
Muddy WebはMuddy = 泥臭いとして、Webフロントエンドの開発現場における話やケーススタディなど泥臭さのある話をもとに学びを得ることを目的として開催しています。現場で遭遇した具体的な体験を元に実際に明日から使えるかもしれないWebフロントエンド的な技術や知識を参加者の皆さまと共有し合うことを通して、フロントエンド開発の糧になれればと思います。ポッドキャストも配信中ですので、よろしければリスナー登録もおねがいします。
本記事は、11月7日に開催した「Muddy Web #10 ~Special Edition~ 【ゲスト: pixiv】」において発表された「ジャンプTOONにおけるサイトマップの自動生成手法について」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
浅原 昌大
2023年新卒入社。 SGEマンガ事業部に所属。好きな縦読みマンガは「フルボー 〜タッたら終わりの異世界無双〜」
それでは「ジャンプTOONにおけるサイトマップの自動生成手法」について、株式会社サイバーエージェントの浅原昌大が発表させていただきます。まず簡単に自己紹介させていただきます。私は2023年度に株式会社サイバーエージェントに新卒で入社し、今年で2年目になります。現在はSGEマンガ事業部に所属しており、「ジャンプTOON Web」の開発を担当しております。
よろしくお願いいたします。

本日のアジェンダをご紹介します。まずは「ジャンプTOON」についてお話しします。
ジャンプTOONは2024年5月にサービスを開始したばかりの縦読み漫画サービスです。現在、アプリ版とWeb版の両方で展開されています。このサービスでは、集英社様が手がけるオリジナルの縦読み作品や、人気作品の縦カラー版を配信しています。
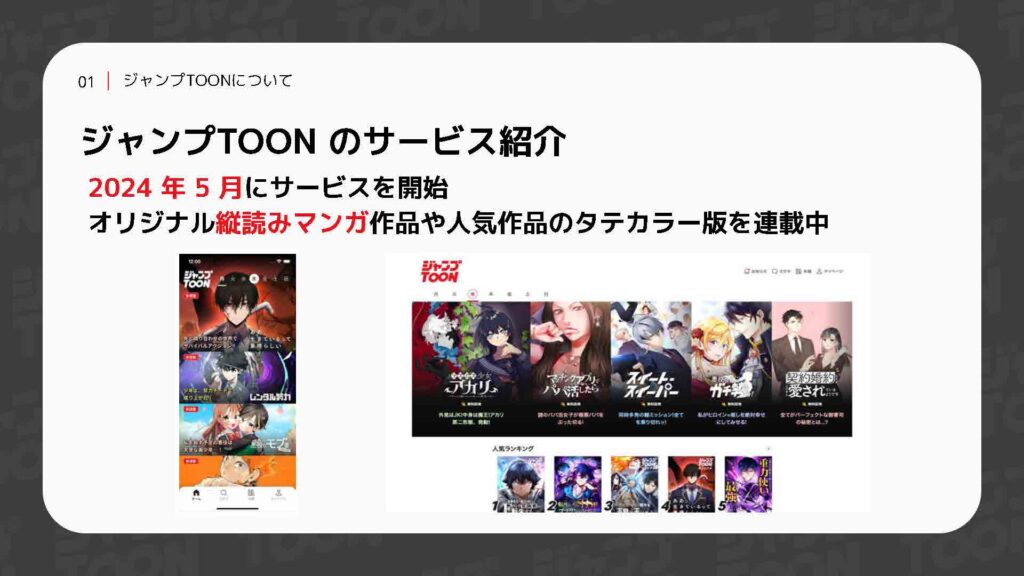
サイバーエージェントは開発とマーケティングを担当しております。サービスはまだローンチしたばかりということもあり、現在はこれからユーザー数を増やしていく段階にあります。その施策の一環として、サイトマップを作成しました。本日はそのサイトマップについて詳しくお話ししたいと思います。
ところで、皆さんは「サイトマップ」という言葉をご存じでしょうか。もしかすると、初めて聞く方や詳しくは知らない方もいらっしゃるかもしれませんので、ここで簡単に説明させていただきます。

サイトマップとは、サイト全体のページ構成を一覧で記載したもので、大きく2種類に分けられます。1つ目は、ユーザーが目的の情報を見つけやすくするための HTMLサイトマップ です。これはユーザー向けのもので、サイト内の情報を整理して提供する役割を果たします。
2つ目は、検索エンジンにサイト内のページ構成を正確に伝えるための XMLサイトマップ です。これは検索エンジン向けに設計されており、クローラーにページを効率よく巡回してもらうために使用されます。
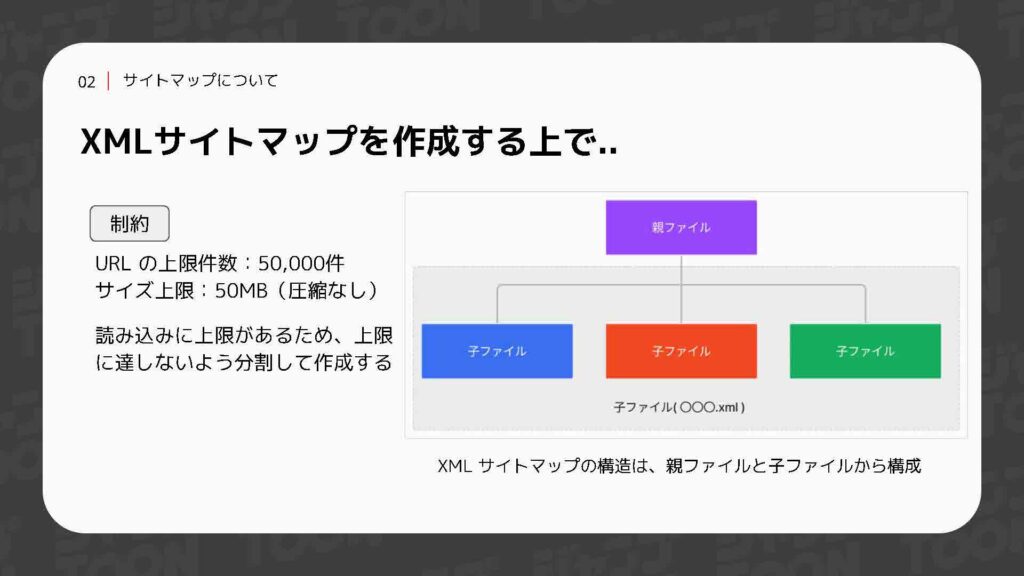
XMLサイトマップを作成する際には、いくつか注意点があります。その一つとして、一つのファイルに記述できるURLの上限が5万件までと決まっていることが挙げられます。このため、規模の大きなサイトやURLの数が多いサイトでは、親のサイトマップファイルと複数の子ファイルに分割して管理する必要があります。この図のように、親ファイルで各子ファイルを指し示す構造を作り、検索エンジンが効率よくページを巡回できるようにします。
ジャンプTOONでは、今後作品が増加し、さらに毎日話数が更新されることでページ数も増えていきます。そのため、最初から分割したサイトマップの構造を前提として作成する設計にしました。
次に、ジャンプTOONでどのようにしてサイトマップを生成しているのか、その手法について具体的にご紹介します。
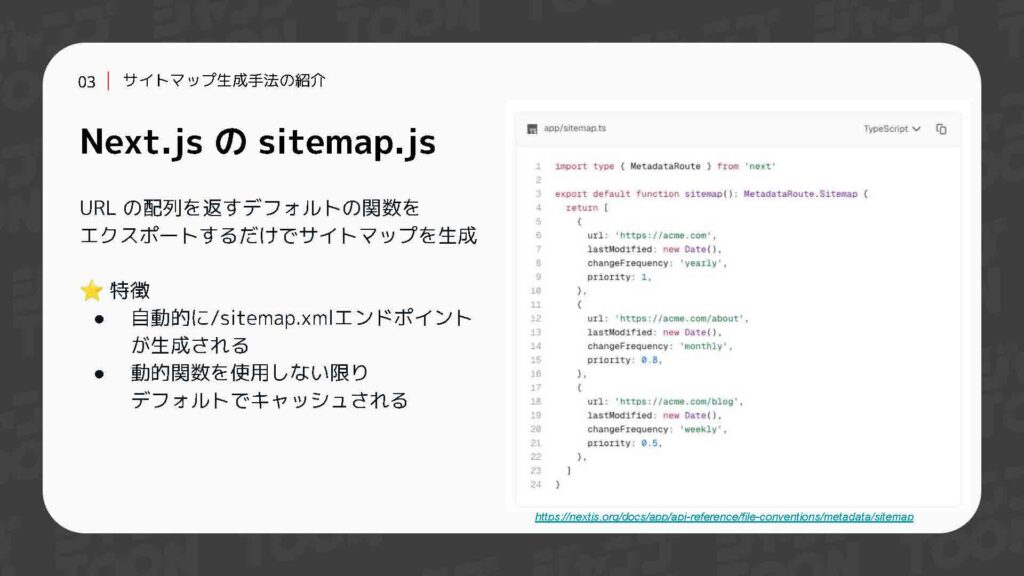
ジャンプTOON WebではNext.jsのアップルーターを採用していて、App Directoryに右のようなSitemap.jsもしくはSitemap.tsのファイルを作成するだけで、簡単にサイトマップを生成できる機能があります。自動的にSitemap.xmlのURLが生成されることになりますので、生成されたURLをそのままSearch Consoleに登録するだけで済みます。また、このXMLはSitemap.jsの中で動的関数を使用しない限りは、デフォルトでキャッシュされるといった特徴があります。
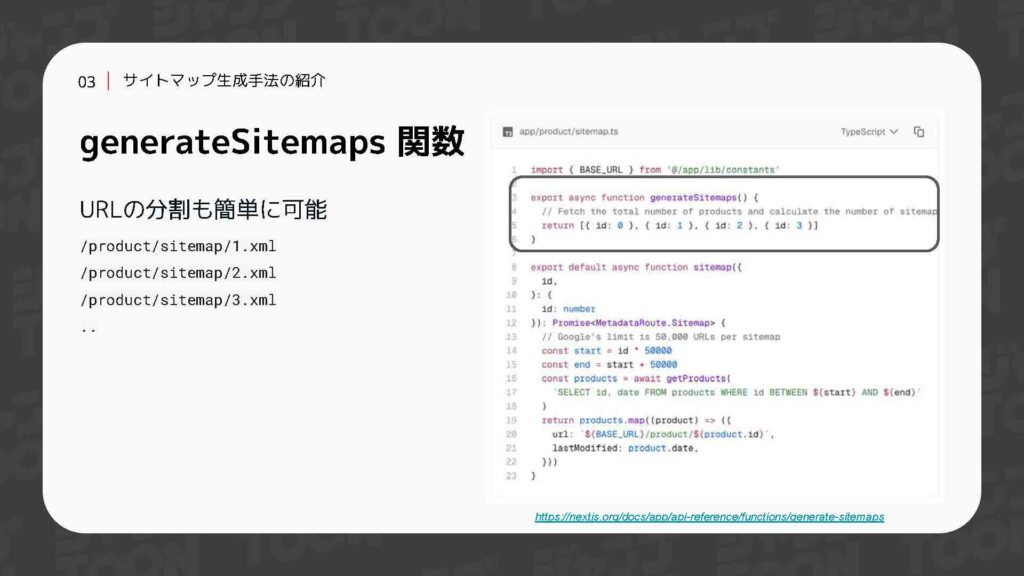
このように、Sitemap.jsの中でデータフェッチを行うことで、ビルド時には作成できなかった動的なパスも含めることが可能になります。また、1ファイルに記述できるURLに上限がある件についても、提供されているGenerator Sitemaps関数を使えば、ファイルの分割を簡単に行うことができます。
一見すると、これで問題なくサイトマップを作成できそうですが、少しだけ不都合な点がありました。それは、このSitemap.jsには分割したサイトマップをインデックスファイルにまとめる機能がまだ実装されていない点です。
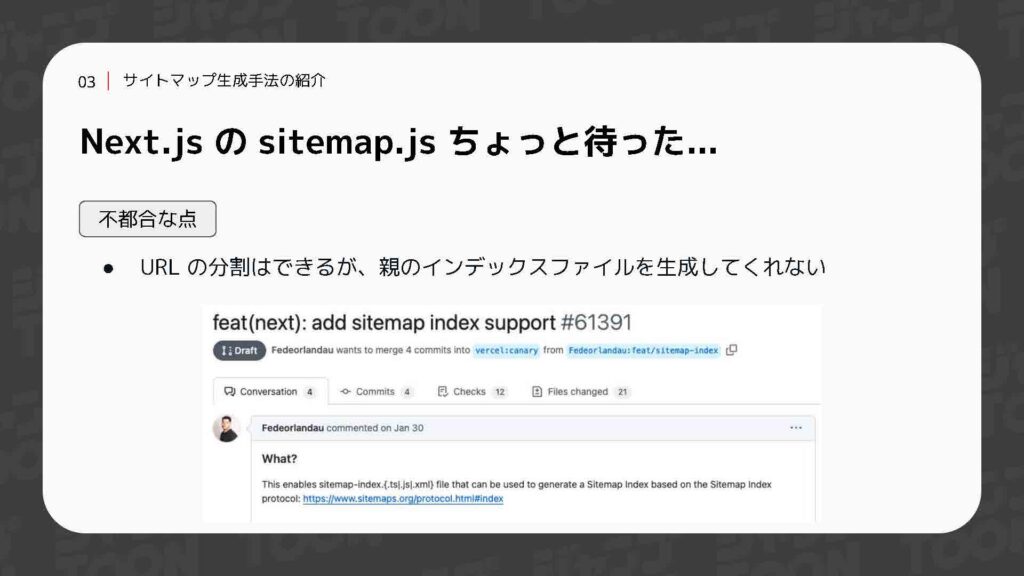
そのため、分割されたサイトマップが増えた場合には、現状では手動でrobots.txtに追加しなければなりません。この作業は手間がかかり、保守性の面で課題があります。これを解決するために、Next.js側でも議論が進んでおり、サイトマップインデックスの生成を自動化する機能が提案されています。現在、この機能はドラフト段階でPull Requestが出ている状態です。

また、Sitemap.jsを用いると、サイトマップが直接ホストしているドメインから配信される仕組みになるため、サイトマップの特定が容易になります。その結果、サイトマップを基にサイト全体がスクレイピングされる可能性が高まる懸念があります。サイトマップ自体はGooglebotがアクセスできれば十分であり、一般ユーザーから特定できない場所に配置するのが望ましいと考えています。
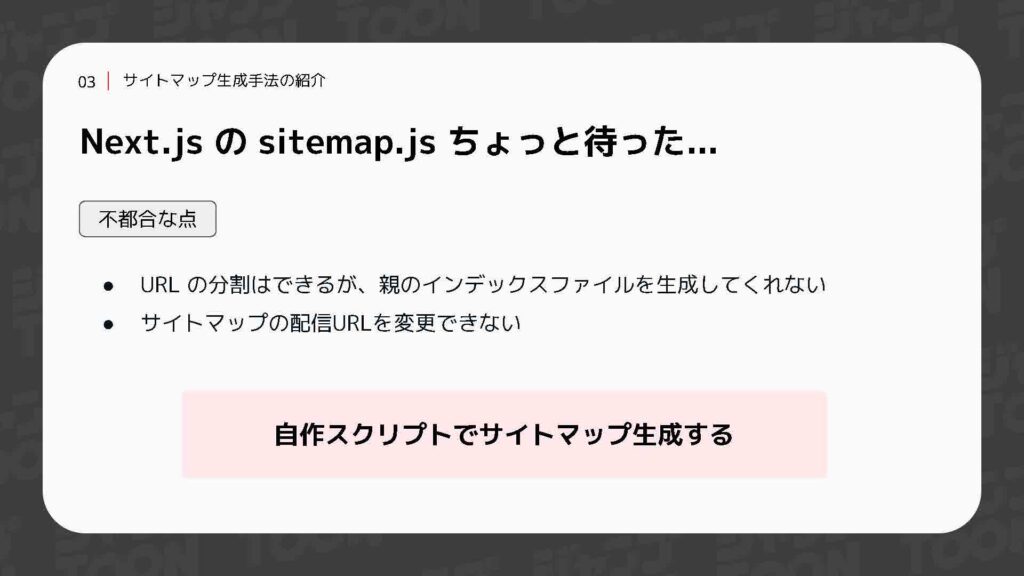
そのため、今回はSitemap.jsを使用せず、自作スクリプトでサイトマップを生成する方針にしました。XMLのサイトマップ構造は既に定まっているため、自作の手間もそれほど大きくないだろうと考え、勢いで進めてみました。しかし、実際に取り組むと予想以上に複雑な作業となり、少々泥沼化してしまいました。ここから先は一つの事例として参考にしていただければと思います。ただし、これが唯一の正解というわけではない点は、予めご了承ください。
では、設計と実装の説明に移ります。まず実装に取りかかる前に、サイトマップに含めないパスを事前に決めておきます。ジャンプTOONにはマイページ機能がありますが、マイページのような検索結果に表示したくないノーインデックスのパスについては、サイトマップに含めないように設計しました。

また、リダイレクトのみで使用しているパスだったり、 無限に存在してしまう検索結果などは載せません。

次に、サイトマップに含める情報についてです。サイト内の各ページに関する情報を記載するlocタグや、ページの最終更新日を記載するlastmodタグは必ず含めるようにします。最終更新日については、コンテンツが変更された場合のみ更新する方針としており、記載できる箇所だけに付ける形としました。
また、changefreqタグやpriorityタグについては、Googleでは無視される仕様であるため、今回は含めないこととしました。他にもいくつかのタグが存在しますが、それらも今回のサイトマップには含めない方針としています。

次に、最終的に完成したディレクトリ構成についてご紹介します。一番上には、定期的にサイトマップを生成するためのワークフローファイルが配置されています。その下には、サイトマップの生成スクリプトがあります。さらに、その下にはルートごとに個別のパスを定義した部分と、サイトマップを生成するためのロジックが配置されています。
ここからは、最初にサイトマップを作成するためのロジックに関する部分を詳しく説明していきます。
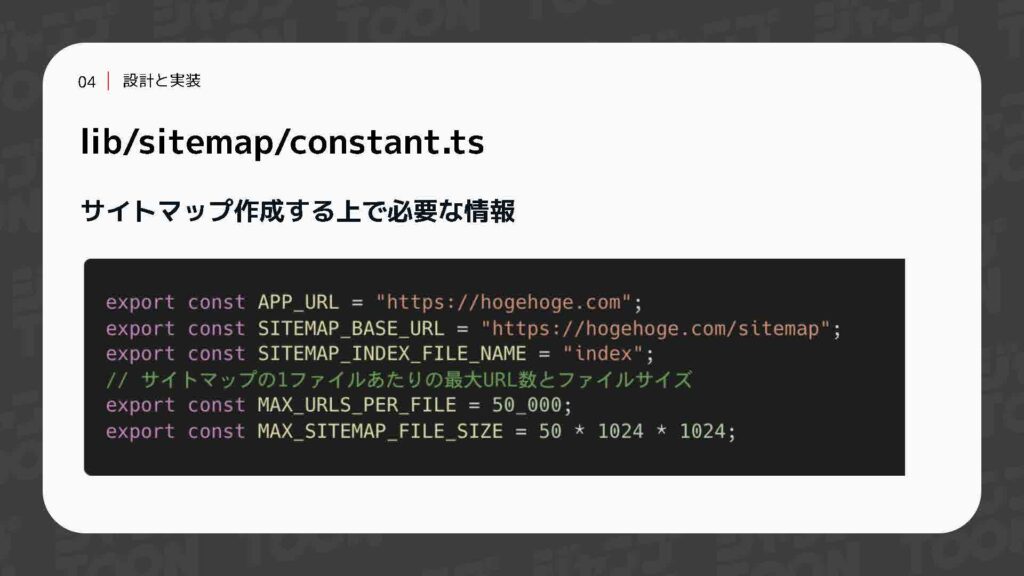
まず、コンスタントファイルを用意しました。このファイルには、サイトマップを作成する際に必要な情報をまとめています。具体的には、ドメイン名やサイトマップのファイル名、一つのファイルに記載できる最大URL数、最大ファイルサイズなどを定義しています。

次に、Sitemap.tsファイル内では、URLと更新日を含むオブジェクトを返すCreateSitemapItem関数を用意しています。この関数は、指定されたパスと日付を受け取り、それをサイトマップファイルに記述できる形式に変換します。先ほどお伝えしたように、URLの更新日以外の情報は今回のサイトマップには不要と判断したため、この関数は非常にシンプルな構造となっています。必要最小限の情報のみを処理することで、効率的かつ分かりやすいコード設計を意識しています。

他にはサーバーからサイトマップを組み立てるための必要なデータが入ったJSONを受け取る関数などがあります。libに置いているのは以上で、SRC配下に置いている箇所を紹介します。こちらではルート個別のサイトマップアイテムというのを作成していきます。

ルーティングに影響を及ぼさないように、ファイル名の先頭にアンダースコア(_)をつけた_sitemap.tsを各ページごとに用意しています。このファイルの内容は非常にシンプルで、先ほど用意したCreateSitemapItem関数にパスと日付を渡した結果をエクスポートする形になっています。サーバーからデータ取得が必要な動的パスの場合は、GetSitemapData関数で取得したデータをCreateSitemapItemに渡して処理する仕組みになっています。
この際、静的パスの生成に関しては非同期にする必要はありませんが、関数のシグネチャを統一しておくことで、他の開発者がサイトマップに新たなパスを追加する際に複製しやすくなるという狙いがあります。次にスクリプトディレクトリについて説明します。このスクリプトディレクトリでは、先ほど用意した各ルートのサイトマップアイテムを結合し、最終的なサイトマップを組み立てる処理を行います。

まず、インデックスファイルの親ファイルについて説明します。Googleはサイトマッププロトコル形式をサポートしているため、この形式に基づいてファイルを生成する関数を用意しています。この関数は、サイトマップ全体を管理する親ファイルを作成し、各分割ファイルへのリンクを記述する役割を果たします。
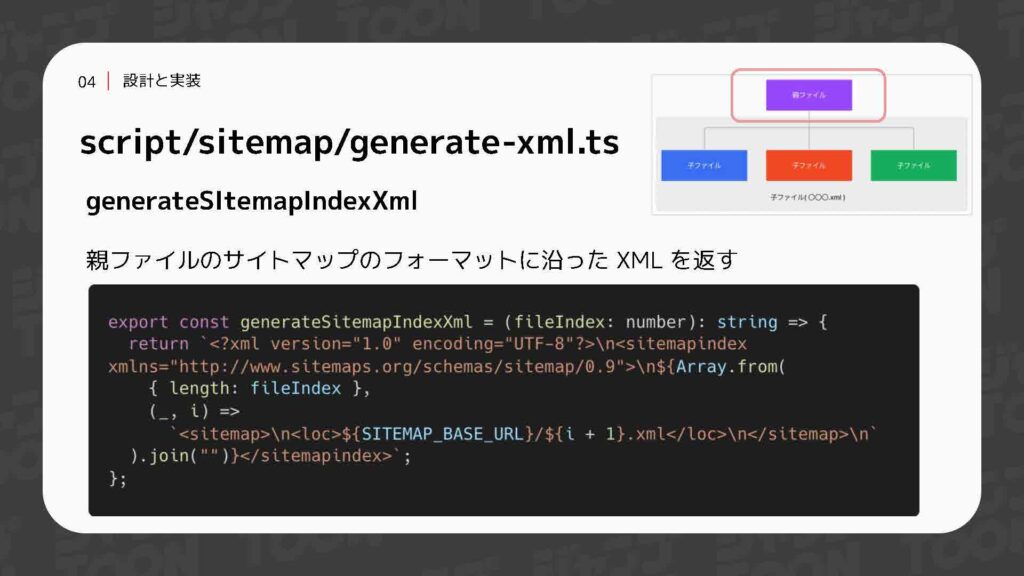
親ファイルに含める個々のファイルについても同様です。これらのファイルもサイトマッププロトコル形式に準拠する必要があるため、同じフォーマットに基づいて形を整える関数を用意しています。
続いて、サイトマップを分割するロジックについて説明します。ここでは、各ルートごとのサイトマップアイテムと出力先のディレクトリを受け取り、条件に応じてファイルへの書き込みを行います。この際、URLの上限数やファイルサイズの制約を考慮して処理を進めるのがポイントです。
具体的には、現在のファイルに含められるURLの数やサイズが上限に達した場合、新しいファイルを作成し、次のサイトマップアイテムの書き込みを開始します。これにより、複数のファイルに分割されたサイトマップが適切に保存されます。

これがファイル書き込みに必要な関数です。具体的には、下記の writeSitemapFile 関数を使用します。この関数は、サイトマップのアイテム、ファイルのインデックス番号、そして保存先のパスを引数として受け取れるようになっています。

最終的に、先ほど紹介したスクリプト部分はここで呼び出します。具体的には、ページごとに用意した _sitemap.ts からサイトマップのアイテムとなるデータを受け取り、それらを結合して saveSplitSitemap 関数に渡すことで処理を完了します。この流れで、分割されたサイトマップが適切な形式で保存されます。
これで大まかなサイトマップの生成プロセスは終了です。
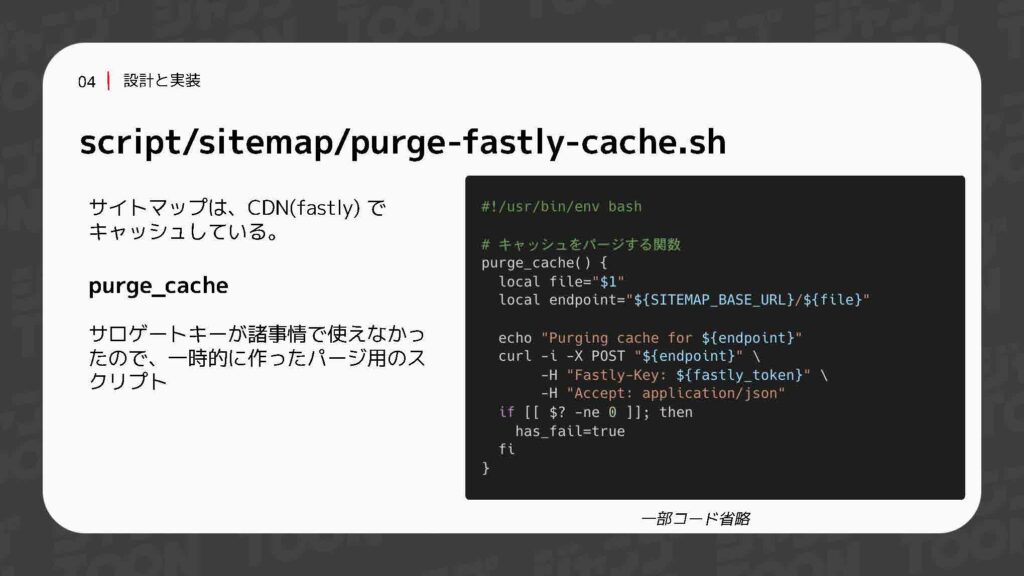
ジャンプTOONでは、CDNにFastlyを利用しており、サイトマップをキャッシュさせています。そのため、キャッシュを適切に更新するためのパージスクリプトも用意しています。このスクリプトでは、分割された複数のサイトマップを順番にパージするロジックを採用しています。
ただし、効率的な運用を考えると、サロゲートキーを活用すれば、分割されたサイトマップ全体を一括でパージすることも可能かと思います。

最後のディレクトリです。このワークフローでは、定期バッチの設定や生成したサイトマップを配信用のGCSにアップロードする処理、さらにはサイトマップ生成に失敗した際の通知処理を行っています。
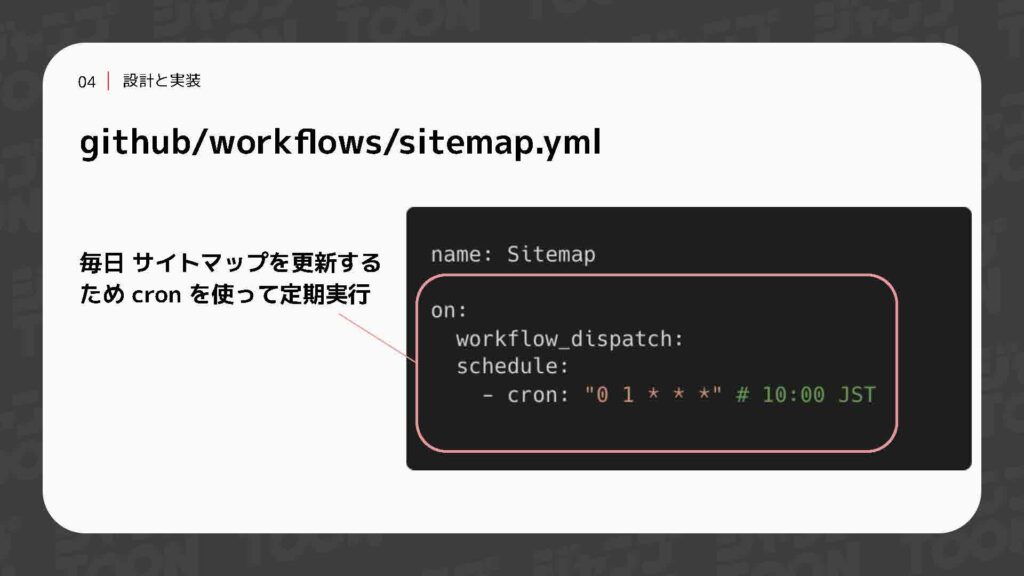
定期バッチはクーロンを使用しており、毎朝10時にこのワークフローが自動で動作するように設定されています。次に、GCSからサイトマップ生成に必要なJSONデータを取得します。このJSONには、サーバー側で用意された話の一覧やIDなどの情報が含まれています。
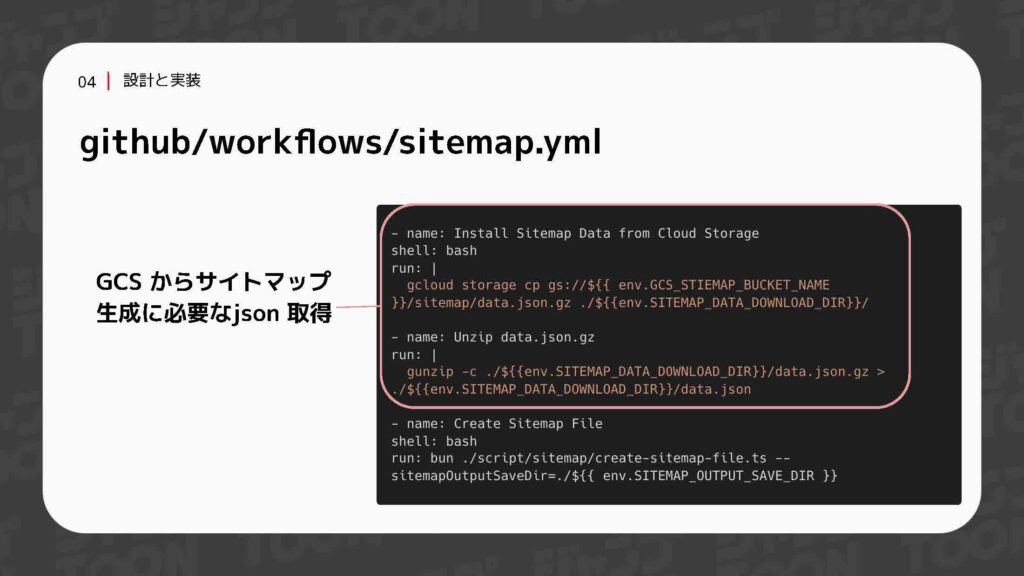
データを取得した後、そのデータをもとにサイトマップを生成します。生成されたサイトマップは配信用のGCSバケットにアップロードします。アップロードが完了したら、キャッシュを削除することで処理が終了します。
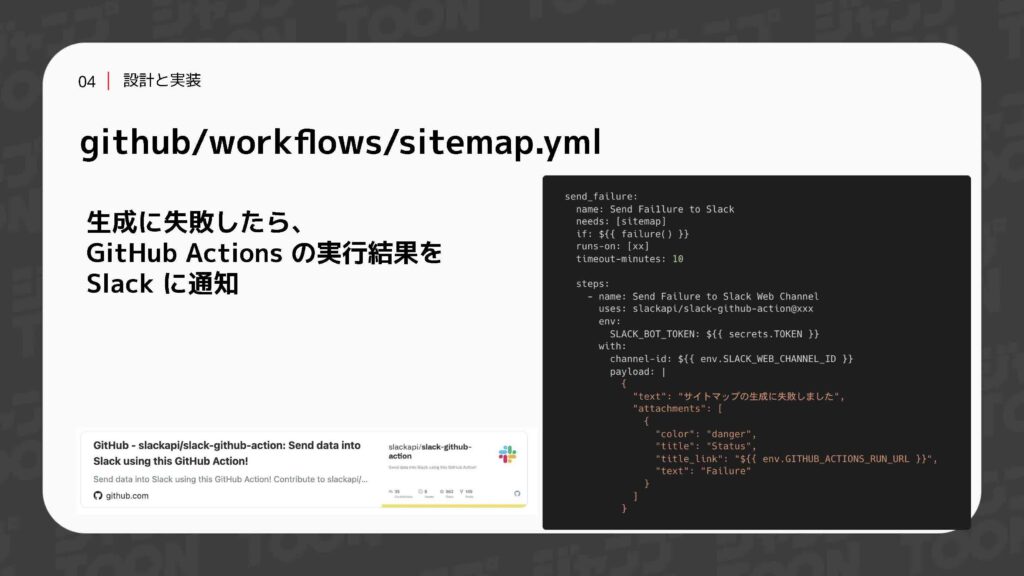
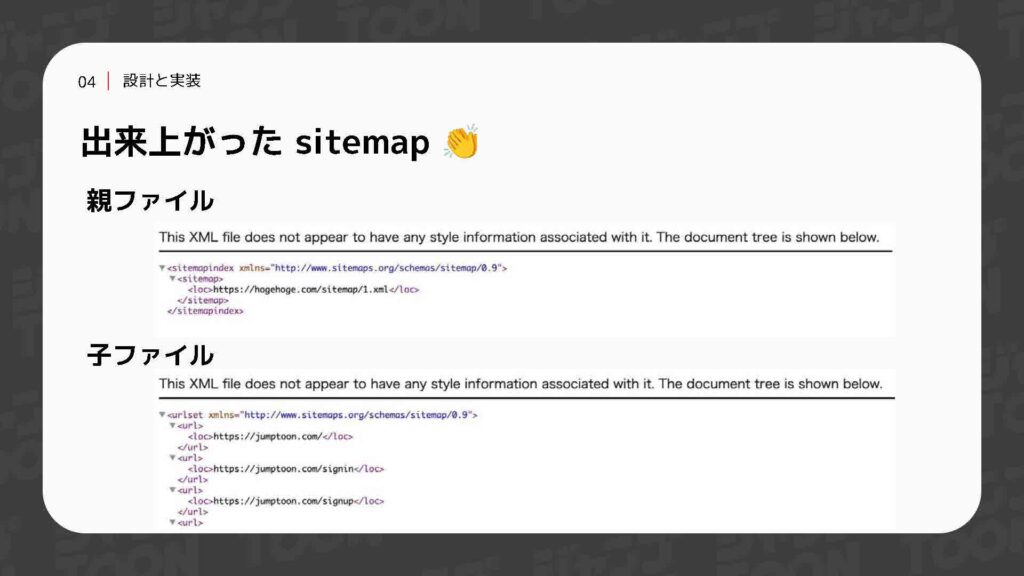
ジョブが失敗した場合に備え、通知を送る仕組みを導入するのも重要です。弊社ではSlackを使用しているため、Slack GitHubアクションを活用して通知を送信するように設定しています。以上のプロセスを経て、ようやく完成したサイトマップがこちらになります。上部に示されているのが親のファイルで、下部が子のファイルになります。
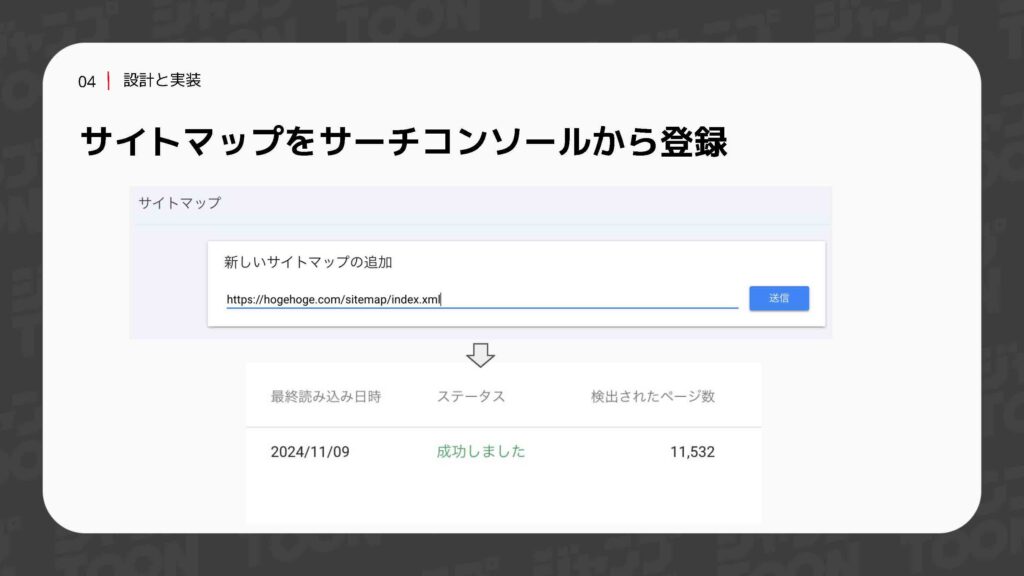
最後に、生成したサイトマップをGoogle Search Consoleに忘れずに登録します。これにより、サイト内のURLが増えた際にも、新しいサイトマップが自動的に生成されるフローが完成しました。
最後にまとめと振り返りです。

今回はライブラリやNext.jsに標準で用意されている機能を使用せず、自作でサイトマップを生成しました。また、漫画の作品や話数が増えた場合でも、自動でスケールするサイトマップファイルの構成を実現しました。副次的な恩恵として、`page.tsx`のそばにサイトマップに含める関数を配置する方針を採用したため、チーム全体の設計方針であるコロケーションの概念とも一致した構成になった点は良かったと思います。
ただし、今回サイトマップを自作したことで、複数のロジックを自前で用意する必要がありました。そのため、テストコードを含めた実装全体が割と大変になってしまった印象があります。特にサイトマップの分割に関するロジックなどは、既存のライブラリを活用する選択肢もあったので、一部取り入れる形でも良かったかもしれません。
最後になりますが、ジャンプTOONで採用されている技術や、Next.jsに関する記事も公開しています。興味がある方はぜひご覧ください。「ジャンプTOON Web 技術」や「Next.js」などのキーワードで検索していただければ、おそらく該当記事が見つかると思います。

以上で発表を終わります。