
はじめに
こんにちは!ABEMA の広告配信システムの開発チームのバックエンドエンジニアの戸田朋花です。
本記事では、CRDT(Conflict-free Replicated Data Type)の基本概念を学びながら、その一種である GCounter を Go 言語で実装してみます。
分散システムにおいて「書き込みのスケール」や、「結果整合性の担保」といった課題に対して、CRDT がどのような解決策を提供してくれるのかを、実装とベンチマークを通じて探っていきます。
分散システムにおけるデータ管理の課題
強い一貫性のあるデータベースは、Leader/Follower 構成のアーキテクチャが代表的です。
このアーキテクチャでは、書き込みは単一の Leader ノードのみに許可されており、Follower ノードは基本的に Read 専用となります。
読み込みのスケーラビリティは Follower を増やすことで対応できますが、書き込みについては Leader ノードに集中してしまうため、スケールアウトが困難です。
また、Leader ノードに障害が発生した場合には、Follower の中から新たな Leader を選出し昇格させることで復旧が可能ですが、この切り替えが完了するまでの間、書き込み処理が一時的に停止してしまいます。
このように、Leader/Follower 構成ではスケーラビリティや可用性に限界があります。
分散システムにおいては、これらの課題を解決する手段の一つとして一貫性を一時的に犠牲にするアプローチが取られます。代表的なものが「結果整合性(Eventual Consistency)」という考え方です。
今回は、この結果整合性を実現するための技術要素として CRDT をご紹介します。
CRDT (Conflict-free Replicated Data Type) とは
CRDT とは、その名の通り「コンフリクトの生じないデータ型」です。
複数のレプリカで同じデータに対して独立に更新が行われたとしても、それらの変更を自動的にうまくまとめて、矛盾のない状態に保つことができます。
CRDT は、Strong Eventual Consistency を提供します。通常の Eventual Consistency は、更新が同期されれば、「いつか」結果が一致するということしか保証しません。Strong Eventual Consistency はさらに強力で、すべての更新が同期されさえすれば、「常に必ず」全レプリカが同じ状態に収束することを保証します。
CRDT には大きく分けて 2 つのアプローチが存在します。
State-based CRDT / CvRDT: Convergent Replicated Data Type
State-based CRDT では、各レプリカがローカルに状態を更新し、その状態を定期的に他のレプリカに送信します。そして、受け取った側はその状態をローカルの状態とマージします。
この操作により Strong Eventual Consistency が保証されるには、マージ対象となるデータ型が以下の 3 つの性質を持つ必要があります。
- 冪等性:同じマージを何度繰り返しても結果が変わらないこと
- 結合性:複数のマージ操作を行う際に、「どのペアを先にマージするか」を変えても、結果が変わらないこと
- 例:A を B にマージしてその結果に C をマージしたものと、C を A にマージしてその結果に B をマージしたものが等しい
- 可換性:マージする順序が入れ替わっても結果が変わらないこと
- 例:A を B にマージするのと、B を A にマージするのが同じ結果になる
Operation-based CRDT / CmRDT: Commutative Replicated Data Type
Operation-based CRDT では、状態ではなく「操作」そのものを各レプリカ間で伝播させます。各レプリカは受け取った操作を順次適用することで状態を更新します。
このモデルで Strong Eventual Consistency を達成するためには、各操作が可換(Commutative)である必要があります。
つまり、操作の適用順が異なっても最終的な状態が同一であることが求められます。
オンラインでリアルタイム共同編集ができるアプリケーションの中には、この Operation-based CRDT が応用されているものがあります。
本記事では、State-based CRDT を活用した GCounter を実装します。
GCounter (Grow-only Counter) とは
GCounter は、加算のみ可能なカウンターです。これは最も基本的な CRDT の一種であり、分散環境でのカウントの整合性を確保するために使えます。
GCounter は複数のノード上にそれぞれ独立したカウンターを保持しており、各ノードは自分のカウンターに対してのみ加算操作を行います。他のノードのカウンターには書き込みを行いません。
ノード間で定期的にレプリカを送信しあい、各ノードで他のノードのカウンターのレプリカを保持します。
レプリカを受信する度にノードで保持していたレプリカと、新しく来たレプリカをマージします。
GCounter は単調増加しかしない性質を持つので、マージの際には各レプリカごとに保持している値の最大値を取ることで整合性がとれます。
GCounter に対する Increment、Merge 操作は以下のシーケンス図のように表されます。
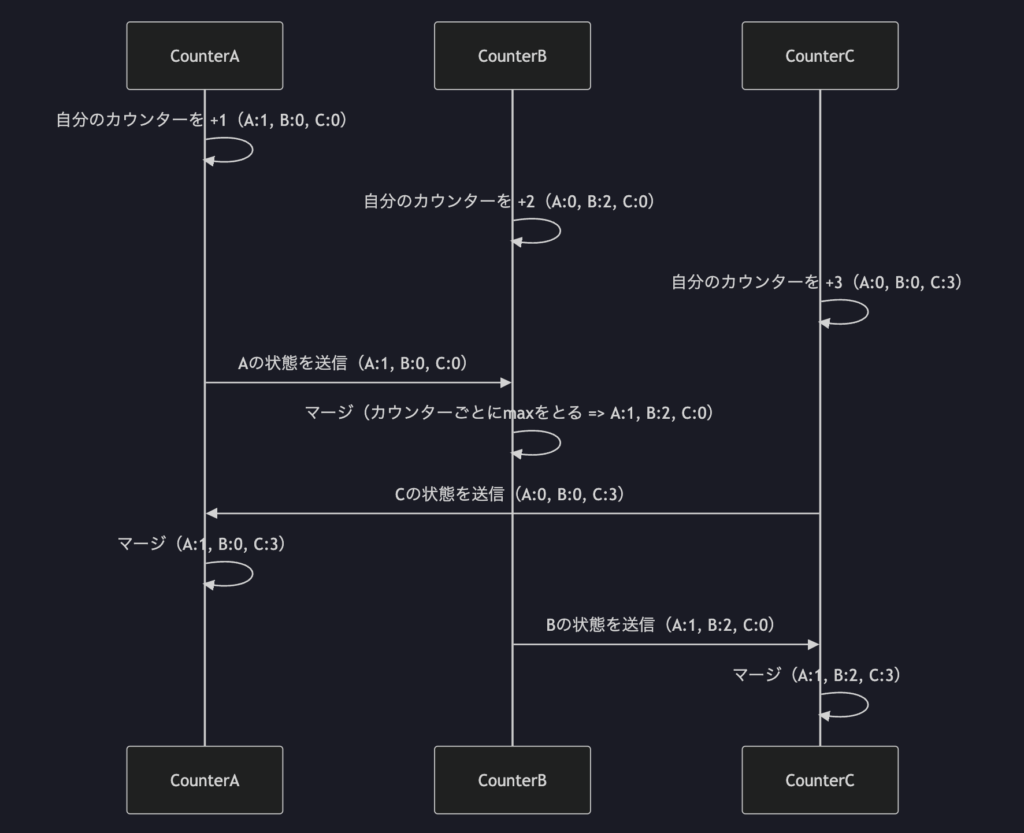
GCounter サンプル実装
GCounter のサンプルを Go 言語を用いて実装しました。
それぞれのカウンターは独立した goroutine で動作することを想定しています。
Increment 操作は、自分の持っているカウンターのみに行い、レプリカに対しては行いません。
カウンター同士は、チャネルを介して定期的にレプリカをやり取りし、非同期的に Merge 処理を行います。 Merge 処理では、他のノードから受信したレプリカ情報と、自分が保持しているレプリカ情報とを突き合わせます。各レプリカ ID ごとに 自分が保持している値と受け取った値を比較し、より大きい方を選ぶことでマージを行います。この「最大値をとる」操作は「冪等性」「結合性」「可換性」を満たしているため、整合性のあるマージが実現できます。
Pause() メソッドを用意することで、一時的に通信を停止できるようにもしました。
これにより、ネットワークの分断やレプリカの遅延といった、分散環境における不安定さもシミュレーションします。
type GCounter struct {
_ [64]byte
count atomic.Int64
_ [56]byte
id int32
mu sync.RWMutex
replicas map[int32]*atomic.Int64
inbox chan map[int32]int64
outboxes []chan map[int32]int64
pause bool
}
func (g *GCounter) Run(t *time.Ticker, stop <-chan struct{}) {
for {
select {
case <-t.C:
if g.pause {
continue
}
go g.SendReplica()
case msg := <-g.inbox:
if g.pause {
continue
}
g.Merge(msg)
case <-stop:
return
}
}
}
func (g *GCounter) Increment() {
g.count.Add(1)
}
func (g *GCounter) Load() int64 {
return g.count.Load()
}
func (g *GCounter) Merge(remote map[int32]int64) {
g.mu.Lock()
defer g.mu.Unlock()
for id, remoteVal := range remote {
if id == g.id {
continue
}
local, ok := g.replicas[id]
if !ok {
local = atomic.NewInt64(0)
g.replicas[id] = local
}
for {
lv := local.Load()
if remoteVal <= lv || local.CompareAndSwap(lv, remoteVal) {
break
}
}
}
}
func (g *GCounter) Value() int64 {
value := g.Snapshot()
sum := int64(0)
for _, v := range value {
sum += v
}
return sum
}
func (g *GCounter) SendReplica() {
snapshot := g.Snapshot()
for _, outbox := range g.outboxes {
outbox <- snapshot
}
}
func (g *GCounter) Snapshot() map[int32]int64 {
g.mu.RLock()
defer g.mu.RUnlock()
snapshot := make(map[int32]int64, len(g.replicas)+1)
snapshot[g.id] = g.count.Load()
for id, ptr := range g.replicas {
snapshot[id] = ptr.Load()
}
return snapshot
}
func (g *GCounter) Pause() {
g.pause = true
}
func (g *GCounter) Resume() {
g.pause = false
}
GCounter の性能評価
GCounter が複数のノードに分散してカウントし、スループットが向上するのを確認するベンチマークテストを行いました。
シンプルなカウンター
比較のため、以下のように単一のノードでカウントを行うシンプルなカウンターの実装も用意しました。
type Counter struct {
count atomic.Int64
}
func (c *Counter) Increment() {
c.count.Add(1)
}
ベンチマークテスト
以下のような条件でベンチマークテストを行いました。
GCounter については、50ms 間隔でレプリカを送信するように設定しており、カウンターの数は 1, 2, 4, 8, 16, 32, 64 に変更して実験を行いました。
func BenchmarkCounterParallel(b *testing.B) {
c := NewGCounter()
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
c.Increment()
}
})
}
func BenchmarkGCounterParallel(b *testing.B) {
testCase := []struct {
name string
shards int
}{
{"1", 1},
{"2", 2},
{"4", 4},
{"8", 8},
{"16", 16},
{"32", 32},
{"64", 64},
}
for _, tc := range testCase {
b.Run(tc.name, func(b *testing.B) {
ids := make([]int32, tc.shards)
for i := 0; i < tc.shards; i++ {
ids[i] = int32(i)
}
counters := NewGCounters(ids)
for _, c := range counters {
stop := make(chan struct{})
go c.Run(time.NewTicker(50*time.Millisecond), stop)
defer func() {
close(stop)
}()
}
b.ResetTimer()
b.RunParallel(func(pb *testing.PB) {
id := rand.Intn(tc.shards)
for pb.Next() {
counters[int32(id)].Increment()
id++
if id == tc.shards {
id = 0
}
}
})
b.StopTimer()
})
}
}
結果
実際にベンチマークテストを実行したところ、以下のような結果になりました。
ベンチマークテストは、Apple M4 Max 16 コアのマシンで行いました。
各カウンターに対して並列にインクリメントを行い、その 1 回あたりの所要時間を ns/op として計測しています。
また、ns/op から逆算し、1 秒間に実行可能なインクリメント回数を op/s として算出しました。
| Type | ns/op | op/s |
|---|---|---|
| Simple Counter | 57.82 | 17,295,053 |
| GCounter / 1 node | 58.95 | 16,963,528 |
| GCounter / 2 nodes | 36.29 | 27,555,800 |
| GCounter / 4 nodes | 22.66 | 44,130,626 |
| GCounter / 8 nodes | 15.06 | 66,401,062 |
| GCounter / 16 nodes | 8.778 | 113,921,166 |
| GCounter / 32 nodes | 6.918 | 144,550,448 |
| GCounter / 64 nodes | 6.908 | 144,759,698 |
単一ノード内でロックを取って処理する一般的なカウンターと比べて、いくつかのノードを持つ GCounter の方が高速です。
また、GCounter の中でもノード数を増やすほどインクリメントの処理が高速になっているのがわかります。
同様に、スループットも GCounter のノードを増やすにつれて増加しています。
この結果から GCounter のようにノードごとに独立して処理できる構造を持つカウンターは、ノード数を増やすことで書き込み処理を並列化でき、スループットが向上することが確認できました。
ネットワークパーティションのシミュレーション
GCounter の結果整合性を確認するために、一部ノードが通信不能になる状況(ネットワークパーティション)をシミュレーションしてみました。
今回は 3 つのカウンター(CounterA, CounterB, CounterC)を起動し、そのうちの CounterA が一時的に他ノードとの通信ができない状況を想定します。
このような障害シナリオは現実の分散システムでも発生しえます。
たとえば、データセンタ内のネットワークの障害によって特定のノードが孤立したり、通信遅延の増加により一時的にノード間のデータのやりとりに時間がかかったりする場合です。
ここではそのような状況においても GCounter がどのように動作し、最終的に整合した状態に収束するのかを観察します。
コード全体は以下です。順を追って解説します。
func main() {
// 3つのカウンターを起動
counters := NewGCounters([]int32{1, 2, 3})
for _, c := range counters {
stop := make(chan struct{})
// 1秒ごとにレプリカを送信
go c.Run(time.NewTicker(1*time.Second), stop)
defer func() {
close(stop)
}()
}
counterA := counters[1]
counterB := counters[2]
counterC := counters[3]
/////////////////////////////////////////
// 1. 通常時の動作
/////////////////////////////////////////
counterA.Increment()
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 1, counterB: 0, counterC: 0
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 1, counterB: 1, counterC: 1
/////////////////////////////////////////
// 2. ネットワーク障害
/////////////////////////////////////////
// CounterAが孤立
counterA.Pause()
counterA.Increment()
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 1, counterC: 1
counterB.Increment()
counterB.Increment()
counterB.Increment()
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 4, counterC: 1
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 4, counterC: 4
// CounterAが復帰
counterA.Resume()
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 4, counterC: 4
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 5, counterB: 5, counterC: 5
}
通常時の動作
まずは通常の状態での動作を確認します。
CounterA に対して 1 回だけ Increment() を実行すると、その直後は他のカウンターにはまだ値が共有されていません。
一定時間が経過すると状態が他ノードに共有され、すべてのカウンターの Value() が「1」に収束します。
counterA.Increment()
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 1, counterB: 0, counterC: 0
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 1, counterB: 1, counterC: 1
ネットワーク障害時の動作
次に、CounterA を Pause() し、他のノードとの通信を遮断します。
この間も CounterA はローカルで Increment() を実行できますが、状態は他ノードへ伝播されないため、CounterB や CounterC の値は更新されません。
// CounterAが孤立
counterA.Pause()
counterA.Increment()
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 1, counterC: 1
この状態で CounterB に対して Increment() を 3 回実行すると、直後は CounterB の値だけが増加します。
その後、CounterC にも状態が同期され、両者の値が「4」に揃います。
一方、CounterA は孤立しているため、依然として「2」のままです。
counterB.Increment()
counterB.Increment()
counterB.Increment()
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 4, counterC: 1
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 4, counterC: 4
ここで CounterA の通信を再開します。
復帰直後の時点では、CounterA は CounterB の変更(3 回のインクリメント)をまだ受け取っておらず、逆に CounterB と CounterC は、CounterA が孤立中に行ったインクリメントを反映していません。そのため、各ノードの値は部分的に古いままとなっています。
その後、レプリカ情報の交換が再開されることで互いの変更が順次マージされていき、最終的にはすべてのカウンターが「5」という正しい合計値に収束します。
// CounterAが復帰
counterA.Resume()
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 2, counterB: 4, counterC: 4
time.Sleep(1500 * time.Millisecond)
fmt.Printf("counterA: %d, counterB: %d, counterC: %d\n", counterA.Value(), counterB.Value(), counterC.Value())
// 出力: counterA: 5, counterB: 5, counterC: 5
結果
GCounter はノードが一時的に通信できない状況に陥っても、CRDT の強い結果整合性により最終的には本来の状態に収束することが実験からも確認できました。
このことから、例えばクラウドの AZ 間でネットワークの一時的な分断が起きた場合でも、各 AZ 内のノードは処理を継続でき、復旧後にマージするだけで整合性が取れることがわかります。
終わりに
本記事では、CRDT の一種である GCounter を Go 言語で実装し、分散環境における書き込みのスケーラビリティや結果整合性の実現方法を実験から確認しました。
GCounter のような CRDT は、各ノードがローカルで処理を進めながら後で非同期に整合性を保てるため、ネットワーク分断やレプリカ遅延といった分散特有の問題に強く、スループットと可用性に優れています。
今回は加算のみを行う GCounter を実装しましたが、減算もサポートする PN-Counter というものもあります。興味がある人はぜひ調べてみてください。
少しでも CRDT の考え方や実装のヒントが伝われば幸いです。