
はじめまして。早稲田大学創造理工学研究科 M1の堀田南と申します。AI事業本部 協業リテールメディアディビジョン プリズムパートナーカンパニーで約2ヶ月間インターンをしていました。
本記事では、2ヶ月間のインターンシップ期間中に私が取り組んだ、AWS Bedrock AgentとStreamlit in Snowflakeを用いた「TextToSQL」システムの開発について解説します。自然言語入力からSQL文を自動生成するこのシステムは、特に広告配信セグメント作成に関わるクエリ生成を効率化する目的で開発されました。実装の概要、チューニング方法、そして今後の展望について紹介します。
目次
タスクの背景と目的
プリズムパートナーでは、ドコモ会員の属性やアプリ利用データなど豊富なデータソースを活用して、業種別・広告主別の顧客セグメントを作成しています。このセグメント作成は、SQL構文の基礎知識を持つアナリストによって行われています。
セグメント作成におけるデータベース環境には以下のような特徴があり、クエリ生成に多大な時間がかかっていました:
- テーブル数が非常に多い(20〜30テーブル)
- 似たようなカラム名が多数存在
- テーブル間の関連性把握が複雑
この結果、アナリストは本来の分析業務よりも、適切なテーブルやカラムを特定するための調査に多くの時間を費やしていました。
このプロジェクトの目的は、テーブル検索や類似クエリの参照にかかる工数を削減し、データベースに精通したアナリストの人的リソース逼迫を解消することです。
効率的なクエリ生成システムを提供することで、セグメント作成プロセスが大幅に高速化され、アナリストが同じ時間内により多くの案件を担当できるようになります。これは直接的な処理能力の向上をもたらし、より多くの広告主に対応可能となるため、事業の売上向上に直結します。
課題
上述のような複雑なデータベース構造では、ChatGPTのような汎用的なAIサービスだけでは正確なSQLを生成できません。AIが適切なテーブルやカラムを選択できず、ハルシネーション(存在しないテーブル名やカラム名の生成)を起こすリスクが高いためです。
このプロセスを自動化するため、RAG(Retrieval Augmented Generation)を用いたクエリ生成システムの構築を目指しました。RAGを導入することで、実際のテーブル定義や過去に生成したセグメントなどの固有データを参照しながらクエリを生成でき、ハルシネーションを防止できます。一方で、以下の課題に直面しました:
- 複雑なデータベース構造に対応するRAGベースのTextToSQLシステムの公開事例が少なく、ベストプラクティスが確立されていない
- 多数のテーブルと類似したカラム名が存在する環境では、参照ミスやハルシネーション(存在しないテーブル・カラムの生成)が多発
- 所望の情報の抜け落ちが頻繁に発生
- RAGに読ませるデータの整形方法や、SQL生成時のコンテキスト理解に効果的なアプローチが不明確
- チューニング手法についても、ケースバイケースで検討の余地が多く残されている
これらの課題を解決するため、独自の工夫と試行錯誤を重ねながら最適なアプローチを模索しました。本報告では、特に効果的だったRAGのチューニング手法と、複雑なデータベース環境における精度向上のための実践的な方法論を共有します。
アーキテクチャ
開発したシステムは、AWS Bedrock Agent(Knowledge Baseを参照)を利用したRAGをStreamlit in Snowflakeで実装しています。
AWS Bedrockを採用した理由は、RAGの参照先となるS3が多様なファイル形式に対応しており、手元にあるテーブル定義や過去クエリを柔軟な形式で格納できる点にあります。
類似機能を持つSnowflake Cortexも選択肢として検討しましたが、Cortexでは各テーブルごとに「セマンティックモデル」と呼ばれるメタデータを生成する必要があり、テーブル数が非常に多い環境では多くの工数が発生します。さらに、1テーブルあたりのカラム数が多いため、YAMLファイルの記述量が膨大になり、テーブルごとの補足情報を追加する作業も煩雑になります。
こうした点を踏まえ、データ準備の柔軟性が高く、迅速なPoC検証が可能であったことから、今回はAWS Bedrockのモデルを活用したRAGシステムを採用しました。
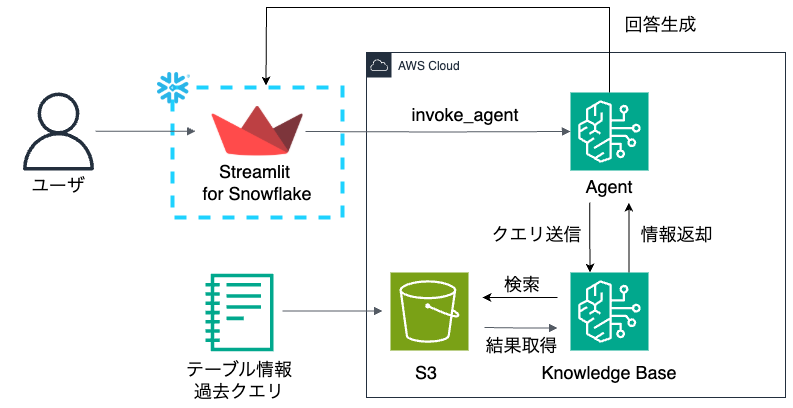
接続方法の詳細については、AWS Bedrock Agent を Streamlit in Snowflake でサーバーレスアプリ化 ー IAMロール + ExternalId によるセキュアな接続で解説しています。よりセキュアな接続にするため、AWS IAMユーザー+アクセスキーではなく、IAMロール+ExternalIdによる接続方式を採用しています。
テーブル・クエリ情報
システムに提供したデータベース情報は以下の通りです:
テーブル情報
- テーブル名
- テーブル定義(カラム名、データ型など)
- カテゴリ情報(テーブルの種類や用途)
過去クエリ情報
- 広告配信セグメント名
- 実際に使用されたSQL文
- クエリ中に利用されたテーブルリスト
ワンポイントアドバイス
テーブル
- 大量のテーブルがある場合、「このようなケースにおいて、このテーブルを参照する」といった補足情報が効果的
- LLMに与えるテーブル定義は事前に整備・補足が必要(ラベル付け、中間テーブル作成、命名規則の統一など)
- 似たカラムを識別できるような補足情報をLLMに考えさせる方法も有効
クエリ
- 業務用語とSQL文の対応関係をFew-shotの形で提供すると効果的
- ユーザーの入力に対して、LLMに「過去クエリから関連度の高いものを選択」させることで精度向上
RAGチューニング
AWS Bedrockの機能を活用し、パラメータチューニングを行いました。詳細な設定方法については、AWS Bedrock AgentやKnowledge Baseを活用したRAG構築時に効果的なパラメータチューニング を参照してください。
特に効果が高かったと感じる改善箇所は以下の通りです:
- 最大トークン数の増加
- 過去クエリのまとまりを分割せずに処理できるようになり、文脈理解が向上
- チャンク戦略の最適化(固定→セマンティックチャンク)
- 単純なトークン数による分割ではなく、意味的なまとまりや文の類似性を考慮したチャンク生成
- 検索クエリや過去クエリの文脈理解が改善
- ハイブリッド検索の導入
- 埋め込みベクトルとキーワード検索の組み合わせにより、適切なテーブル・カラムへの到達確率が向上
- クエリ分解機能の実装
- 複雑な指示を受けた場合に特に効果的で、部分ごとに適切な処理が可能に
プロンプトエンジニアリング
プロンプト設計では、以下の要素を組み込みました:
- エージェントの役割定義
- 制約条件と要件
- 推論プロセスの詳細化
- 明確な出力形式の指定
Claudeを基盤モデルとして採用し、公式ドキュメントのベストプラクティスも参考にしました。
また、SQLは構文の自由度が高いため、過去のクエリや生成されるクエリが可読性や保守性の観点で必ずしも適切なフォーマットではない課題がありました。この問題に対処するため、プロンプト内でsqlfluffのフォーマッティングルールを指定し、一貫性のある読みやすいSQL出力を促すよう工夫しています。
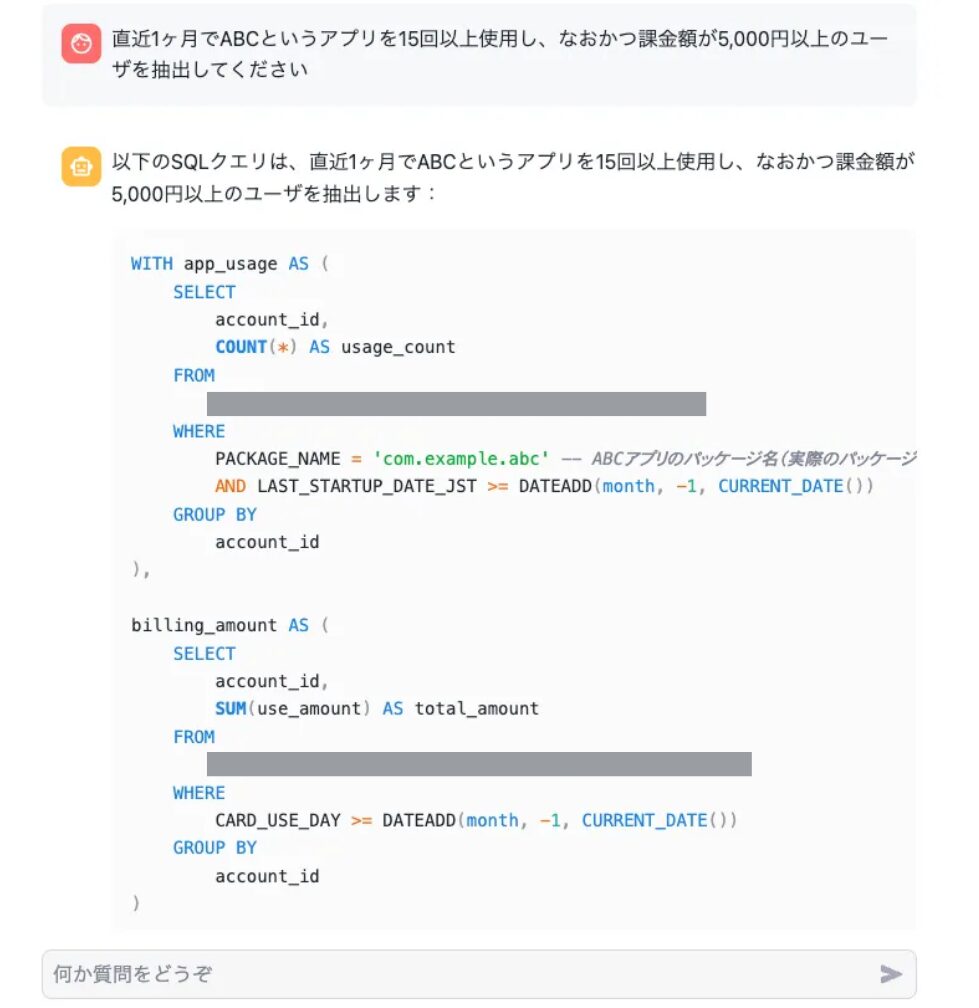
プロトタイプの出力例
実際のプロトタイプは下記の通りです。簡単な指示文章を入力すると、条件に合ったCTEを作成してくれます。また、クエリに関する説明や注意点についても言及してくれます。対話を続行することで、要件の追加や他テーブルの参照など、回答をさらにブラッシュアップすることができます。

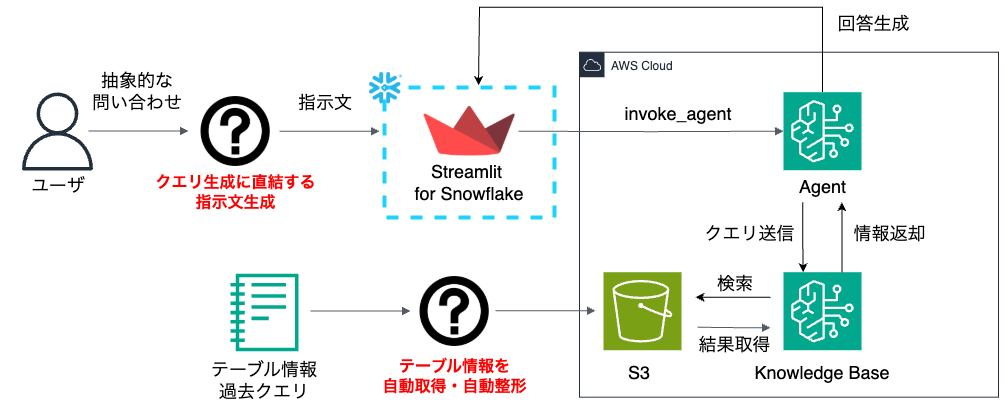
今後の課題
現在のシステムには以下の課題があります:
- ユーザースキルの前提
現在のシステムは、SQL構文の基礎知識を持たないビジネスユーザーが利用することを想定していない点です。SQLをある程度理解しているユーザーが、サブクエリを意識した指示を出すことを想定しているため、抽象的な指示をすると、適切なクエリを得られない可能性が高いです。 - テーブル定義の取得
システムに提供するテーブル定義の取得とラベル付けが手動である点です。
今後は、テーブル定義の自動取得パイプラインや、ビジネスサイドの抽象的な要望を具体タスクに落とし込むシステムの構築など、改良を進める必要があります。上記の課題を踏まえた将来的なアーキテクチャとしては、以下のような構成が考えられます:
まとめ
本記事では、TextToSQLシステムの開発において、AWS Bedrock AgentとStreamlit in Snowflakeを組み合わせたアーキテクチャの構築方法と、RAG機能のチューニングについて解説しました。今回の実装では、テーブル定義の整備やプロンプト設計、検索パラメータの最適化により、複雑なデータベース構造に対応したSQL生成を実現しています。
技術的な詳細や接続方法については、関連する別記事も参照いただければ幸いです。