
こんにちは、株式会社AJA の SSP Division でバックエンドエンジニアをしている、サイバーエージェント2024新卒の石上敬祐(@kei01234kei)です。 本記事では、私が配属されてからの初タスクで「数万 QPS をさばく広告配信サーバのリクエスト制御」に取り組んだ話をご紹介します。
目次
- タスク背景
- 既存の QPS 制御の仕組み
- 新 QPS 制御の基本的な設計
- 実装の中で直面した問題
- アドサーバ pod の IP アドレスを中間コンポーネント側が知る方法
- ターゲット PPM がマイナスになってしまう
- QPS がマイナスになってしまう問題を解決する
- 新 QPS 制御の実装後のメトリクス
- まとめ
- おわりに
タスク背景
AJA SSP では、Real Time Bidding における SSP(Supply Side Platform)を提供しています。AJA SSP が接続しているメディアにユーザが来訪し、広告枠が発生するとメディアから AJA SSP へ広告のリクエストが送信され、このリクエストを受け取った SSP サーバは DSP サーバに対して広告枠の買い付け募集を行います。この「広告枠の買い付け募集」をビッドリクエストと呼びます。
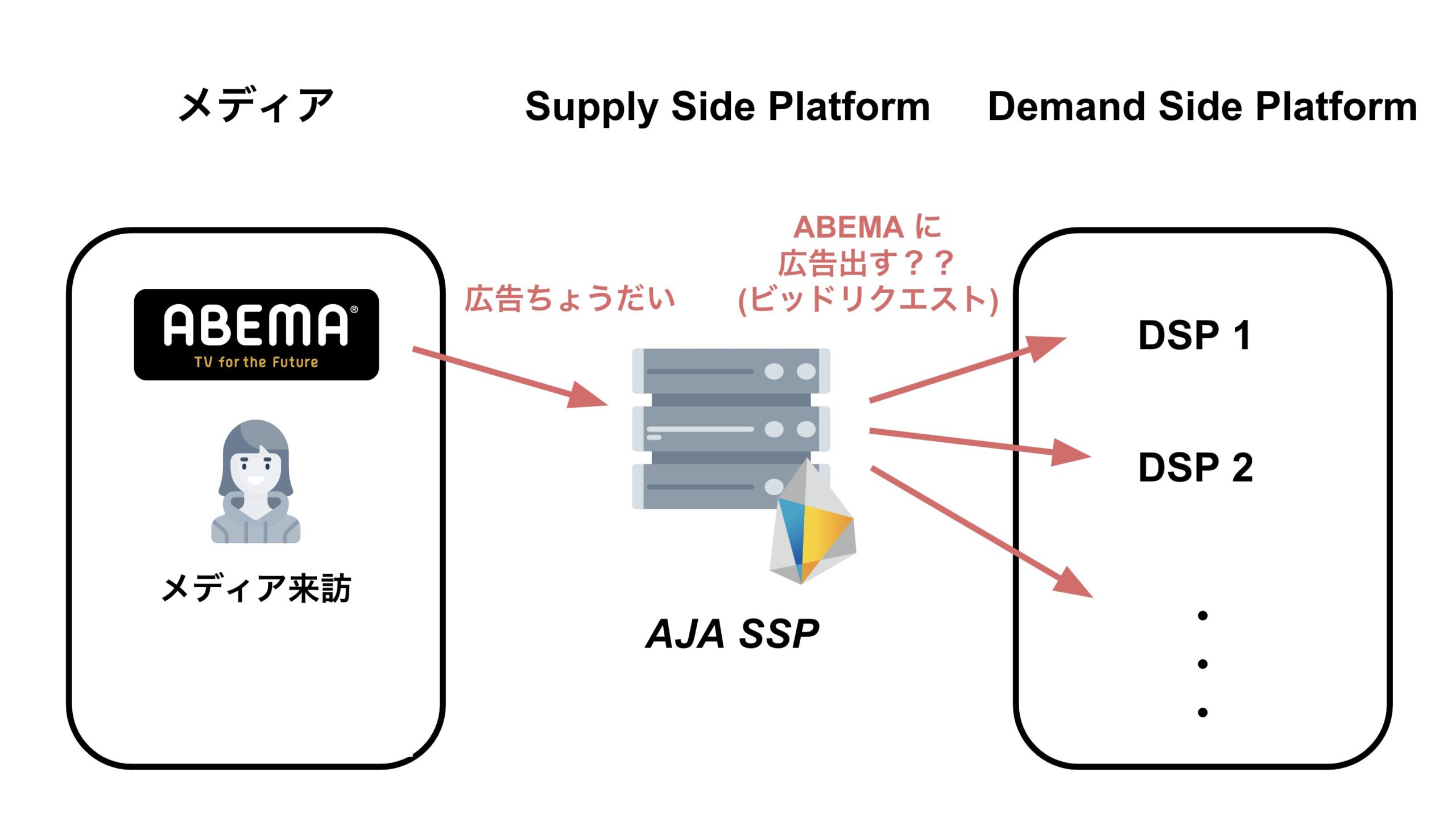
この仕組みの問題は、人気ドラマやスポーツイベント、重大なニュースなど、メディアにユーザが集中するタイミングでメディアから SSP への広告リクエストが急増し、それに伴いビッドリクエストも急増します。このような状況下では DSP サーバに大きな負荷がかかってしまいます。
(QPS とは Query Per Second の略で、アドテク文脈では RPS(Request Per Second)と同じ意味として使われます。)

ビッドリクエストの QPS を一定値以下に抑える仕組みはすでに存在したのですが、この仕組みはコスト、そして QPS 制御の精度に大きな改善の余地がありました。そこで、私は QPS 制御の仕組みを刷新し、精度改善に取り組みました。
既存の QPS 制御の仕組み
前提として、本 QPS 制御において重要な値である ターゲット PPM についてご説明します。(PPM とは parts per million、つまり100万分率のことです。)
QPS 制御を実現するために、「ビッドリクエストを確率的に送る」というアプローチを私たちはとっています。例えば、DSP A の ターゲット PPM が 750,000 であれば、DSP A に対してリクエストを送る際に、当選確率が75%の抽選を毎回行い、当選した場合にのみリクエストを送るようにしています。
ターゲット PPM は簡単な式で算出されており、ビッダーの許容 QPS(DSP からの「ビッドリクエストはこの QPS までに抑えてね!」と要請された値)を $BM$ 、直近のビッドリクエストの QPS を $qps$ とすると、ターゲット PPM 、 $p$ は以下の式で表せます。
$$ p = \min(\frac{BM}{qps}, 1) \times 1,000,000 $$
例えば、DSP A の $BM$ が 100 で、直近の DSP A へのビッドリクエストの $qps$ が 300 であれば、
$$ p = \min(\frac{100\;}{300\;}\;, 1) \times 1,000,000 = 333,333 $$
となり、DSP A へのビッドリクエストは 約 33% の確率で送られるようになります。
この式からわかることは、 ビッドリクエストの QPS 制御の精度を上げるには、より正確な $p$ を求めることが重要。そして、より正確な $p$ を求めるには、より正確な $qps$ を求めることが重要であるということです。なぜなら、$BM$ は定数であり、$p$ を求める式での変数は $qps$ のみだからです。
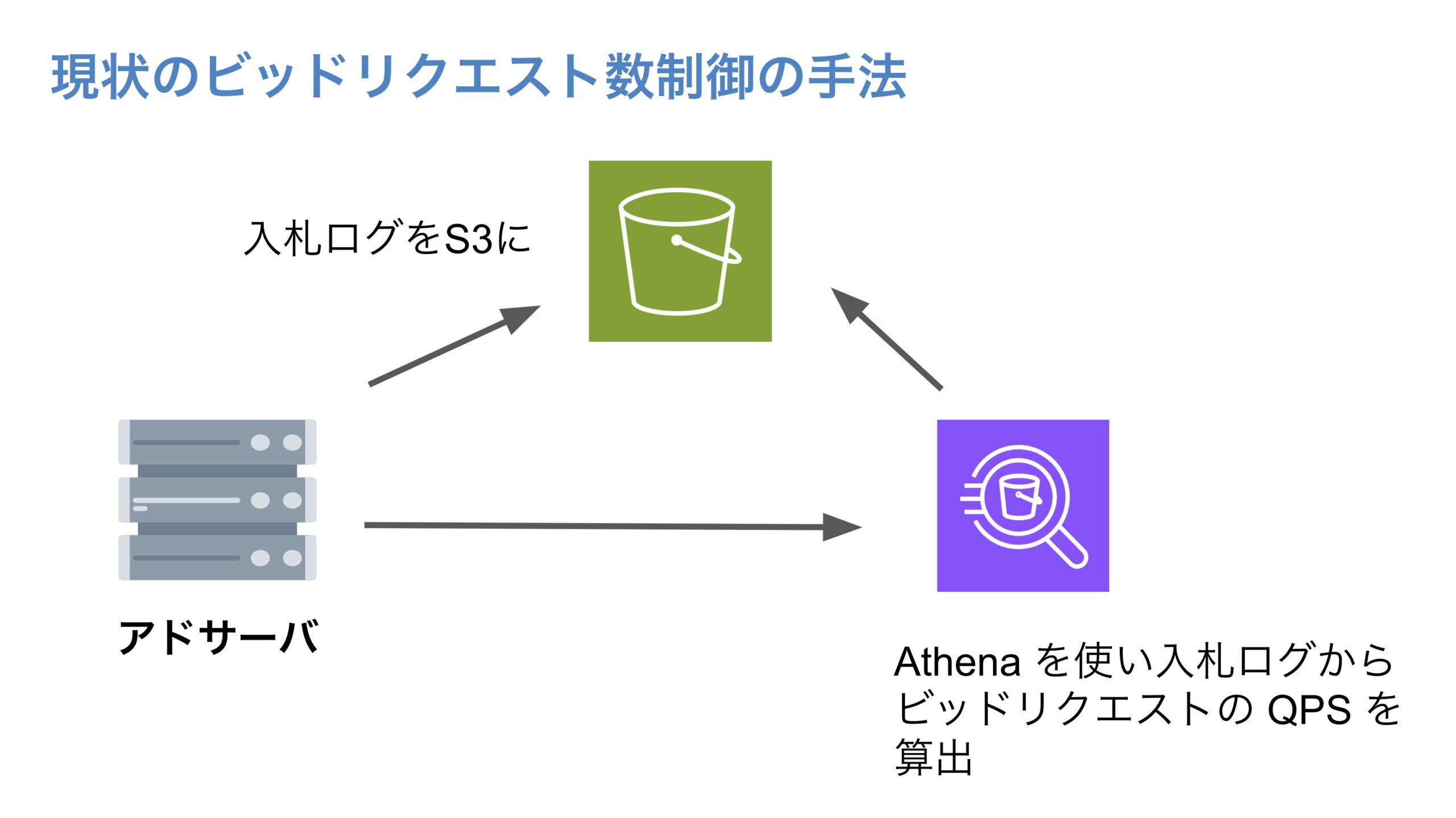
既存の QPS 制御の制御の仕組みではビッドリクエストに関するログ(入札ログ)を Amazon S3(以下S3)に吐き、そのログを Amazon Athena(以下Athena) からクエリを叩き、ビッドリクエストの QPS を算出していました。しかし、S3 に吐かれる入札ログの量は膨大なものであり、そのログに対して Athena からクエリを叩いて $qps$ を算出するのには時間がかかってしまい、瞬間的な QPS を求めることは難しい状況でした。
また、既存の仕組みでは、$qps$ は、十数分前のビッドリクエスト数を集計し、1秒間の平均に直したものとなっており、この 新鮮ではない $qps$ を使って算出された $p$ では正確な QPS 制御が難しいという課題がありました。
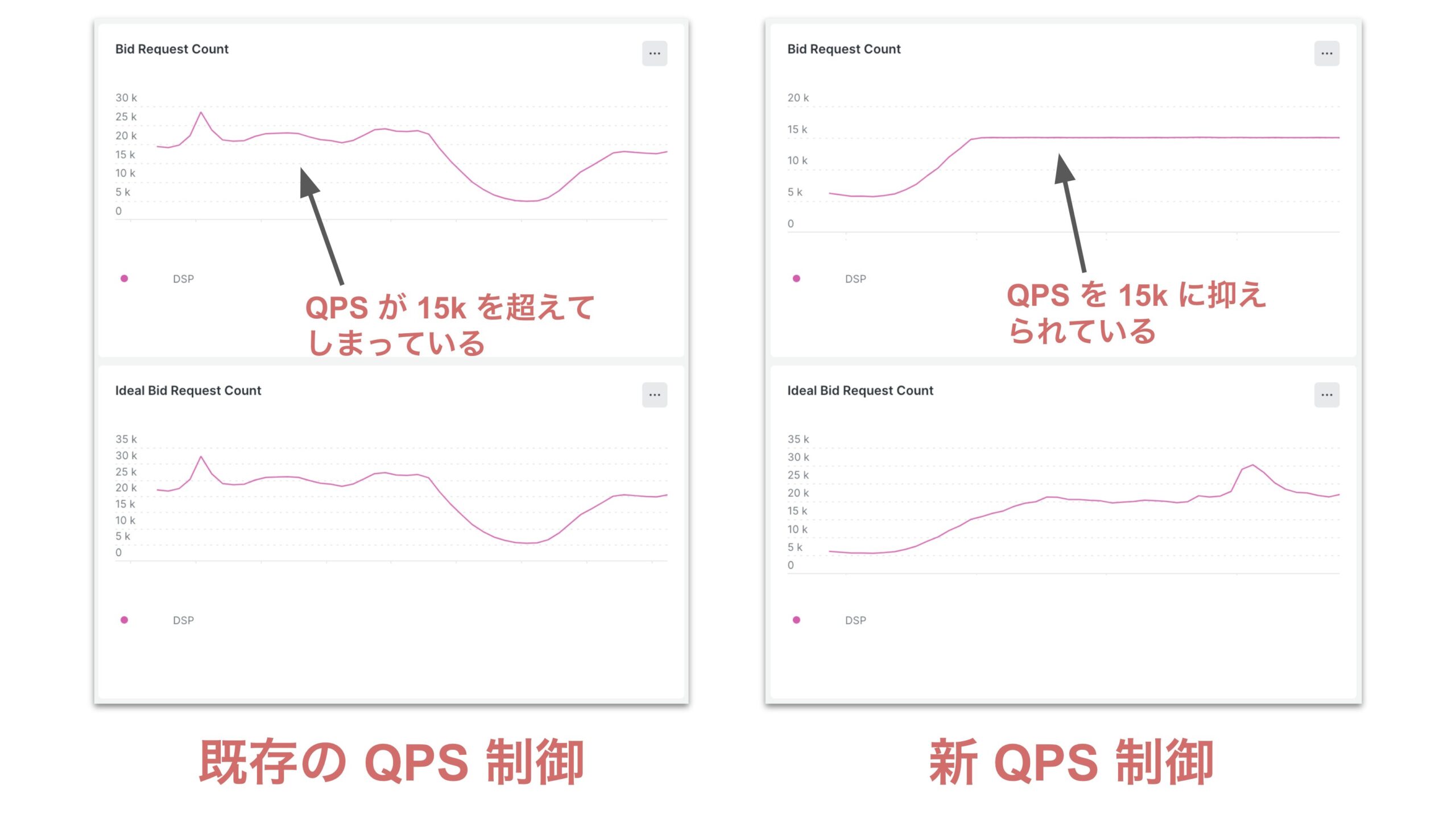
既存の QPS 制御の精度の雰囲気を感じるためのメトリクスを用意しました。下の 「既存の QPS 制御と新 QPS 制御のメトリクス」をご覧ください。
(こちらは新 QPS 制御実装後の動作テスト時に計測したものです。)
Bid Request Count は実際に送られたビッドリクエスト数、Ideal Bid Request Count はリクエストが何もフィルタリングされない場合に送られるはずだったビッドリクエスト数を表しています。
メトリクスに載っている DSP へのビッドリクエストは 15,000 QPS まで抑えないといけないのですが、既存の QPS 制御ではビッドリクエストが 15,000 QPS を超えてしまっています。しかし、新 QPS 制御ではビッドリクエストが一貫して 15,000 QPS に抑えられていることがわかります。
それでは、どのようにして精度の高い QPS 制御を実装したのかをご説明していきます。
新 QPS 制御の基本的な設計
新 QPS 制御の基本的な設計は先輩から頂いており、この設計を解説していきます。
まず、それぞれのアドサーバが「ビッドリクエストをどれくらい送っているのか」を集計するための中間コンポーネントを作成します。その中間コンポーネントがアドサーバの /metrics エンドポイントを1秒間に1回叩き、それぞれのアドサーバが 起動してから現在までにどれくらいリクエストを送ったか(リクエストの累積和) を取得します。
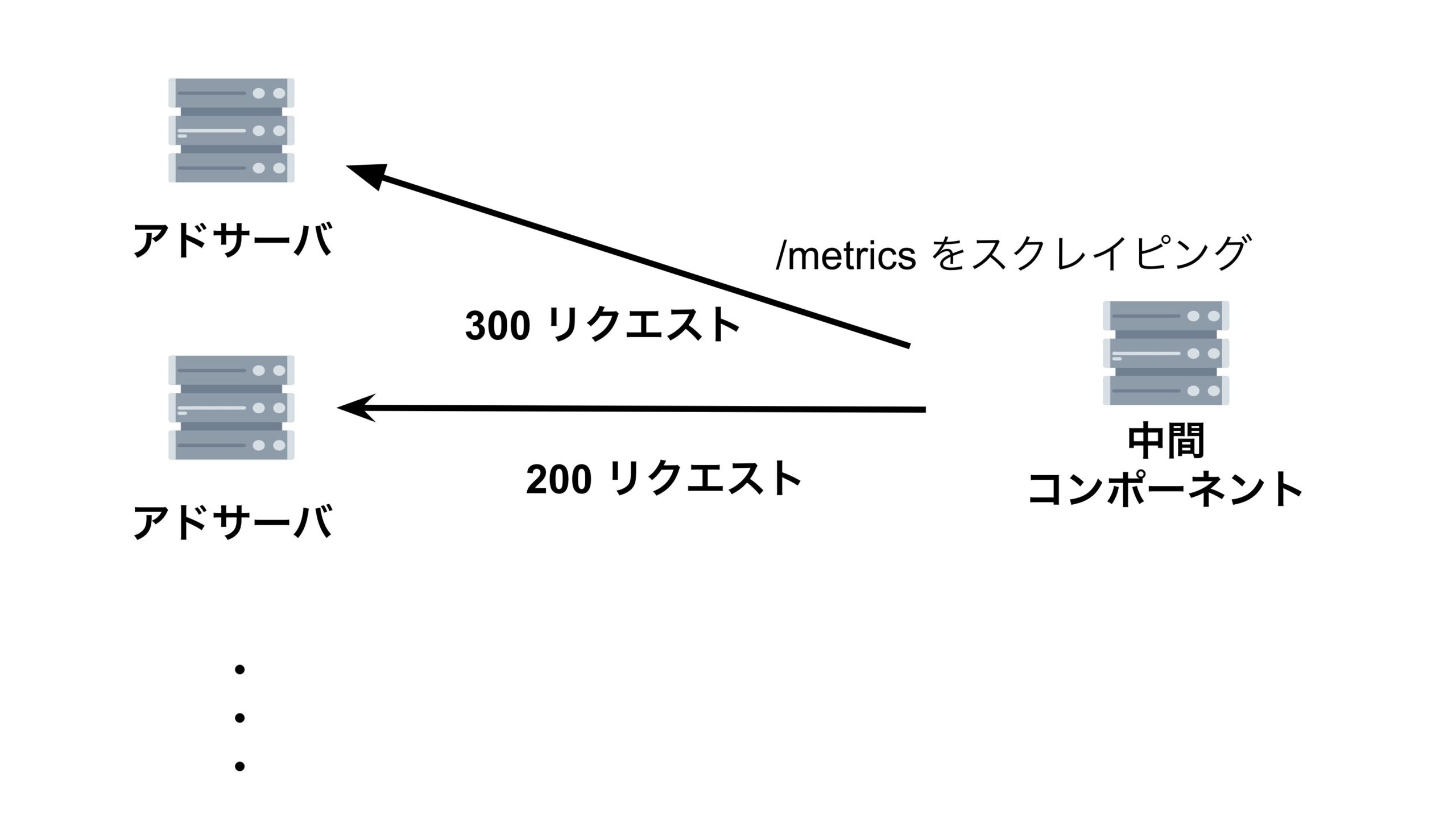
アドサーバは1秒間に1回、中間コンポーネントが集めた、全てのアドサーバのリクエストの累積和を取得します。そして、アドサーバは中間コンポーネントから取ってきた値から、1秒前に中間コンポーネントから取ってきた値を引いて、1秒間のリクエスト数を算出します。この値が $qps$ となっています。
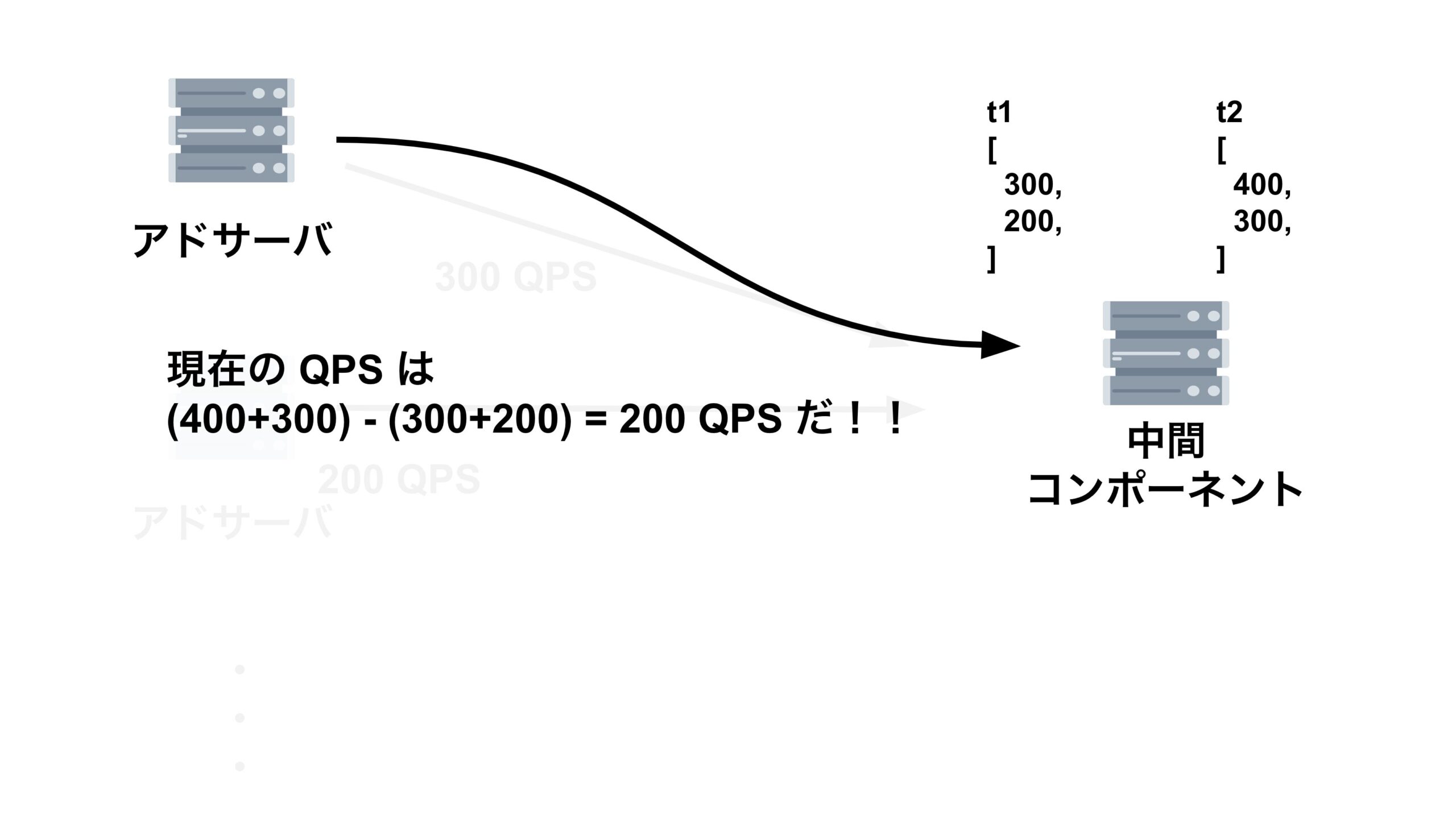
求めた $qps$ を下の式に代入し、$p$ を求めます。そして、$p$ を使って確率的にビッドリクエストを送信します。
$$ p = \min(\frac{BM}{qps}, 1) \times 1,000,000 $$
入札ログから Athena を使い QPS を求める手法ではなく、QPS 制御用の仕組みを新たに作成することで QPS 制御の精度を上げることができています。また、ビッドリクエスト数のカウンタをデルタ値ではなく累積和として持つことで、 Prometheus SDK のカウンターメトリクスを使うことができ、カウンタを自分で実装する必要がなくなりました。
実装の中で直面した問題
新 QPS 制御の実装にあたり、以下の2つの問題に直面しました。
- アドサーバ pod の IP アドレスを中間コンポーネント側が知る方法
- ターゲット PPM がマイナスになってしまう
アドサーバ pod の IP アドレスを中間コンポーネント側が知る方法
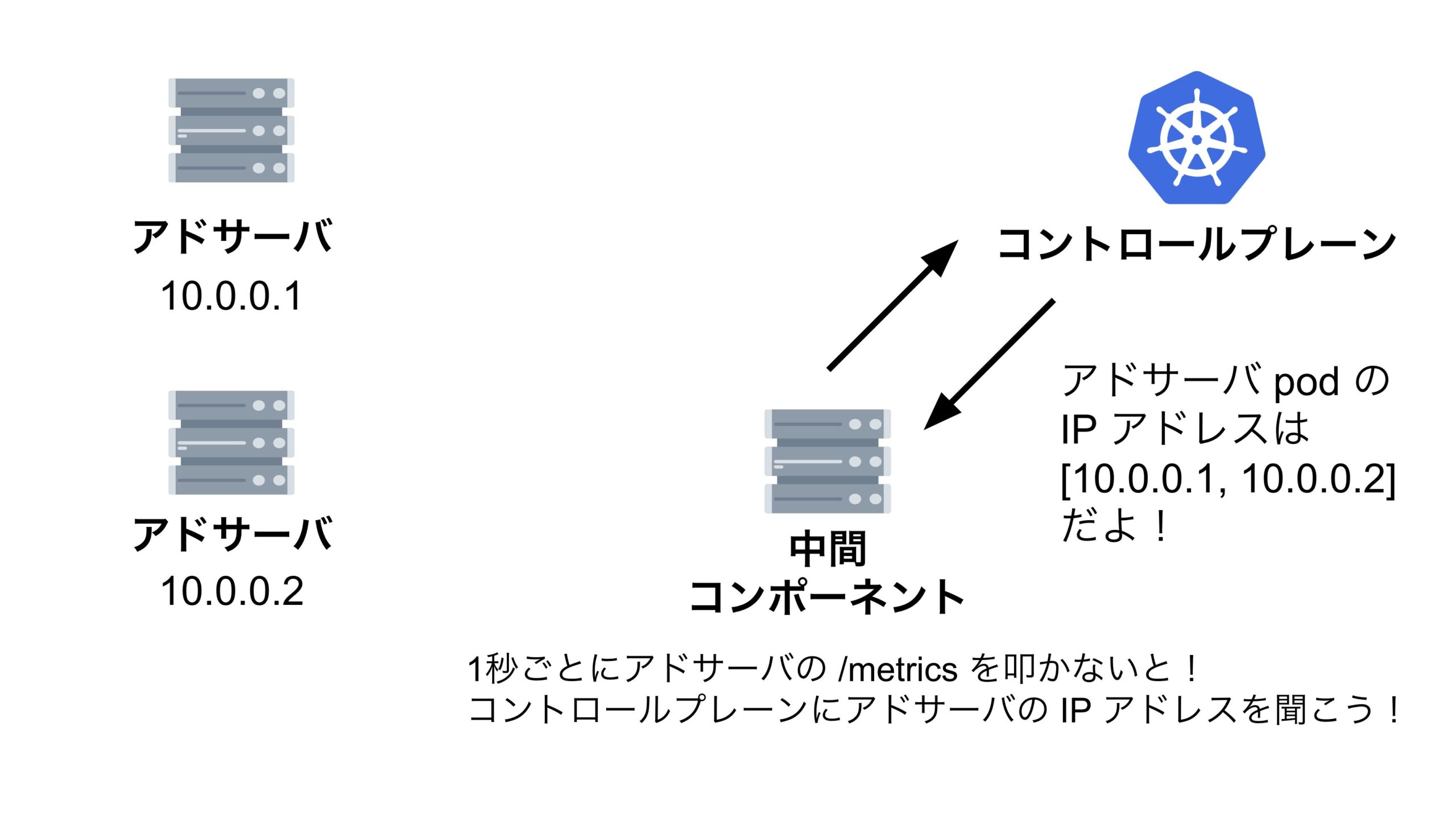
中間コンポーネントがアドサーバの /metrics エンドポイントを叩くためには、アドサーバの IP アドレスを知る必要があります。
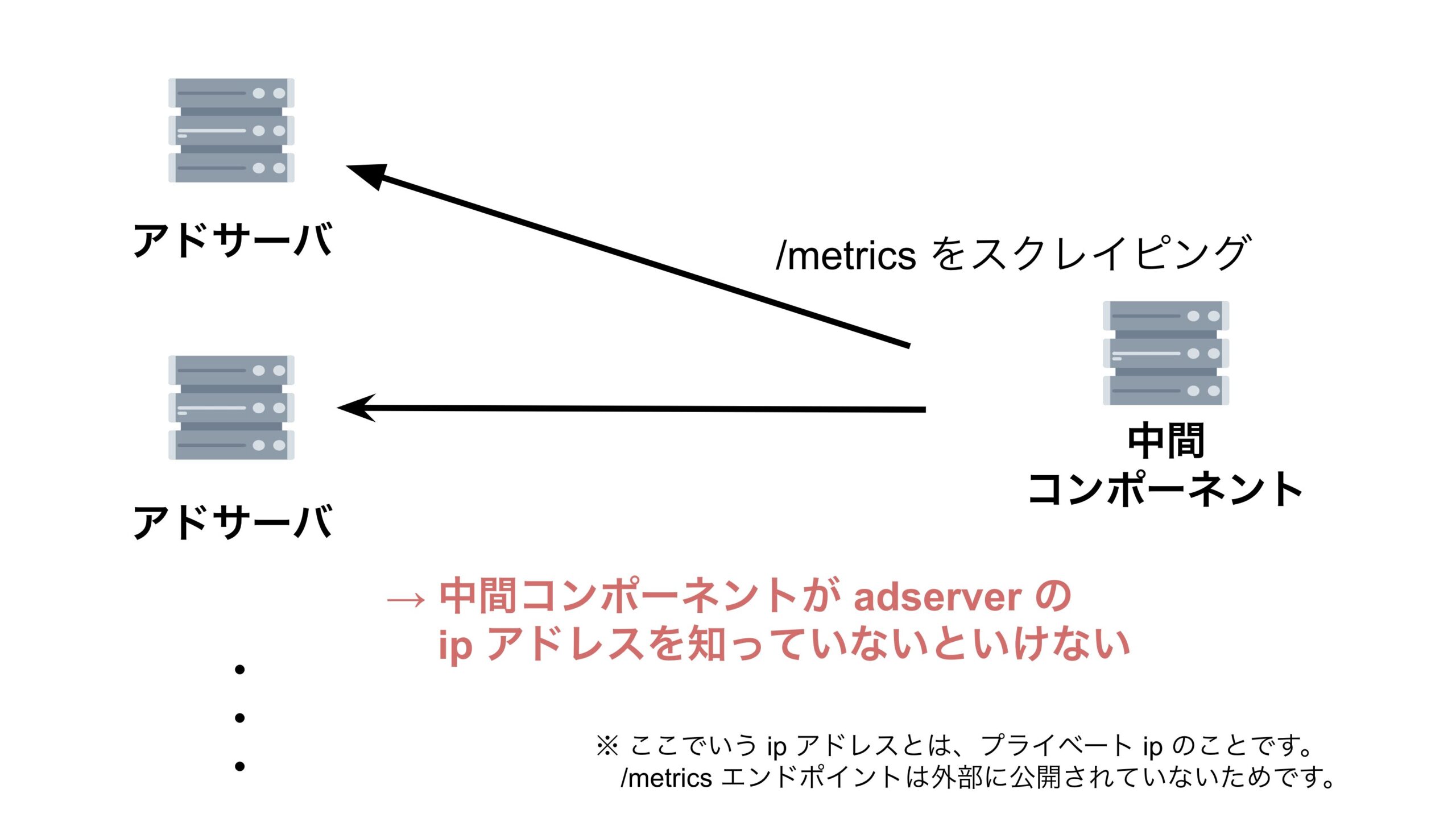
弊開発チームのアドサーバは EKS 上で動いており、中間コンポーネントがアドサーバの IP アドレスを知るには以下の2つの選択肢がありました。
- Headless Service を使う
- コントロールプレーンに問い合わせる
先に結論を述べると、「コントロールプレーンに問い合わせる」方の手法を採用しました。では、なぜ Headless Service を使わなかったのかの解説をします。
そもそも Headless Service とは
Headless Service とは DNS を使用して Service に関連付けられた Pod の IP アドレスを公開してくれるというものです。
参照: https://cloud.google.com/kubernetes-engine/docs/concepts/service?hl=ja#headless_service
これだけ聞いてもピンとこないと思うので、下の画像をご覧ください。
headless-deployment-* という pod は headless-deployment という deployment が管理している pod です。この deployment は headless-svc という Headless Service に関連付けられています。
これにより、同 namespace 内にある pod から headless-svc を nslookup すると headless-deployment が管理している pod の IP アドレスの一覧を取得することができます。
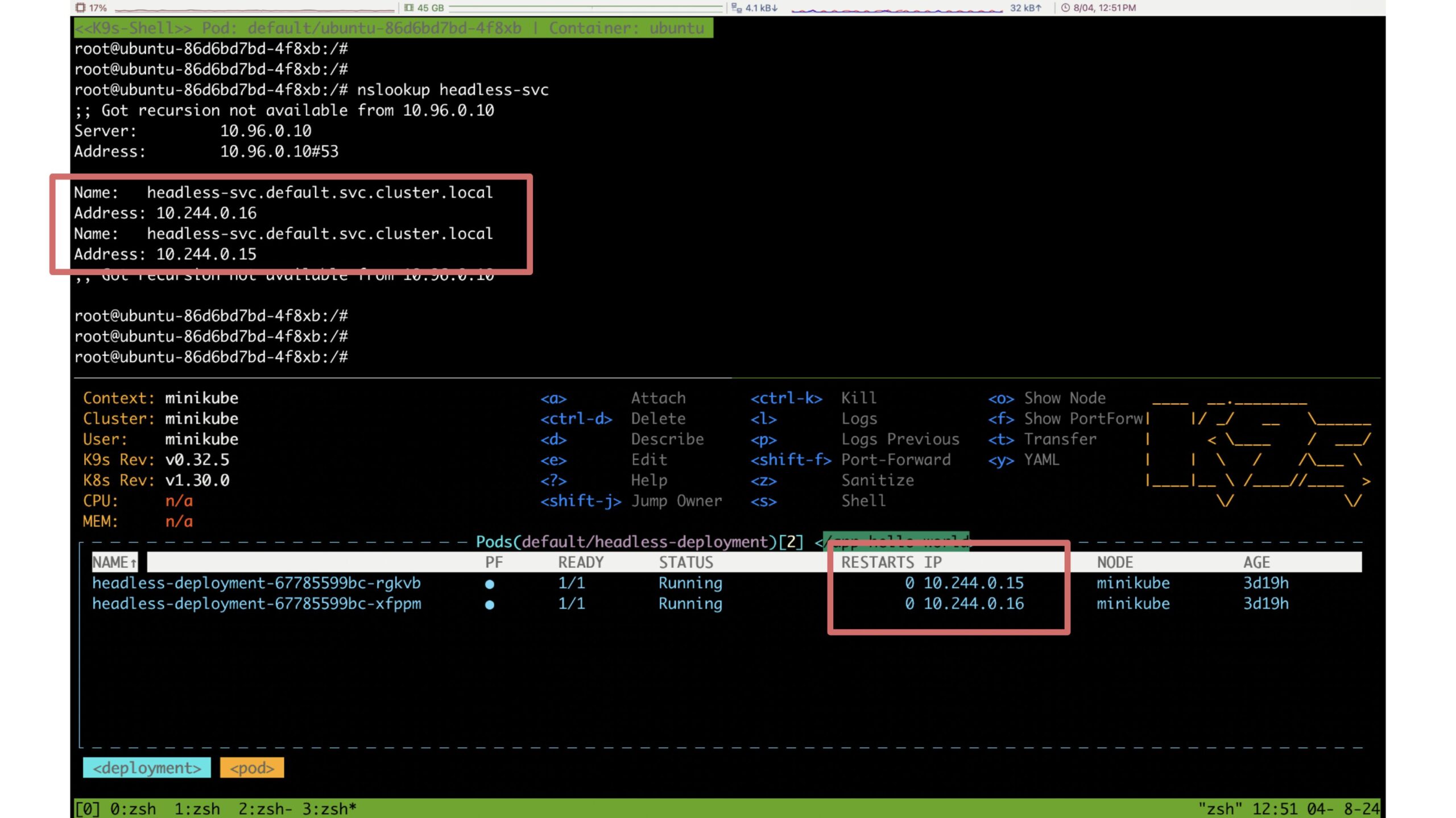
つまり、Headless Service にアドサーバの deployment を関連づけ、その Headless Service に問い合わせることでアドサーバの pod 全ての IP アドレスを知ることができます。
よさそう😀
しかし、Headless Service を使うことによる落とし穴がありました。新しく作成された pod の IP アドレスの取得に時間がかかるという問題が発生してしまったのです。
Headless Service の落とし穴
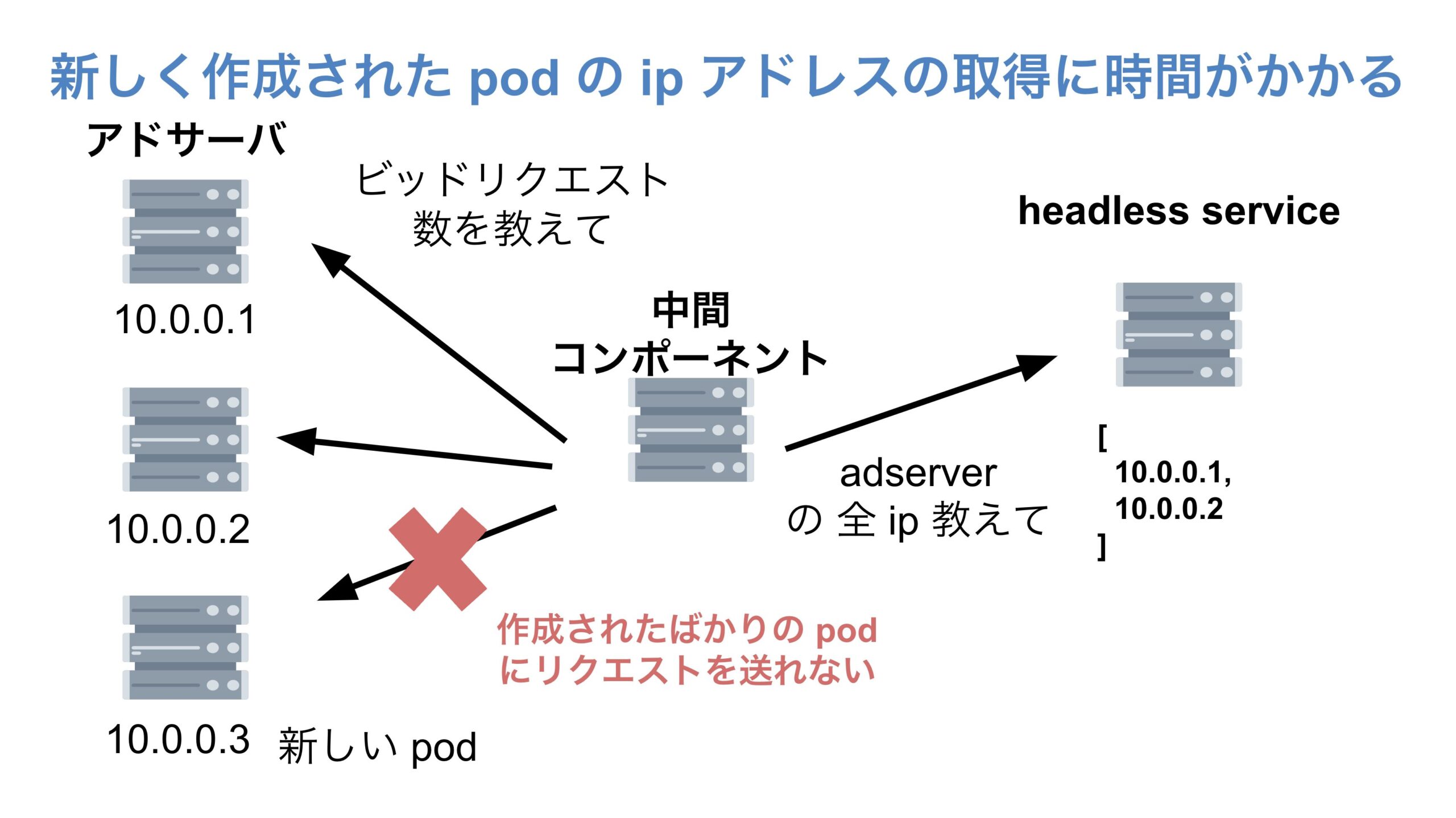
新規の pod の IP アドレスの取得に時間がかかることによる問題は、特にリクエストが急増するタイミングなど、新規の pod がたくさん作成されるタイミングで顕著になります。
なぜかというと、新規の pod はすでにビッドリクエストを送っているのに中間コンポーネントは新規の pod の IP アドレスを知ることができず、新規の pod が送っているビッドリクエスト数を中間コンポーネントは知ることができない。それに加え、ビッドリクエスト数を中間コンポーネント側で知ることができない対象の pod が1つだけでなく、たくさんある。という状況が発生してしまうからです。
pod が新しく作成されてから中間コンポーネントがその新規の pod の IP アドレスを知るまでのタイムラグが1~3秒程度の比較的短い時間であればまだ許容できます。しかし、実際にはこのタイムラグは1~30秒程度であり、QPS 制御の精度を保つためにこのタイムラグは許容できませんでした。
Headless Service と CoreDNS のキャッシュ
ではなぜ中間コンポーネントが Headless Service を使って新規の pod の IP アドレスを取得する際に時間がかかってしまうのか。先に結論を述べると、CoreDNS のキャッシュ TTL が原因でした。
先に述べたように、「Headless Service とは DNS を使用して Service に関連付けられた Pod の IP アドレスを公開してくれる」というものです。
また、弊チームでは EKS を使用しており、EKS はクラスターデプロイ時に CoreDNS イメージをデプロイします。そして、CoreDNS の Pods は、クラスター内のすべての Pods の名前解決を行います。
参照: https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/managing-coredns.html
CoreDNS にはキャッシュ機能があり、レコードデータを一定時間キャッシュすることができます。
参照: https://coredns.io/plugins/cache/
弊チームでは CoreDNS configmap の cache が30秒に設定されていました。この設定により、新規の pod の IP アドレスを取得する際のタイムラグが1~30秒となってしまっていたのです。
この状況において、タイムラグを短くするために取れる選択肢は以下の2つでした。
- CoreDNS cache プラグインの disable オプションを使い、対象 Headless Service のキャッシュを無効にする
- Headless Service を使わず、コントロールプレーンに問い合わせてアドサーバの IP アドレスを取得する
この2つであればどちらを選んでも良いとは思いますが、「Headless Service というコンポーネントを減らすことができる。つまり、コンポーネントを減らし、よりシンプルな構成にできる。」という理由から、私は「コントロールプレーンに問い合わせる」方の手法を選びました。
これにより、無事、ほぼリアルタイムで中間コンポーネントはアドサーバの IP アドレスを取得し、アドサーバの /metrics エンドポイントをスクレイピングできるようになりました。
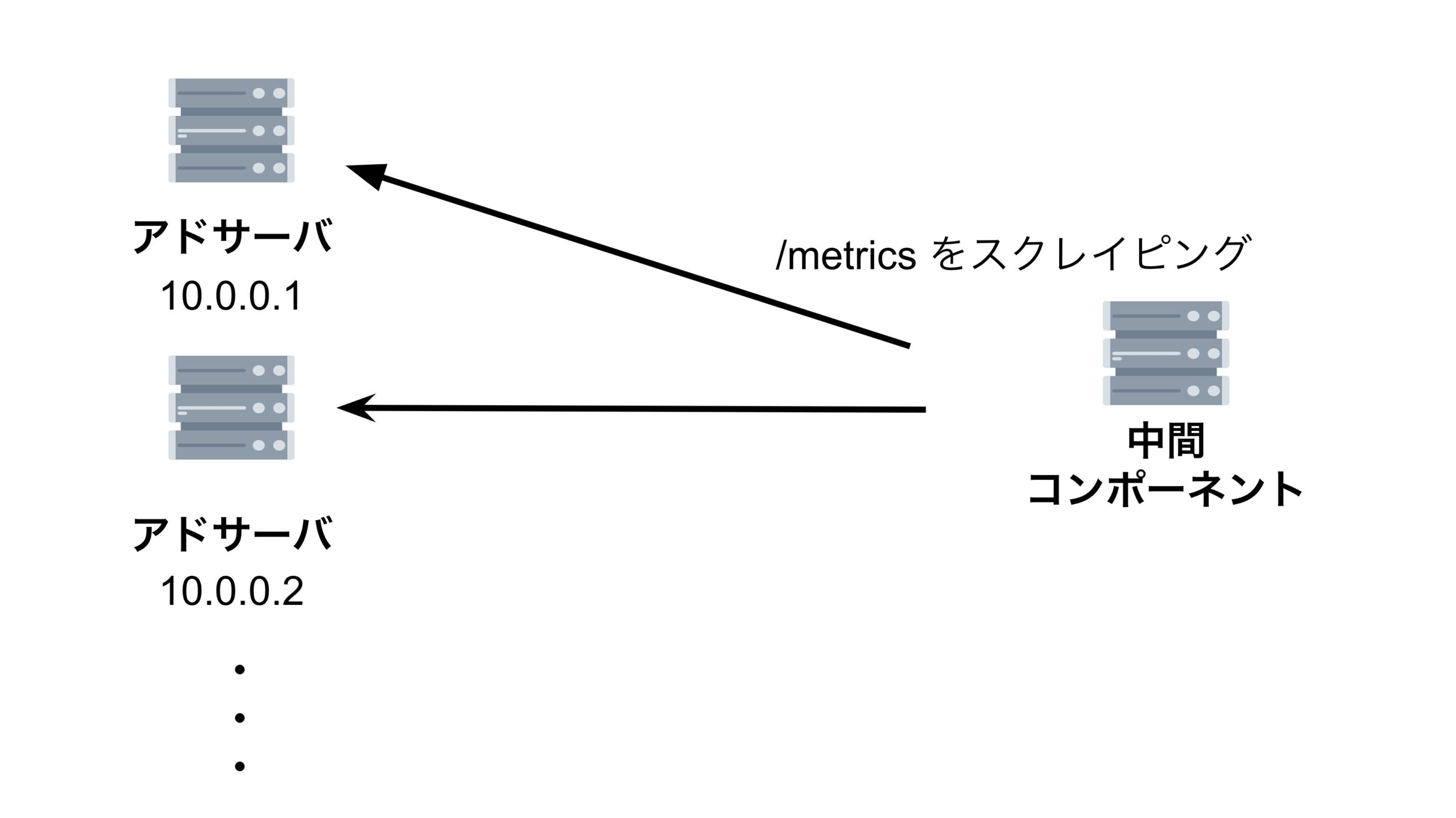
全アドサーバが送っているリクエスト数を取得することができるようになったのですが、ここで「ターゲット PPM がマイナスになってしまう」という問題に直面してしまうのでした。
ターゲット PPM がマイナスになってしまう
本記事の最初にご説明したように、ビッダーの許容 QPSを $BM$ 、直近のビッドリクエストの QPS を $qps$ とすると、ターゲット PPM 、 $p$ は以下の式で表せます。
$$ p = \min(\frac{BM}{qps}, 1) \times 1,000,000 $$
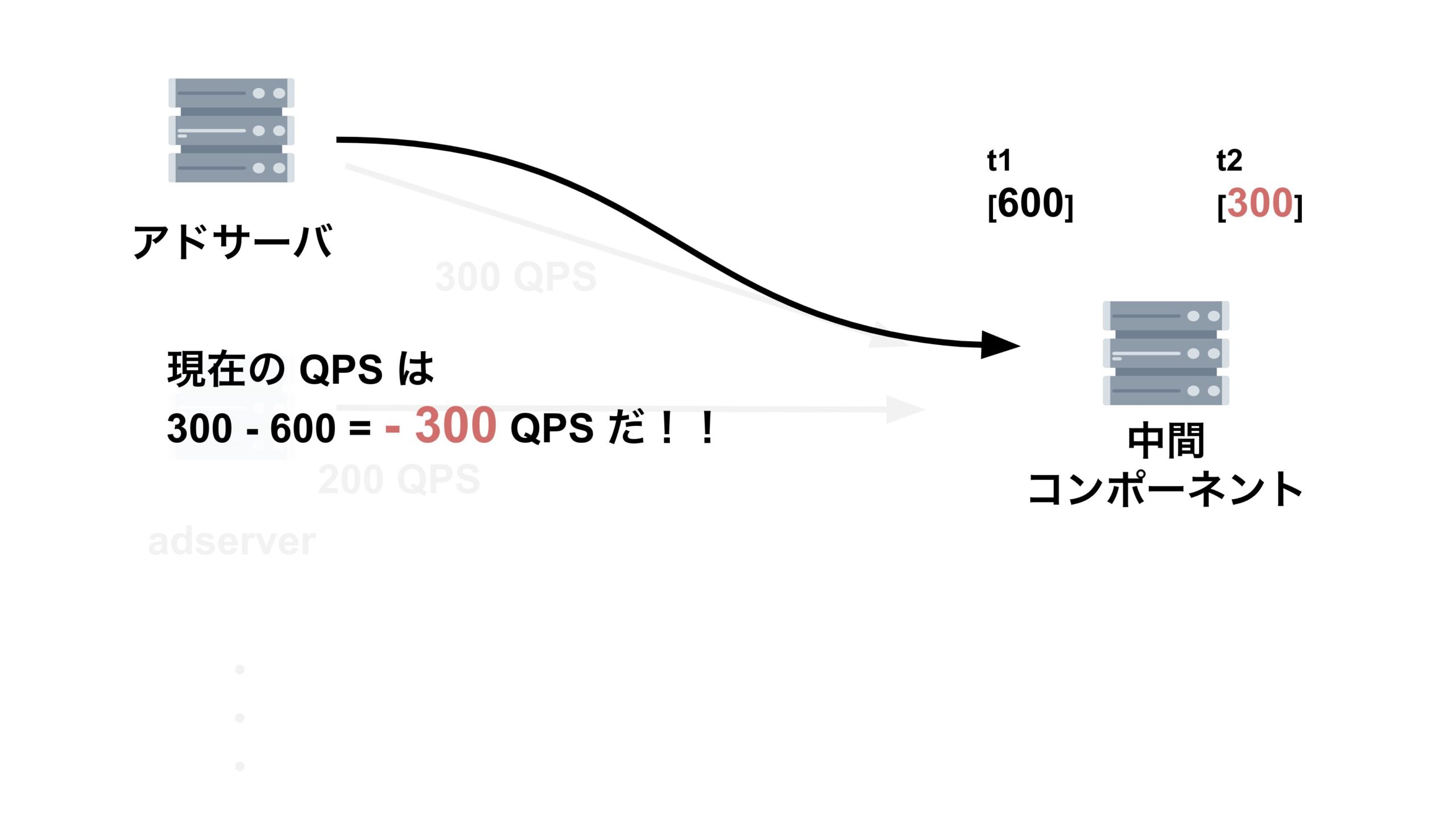
この式において、$BM$ は定数であり、変数は $qps$ のみです。つまり、ターゲット PPM である $p$ がマイナスになってしまうということは。$qps$ の算出ロジックに問題が発生してしまっている可能性が高いです。実際、この仮説は正しく、$qps$ の算出ロジックに問題が生じていました。
アドサーバは1秒間に1回、中間コンポーネントが集めた、全てのアドサーバによるリクエストの累積和を取得します。そして、アドサーバは中間コンポーネントから取ってきた値から、1回前に中間コンポーネントから取ってきた値を引いて、1秒間のリクエスト数を算出します。この値が $qps$ です。
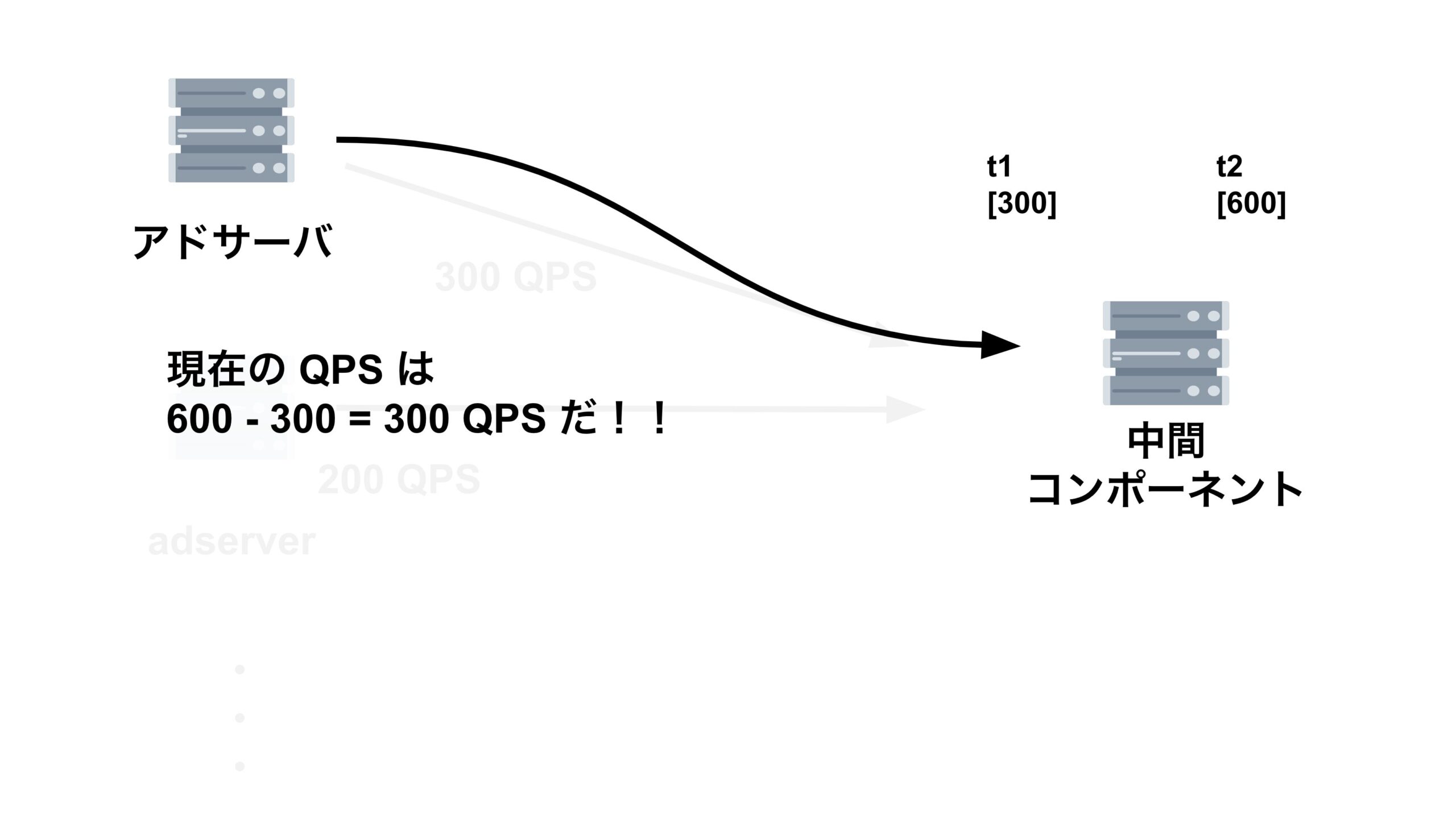
今回はリクエストの累積和の時系列が逆転してしまう現象が起きており、 $qps$ がマイナスになってしまっていたのです。
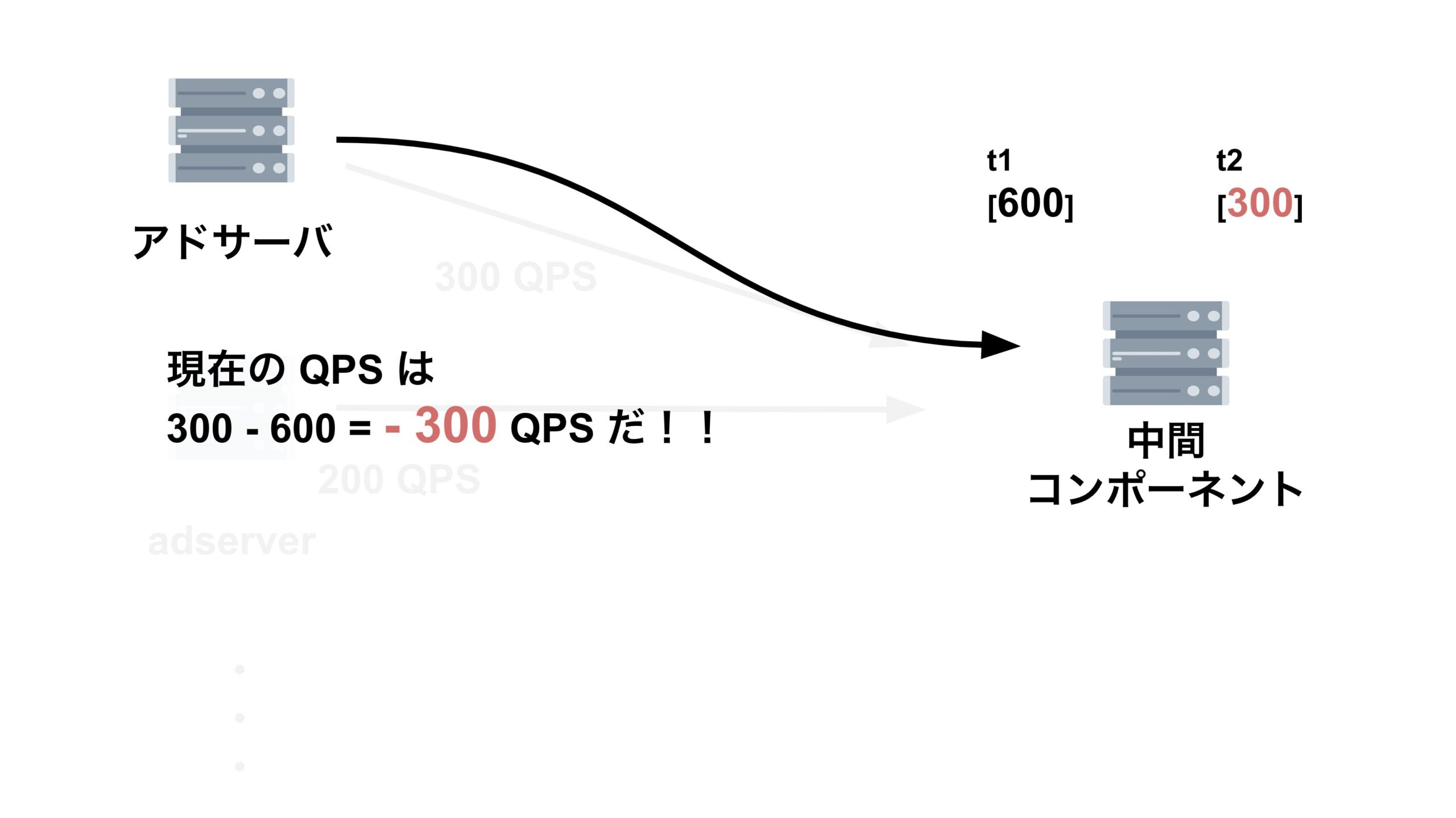
ではなぜリクエストの累積和の時系列が逆転する現象がおきてしまっていたのでしょうか。
結論、縮退対象のアドサーバに対して中間コンポーネントがリクエストを送信した際に、レスポンスがなかなか返って来ず、その間に中間コンポーネントが次のリクエストを送信してしまっていたため、リクエストの累積和の時系列が逆転してしまっていたのです。
この現象を分かりやすく解説するためにスライドを作りました。
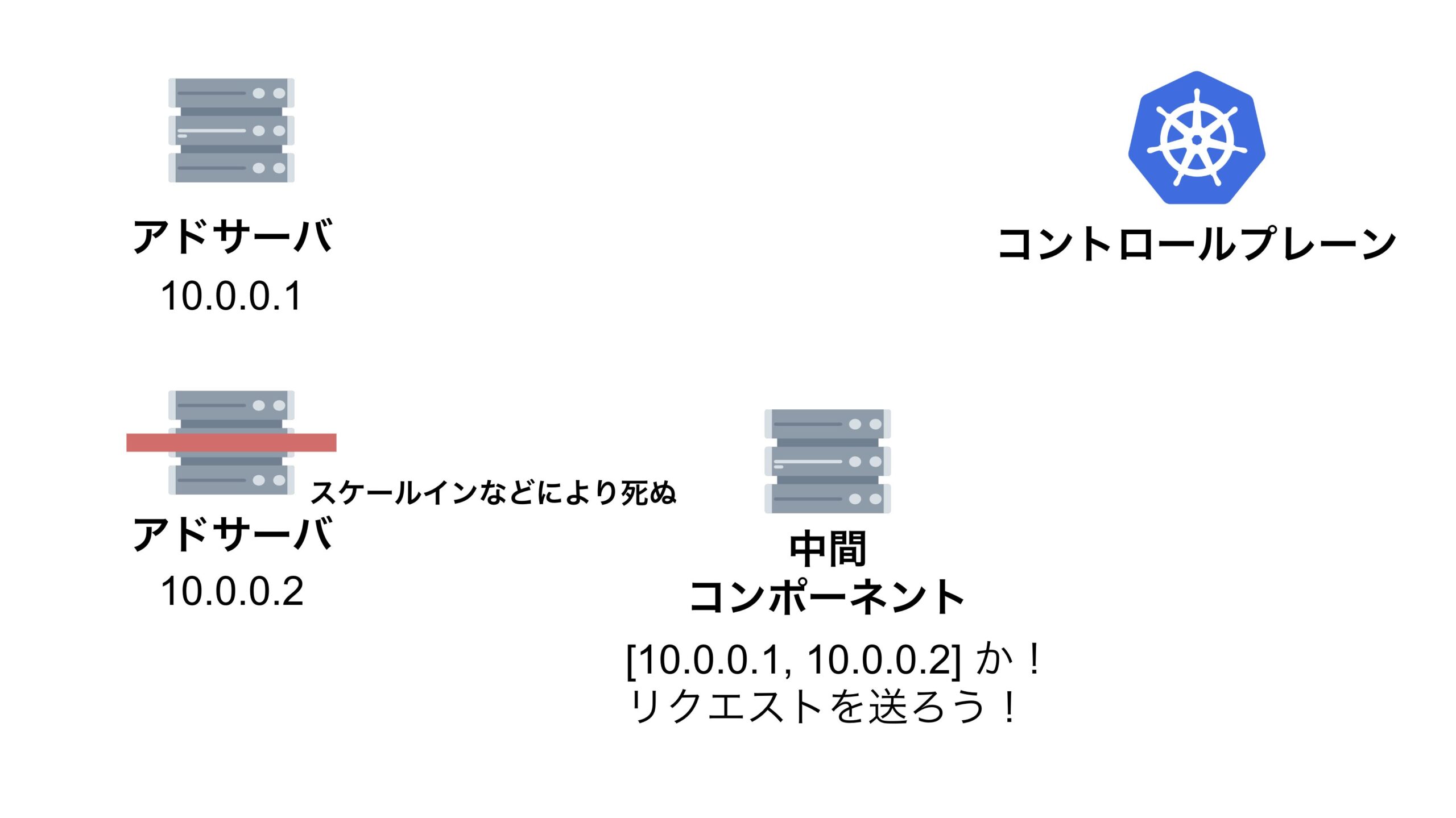
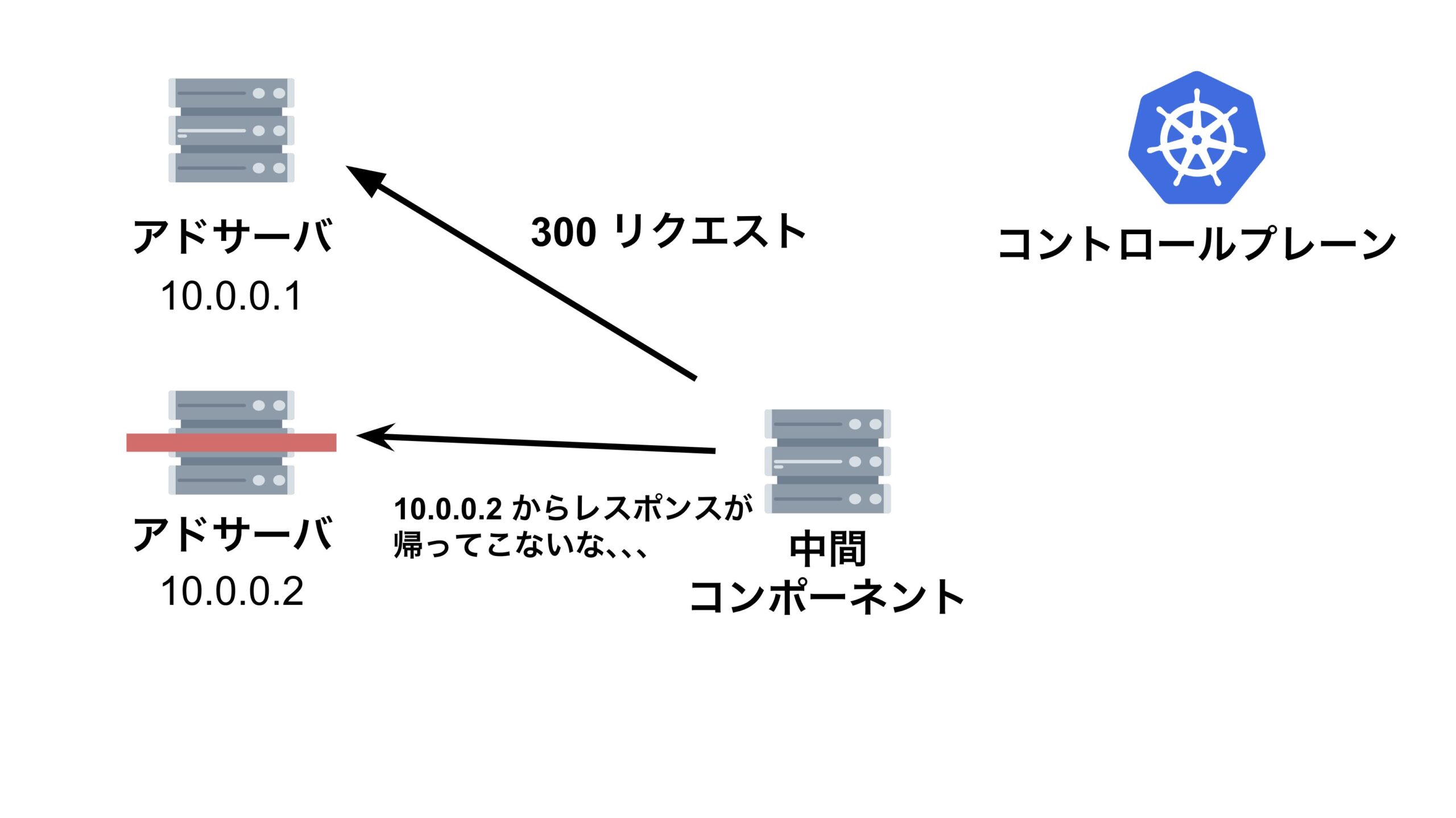
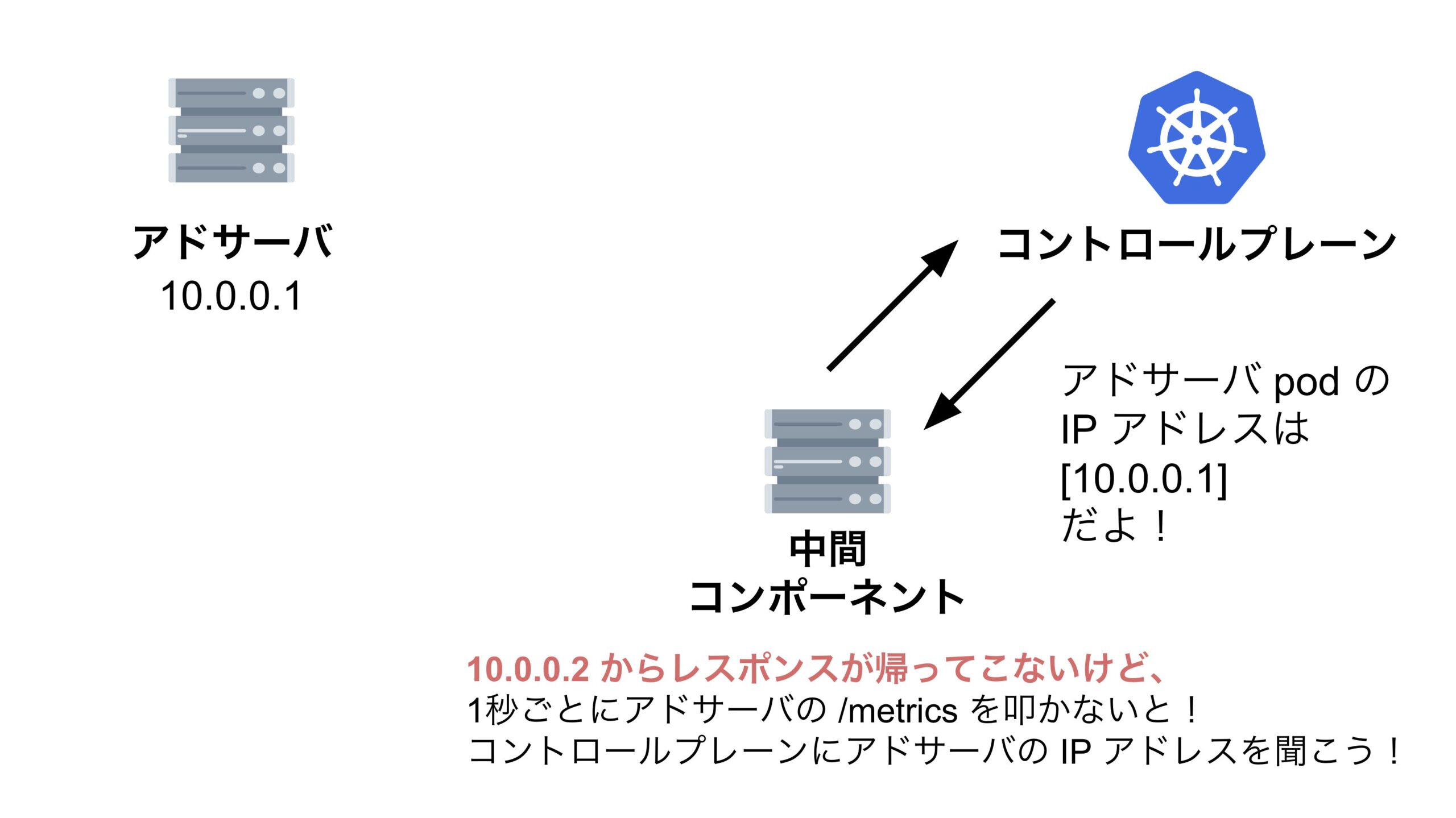
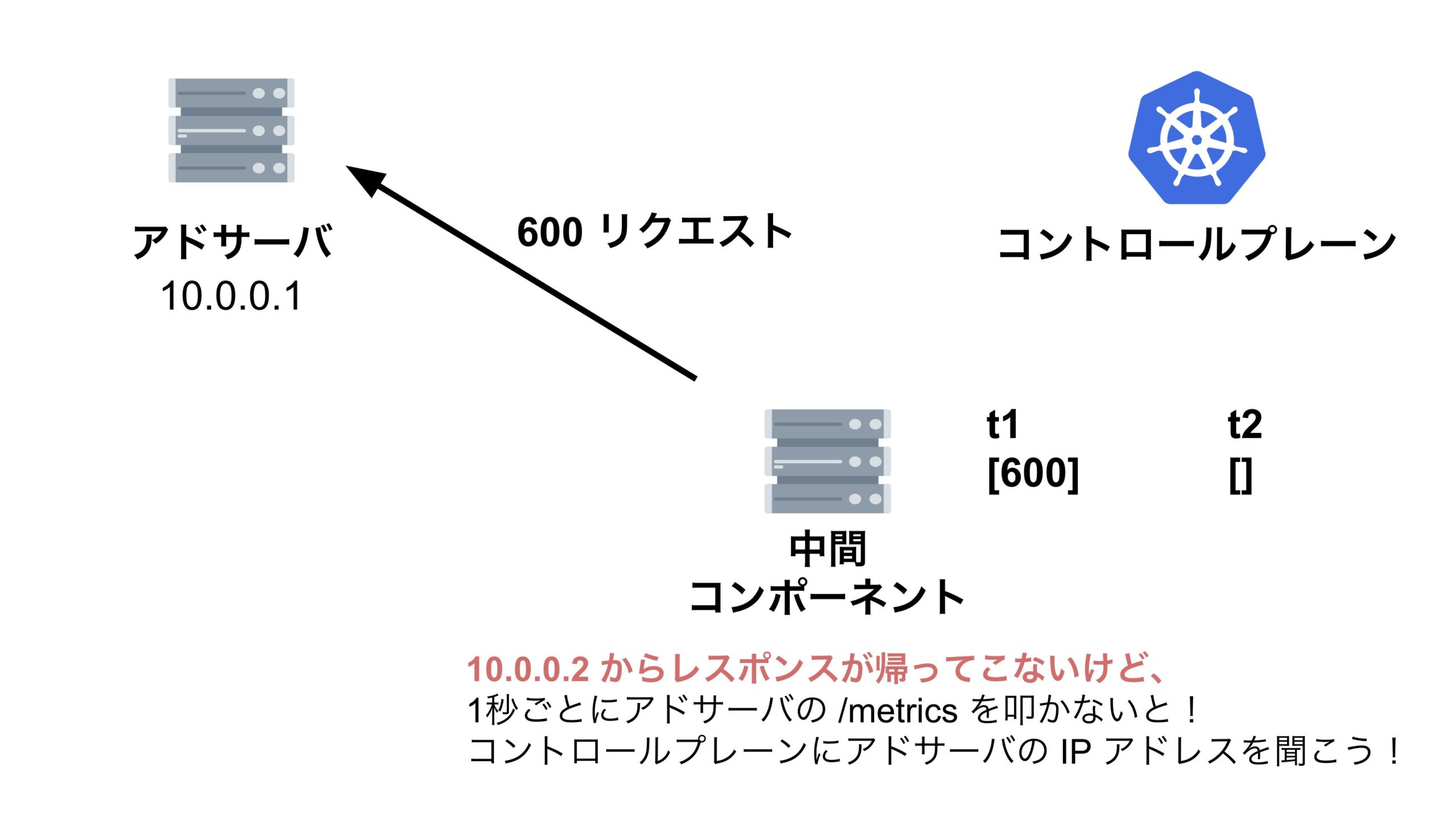
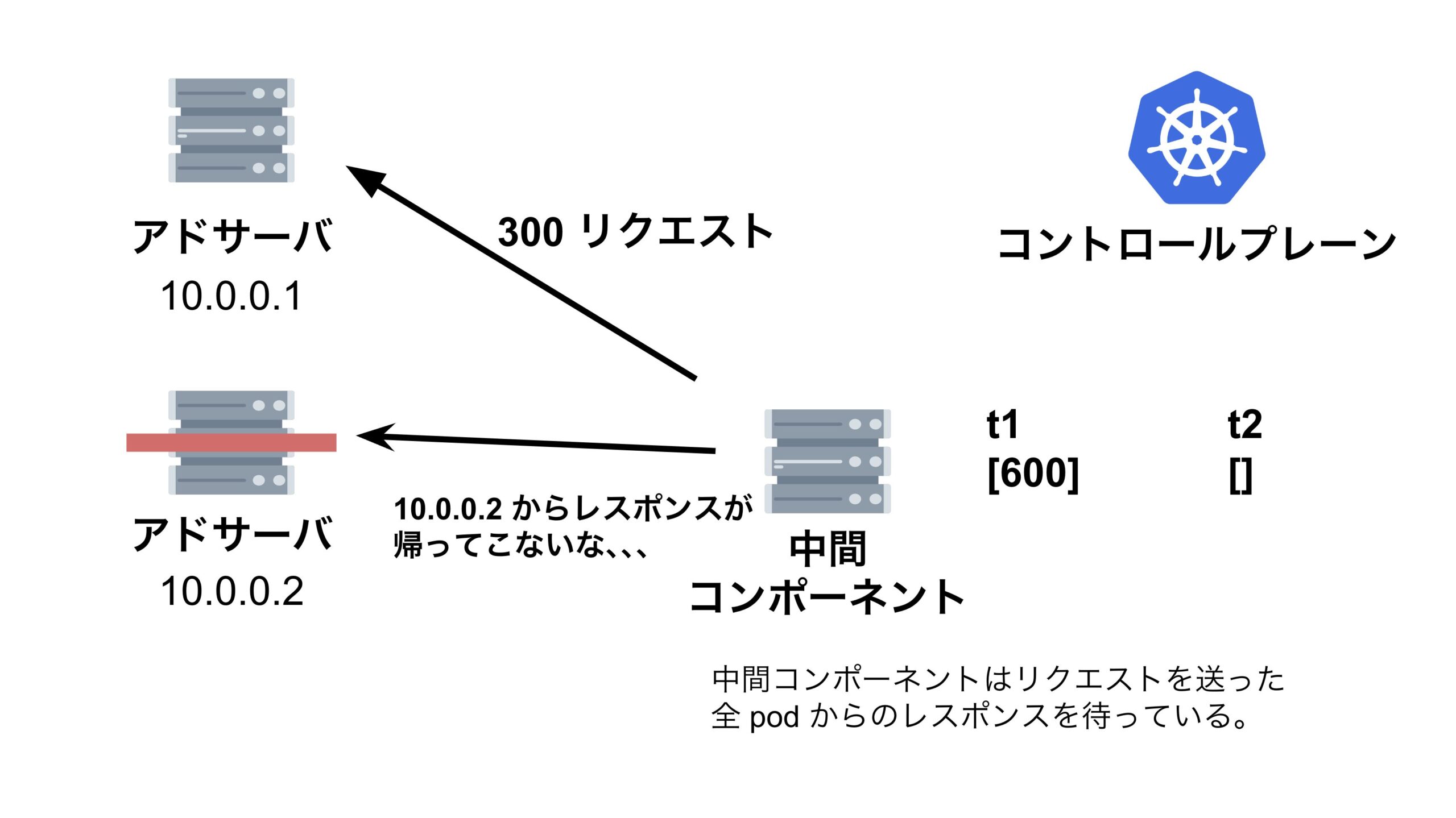
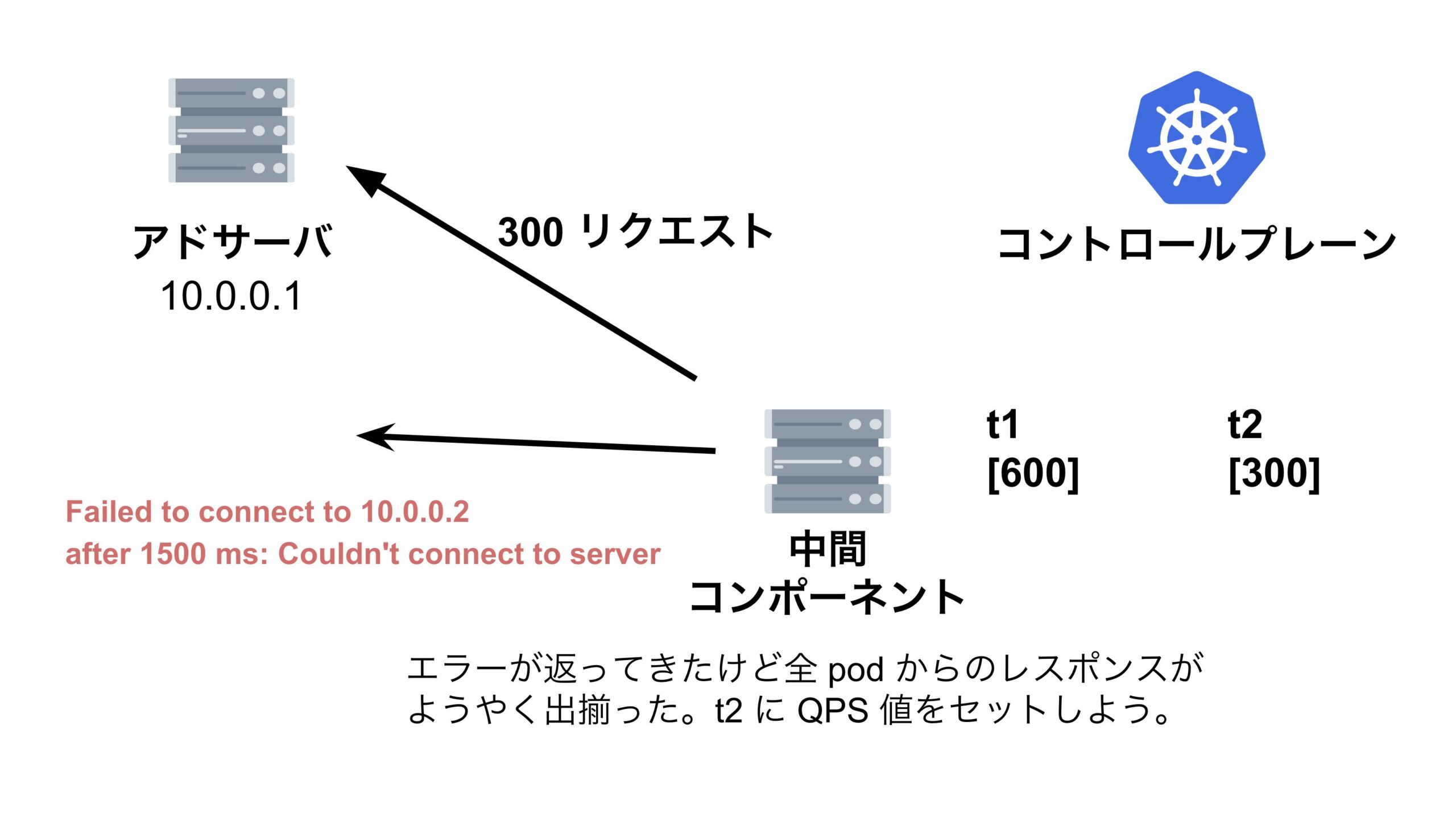
QPS がマイナスになってしまう問題を解決する
QPS がマイナスになってしまう問題を解決するためにはどうしたらよいのでしょうか。結論、http リクエストにタイムアウトを設定してあげることで問題を解決できました。
そもそも今回の QPS がマイナスになってしまう問題、つまり「リクエストの累積和の時系列が逆転」してしまう問題は、すでに死んでしまったアドサーバ pod へのリクエストを含む、全リクエストに対するレスポンスを中間コンポーネントがずっと待ち続けないといけないことに起因していました。
そこで、中間コンポーネントからアドサーバへのリクエストのタイムアウトを、アドサーバへのリクエスト間隔より短くすることで、リクエストの累積和の時系列が逆転しないようにしました。 具体的には、今回は中間コンポーネントからアドサーバへのリクエスト間隔が1秒であるため、このリクエストのタイムアウトを 900ms に設定しました。
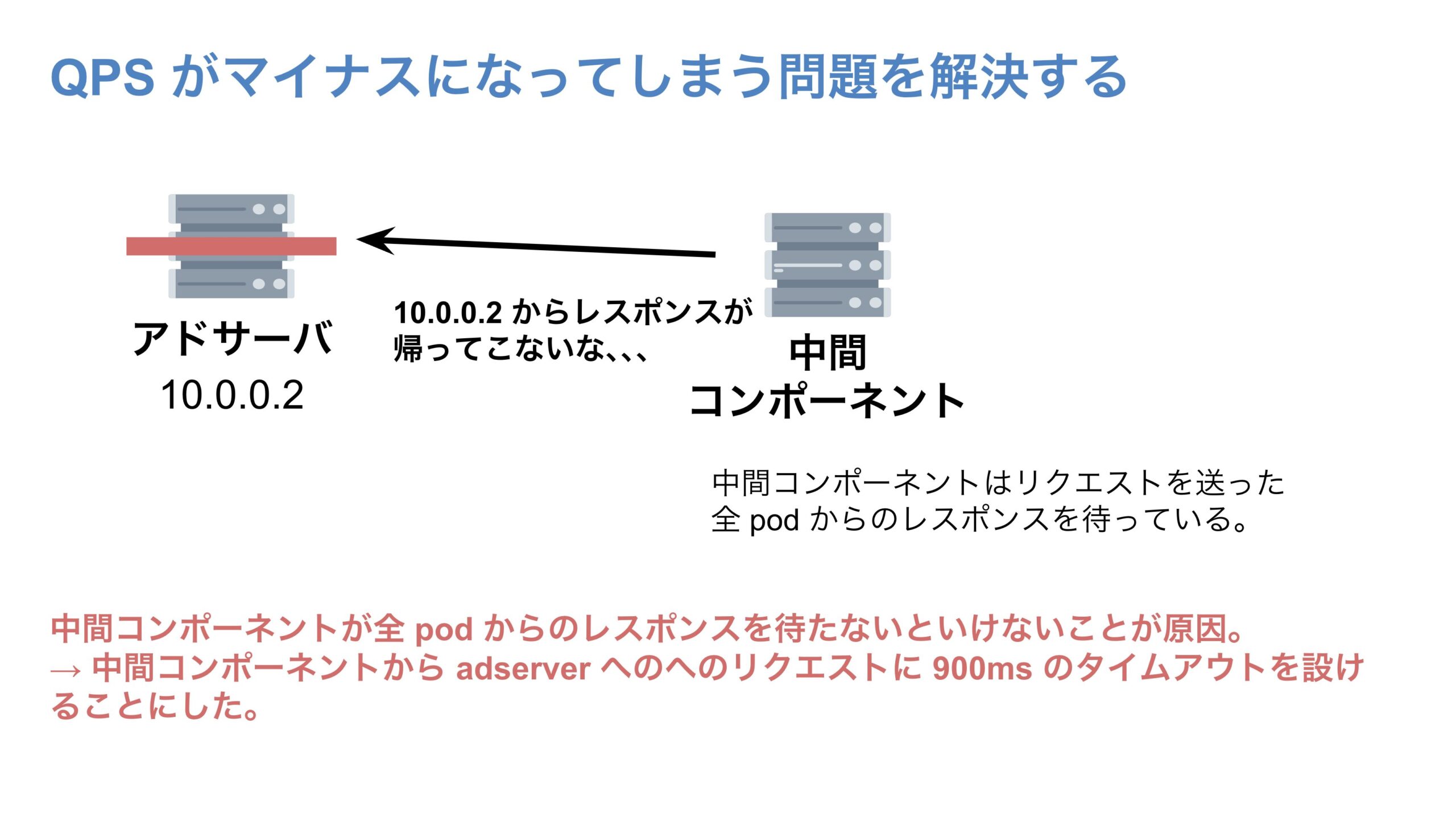
この設定により、リクエストの累積和の時系列が逆転する現象が解消され、QPS がマイナスになる問題を解決することができました。
新 QPS 制御の実装後のメトリクス
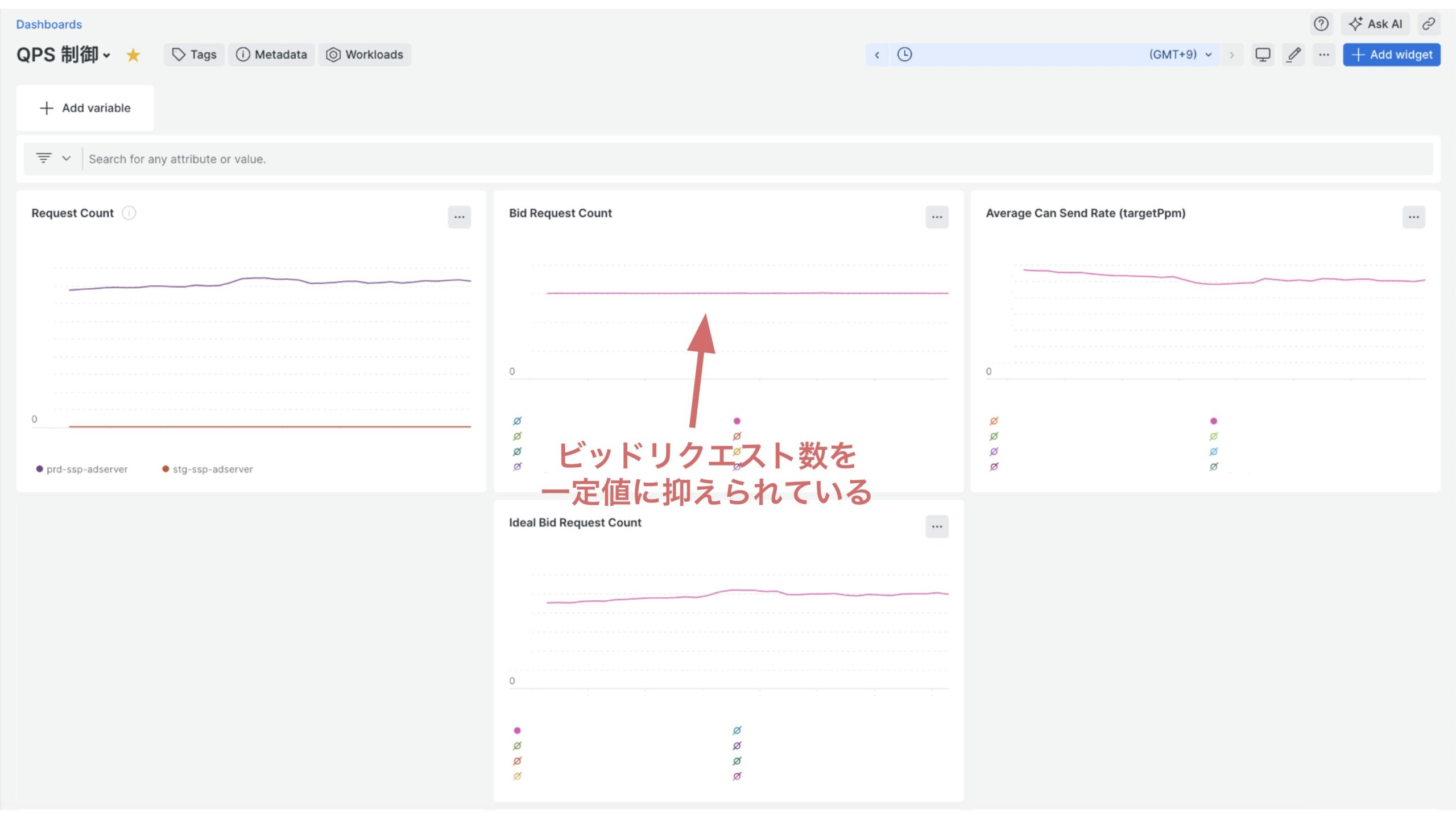
下の画像は新 QPS 制御実装後の QPS 制御のダッシュボードになります。
Request Count がアドサーバに飛んできているリクエスト数の推移、Bid Request Count が実際に送られたビッドリクエスト数の推移、Ideal Bid Request Count が本 QPS 制御システムによってリクエストがフィルタリングされなかった場合に送られるビッドリクエスト数の推移、ターゲット PPM 送ってよいビッドリクエストの割合を表しています。
Ideal Bid Request Count が盛り上がっているタイミングでも、Bid Request Count は一定値に抑えられており、正確に QPS 制御ができていることがわかります。
まとめ
本記事では、膨大なリクエストをさばく広告配信サーバならではの、分散環境における QPS 制御の実装と、EKS、特に CoreDNS のキャッシュ TTL 周りや、リクエストの累積和の時系列が逆転してしまう問題とその解決策についてご紹介しました。
本記事から大規模なシステム開発の楽しさを感じていただけたら幸いです。
おわりに
AJA SSP 開発チームの皆さんをはじめ、自分の力だけでは解決が難しい課題にぶつかった時にアドバイスをくださった 古川 太郎 さん、坂本 泰規 さん、内定者アルバイト時代からたくさんのサポートをしてくださった 新 真虎 さんには大変お世話になりました。この場を借りてお礼申し上げます。