
CA DATA NIGHTは、サイバーエージェントが主催するデータサイエンスに特化した技術者向けの勉強会です。機械学習、統計学、自然言語処理、コンピュータビジョン、情報推薦、検索、経済学など様々な専門分野のエンジニアやデータサイエンティストから技術・取り組みなどを紹介いたします。
今回は、急速に進化する生成AI/大規模言語モデル(LLM)の活用が、それぞれの現場でどのように根づいてきているのかに着目。コンテンツ領域におけるABEMAでのLLMレコメンドの実験・検証結果、マッチングアプリ「タップル」での自然言語からSQLを生成する社内エージェントの導入フロー、そしてCodeAgentとMCPを活用した企業内LLM運用の事例など、異なる切り口からのデータ・AI実践事例を技術者自身がご紹介します。
本記事は、2025年05月22日に開催した「CA DATA NIGHT #6 〜活用から実務へ──生成AI・LLMの“業務の入り口”を探る〜」において発表された「LLMを用いたメタデータベースレコメンド検証」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
宇戸 慎吾(株式会社AbemaTV/Development Headquarters/データサイエンティスト)
データ分析の常駐支援、受託分析のデータサイエンティストを経て、2023年8月に中途入社。現在は「ABEMA」で施策の効果検証や戦略立案のためのデータ分析業務に従事。
X:@s1ok69oo
ABEMAにおけるLLMを用いたメタデータベースのレコメンド検証というテーマでお話いたします。

名前は宇戸 慎吾と申します。ABEMAでデータサイエンティストとして働いております。バックグラウンドは経済学で、2023年8月にサイバーエージェントに中途入社し、そのままABEMAにジョインしました。現在は、様々な施策の効果検証や、データから広告の売上を伸ばすための戦略を考えるなどの業務を担当しています。趣味はキックボクシングで、Xでは「うとしん」という名前で活動していますので、ご存知の方がいらっしゃいましたらお声がけいただけると嬉しいです。

今回お話する内容は、2024年のCODE@MITというカンファレンスに採択されたものです。CODEは、NetflixやAmazon、Metaなどの民間テック企業が参加し、A/Bテストの結果や知見を共有するカンファレンスです。
施策の背景
ABEMAの紹介
ABEMAは無料で視聴いただける部分と、プレミアム会員向けのコンテンツがあります。無料視聴の場合は広告収入、プレミアム会員の場合は課金収入がビジネスモデルとなっています。
ABEMAのレコメンドシステム

コンテンツの特徴を示す要件のようなものがあり、その中に要件を満たしたコンテンツが集められています。そのコンテンツの集合をモジュールと呼んでいます。
ABEMAのレコメンドシステムには複数のロジックが存在しています。シンプルなルールベースのもの、機械学習ベースのもの、バンディットアルゴリズムなど複数のロジックが存在しています。図のようにページごと、モジュールごとに適用されるロジックが異なっています。例えば、ページAのモジュールaの部分ではバンディットのロジックが、同じページAでもモジュールbの部分ではルールベースのロジックが使われており、ページBのモジュールCではMLベースのものが採用されている、みたいなイメージです。このように、ページごと、モジュールごとに適用されるロジックが異なっているのが、ABEMAのレコメンドシステムです。
視聴ページの推薦枠について
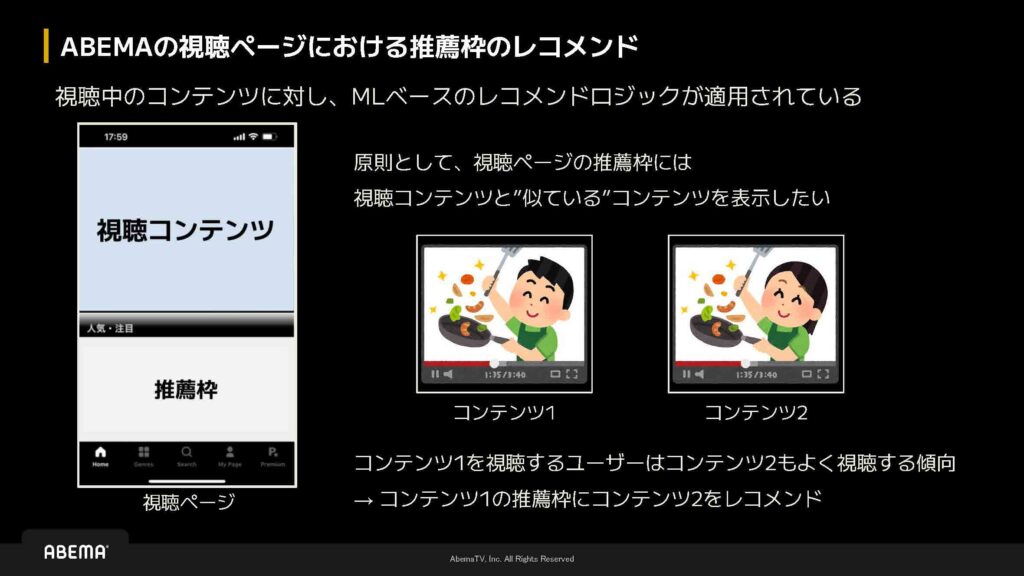
ABEMAの視聴ページには、視聴中のコンテンツの下部に推薦枠があります。ここでは機械学習ベースのレコメンドロジックが適用されています。この推薦枠にレコメンドするコンテンツの要件として「視聴中のコンテンツと似ているコンテンツを表示する」というものがあり、「似ている」の定義はデータサイエンティストやMLエンジニアに委ねられています。
元々使用していた機械学習ベースのロジックでは、「コンテンツ1を視聴するユーザーはコンテンツ2もよく視聴する傾向がある」という行動パターンを捉え、レコメンドを行っていました。
Popularity Biasの問題

このアプローチでは、よく視聴されるコンテンツはさらに多くレコメンドされる一方、あまり視聴されていないコンテンツはレコメンドされにくいという「Popularity Bias」の問題が生じていました。
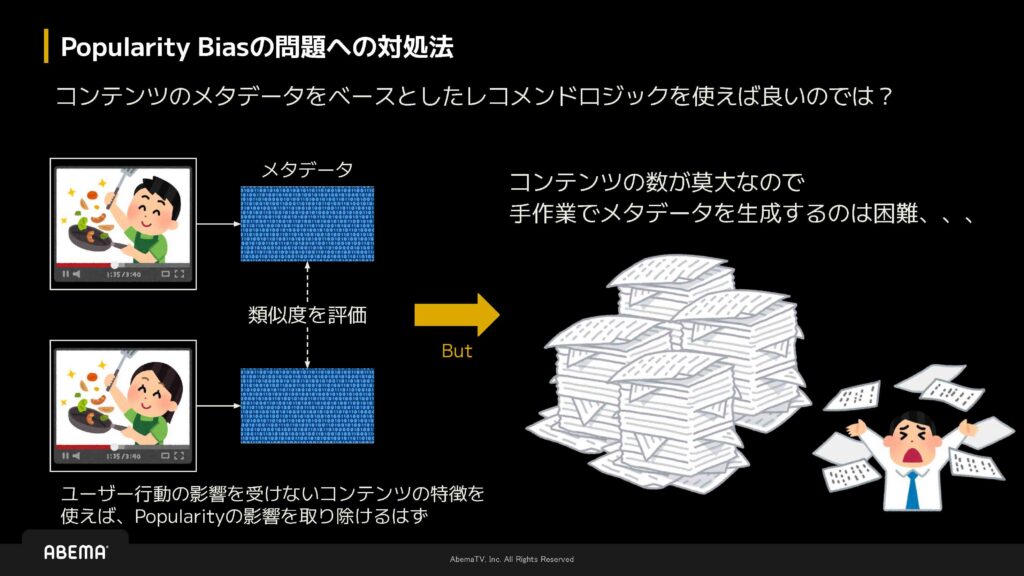
次に、Popularity Biasの問題への対処法として、コンテンツのメタデータをベースにしたレコメンドロジックを作成し、それを使ってレコメンドを行えばよいのではないかと考えました。ユーザー行動の影響を受けにくいコンテンツの特徴を活用すれば、Popularity Biasの影響を緩和できるだろうと想定しました。
そこで、具体的にはコンテンツ1とコンテンツ2のメタデータを作成し、その類似度を評価する方法を検討しました。しかし、ABEMAでは扱うコンテンツの数が非常に膨大であるため、手作業でメタデータを生成するのは現実的ではありません。そこで、LLM(大規模言語モデル)を利用することにしました。

LLMを用いたメタデータベースレコメンド
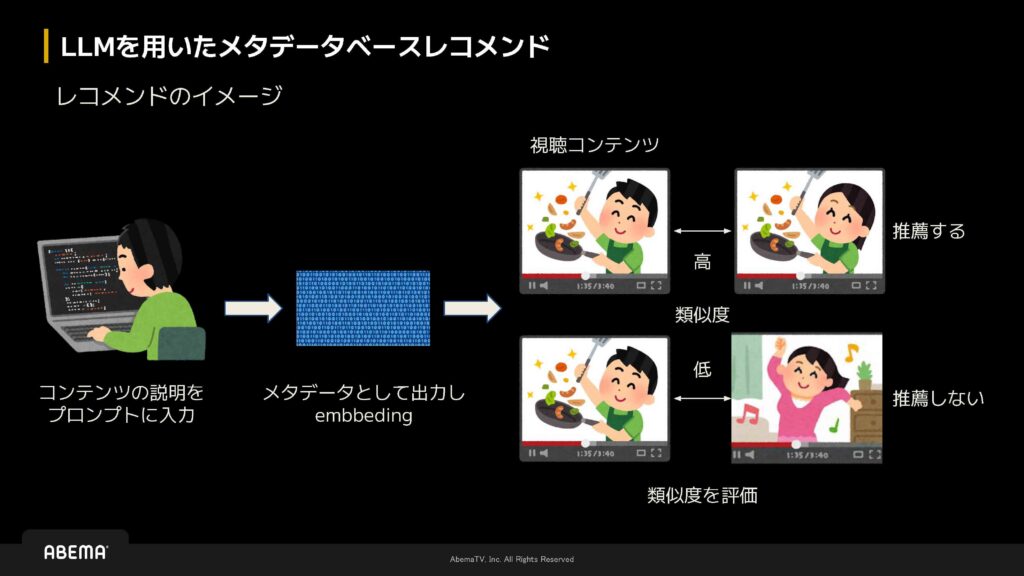
LLMを用いたメタデータベースレコメンドのイメージは、まずコンテンツの説明をプロンプトに入力することから始まります。入力した説明から一度メタデータを生成し、そのメタデータをembeddingしてベクトル化します。最後に、ベクトル化された各コンテンツのベクトル同士で類似度を評価し、類似度が高いコンテンツを推薦し、低いコンテンツは推薦しないという流れでレコメンドを行います。
検証結果
実験デザイン

ここからは雰囲気が変わり、検証結果や分析結果についてお話しします。まず、このようなレコメンドロジックを作成した後に、どのように検証したかをご説明します。実験デザインとしては、10日間にわたってA/Bテストを実施し、以下の回帰モデルを用いて処置効果を推定しました。
Yi, t=1 = β0 + β1・Yi, t=0 + τ・Ti + ui
細かい数式の詳細には触れませんが、モデルのアウトカム変数Yは視聴に関するKPIを想定しています。ユーザーごとに時点t=1とt=0でのYを観測し、t=1が検証期間、t=0が検証前の期間を表します。ここで特徴的なのは、単純に
Yi = β0 + τ・Ti + ui
のような単回帰モデルでモデリングするのではなく、過去時点(t=0)のアウトカムを今日変量として組み込んでいる点です。その結果、A/Bテスト実施前から偶然に差があった場合でも、そのバイアスをコントロールできるように設計しています。
A/Bテストの設定は、ユーザーがログインしたタイミングでControl GroupまたはTreatment Groupのいずれかにランダムに割り振られます。Control Groupに割り振られたユーザーにはMLベースのレコメンドロジックが推薦枠に表示され、Treatment Groupに割り振られたユーザーにはメタデータベースレコメンドが推薦枠で使用されるという実験デザインになっております。
想定される効果

想定される効果は大きく二つあります。まず一つ目は、majorコンテンツの視聴KPIが減少することです。もともとPopularity Biasはmajorコンテンツを多く表示する傾向が問題でしたが、今回の手法ではその傾向を抑制します。そのため、majorコンテンツの表示回数が減り、結果として視聴数も減少するだろうと考えられます。一方で、majorコンテンツのインプレッションが減少するぶん、minorコンテンツのインプレッションが増加します。したがって、minorコンテンツの視聴KPIは増加するのではないかと想定されます。
ここで、majorコンテンツとminorコンテンツの定義についてご説明します。実験前の20日間におけるサービス全体の視聴ユニークユーザー数を集計し、その上位50コンテンツをmajorコンテンツと定義しました。それ以外のコンテンツをminorコンテンツとしています。
推定結果

ここからは推定結果についてご説明します。まず、介入対象枠として、視聴ページの推薦枠経由の視聴KPIへの効果を確認しました。
全コンテンツ、majorコンテンツ、minorコンテンツに分けて評価した結果、全コンテンツの視聴KPIはユーザー1人当たり約0.0027減少していることが分かりました。結果を詳細に見ると、majorコンテンツの視聴KPIは想定どおり大きく低下し、minorコンテンツの視聴KPIは想定どおり若干上昇していました。しかし、推薦枠経由での視聴は全体として減少しており、サービス全体における影響を把握するために、他の経路も含めて全体の視聴状況を調査しました。
すると、意外な結果が得られました。先ほどと同様に、全コンテンツ、majorコンテンツ、minorコンテンツに分けて分析したところ、サービス全体の視聴KPIはユーザー1人当たり増加していたのです。推薦枠経由では減少していたものの、サービス全体では増加したという結果になりました。majorコンテンツの視聴KPIは低下傾向が見られたものの、統計的には有意な差は認められませんでした。一方で、minorコンテンツの視聴KPIはユーザー1人当たり増加していることが分かり、これは推薦枠経由の結果とは逆の傾向です。

ここまでをまとめると、推薦枠経由の視聴KPIでは、majorコンテンツの減少幅がminorコンテンツの増加幅よりも大きいという結果でした。一方、サービス全体の視聴KPIを見ると、minorコンテンツの増加幅がmajorコンテンツの減少幅を上回っていました。

以上の結果から、推薦枠以外の画面や経路を経由した視聴が増加していると考えられます。そのため、ユーザーのトラフィックが多いトップ画面やジャンルトップ画面を経由した視聴KPIを確認したところ、トップ画面経由でもジャンルトップ画面経由でも、majorコンテンツの視聴KPIが増加していることが分かりました。一方で、minorコンテンツの視聴KPIはほとんど減少していませんでした。

考察

これまでの結果を踏まえて考察すると、レコメンド枠のロジックを変更したことによって、視聴画面を起点としたユーザー行動には次のような変化が見られました。
まず、旧ロジックでは、レコメンド枠にmajorコンテンツが多く表示され、minorコンテンツはほとんど表示されていませんでした。そのため、レコメンド枠経由で何かコンテンツを視聴しようとすると、ユーザーは基本的にmajorコンテンツを選択して視聴する行動になっていました。では、レコメンド枠に目当てのコンテンツが見つからなかった場合、ユーザーはどのような行動を取っていたかというと、一度トップ画面などに遷移してから別のコンテンツを探すという流れになります。
しかし、トップ画面にもサービス側が推奨したいmajorコンテンツや人気のコンテンツが多く表示されるため、ここでも結局はmajorコンテンツを選んで視聴するという動きになっていました。つまり、旧ロジック下では、どの経路を通ってもmajorコンテンツが優先的に視聴される構造になっていたと言えます。
新ロジックに変更した結果、まず推薦枠で表示されるmajorコンテンツが減り、minorコンテンツの表示が増加しました。そのため、推薦枠経由でminorコンテンツを視聴する割合が増えたという点が、最初の大きな変化です。
一方で、推薦枠に見たいコンテンツがなかった場合、ユーザーは旧ロジックと同様にトップ画面などへ回遊し、その後majorコンテンツを視聴する動きをとります。しかし重要なのは、旧ロジックによって推薦枠で表示されていたmajorコンテンツは、最終的にトップ画面などにも表示されているという点です。そのため、推薦枠経由で減少したmajorコンテンツの一部は、トップ画面経由での視聴によって回収されています。
結果として、majorコンテンツの視聴減少分をすべてトップ画面で埋め合わせているわけではないものの、一部はしっかりと回収されている状態です。一方、minorコンテンツの増加分はトップ画面でもほとんど回収されず、そのまま純粋に増加しています。そのため、majorコンテンツの視聴減少幅よりも、minorコンテンツの視聴増加幅のほうが大きくなっているのではないかと考えられます。
まとめ
 まとめです。まず最初に、MLベースのレコメンドロジックを使っていましたが、Popularity Biasの問題があるという話でした。その問題に対処するために、メタデータベースのレコメンドロジックを開発しました。その際、莫大なコンテンツ数に対応するために大規模言語モデル(LLM)を用いてメタデータを生成し、この課題をブレイクスルーしました。
まとめです。まず最初に、MLベースのレコメンドロジックを使っていましたが、Popularity Biasの問題があるという話でした。その問題に対処するために、メタデータベースのレコメンドロジックを開発しました。その際、莫大なコンテンツ数に対応するために大規模言語モデル(LLM)を用いてメタデータを生成し、この課題をブレイクスルーしました。
次に、そのロジックに対してA/Bテストによる効果検証を実施しました。その結果、サービス全体では市長が増加する傾向が見られました。内訳としては、majorコンテンツの視聴がやや下がり、minorコンテンツの視聴が大きく増加するという結果になっています。
ここでポイントとなるのは、推薦枠経由のmajorコンテンツの視聴は減少したものの、その減少分の一部はトップページやジャンルトップなどの別のページで回収されていた点です。そのため、全体で見るとminorコンテンツの視聴増加分がポジティブに働き、サービス全体の視聴を増加させることができました。あまり人気のないコンテンツを表示しつつ、サービス全体の視聴時間を伸ばすという面白い成果を得られたと感じています。
なお、現在ABEMAではデータサイエンティストを募集しています。「ABEMA 経営 データサイエンス」で検索すると詳細ページが見つかりますので、興味のある方はぜひご応募ください。