
Muddy WebはMuddy = 泥臭いとして、Webフロントエンドの開発現場における話やケーススタディなど泥臭さのある話から、学びを得ることを目的として開催しています。
現場で遭遇した具体的な体験を元に、実際に明日から使えるかもしれないWebフロントエンドの技術や知識を、参加者の皆さまと共有し合うことを通して、フロントエンド開発の糧になれればと思います。
第11回はゲストに株式会社Cybozu様をお招きし、Webフロントエンドの現場から明日使えそうな技術や事例をトークしました。
本記事は、2025年03月21(金)に開催した「Muddy Web #11 ~Special Edition~ 【ゲスト: Cybozu】」において発表された「ノーコードツールの裏側につきまとう「20分岐」との戦い」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
おぐえもん
サイボウズ株式会社 開発本部 フロントエンドエンジニア(kintoneプラットフォーム) 2022年にサイボウズに入社し、kintoneのフロントエンド刷新に従事。 2024年からkintoneの主要機能の1つである「アプリ」機能のUI刷新をリード。 個人サイト「おぐえもん.com」で税金計算のWebサービスや雑学記事などを公開しています!
X: https://x.com/oguemon_com
GitHub: https://github.com/oguemon
はい、ではここからはサイボウズのおぐえもんこと小倉 且也が発表させていただきます。
今回のイベントは「#MuddyWeb」というハッシュタグで展開しておりまして、Xの検索画面でこのハッシュタグを検索していただくと、これからご紹介する登壇資料のURLを載せた投稿も確認できます。ぜひそちらも合わせてご覧ください。

では、早速始めていきたいと思います。
この発表では、サイボウズの主力製品であるkintone、先ほどテフンさんからも紹介があった製品ですが、そのフロントエンド刷新の取り組みの中で、常に課題となっている「大量の条件分岐」という、まさにMuddyな存在の実態についてお話ししていきます。
その中で、ノーコードツールを支えるフロントエンドの実装が実際にどのようなものなのかという点についても、あわせて簡単にご紹介できればと思っています。
また、発表の後半では、この大量の条件分岐や複雑な型を効率的にさばくためのテクニックについても触れていく予定です。

はい、ここで簡単に自己紹介をさせていただきます。私はサイボウズ株式会社に2022年の9月に入社しまして、そこから現在に至るまで、一貫してkintoneのフロントエンド刷新に取り組んでいます。

趣味では個人開発をいろいろやっていまして、ここにいくつか自作のサービスが並んでいます。その中でも「簡単手取り給料計算機」というサービスがありまして、これは額面の給料を入力すると手取り額がわかるというものです。普段、国からどれだけ社会保険料や税金が差し引かれているのかを視覚的に確認できるようになっていて、とてもおすすめのサービスです。

では、本題に入る前に、今回取り上げる製品の概要についてご紹介します。
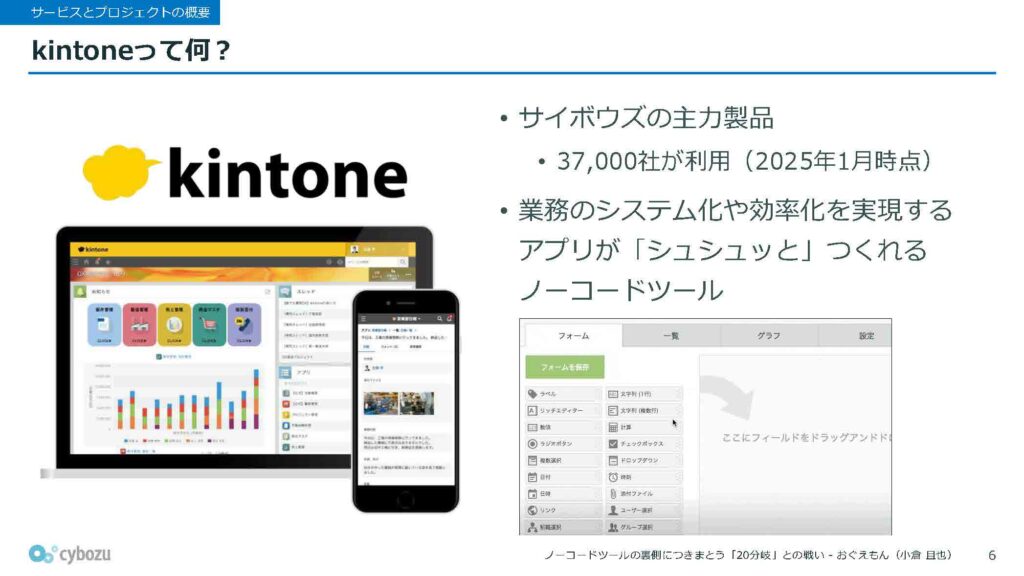
まず、kintoneとは何かという話から始めます。kintoneはサイボウズ社の主力製品で、簡単に言うと業務のシステム化や効率化を支援するためのノーコードツールです。主に「アプリ」というものを作っていくのですが、これはデータの入力フォームを二次元的に自由に配置してシュシュっと作れるようなイメージのもので、誰でも直感的に使えるのが特徴です。

アプリ機能に加えて、kintoneには他にもさまざまな機能が備わっており、非常に多機能なツールになっています。

kintoneは2010年頃に開発が始まったサービスで、そこから約15年が経過しています。その結果、フロントエンドの実装がかなりレガシーな状態になってきました。特に根幹の部分ではGoogle Closure Toolsが使われているのですが、現在ではこれを扱えるエンジニアが非常に少なくなっており、メンテナンスが難しくなっているという課題があります。
そこで、2021年頃から「脱レガシー」を掲げて、kintoneのフロントエンドをReactとTypeScriptを使ったモダンなコードに一から書き換えるという挑戦を進めています。
今回取り上げるアプリ機能についても、昨年から本格的に刷新に着手しており、その中で直面したMuddyな話を今回は共有したいと思っています。
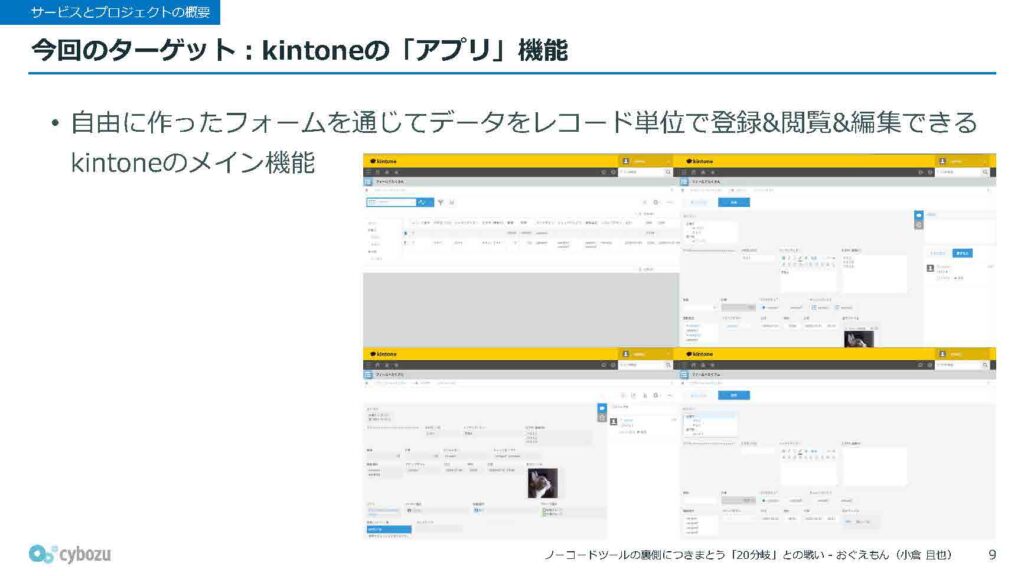
では、そのアプリ機能とは何かという話に移ります。この機能は、先ほどkintoneの特徴として紹介した部分でもありますが、ユーザーが自由に作成したフォームをもとに、データをレコード単位で登録・閲覧・編集できるという、kintoneの中核を担う機能になっています。
画面に表示された例を見ると、データの入力欄を二次元に配置したレイアウトになっているのがわかると思います。こうした柔軟な構成が可能な点が、kintoneの大きな特徴のひとつです。

Muddyな話に入る前に、先ほどお見せしたアプリ機能が実際にどのような仕組みで動作しているのか、どのように実装されているのかについて、まずは簡単に紹介していきます。
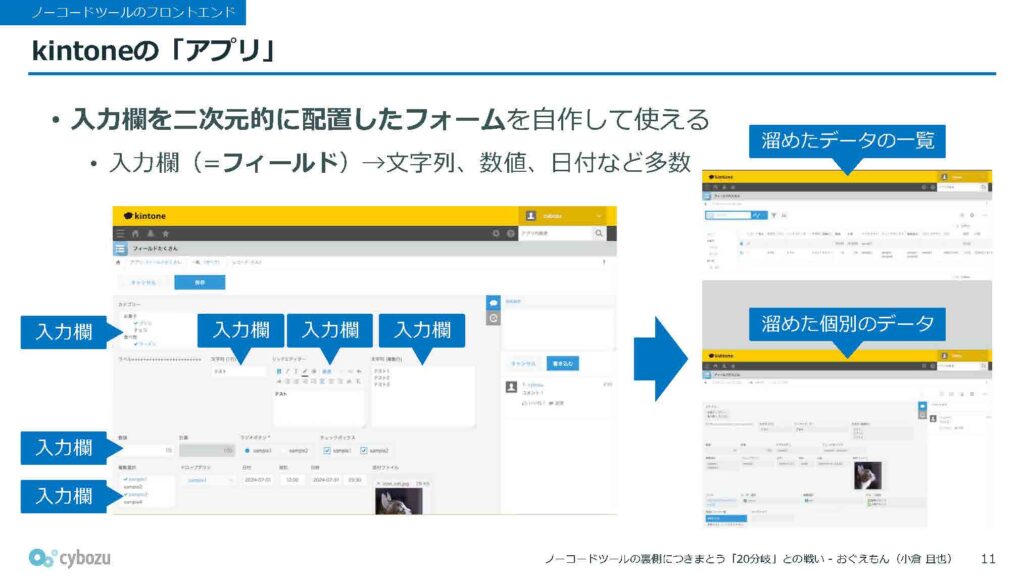
kintoneのアプリについて、少し繰り返しになりますが説明します。このアプリでは、入力欄をあらかじめ自作できるようになっていて、私たちはこの入力欄のことを「フィールド」と呼んでいます。これらのフィールドを二次元的に自由に配置したフォームを作成しておき、あとからそのフォームを使ってデータの追加や編集ができる仕組みになっています。
フィールドにはさまざまな種類があり、たとえばこの画面に表示している例では、テキスト入力欄やラジオボタンなど、用途に応じたコンポーネントが用意されています。
また、保存されたデータは一覧表示で表形式に見ることもできますし、個別のレコードを同じフォームの見た目で確認・編集することもできるようになっています。
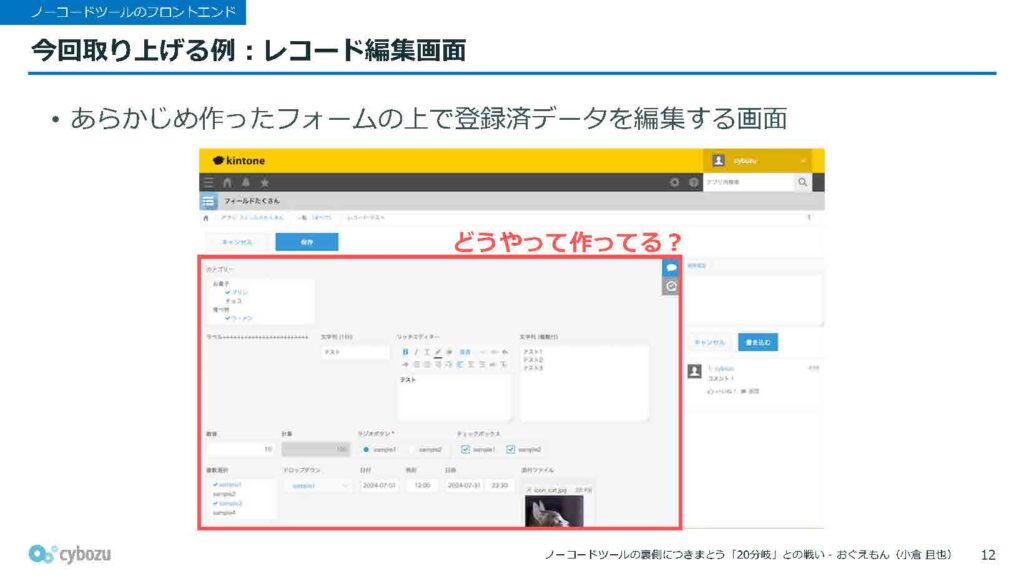
ちょっといろいろな機能がある中で、今回は「レコード編集画面」について取り上げます。これは、あらかじめ作成したフォームの上で、すでに登録されているデータを編集するための画面です。この画面がどのように作られているのかを、簡単に紹介したいと思います。
一見すると、さまざまなパーツが並んでいて、とても複雑そうに見えるかもしれませんが、実は話はけっこうシンプルです。
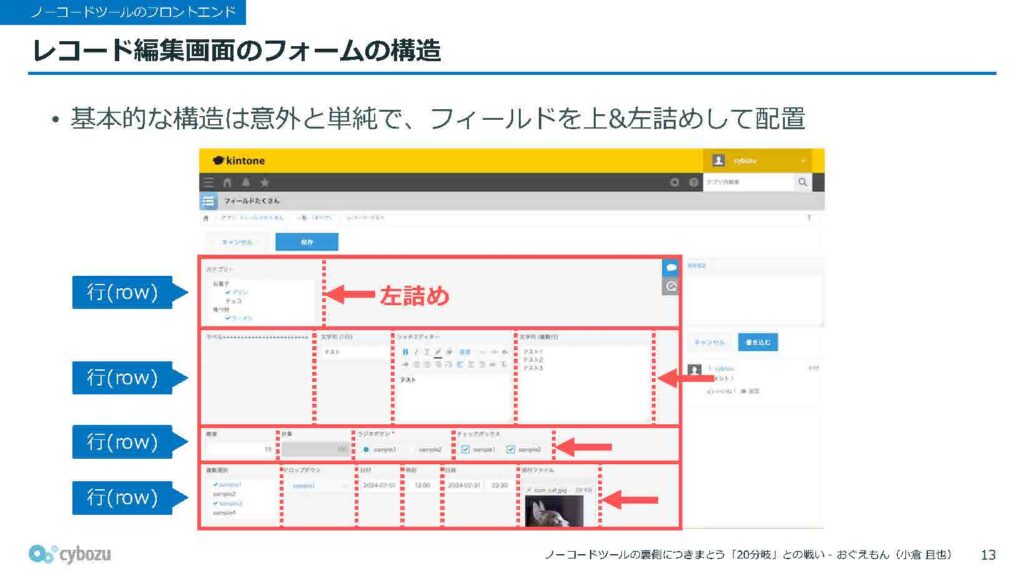
フィールドは上に詰めていき、同じ列に配置されるものは左に詰めていく、というルールに従って、ひたすら順に表示しているだけです。フォームは行単位で構成されていて、一つの行の中に複数のフィールドが並んでいる、いわばすし詰めのような状態になっています。
では、これをどうやって実現しているのかという話ですが、登場人物は大きく分けて3つです。

1つ目は「レイアウト」と呼ばれるもので、これは各フィールドの配置情報を保持しています。構造は二次元配列になっていて、どのフィールドがどの位置にあるかというレイアウト構成を示しています。2つ目は「スキーマ」と呼ばれるもので、これはレイアウトで配置されたそれぞれのフィールドの詳細な情報を持っています。たとえば、「このフィールドは何文字まで入力できるか」といった入力規則や、「必須かどうか」といった制約などが含まれています。
そして最後、これが最も肝心なもので「入力値」です。これはフィールドに流し込まれるデータ、つまり前回保存された値そのものを指しています。
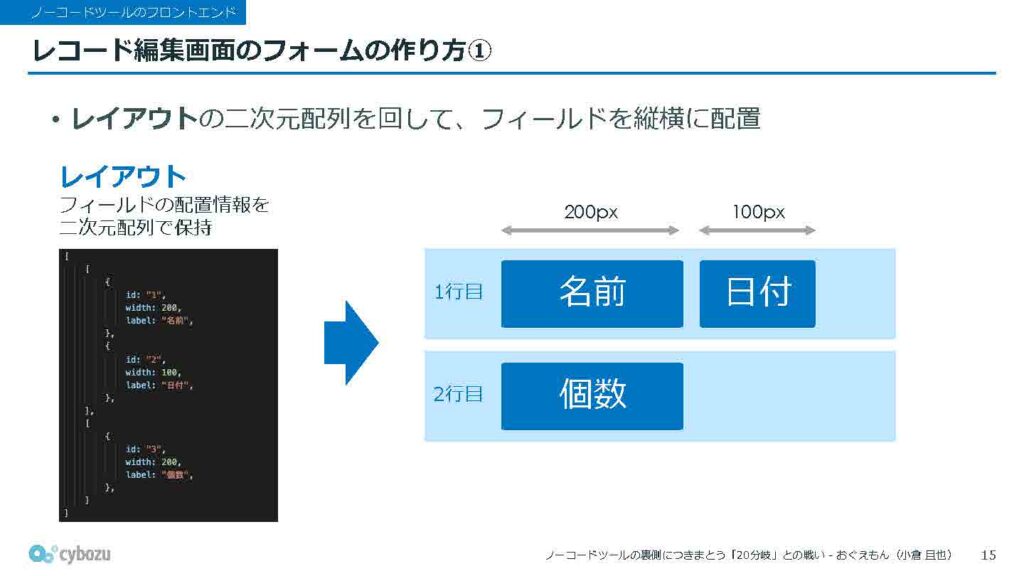
フォームの作り方は、おおよそ3つのステップに分かれています。まず最初に行うのは、レイアウトと呼ばれる二次元配列を順に回していく処理です。1行目の1つ目、2つ目といった具合に、フィールドを左から順に並べていきます。行のパーツをすべて配置し終えたら、次の行に進むという流れを繰り返し、全体の配置を行っていきます。
このとき、レイアウトの中にはフィールドごとの横幅の情報も含まれているため、ユーザーがフォーム作成時に設定した寸法がそのまま画面に再現されるようになっています。
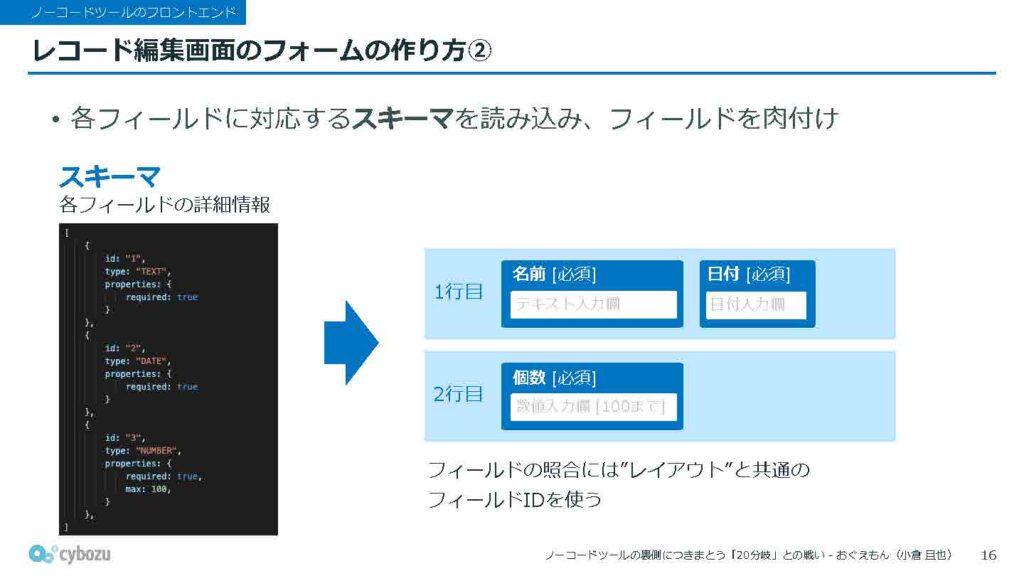
先ほどのレイアウト処理と並行して行うのが、各フィールドに対応するスキーマの読み込みです。これは、先ほど2番目に紹介した構成要素で、各フィールドの詳細な設定情報が入っています。
レイアウトの段階では、フィールドの寸法やタイトル程度の情報しかありませんが、このスキーマを読み込むことで、たとえば「何文字まで入力できるか」「このフィールドは必須かどうか」といった、より細かい設定が反映されるようになります。
この処理によって、フィールドに必要な属性が肉付けされ、ユーザーの操作やバリデーションに対応できる形に仕上がっていきます。
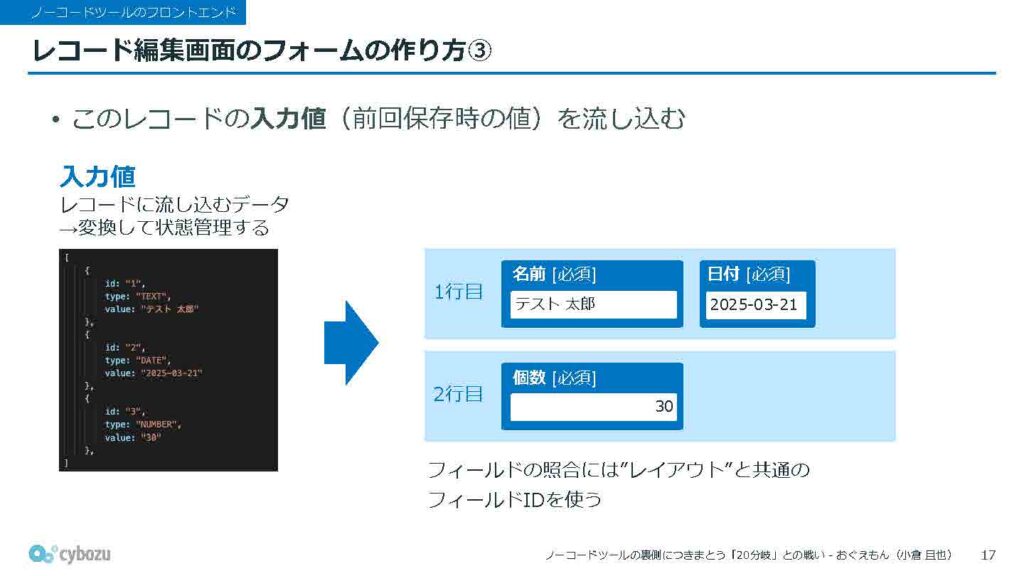
ここまでの処理が終わったら、最後のステップとしてレコードの入力値を各フィールドに流し込み、編集可能な状態にします。ただし、この入力値はそのまま直接使えるわけではなく、実際は状態管理ライブラリに渡すために、入力値を適切な形に変換しています。
これまで紹介してきたレイアウト、スキーマ、そして入力値の3種類の情報は、それぞれのフィールドごとに存在していて、1つのフィールドに対して3つの情報が紐づく構造になっています。これらは共通の「フィールドID」と呼ばれる識別子を使って照合し、正しく紐付けることで対応関係を保っています。
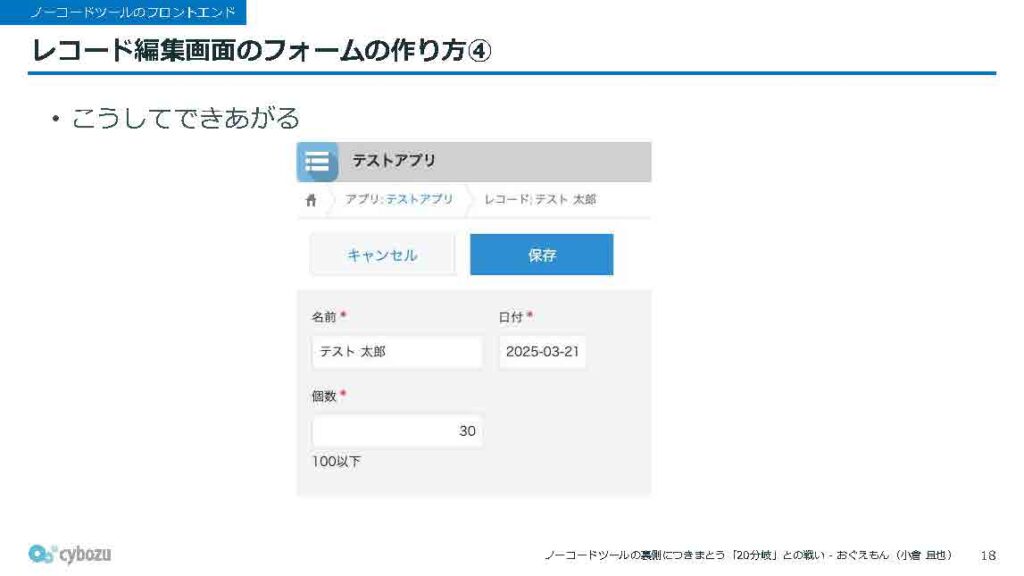
という流れで、先ほどお見せしたようなフォームが出来上がる仕組みになっています。
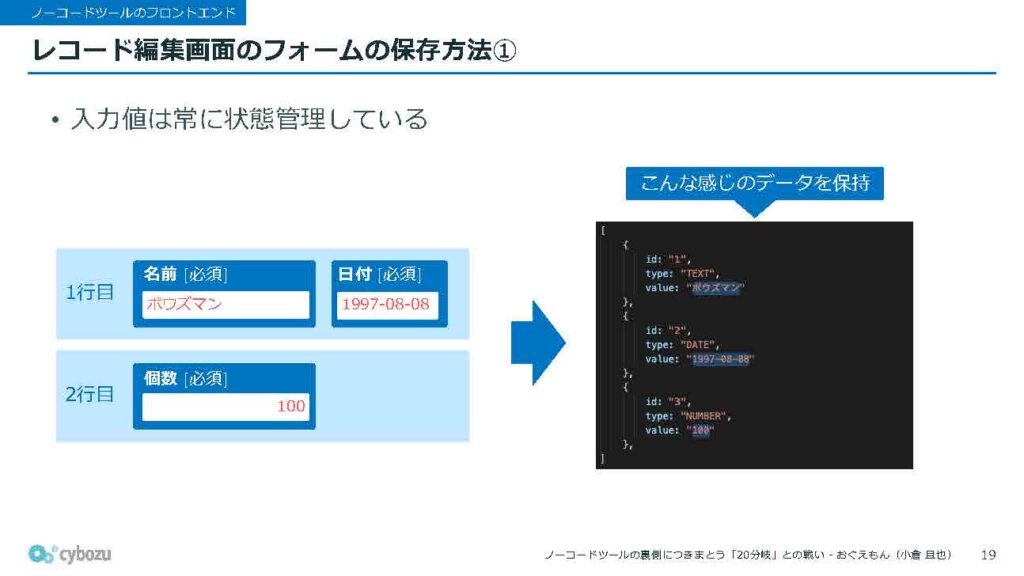
ここまではフィールドのフォームの作り方についてお話ししてきましたが、せっかくなので保存の仕組みについても紹介したいと思います。先ほども触れたとおり、入力値は常に状態管理されていて、ユーザーが入力した値が常に保持されている状態になっています。
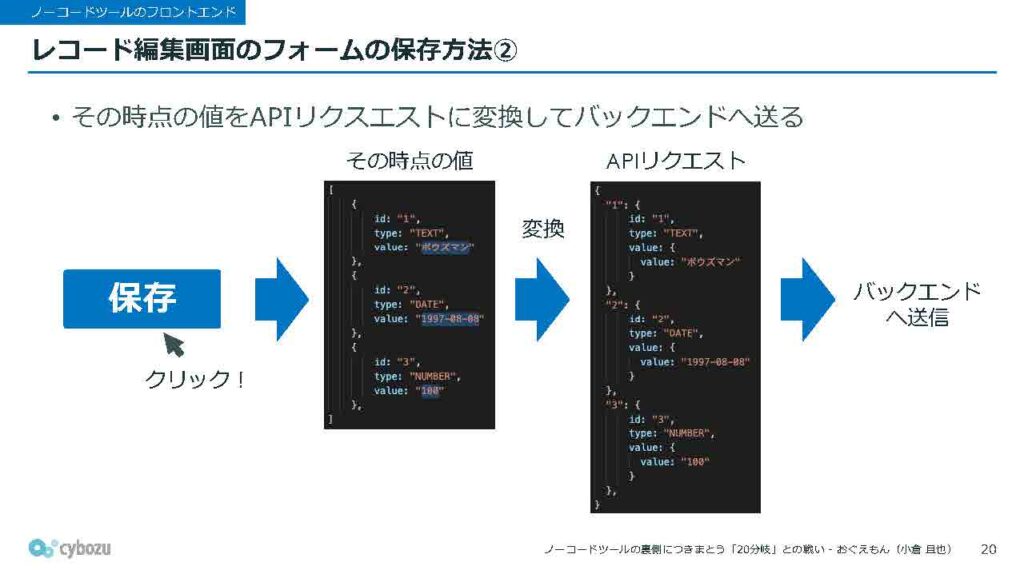
保存ボタンがクリックされると、その時点で状態管理ライブラリに保持されている最新の入力値を取り出して、それをAPIリクエストの形式に沿うように変換します。そして、その変換データをバックエンドに送信するという流れになっています。こうして聞くと、見た目は複雑に見えるかもしれませんが、意外とシンプルな仕組みで動いていることが分かるのではないかと思います。

そこで、今回のMuddyポイントということで、この仕組みの中身が実は条件分岐だらけで、かなり大変だったという辛い話をしていきたいと思います。
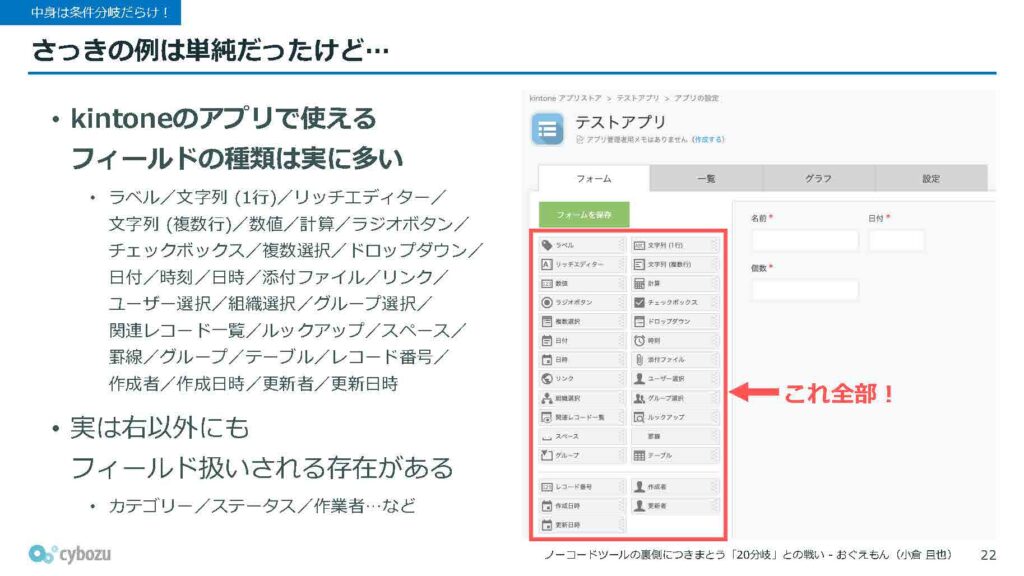
さきほどまでは、フォームの構造や仕組みについて、比較的シンプルな例で紹介してきましたが、実際のところはもう少し複雑です。kintoneのアプリで使えるフィールドの種類はとても多く、たとえばラベル、文字列一行、リッチテキストエディターなど、20種類ほどが用意されています。さらに、画面上には表示されないけれど、内部的にはフィールドとして取り扱っているものも存在していて、それらを含めると、最終的には30種類近くのものが登場することになります。
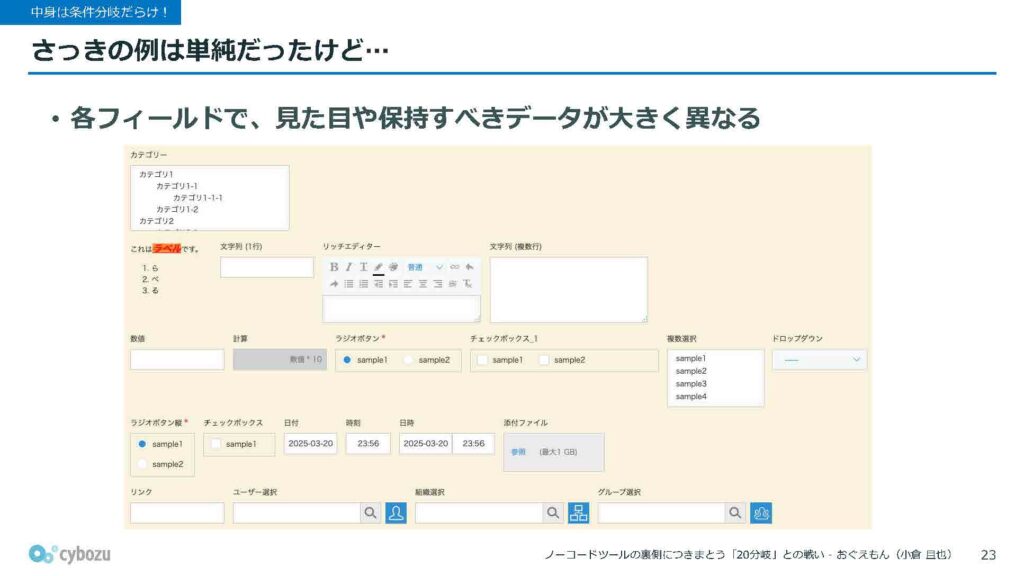
それぞれのフィールド、つまり入力欄は見た目も機能も大きく異なっています。たとえば、文字列を1つ入力すれば終わるシンプルなものもあれば、ラジオボタンやチェックボックスのように複数の選択肢から選ぶものもあります。また、ユーザー選択のように、検索欄に人の名前を入力すると候補が表示されて、それをクリックして選ぶといった、やや複雑な動作をするパーツもあります。
そういった背景があるため、各フィールドで保持すべきデータの構造も大きく異なります。
扱うデータの中には多様なフィールドが混在しているので、処理を進めるにはまずその1つ1つに対して、「これはどの種類のフィールドか」を特定し、その種類に応じた処理を行う必要があります。
そのため、フィールドごとに処理を行う場面では、ほぼ必ずと言っていいほどフィールドの種類ごとの条件分岐が発生します。このフィールドの種類が全部あわせて30近く存在しているため、条件分岐は常に20〜30分岐ほどあるというのが実態です。

ここからは、先ほどのような条件分岐がどのような場面で登場するのかお話ししていきたいと思います。
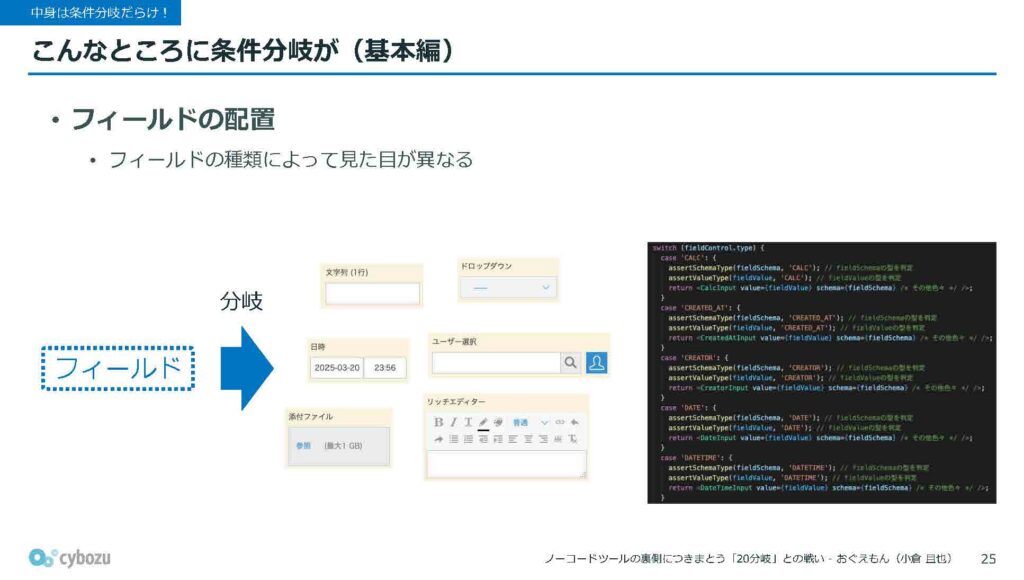
まずは基本編として、フィールドの配置に関する部分です。フィールドの種類によって見た目が異なるため、先ほど説明したようにレイアウトの二次元配列をぐるぐる回して配置していく際、各フィールドがどの種類なのかを判別して、対応するコンポーネントを使い分ける必要があります。
この処理の中で、フィールドの種類ごとの条件分岐が発生し、それがだいたい20個以上、多いときで30近くになります。毎回このループを回すたびに、そういった分岐を経て適切な見た目のフィールドが描画される仕組みになっています。
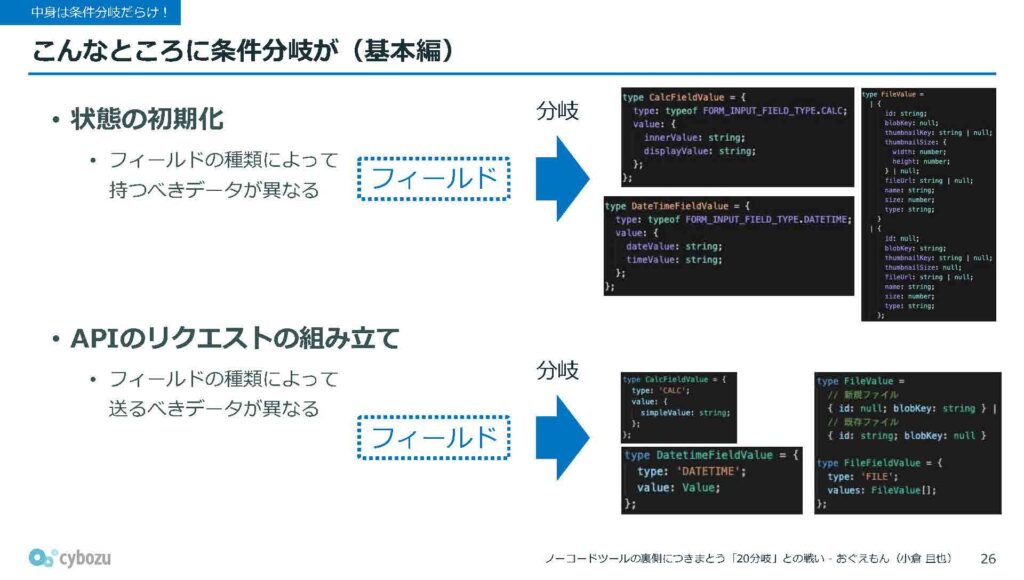
状態管理を通じて現在の値を管理しているという話を先ほどしましたが、この状態の初期化処理でも、フィールドの種類ごとに保持すべきデータが異なるため、毎回フィールドをぐるぐる回しながら、その種類を特定して、適切なデータを設定するようにしています。
また、APIリクエストを組み立てる際にも、フィールドの種類によって送信すべきデータの形が変わってきます。そのため、ここでも同様に、各フィールドの種類を判定して、それに応じたデータを構築する必要があります。
他にもさまざまなケースがありまして、一部のフィールドには「フィールドの中に別のフィールドが含まれている」という、少しややこしい構造のものも存在します。そういったフィールドにも対応する必要があります。
その一例が「テーブルフィールド」です。これはどういうものかというと、テーブルというフィールドの中に列を設定できるようになっていて、その列ごとに個別のフィールドが存在します。つまり、テーブルフィールドを表示するには、その中に含まれる各列のフィールドも一つずつ処理する必要があります。
当然ながら、その中に含まれる各フィールドが何の種類なのかを特定する必要があり、ここでもまた多くの分岐が生じることになります。
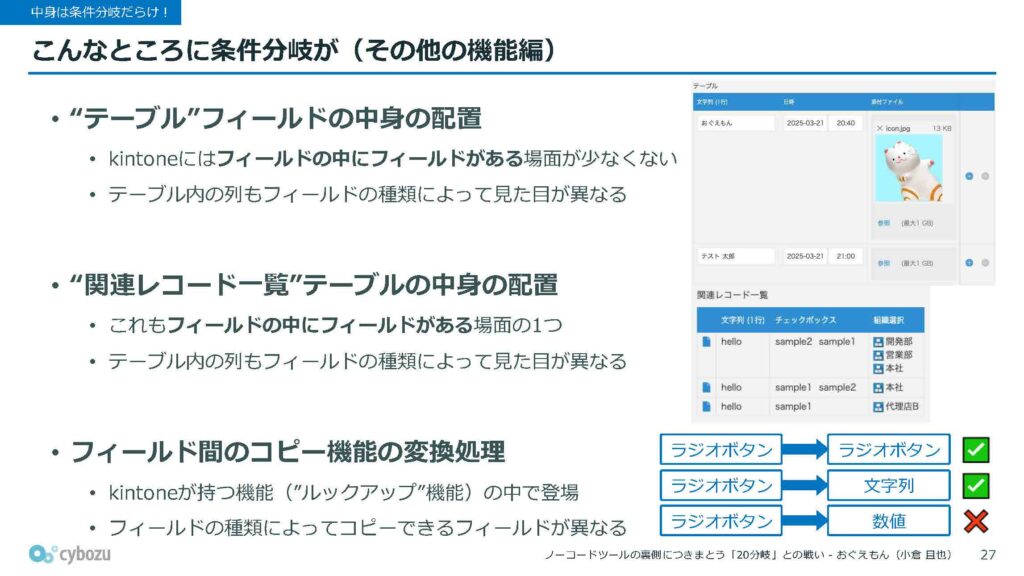
同じような構造を持つものとして、「関連レコード一覧テーブル」というフィールドもあります。これも、フィールドの中に複数の列があり、それぞれの列ごとにフィールドが存在するという構造になっています。そのため、描画処理を行う際には、各列のフィールドがどの種類なのかを判定する必要があり、ここでも条件分岐が発生します。
さらに他にも、「フィールド間のコピー機能」に関する変換処理があります。これはkintoneの便利な機能のひとつで、あるフィールドの値を別のフィールドにコピーすることができるというものです。フィールドの種類によってコピーできるフィールドが異なるため、コピー処理を行う前に、元のフィールドがどの種類かを判定する必要があります。
この処理においても、多くの条件分岐が発生することになります。
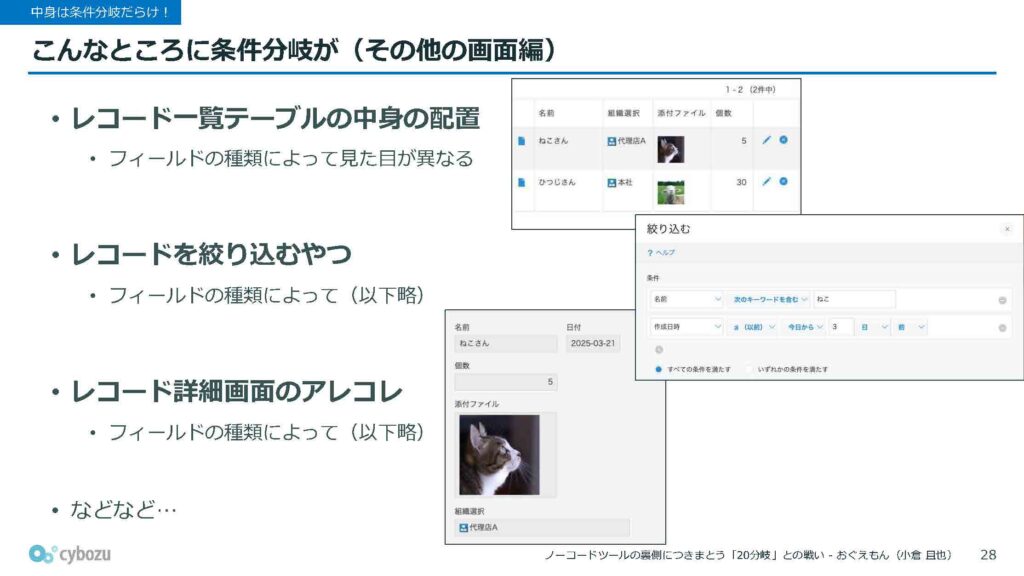
今お話ししたのは、冒頭で紹介した「レコード編集画面」に関する内容でしたが、kintoneのアプリ機能を構成する画面はそれだけではありません。レコード一覧画面やレコード詳細画面など、他にも色んな画面が存在していて、それぞれの画面でも「このフィールドは何か?」という判定が必要になる場面が数多くあります。
kintoneの中にいかに多くの条件分岐が潜んでいるか、ここまでの話から伝わったのではないかと思います。実際、この発表の準備にあたってkintoneのコードベースを調べてみたところ、20種類以上の選択肢がある条件分岐が少なくとも15か所以上存在していることがわかりました。

ここで「15以上」と書いているんですが、これはあくまで私のチームが担当しているコードベースの中だけで見つかった数です。なので、実際には全体で見ると15か所どころか、おそらく20〜30か所はあるんじゃないかと思います。また、「20択以上の条件分岐」と表現していますが、これ以外にも17択くらいの分岐も少なくありません。そういったものも合わせると、さらに多くの分岐がコード全体に存在しているということになります。

これまでのスライドの中で、TypeScriptの型を例示した場面がいくつかありました。フィールドの数が多く条件分岐が多発するのと同じように、フィールドの種類によって保持するデータの構造も異なるため、それに対応する型もそれぞれ管理しなければならないという、別のMuddyなポイントがあります。
具体的には、各フィールドを扱うために、まずスライドの左側にあるように各フィールドの専用の型を用意しています。これらは条件分岐のあと、各フィールドを制御する処理の中で使うための型です。
一方で、右側にあるのは、左のような各フィールドごとの型を20〜30個まとめてunion型にしたものです。こちらは主に、条件分岐をする前の段階で使われるもので、あらゆるフィールドが入っている可能性があるデータをひとまとめにして扱えるようにするための構造です。
このように、条件分岐の数に比例して管理しなければならない型の数も増えていくため、型の設計や運用もかなり複雑になっているというのが実情です。

ここまでお話ししてきたようなとてもMuddyな状況にどう対応しているのか。ここからは、これらをうまくさばいていくために、どんな工夫や仕組みを取り入れているのかをご紹介していきたいと思います。
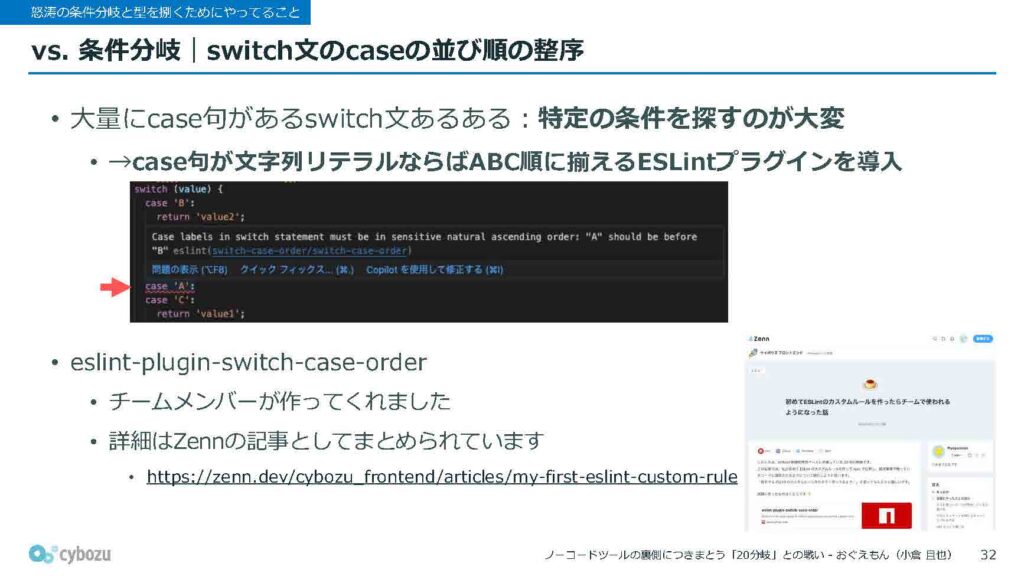
まずは、条件分岐との戦いについてです。この大量の条件分岐を処理する際には、主にswitch文を使っています。switch文は、たくさんのcase句を並べて一括で条件を分けられるという点で便利なのですが、case句の数が多くなればなるほど、特定の条件を探すのが大変になってきます。
一時期は、どのフィールドに対応するcase句がどこにあるのかを、毎回マウスのホイールをカリカリ回しながら探すという、なかなか手間のかかる作業を繰り返していました。さすがにこれは効率が悪いので、何とかしたいという思いが強くなってきました。
そこで、case句が文字列リテラルで書かれている場合、それをアルファベット順に自動で並び替えてくれるESLintのプラグインを導入することにしました。
これは、コードを見てもらえば一目瞭然ですが、case句がアルファベット順に整っていないとエラーを出してくれる、非常にシンプルなものです。このルールを取り入れることで、どのフィールドに対応するcase句が大体どの辺にあるのかが自然とわかるようになり、以前のようにホイールで探し回るといったことがかなり減りました。
ちなみにこのESLintプラグインは、チームメンバーが作ってくれたもので、npmパッケージとしても公開されています。もし似たような悩みをお持ちの方がいれば、ぜひ導入してみてください。
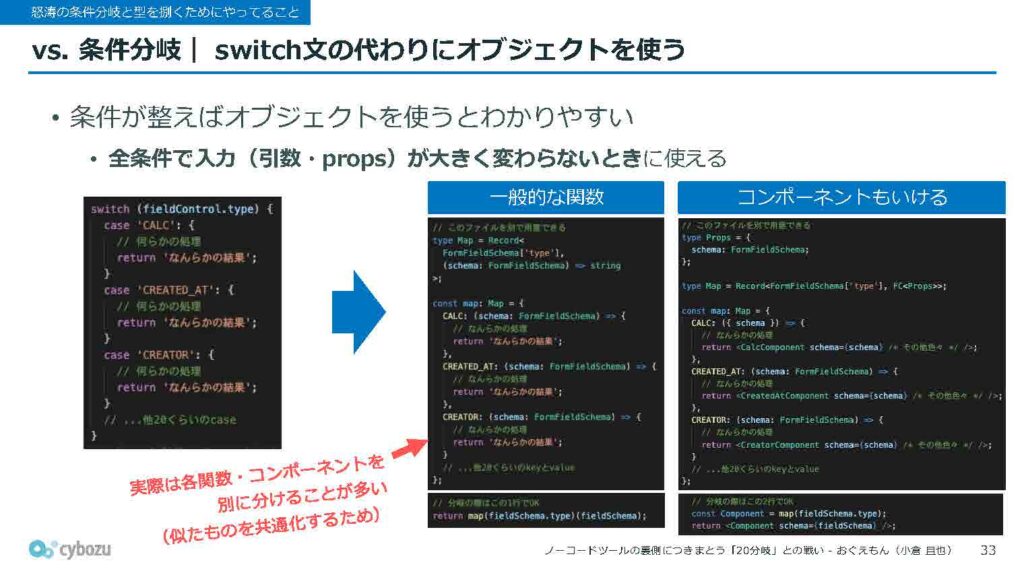
他には、条件分岐の処理をswitch文ではなく、オブジェクトを使って行うこともあります。これはあくまで条件が整っている場合に限りますが、switch文よりも見通しが良くて、わかりやすくなるケースがあるため、適宜使い分けています。
どういうことかというと、スライドの左側に示されているように、switch文ではカッコの中に変数を入れて、それに対してcase句で分岐していくという形式になります。
一方で、オブジェクトを使う場合は、switch文で使っていたcase句のリテラル値を、オブジェクトのkeyとして持っておきます。そして、そのkeyに対応する処理をvalueとして定義しておき、分岐させたいタイミングで、対象の値をkeyとしてオブジェクトに渡すことで、自然に処理が切り替わるという仕組みです。
これは関数の処理だけでなく、Reactのコンポーネントの切り替えにも使うことができるので、私たちのケースでは、レコード一覧表など、どのフィールドも似たような入力値を扱うようなシーンでよく使っています。オブジェクトでコンポーネントをまとめて管理し、条件に応じて切り替えるという形です。
こうした使い方は非常に便利で、条件が多いときほどコードの可読性や保守性がぐっと上がると感じています。
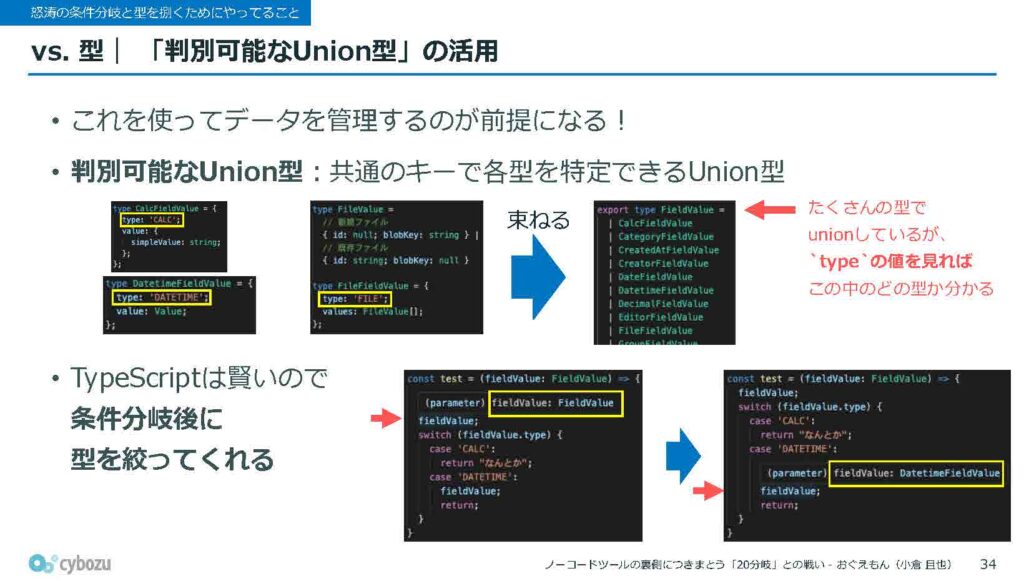
次は、無数にあるフィールドの型に対してどんなことをしているのかという話です。まず、こういった型の管理には判別可能なUnion型を使わないとやっていられません。
判別可能なUnion型というと少し大げさな名前がついていますが、やっていることはシンプルで、たくさんUnionしているそれぞれの型に対して共通のキーを用意しておいて、それぞれ一意なバリューをリテラルとして設定しておくというものです。
今回の場合だと、フィールド種別をtypeというキーで管理していて、そのtypeの値に対して文字列を割り当てるという形になっています。
こうしておくことで、たとえばたくさんUnionされたFieldValueという大きな型があったとして、その中から中身を特定したい場合には、typeというキーの値を見て、それが何の文字列かをチェックするだけで、どの型なのかがわかるようになります。
TypeScriptはこのあたりがとても賢くて、typeの値を文字列リテラルで比較すると、その後の処理では型が自動的に絞り込まれた状態で型推論されるので、扱いがとても楽になります。
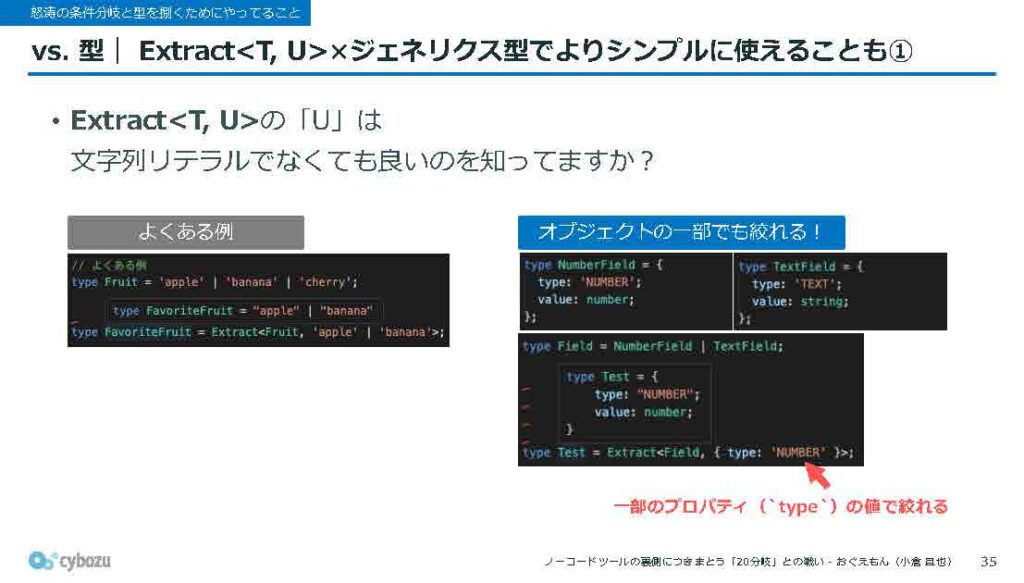
もう一つ、小ネタのような話になるんですけど、Extractとジェネリクス型の組み合わせによって、型をシンプルに扱うことができます。
Extractのユーティリティ型は、よくある例だと第2引数に文字列リテラルを渡して、特定の型だけを抜き出すといった使い方がよく紹介されがちです。ただ、実際には第2引数に指定できるのは文字列リテラルだけではなく、もっと柔軟に色んな型を使うことができます。
私たちのケースでは、この第2引数に、さきほど紹介した判別可能なUnion型のtypeの値を指定することで、特定のフィールド種別に対応する型だけを絞り込むようにしています。
こういった指定方法でも、TypeScriptはちゃんと意図通りに型を絞り込んでくれるので、非常に便利な機能として活用しています。これにジェネリクス型を掛け合わせるというのはどういうことかというと、スライドの右側にあるような使い方になります。
ジェネリクスのTの部分に、先ほどのtypeキーの値を指定しておくことで、そのtypeに該当する型だけを絞り込む、というジェネリクス型をあらかじめ用意しています。
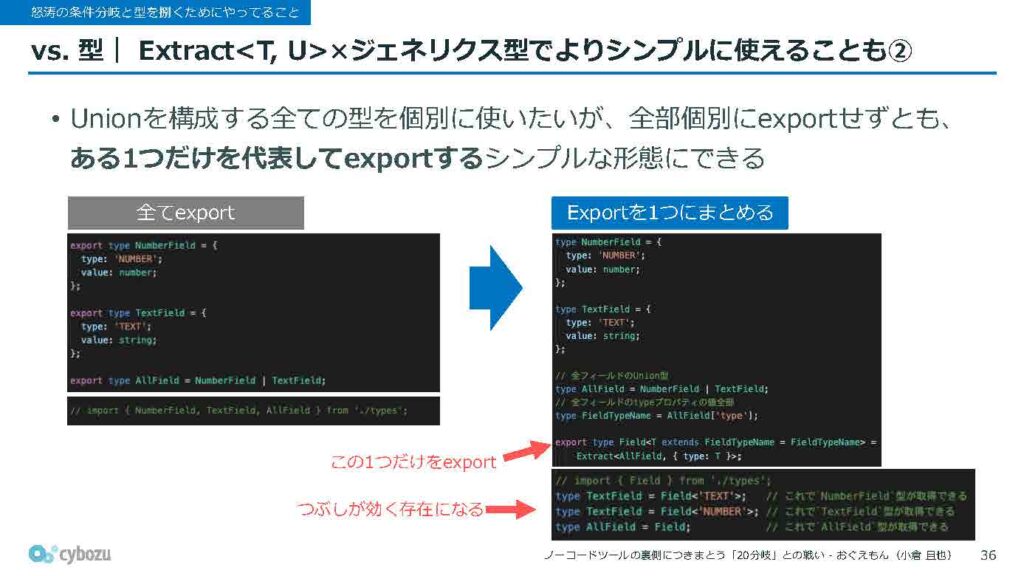
こうしておくと、今まではスライド左側の例にあるようにUnion型全体とその中の個別の型を両方使いたいときに、今まではそれぞれの型をすべて個別にエクスポートしておく必要がありましたが、スライド右側のような書き方をすることで、最終的に一つのジェネリクス型だけエクスポートしておけば済むというメリットがあります。
使い方は簡単で、スライドの右下にあるように、ジェネリクスのTに相当する部分にフィールドの名前を指定することで、そのフィールドに対応する型だけを取り出すことができます。何も指定しない場合は、すべてのUnion型が返される仕組みになっています。
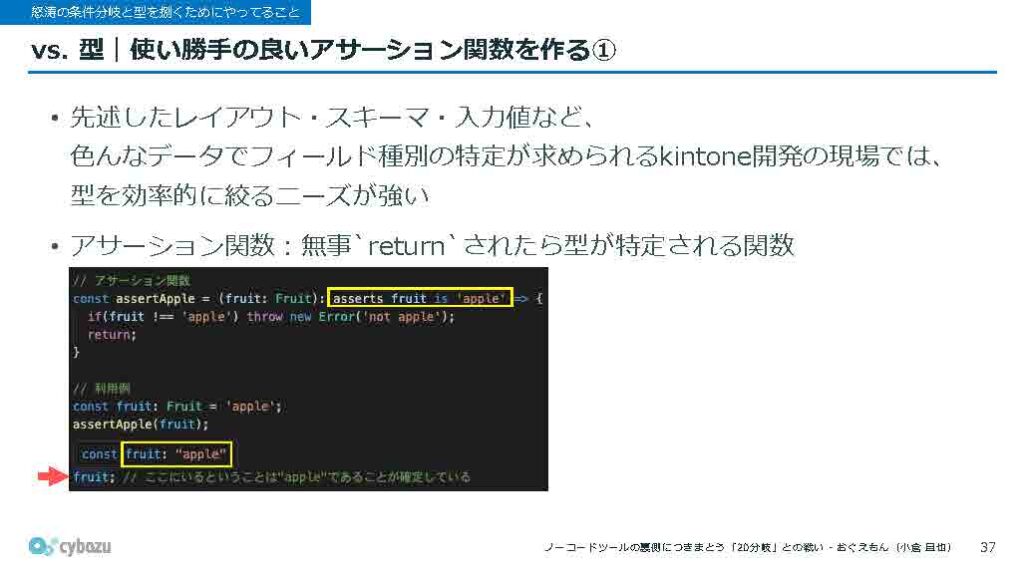
他にどんなことをやっているかというと、使い勝手のいいアサーション関数を作ったりもしています。先ほど、レイアウトとスキーマと入力値という三点セットを使って描画しているという話をしましたが、それぞれの処理の中で毎回どのフィールド種別かを判定しないと型が絞り込めないという課題があります。そこを効率化しないと、コードが全体的に汚くなってしまうという課題に対して、このアサーション関数を導入しています。
アサーション関数は知っている方も多いと思いますが、関数が無事にリターンされた場合に、特定の型であると判断できる関数です。逆にリターンされないというのは、エラーがスローされた場合に相当します。
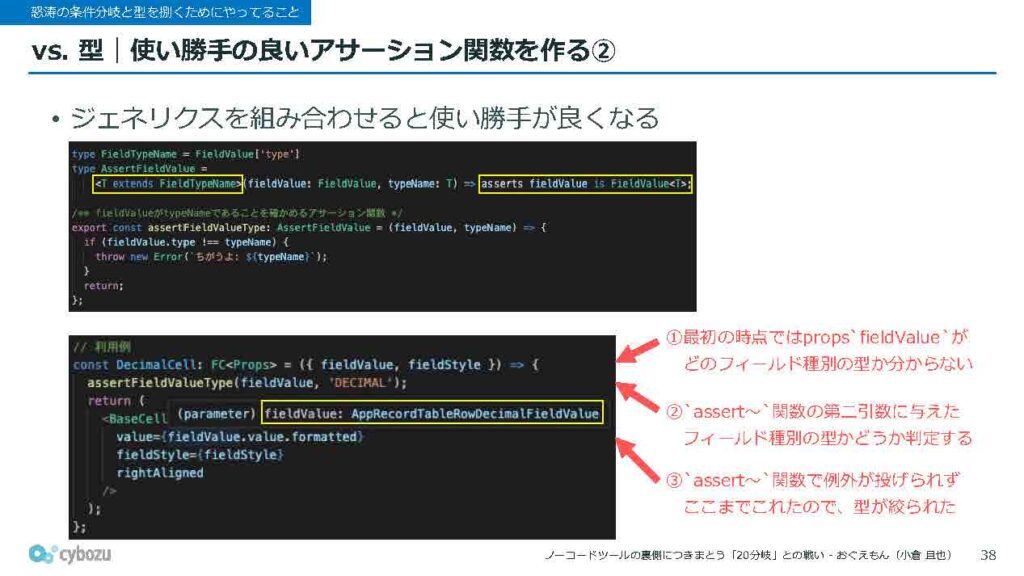
この関数もジェネリクスを組み合わせて、無数にあるフィールド種別に対応できるように作っています。詳しくはコードを見ていただけると分かりやすいのですが、画面の上の方にあるようなコードを書いておくと、下の方にあるようなassertsFieldValueTypeという関数を呼び出すだけで、第2引数に指定したフィールド種別の型だけに絞り込まれるようになります。
その結果、関数を通過したあとの処理では、すでに型が特定された状態になっているので、そのまま安心して扱うことができます。こういった細かい工夫を積み重ねることで、少しでもこのMuddyな状況を和らげられるように日々工夫しています。

ということで、最後にまとめです。

まず、ノーコードツールであるkintoneの裏側には、先ほど紹介したような大量の条件分岐や型管理が存在しています。 そのほとんどは、20〜30種類ほどあるフィールド種別ごとの処理を分けるためのものでした。こういったフィールド種別による条件分岐を少しでも扱いやすくするために、いくつかの工夫を行ってきました。 具体的には、ESLintプラグインの導入、条件分岐の実装方法の工夫、TypeScriptの型をパズルのように組み合わせて使うような型運用などを紹介してきました。
最後になりますが、いろいろ工夫を重ねているものの、まだすべての課題に通じるような銀の弾丸的な解決策は見つかっていません。
今後もチームでアイデアを探りながら、より良い方法を随時取り入れていこうと考えています。これで発表を終わります。ご清聴ありがとうございました。