
今回の記事ではデータエンジニアリングの領域において、チームで取り組んでいるLLM活用のアプローチについて紹介します。
簡潔に要約すると、データの前処理における変換部分(データレイク層からDWH層への変換部分)において、LLMを利用した工数削減の手法と実践の紹介になります。
モチベーション
現在私が所属しているチームはAI事業本部の「リテールメディア ディビジョン」で、小売の企業様と協業で、アプリ開発やデータ分析、クーポン配信などを行なっています。
- (参考)過去に弊社が出しているプレス
チームでは、小売業のデータ活用のためのアプリケーションやパッケージを幾つも開発しており、それらを各小売企業のデータと連携させることで、新しいサービスを提供するという取り組みを行なっています。
例えばアプリケーションの一つとして「AIセグメント」という機械学習を用いたサービスがあり、顧客の過去購買データから、特定の商品にマッチした顧客を予測することができます(1)。
多くの小売企業と協業してプロジェクトを推進していく上で課題となってくるのが、全ての企業において管理しているデータベース構成と、テーブルの形式が微妙に異なる点です。
「微妙に異なる」というのがミソで、小売企業で扱う重要なデータの構造は基本的に似通っています。(例: 各店舗での購買(POS)データ、商品マスタ、店舗マスタ…etc)
必要な情報は共通で揃っていて、構造も一定似通っているのに、種々の細かなテーブルの定義方法が異なるために、個別でデータパイプラインを構築する必要がありました。
この点は、弊社で開発したパッケージを幅広く展開していく上での課題となっていました。
そこでデータベースの構成、テーブルの形式を自動変換できるシステムを構築することで、先に紹介した「AIセグメント」などを含む多くのアプリケーションを、データ接続から数週間と待たずに素早く展開できるようにしていくことが、今回の取り組みの最終的なビジョンです。
また、技術的なチャレンジとして、将来的にはデータの整形だけでなく、その後の工程である集計やフィルタリング、計算などを行なってダッシュボード構築などもLLMで自動化していくというアプローチも視野に入れています(2)。
そのためにまず、今回の取り組みではLLMを使用してデータベースのテーブル構成を解釈させ、自分たちの定義した扱いやすい形式に変換するシステムを実装しました。
システムの概要
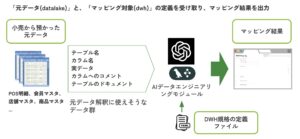
本システム(AIデータエンジニアリングモジュールと呼んでいます)では、実際のデータベースから、テーブルの内容を解釈するのに使えそうな情報(例: テーブルスキーマ、実際のデータなど)をシステム的に収集してLLMに読み込ませ、事前にyamlで定義した自分たちが扱いやすい形式へと変換するためのマッピングを予測します。
予測する内容は具体的には、以下の二つです
- DWHで取得したいカラムに対して、元データのどのテーブルのどのカラムがマッチしているか
- 元データでは、各カラム同士が、どのようなテーブル構造(リレーション)で定義されているか
1.をカラム予測、2.をリレーション予測とし、タスクとして分けて考えています。
両方が正しく認識できれば、データレイク(元データ)からDWH(使いやすく整形したデータ)への変換のためのsqlを記述することができるという前提です。
アプリケーションを作る上での発想として、「システムに初めから終わりまで全てを行わせる」のではなく、「人間の工数を下げる形で業務に導入する」という方針で進めていました。
マッピングの予測結果は人間が判断・修正を行うオペレーションを前提で構築しているため、最終的なアウトプット方法も人間が扱いやすいGUIを選択しました。
このような方針をとっているため、予測のモジュールを評価する方針も、正解カラムを1位に予測することに重きを置くのではなく、3位以内に出来る限り正解カラムを含められるようにすることとしました。GUI上で表示される候補カラムは多くて5つ、できれば3つ以内に正解が含まれていることが望ましいと思われたためです。


上記の画像は実際のUIの一部で、テーブルのカラム予測とリレーション予測の確認と修正を行うことができます。
テーブルの解釈・マッピング予測のロジック
AIデータエンジニアリングモジュールは、大きく分けて二つのモジュールから構成されています。
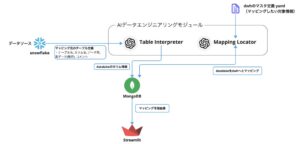
1. テーブル情報の解釈
まず第一ステップの「Table Interpreter」では、テーブルのメタデータを後段でLLMが扱いやすいデータに加工してデータベースに保存します。
今回はドキュメントDBを選択しており、MongoDBを採用しています。
データベースの解釈は、以下のような情報をカラムごとに収集しています。
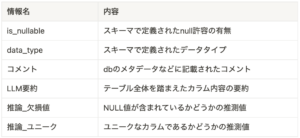
基本情報をテーブルのスキーマなどから取得し、それだけでは収集できない情報を他の方法で補う、といった形をとっています。
欠損値やユニークを推測しているのは、それらが予めデータベースのスキーマ情報として含まれていないケースも多いためです。例えば小売業のPOSデータ(レジのデータ)などは、csvとして出力された値をそのままデータベースから参照しており、nullかどうかの情報が存在していないことがあります。
そこでデータベースから実際のレコードの一部を参照(BigQueryでは、table-sampleなどが利用できます)して推測した結果を代入するようにしています。
2. マッピングの予測
次に、第二ステップでは、対象のデータベースを自分たちが定義した「扱いやすいデータ形式」とマッピングするための予測を行います。
予測にあたってはLangGraphというライブラリを使用してワークフローを組んでいます。
LangGraphは「マルチエージェントシステム」(定義は色々な種類があるように思われますが、広くは複数のLLMを連携させたシステムの事を指します)を開発する上で選択肢に上がってくるツールです。
本システムでも一度のリクエストで全てを予測させるのではなく、複数回LLMを呼び出して分岐などをさせていくフローを構築したかったので、LangGraphを採用しました。

LangGraphで作成したワークフロー(mermaid記法や、画像としてワークフローをアウトプットできる機能が含まれています)が、こちらになります。
まず最初に「明細テーブルを探す」というnodeからスタートします。これはテーブルのリレーションを前提に予測を行う上で、起点となるテーブルを決めた方がやりやすかったためです。目的は完璧にデータソースのリレーションを予測することではなく、自分たちの定義したスキーマにマッピング可能な形でリレーションを抽出することなので、小売企業のデータで確実に存在し、かつ重要なテーブルをそのエントリーポイントとして選択しました。
カラムの予測は主に二つに分岐しており、「単一カラムのマッピング」と「階層型カラムのマッピング」としています。
単一カラムはイメージしやすいかと思いますが、目的の情報が単一のカラムで表現されているもの(例 : 商品の名前、値段、購入された個数など)です。
対して階層型のカラムは、例えば地域データ(都道府県 > 市区町村 > それ以下)や、商品のカテゴリ(大カテゴリ > 中カテゴリ > 小カテゴリ)などが該当します。難易度としてはこちらの方が予測が難しく、データソースによって階層の数自体が異なります。商品カテゴリを5段階で分類しているパターンもあれば、3段階までしか階層を掘っていないケースもあるため、まず階層が何階層まで定義されているかを解釈し、それぞれのマッピングのパターンを予測する必要があります。
全てのカラムを対象に予測を行った後、それらの結果をマージして、改めてリレーション予測を行う、というフローになっています。
性能の検証
LLMを使ったアプリケーションをつくる上で、性能検証の方法論はまだ確立されていないように思います(3)。
一方で、今回のシステムでは明確に正解が存在しているため、性能の検証はかなりやりやすかった印象です。

今回は、まずLLMが解釈しやすい・しづらいだろうという仮説を立てた上で、難易度を調整したデータセットを複数用意して、上記のlanggraphのワークフローや、LLMのプロンプトチューニングなどを行いながら、性能を向上させていくというアプローチを取りました。
結果として、難読なテーブル名(人間でも読み取るのが難しい)でなければ、カラムの予測は90%以上の確率で、上位3位以内に正解カラムを予測可能な精度を出すことができました。
実際に業務で使っているデータソースに適応したところ、全てのカラムを上位3位以内で予測することができました。
課題として残ったのはリレーションの予測精度で、こちらは60%程度の正答率に留まっています。
特に、先に述べた階層型カラム(地域やカテゴリの表などの、事前にカラム数を確定できないカラム)のリレーション予測は難しい課題でした。
階層型のデータは、階層の数だけでなく正規化の度合いもデータソースによって異なるため、構築すべきリレーションの組み合わせも条件分けが多くなってしまっているためです。
今後はこのリレーションの組み方の問題を解決するとともに、生成した予測及び、ユーザが修正した内容をもとにsqlを実際に組んでいくという部分にも広げていきたいと考えています。
おわりに
今回は、データエンジニアリング領域におけるLLM利用の取り組みの一つである「データ変換・マッピングの予測アプリケーション」について紹介しました。
LLMは日夜新しい技術や応用が発表されている一方で、実際の業務内に組み込む上でのハードルが高いことも感じていました。今回の実践を経て、特に重要だと考えたのは、常に100点を出してくれるとは限らないLLMの出力と、人間による確認・修正のプロセスをどのように統合するか、という事と、LLMを含むアプリケーションの出力を継続的に評価する体制をどのようにつくれるかという事の二点でした。
今回はGUIによる人間の介入を前提にした設計と、正解の存在するテストデータ作成によってこれらの課題に対処しました。より難易度が高いのは、後者の「LLMの評価」において、正解を確定できないような場合だと思います。
自分たちのチームでは、データエンジニアリングや分析結果のアウトプット解釈など、データ活用の文脈でのLLMの導入を進めています。
興味を持って下さった方は、ぜひ一度カジュアル面談への参加などもご検討いただけると嬉しいです。
脚注
-
- AIセグメントに関連した記事としてはインターンシップで挑戦した広告効果の推定方法の開発と実践などがあります
- この分野はより広くみると、Text-to-SQLと呼ばれるタスクとも大きく重なる部分です。Text-to-SQLは、LLM以前から研究されていた分野ではありますが、近年はLLMの影響も大きく、論文などがより活発に投稿されています。
- 以下の記事などに網羅性が高くまとめられており、参考にさせていただきました。Evaluating LLM systems: Metrics, challenges, and best practices