
はじめに
アメーバブログでバックエンドエンジニアをしている須永です。
今回はアメーバブログで利用しているアクセス解析基盤を移行した経験をお話します。
対象読者は下記のようなキーワードに興味がある方です。
大規模開発,並列処理,DynamoDB,クロスアカウント
目次
移行の背景
アメーバブログには管理画面があります。そして、この中には自分のブログを見た人の情報を確認できるアクセス解析という機能があります。
具体的には自分のブログを何人見たのか、どこから流入があったか、年齢や性別などを確認できます。
アクセス解析には、リアルタイム集計と日次集計があるのですが、今回は日次集計を移行しました。
アクセス解析では毎朝8時までに前日のデータを解析し、時間、日、週単位などで集計して閲覧できることが要件となっていました。
移行前はおおまかに下記のような流れでEMRを利用してアクセス解析を実現していました。
S3(旧AWSアカウント、アクセスデータが保存されています)
→ EMR(旧AWSアカウント)
→ DynamoDB(旧AWSアカウント)
→ Elastic Beanstalk(旧AWSアカウント)
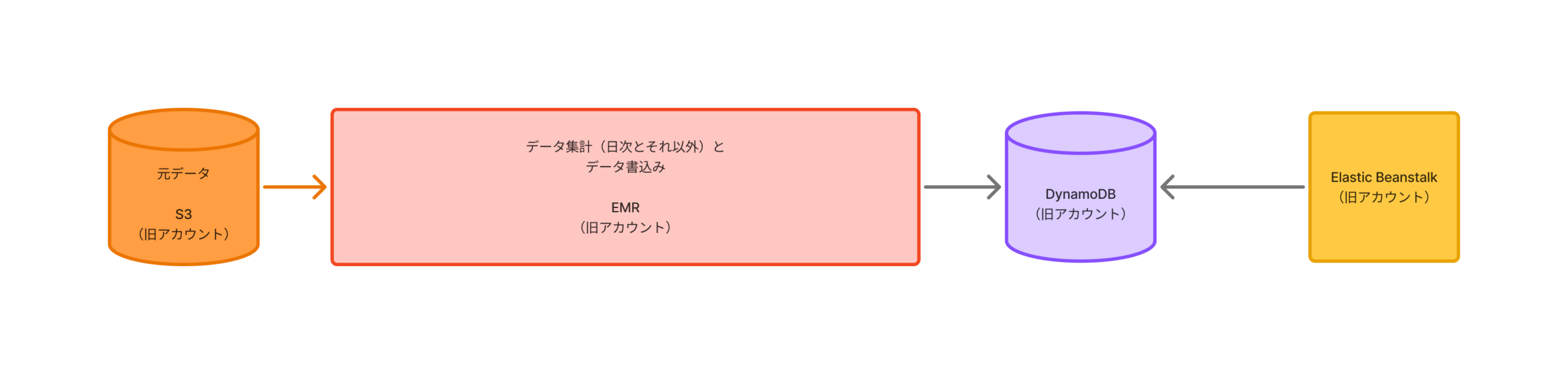
EMRでも要件を満たせていたのですが、移行したのには下記のような理由があります。
- 時々動作が不安定となっていたが、古いシステムだったためメンテナンスが難しかったこと
- Data Science Center(DSC)が管理してくださっているアクセス情報がBigQueryにも存在し、開発チームで管理しているS3と二重管理となっており、BigQueryに統合しようという動きがあったこと
- 現在AWSアカウントを複数利用しているが、管理が煩雑になってきたこともあり、アクセス解析で利用しているAWSアカウントを廃止して別のAWSアカウントへと統合しようという動きがあったこと
- AWSの方に以前相談した際にEMRだと要件に対してオーバーであると言っていただいたこと
移行後は下記のような流れとなっています。
BigQuery(アクセスデータが保存されています)
→ DSC管理のWorkflow
→ EKSのCronJob (新AWSアカウント)
→ DynamoDB(新AWSアカウント)
→ Elastic Beanstalk(旧AWSアカウント)
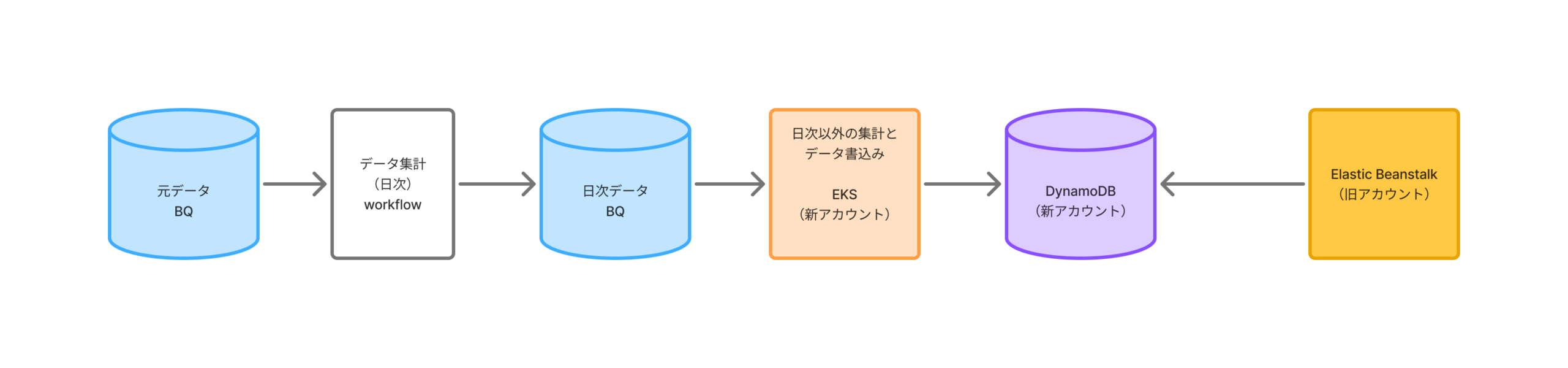
簡単に流れを説明すると、
1日に1回BigQueyに保存されたアクセスデータがDSC管理のWorkflowによって集計され日次データとしてBigQueryのテーブルに書き込まれます。
その後、EKSのCronJobによって週や月単位のデータが作成され、それらがDynamoDBに書き込まれます。そして、Elastic Beanstalkによって取得され実際に画面に反映されます。
移行前と移行後を比べると下記のようになります。
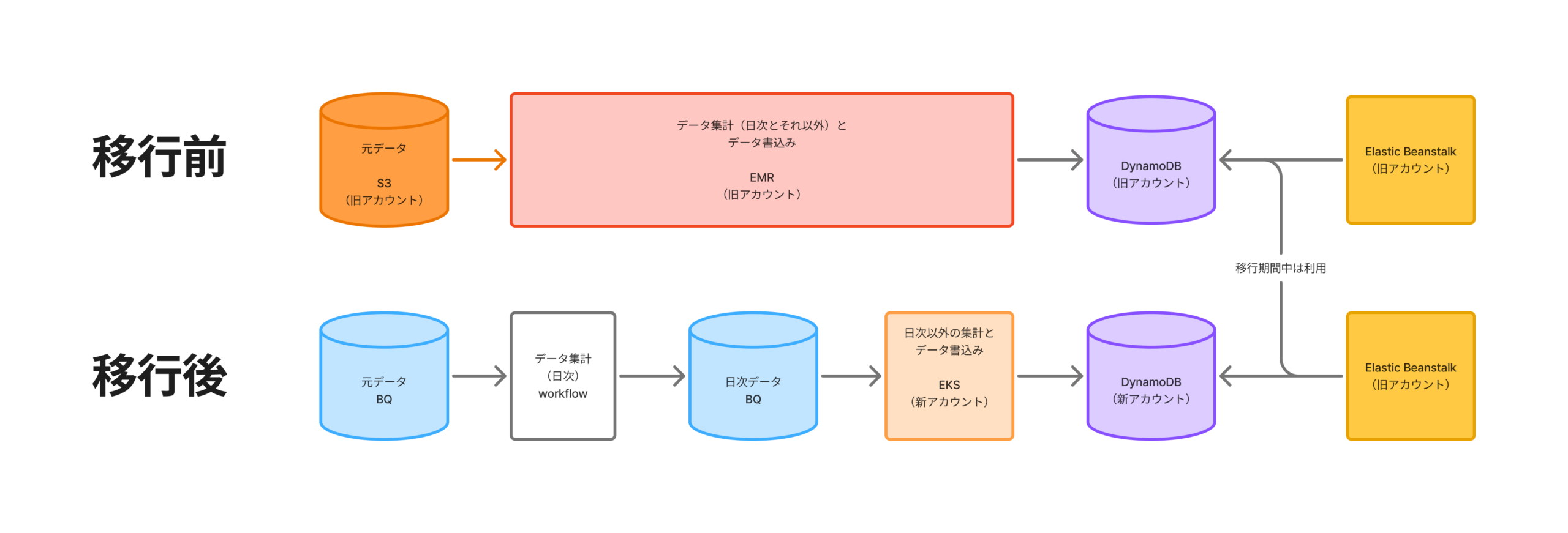
細かいお話は色々とあるのですが、今回は大まかに下記の3点のお話をしていきます。
- EMRからWorkflowへの移行
- Workflow作成データの書込み(EKS CronJob)
- アクセス解析データの利用側の修正(Elastic Beanstalk)
EMRからWorkflowへの移行
大規模開発における構成図の重要性
EMRは元々古いシステムであり、かつ、大量のクエリが関係しあっていました。それらをDSCが管理するWorkflowに置き換える作業から始まったのですが、量が膨大なのでまずはそれを整理するところから始めました。
具体的にはファイルを1枚ずつ確認し、下記のような構成図を作成しました。
(モザイクをかけています)
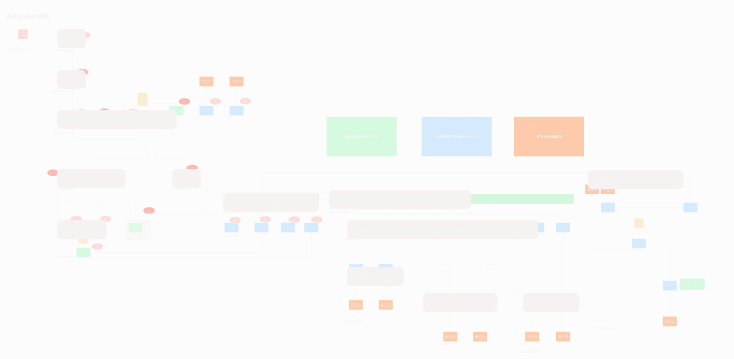
最初は時間がかかったのですが、これを最初に作成したことによってWorkflowへの置き換えの時に迷うことが減り、実装において削除可能な部分を洗いだすことも楽になりました。
構成図はどこでも重要ですが、規模が大きくなればなるほどその重要性は増すなと痛感しました。
1点反省としては、新卒の佐藤君も似たタスクに取り組んでいたのですが彼はLLMを活用してクエリを読み込ませてMermaidで構成図を作っていたので、僕もそうすればよかったなと思いました。
丁寧に管理されている基盤のありがたみ
今回はDSCが管理しているWorkflowへと置き換えを行ったのですが、個人的には独自基盤やフレームワークは巷ではあまり良い噂を聞かないイメージだったので少し心配していました。
しかし、実際に利用してみると、ドキュメントがきっちりと整備されていてわかりやすく、実装でわからない部分があってもDSCの方がすぐに解決してくださり、ストレスなく実装を完了させることができました。
下記はWorkflowのドキュメントの目次の画像なのですが、丁寧に各項目が記載されていることがわかると思います。
独自基盤やフレームワークそのものが悪いわけではなく、それが価値を生み出せる体制も一緒に整備されていることで大きなメリットが生まれるのだと思いました。
Workflow作成データの書込み(EKS CronJob)
データを随時書込みさせる
つづいて、BigQueryに保存した日次データをEKSのCronJobを利用してDynamoDBに書き込みます。最初はBigQueryのデータを丸ごと引っ張ってきて、すべてMemory上に乗せる実装にしており、OOM Killされてしまいました。。。
元の実装(実装の一部は割愛しています)
func (w *PartialBestImpl) Stream(ctx context.Context, parameter model.AnalysisParameter) ([]*model.PartialBest, error) {
q := w.bqClient.Query(partialBestQuery)
q.Parameters = []bigquery.QueryParameter{
{Name: "TARGET_JST_YYYY_MM_DD", Value: parameter.TargetHyphenDate},
}
job, err := q.Run(ctx)
if err != nil {
return nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "q.Run")
}
status, err := job.Wait(ctx)
if err != nil {
return nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "job.Wait")
}
if status.Err() != nil {
return nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "status.Err")
}
it, err := job.Read(ctx)
if err != nil {
return nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "job.Read")
}
var results []*model.PartialBest
for {
var partialBest model.PartialBest
err := it.Next(&partialBest)
if errors.Is(err, iterator.Done) {
break
}
if err != nil {
return nil, err
}
results = append(results, &partialBest)
}
return results, nil
}
そこでつぎのように実装を変更して、データを一部取得して、チャンネルに渡して書込み、また、一部取得して書込み、というふうに逐次書込みへ変更しました。
func (w *PartialBestImpl) Stream(ctx context.Context, parameter model.AnalysisParameter) (<-chan *model.PartialBest, <-chan error, error) {
q := w.bqClient.Query(partialBestQuery)
q.Parameters = []bigquery.QueryParameter{
{Name: "TARGET_JST_YYYY_MM_DD", Value: parameter.TargetHyphenDate},
}
job, err := q.Run(ctx)
if err != nil {
return nil, nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "q.Run")
}
status, err := job.Wait(ctx)
if err != nil {
return nil, nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "job.Wait")
}
if status.Err() != nil {
return nil, nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "status.Err")
}
it, err := job.Read(ctx)
if err != nil {
return nil, nil, errorutil.ErrorWithMessage(errs.ErrorTypeServer, "job.Read")
}
// データを逐次的に返すチャネルを作成
outChan := make(chan *model.PartialBest)
errChan := make(chan error, 1)
go func() {
defer close(outChan)
defer close(errChan)
for {
var partialBest model.PartialBest
err := it.Next(&partialBest)
if errors.Is(err, iterator.Done) {
break
}
if err != nil {
errChan <- err
return
}
// データをチャネルに送信
outChan <- &partialBest
}
}()
return outChan, errChan, nil
}
これによりkillされることがなくなり、安定的に稼働するようになりました。
並列処理
Workflowが完了するのは午前5時半頃なので、Batchによる書込みを開始するのは午前6時からとしていました。そのため、午前8時までだと2時間で終わらせる必要があります。
最初は直列で書込みをしており、2時間以内に収まりませんでした。そこで並列処理の実装を追加しました。
最初のコードがこちらです。
func (a *Application) Execute(ctx context.Context) error {
var wg sync.WaitGroup
errCh := make(chan error, 11) // エラーを収集するためのチャネル(バッファサイズはゴルーチンの数)
// 各集計処理を並行して実行
tasks := []struct {
name string
fn func(context.Context) error
}{
{"WeeklyEntry", a.weeklyEntry.Summarize},
{"WeeklyReferrer", a.weeklyReferrer.Summarize},
{"MonthlyEntry", a.monthlyEntry.Summarize},
{"MonthlyReferrer", a.monthlyReferrer.Summarize},
{"ThirtiethEntry", a.thirtiethEntry.Summarize},
{"ThirtiethReferrer", a.thirtiethReferrer.Summarize},
{"PartialBest", a.partialBest.Summarize},
{"DailyEntry", a.dailyEntry.Summarize},
{"DailyPageview", a.dailyPageview.Summarize},
{"DailyReferrer", a.dailyReferrer.Summarize},
{"HourlyPageview", a.hourlyPageview.Summarize},
}
for _, task := range tasks {
wg.Add(1)
go func(taskName string, summarizeFunc func(context.Context) error) {
defer wg.Done()
if err := summarizeFunc(ctx); err != nil {
errCh <- errorutil.ErrorWithMessage(errs.ErrorTypeServer, "usecase.%s.Summarize: %w", taskName, err)
return
}
}(task.name, task.fn)
}
// ゴルーチン全ての完了を待つ
wg.Wait()
close(errCh)
// すべてのエラーを収集して返す
var errs []error
for err := range errCh {
if err != nil {
errs = append(errs, err)
}
}
if len(errs) > 0 {
return fmt.Errorf("multiple errors: %v", errs)
}
レビューをチームに依頼ところ、江原君からerrgroupを利用したほうが見通しがよくなりそうとレビューをいただき、下記のように修正しました。
func (a *Application) Execute(ctx context.Context) error {
// errgroup を使用して並行処理を管理
**g, ctx := errgroup.WithContext(ctx)**
g.SetLimit(11) // 同時に実行するゴルーチンの最大数を11に設定
// 各集計処理のタスクを定義
tasks := []struct {
name string
fn func(context.Context) error
}{
{"WeeklyEntry", a.weeklyEntry.Summarize},
{"WeeklyReferrer", a.weeklyReferrer.Summarize},
{"MonthlyEntry", a.monthlyEntry.Summarize},
{"MonthlyReferrer", a.monthlyReferrer.Summarize},
{"ThirtiethEntry", a.thirtiethEntry.Summarize},
{"ThirtiethReferrer", a.thirtiethReferrer.Summarize},
{"PartialBest", a.partialBest.Summarize},
{"DailyEntry", a.dailyEntry.Summarize},
{"DailyPageview", a.dailyPageview.Summarize},
{"DailyReferrer", a.dailyReferrer.Summarize},
{"HourlyPageview", a.hourlyPageview.Summarize},
}
for _, task := range tasks {
g.Go(func() error {
if err := task.fn(ctx); err != nil {
return errorutil.ErrorWithMessage(errs.ErrorTypeServer, fmt.Sprintf("usecase.%s.Summarize: %%w", task.name), err)
}
return nil
})
}
// 全てのタスクの完了を待つ
if err := g.Wait(); err != nil {
return err
}
これにより、実装がかなりすっきりしました。
DynamoDBをアプリケーションからプロビジョニングする
DynamoDBにはキャパシティという書込みや読み込みの性能を表す単位があり、リクエストに応じて自動で変動させるオンデマンドモードと一定の量を維持するプロビジョニングモードがあります。
アクセス解析で必要となるキャパシティは毎日極端に変動するわけではなくある程度予測可能なので、プロビジョニングモードで実装することにしました。
最初は定期実行によって6時から8時の間にDynamoDBのWCU(DynamoDBの書き込み性能を表す単位)を一時的にApplication Auto Scalingを利用して増やしていました。
書込み自体は6-7時で終わる予定にもかかわらず8時まで上げていたのは、仮に途中で失敗したとしても再度リトライする時間として確保していました。
ですが、この実装では無駄が多く大きなコストが発生してしまいました。
そこで、アプリケーション側で利用時にWCUを上げて、利用が終わったら下げるという実装を追加しました。下記のような実装です(簡略化しています)
ポイントは、waitForTableAndGSIActive関数です。
プロビジョニングが確実に成功するまでポーリングし、成功してから書き込むようにしています。
func (w *PartialBestImpl) BulkInsert(ctx context.Context, dataChan <-chan *model.PartialBest, errChan <-chan error) error {
ctx, cancel := context.WithCancel(ctx)
defer cancel()
// 現在のプロビジョニング設定を取得
tableStatus, err := w.DynamoDBClient.DescribeTable(ctx, &dynamodb.DescribeTableInput{
TableName: aws.String(tableName),
})
if err != nil {
return fmt.Errorf("w.DynamoDBClient.DescribeTable: %w", err)
}
// テーブルを更新(RCUは既存のまま、GSIの設定はしない)
err = updateDynamoDBTableCapacityUnits(ctx, w.DynamoDBClient, tableName, *tableStatus.Table.ProvisionedThroughput.ReadCapacityUnits, w.config.DynamoDBConfig.BestWCU, "", -1, -1)
if err != nil {
return fmt.Errorf("updateDynamoDBTableCapacityUnits: %w", err)
}
// テーブルがアクティブになるまで待機、アクティブになる前に書き込むとスロットリングされて最悪失敗する
err = waitForTableAndGSIActive(ctx, w.DynamoDBClient, tableName)
if err != nil {
return fmt.Errorf("waitForTableAndGSIActive: %w", err)
}
// テーブルに内容を書き込む処理(割愛)
// テーブルを更新
err = updateDynamoDBTableCapacityUnits(ctx, w.DynamoDBClient, tableName, *tableStatus.Table.ProvisionedThroughput.ReadCapacityUnits, 1, "", -1, -1)
if err != nil {
return fmt.Errorf("updateDynamoDBTableCapacityUnits: %w", err)
}
// テーブルがアクティブになるまで待機
err = waitForTableAndGSIActive(ctx, w.DynamoDBClient, tableName)
if err != nil {
return fmt.Errorf("waitForTableAndGSIActive: %w", err)
}
return nil
}
func updateDynamoDBTableCapacityUnits(ctx context.Context, dynamoClient *dynamodb.Client, tableName string, newRCU, newWCU int64, gsiName string, newGSIRCU, newGSIWCU int64) error {
// テーブルのRCUとWCUを更新する
input := &dynamodb.UpdateTableInput{
TableName: aws.String(tableName),
}
input.ProvisionedThroughput = &types.ProvisionedThroughput{
ReadCapacityUnits: aws.Int64(newRCU),
WriteCapacityUnits: aws.Int64(newWCU),
}
if gsiName != "" {
// GSIのRCUとWCUを更新する場合
input.GlobalSecondaryIndexUpdates = []types.GlobalSecondaryIndexUpdate{
{
Update: &types.UpdateGlobalSecondaryIndexAction{
IndexName: aws.String(gsiName),
ProvisionedThroughput: &types.ProvisionedThroughput{
ReadCapacityUnits: aws.Int64(newGSIRCU),
WriteCapacityUnits: aws.Int64(newGSIWCU),
},
},
},
}
}
_, err := dynamoClient.UpdateTable(ctx, input)
if err != nil {
return fmt.Errorf("dynamoClient.UpdateTable: %w", err)
}
return nil
}
func waitForTableAndGSIActive(ctx context.Context, dynamoClient *dynamodb.Client, tableName string) error {
ticker := time.NewTicker(60 * time.Second) // 60秒ごとにチェック
defer ticker.Stop()
timeoutCtx, cancel := context.WithTimeout(ctx, 60*time.Minute)
defer cancel()
for {
select {
case <-ticker.C:
// テーブルのステータスをチェック
input := &dynamodb.DescribeTableInput{
TableName: aws.String(tableName),
}
output, err := dynamoClient.DescribeTable(ctx, input)
if err != nil {
return fmt.Errorf("dynamoClient.DescribeTable: %w", err)
}
// テーブルのステータスがACTIVEであるか確認
if output.Table.TableStatus != types.TableStatusActive {
continue // テーブルがACTIVEでないので待機を続ける
}
// 全てのGSIがACTIVEであるか確認
allGSIActive := true
for _, gsi := range output.Table.GlobalSecondaryIndexes {
if gsi.IndexStatus != types.IndexStatusActive {
allGSIActive = false
break
}
}
if allGSIActive {
// テーブルと全てのGSIがACTIVEになった
log.Default().Printf("Table %s and its GSIs are ACTIVE", tableName)
return nil
}
// まだACTIVEになっていないので待機を続ける
logger.FromContext(ctx).Info(fmt.Sprintf("Waiting for table %s to become ACTIVE", tableName))
case <-timeoutCtx.Done():
return fmt.Errorf("timeout: table %s and its GSIs did not become ACTIVE within the expected time", tableName)
case <-ctx.Done():
return fmt.Errorf("context cancelled while waiting for table %s and its GSIs to become ACTIVE", tableName)
}
}
}
これにより、アプリケーションがWCUを必要としている時だけ利用することができ、コストを大幅に抑えることができました。
アクセス解析データの利用側の修正(Elastic Beanstalk)
クロスアカウントによる移行
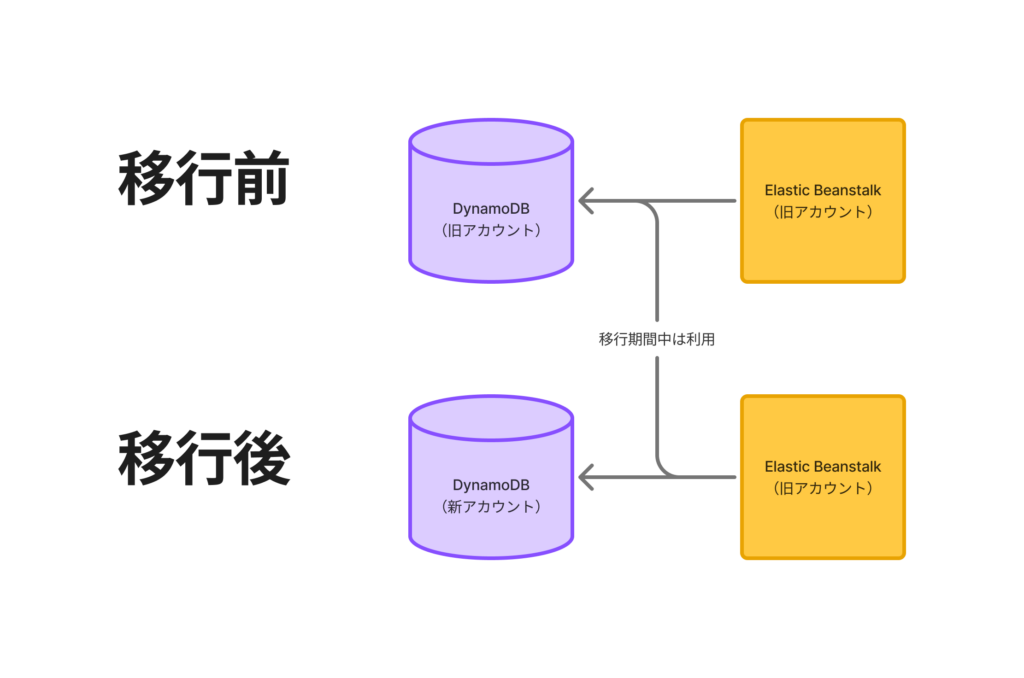
アクセス解析では過去3ヶ月分のデータを確認できるようにする必要があるので、古いデータと新しいデータをうまく使い分ける必要がありました。
また、API側は事情があり新しいアカウントへと今回は移行していません。
まとめると下記のようなイメージです。
移行日以前のデータが必要なリクエスト→旧アカウントのDynamoDBの情報取得
移行日以前と以後のデータの両方が必要なリクエスト→新旧アカウントのDynamoDBの情報取得
移行日以後のデータが必要なリクエスト→新アカウントのDynamoDBの情報取得
そこで、コード的には下記のような実装を追加しました。
func (r *dailyPageviewRepositoryImpl) List(ctx context.Context, amebaID model.AmebaID, start, end civil.Date) (model.DailyPageviews, error) {
// 移行日を設定
migrationDate := civil.Date{Year: 2025, Month: 2, Day: 25}
var pvs model.DailyPageviews
if end.Before(migrationDate) {
// **ケース1:終了日が移行日より前**
// 古いテーブルからデータを取得
tableName := strings.Replace(r.tableName, "blog_", "", 1)
data, err := r.queryDailyPageviews(ctx, tableName, amebaID, start, end)
if err != nil {
return nil, err
}
pvs = append(pvs, data...)
} else if start.Before(migrationDate) && (end == migrationDate || end.After(migrationDate)) {
// **ケース2:開始日が移行日より前で、終了日が移行日以降**
// 1. 古いテーブルからデータを取得(開始日 ~ 移行日の前日)
tableNameOld := strings.Replace(r.tableName, "blog_", "", 1)
oldEndDate := migrationDate.AddDays(-1)
dataOld, err := r.queryDailyPageviews(ctx, tableNameOld, amebaID, start, oldEndDate)
if err != nil {
return nil, err
}
pvs = append(pvs, dataOld...)
// 2. 新しいテーブルからデータを取得(移行日 ~ 終了日)
tableNameNew := r.tableName
dataNew, err := r.queryCrossClientDailyPageviews(ctx, tableNameNew, amebaID, migrationDate, end)
if err != nil {
return nil, err
}
pvs = append(pvs, dataNew...)
} else {
// **ケース3:開始日が移行日以降**
// 新しいテーブルからデータを取得
tableName := r.tableName
data, err := r.queryCrossClientDailyPageviews(ctx, tableName, amebaID, start, end)
if err != nil {
return nil, err
}
pvs = append(pvs, data...)
}
return pvs, nil
}
また、IAM的にはクロスアカウント設定を行い、旧アカウントから新アカウントへアクセスできるようにしています。
API側のIAMの設定(旧アカウント)
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": "sts:AssumeRole",
"Resource": "新アカウントのarn"
}
}
DynamoDB側のIAMの設定(新アカウント)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "旧アカウントのarn"
},
"Action": "sts:AssumeRole"
}
]
}
両方のアカウントに設定が必要なことがポイントです。
動作確認
Workflowの時もだったのですが、どのように動作確認をするかが非常に重要でした。
小さいシステムなら小さいサンプルを取って動作確認すればそれで終わりでよさそうですが、アメーバブログほど大きいサービスで動作を担保するにはどうしたらよいか悩みました。
そこで同じチームの金井さんに相談したところ、ランキング上位1000人分のデータで動作確認をすればよいかもねとアドバイスを受けたので、その通りに実践してみました。
誰でもいいわけではなく、PV数の影響が大きな数字として現れる可能性が高いユーザーに絞って動作確認するという一工夫や、1000人というやや大きいですが、スクリプトを書けば動作確認できる絶妙な単位で動作確認するというのはこれまでの自分にはない観点で学びになりました。
そして、その1000人分に対して関連するエンドポイントと考えうるパラメータをすべて列挙して動作確認するスクリプトをLLMをフル活用して書きました。ここではLLMを活かせたので、かなり時間削減になりました。
これによって、既存のアクセス解析のデータと新しいアクセス解析のデータを比較することが可能になりました。元データは移行により改善されて数値が少し異なっているので、大まかな一致の確認となりましたが、不安を減らしてリリースに臨むことができました。
大規模な移行だったので、リリース後にお問い合わせが大量にくるかなと思い、PMの方とも気を引き締めてリリースしたのですが、結果的にはお問い合わせは2件で、それも移行に伴い元データが改善したことに起因する想定内のものでした。動作確認方法は問題なかったようです!
まとめ
合計で3ヶ月ほどかかったタスクとなり、たくさんの反省がありますが無事に移行できたことが非常に嬉しいです。
トラブルに見舞われても、Data Science Centerの方やインフラチームの方、自チームの方にも迅速に助けていただき本当にありがたかったです。
Amebaというユーザーが膨大にいる旧システムを理解し、それを新しい技術で刷新して運用方法から見直していける、というのは技術者として非常にチャレンジングで楽しい経験で今後も頑張っていきたいと思いました。
以上です!