
はじめに
こんにちは!ABEMAの広告配信システムの開発チームでバックエンドエンジニアとしてバイトをしている内定者の戸田朋花です。
本記事では、Datadog Continuous Profiler を用いてボトルネックを特定し、Go1.23 から追加された iterator を活用してコードをリファクタリングした結果、CPU 時間を 57%短縮し、メモリ確保量を 99.4%削減した取り組みについてご紹介します!
背景
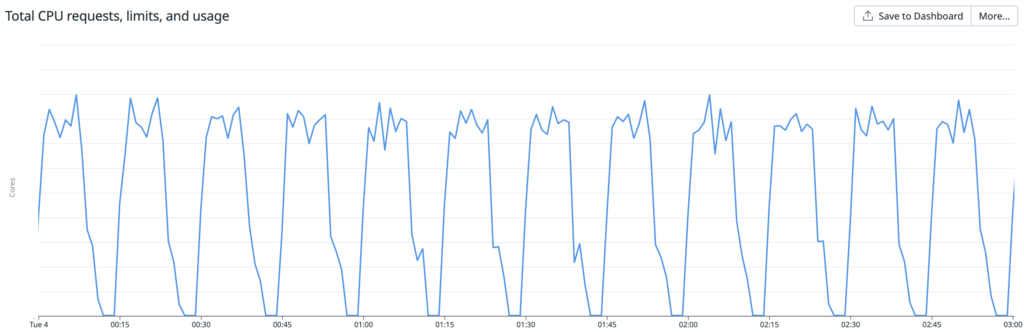
ABEMA の広告配信システムは多数のマイクロサービスで構成されていますが、とあるコンポーネントにおいて、CPU使用率が定期的にスパイクしている課題がありました。
性能改善と今後の安定した機能追加を実現するため、原因の分析とリファクタリングを検討しました。
Profier を利用した原因特定
Profilerとは
Profilerとは、アプリケーションの実行中にどの処理がどれだけのリソースを消費しているのかを解析するツールです。Goには、標準で pprof というProfilerが用意されており、CPU・メモリ・ゴルーチンの使用状況などを分析できます。
Datadog Continuous Profilerとは
Datadog Continuous Profilerは、リソース使用量をリアルタイムで解析し、その結果を継続的に保存できる機能です。実際のトレースとプロファイルデータを紐づけてくれたり、収集した結果からインサイトを提案してくれたりします。
Profiler からわかったこと
本記事では実際の関数名などは伏せていますが、処理のフローは概ね図示したとおりです
CPU 時間

上記は当該のCPU時間がスパイクしている最中の CPU 時間に関するプロファイリング結果です。
この結果から、CPU 時間の消費割合が大きい 4 つの処理が全て同じメソッド(extractElement)であることが確認できました。
実際に、 filterAndSum や extractElement は内部に多くのループを含んでおり、大規模なデータを扱うと計算コストが高くなりやすい構造でした。
アプリケーションサーバ内でこの処理が定期実行されており、その結果、コード上のホットスポットとなり、CPU使用率が定期的に上がる原因となっていそうです
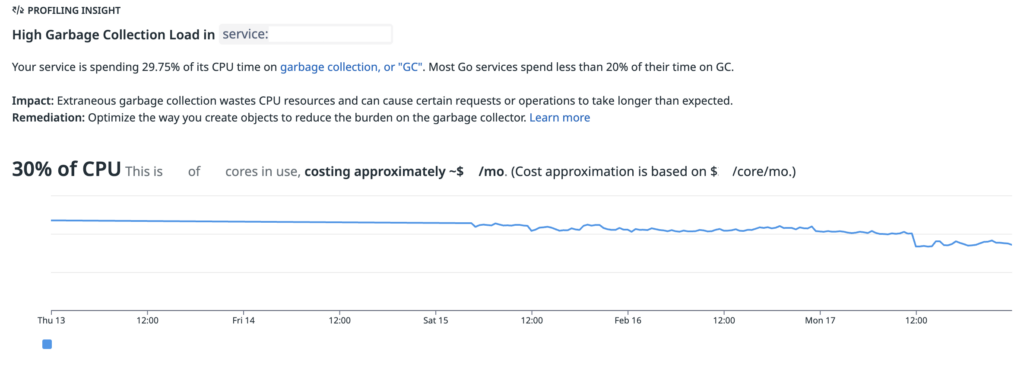
また、DatadogのProfiling Insightからは、「High Garbage Collection Load」が自動的に指摘されていました。約 30%もの時間が GC に消費されているのではないかという内容だったので、この情報をヒントに調査を進めていきました。
メモリ確保量

ヒープメモリに関するプロファイリング結果は上図です。こちらは1分あたりに確保したメモリの内訳を表しています。1 分あたり 25.8GiB と、大量のメモリを確保してしまっていることがわかりました。
CPU 時間と同様に、メモリ確保量の多い 4 つの処理も全て extractElement メソッドであることが確認できました。
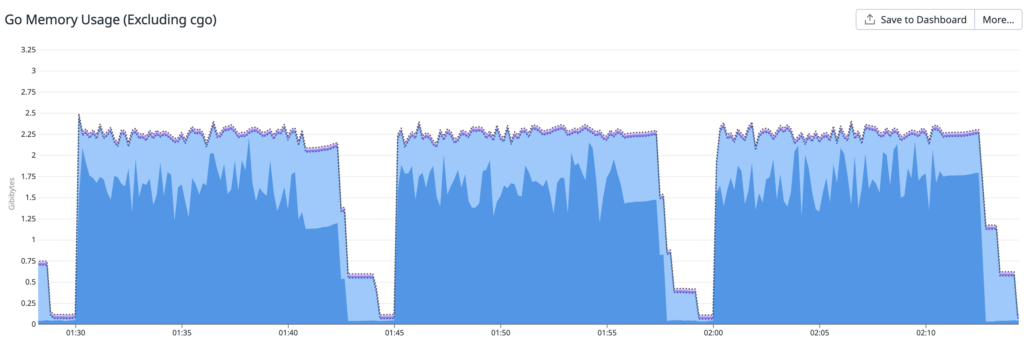
上記の図から実際のメモリ確保量は2.25GiB程度と、常に25.8GBのメモリを消費しているわけではなさそうなので、ヒープに短命なオブジェクトが確保されていそうなことがわかります。
仮説
プロファイリングの結果、CPU 時間の消費量とメモリの確保量が大きいのは、extractElement メソッドであることが判明しました。
このメソッドと、そのメソッドを呼び出している処理は以下のようなものでした。
func filterAndSum(target targetList, args args) int64 {
filteredList := target.Filter(args.arg0, args.arg1, args.arg2, args.arg3)
var result int64 = 0
for _, e := range filteredList {
result += e.value
}
return result
}
func (l targetList) Filter(arg0 string, arg1 string, arg2 string, arg3 string) targetList {
return l.extractElement(&arg0FilteringStrategy{arg0}).
extractElement(&arg1FilteringStrategy{arg1}).
extractElement(&arg2FilteringStrategy{arg2}).
extractElement(&arg3FilteringStrategy{arg3})
}
func (l targetList) extractElement(s filteringStrategy) targetList {
r := make(targetList, 0, len(l)) // ⚠️問題の箇所
for _, e := range l {
if s.match(e) {
r = append(r, e)
}
}
return r
}
実装を見ると、コメントを入れた箇所で毎回新たにメモリ確保が行われていそうに見えます。
これが短命なヒープメモリ割り当てと、GC のコスト増大を引き起こしている可能性を疑い、エスケープ解析を行いました。
Goのメモリエスケープとは
メモリの確保には スタック確保 と ヒープ確保 の2種類があります。
ポインタではないローカル変数に関して、コンパイル時に静的にメモリが生存する範囲(レキシカルスコープ)を事前に決定できる場合はスタック領域に確保され、そうでない場合はヒープ領域に確保されます。後者のようにヒープに確保されるケースをメモリエスケープと呼びます。
スタック領域はメソッド呼び出し時にまとめて確保し終了後にまとめて解放されるため確保と解放が高速ですが、ヒープに確保されたオブジェクトはGCによって定期的にクリーンアップする必要があるためオーバーヘッドが存在します。
go build の際に -gcflags=-m を指定すると、エスケープ解析の結果を確認できます。
実際に以下のようなコードとそれを呼び出すテストコードを書いてエスケープ解析をしてみました。
package main
func filterAndSum(target targetList, args args) int64 {
filteredList := target.Filter(args.arg0, args.arg1, args.arg2, args.arg3)
var result int64 = 0
for _, e := range filteredList {
result += e.value
}
return result
}
func (l targetList) Filter(arg0 string, arg1 string, arg2 string, arg3 string) targetList {
return l.extractElement(&arg0FilteringStrategy{arg0}).
extractElement(&arg1FilteringStrategy{arg1}).
extractElement(&arg2FilteringStrategy{arg2}).
extractElement(&arg3FilteringStrategy{arg3})
}
func (l targetList) extractElement(s filteringStrategy) targetList {
r := make(targetList, 0, len(l)) // ⚠️問題の箇所
for _, e := range l {
if s.match(e) {
r = append(r, e)
}
}
return r
}
func main() {
target := make(targetList, 100)
for j := 0; j < 100; j++ {
target[j] = element{value: int64(j)}
}
args := args{
arg0: "arg0",
arg1: "arg1",
arg2: "arg2",
arg3: "arg3",
}
filterAndSum(target, args)
}
$ go build -gcflags '-m' main.go
# command-line-arguments
main.go:65:6: can inline (*arg0FilteringStrategy).match
main.go:73:6: can inline (*arg1FilteringStrategy).match
main.go:81:6: can inline (*arg2FilteringStrategy).match
main.go:89:6: can inline (*arg3FilteringStrategy).match
main.go:19:7: l does not escape
main.go:19:36: leaking param: s
main.go:20:11: make(targetList, 0, len(l)) escapes to heap
main.go:12:7: l does not escape
main.go:12:28: leaking param: arg0
main.go:12:41: leaking param: arg1
main.go:12:54: leaking param: arg2
main.go:12:67: leaking param: arg3
main.go:13:26: &arg0FilteringStrategy{...} escapes to heap
main.go:14:18: &arg1FilteringStrategy{...} escapes to heap
main.go:15:18: &arg2FilteringStrategy{...} escapes to heap
main.go:16:18: &arg3FilteringStrategy{...} escapes to heap
main.go:3:19: target does not escape
main.go:3:38: leaking param: args
main.go:30:16: make(targetList, 100) does not escape
main.go:65:7: s does not escape
main.go:73:7: s does not escape
main.go:81:7: s does not escape
main.go:89:7: s does not escape
main.go:20:11: make(targetList, 0, len(l)) escapes to heapという出力から、make(targetList, 0, len(l)) がヒープにエスケープしていることがわかります。ヒープにエスケープし確保された領域は GC の対象になるため、この処理がメモリ割り当てと GC の負担を増やしている可能性が高いと考えました。
仮説の検証
仮説を検証するため、新たにスライスを作成せず、既存のスライスを更新するように実装を変更しました。
func (l *targetList) Filter(arg0 string, arg1 string, arg2 string, arg3 string) targetList {
return l.extractElement(&arg0FilteringStrategy{arg0}).
extractElement(&arg1FilteringStrategy{arg1}).
extractElement(&arg2FilteringStrategy{arg2}).
extractElement(&arg3FilteringStrategy{arg3})
}
func (l *targetList) extractElement(s filteringStrategy) targetList {
n := 0
for _, e := range l {
if s.match(e) {
(*l)[n] = e //既存のスライスを更新
n++
}
}
*l = (*l)[:n]
}
以下のベンチマークテストを用いて、実装変更前後の性能を比較しました。
func BenchmarkTargetList_Filter(b *testing.B) {
l := make(targetList, 100)
// 省略 - 適当なデータを用意
b.Run("Filter", func(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = l.Filter(arg0, arg1, arg2, arg3)
}
})
}
ベンチマークテストの結果は、以下のようでした。
| ns/op | B/op | allocs/op | |
|---|---|---|---|
| 変更前 | 1256 | 3720 | 8 |
| 変更後 | 1051 | 136 | 4 |
この結果から、処理速度は約 16%向上し、メモリ使用量は約 96%削減されたことが確認できました!
これにより、当該箇所がボトルネックであると特定できました。
リファクタリング
前述した検証用のコードでは、元のスライスを直接更新しています。
パフォーマンス上は効率的なものの、ミュータブル(元の値を直接更新する)な処理となっているため、呼び出し元がこの挙動を把握していないと意図しない不具合を引き起こす可能性があると考えました。
そこで、Go 1.23 で追加された iterator を利用して、メモリ確保の量を抑えつつ、呼び出し元が内部実装のことを意識しなくてよいような実装ができないか試してみました。
Go の iterator と range over func
Go1.23から、iteratorを定義できるようになりました。(参考)
Go の iterator は、 yield と呼ばれるコールバック関数を引数に取る関数として、以下のように表現されます。
type (
Seq[V any] func(yield func(V) bool)
Seq2[K, V any] func(yield func(K, V) bool)
)
例えば、maps.Keys は以下のような iterator を返す関数型として実装されています。iterator 内部では、シーケンスの連続する値をコールバック関数に順次渡していきます。
func Keys[Map ~map[K]V, K comparable, V any](m Map) iter.Seq[K] {
return func(yield func(K) bool) {
for k := range m {
if !yield(k) {
return
}
}
}
}
さらに、Go 1.23 から iteratorに対して range を使用できる「range over function type」という仕様が追加されました。(参考)
これにより、以下のような iterator を for 文の range 句で使用できるようになりました。
func(yield func() bool)
func(yield func(V) bool)
func(yield func(K, V) bool)
range over func を用いた実装の例は以下です。
iterator を range 句に使用すると、iterator 内部で値がコールバック関数に渡されるたびに、 k にその値が割り当てられます。
iter := maps.Keys(m)
for k := range iter {
fmt.Println(k)
}
このように、iterator を for 文で直接反復処理できるため、中間のスライスを作成せずに効率的にデータを処理できます。
iterator を用いたリファクタリング
上で述べた iterator を活用して、今回は以下のように実装を変更しました。
func filterAndSum(target targetList, args args) int64 {
var result int64 = 0
for r := range target.Filter(args.arg0, args.arg1, args.arg2, args.arg3) {
result += r.value
}
return result
}
type targetListIter func(yield func(*targetItem) bool)
func (l targetList) ToIter() targetListIter {
return func(yield func(*targetItem) bool) {
for _, e := range l {
if !yield(e) {
return
}
}
}
}
func (l targetList) Filter(arg0 string, arg1 string, arg2 string, arg3 string) targetListIter {
return l.ToIter().
extractElement(&arg0FilteringStrategy{arg0}).
extractElement(&arg1FilteringStrategy{arg1}).
extractElement(&arg2FilteringStrategy{arg2}).
extractElement(&arg3FilteringStrategy{arg3})
}
func (p targetListIter) extracElement(s filteringStrategy) targetListIter {
return func(yield func(*targetItem) bool) {
for pp := range p {
if s.match(pp) {
if !yield(pp) {
return
}
}
}
}
}
主な変更点は以下の通りです。
extractElementの返り値をスライスから iterator へ変更しました。- フィルタリングの中間結果をスライスとして格納する必要がなくなりメモリ割り当てが減ります✅
Filterメソッドではスライス(targetList)ではなくイテレータ(targetListIter) を返すように変更しました。- 呼び出し元では、iterator を range 句に直接渡すことができるので、中間スライスが作成されません✅
Filter関数 の呼び出し元にも変更を加えたため、新たにベンチマークテストを以下のように実装し直しました。
func BenchmarkFilterAndSum(b *testing.B) {
l := make(targetList, 5000)
// 省略 - 適当なデータを用意
b.Run("Filter", func(b *testing.B) {
for i := 0; i < b.N; i++ {
_ = filterAndSum(l, args)
}
})
}
ベンチマークテストの結果は、以下のようでした。
| ns/op | B/op | allocs/op | |
|---|---|---|---|
| 変更前 | 74062 | 163977 | 8 |
| 変更後 | 66137 | 336 | 12 |
処理速度は約 11% 向上し、メモリ確保量は約 99% 削減されました 🎉
メモリの確保回数が変更前より増えてしまっていますが、これはクロージャを使用する処理が増えたためと考えられます。しかし、メモリ確保回数のオーバーヘッドよりも、ヒープメモリ使用量改善の効果が大きいと考えられるので、この実装を本番環境にデプロイしてみました!
今回のベンチマークテストではコードの純粋な実行速度のみを測定しているので、GCのオーバーヘッドは直接考慮されていません。
Datadog上の指摘にもあったように、GCのオーバーヘッドの影響がパフォーマンスに与える影響が大きいので、実ワークロードではさらなる高速化が期待できます!
結果
実際にデプロイ後、Datadog でメトリクスを比較したところ、期待通りの効果が得られました!
まずは、課題特定時に参考にした Profiles が実際に改善しているかどうかを確認します。
CPU 時間 (A: 変更前 B: 変更後)
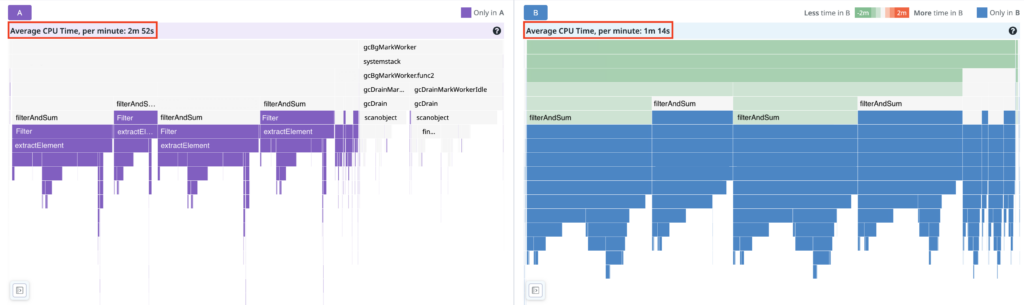
GC にかかっていた時間がごっそりなくなっているのがひと目見てわかります 🙌
CPU 時間は 2m 52s から 1m 14s になり約 57%短縮できました!
メモリ確保量 (A: 変更前 B: 変更後)
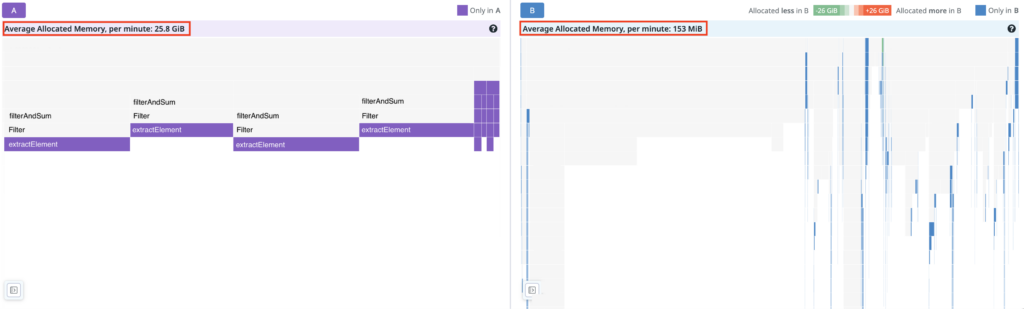
プロファイリング結果にリファクタリングを行ったメソッドがほとんど現れなくなりました!
1分間あたりのメモリ確保量は 25.8GiB から 153MiB になり、約 99.4%削減できました。
続いて、Datadog APM で確認できるランタイムメトリクスについても見ていきます
GC
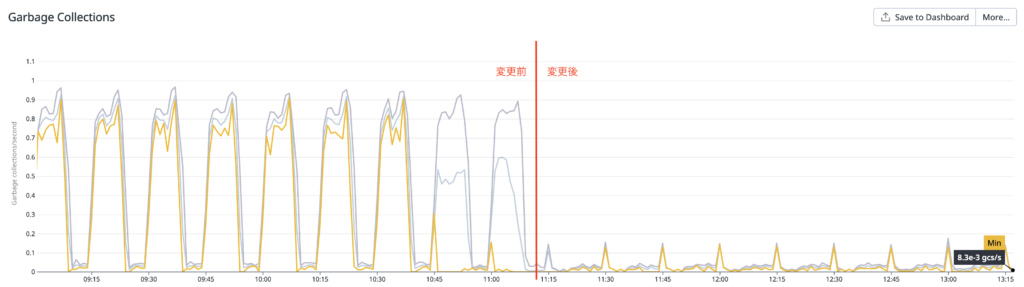
こちらは 1 秒あたりの GC の回数を表すメトリクスです。
デプロイ前後で大きく変化しているのがわかります!プロファイリング結果からヒープのメモリ確保量が激減していましたが、この影響によって GC の頻度も減ったと考えられます。
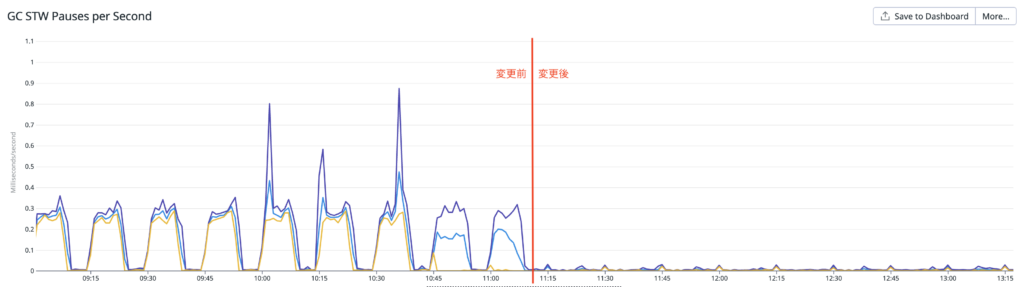
こちらは、GC による stop the world でアプリケーションの実行が停止していた時間です。こちらも大幅に減っているのがわかります 👏
本番環境ではベンチマークテスト時よりも実行時間が大きく減少しました。
これは GC の回数が減ったことで GC に CPU が割り当てられる頻度が減少したこと、stop the world により実行が完全に停止することが減ったのが要因と考えられます!
リソース使用状況
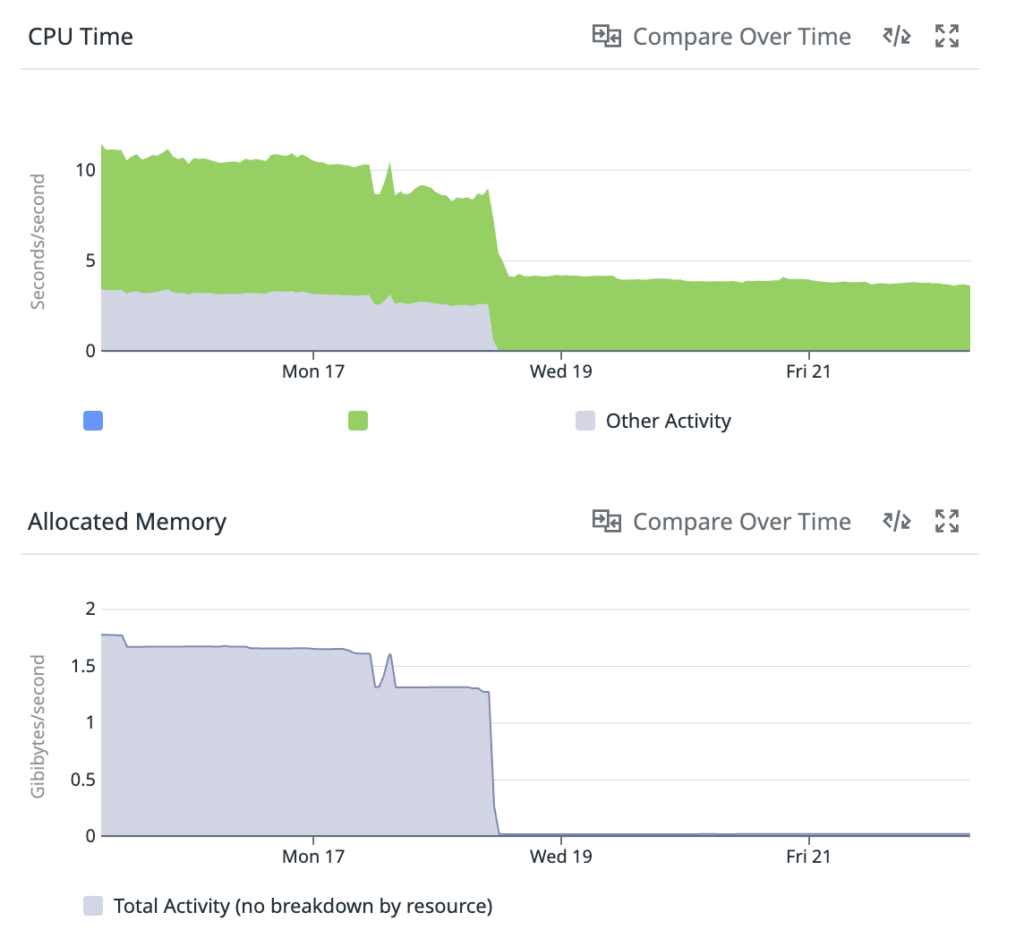
デプロイ前後でのCPU時間とメモリ確保量の変化は上図の通りです。
大きく改善していることが確認できました!
終わりに
本記事では、システムのボトルネックの特定から、リファクタリングによる性能改善までの一連の過程をご紹介しました。
Datadog を活用することで、ボトルネックの特定からリファクタリング後の効果検証までできました!この一連の流れを通して、課題特定や効果検証のためにシステムの observability を確保する重要性について実感できました。
また、iterator と range over func の活用によってメモリ確保量を大幅に削減し、処理速度を向上させることができました!大規模な処理が行われる環境では、わずかな実装の違いがパフォーマンスに大きな影響を与えることを改めて実感しました。
今回の経験を今後の開発にも役立てていきたいなと思います!