
慶應義塾大学大学院修士2年の小松 拓実です。普段はマルチモーダル言語処理に関する研究を行っています。今回は”新しい未来のテレビ”ABEMAのインターンで、DeepLearning技術を活用し、バーチャル動画の生成を行いました。
早速ですが、以下が今回生成した動画の例です。
ここでは3種類の動画を示しました。
1つ目の動画は男性の声を基に生成した音声と男性の画像から生成した動画、2つ目の動画は女性の声を基に生成した音声と男性の画像から生成した動画、最後の動画は、英語の音声を生成させた結果を示しています。
この記事では、バーチャル動画を生成する方法や、その背景について伝えたいと思います。
バーチャルヒューマンの活躍に期待大
昨年、COACHがバーチャルヒューマンimmaさんを起用し話題となりました。詳細については、公式サイトをご確認ください。
https://japan.coach.com/feature/find-your-courage.html
このようにバーチャルヒューマンのクオリティは急速に上がっています。その活躍の場は、動画制作、広告・マーケティングに加え、インタラクティブな教育やカスタマーサポートなど多岐にわたっています。
本記事は動画制作事例ではありませんが、ABEMAオリジナルのリアリティショー番組「Hashtag House」においても、ゲームマスターとしてimmaさんにご出演いただいています。別のアプローチとして生成AI由来のバーチャルヒューマンも登場し始めていますが、クオリティの点ではimmaさんに及ばない印象でした。
今回の取り組み
今回のインターンでは、生成AI由来のバーチャルヒューマン技術のサーベイを行いました。そして、実際に事業のDXでバーチャルヒューマンを活用できるとしたらどのようなポイントがあるのかを部署の社員の方と議論しました。最終的に音声合成にGPT-SoVITS、動画生成にHallo2を採用し、サイバーエージェントのお金とリソースを用いて、社員をバーチャルヒューマン化してみました。
バーチャルヒューマンを利用した接客に注目が集まっている
今回ご協力いただいた部署には、ABEMAの内部業務のDX、特に接客業務のDXについて議論をさせていただきました。
接客業務にもいろいろありますが、特にECサイトのお問い合わせや公共の場のサイネージが、だんだんバーチャルヒューマン化されています。例えばABEMAがある渋谷駅でも最近スマートシティ化が進み、バーチャルヒューマンが観光スポットなどを案内してくれています。こちらの事例については、リンク先をご覧ください。
ABEMAでもバーチャルヒューマンを利用した接客の可能性を探るべく、様々な議論を行いました。
今日から始めるバーチャルヒューマン
技術の進化により、バーチャルヒューマンを作成するハードルは劇的に下がりました。
特に、音声合成(TTS: Text-To-Speech)や動画生成技術においても、オープンソースのツールやサービスの促進に伴い、個人でも高品質な音声・映像コンテンツの作成が可能になっています。
たしかに、2023年以前、大規模なDeepLearningモデルの学習には豊かなリソースが必要でした。しかし、基盤モデルの開発や事前学習済みモデルのオープンソース化により、GPU1台で1枚の画像と数秒の音声さえあれば、バーチャルヒューマン動画の作成が可能になっています。
個人で利用可能なツールのオープンソース化
DeepLearningの発展に伴い、音声や動画に関する技術は著しい発展を遂げました。
① 2023年以前: 音声とアバターの発展
2023年以前、音声合成技術は一般的に幅広く行われてきました。最も身近な例としてAppleのSiriが挙げられます。Siriは自然な音声応答を提供するバーチャルアシスタントとして、現在でも多くのユーザに使用されています。
また、アバターの分野では、Metaのインスタグラムにおいてアバター機能が2022年に登場し、アバターを用いたコミュニケーションが可能となりました。初期のアバターは静止画ベースでしたが、近年は音声と組み合わせたリアルなアニメーションが可能になり、ユーザーの個性をより豊かに表現できるようになりました。

② 生成AIの登場
生成AIの発展により、誰でもテキストから画像や動画を生成することが可能になりました。
代表的な画像生成AIとしてStable Diffusionが挙げられます。Stable Diffusionは2022年に登場した拡散モデルを活用した画像生成技術の一つであり、誰でもテキストから画像を生成することを可能にしました。
一方、2024年に登場した動画生成AIとしてOpenAIのSoraが挙げられます。SoraはStable Diffusionと同様にテキストから動画を直接生成することができ、誰でも利用可能なツールとして公開されています。既存のGANベースの動画生成と異なり、Soraは物理シミュレーションを考慮した動画生成を可能にし、既存手法よりも高い品質の動画生成を可能にしました。
https://openai.com/ja-JP/sora/
③ 2023年以降: 音声技術の発展
音声合成や映像生成技術の発展に伴い、計算資源を抑えつつ、高品質な音声・映像を生成する技術が発展しました。以下にいくつか例を示します。
- VALL-E-X:Microsoftにより開発された音声合成モデル。3秒ほどの短い音声サンプルから話者の声質を模倣した音声合成を可能にしています。また、多言語にも対応しており、入力となる言語と異なる言語での音声合成を実現しています。
- GPT-SoVIT:VALL-E-Xを拡張した音声合成モデル。入力されたテキストから音声特徴量を抽出するテキストエンコーダ、話者の音声から話者固有の特徴量を抽出する音声エンコーダ、得られた特徴量を統合し、最終的に音声波形を合成するデコーダで構成される。zero-shot、few-shotが可能であり、多言語にも対応しています。
- Hallo2:音声およびポートレート画像を入力し、アニメーション化を行う動画生成モデル。1枚のポートレート画像とサンプル音声からアニメーションを作成することができます。また、既存手法では短時間の動画生成に留まっていましたが、Hallo2では、最大数時間の長時間かつ高解像度の動画生成を可能にしました。
④ 2024年以降: 高精度・リアルタイム化の追求
2024年以降、 高精度かつリアルタイムで高速かつ高品質な音声・映像を生成する技術が提案されています。例えば、高精度なリアルなポートレート動画を生成する技術としてHallo3が挙げられます。Hallo3では、後述の通り、Transformerベースの拡散モデルを使用した動画生成手法であるDiffusion Transformer (DiT)の導入および3D VAEを用いた参照画像からの人物の特徴量を条件付けることにより、より時間的な整合性のある高品質な動画性性を可能にしました。
一方で、リアルタイムな動画生成に取り組んだ手法として、VASA-1が挙げられます。
VASA-1はMicrosoftによって提案された音声駆動型Talking Face生成モデルです。1枚の画像および音声を入力として、リアルな顔の動きをリアルタイムで生成することが可能です。VASA-1では、Diffusion modelを用いて、直接画像(pixel)を生成するのではなく、顔の動き(モーション)を潜在空間上で生成します。これをもとに、デコーダを用いて動画を生成することにより高速化を実現しました。これにより、512×512解像度の画像で、40FPSのリアルタイム推論を可能にしています。
リアルタイムなバーチャルヒューマンの映像生成が可能になれば、より現実的かつパーソナライズされた接客が可能になります。
結果
1画像および1音声から動画の生成を可能にした
今回、実際に1枚の画像およびサンプルとなる音声を用いて音声合成および動画生成を行なった結果が冒頭のようになります。
タスクを組み合わせることで、複雑なタスクの実現を可能に
今回の調査では、「任意のテキストをまるで本人が話しているかのような動画を生成する」タスクを一度に実現する高精度なモデルは見つかりませんでした。
そこで、「まるで本人が話しているかのような」の部分をvoice cloningおよび音声合成 (TTS: Text-to-Speech)、「動画を生成する」部分をTalking Head Generationという二つのタスクに分解することにしました。
高精度な手法のオープンソース化が進む現代において、一見複雑に見えるタスクでも、適切に分解し、モデルや技術を組み合わせることにより、実現可能であることが示されました。
今回は、TTSにはGPT-SoVITを、Talking Head GenerationにはHallo2というオープンソースなモデルを用いました。これらの手法はzero-shotでも高品質なTTSおよび動画生成が可能であり、特にGPT-SoVITは日本語でのfine-tuningも容易に行うことが可能であるため、今回はGPT-SOVITのzero-shotおよびfine-tuningの結果と生成した音声を用いてzero-shotでHallo2で動画生成を行うことにしました。
また、モデルの学習および推論には、CyberAgentのプライベートクラウドであるCyCloudにおいて、VRAM40GBの1枚のA100を用いて実験を行いました。
音声合成の発展
今回の動画生成で一番難しいのは音声合成パートです。
音声合成技術はDeepLearningの発展に伴い、高品質になってきました。以下では、GPT-SoVITを構成する音声技術手法およびその発展について述べます。まずは、音声合成およびその周辺技術の5種類の進化についてです。
- tacotron2: 代表的な音声合成モデル音声合成技術の発展の中で、tactronはEncoder-Decoder構造を用い、文字列から直接スペクトログラムを生成するTTSモデルの代表的なモデルとして広く知られています。特に、tacotoron2は、既存のTTSモデル手法と比べて音声品質を大幅に向上させ、その後のTTS技術の発展に大きな影響を及ぼしました。現在では、多くの手法がTactron2をベースに発展しており、TTS技術の基盤となる代表的な手法の一つです。tacotoron2は、入力テキストを直接メルスペクトルに変換し、WaveNet等のボコーダーを用いることで、メルスペクトルから音声波形を生成します。Encoder-Decoder構造を採用しており、LSTMを用いたアテンション機構により、テキストと音声の関係を学習し、自然な音声の生成を可能にしています。一方で、中間表現として、メルスペクトルを用いる性質上、細かい音響情報や話者の情報などが欠落するという課題が指摘されていました。
- HuBERT: 音声特徴量の表現力の向上音声特徴量を獲得する既存手法としてWav2VecやRNNベースの手法が存在しました。RNNの構造上、逐次的に情報を処理するため、過去の情報を長期間にわたって保持することが困難であり、情報が徐々に失われることが知られています。(勾配消失) これにより、音声データの時間的な関係をモデル化する際に、長距離の依存関係を適切に捉えることが困難であるという課題がありました。HuBERT (Hidden-Unit BERT)は、自己教師あり学習を活用し、大規模な音声データから有用な音声表現を学習する表現学習モデルの一つです。特に、音声の時間的な構造を捉えることを可能にしています。HuBERTでは、音声波形を直接Encode後、BERTのマスク付き言語モデルと類似した学習手法を用いて、長距離の音声依存を捉えることを可能にしています。具体的には、音声データの一部をマスクし、マスクされた部分のラベルを予測します。ここで、ラベルは、音声波形から抽出したMFCC (メル周波数ケプストラム係数)を用いて、k-meansクラスタリングを行うことで音声のpseudo labelを生成します。これにより、従来のメルスペクトグラムを使用する手法と異なり、HuBERTは直接音声データから、時間的な依存関係を効果的にモデル化し、言語情報と音声情報を統合した特徴量の獲得を可能にしています。

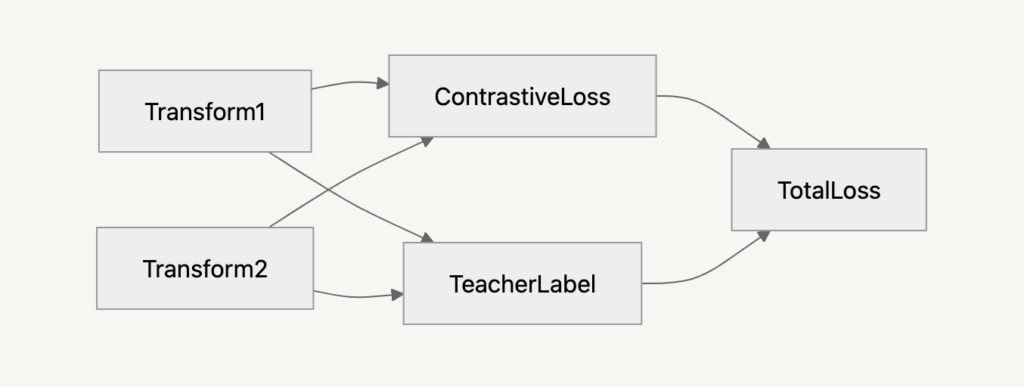
- ContentVec : 話者情報の分離HuBERTは優れた音声特徴の獲得を実現した一方で、話者情報を強く保持してしまうという課題がありました。すなわち、異なる話者が話した同一の音声が異なる特徴として捉えられてしまい、話者によって音声表現が変化してしまうという課題が存在しました。この原因として、HuBERTは教師ラベルとしてMFCCベースのk-meansクラスタリングを用いたpseudo-labelを使用することが挙げられます。このpseudo-labelには話者情報が含まれているため、HuBERTの学習過程で話者依存の特徴が残存し、結果として音声表現が話者に依存される形で学習されてしまいます。しかし、音声データは連続的であり、単語や音素の明確な境界が存在しないため、適切なクラスタリングが困難であり、話者情報が残存しやすいという問題もあります。ContentVecはこの課題を解決するために、話者情報を効果的に分離し、音声の内容に基づいた特徴量を獲得する手法です。具体的には、SimCLRのような対照学習を導入しており、話者情報の影響を小さくするために、異なる話者の音声間の特徴量の類似度を抑制しつつ、同一話者の異なる発話の特徴量を近づけることにより、話者情報を分離します。これにより、話者情報を保持しつつ、コンテンツ内容(音声内容)にのみ焦点を当てた音声特徴の獲得が可能となり、話者に依存しない音声認識やTTSが期待されます。
- VALL-E-X : マルチリンガル音声合成HuBERTは音声データに対する自己教師あり学習を行う際に、BERT-likeなマスク付き学習を用いることで特徴表現を学習する手法です。入力は音声波形のみです。一方で、VALL-E-Xでは、音声とテキストのペアを直接扱い、テキストと音声を統合的にモデル化するCross-Attention機構を導入することで、音声とテキストの関係を明示的に捉えることを可能にしています。実際にVALL-E-Xを用いて、hugging-faceのサンプル音声から、音声を生成してみます。
ここでは、1つ目の音声およびそのスクリプトを基に、2個目の音声を生成しています。生成された音声品質がかなり高いことがわかります。VALL-E-Xの高い音声合成能力は単なるCross-Attention機構によるものだけではなく、ニューラルコーディック表現と超解像度化を行っている点にもあります。ここで、ニューラルコーディックでは、音声を離散的なトークン (Acoustic token)に変換し、そのトークン列を直接予測することで、音声波形を再構築します。これにより、メルスペクトグラムと異なり、情報の損失を抑えつつ音声の細かい情報を保持することができます。VALL-E-Xは、ニューラルコーディック言語モデルを活用したクロスリンガル音声合成モデルです。VALL-E-Xでは、音声波形の生成にメルスペクトグラムを使用せず、ニューラルコーディックを用いてAcoustic tokenを直接生成します。VALL-E-Xでは、Acoustic tokenを用いた言語モデル構造を持つため、In-Context Learningにより、特定の話者の音声を異なる言語で生成する (マルチリンガル音声合成)やゼロショットでの音声合成を可能にします。
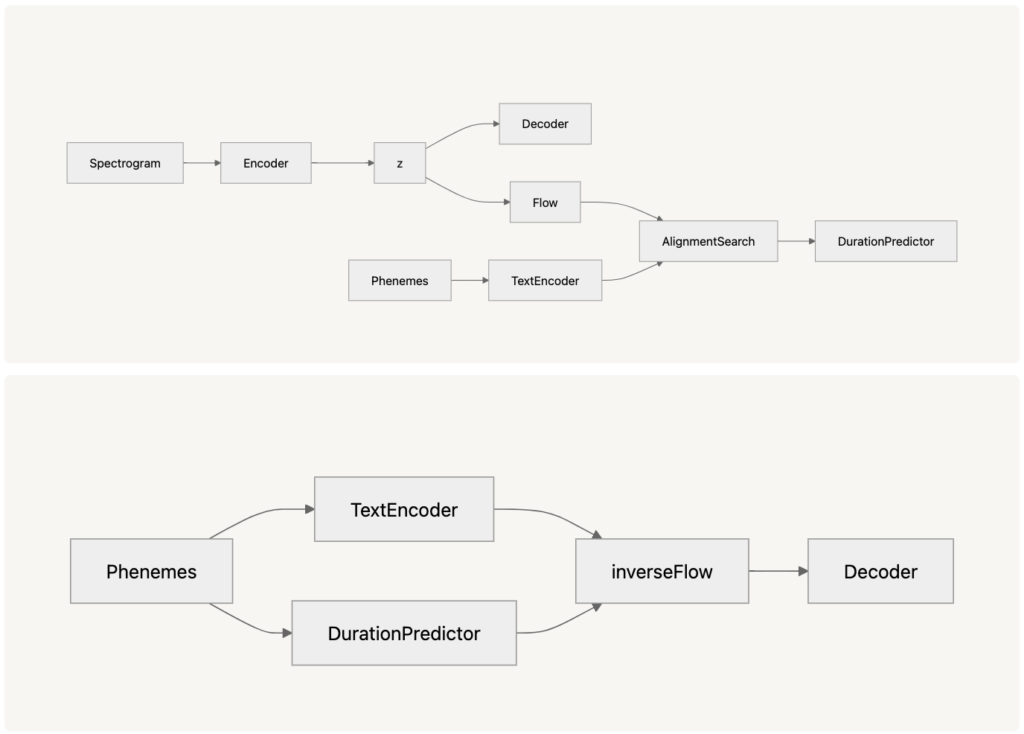
- VITS (Variational Inference Text-to-Speech)VITSはVALL-E-X等と同様に、メルスペクトルを介さずに直接音声波形を出力するEnd-to-Endなモデルです。既存手法と異なり、VITSでは、VAE・正規化フロー・敵対的学習を組み合わせることで、より高品質な音声合成を実現しています。(上図: training / 下図: inference)既存のメルスペクトグラムを介する手法では、テキストを決定論的なマッピングに基づいて、変換するため、イントネーションや会話のリズムなどの音声の多様性を表現できないという課題がありました。そこで、VITSでは、VAEを用いることで、発話のバリエーションを潜在変数zによってモデル化することで、多様性を適切に表現することを可能にしました。一方で、VAEの潜在変数の分布は単純なガウス分布でN(0, I)であることが多いです。実際の音声データの分布は単純なガウス分布ではなく、複雑で非線形な構造を持っているため、単純なガウス分布では表現力が不十分です。そこで、VITSでは、正規化フローを適用し、以下のような可逆変換を適用することで、単純なガウス分布を複雑な分布に変換することを可能にし、音声の豊かな特徴量の獲得を実現しました。$$ p_{\theta}(z \mid c) = {N}(f_{\theta}(z); \mu_{\theta}(c), \sigma_{\theta}(c)) \left| \det \frac{\partial f_{\theta}(z)}{\partial z} \right|, c = \begin{bmatrix} c_{\text{text}}, A \end{bmatrix} $$最後に、VITSでは、音声波形の生成精度を高めるために、HiFi-GANの敵対的学習を用いて合成音声の品質を向上させました。損失関数は一般的なGANベースの手法と同様に、識別器Dおよび生成器Gを用いて以下のように表されます。$$ L_{\text{adv}}(D) = \mathbb{E}_{(y,z)} \left[ (D(y) – 1)^2 + (D(G(z)))^2 \right]$$$$ \begin{equation}L_{\text{adv}}(G) = \mathbb{E}_z \left[ (D(G(z)) – 1)^2 \right]\end{equation} $$これにより、VITSはイントネーションや話者の特徴などの細かい特徴を反映した高品質な音声合成を実現しました。
音声からの動画生成
- Talking Heads Generationとは、静止画像と音声を入力し、自然な口の動き (Lip Sync)・表情 (Facial Dynamics)・頭部の動き (Pose)を含む動画を生成する技術です。Talking Heads Generationに取り組んだ代表的な手法としてHallo系列が存在します。
- Hallo (Hierarchical Audio-Driven Talking Head Generation)は、Talking Heads Generationに取り組んだ代表的な手法の一つであり、従来のLip Syncに留まらず、表情や頭部の動きも統合した動画生成に取り組んでいます。はじめに、音声入力 A をWav2Vecなどの事前学習済み音声モデルを用いて、特徴ベクトルを抽出します。$$ F_A = f_{audio}(A) $$ここで、f_audioはaudio encoderを表します。さらに、Halloでは、拡散モデルを用いて、過去の情報に基づくフレーム生成を行うことで、時間的な整合性を向上させています。具体的には、時間依存性を持つ潜在変数Z_tを拡散モデルを用いて学習します。$$ X_t = H(X_{t-1}, F_A, Z_t, C) $$ここで、Hは拡散モデル、Z_tは時間依存の潜在変数、Cは音声・テキスト・参照画像をCross-Attentionを用いて統合した制御情報を表します。ここで、時間的な一貫性を向上させるために、以下の損失を用いて学習します。$$ L_{temporal} = \Sigma_t ||X_t -X_{t-1}|| $$入力音声・入力テキスト・参照画像の特徴はそれぞれCross-Attention機構を導入し、統合します。ここで、Cross-Attentionは以下の式で示されます。$$ Q = W_Q X_t, K=W_kC, V=W_VC $$$$ Atten(Q, K, V) = \mathrm{softmax}(QK^T/\sqrt{d_k})V $$ここで、W_Q, W_K, W_Vは学習可能なパラメータ、d_kスケールファクターを表します。参照画像の特徴量C_image, 音声特徴量C_audio, テキスト特徴量C_textを統合し、オーディオ入力と視覚情報の関係を学習します。
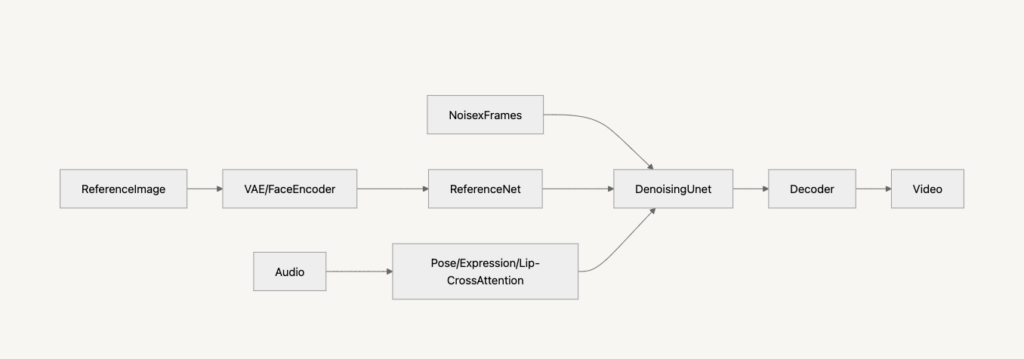
- Hallo2は、Halloをベースとし、長時間かつ高品質な動画生成を可能にした手法です。既存手法では、数秒程度の短時間の動画生成にとどまっていました。これは、時間整合性の欠如や長時間のフレーム生成による外観の劣化などにより、長時間の動画生成が困難であったからです。Hallo2では、これらの課題を解決するために、Patch-Drop AugmentationおよびGaussian Noise Augmentationを提案しています。Patch-Drop AugmentationHalloなどのようにフレームを逐次的に生成する手法では、前のフレームの外観情報が蓄積することで、参照画像から徐々に乖離してしまう問題が存在します。そこで、Hallo2では、各フレームをパッチに分割し、一部のパッチをランダムに削除し、削除された領域を参照画像の情報で補完することにより、動画の各フレームが参照画像を基準に再構築されるように誘導するPatch-Drop Augmentationを導入しました。はじめに、各フレームをK個のパッチに分割します。$$ I_{t-1}^{(k)}, k \in {1, 2, …, K} $$ここで、I_t-1^(k)は前フレームのk番目のパッチを表します。ランダムにパッチを削除するためのマスクM_(t-1)^(k)を導入する$$ M_{t-1}^{(k)} =\begin{cases}1, & \text{if } \xi^{(k)} \geq r \\0, & \text{otherwise}\end{cases} $$ここで、$$ \xi^{(k)} \sim U(0,1) $$は乱数、rは削除する確率を表します。マスクを適用することで、パッチを削除し、削除された領域は参照画像で補完します。$$ \tilde{I}_{t-1}^{(k)} =M_{t-1}^{(k)} \cdot I_{t-1}^{(k)}$$$$ I_t = \tilde{I}_{t-1}^{(k)} + (1-M_{t-1}) \cdot I_{\text{ref}}$$ここで、I_refは参照画像を表します。これにより、長時間動画であっても、参照画像の情報が強く保持され、時間的整合性を維持しつつ、自然な変化を保持することを可能にしています。さらに、従来手法は、前フレームの誤差が蓄積し、長時間動画の品質が劣化する問題が挙げられています。そこで、Hallo2では、前のフレームにガウシアンノイズを加え、拡散モデルを用いることで、デノイジング能力を高めることで、ロバスト性を向上させています(Gaussian Noise Augmentation)。はじめに、前のフレームにノイズを加えます。$$\hat{z}_{t-1} = \tilde{z}_{t-1} + \eta_{t-1}, \quad \eta_{t-1} \sim N(0, \sigma^2 I)$$これを用いて、拡散過程では以下の損失を用いて学習を行います。$$L = \mathbb{E}_{z_t, c, \eta, t} \left[ \left\| \eta – \epsilon_{\theta}(z_t, t, c) \right\|^2 \right]$$ここで、$$\epsilon_{\theta}$$はノイズを予測するU-Netモデルを表します。これにより、誤差の蓄積を抑制し、長時間動画でも品質を維持することを可能にしています。
- Hallo3
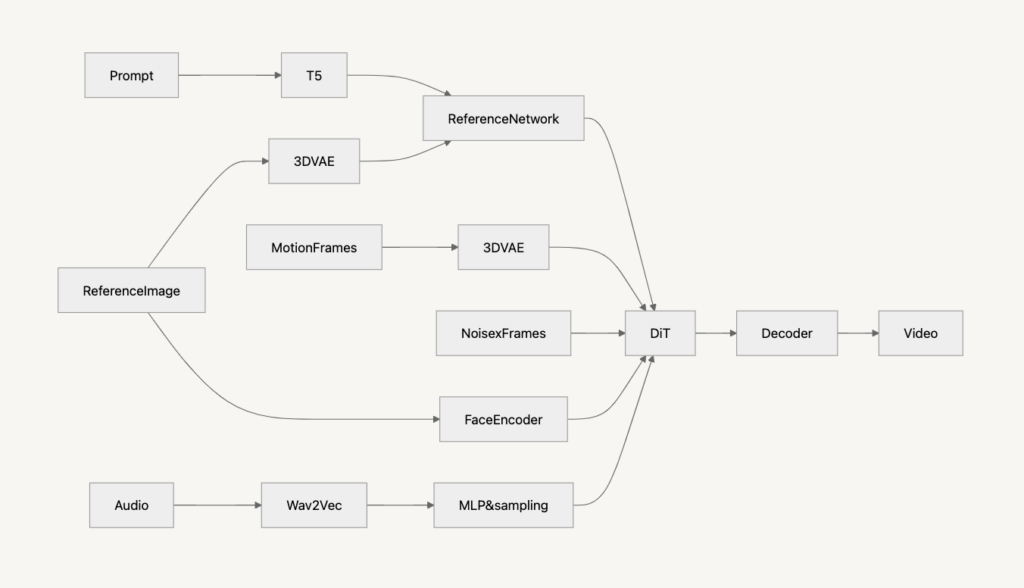
Hallo3は、Transformerベースの拡散モデル (Diffusion Transformer)を導入した手法で、Hallo2と比較して、より高品質かつ長時間のリアルな動画生成を可能にした手法です。HalloおよびHallo2では、CNNに基づくU-Net構造を用いた拡散モデルを使用していました。しかし、U-NetはCNNを用いるため、局所的な情報に依存し、画像全体の大域的な依存関係を捉えづらいという課題があります。また、U-Net構造は時間的な関係を明示的に考慮していないため、動的なシーン(背景の変化等)を適切に処理することが困難でした。そこで、Hallo3では、Transformerベースの拡散モデルであるDiffusion Transformer (DiT)を用いることで、画像全体の大域的な特徴を統合しました。さらに、単純なTransformerにおけるPositional Encodingでは、フレーム間の長距離依存性を適切に捉えることは困難でした。そこで、時間軸を考慮した3D RoPE (Rotational Positional Encoding)を導入することで、フレーム間の関係性を学習することを可能にし、フレーム間の時間的整合性を向上させました。また、Hallo2では、参照画像を直接条件付けに利用しているため、長時間の動画では、徐々に参照画像と異なる顔になることや、異なる視点での生成が困難であるという課題がありました。そこで、Hallo3では、参照画像をそのまま用いるのではなく、3D VAEを用いて参照画像の顔の特徴量を抽出し、Transformerを用いて統合することにより、時間的な整合性を捉えることを可能にしました。参照画像を3D VAEのEncoder (E_3D)に入力し、潜在特徴量z_idを取得します。$$ z_{\text{id}} = E_{\text{3D}}(I_{\text{ref}}) $$続いて、取得したz_idをTransformerを用いて統合することで、顔の一貫性を保持しながら時間的な整合性を保つことを実現しています。$$ z_{t,\text{enhanced}} = \text{Attention}(z_t, z_{\text{id}}) $$このように、3D VAEを用いることで、顔の形状や表情、奥行き等を時間的に一貫した形で表現することを可能にしました。これらの工夫により、Hallo3ではより高品質かつ長時間な動画生成を可能にしました。注意点として、冒頭の動画ではHallo3ではなくHallo2を採用したため、3DVAEによるPose生成等が不完全であることがわかります。
技術に関する学び
今回のインターンシップでは、TTS技術およびTalking Head Generation技術に焦点を当ててサーベイを行いました。DeepLearning技術を活用する中で、一つ一つの課題をどのようにして解決し、現在の高精度なモデルの実現に至ったかを掘り下げていくことは非常に興味深く、サーベイの醍醐味であると感じました。
さらに、これらの技術を実際に手元で動かして音声や動画を生成することで、さまざまな発見がありました。生成された音声が話し手の特徴をうまく反映しており、特に伸ばし方や息の使い方など、微細なニュアンスまで再現されていたことが非常に面白かったです。
また、Talking Head Generationを使用した際、実際の画像でも非常に高品質に、音声に合わせた口や表情等の動きが生成できていることは面白かったです。これらの技術を実際に体感することにより、今後のバーチャルヒューマンの可能性が広がることを強く感じました。
結びに
今回のインターンシップを通じて、特に印象に残ったことは、社員の皆さんの人柄の良さでした。社員の皆さんは非常にユニークで親しみやすく、フレンドリーに対応していただきました。わからないことがあれば気軽に質問できる雰囲気があり、何よりチームで一丸となって目標に向かって進んでいる姿は非常に印象的でした。このような環境で仕事をすることができ、貴重な経験を得ることができました。技術面だけでなく、チームワークやコミュニケーションの重要性も学ぶことができ、大変有意義な時間を過ごすことができました。
最後に本インターンシップを進めるにあたり、日頃からご指導や貴重な意見を頂きましたABEMA開発本部データ部の金田 健太郎さん・松﨑 遥さんに深く感謝いたします。また、レビュー・感想をいただいたAI事業本部 AI Labの山本 克彦さん、また、撮影・実験に快くご協力くださいました山泉 佑太さん・福岡 理緒菜さんに心より御礼申し上げます。最後に、日頃からさまざまな意見を下さいましたABEMAの社員の皆さまに心より感謝いたします。