
はじめまして。早稲田大学創造理工学研究科 M1の堀田南と申します。AI事業本部 協業リテールメディアディビジョン プリズムパートナーカンパニーで約2ヶ月間インターンをしていました。
本記事では、AWS Bedrock Agent(以下、エージェント)やKnowledge Base(以下、ナレッジベース)を活用したRAG(Retrieval-Augmented Generation)システム構築時に効果的なパラメータチューニング方法について解説します。適切なチューニングを施すことで、より高精度な回答を得ることが可能になります。
エージェントとナレッジベースのチューニング方法を体系的に対応づけた情報が不足していたため、AWSサポートセンターへの問い合わせ結果をもとに、実用的な知見をまとめました。これから紹介する手法を活用することで、より効果的なRAGシステムを構築していただけるはずです。
目次
目的
AWS Bedrockのエージェントやナレッジベースは、適切なパラメータチューニングなしでは期待通りの結果を得られないことがあります。チューニングを行わない場合、以下のような問題が発生する可能性があります:
- 検索精度の低下によるレレバンス問題
- 出力の一貫性が欠けることによる回答のブレ
- 所望の回答との乖離
- ハルシネーションの発生
本記事では、AWS Bedrockが提供する各種機能を適切に設定し、出力精度を向上させるための主要なチューニングのポイントについて解説します。公式ドキュメントや技術記事では一般的にretrieve_and_generate APIのチューニングに関する情報は見受けられますが、エージェントやその他のAPIについての具体的なチューニング方法に関する情報はほとんど公開されていません。本記事では、これらの情報ギャップを埋め、実用的なチューニング手法を提供します。
備考
ナレッジベースにおけるチューニング
Bedrock コンソール上の設定
AWS Bedrock管理コンソールからナレッジベースに関する様々なパラメータを設定できます:
- ナレッジベースのページにアクセスし、対象のナレッジベースを選択します
- 設定アイコンをクリックすると詳細設定オプションが表示されます
- モデル選択後、さらに詳細なパラメータを設定できます
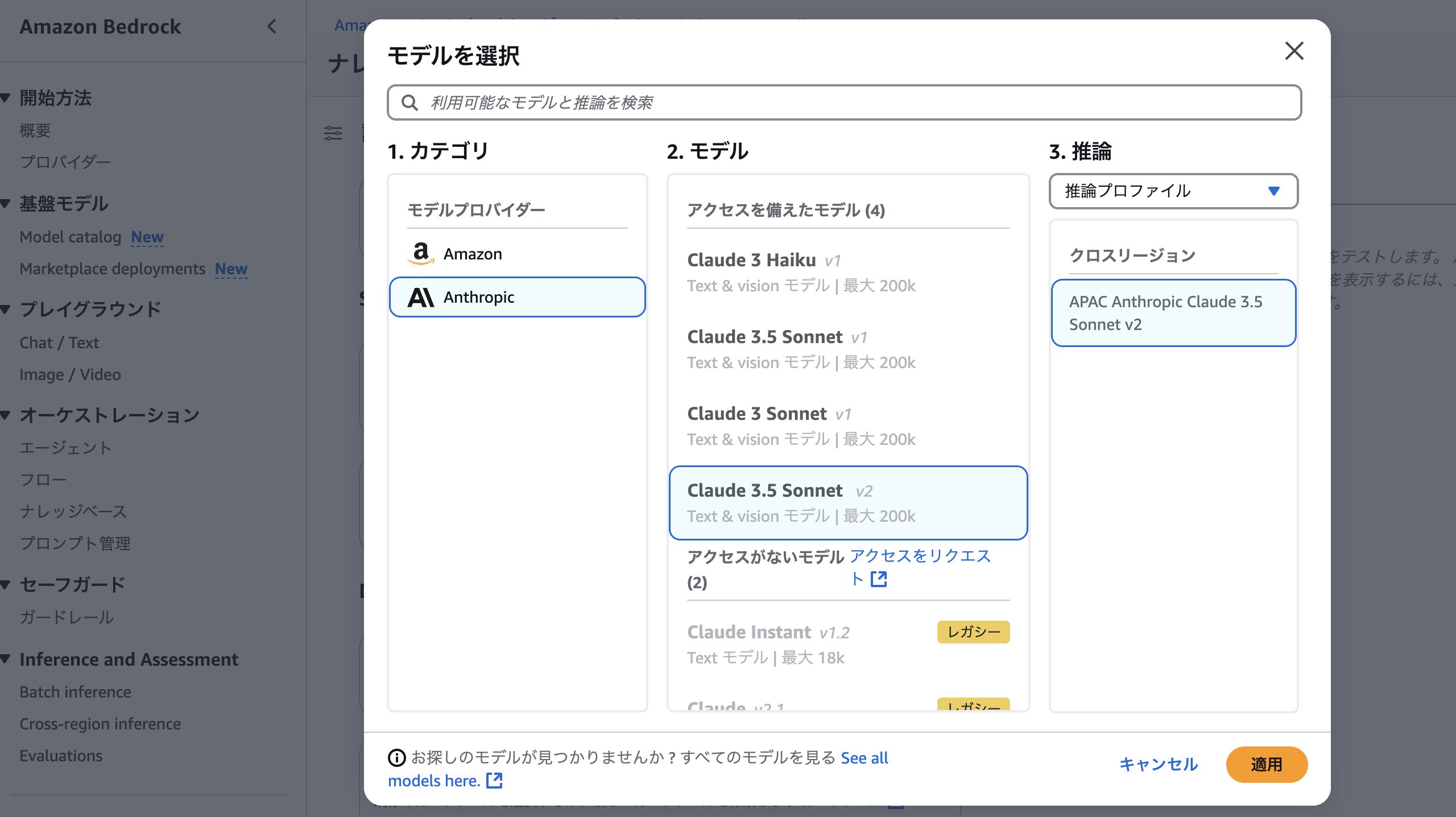
重要なパラメータ
ナレッジベース設定で調整可能な主要なパラメータは以下のカテゴリに分類され、それぞれ異なる効果が期待できます:
| 設定カテゴリ | パラメータ | 機能 | 解答精度への寄与 |
| Source(ソース) | 検索結果の最大数 | ベクトルストアから返される検索結果の数を指定 | 多すぎるとノイズ、少なすぎると情報不足になるため、適量を設定することで関連情報だけを抽出できる |
| 検索タイプ | 「セマンティック検索」または「ハイブリッド検索(セマンティック+キーワード)」を選択 | 意味ベース(セマンティック)だけでは拾えないキーワード一致も含めることで、曖昧・間接的な質問にも対応しやすくなる | |
| Data manipulation(データ操作) | Reranking | 検索されたソース・チャンクを関連性で再スコア・並べ替えする | 最も関連性が高い情報を優先して使えるようになり、不要な情報による誤答を防げる |
| Query modification | 複雑なクエリを小さく分割する | クエリの意味が明確になり、検索ヒット率と正確性が高まる | |
| Generation(生成) | ナレッジベースプロンプトのテンプレート | レスポンス生成時に使用されるプロンプト | 一貫した指示文により、安定した品質の回答を得やすくなる |
| 推論パラメータ | モデルの温度・トークン数などを調整する | 回答の一貫性や柔軟性をコントロールし、望ましい出力を得やすくする | |
| Orchestration(オーケストレーション) | Orchestration prompt | 全体の処理フローを指示するプロンプトを設定する | 適切な順序と流れで処理を行い、不要な分岐や誤解を減らす |
[参考] https://docs.aws.amazon.com/bedrock/latest/userguide/kb-test-config.html
API 呼び出し時の設定
retrieve_and_generate APIを使用する場合、以下のようにパラメータを設定できます:
KNOWLEDGE_BASE_ID = '<10桁のナレッジベースID>' #
FOUNDATION_MODEL_NAME = '<基盤モデルのARN>' # Claude 3.5 Sonnet v2 の場合、'apac.anthropic.claude-3-5-sonnet-20241022-v2:0'
RERANK_MODEL = '<RerankモデルのARN>' # Rerank 1.0 の場合、'arn:aws:bedrock:ap-northeast-1::foundation-model/amazon.rerank-v1:0'
REGION_NAME = '<リージョン名>' # 東京リージョンの場合、'ap-northeast-1'
response = bedrock_agent_runtime.retrieve_and_generate(
"input": {"text": '{input_text}'},
"retrieveAndGenerateConfiguration": {
"type": "KNOWLEDGE_BASE",
"knowledgeBaseConfiguration": {
"knowledgeBaseId": KNOWLEDGE_BASE_ID,
"modelArn": FOUNDATION_MODEL_NAME,
"orchestrationConfiguration": {
"queryTransformationConfiguration": {
"type": "QUERY_DECOMPOSITION" # Query modification
},
"promptTemplate": {
"textPromptTemplate": '{orchestration_prompt}' # Orchestration prompt
}
},
"retrievalConfiguration": {
"vectorSearchConfiguration": {
"overrideSearchType": "HYBRID", # 検索タイプ
"numberOfResults": 10, # 検索結果の最大数
"rerankingConfiguration": {
"type": "BEDROCK_RERANKING_MODEL",
"bedrockRerankingConfiguration": {
"modelConfiguration": {
"modelArn": RERANK_MODEL # Rerank
},
"numberOfRerankedResults": 10 # Rerank 対象数
}
}
}
},
"generationConfiguration": {
"inferenceConfig": {
"textInferenceConfig": {
"maxTokens": {max_tokens}, # 推論パラメータ
"temperature": {temperature}, # 推論パラメータ
"topP": {top_p} # 推論パラメータ
}
},
"promptTemplate": {
"textPromptTemplate": '{knowledgebase_prompt}' # ナレッジベースプロンプトのテンプレート
}
}
}
}
)エージェントにおけるチューニング
Bedrock エージェントのパラメータチューニングは、Bedrock コンソール上の設定とAPI呼び出し時の設定に分かれます。
Bedrock コンソール上の設定
下記の手順で設定します:
- エージェントを選択し「エージェントビルダーで編集」
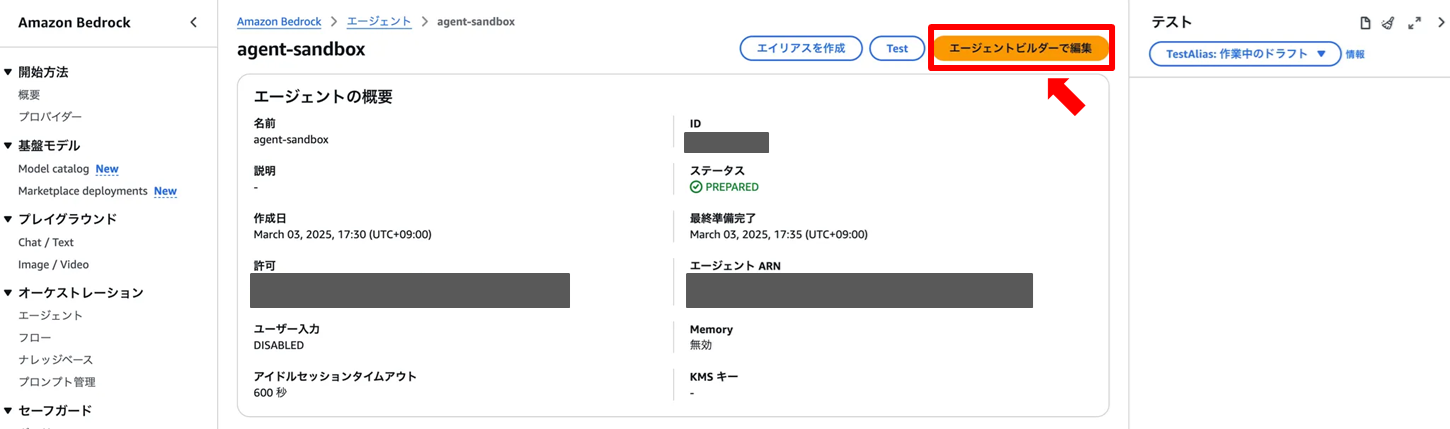
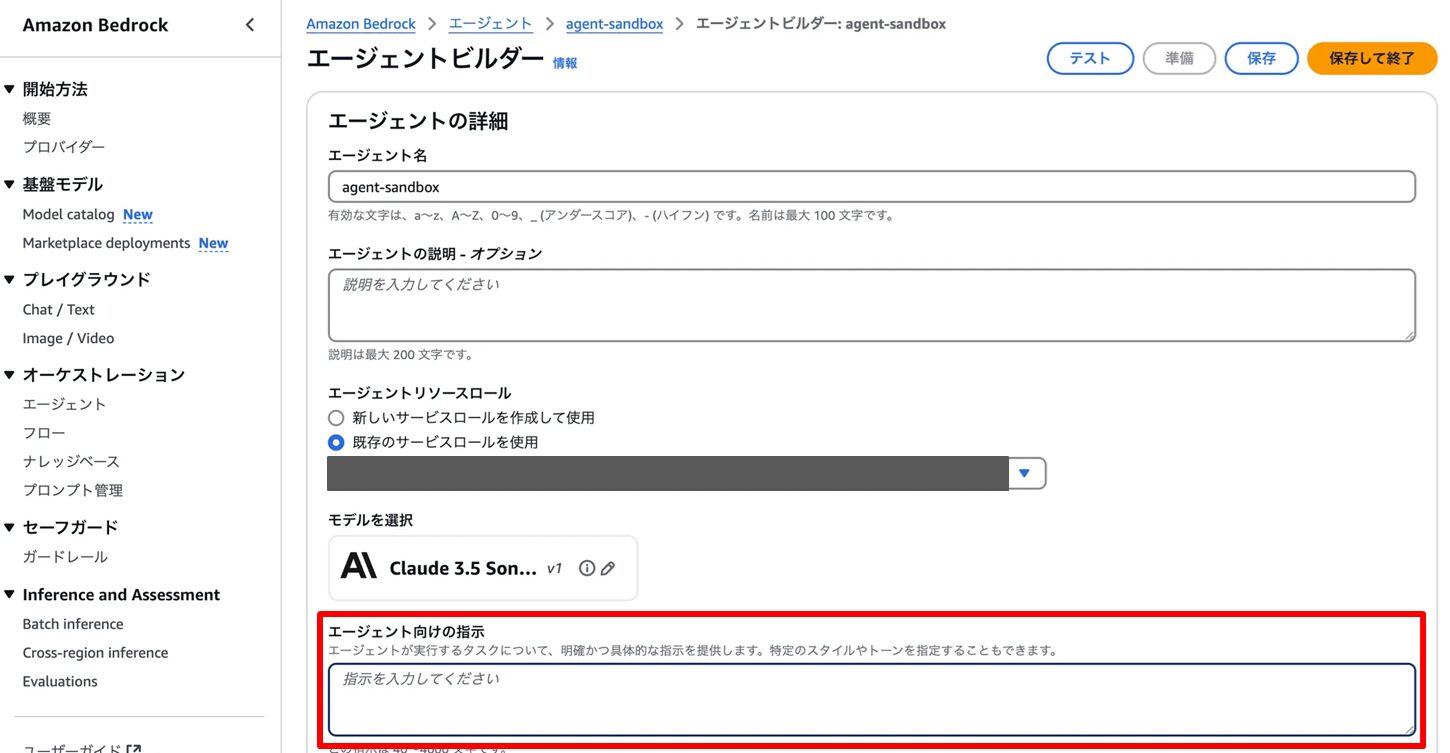
- 「エージェント向けの指示」または「Orchestration strategy」から設定
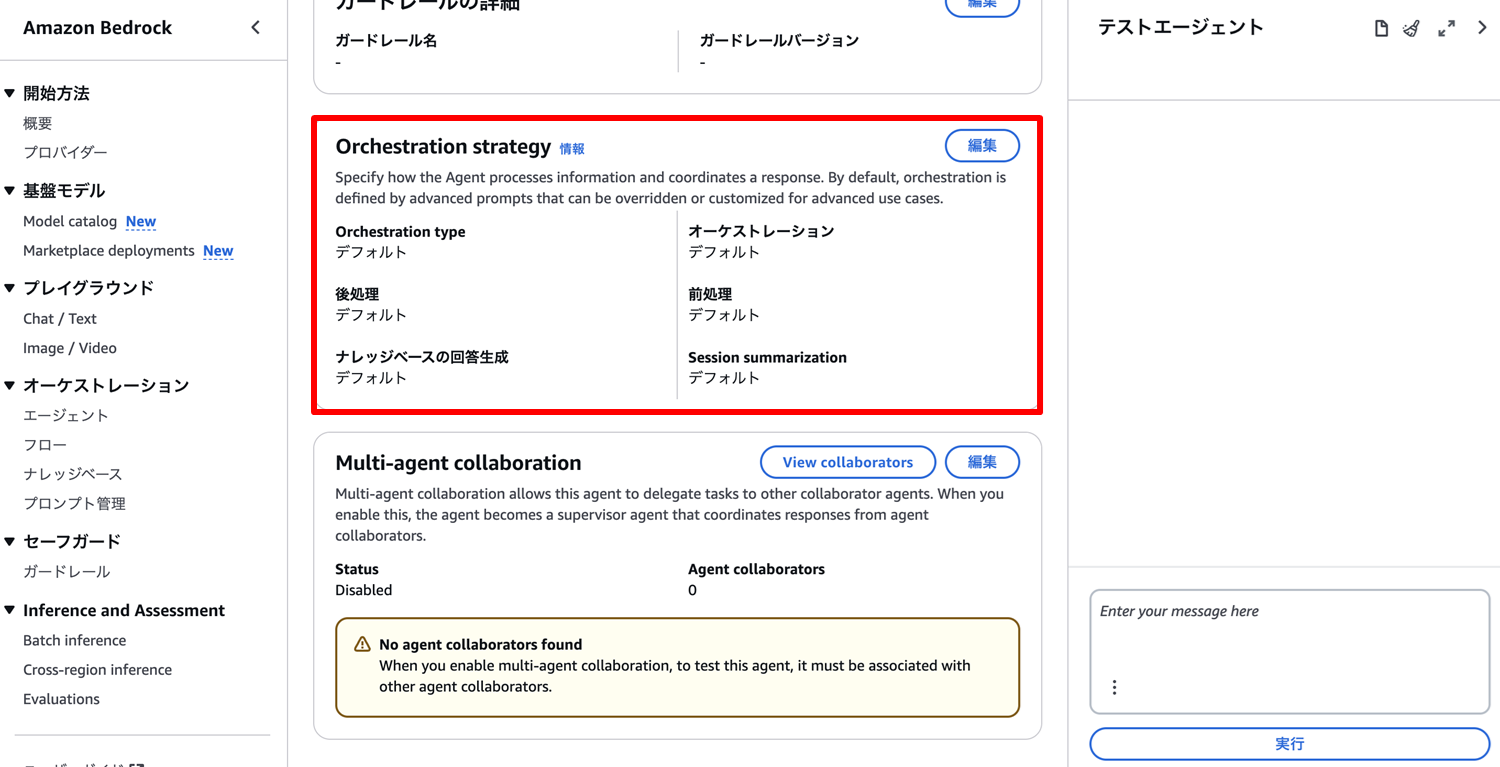
主要な設定項目:
- クエリ分解: エージェント向けの指示に「クエリに複数の質問が含まれる場合にクエリを分解して検索する」と記述することで実現
- 推論パラメータ: エージェントのオーケストレーション戦略で、オーケストレーションテンプレートの編集を有効化することで設定可能
- プロンプトテンプレート: エージェント向けの指示またはプロンプトテンプレートのカスタマイズで設定
API呼び出し時の設定
invoke_agent API呼び出し時に、sessionStateを通じてベクトル検索の設定(検索結果の最大数、検索タイプ、Rerank)を指定できます:
response = client.invoke_agent(
# 略
sessionState={
# 略
'knowledgeBaseConfigurations': [
{
'knowledgeBaseId': KNOWLEDGE_BASE_ID,
'retrievalConfiguration': {
'vectorSearchConfiguration': {
# 略
'numberOfResults': 10, # 検索結果の最大数
'overrideSearchType': 'HYBRID', # 検索タイプ
'rerankingConfiguration': {
'bedrockRerankingConfiguration': {
# 略
'modelConfiguration': {
# 略
'modelArn': RERANK_MODEL # Rerank
},
},
'type': 'BEDROCK_RERANKING_MODEL'
}
}
}
},
],
# 略
}
)
まとめ
AWS Bedrockのエージェントとナレッジベースのパフォーマンスを最適化するためのパラメータチューニングについて解説しました。適切なチューニングを行わないと、検索精度の低下や回答のブレ、ハルシネーションなどの問題が発生します。
主要ポイント:
- ナレッジベースのチューニング:
- Source設定:検索結果数の調整と検索タイプ(セマンティック/ハイブリッド)の選択
- Data manipulation設定:Rerankingとクエリ分解の活用
- Generation設定:プロンプトテンプレートと推論パラメータの調整
- Orchestration設定:全体のフロー制御に関するプロンプト設定
- エージェントのチューニング:
- エージェント向け指示による機能拡張:クエリ分解、プロンプトテンプレートなどの設定
- API呼び出し時のsessionStateパラメータ:検索結果数の調整と検索タイプの選択、Reranking
これらのチューニングポイントを適切に調整することで、RAGシステムの品質を大幅に向上させることができます。特に最大トークン数の増加、セマンティックチャンクの採用、ハイブリッド検索の導入、クエリ分解機能の実装が効果的でした。
また、本記事でご紹介したパラメータチューニングの適用例(TextToSQL)や、AWS Bedrock Agentを活用したサーバーレスアプリ構築にご興味のある方は、ぜひ以下の関連記事もご覧ください。