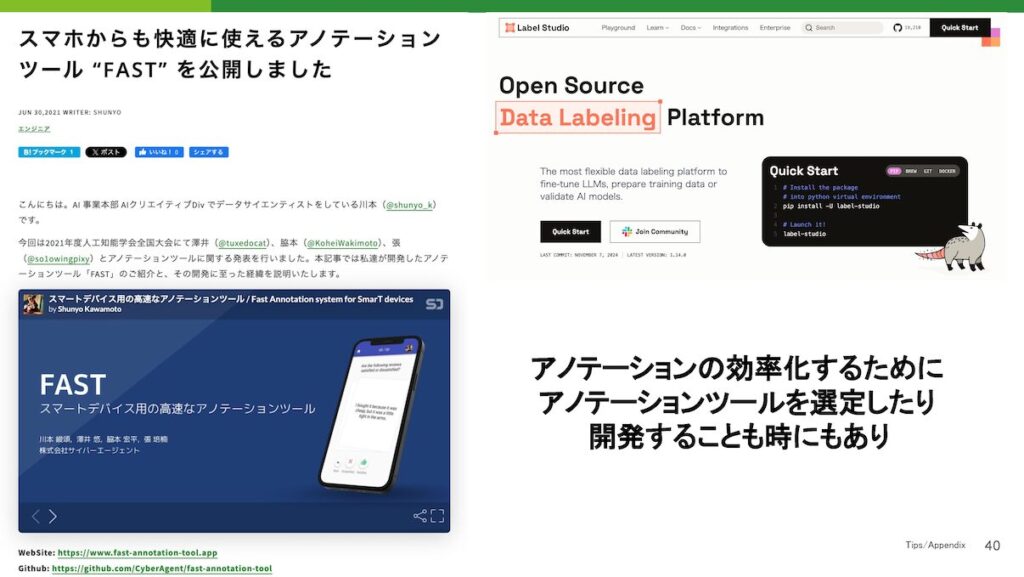 他にもアノテーションの効率化について、アノテーションツールの選定が重要であるという話があります。右側のツールは、皆さんもよくご存知の「ラベルスタジオ」などを使用し、さまざまなアノテーション作業を効率的に行う方法です。このツールを活用することで、作業のスピードと精度を向上させることができます。
他にもアノテーションの効率化について、アノテーションツールの選定が重要であるという話があります。右側のツールは、皆さんもよくご存知の「ラベルスタジオ」などを使用し、さまざまなアノテーション作業を効率的に行う方法です。このツールを活用することで、作業のスピードと精度を向上させることができます。
左側には、弊社のゼミ制度で生まれたアノテーションツールがあります。このツールは、アノテーターが全員PCを持ち歩いているわけではないという現実を踏まえて開発されました。特に移動時間にアノテーション作業を行えるように、スマートフォンでスワイプするだけでアノテーションができる仕組みを作り上げたのです。まるでマッチングアプリのように、スワイプで簡単にデータを処理できるという、実用的で効率的なツールです。
こうした効率化のためのツール選定や改善は、ブレをなくすために重要な要素です。アノテーションの精度を保ちながら、作業を迅速に進めるためには、適切なツールの導入と運用が必要不可欠です。
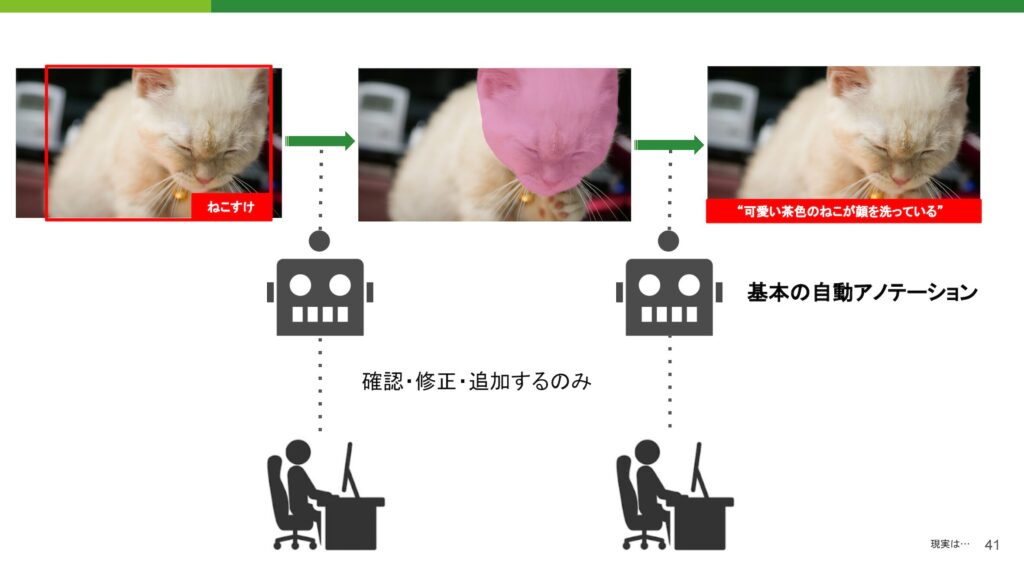 また、効率化に関しても一つのアプローチがあります。最初の段階では、基本的な検知作業やアノテーションに関しては、高精度なモデルを利用して一度基本的なアノテーションを行い、その後は確認や修正、追加作業をボタン一つで行えるようにすると、作業スピードが飛躍的に向上します。こうすることで、アノテーション作業の効率が大幅に改善されることがあります。
また、効率化に関しても一つのアプローチがあります。最初の段階では、基本的な検知作業やアノテーションに関しては、高精度なモデルを利用して一度基本的なアノテーションを行い、その後は確認や修正、追加作業をボタン一つで行えるようにすると、作業スピードが飛躍的に向上します。こうすることで、アノテーション作業の効率が大幅に改善されることがあります。
さらに、効率化のためには「考えさせない」という方法も有効です。例えば、「5秒以内にアノテーションをつけてください」と制限を設け、5秒以上かかったものは無効にするというルールを設けると、直感的に素早くアノテーションを行うことができ、作業がスムーズに進みます。この方法により、アノテーションのスピードが大きく向上する場合があります。
さらに高度なアプローチとしては、アノテーションタスクを単なる仕事としてではなく、普段の体験としてユーザーに行わせる方法も考えられます。例えば、サービスと連携してユーザーが日常的に触れるコンテンツの中でアノテーションを実施させることで、自然な形でデータを収集する方法です。

これは、2023年のRecommend Systemsの学会に参加した際に面白いと感じた内容です。ECの検索体験に関連する話で、例えばユーザーが「ちょっと暗めの色のスウェードのパンプスが欲しい」と思っている場合、言葉でそのニーズを表現するのが難しいことがあります。ユーザーは具体的な言葉ではなく、頭の中で欲しいもののイメージを持っているだけです。
こうした場合、検索機能が「I prefer red suede」という入力に対してまず1回検索結果を提示し、そこから近い商品を提示します。その後、ユーザーは「これが近い!」と思った商品を選び、さらに「もっと暗い色でフラットにしてほしい」と調整することで、最短のターンで自分の欲しい商品にたどり着けるという体験を提供します。
これにより、ユーザーがさらに操作を進めるたびに、システムが彼らのニーズに合った商品を提案する仕組みになり、最終的にユーザーの体験が向上します。しかも、このプロセスを通じて自然にラベルが集まり、データとして活用できるようになります。つまり、ユーザーがサービスを利用すればするほど、データがリッチになり、それがサービス向上にもつながるという良循環が生まれます。
このように、ユーザーのモチベーションを上手く引き出しながらデータ収集を行う設計は、非常に効果的なアプローチだと感じました。

今の話は、こういった書籍の中にも詳しく紹介されている内容で、実際に自分も読み進めているところです。ということで、以上となります。ご清聴ありがとうございました。