
Hello, I’m Hoang from Hanoi DevCenter. I’m currently collaborating with the AI Operations team, focusing on generative AI application development. In this blog, I’ll outline how backend engineers can effectively utilize LangChain to overcome development challenges, streamline workflows, and build robust AI applications.
I. Why did we choose LangChain?
Generative AI applications powered by models such as GPT-4o and Claude-3.7-sonnet often need specialized methods like Retrieval-Augmented Generation (RAG) and function calling to answer domain-specific or up-to-date queries effectively. LangChain simplifies complex interactions with LLM by abstracting them, significantly reducing integration complexity.
Key Benefits:
- Quick prototyping and development
- Extensive provider compatibility. For example: OpenAI, Google Vertex-AI, Azure AI Foundry, …
- Rich documentation and active community support
- Keeping track of the latest papers about generative AI
Essential LangChain Ecosystem Components:
- LangChain: Core framework to simplify interactions with LLM APIs.
- LangGraph: Facilitates the management of complex, multi-agent workflows.
- LangSmith: Tool for LLM observability, including debugging, evaluation, and prompt management.
Recently, LangMem was introduced and is responsible for managing memory and improving context-handling capabilities.
II. Practical Challenges and Solutions when using LangChain
Challenge 1: Limited flexibility
In generative AI applications, you typically work with the agent, which includes a prompt(instructions), a base LLM, and helpful tools (functions providing additional information to the LLM).
The ReAct agent is commonly used for AI agent-based applications because it enables the LLM to interact with tools to obtain desired answers. LangChain conveniently provides a method to create a ReAct agent (create_react_agent) . You simply define the prompt and tools and run the ReAct agent, as shown below:
from langchain.agents import AgentExecutor, create_react_agent
from langchain_openai import AzureChatOpenAI
from langchain.tools import tool
from langchain.prompts import PromptTemplate
@tool
def get_temperature:
"""Return the current temperature"""
return "26°C"
tools = [get_temperature]
prompt = PromptTemplate.from_template("""
You are a helpful assistant.
{input}
""")
model = AzureChatOpenAI()
agent = create_react_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_executor.invoke({"input": "What is the current temperature"})
However, modifying the interaction between the base LLM and the tools can quickly become complicated. We must understand and implement the underlying logic to implement custom interactions. For example, the typical workflow of a ReAct agent involves:
- Step 1: Call the base LLM
- Step 2: If the response doesn’t require any functions, return the response to the user.
- Step 3: If the response requires functions:
- Execute the function with arguments provided by the LLM response.
- Obtain the function result.
- Convert the result to a message.
- Step 4: Call the base LLM again, including the original message and the function result in the history.
- Step 5: Repeat from Step 2 as necessary.
Here is the simplest pseudo version. We can process the tool result as we want.
history = []
buffer_size = 10
for i in range(buffer_size):
res = llm.invoke(input)
history.append(res)
if !res.need_tool:
return res.content
# Invoke the function with arguments
result = ...
history.append(to_tool_msg(result))
input["chat_history"].extend(history)
The main challenge is the limited flexibility in modifying interactions between LLMs and tools when relying solely on LangChain’s built-in utilities. These methods provide convenience and speed but come at the cost of reduced control and transparency. A deeper understanding of the underlying implementation—and often a custom approach—is necessary to customize tool selection and invocation behaviour.
The solution can be:
- Carefully review internal documentation. The LangChain document is quite a good place to summarize the basic knowledge about the definitions. Reference about ReAct Agent.
- Study the original academic papers for deeper theoretical insights. In the case of the ReAct agent, we need to read ReAct: Synergizing Reasoning and Acting in Language Models paper
- Utilize detailed logging and monitoring tools (like LangSmith) for improved transparency and easier debugging. With the ReAct agent example, we can see the underlying process with LangSmith Tracing
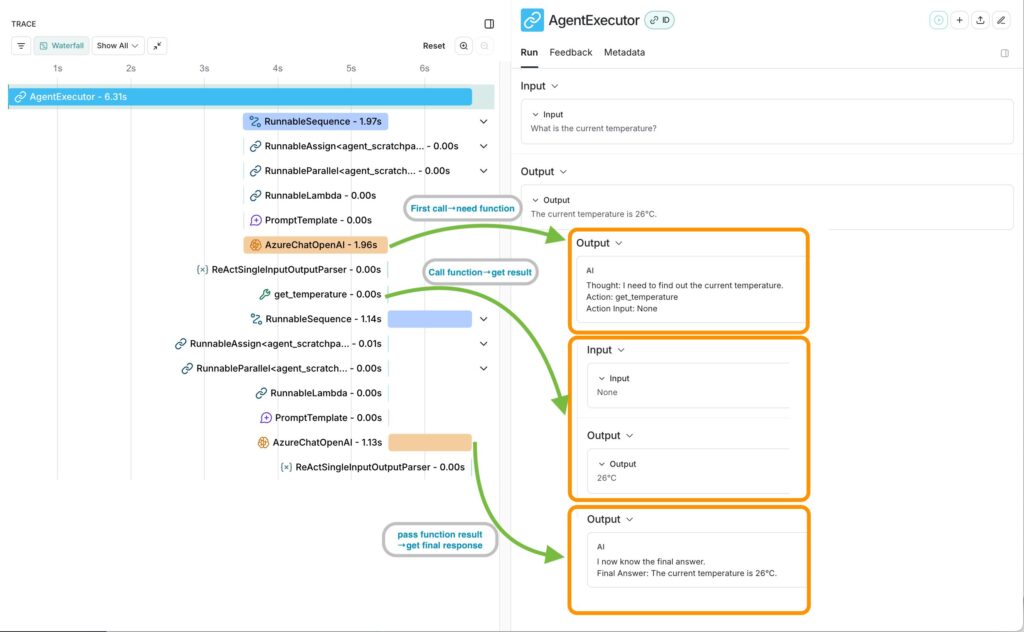
Challenge 2: Feature Instability
We are developing a chatbot application. In the initial phase, we would like the testing users to provide feedback on each message that the agent generates. LangChain provides a mechanism that helps track and monitor every message. When invoking, LangChain attaches a run_id to the message. This integrates with the monitoring system, helping developers debug, trace, and evaluate it more easily. We use that run_id to assess users’ scores based on their responses.
Coming to the details in LangChain, we can receive a response message from either a singular LLM object or a chain object. Chaining is one of LangChain’s powerful and unique features. Similar to the pipe in Linux, chaining passes the output of one component as the input to the next. For example, chain = prompt | model | StrOutputParser(). This allows the prompt to be processed by a model and then formatted into a predefined output structure.
Everything seemed to work well until we realized that passing the run_id to the monitoring system (LangSmith) only works by directly calling the singular model. The chain hasn’t supported it yet. At that time, we wanted that feature to be done soon, so we made a PR to resolve that problem. Happily, we could use that feature after 1-2 weeks of waiting for a new release.
That is one of the advantages of the Open-source software(OSS). The project can take the community’s contribution.
This highlights both a key challenge and a benefit of rapidly developing OSS: some features may initially be incomplete or unstable, but developers can contribute improvements directly.
Lesson learned:
- Wait for official updates from the LangChain team.
- Actively contribute to OSS to implement needed features directly.
Challenge 3: Complex prompting tasks
Initially, our chatbot was simple and designed for basic tasks. However, as we added new features, complex prompts increased hallucination risks and reduced accuracy. Therefore, we needed a better approach to implement an agent that could handle multiple functions.
That’s when we decided to use a multi-agent architecture.
The multi-agent architecture consists of multiple agents interacting with one another. Depending on the interaction model, we can have different structures. Two common ones are hierarchical and network-based models.
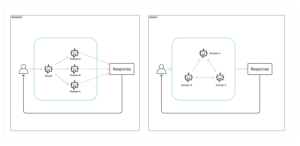
Several frameworks are available for implementing multi-agent systems, and LangGraph is one of them. Integrated with LangChain, LangGraph uses the concept of graphs to build a multi-agent architecture, where each node represents a processing station—either a base LLM or a separate function—while each edge represents the connection between nodes. With the graph-based approach, users have the flexibility to define various structures as needed. Another advantage of using LangGraph is its compatibility with LangSmith, simplifying system monitoring, debugging, tracing, and evaluation.
Additionally, other well-known frameworks such as AutoGen, CrewAI, and Multi-Agent-Orchestrator exist. Some key strengths of each framework include:
- Multi-Agent-Orchestrator (AWS): Specifically designed for AWS cloud environments, highly compatible with Bedrock (AWS’s LLM provider service), modular architecture, easy integration and expansion.
- CrewAI: Simple, designed for managing AI agents working in teams.
- AutoGen (Microsoft): Optimized for agent interactions, easily scalable due to its decoupled pub-sub messaging structure between agents.
However, considering factors such as the LangChain ecosystem, the relatively medium user base, and the flexibility in defining agent structures, LangGraph stands out as the best choice in our use case.
Recommended Approach:
- Evaluate your project’s integration complexity and scalability.
- Choose frameworks strategically based on the specific needs and integration costs.
Challenge 4: Database related obstacle
With the shift to a multi-agent architecture, we encountered several database problems, especially concerning chatbot memory and context retention. Persistent storage is crucial for chatbots to maintain conversation context. While InMemory works well for local testing, we needed a long-term solution to store chat history reliably.
In LangGraph, this persistent storage is managed through the Checkpointer, which supports SQLite and Postgres. However, our project exclusively used DynamoDB at the time.
The first problem came: No DynamoDB Support for Checkpointer
Since Checkpointer had no built-in support for DynamoDB, we had two choices:
Choice 1: Introduce a new SQL-based database just for Checkpointer.
Choice 2: Implement our own DynamoDB-based Checkpointer to avoid unnecessary dependencies.
We opted for the second approach and implemented the following Checkpointer using DynamoDB. Because the Checkpointer already implemented the abstract class, we just need to follow and implement the core logic to handle the DynamoDB record.
class DynamoDDSaver(BaseCheckpointSaver[str]):
def put(self, config, checkpoint, metadata, new_versions):
self.dynamodb_store.checkpoint.put(config, checkpoint, metadata, new_versions)
def put_writes(self, config, writes, task_id):
self.dynamodb_store.write.put(writes, task_id)
def get_tuple(self, config):
self.dynamodb_store.checkpoint.get(config)
This solution worked smoothly, and we were satisfied with its performance. However, as chat history grew, a new issue emerged.
The second problem say hello: DynamoDB’s 400KB Item Size Limitation
Over time, chat history length increased, and eventually, some conversation threads became too large for a single DynamoDB record. The 400KB item size limit caused internal errors when trying to store long conversations.
We had two possible solutions:
- Split chat history into multiple records in DynamoDB. However, this would require complex logic and higher maintenance costs.
- Migrate to a different database that supports larger storage and better querying capabilities.
At the same time, we faced another challenge: querying complex conditions and extracting statistical insights from DynamoDB was difficult. Given these constraints, we decided to migrate to Postgres, which offered better scalability, easier maintenance, and better analytical capabilities.
The migration went smoothly—until the next problem surfaced.
The third one: Unexpected Schema Changes in LangGraph
Post-migration, our application worked flawlessly—until one deployment unexpectedly caused downtime. After investigating the logs, we discovered that the database schema didn’t match.
The root cause? LangGraph had modified the Checkpointer table schema in a minor release by adding a new column, task_path, without marking it as a breaking change. The full release note can be found here.
This incident was a crucial lesson in handling dependencies and schema changes.
Key Takeaways:
- Evaluate database limitations early—Anticipate scaling needs before making storage decisions.
- Be cautious with Python libraries—Some Python libraries lack strong backward compatibility, so even minor updates can introduce unexpected breaking changes.
- Think beyond the present—A solution that works today may become a maintenance burden in the future. Always factor in long-term sustainability.
Migrating from DynamoDB to Postgres significantly improved our chatbot’s scalability and performance. While it wasn’t without challenges, the journey reinforced the importance of foresight, adaptability, and rigorous dependency management in software architecture.
Challenge 5: Testing, evaluation and prompt management
As our chatbot system evolved, maintaining high-quality responses became a growing challenge. Testing and evaluating LLM-generated responses is vastly different from traditional software testing.
Problem 1: Inefficient Prompt Management
As our chatbot relied heavily on prompts, keeping track of prompt changes, testing variations, and ensuring consistency across multiple agents became increasingly difficult. Without a structured way to manage prompt updates, we encountered:
- Versioning issues—tracking prompt iterations was tedious.
- Inconsistent results—some agents behaved differently due to outdated prompts.
- Difficult debugging—pinpointing the root cause was tricky when a response went wrong.
Solution: Managing Prompts with LangSmith
To streamline prompt management, we turned to LangSmith, which allowed us to:
- Version control prompts—we could track and compare changes over time.
- Run A/B testing—experimenting with different prompt structures became easier.
- Monitor performance—identify which prompts performed best across different datasets.
By centralizing prompt management, we improved efficiency, consistency, and debugging in our chatbot system.
Problem 2: Difficulty in Testing LLM Logic
Unlike traditional software, where we can write unit tests with predefined inputs and outputs, testing an LLM response is more complex because:
- LLM outputs can be non-deterministic—they might vary slightly each time.
- Evaluating correctness is subjective—some answers are better but not necessarily “correct” or “incorrect.”
- Large datasets need automated evaluation—manual review isn’t scalable.
Solution: Using LangSmith for Evaluation
LangSmith’s evaluation framework provided a structured way to measure response quality. We leveraged:
- Automated LLM-based grading—LLMs helped assess responses against expected criteria.
- Real dataset integration—using historical chat logs, we tested prompts on real user queries.
- Custom metrics—we defined accuracy, relevance, and coherence criteria to assess responses systematically.
We can improve our chatbot’s performance by combining real-world datasets, prompt tracking, and automated evaluation.
Some key points:
- Effective prompt management is crucial
- Testing LLMs requires new methodologies—Traditional testing doesn’t work; automated evaluation with real datasets is the key.
- Continuous monitoring improves responses—Integrating evaluation tools like LangSmith ensures the chatbot evolves effectively.
III. Conclusion and Best Practices
LangChain significantly boosts generative AI development efficiency yet demands careful management to address abstraction complexities, frequent updates, and integration challenges. Key recommendations for backend engineers include:
- Implement continuous monitoring and optimize prompts regularly.
- Select databases and tools strategically based on evolving application requirements.
- Actively manage updates to maintain application stability and functionality.
By proactively managing these areas, engineers can fully harness LangChain’s capabilities, delivering robust, scalable, and reliable generative AI solutions.