
本記事は、10月29日〜30日にかけて開催した「CyberAgent Developer Conference 2024」において発表された「WINTICKETアプリで実現した高可用性と高速リリースを支えるエコシステム」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
木永 風児 (株式会社WinTicket モバイルアプリエンジニア)
2020年中途入社。ABEMAのAndroidアプリの開発を担当。2023年にWinTicketへ異動し、現在はアプリチームのマネージャーとして従事。
まずはじめに自己紹介をさせていただきます。木永風児と申します。株式会社WINTICKETでモバイルアプリのエンジニアを担当しながら、アプリチームのマネージャーも務めています。今回は、以下のアジェンダに沿ってお話しさせていただきます。

まず、WINTICKETの紹介を行い、その後、アプリチームとモバイルアプリプロダクトの現状について、昨年のCyberAgent Developer Conference 2023と現在の状況を比較しながら解説します。その後、Flutterリプレイス以降、どのようにして現在の状態に至ったのかについて、主要な取り組みを紹介し、最後に今後の展望として、これからのチームやプロダクトの方向性について説明させていただきます。
1. WINTICKETについて

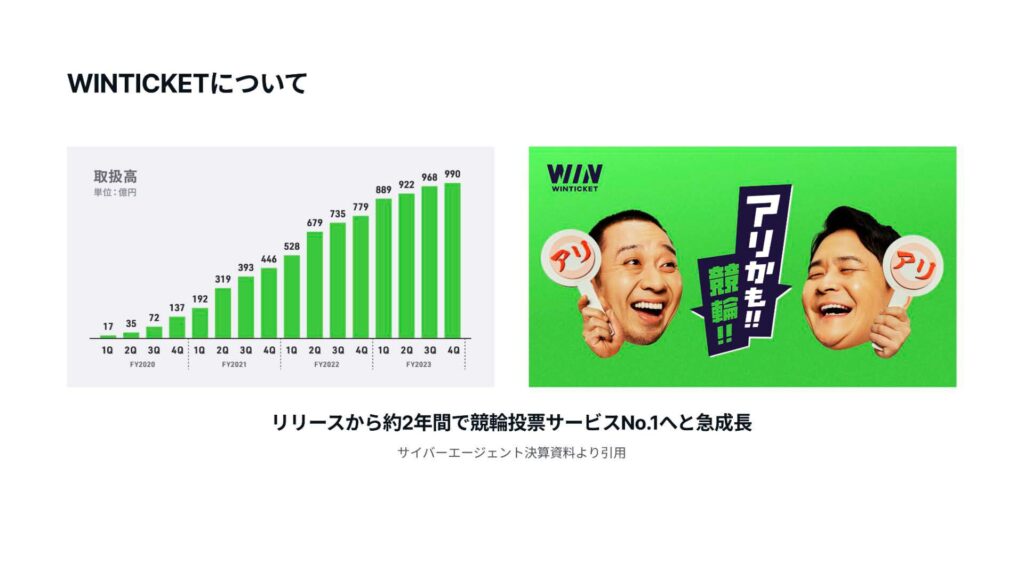
まずはWINTICKETについて説明いたします。WINTICKETは、競輪とオートレースに投票できるサービスです。WINTICKETでは、レース映像をライブで視聴したり、AI予想やEXデータといった豊富なデータを提供しています。また、ABEMA番組とも連動しており、ミッドナイト競輪などの番組をWINTICKETでも視聴することができます。
サイバーエージェントの決算資料からの引用ですが、WINTICKETはリリースから約2年間で競輪投票サービスNo.1へと急成長しています。また、芸能人などを起用したCMやマーケティングにも力を入れ、競輪業界を引っ張る存在となっているサービスです。
2. アプリチームとプロダクトの状況
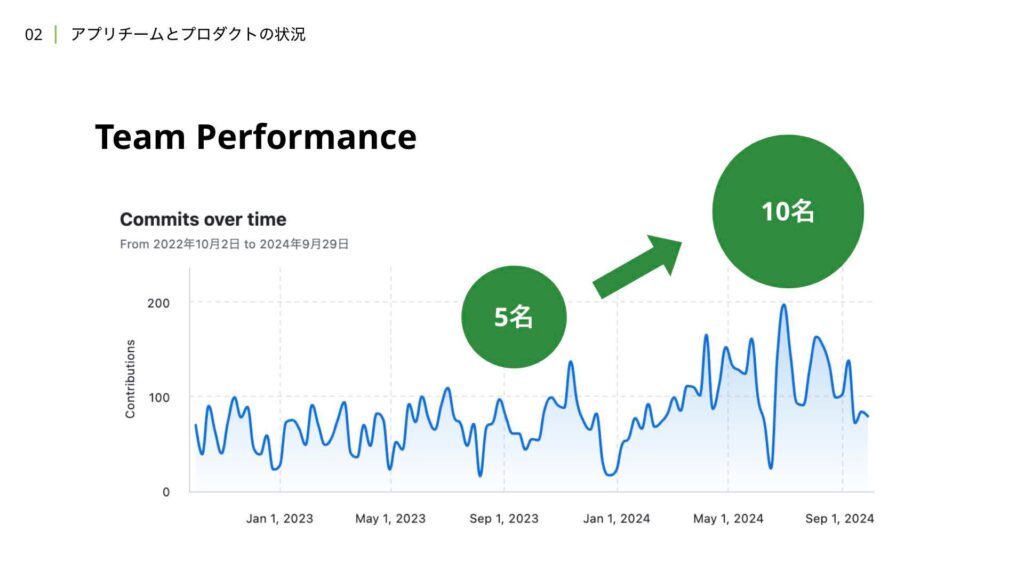
それでは、アプリチームとプロダクトの状況について解説していきます。現在、アプリチームは10名体制となっており、Flutterリプレイス後のメンバー数から2倍の規模に成長しています。GitHubのコミット数の推移を見てみると、2023年の後半から現在にかけて、ベースラインが引き上がっていることが確認できるかと思います。
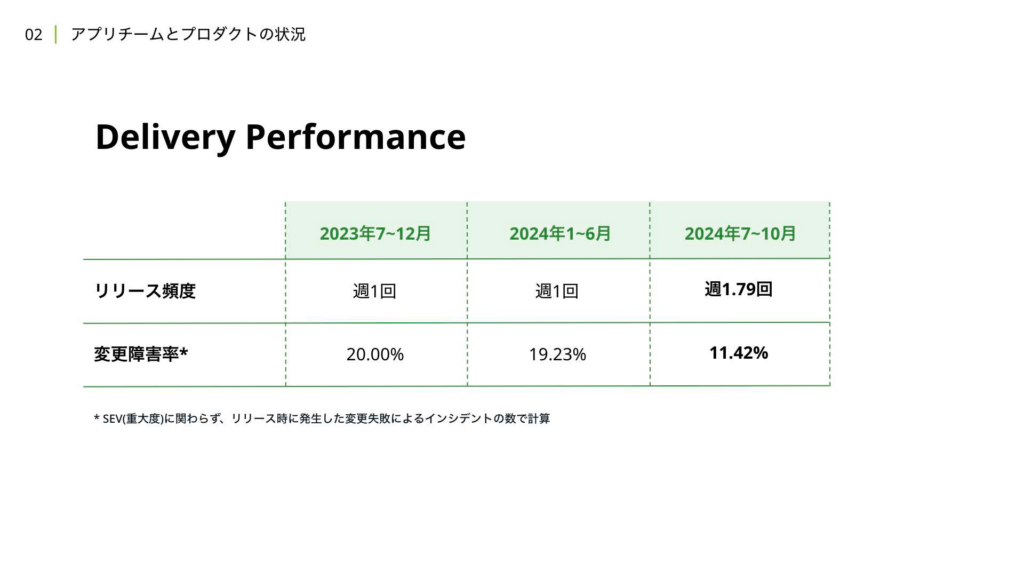
次に、デリバリーのパフォーマンスについて見ていきましょう。アプリチームでは、Flutterリプレイス当初から週1回のリリースを採用していましたが、2024年の8月頃からは、より高頻度なリリースの運用を検証しています。
変更障害率については、もともと20%に近い数値となっていましたが、現在の変更障害率は11.42%に低下しています。指標について説明しますと、例えば1ヶ月に4回の定常リリースがあった場合、そのうち1つのリリースで変更起因のインシデントが発生し、緊急リリースを行った場合、その月は20%の変更障害率だったことになります。仮に緊急リリースを行わない場合でも、変更時にインシデントが発生した場合は、変更障害としてカウントされます。
つまり、リリース頻度自体は増えているものの、平均して月に1度程度はモバイルアプリのリリース時にインシデントが発生している状況は変わりません。しかし、メンバーやプロダクトのスケール、リリースプロセスの変更を行いながらも、インシデントの総量は以前とあまり差がない状態を維持できているとも言えます。
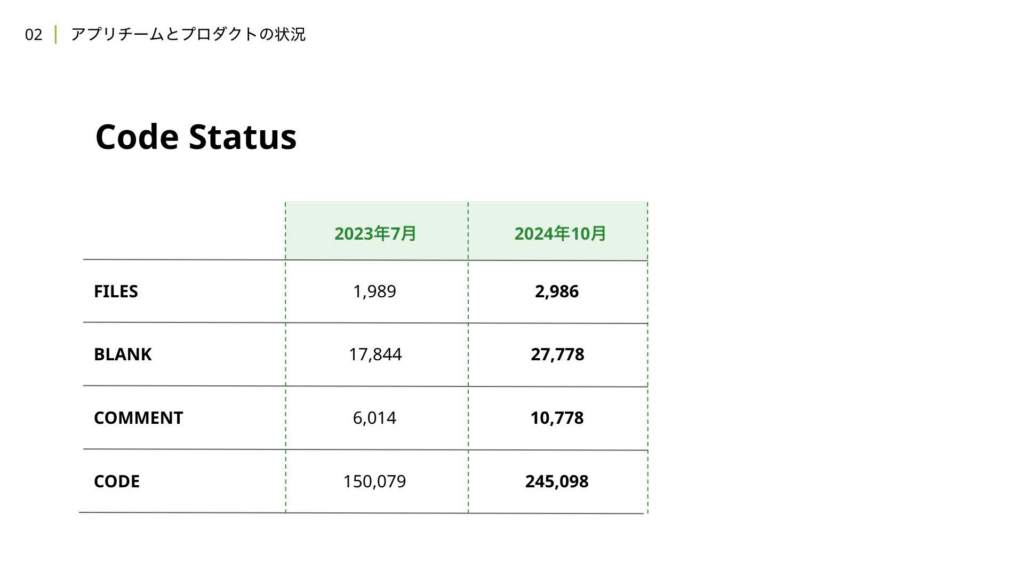
次に、コードの状況についても補足として触れます。2023年7月は、去年のCyberAgent Developer Conferenceが開催された時期で、Flutterリプレイス当時の成果について、弊社チームの仙石より発表がありました。その際の数字と比較したものがこちらになります。この1年余りの期間で、2倍とまではいかないものの、かなり多くの開発が行われてきたことがわかります。パッケージ数は、リアーキテクチャを行った関係でマルチパッケージ化が進んでいます。
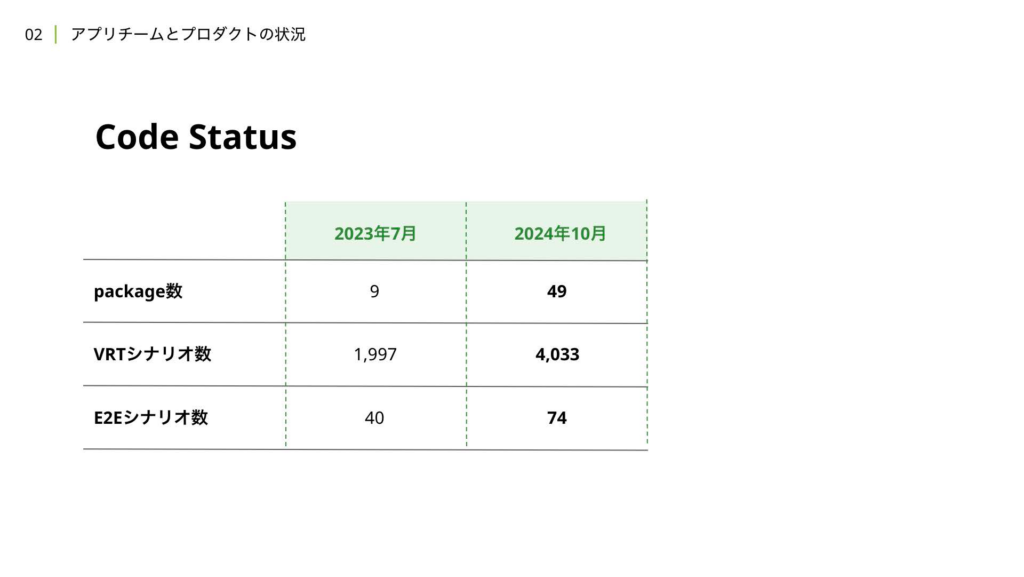
こちらについても、コードの依存関係の健全性や保守性を担保するための取り組みは、記事の後半で詳しく解説します。また、Visual Regression TestやE2Eのテストシナリオに関しても、2倍に近い拡大が進んでおり、プロダクトやコードのスケールに合わせてテストも等しく拡充されてきたことが伝わるかと思います。
3. Flutterリプレース後からの歩みと課題解決
それでは、これまでに紹介した様々な指標の成長をどのように実現したのかについて、具体的な取り組みを課題と合わせて解説していきたいと思います。

こちらの2つは、アプリチームで半期ごとに策定したチーム目標を端的に表したものになります。WINTICKETでは、半期ごとに開発組織の戦略やチーム目標を策定し、日々の機能開発や改善を定常的にこなしながら、その達成に向けた理想状態の追求を掛け合わせ、成長と成果の最大化を目指しています。
まずは2023年下半期の動きから解説します。当時は「高可用性」をチーム目標として掲げ、様々な取り組みを行っていきました。
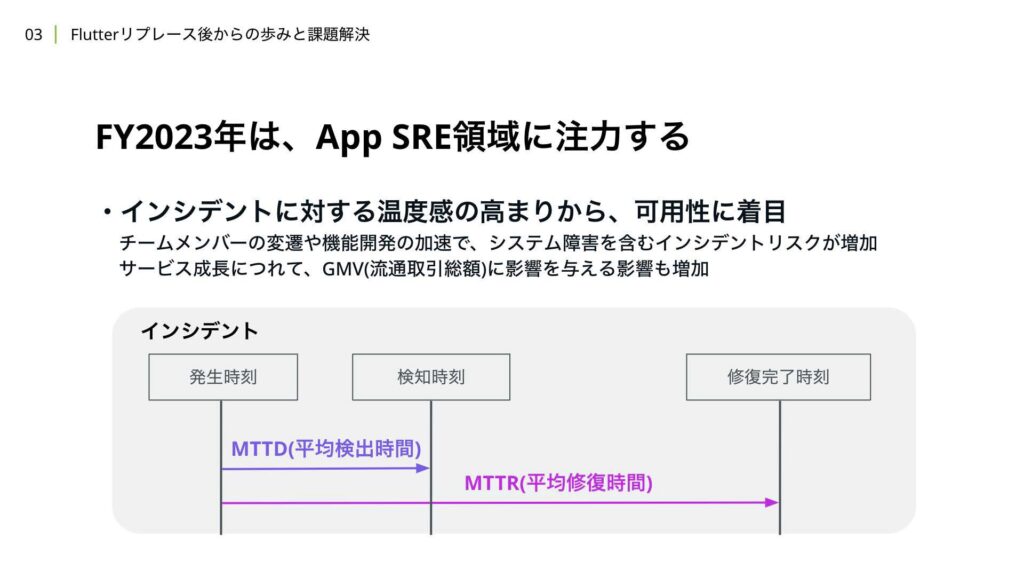
高可用性を支える2つの柱として、「システム障害の抑制」と「迅速な修正」が挙げられます。システム障害の抑制については、過去に発生した事象からその要因や対策についてチームで議論し、そもそもシステム障害が起きないような仕組みや状態を作ることに注力しました。

一方で、システム障害をゼロにすることは現実的に難しいため、実際に障害が発生した場合に備えて、迅速に修正を行える体制を整えました。例えば、システム障害の検知を即時に行える体制を作ったり、原因の特定や分析をしやすくするためのオブザーバビリティの担保、高速な修正を可能にする開発フローの構築に取り組みました。
WINTICKETにおける2023年は、FlutterへのリプレイスがiOSアプリでも完了し、モバイルアプリ開発が本格的なFlutter運用に切り替わった年でした。今後の事業成長に合わせた組織のスケールにも力を入れていたため、チームメンバーの変遷や機能開発数が多くなる時期でもありました。
その分、インシデントの発生リスクも増加しました。サービスが成長すればするほど、システム障害を含むインシデントがGMVに与える影響も大きくなります。この解決手段としてSREチームを新設し、平均検出時間やインシデント全体にかかる平均修復時間を短縮すること、またインシデントの発生回数を減らすことによって変更障害率を下げることを、SREチーム主導でチーム全体で取り組んでいくことにしました。
それでは、ここからは高可用性を実現するためにどのような実践を行ったのかについて紹介いたします。

まず、テスト戦略の見直しと自動テストの推進について解説します。変更障害率への対策として、過去に発生したインシデントを分析し、それらのインシデントを自動テストで防ぐことができないかという方向性でテスト戦略の見直しを検討しました。

この取り組みについては、昨年のサイバーエージェント Developer Conference 2023でも一部触れられていますので、ぜひ参考にしていただければと思います。

また、本セッションでは詳細な説明については時間の都合上触れることができませんが、Flutter会議2023にて、弊社チームメンバーの長田が発表した内容をぜひご覧いただければと思います。

簡単に内容に触れますが、WINTICKETではE2Eテストに注力し、自動テストを強化しました。ツールの選定を行った結果、Flutter標準のIntegration Testパッケージを使用し、Firebase Test Labを使って、実際のデバイスでのE2Eテストを定期的に実行しています。

Integration Testパッケージを使ったE2Eテストは、他のツールに比べて実装コストが高いという課題がありましたが、ロボットテストパターンを採用し、必要な労力を削減しました。また、シナリオについてもテストケースの優先度を定義する方法を導入し、WINTICKETにおける機能別のシナリオ作成の判断基準や優先度を標準化しました。
これにより、機能開発時に誰でもE2Eテストを書くかどうかの判断ができるようになり、あらかじめ決められたコーディングルールに従ってE2Eテストを記述できるようになりました。運用実績としては、優先度の高いシナリオが十分に実装されてきた段階で、サーバーサイドの変更により動作が変わったり、デグレが検出されたりする事例も確認され、テストが失敗するケースも発生しました。

今回は、E2Eテストを運用していく中で実際に課題になったことや、それに対して取った対策についても紹介できればと思います。
1つ目の課題として、エラーが発生した際には、Firebase Test Labの管理画面から確認できる実行動画を確認しながら原因を突き止める必要があるのですが、このトラブルシューティングが非常に手間となることが挙げられます。一見してエラーの内容がわかるものもあれば、難解なエラーもあり、手元で再度確認して再現を試みるといった対応をすることがよくありました。
また、シナリオが増えてくると、動画の時間が長くなり、対象位置へのシークが手間となったり、再生が止まるといった問題も発生しました。さらに、動画をダウンロードして再生しなければならないケースも増えてきました。
これに対する対策としては、シナリオ実行時に発生したエラーをハンドリングする際に、スタックトレースも一緒に取得してプリント処理を行うことで、Firebase Test Lab上のログデータからも確認できるようにしました。これにより、動画を確認せずに原因箇所を特定するための情報を簡単に取得できるようになりました。
2つ目の課題は、Firebase Test Lab上でテストシナリオの実行中に自動テストが失敗した場合、タイムアウトになるまで実行が終了しない点です。こちらは、Flutter起因やWINTICKETアプリのコール起因の可能性もありますが、例えば、タイムアウトを30分、失敗時には3回までリトライを行う設定をしている場合、1分でテストが失敗しても、通知が来るのは90分後という状況が発生していました。
これに対する対策として、1つ目と同様に、シナリオ実行時に発生したエクセプションをハンドリングする際、process.dartファイルが持つexit関数を失敗としてマークし、呼び出すようにしました。これにより、1分でテストが失敗した場合でも、リトライを含めて約3分程度で結果が通知されるようになり、コスト面でも良い影響を与えました。
最後に、今後の対応についてですが、Firebase Test Labに都度アクセスして原因を特定する作業をより効率化できる方法を検討しています。具体的には、GCS上にアップロードされたテストデータにアクセスし、原因箇所のログの抽出や動画ファイルのアクセスを円滑に行える方法を検討していきたいと考えています。
次に、SLI/SLOのモニタリングとアラートの導入について解説します。指標の補足として、SLIとはサービスレベルインジケーターの略で、定量的に測定可能なユーザーの満足度を表す指標です。そして、SLOはサービスレベルオブジェクティブの略で、SLIが達成すべき数値目標を示します。

こちらは、平均検出時間の改善策として、SLAやSLOを導入し、これまで検知できていなかったエラーに対する機械的な検知を可能にしようという取り組みです。これまでは、Sentryというエラートラッキングツールを使用し、クラッシュやカスタムログを仕込んだ箇所のアラートについては検知できていましたが、ユーザーからのお問い合わせやSNSによる投稿、ストアレビューといった場所から届くエラーについては対応が後手に回っている状況でした。
この対策についても、本セッションでは詳細な説明をする時間がないため、Flutter Ninjas Tokyo 2024にて、弊社チームメンバーの長田が登壇した際の内容をご覧いただければと思います。

内容を簡単に触れますが、まず初めに行ったことは、クリティカルユーザージャーニーの策定です。クリティカルユーザージャーニーとは、ユーザーが重要な目的を達成するために行う特定の動作のことを指します。
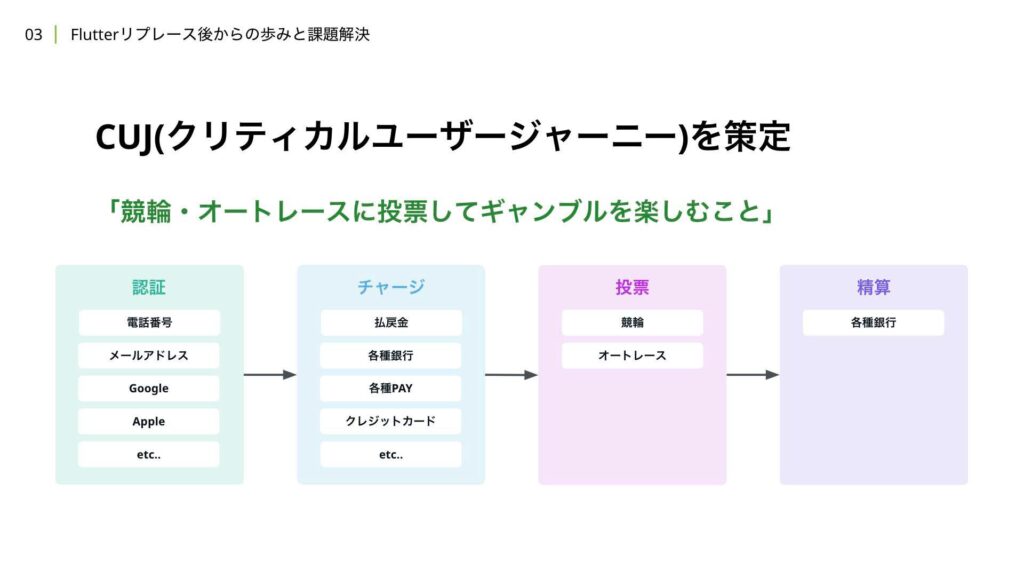
私たちはWINTICKETにおけるクリティカルユーザージャーニーを、「競輪やオートレースに投票してギャンブルを楽しむこと」と定義しました。このために必要な大きく4つの要素として、
- アカウント作成や本人確認などの認証
- 投票するために必要なポイントを得るチャージ
- 競輪やオートレースに投票する投票
- 最後に的中した払戻金を得る精算
を定義しています。
クリティカルユーザージャーニーを定義したら、その定義に含まれるユーザー体験に対してSLIを策定していくことを検討します。SLIは主にバックエンド側の事例としてAPIのリクエスト単位で計測するケースが多いですが、WINTICKETではモバイルアプリらしいSLIとして、特定の機能の利用を1トランザクションとして計測しています。例えば、認証フェーズとして、電話番号でログインする際のユーザー体験を考えてみましょう。

このユーザー体験は、電話番号でログインするボタンを押してから始まり、ホーム画面にて「ログインしました」のスナックバーUIが表示されるところまでがユーザー体験となります。この範囲を一つのトランザクションとしてSLIの計測対象としています。パターンを考えると、このユーザー体験は途中で失敗するケースもあります。

例えば、電話番号によるSMS認証で、6桁の番号を入力してエラーとなってしまったケースです。この場合、そのトランザクションはエラーとして計測します。また、途中で離脱するようなケースも考えられます。電話番号でログインするボタンを押して計測のトランザクションは開始しましたが、バックボタンで初めの画面に戻ってきてしまったケースです。この場合、そのトランザクションはキャンセルとして計測されます。

実装の箇所やエッジケースなどは省略して解説していますが、大まかな考え方としてはこのような計測方法になります。このようにして、クリティカルユーザージャーニーを構成する機能群に対して、SLIを策定し拡充していきました。加えて、それらのSLIとそれぞれに紐づくSLOを確認できるダッシュボードを作成し、運用しています。
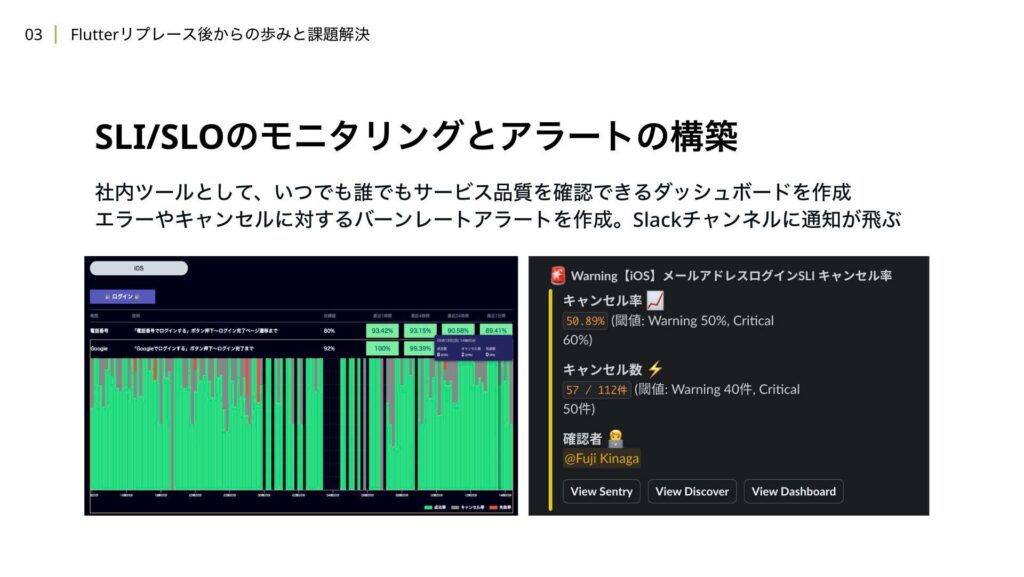
もともと社内にはKPIや進行中の機能開発の一覧を可視化した社内ツールが存在し、ビジネスメンバーを含む全社員がそのページにアクセスできる状態でした。SLI/SLOを組織全体で活用したいという想いから、社内ツールにSLI/SLOの可視化機能を追加しました。
実際にインシデントが発生した際、ビジネスメンバーはこのダッシュボードを確認し、全体への影響の有無や、iOS、Androidいずれかでのみ発生しているかといった状況を把握しています。さらに、SLOに対してエラーレートやキャンセルレートが急上昇した場合には、Slackチャンネルに通知が飛ぶ仕組みが導入されており、異常が即時に把握できるようになっています。
今回は、E2Eテストと同様にSLI/SLOを運用する中で実際に課題になったことや、それに対して取った対策についても紹介したいと思います。最初の課題として、偽陽性のエラー発火があります。偽陽性とは、実際にはエラーが発生していないにもかかわらず、エラーが発生したものとして扱われる状態を指します。

機能レベルのSLIとして、トランザクション単位を広く取ってしまうと、コールできていないユーザーの操作が発生した場合、計測に不整合が生じる可能性が高くなります。このため、実装レベルで予期しない状態が発生した場合には、カスタムログを発火させ、そのスタックトレースから問題を遡って調査できるようにしています。
また、SLI/SLOを導入したばかりの段階では、実際のキャンセルレートやエラーレートがまだ明確でないため、運用を開始し、実際のデータを確認しながら基準を調整していく必要があります。
次に、あまり利用されていない機能についてですが、これらの機能はエラーレートやキャンセルレートに変動を引き起こしやすいです。例えば、決済手段や本人確認書類の選択肢が多いため、使用されないものは必然的に母数が少なくなります。このような場合には、判定に利用する際の母数の加減値を決定し、運用しています。
最後に、今後対応したいこととして、SLIの計測が多くの箇所に埋め込まれているため、処理が追いづらく、プロダクトコードの可動性にも影響を与える点が挙げられます。現在はデバッグ機能を利用して計測結果を確認していますが、日々の開発で常にそのデバッグ機能を確認しながら実装を進めることは現実的ではありません。対策としては、ステートレスなウィジェットでの計測を禁止したり、よりイベント駆動型の処理にアーキテクチャを見直すことを検討しています。
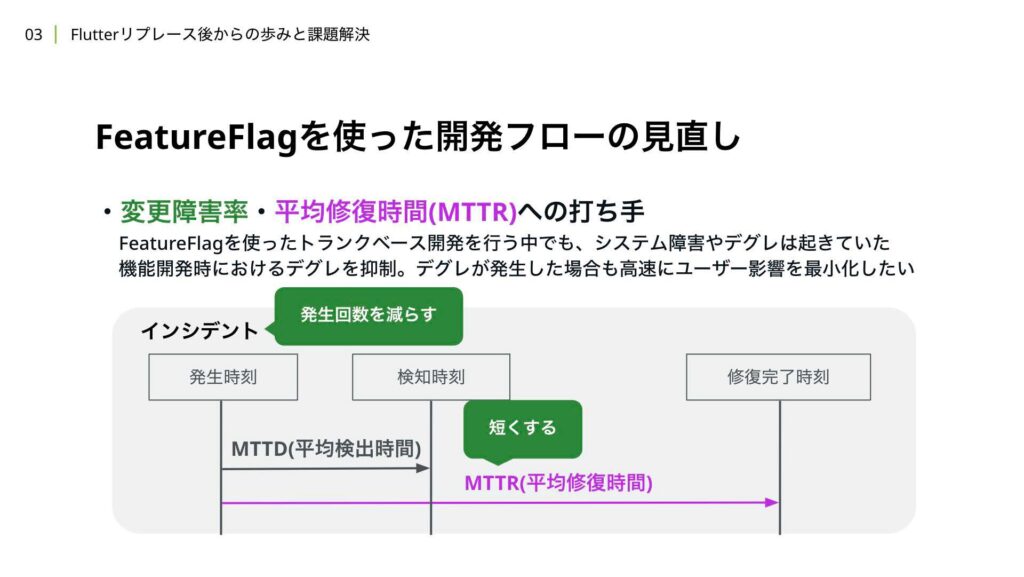
3つ目は、FeatureFlagを使った開発フローの見直しについてです。こちらでは、平均障害率と平均修復時間の2つの指標を用いて、開発フローの見直しを行いました。
WINTICKETでは、Flutterリプレイス当時からFeatureFlagを使ったトランクベース開発を行っています。FeatureFlagを効果的に活用することで、インシデント発生時には即時にロールバックが可能となり、既存機能への影響を最小限に抑えつつ開発を進めることが期待できます。
しかし、過去のインシデントを振り返ると、FeatureFlagの制御漏れや、既存機能へのデグレが一部のケースで発生してしまったことがありました。これらの問題に対する改善策については、本セッションでは触れませんが、CyberAgent Developer Conference 2024年のDay 2セッションにて、弊社チームメンバーの中鉢が登壇し、詳細を解説いたしますので、ぜひご覧ください。


高可用性に向けた取り組みをまとめます。
E2Eテストを活用し、重要なシナリオの動作保証をカバーしました。デバッグの難しさや実装コストは依然として課題ですが、日々改善を重ね、ブラッシュアップを進めています。この取り組みのメリットとして、デグレの早期検知が挙げられます。実際にシステム障害が発生する前に不具合に気づけた事例も多くあります。
次に、ユーザー体験を可視化するためにSLI/SLOを導入し、社内向けに可視化を行いました。こちらには、偽陽性の検出が難しいことや、実装コストが高いことなどの課題もありますが、システム障害の検出時間の短縮には大きく貢献しており、社内全体でサービスの品質状態を把握するツールとしても有効に活用されています。
最後に、FeatureFlagを取り巻く開発フローを見直し、最適化を進めました。実装コストが増加したものの、デグレの頻度は減少し、FeatureFlagを利用した改修については、現在もデグレは発生していない状態を維持できています。

次に、2024年上半期の動きについて解説いたします。高可用性を目指した取り組みの次は、「安全な週3リリース」をチーム目標として掲げ、様々な施策を進めていきました。
この半期で目指した主な3つの目標があります。まず、週に3回リリースを継続的に実現するためには、リリースのための機能開発や改善にかかる時間を効率化し、リリースできる差分がない状態をできるだけ作らないようにすることが理想です。これを達成するためには、実装時に発生する待ち時間やストレスを引き起こしているボトルネック箇所を洗い出し、改善していくことが必要です。
次に、リリースコストの削減です。これまで週1回行っていたリリース作業を、単純計算で週2回または3回行うことは多くのリソースを割くことになり、現実的ではありません。そのため、リリースにかかるコストを現在の3分の1に削減することを目指して改善を進めていく方針です。
最後に、開発の信頼性についてです。前期に目指していた高可用性の良い状態を、新しい取り組みを進める過程で低下させてしまっては元も子もありません。したがって、前期の状態を維持しつつ、開発生産性の観点から高可用性に繋がる部分でさらなる向上を目指していくことを考えました。

そもそも、安全な週3リリースを目指すことにした背景についても触れておきたいと思います。WINTICKETでは、日々の新機能や改善の開発は、社員からの提案形式で行われることが多く、その割合が大きいです。各領域の責任者が提案内容に点数をつけ、高い点数を得たものほど優先的に開発リソースが割り当てられ、開発チームが組成されます。
開発組織がスケールするにつれて、複数の開発チームが平行して動く場面が増え、一つのリリースで複数の機能や改善を同時に提供するケースも定常化してきました。開発カレンダーを見ても、週に何かしら1つ以上の機能や改善がリリースされる状況が加速することが予測されています。

1つ目の課題と関連していますが、新機能や改善をリリース単位で安全に提供するためには、Feature Flagを使うことで、その変更自体が一定の安全性を担保することができます。しかし、Feature Flagを適用できない基盤の改修作業などが同時にリリースに含まれる場合、基盤の改修部分で不具合が発生するリスクを考慮する必要があります。そのため、慎重にリリースできるよう、独立したリリースを行いたくなります。
カレンダーを見ていただくと、直近の7月から8月にかけての2ヶ月間を参考にした場合、重賞レースや既にリリース予定の機能開発、改善があるため、安全にリリースできる枠は1つしかないことが分かります。このような状況では、重賞レースや他の機能開発、改善のリリースと重ねてリスクを取るか、他のリリースと提供タイミングを調整していく必要があります。そのため、これまでの戦略としては、安全なリリース作業を実現するために、基盤の開始を逆算的に行ったり、プルリクエストをオープンな状態で残しておくなどのアプローチを取ってきました。
補足として、週3回リリースを行える状態を想定した場合、調整が不要となり、リリース枠を2つほど増やすことができる状態でした。

次に、3つ目の課題は、リリース前に行われるチーム内での変更作業に関する動作確認作業です。WINTICKETのアプリチームでは、リリース前にQCチームによる手動テストは実施せず、チーム内で動作確認を行い、ビジュアルリグレーションテストやE2Eテストなどの自動テストを使用して品質保証を行っています。しかし、この動作確認作業は、チームや機能量が増えるにつれて肥大化し、もともと1時間で項目を確認することになっていたものが、1時間内に終わらないケースが頻繁に発生するようになりました。
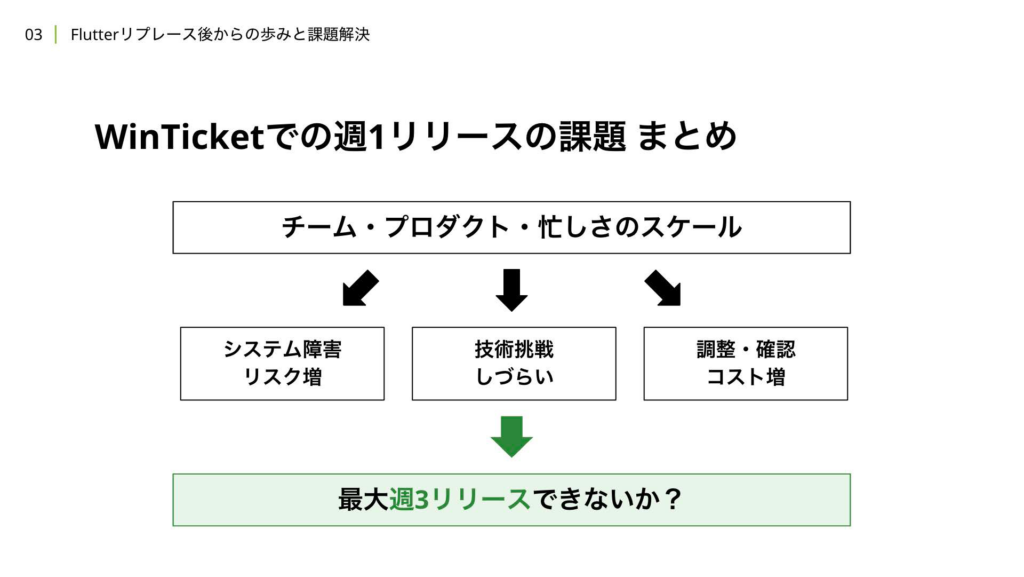
チームやプロダクト、繁忙期のシーズンなどで忙しさがスケールするにつれて、システム障害のリスクや技術調整の難しさ、リリースに関する調整や確認作業のコストが増加していました。そのため、最大で週に3回のリリースを行えるような開発フローを構築すれば、現状の課題を解決できるのではないかと考えました。

週に3回リリースを行うことになった場合、いくつかの恩恵が期待できます。まず、機能開発や改善、基盤改修などを等しくプロジェクトと解釈した場合、一つのプロジェクトに対して一つのリリースを原則とするルールを定めることができます。1リリースで大きな変更が1プロジェクトのみになることで、1回あたりのチーム内動作確認が効率化され、基盤改修を含められる枠の確保も現在よりも容易になります。
次に、リリーストレインの考え方をより本質的に捉えることができます。リリーストレインでは、リリース日をあらかじめ決めておき、リリース日までに開発が間に合わなかった機能は次のリリース日に先送りするという考え方です。この方式は、電車を例に説明されることが多いです。リリーストレインにはメリットも多いですが、デメリットもあります。Thoughtworks社のTechnology Radarにも記載がありますが、機能の完成を急ぐことで品質が低下する可能性があると指摘されています。
しかし、東京の山手線などをイメージしてみてください。次の電車が来る時間が短ければ短いほど、急いで電車に乗ろうという気持ちが薄れるということです。つまり、リリースコストを下げ、決められたリリース日の数自体を増やすことで、リリーストレインの副作用は解消できると考えています。
最後に、将来的にはコードプッシュ技術を活用することで、Hotfixリリースの方法を変え、週3回以上のリリースも実現可能になるのではないかと考えています。これらの技術の恩恵を早期に受けるためには、日々のリリースにかかるコストや品質保証にかかるコストを減らしていくことが重要だと考えています。

前置きが長くなりましたが、まずは安全な週3リリースを目指す上で取り組んだ開発効率を1.5倍にするための取り組みについて解説いたします。
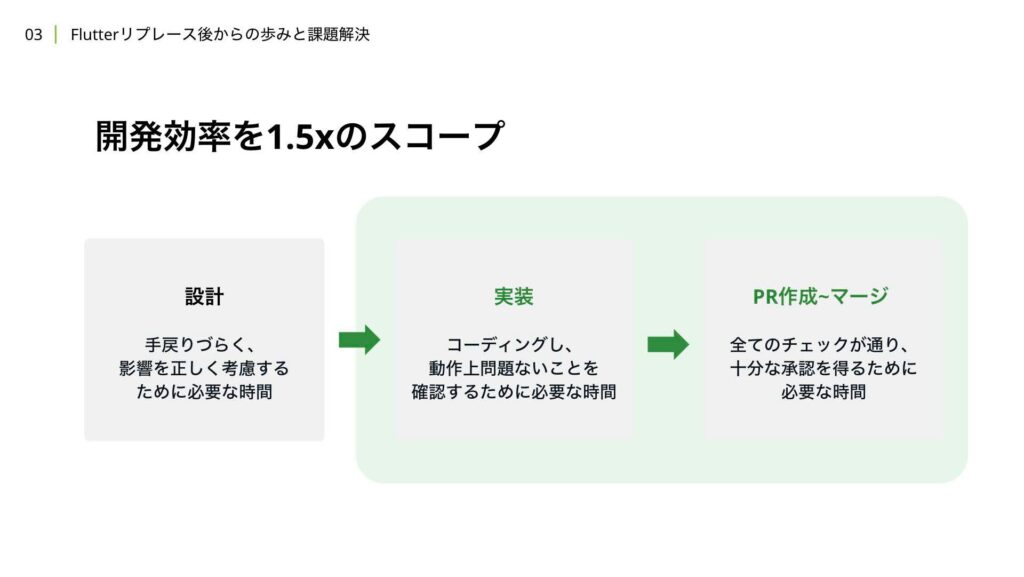
開発効率に関するスコープは、主に実装のステップとプルリクエストを作成してからマージするまでのステップを対象としています。設計においては効率よりも網羅性や妥当性が重要だと考えているため、この対応からは除いています。まず初めに行ったことは、チーム内で負債解消や生産性向上の観点から、開発効率を上げられそうな要素をリストアップすることでした。
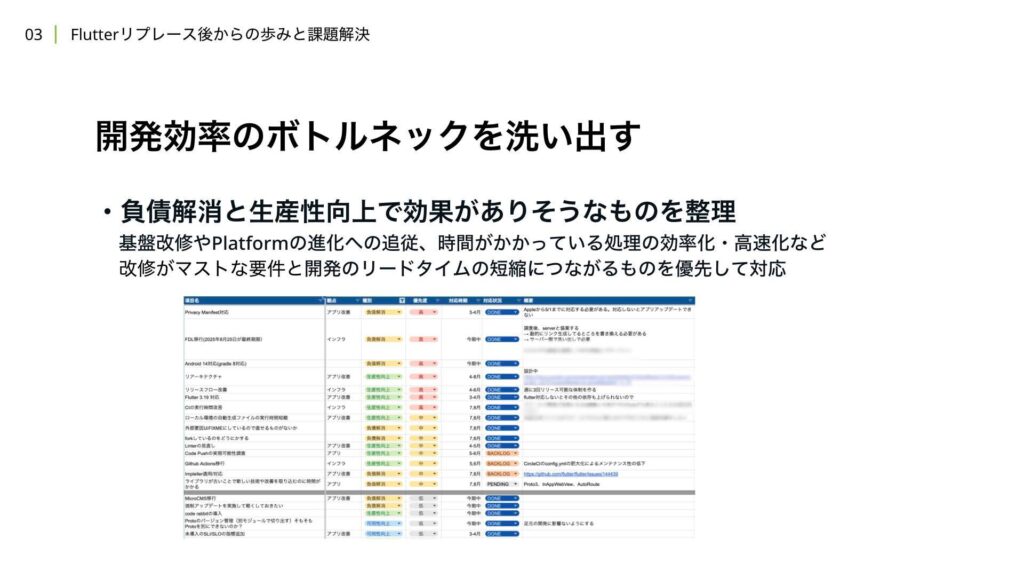
その後、インパクト度合いや対応の緊急度や重要度などに応じて、優先度付けを行い、対応するものを決定していきました。今回はその中から一部対応したものについて抜粋して紹介できればと思っています。

まずはLint Ruleについて説明します。これはチーム内で推奨されている書き方や過去の議論で決まった暗黙的なルールを覚えなくても十分に開発ができる状態を支援するものです。ID上で警告が表示されることで、その都度変更を行いながらルールを覚えていくことができ、プルリクエストレビューの際に指摘されるケースも減らすことができます。
この取り組みでは、VeryGoodVentures社が提供している「VeryGoogAnalysis」というパッケージを導入しました。一通りのルールを精査し、変更が発生する箇所の影響範囲を明確にした上で、チームメンバー全員で分担しながら適用を行いました。また、customlintパッケージを活用し、チーム内の暗黙的なルールやインシデント発生時の再発防止策、レイヤー構成に関するルールなどもID上で気づけるようにしています。
次に、CI/CDの待ち時間削減について解説します。

当時、Visual Regression Testにかかる時間が約35分を超えており、プルリクエストのマージが遅れてしまっている状態でした。この問題は、4端末を使用したVisual Regression Testを直列で実行していたため、カタログのシナリオが増えるほど、4端末分の実行時間が累積して長くなっていたことが原因です。また、後に紹介するマルチパッケージ化の影響により、Melosやbuild_runnerの処理がパッケージを分けるごとに処理時間が増加したり、セットアップに失敗する頻度が増加したりしていました。その結果、1つのプルリクエストがマージ可能な状態になるまでに、95パーセンタイルで63分の時間がかかっていました。
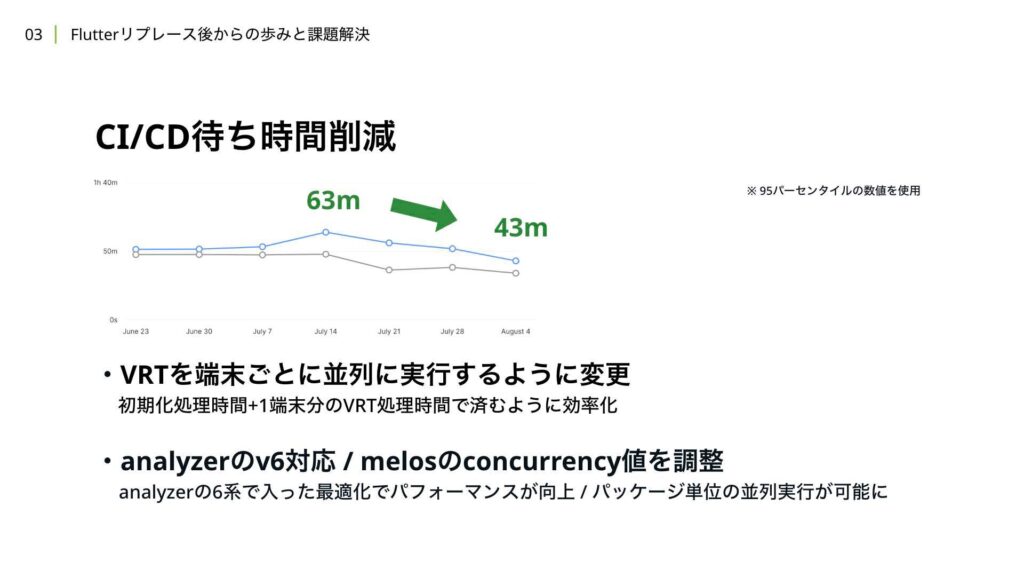
これらの課題に対しての対策として、まずVisual Regression Testでは、4端末を直列で動かしていた処理を端末ごとに並列で実行するように変更しました。これにより、1端末分の処理時間で済むようになり、効率化が実現されました。次に、Analyzerの対応です。当時、v5を使用していましたが、v6ではモノレポ構成におけるマルチパッケージの最適化が改善されました。この変更により、マルチパッケージ化でセットアップの時間が延びていた部分が改善されました。
さらに、Melosのコマンドで設定できるconcurrencyを設定することで、build_runnerによる自動生成がパッケージ単位で並列に行えるようになり、CDの時間にも改善が見られました。
これらの対応により、結果的に20分の短縮に成功しました。
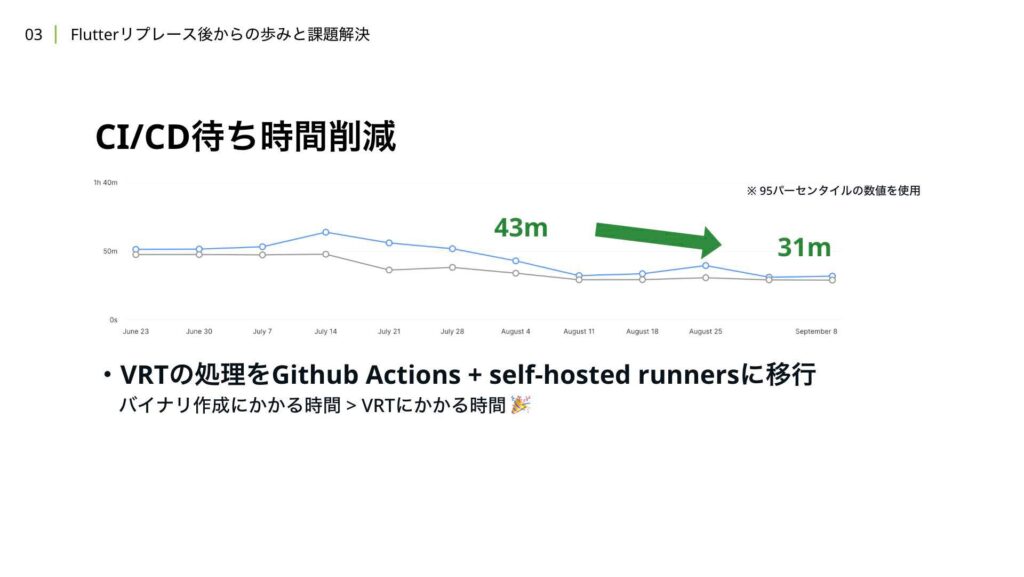
さらに、Visual Regression Testを行っていた処理を、self-hosted runnersを使ったGitHub Actionsに移行しました。これにより、セットアップ処理から並列で動かすことができるようになりました。実際、Visual Regression Testの完了までにかかる時間が約20分程度となり、バイナリ作成にかかる時間の方が長くなりました。結果として、プルリクエストがマージ可能な状態になるまでにかかる時間は、当初の51分から31分に短縮されました。
次に、リリースコストを3分の1にする取り組みについて解説します。現状のリリースコストを削減する際に、品質も低下させてしまっては本末転倒です。
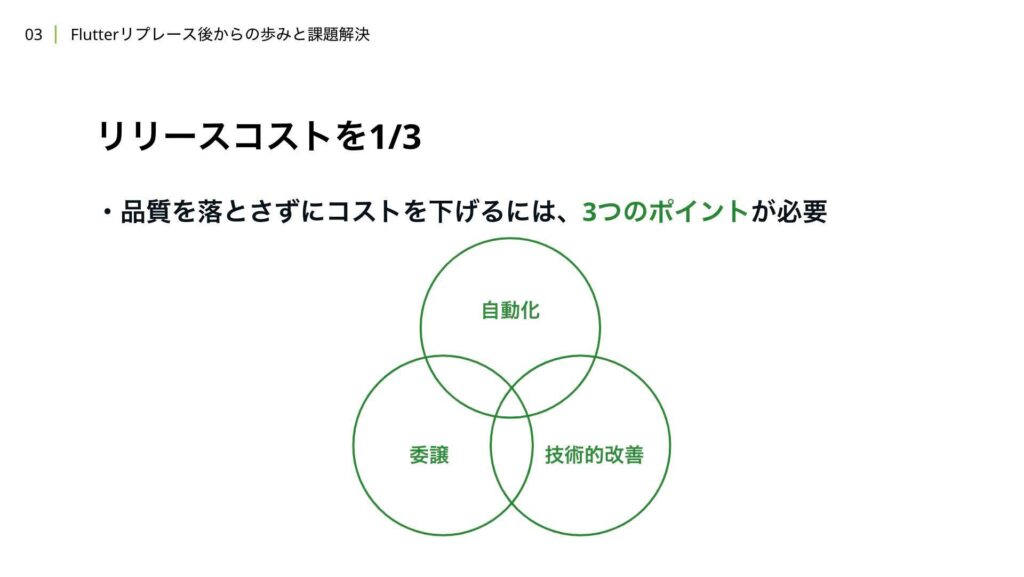
一方で、現状のコストを1/3にするというのは、かなり大きな改善であり、簡単には実現できません。そのため、改善には大きく3つのポイントが必要だと考えています。
1つ目は、手動で行っている作業を自動化することです。2つ目は、自分たちで行っている作業を他のリソースに委譲することです。そして、最後に、今までのフローを大きく変える技術的な改善を行うことです。それぞれの取り組みを、ステップに分けて解説していきたいと思います。
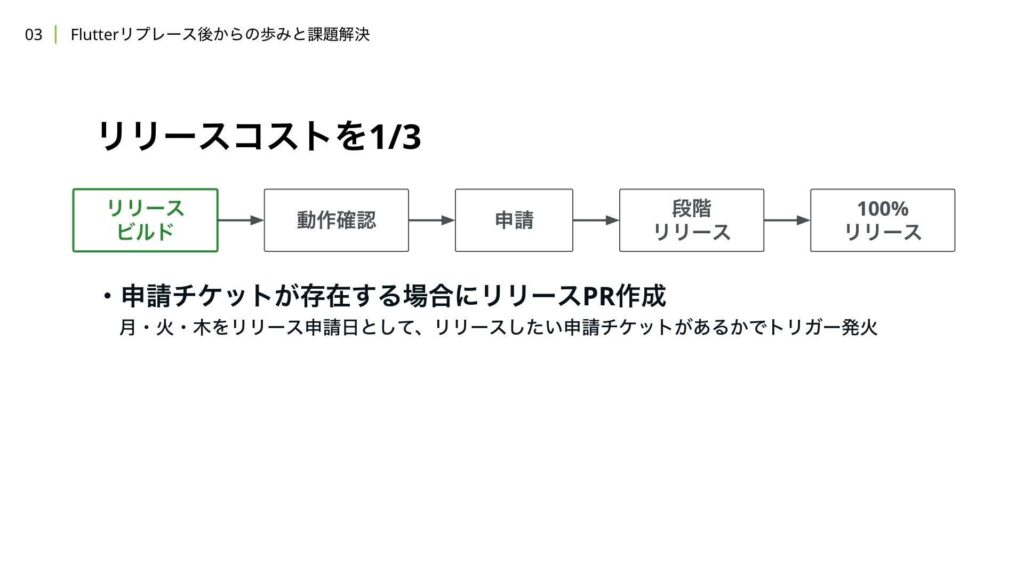
まずはリリースのビルドが行われる初回のステップについて説明します。週1リリースの場合、固定の曜日と時間にクーロンジョブが走り、そのタイミングでリリースプルリクエストが作成されていました。今回は、申請したい機能開発や大きな改善、基盤改修などが存在する場合、そのチケットの有無を月、火、木のタイミングで固定の曜日と時間に確認するようにしました。
これにより、リリースが不要な場合には、リリーストレインの考え方に基づいて、リリースを先送りすることができます。次に、動作確認のステップについて説明します。WINTICKETでは、機能開発や改修時に、その変更の影響単位で個別にQCテストを実施しています。
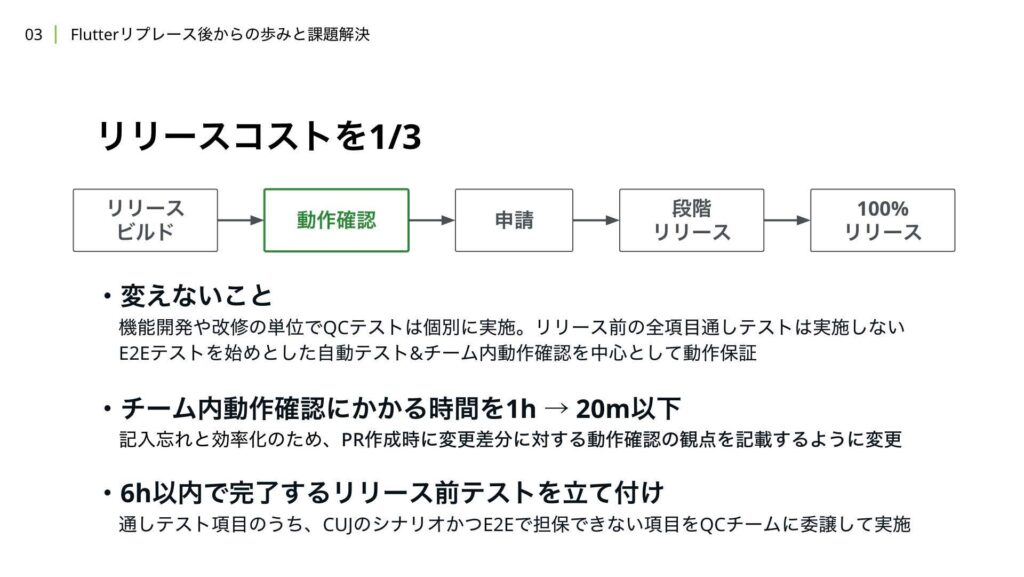
全項目の通しテストはリリース前には行っておらず、FlutterやOSのアップデート時、または変更の影響範囲が読めない改修など、スポットで依頼を行い、通しテストを実施しています。そのため、リリース時にはE2EテストやVisual Regression Testをはじめとした自動テストと、チーム内で行う動作確認を中心に動作保証を行い、リリースをしています。
ここでは、リリースコストを1/3に削減する場合でも方針は変えていませんが、プロセスの改善や新しい取り組みを新たに導入しています。1つ目の取り組みは、チーム内動作確認にかける時間を1時間から20分以下に短縮することです。もともとは変更差分が膨大になり、1時間でも確認が終わらないケースがありましたが、週に複数回リリースする前提で、1回あたりの動作確認で確認する差分を少なくすることができました。
また、プロセスの改善として、プロリクエスト作成時にチーム内動作確認に必要な確認項目を概要に記載してもらい、リリース前にそれらの確認項目を自動で集約し、チェックリストを作成するフローに変更しました。これにより、確認項目の記入漏れを防ぎ、チーム内動作確認の時間内で行う作業を効率化することができます。
2つ目の取り組みは、6時間以内で完了するリリース前テストを設定し、QCチームにリリース前に必ずそのテスト項目を確認してもらうことです。このテスト項目は、投資テストの項目のうち、クリティカルユーザージャーニーに関するシナリオかつE2Eテストで担保できない項目を厳選してピックアップしています。
リリース前テストの詳細については、後ほど別途解説を行います。また、申請のステップにおいては、申請にかかる作業のトイルを削減する対応を行いました。
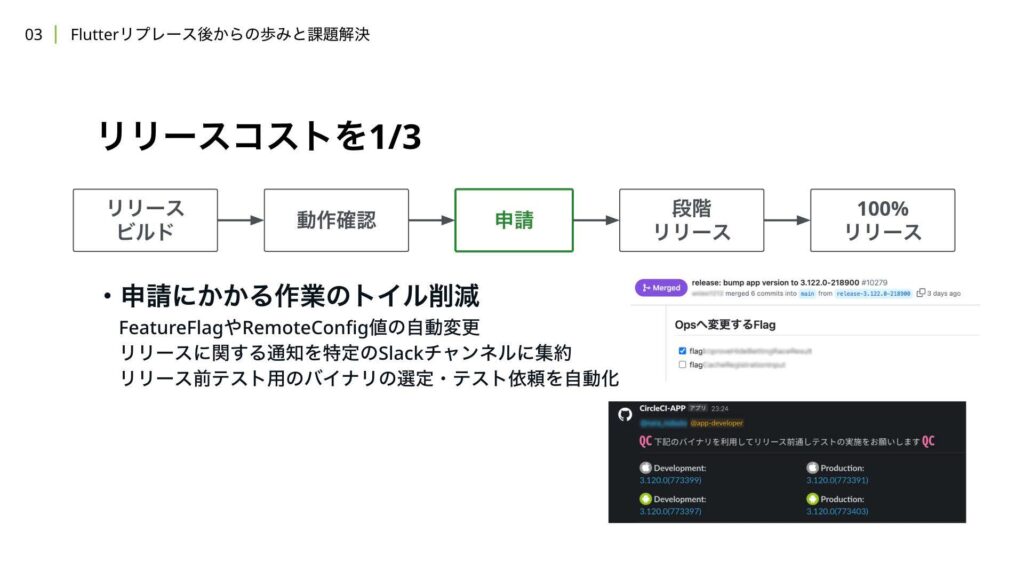
例えば、Feature FlagをWIPなフラグからOPSなフラグに変更したり、RemoteConfigの値を自動で変更できるようにする改善を行いました。また、リリースに関する通知のコストを削減したり、先ほど解説したリリース前テストに必要なバイナリを選定し、Slackチャンネルに自動で投稿する機能を作成したりしています。
最後に、リリース後のステップについてです。2023年の下半期に導入したSLI/SLOやSentryのデータを活用することで、リリースの状況を判断するための情報を集約し、リリースの安定性をチェックする仕組みを運用しています。
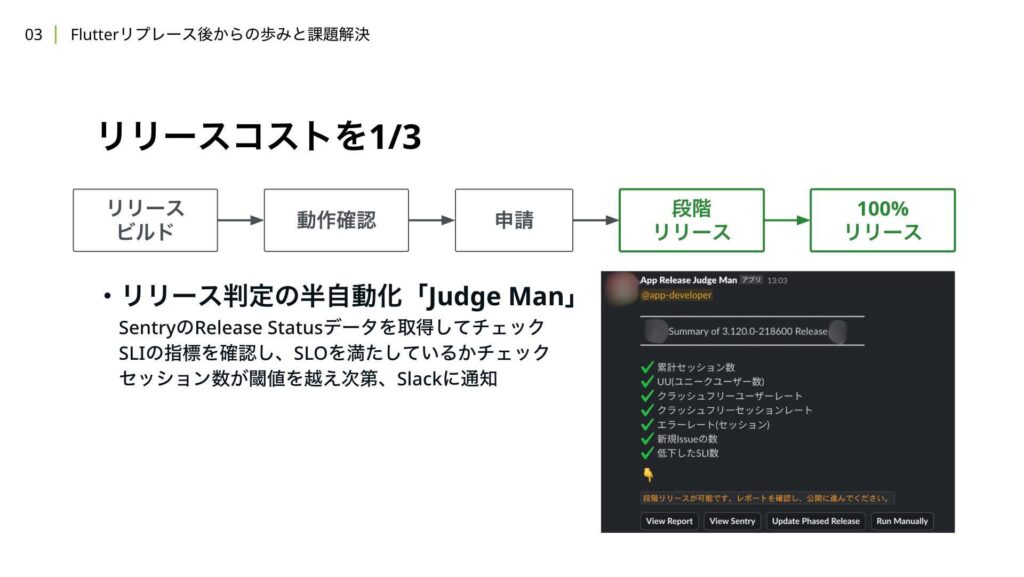
定期的にSentryやSLI/SLOの状態を確認し、ユーザーのセッション数が閾値を超えたタイミングでチェックを行うことで、ほぼ最短でリリース判定を行うことができる仕組みになっています。
次に、リリース前テストについて詳細に解説していきます。

リリース前テストとは、全機能の通しテストのうち、特に重要な箇所に絞った手動テストを指します。基本的には、6時間以内で完了することを目指しています。なぜ6時間かというと、リリース申請日の午前中にビルド作成や自動テストを走らせ、チーム内での動作確認を行った場合、午後からリリース前テストを開始し、その日中にテストが完了し、申請作業まで行える時間を確保するためには、約6時間が必要だからです。
過去の手動テストにかかった時間を参考にし、1人当たりの確認可能な項目の上限数を算出し、それに基づいてリリース前テストの項目を決定しています。リリース前テストの項目を選定するにあたって、本来自動テストで担保できるべき項目が担保されていない場合、リリース前テストの肥大化や、デグレやシステム障害のきっかけになる可能性があります。
そのため、既存の通しテスト項目を見直し、自動テストで担保すべき項目と担保が難しいものを言語化し、カバレッジの拡充を推進しています。

その項目はこのようになっています。例えば、UIに関しての表示・非表示の条件の正しさや遷移先の正しさ、デザインの正しさなどは、Unit TestやE2Eテスト、Visual Regression Testでカバーできる範囲です。そのため、全機能の通しテストの中でも、これらの項目は実施を割愛することが検討可能な項目となります。
E2Eテストを実施すべきかどうかは、シナリオの優先度によりますが、Unit TestやVisual Regression Testを使った自動テストでは、積極的に担保すべきだと考えています。
一方で、キャンペーンやサーバーから返却される動的に変化するデータや、遷移以外のウィジェットの動的な変化、操作に対する応答の正しさは、自動テストで完全に担保するのが難しい領域です。

たとえダミーデータを渡して、それが正常にUIまで反映されていることを確認する自動テストが書けたとしても、実際の入稿物が正しくない場合や、サーバー側から返却されるデータの整合性まではテストすることができません。また、自動テストをそもそも書くことができないケースも一定数存在します。例えば、物理デバイスのデータやNative Platformにアクセスすることで得られるレスポンスは、自動テストでその応答が正しいかどうかを確認することが難しいと考えられます。

また、時間やデバイス、ユーザー、ドメインの特性が組み合わさって作られる状態は再現が難しく、安定した自動テストを記述することが困難です。さらに、過去にインシデントが発生して温度感が上がっている箇所や、脆弱性やセキュリティに関する部分、バージョンアップ時の動作も含まれます。
バージョンアップに関しては、マイグレーション処理などは自動テストで担保が可能なケースもありますが、自動テストではテストの実行単位で前回のテストの状態が初期化されてしまうため、アプリケーションの動作自体は手動テストで確認する必要があります。
次に、開発の信頼性について解説します。まずはこれまでの開発体制について説明したいと思います。当時、5名体制だった頃のイメージ図がこちらになります。
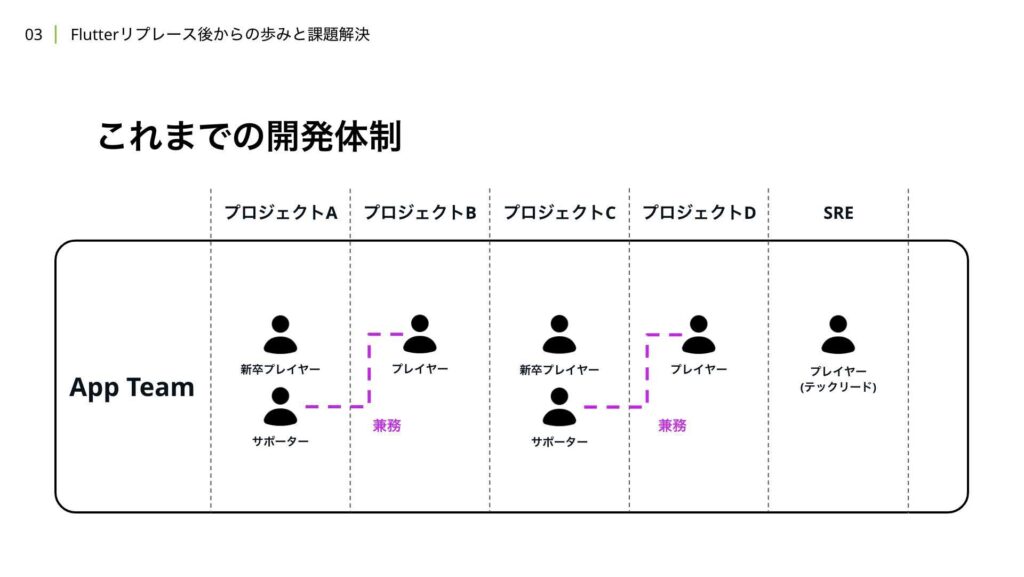
新卒のプレーヤーをサポートしながら、別のプロジェクトを担当するプレーヤーがいて、公開を目指すSREチームの専任メンバーが1名います。当時はプルリクエストに2Approve制を採用しており、プロジェクトごとに空いているメンバーをアサインする構成でした。
この開発体制では、複数のプロジェクトが平行で進行する繁忙期において、サポート役の負担が大きくなることが課題として挙げられます。異なるプロジェクトを横断して担当する場合、ミーティングへの参加やキャッチアップにかかるコストが増加し、作業時間の確保が難しくなることがしばしばありました。
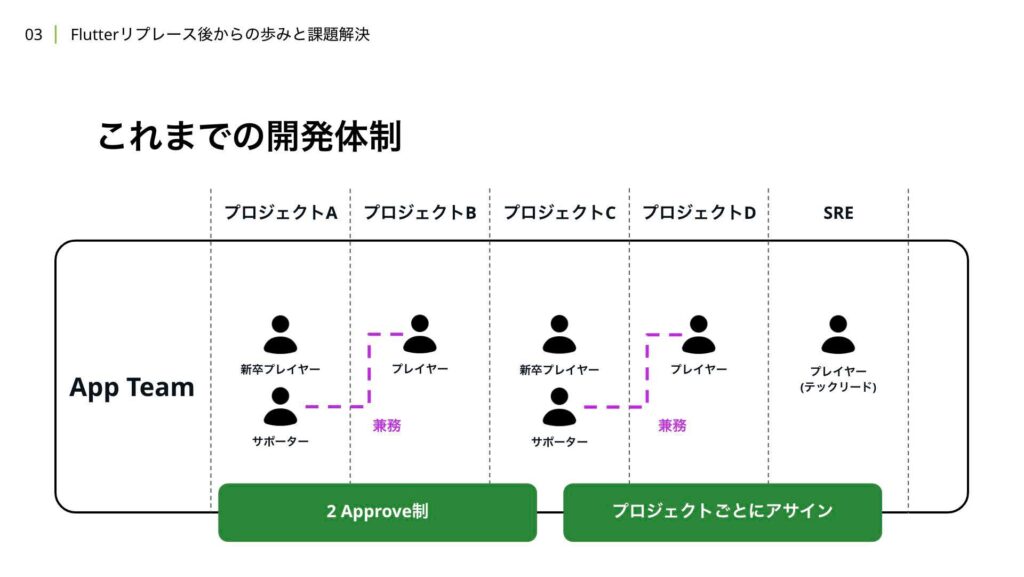
次に、プロジェクトごとにアサインしていることで、プロジェクト単位のアプリチームにおいて知見が浸透しづらい点が挙げられます。中長期的には、同じメンバーが近い系統のプロジェクトをやり続けることは、属人化の観点でもデメリットとなる可能性がありますが、短期的にはメリットもあります。プロジェクトが完了すると、開発チームも解散するため、そこで得たナレッジを次のプロジェクトに活かすことが暗黙的に期待される場合がありますが、実際にはそれが難しい傾向がありました。
最後に、プロジェクトをまたぐ場合、キャッチアップにかかるコストが発生し、その結果、レビューのコストが高くなる点が挙げられます。これにより、テックリードや手が早いメンバーにレビュー負荷が集中し、チームのスケールにとって障壁となっていました。
スケールするチームを目指すためには、これらの課題に対して対策を講じて実行していく必要があります。チームのスケールを考える上で参考にしたのは、このような概念や考え方です。

WINTICKETでは、高可用性を目指すにあたり、クリティカルユーザージャーニーを策定しました。そのため、コアとなる体験や機能は明確に把握できており、これらのコア体験ほど複雑になりやすく、改修も頻繁に発生し、インシデントに対する温度感も高まります。
これらのコア体験を最大化するためには、適切なチーム体制を構築する必要があります。コア体験に合わせたチーム体制を整えることができれば、システムもそれに合わせた構造を目指しやすくなります。この考え方は、コンウェイの法則やチームトポロジーの原則を参考にしています。さらに、すべての機能や仕様を理解することが規模的に難しく、時間もかかるため、開発者側に複数のドメインにおけるエキスパートを配置することができれば、より短期間でそのドメインに対する機能開発や改善を迅速にリードできると考えました。
アプリチームでは、過去のプロジェクトや事業の状況、既存のコードベースなどを参考にして、4つのドメイン領域と2つの領域を見るPlatformチームを定義しました。
4つのドメインとしては、
- ユーザーやマーケティングに関するもの
- 投票やレースに関するもの
- チャージや精算、ポイントといった決済に関するもの
- 動画や配信に関するもの
です。
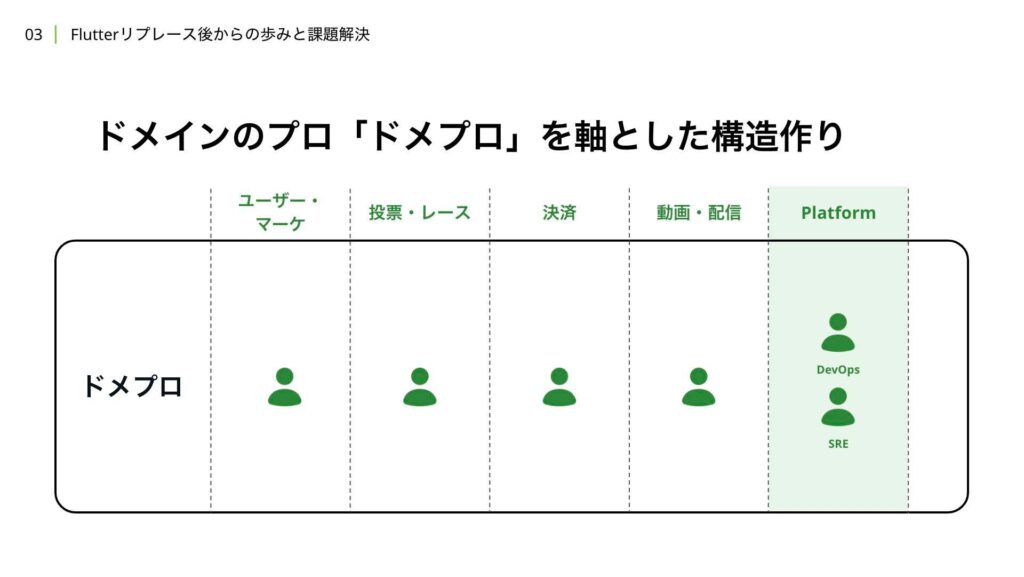
また、Platformチームとしては、SREやDevOpsに関する領域で開発を推進するため、合計で6つの領域を担当するメンバーを配置しています。これにより、プラットフォーム全体の安定性や効率を向上させることを目指しています。
4つのドメインに関しては、それぞれ担当するメンバーを「ドメプロ」として分かりやすく呼び、運用を開始しました。本記事でも、以降は「ドメプロ」として記載や説明を行っていきます。この新しい構造に加えて、従来の2Approve制から3Approve制に変更し、プロジェクトに対するメンバーのアサイン方法も改善しました。具体的には、ドメプロのメンバーに加えて、必要に応じて他のメンバーをプラスアルファでアサインする形に変更しました。
さらに、ドメプロという枠組みに責務を集中させるため、アーキテクチャの面でも改善を行い、より効率的な開発体制を築いていきました。

もともとは、モデルクラスはAppパッケージ内のディレクトリにまとめられていましたが、モデルのグループごとにパッケージを分け、依存関係をより明確にするように改善しました。それぞれのパッケージには、ドメプロごとに設定したGitHubのチームをコードオーナーとして割り当て、各グループに含まれているメンバーのレビューを必ず通すようにしています。
このように、モデルの構造をマルチパッケージ化して可視化できたことにより、ドメプロとして定義した4つの領域がより網羅的であることを確認することができました。また、モデルパッケージが循環参照を起こしていないかについては、melosのコマンドを使用して確認できるため、CI上で自動的に検知できるようになっています。
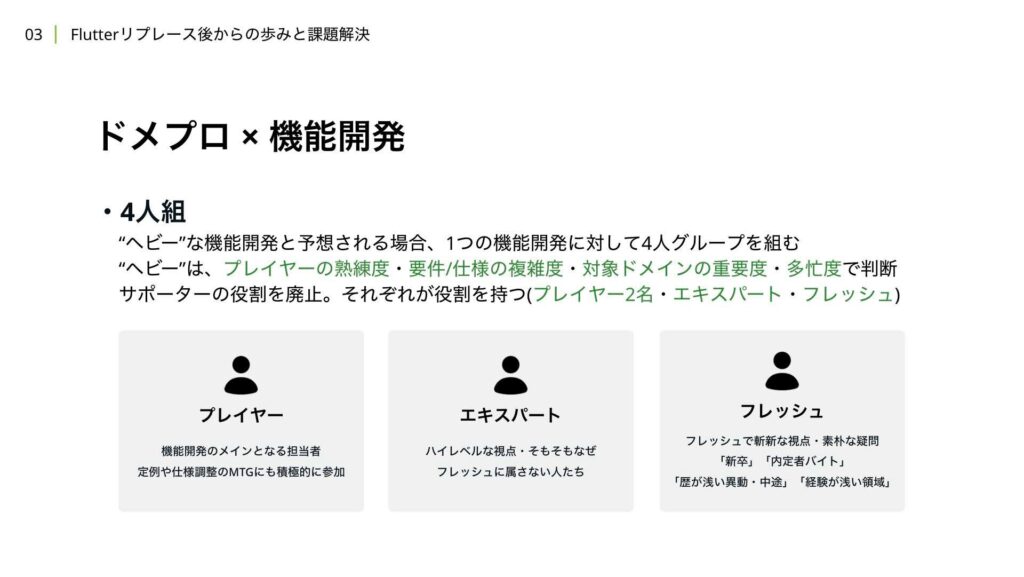
機能開発において、3Approve制を採用した直後、最後の1Approveがなかなか集まらず、マージまでの時間が延びてしまう事象が頻発しました。これに対して、機能開発の進行をスムーズにするために、4人組を作り、そのグループ内で3Approve制を担保することを、機能開発の開始時に合意形成として定義しました。
4人組のメンバーは、プレイヤー、エキスパート、フレッシュの3つの役割に分けられます。運用開始当初はサポーターという役割も存在していましたが、この4人組に関する運用と検証・振り返りを行った結果、ヘビーな機能開発ほどインシデントが発生しやすく、スケジュールが遅延しやすいことがわかりました。また、サポーターの役割は機能が難しく、3Approveを集めるスピードが遅いという問題も浮き彫りになりました。そのため、サポーターという役割を廃止し、プレイヤーが2名いる体制に変更しました。
現在は、この4人組の運用は、ヘビーな機能開発の場合にのみ適用しています。ヘビーかどうかは、プレイヤーとなるメンバーの熟練度や要件、仕様の複雑度、変更が発生するドメインや画面、機能の重要度、さらには組織の忙しさなどを総合的に判断しています。

次に「ドメプラ」について解説します。ドメプラは、ドメプロの概念とペアで覚えやすいように命名されていますが、実際には実装を開始する際に行う設計レビューのために作成するDesignDocのようなものです。このドメプラはプルリクエスト形式でレビューを行い、さまざまな観点での考慮事項を記載することを求めています。例えば、2023年の下半期には、自動テストのシナリオ作成可否やFeature Flagの導入方針、SLI/SLOへの影響の確認などを、実装前のタイミングで検討できるような運用を行いました。
これまでの取り組みを反映したイメージ図は、こちらのようになっています。
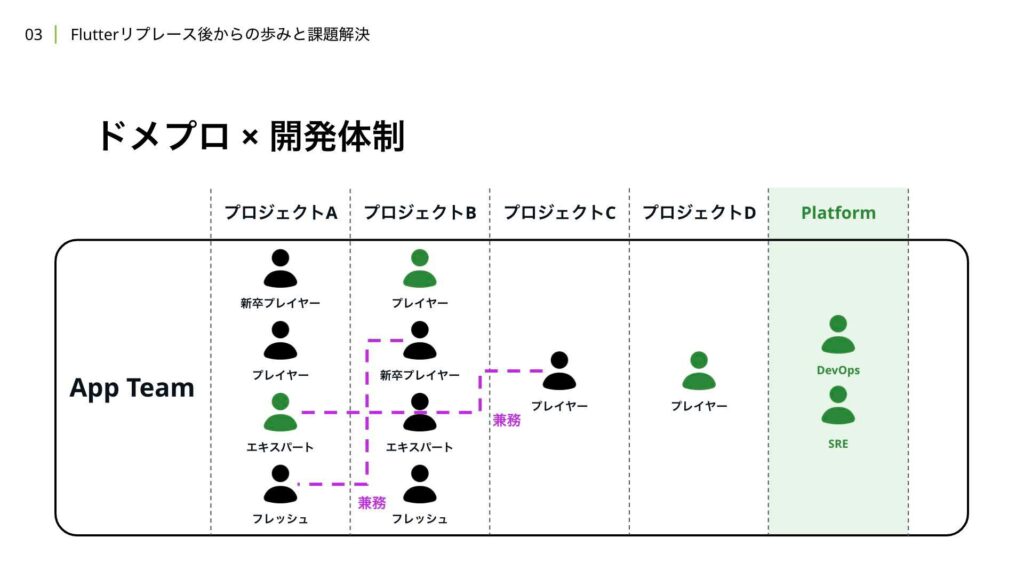
それぞれの変更点について詳しく解説していきます。まず、Platformチームを新設したことで、DevOpsやSRE領域に対してさらに大胆な改修を機能開発と並行しながら進められるようになりました。開発効率やリリースプロセスの改善、ドメプロの推進、さらにはマルチパッケージ化などは、Platformチーム主導でチーム全体を巻き込みながら進めています。
現在は3Approve制を採用しながら、4人組の運用を行っていますが、ヘビーでない開発については、担当者がドメプロかどうかに関わらず開発を推進しています。ドメプラをレビューするフェーズでかなりリスクヘッジができるため、開発体制に柔軟性を持たせています。
また、繁忙期における兼務の大変さにも改善を行いました。サポーターの役割を廃止し、プレイヤーとして複数のプロジェクトを担当することがないようにしました。さらに、新卒プレイヤーを見るトレーナーは、なるべく同一プロジェクトに配置されるようにアサインを工夫しています。
最後に、ヘビーなプロジェクトにおいては、4人組を組成し、なるべくコンテキストを共有したメンバー間で3Approveを担保できるような構造を目指しています。

次に、リアーキテクチャについて解説します。時間の都合上、進行中の話でもあるため、簡単に紹介しますが、主に目指している状態は2つです。1つ目は、新機能を独立して開発できる状態であり、2つ目は、誰が書いても迷わないことが担保された状態です。まず、新機能を独立して開発できる状態についてですが、モデルパッケージで行ったように、依存外のファイルにアクセスできない状態を作ることを目指しています。また、特定の機能を独立してビルドできる状態を作るために、データの注入方法や特定の機能へのアクセス方法を工夫したいと考えています。
現在、Analyzerの機能にパフォーマンス上の課題があり、パッケージを分けるほどビルド時間が増加したり、melos bootstrapのエラー頻度が増加したりするため、細かいパッケージ化は延期しています。しかし、Analyzerをv6にアップグレードすることで、マルチパッケージ化のパフォーマンス問題はある程度解消されました。これにより、モデルのパッケージ化は進めることができました。Dart 3.5以降の改善も予定されており、さらなるアナウンスを追いかけていくつもりです。
次に、誰が書いても迷わない状態についてですが、現状はLintRuleの取り組みにより、認知負荷を全体的に下げることができています。ただし、ボイラープレートの記述をしなくても済む状態を常に追い求めることが必要だと考えています。こちらについても引き続き対応していきます。
最後に、安全な週3リリースに向けた取り組みのまとめです。
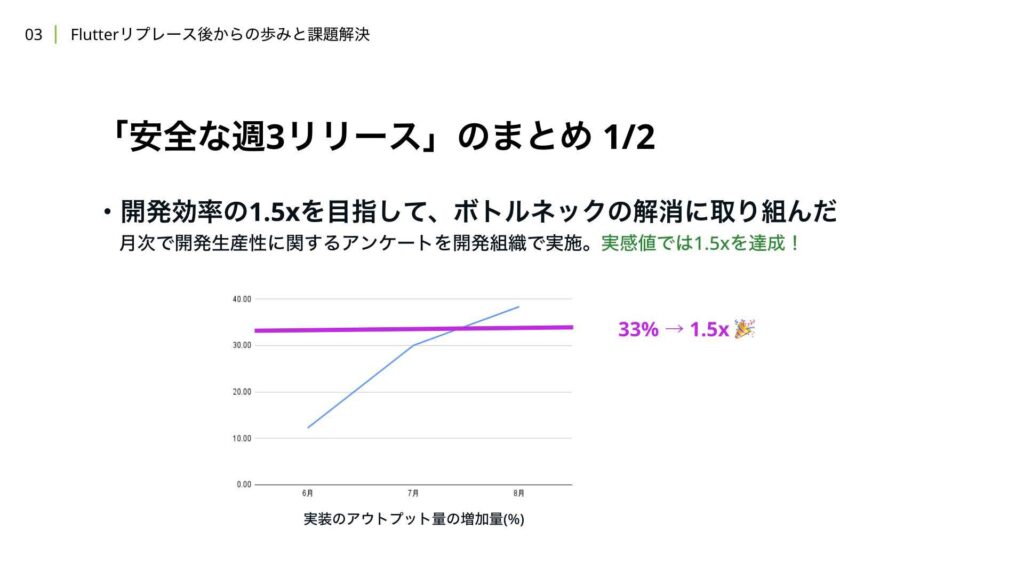
負債解消や生産性向上に向けたボトルネック解消の改修を通じて、開発効率を1.5倍にすることを目指しました。この期間中、開発組織全体で月次のアンケートを実施し、開発生産性に関するフィードバックを収集していました。アプリチームからの回答を見てみると、実際に1.5倍以上の改善を実感しているという回答を得ることができました。

また、リリースにかかるコストを3分の1に減らし、1週間に最大3回のリリースが行える状態を目指しました。祝日やリリース物がない日もあったため、リリース回数の平均としては週3回を下回る結果となってしまいましたが、リリースプロセスの改善が継続的に定着していることが確認できました。
最後に、開発体制については、ドメプロの取り組みを軸に、スケーラビリティと信頼性を底上げするための施策を進めました。システム障害数は現状、過去1年間の推移を見ても少ない状態で推移しています。
結果として、週3回のリリース実現には至っていませんが、安全な週3回リリースの実現に大きく近づけたと考えています。
4. 今後の展望
それでは、一連の取り組みについて紹介した後、今後の展望について解説いたします。WINTICKETのアプリチームでは、半期ごとのチーム目標に加え、1年から3年スパンでの中長期的な目標を掲げています。その理想の状態として、私たちは「日本一技術で事業価値を創出するアプリチーム」を目指しています。

事業ファーストの組織文化の中で技術的なチャレンジを行う際にも、最優先で事業への貢献を意識し、アプローチや手段を選定しています。事業は、組織が直面している課題に対して最適な解決策を実践することで、最も近い形でベストプラクティスに到達できると考えています。
その取り組みの一つとして、発表や登壇の機会を積極的に活用し、チームの成長と成果の最大化を目指しています。事業の課題に高いレベルで取り組み、その成果をアウトプットすることによって、その過程や実際のアウトプットに対してフィードバックを得ることができ、次の改善につなげることができます。
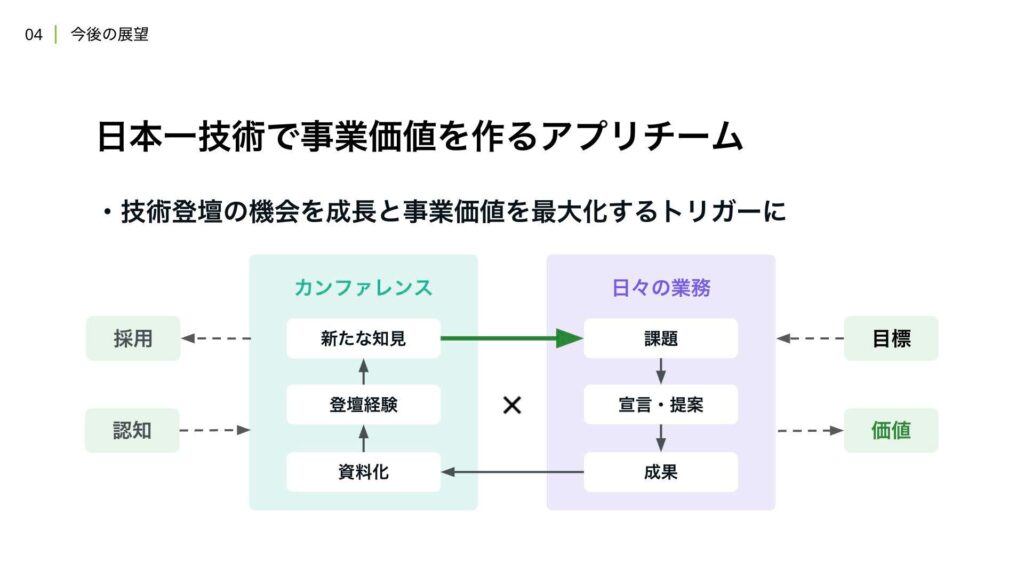
それらのフィードバックは、さらなる課題の創出や自身の成長に繋がると考えており、最終的には事業価値を創出するきっかけとなると確信しています。
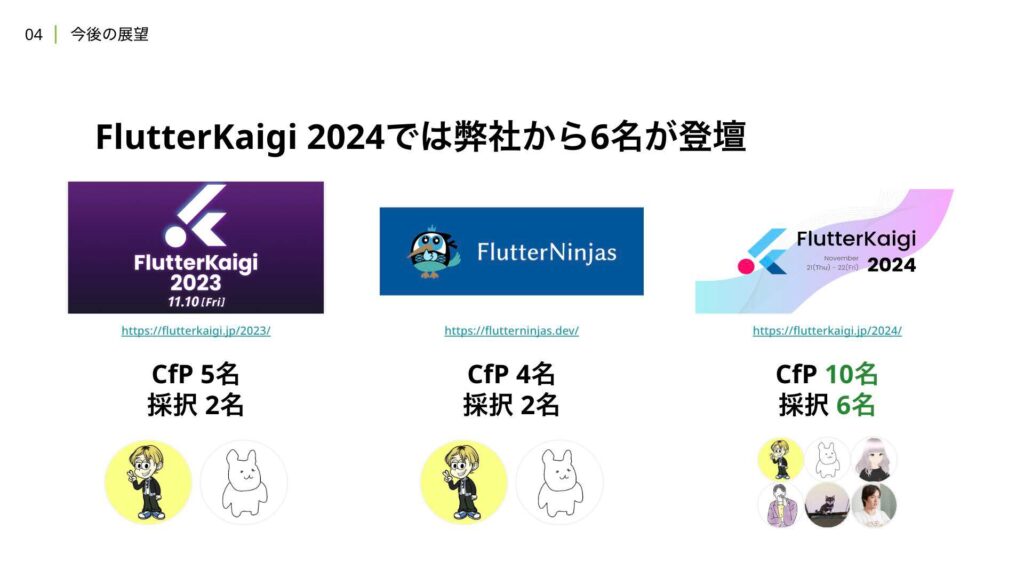
これまでも、カンファレンスを通じて、事業の課題に対する技術チャレンジを積極的に発信してきました。例えば、FlutterKaigi 2024では、例年以上に多くのプロポーザルが採択されました。それらのフィードバックは、さらなる課題の創出や自身の成長に繋がると考えており、最終的には事業価値を創出するきっかけとなると確信しています。
この貴重な機会を通じて、引き続き成長と成果の最大化を目指し、結果的に日本一技術で事業価値を作り出すアプリチームを目指していきたいと考えています。最後に、まとめとして、この約1年間はスケーラビリティと開発生産性に向き合い、さまざまな取り組みを行ってきました。

半期のチーム目標として、高可用性と安全な週3リリースを掲げ、課題の改善に取り組みました。その結果、チーム規模やコードベース、開発プロセスにおいては、2倍に近い成長や改善を実現することができました。今後は、事業価値のスケールを目指し、開発の推進や技術の挑戦をさらに進めていきたいと考えています。