
はじめに
こんにちは、慶應義塾大学理工学部四年の加藤駿です。私はCA Tech JOBとしてABEMAでのインターンシップに7月から9月初旬までの2ヶ月間参加し、検索システムの改善をLLMを用いて行う取り組みに参加しました。本記事では私がインターンシップを通じて行った内容と学んだことについて紹介させていただきます。
インターンシップ参加の目的
私は以前よりCyberAgent社が運営を行っているCA Tech Loungeに参加し機械学習についての勉強を行いつつ、BtoBの別の会社で自然言語処理に関するインターンシップ活動を行っていました。
CA Tech Loungeは学生や社会人がABEMA Towersの4Fのフリースペースを使って勉強しながらコミュニケーションをとることができるコミュニティです。学部四年であり就職活動を控えた私はコミュニティの中で就職に対する不安やCyberAgentの職務内容についての疑問を度々発信していました。
そんなある日、私はCyberAgentが全職種型のインターンを募集していることを知りました。研究室配属後本格的な研究活動にまだ取り組んでいなかった私はそれも合わせて以下の三つを学ぶことを目的に本インターンに応募しました
- 自分がラウンジで感じたCyberAgentの社風と実際の業務を通して感じる社風に差分はあるのか
- CtoC、BtoBの会社で業務内容や考え方にどのような違いが生まれるのか
- 研究活動につながるような仮説検証
インターンが始まるとすぐに自分が設定した目的をトレーナーさんや人事の方と共有する機会を頂きました。就職活動全体の解像度を高めたいとの話をするとメンターさんが複数業種にまたがる社員さんとのMTGをセッティングしてくださいました。
一日のスケジュール
インターンが始まるとABEMAの検索推薦チームでの活動が始まりました。
業務形態はハイブリッドで、月曜日と木曜日、金曜日が出勤日、その内金曜日をリモートとしました。
朝出社すると11:15から朝会が始まります。朝会はチーム内でその日、その週に何をするかを共有する会であり、この会で一日の方向性を定めます。一日の終わり(私の場合は17:30頃が多かったです)には夕会が設定され、トレーナーさんとその日行ったこととネクストアクションについて確認します。
お昼にはランチがあり、12:00-13:00までの間でチームでランチに連れて行ってもらえました。
朝会から夕会までの時間が作業時間になるのですが朝会と夕会のみの日は基本的にはなく、週末のバックエンドチーム全体での進捗管理やABEMAの人事主催の会社説明MTG、週一回のトレーナーさんとは別のメンターさんとのMTGもあり朝会+夕会+別MTG2個、というのが平均的な一日のMTGスケジュール、それ以外の可処分時間を作業に充てる、といった形でした。
取り組んだタスクについて(前半)
ここからが本編です。
まず私が取り組んだタスクの詳細と結果について話します。実はどちらかというと後半の話を読んでもらいたいので前半の話は飛ばしていただいても構いません。
タスクの設計
まずタスクについて取り決めを行いました。ABEMA検索の仕組みと合わせてタスク内容について説明します。取り組んだタスクはABEMAの検索システムで起こる0件ヒット問題についてのものでした。
ABEMA検索の仕組み
まずABEMA検索の仕組みについて説明します。ABEMAでは検索を辞書によって管理しています。
辞書では番組名に対して正クエリと呼ばれるクエリが紐付けられており、検索されたワードが正クエリと一致していれば検索ワードと番組が紐付けられ、番組が表示されます。
しかし、この検索システムだと検索者は正クエリを正しく推定する必要があります。検索したい番組に対して当然ユーザーはシステムのことを考えずに色々な検索クエリで番組を検索するはずです。そこで正クエリにはその正クエリに対して考えられる表記揺れや通称、愛称などを表す誤クエリが結び付けられています。この番組に対して結び付けられた正クエリと誤クエリ(関連クエリと呼びます)が検索クエリに一致すれば検索が成功し番組が表示される仕組みです。
0件ヒット問題とは
上記の検索方法でも検索クエリが関連クエリに一致しなかった場合、検索結果は0件と表示されてしまいます。実際に検索クエリに対応する番組がないのであればこれは正常な挙動ですが、対応する番組があるのに検索結果が0件とでてしまうのはいけません。この「検索結果として表示すべき番組が存在するのに関連クエリと一致しないことで検索結果が0件となってしまう現象」を0件ヒット問題と呼び、0件ヒットが起きてしまうクエリを0件ヒットクエリと呼びます
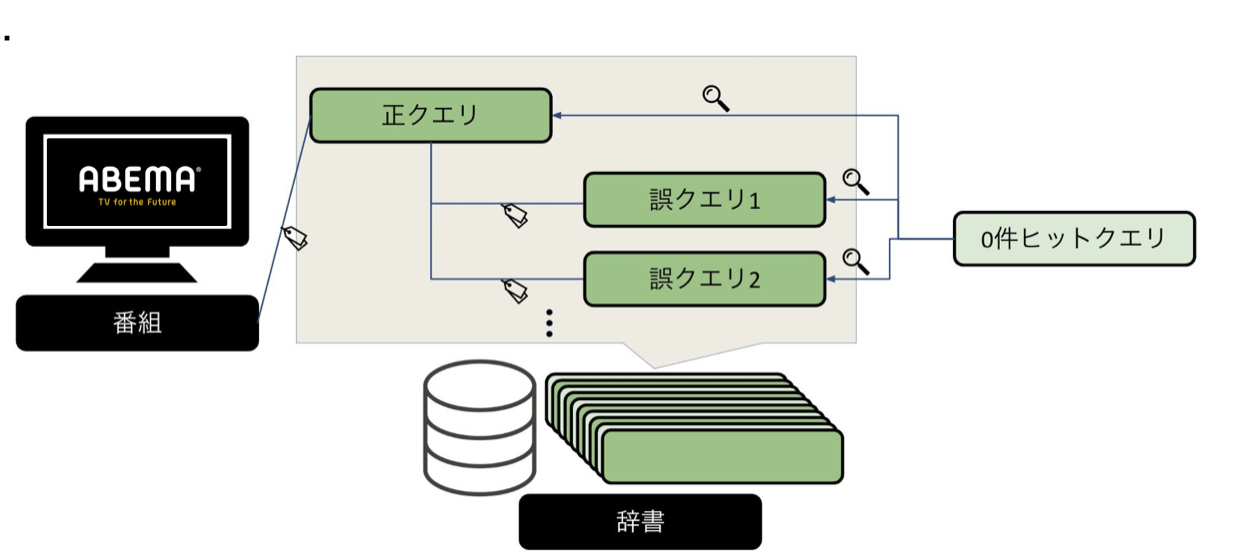
図1. ABEMA検索の仕組み
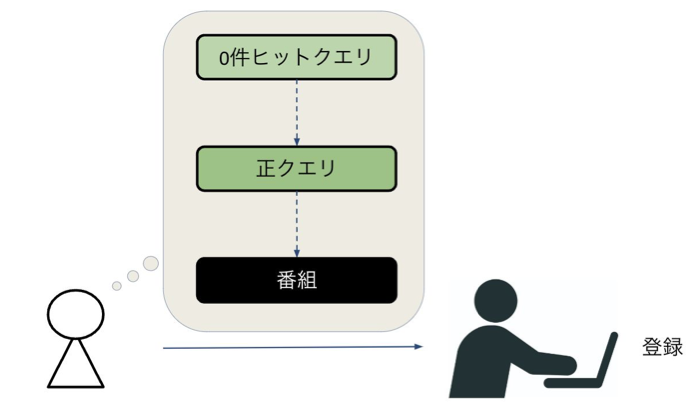
図2. 既存の辞書登録の仕組み
設定したタスク
そこで、「今まで人手で行っていた正クエリと0件ヒットクエリの関連評価をLLMによって行うパイプラインを設計する」をタスクとして取り組みました。LLMによる関連評価を行うことで人手で行っていた関連評価の作業工数を減らすことが目的です。
手法
始めに設計したパイプライン
まずLLMを用いた以下のようなパイプラインを設計しました。
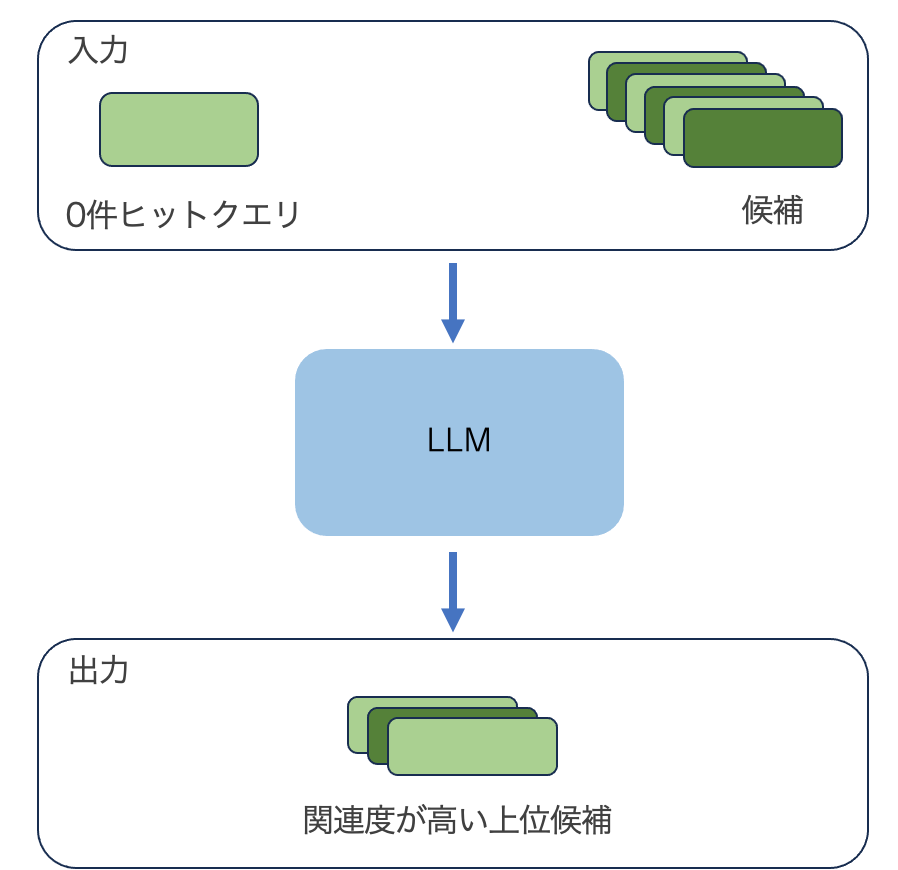
図3. 設計したパイプライン
パイプラインはシンプルなもので候補と0件ヒットクエリを入力としてLLMによる関連性評価を行います。LLMは0件ヒットクエリと候補それぞれの関連性を評価しランキングをつけ、上位候補k件を出力するというパイプラインです。出力が最上位ではなく上位k件なのは元々このパイプラインが「関連評価の作業工数を減らす」目的で設計されたものであり、辞書の紐付けを行う作業者がLLMが挙げた候補の中から正しいものを選んで承認するという使い方を想定されたからです。
このパイプラインをベースに予備実験を通して細かい設定を行いました。具体的には
- 入出力と正解の設定
- 事前選定を行うコンポーネントの追加
です。
入出力と正解の設定
入出力の設定は本インターンで一番苦戦したことの一つでした。
最初、私は0件ヒットクエリと正解が1対1で対応する番組名のデータを用いて予備実験をおこなっていました。入力の正解の区分とそれぞれの設定としては以下のようなものです
- 0件ヒットクエリと正解が1対1で対応するもの
- 入力: 番組名/正クエリ全てと0件ヒットクエリ
- 出力: 0件ヒットクエリに対応すると考えられる番組名/正クエリの候補k件
- 正解: 0件ヒットクエリに対応する番組名/正クエリ1件
しかし、この設定には無理がありました。設計したパイプラインでは0件ヒットクエリと候補の関連を評価しランキング付けを行います。正解が1件しかない番組名推論ではランキング付けに以下のような問題が生じます
- ランキング問題なのに正解の1件にのみフォーカスした評価しか行えない
- LLMにfew-shotを与える時k件の出力中top-1を除いたk-1件のサンプルどう作ろう?
そこで途中から入出力の実験設定を以下のように変更しました。
- 0件ヒットクエリと正解が1対多で対応するもの
- 入力: クエリ全体と0件ヒットクエリ
- 出力: 0件ヒットクエリに対応すると考えられる関連クエリの候補k件
- 正解: 0件ヒットクエリに対応する関連クエリn件
関連クエリとは「ABEMA検索の仕組み」で説明した「0件ヒットクエリに対応する正クエリと誤クエリ」です。
こうしてパイプラインによって推論する入出力と正解が決まりました。
事前選定を行うコンポーネントの追加
始めに設定したパイプラインでは候補(=クエリ全体)を入力とします。これら全てと0件ヒットクエリとの関連性をLLMで評価できれば良いのですが予備実験によってLLMが認識し、正しくランキングを行うことのできる候補クエリの量には限りがあることがわかりました。その数約2000件。クエリ全体の量は約30000件あったため、あらかじめクエリ全体から2000件のクエリを事前に選定し、事前に選定したクエリを候補としてLLMに渡すことにしました。
これらを踏まえて設計したパイプラインの全体図は以下のようになります。
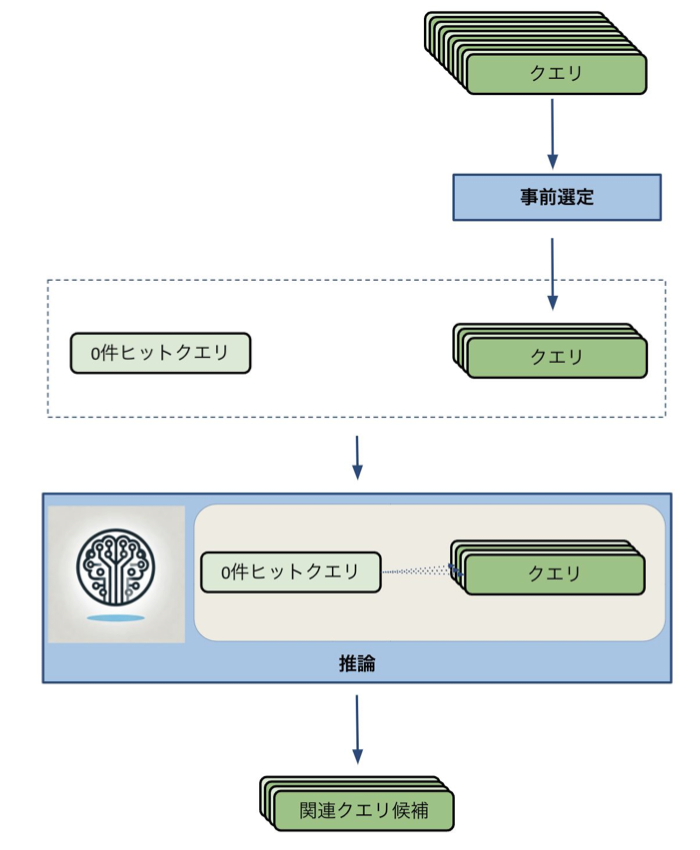
図4. 実験で用いたパイプライン
実験
実験ではまず事前選定について2種類、LLMによる推論について3種類の方法を実装し比較しました。
事前選定手法
- コサイン類似度
コサイン類似度は文章や単語の意味的な類似度を計測する際に多く用いられる類似度計算手法です。ベクトル化した文章/単語の二つのなす角を表し、直行する(意味的に全くにていない)ベクトル同士に0を、完全に向きが一致するベクトルに1を割り当てます。コサイン類似度が高い二つの文章/単語ベクトルは特徴空間で近い方向を向いていることから類似度が高いということができます。[1]
- Jaro-Winkler距離
Jaro-Winkler距離はルールベースで二つの文章/単語の類似度を測る手法です。単純な編集距離と異なりJaro-Winkler距離では計算の中で「比較対象のうち長さが最大のもの長さを半分にした後1を引いた値の範囲の中で文字が一致すること」や「先頭から文字が一致すること」がスコアを上げることに繋がり、タイポしてしまった文字列同士の類似度を高く評価することができます。[2]
LLMの推論手法
- 一括推論
一つ目は最もシンプルな方法です。
一括推論ではLLMに候補となるクエリ、0件ヒットクエリを与え「{0件ヒットクエリ}と{候補となるクエリ}の関連度評価を要素それぞれについて行い、関連度が高いと考えられる上位k件を出力してください」というプロンプトで一括に推論を行う方法です。
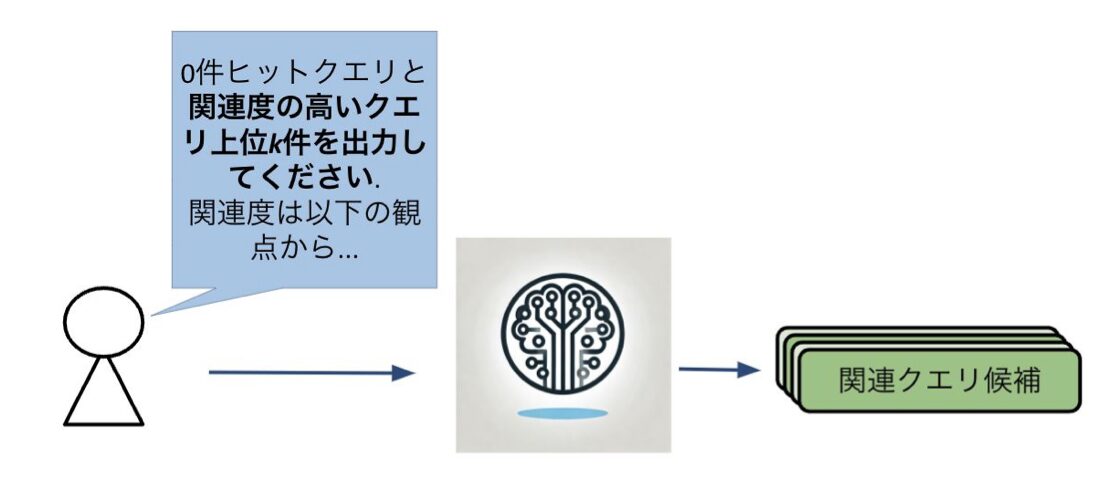
図5. 手法1の図解
2. Weiwei らの手法[3]
関連度評価は2000件の要素の間で行うよりも100件の要素の間で行う方が、さらに言えば10件、5件…とランキングをつける件数が少ない方がより簡単なタスクであるはずです。
手法2はEMNLP2023で提案されたLLMを用いてランキングを行う方法です。並び替えを行う対象から小ウィンドウを取り出し要素を並べ替えます。多くの要素間のランキングを小分割したランキングの繰り返しにすることで安定した精度を出すことが期待されます。
小ウィンドウをスライドさせながら先頭まで並び替えを行いますがこの時n回目の並び替えのウィンドウの後半にn-1回目の並び替えで前半に位置した(上位と評価された)要素を含めることで上位と評価され続けた要素は先頭まで移動することができ、ランキングが完了します。
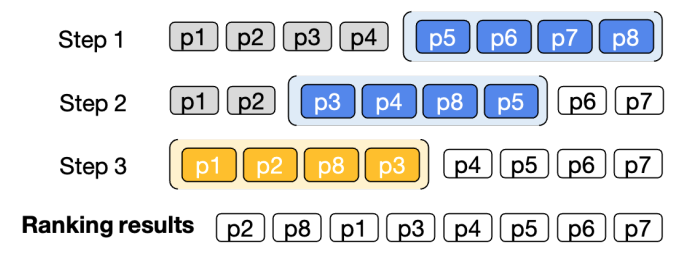
図6. 手法2の図解[3]
3. Weiwei らの手法 + スキップシステム
2の手法は本来数が8つ程度の少ない文書を並べ替えるための手法であり、30000件のクエリデータに適用する際には並べ替えの途中で下位にいた有力候補が脱落してしまうことがわかりました。そこで手法3として並び替えを行っている途中で複数回連続で小ウィンドウに残った要素を有力候補としてクエリ全体のリストの先頭に移動させるスキップシステムを導入し、有力候補の並べ替えの回数の緩和を図りました。
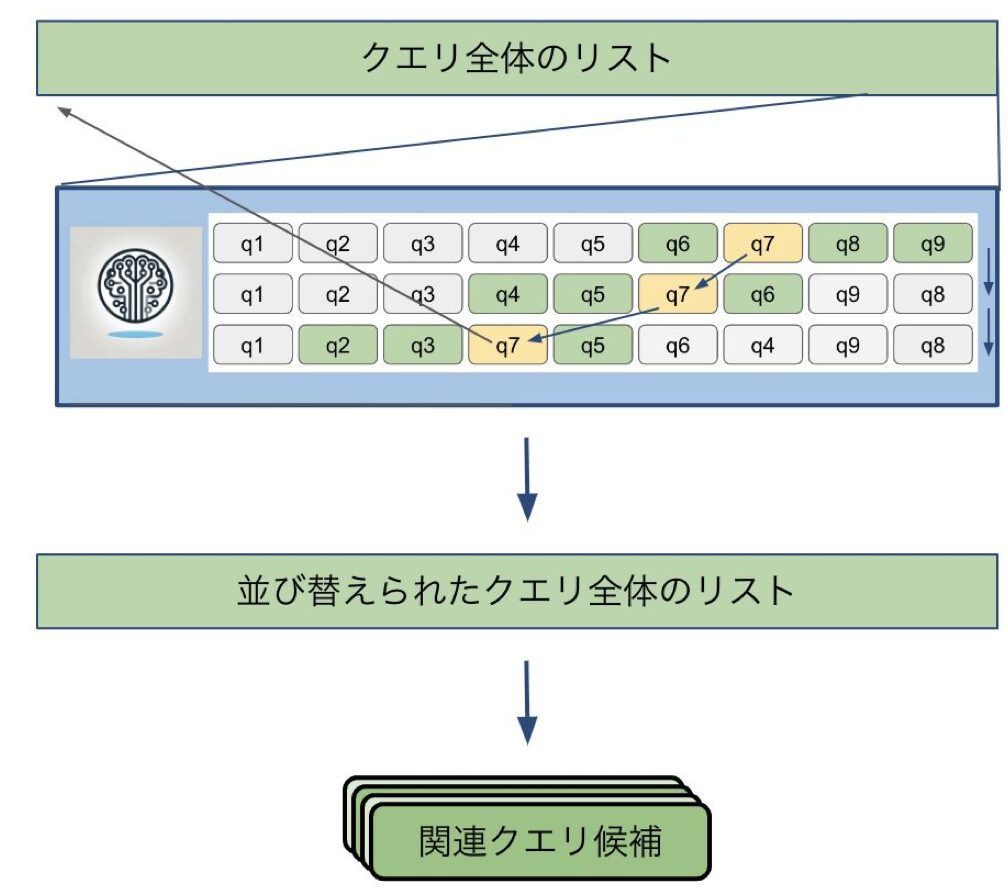
図7. 手法3の図解
データセット
データセットは直近半年間で確認された0件ヒットクエリ15件と登録されている全てのクエリ約30000件、正解データとして0件ヒットクエリに結び付けられるべきとされた関連クエリを用意し実験しました
評価指標
評価指標はランキングがどれだけ関連クエリを上位候補に含めているかを示すRecallとそもそもランキングに関連クエリを一つでも含めることができているかを表すHit-rateで評価しました。評価はそれぞれ事前選定の段階と推論の段階で行いました。
その他の設定
出力する候補の数kは10に設定しました。またスキップシステムの小ウィンドウのサイズは10件とし、ストライド(スライドする数)は5に設定しました。
実験結果
得られた結果は以下のようになりました。
表1は事前選定について評価を行ったものです。コサイン類似度による事前選定では0件ヒットクエリに対して紐付けられた関連クエリを平均して半分以上一つも2000件の事前選定済み候補に含めることができていないことがわかります。対してJaro-Winkler距離を用いた事前選定では0件ヒットクエリ15件のうち1件を除く14件で関連クエリを事前選定済み候補に含めることができている他、平均して関連クエリのうち6割ほどを含めることができています。
表2は事前選定の後の推論について評価を行ったものです。事前選定では表1で良い結果を得ることができたJaro-Winkler距離を用いた事前選定を行いました。
Hit-rate、Recall共に最も良い結果は手法1によるものであることがわかります。手法2は並べ替え途中の関連クエリの脱落によって大きく性能が落ちてしまうことがわかり、またスキップシステムを導入した手法3では脱落による評価指標の悪化は防ぐことができたものの全体として手法1と比較して評価回数が多いことが悪く働いたようで手法1の結果には届きませんでした。
表1. 事前選定の手法の定量評価

表2. 推論の手法の定量評価
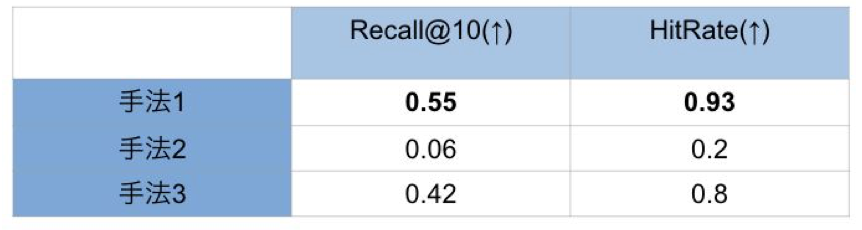
様々な手法の比較を行いましたがJaro-Winkler距離による事前選定+手法1による推論によって検証データにおけるHitrateは0.93となり、15件中14件の0件ヒットクエリについてクエリ全体30000件から関連クエリのうちの少なくとも一件を関連度が高いtop10に含めることができるという結果を得ることができました。この結果よりLLMによって関連性を評価し辞書登録の工数を削減するというシステムの実現が可能であることを一定示すことができました
タスクの話は以上になりますが実はこの取り組みには続きがあります。なんとABEMA組織の所属インターン生としては初めてとなる学会でのポスター発表を行うことができたのです。
YANSに行くことができた話(後編)
タスクについての成果がでた段階でトレーナーさんからある提案を頂きました。
それは「この成果をインターン後の9月に行われるYANS(NLP若手の会)でポスター発表しない?」というものでした。
YANSは近年勢いのある言語処理学会の若手支援事業であり、今年は大阪の開催でポスター発表の募集が行われていました。
研究活動をまだ行なっていなかった私はポスター発表にとても憧れがあったためこのお誘いはとても魅力的で二つ返事で是非、と返しました。
そして、なんと、ありがたいことに、様々な人のご助力もあって本インターン成果をYANSでポスターとして発表できることが決まったのです!!!
ここからはポスター発表が決まってから大阪のYANSで発表する9月5日までにあったことをまとめたいと思います。
ポスター作成、参加申し込み(7月中旬 – 8月下旬)
ポスターは研究の内容をA1の大きい用紙にまとめたものです。みなさんも小学生の頃書いた自由研究を思い出してもらえればわかりやすいと思います。あれです。まあ小学生の頃作っていたものですし初めてとはいえど書きやすいはずです。まあ楽勝でしょう。
書いた感想ですが、学術的な文章を書くのがこんなに大変だとは思いませんでした。
いや、全然ポスターが悪いとかじゃないと思います。初めてのポスターだったのもあってひたすら手探りで作業を進めていたのが大きいです。
2時間たっても1セクションの内容がまとまらない、ポスターの構成がわからない、色使いや結果の分割がわからない…
トレーナーさんが色々な社員の方に小出しにした進捗のレビューを依頼してくださり、そこからデザイナーさんがポスターのテンプレートを作成してくださり、メンターさんが構成の修正をしてくださり、バックエンドチームの方が用語や誤字の指摘をしてくださり、と補助輪を左右に10個ずつつけたような形でポスター作成は進みました。
またYANSのポスター発表応募の勢いがすごくて申し込みがギリギリになったりと色々なことがありながらも順調にポスター作成と参加申し込みまで行うことができました。
またありがたいことに発表練習は検索推薦チームのみなさんを相手に行わせていただきました。振り返って思うとインターンの学生のためにABEMAの1チームの社員さんが時間をとって発表のレビューをくれるってすごい通り越してる感じもします。
準備をしていざ大阪へ
YANS参加、ポスター発表(9月)
YANSのことを全て書くとそれだけでとんでもない量になってしまうので一言で表すととんでもなく楽しかったです。全3日間のセクションがあり、私は3日全てに参加していました。
ここからは3日間の出来事をかいつまんで話したいと思います。
1日目
1日目は大阪に移動してハッカソンから始まりました。ハッカソンは与えられたテーマに沿った内容の成果物を決められた時間(5時間くらい?)で作るもので初めましての方々とわいのわいのしながら実装を進めました。
時間がひたすら足りないと泣きながらでしたが、学生と社会人が混ざったハッカソンで色々なアイディアをみることができ、とても楽しいハッカソンでした。

大阪到着
2日目
2日目は私のポスター発表の日でした。発表は昼の間に行われましたがとても多くの人がきてくださり、発表について色々質問もしてもらえました。
最初はしっかり緊張していましたがいざ始まると多くの方が興味を持ってフランクにディスカッションしてくださったおかげで次第に緊張はほぐれ、終わりのころにはひたすら楽しんで話すことができました。
2日目の終わりには若手の会が主催する懇親会に参加しました。懇親会は自然言語分野で仲間を増やしたい学生や社会人の方が集まり自由に歓談する場となっており、そこで自分の興味のある分野や研究について沢山の話を聞くことができました。

ポスター発表をする自分
3日目
3日目はポスター発表と特別ポスターと特別講演、そして表彰式がありました。特別ポスターでは友人が所属している研究室のボスに会えたり、特別講演では機械学習を勉強していると身近な損失の地形についての興味深い話を聞くことができました。
表彰では奨励賞と各スポンサーが用意したスポンサー賞がそれぞれ用意され、奨励賞は参加者の投票によって決められていました。
そして、なんと、今回私は奨励賞をいただくことができました!

表彰の時の写真
こうして三日間の学会を終え、無事に帰路についたのでした。
インターン活動を終えて
本インターンでは2ヶ月とは思えないほどの経験を得ることができました。CA Tech Loungeで自分が感じた挑戦に対してとても前向きな社風が実務についてもそのまま根付いていると感じた他、就職活動に向けて知っておきたかったBtoBとBtoCでの動き方の違いを知ることができ、またCyberAgentで働く様々な職種の方の働き方を知ることでそれぞれの職についての解像度が高まり、自分に合う仕事の方向性をある程度定めることができました。
またCA Tech Loungeにいる間には気づけなかったのはこのように就職活動を控えた学生に寄り添い、社員さんが積極的に、本当に積極的に動いてくれる会社だということでした。
トレーナーさんはもちろんのこと、メンターさんはインターン最終日にまでランチを組んでくださったり、ランチに来てくださる方は快く自分の仕事についてお話をしてくださりました。
またメンターさんだけでなく人事の方からも理系を飛び越えてビジネス職の方までランチをセッティングしてくださり、当初想定していた以上にCyberAgentについて理解することができました。
また取り組んだタスクの成果でポスター発表、そして奨励賞をいただけるという最高の形でインターン終了まで走り切ることができました。
何度も言うようですが本インターンは本当にトレーナーさんとメンターさん、サポートしてくださった社員さんとバックエンドチーム、検索推薦チームの方全員に支えられて成り立ったものです。自分でインターンをやりきることができたことで自信がついたと同時に、自分一人では絶対にここまでなし得なかったとチームの大切さを学ぶことのできた2ヶ月でした。
関わってくださったみなさまに感謝をして結びとさせていただきます。本当にありがとうございました。
Reference
[1] 高校数学の美しい物語 コサイン類似度 url: https://manabitimes.jp/math/1378
[2] Medium Jaro winkler vs Levenshtein Distance url: https://x.gd/OI8fs
[3] Weiwei et.al, “Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents”, EMNLP, 2023