
CA DATA NIGHTは、サイバーエージェントが主催するデータサイエンスに特化した技術者向けの勉強会です。機械学習、統計学、自然言語処理、コンピュータビジョン、情報推薦、検索、経済学など様々な専門分野のエンジニアやデータサイエンティストから技術・取り組みなどを紹介いたします。
今回は、急速に進化する生成AI/大規模言語モデル(LLM)の活用が、それぞれの現場でどのように根づいてきているのかに着目。コンテンツ領域におけるABEMAでのLLMレコメンドの実験・検証結果、マッチングアプリ「タップル」での自然言語からSQLを生成する社内エージェントの導入フロー、そしてCodeAgentとMCPを活用した企業内LLM運用の事例など、異なる切り口からのデータ・AI実践事例を技術者自身がご紹介します。
本記事は、2025年05月22日に開催した「CA DATA NIGHT #6 〜活用から実務へ──生成AI・LLMの“業務の入り口”を探る〜」において発表された「SQL Agentによるタップルのデータ利活用促進」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
原 和希(株式会社タップル/技術本部/機械学習エンジニア)
2021年に株式会社サイバーエージェントへと新卒入社。 同年より、子会社である株式会社CAMにてMLOpsシステムやレコメンドモデル、生成AIを活用したプロダクト開発などに従事。2025年より、株式会社タップルにて生成AIを活用したプロダクト開発に従事。Google Developer Experts(Google Cloud/ AI)、CyberAgent Next Experts(Google Cloud/ MLOps)として選出され、活動中。
X:@Harappa80
SQL Agentによるタップルのデータ利活用促進と題しまして、発表させていただきます。

原 和希と申します。2021年にサイバーエージェントに新卒入社して、現在は株式会社タップルで機械学習エンジニアをしています。GoogleのDeveloper Expertsや、サイバーエージェントのNext Expertsとして選出いただいており、Google Cloudの活用を得意としています。

今回の目次はこのようになっています。
サービス紹介
まずはじめに株式会社タップルで運営しているサービスの紹介をしたいと思います。弊社は2つのマッチングアプリを運営していまして、1つ目がタップルになります。
こちらは2014年にサービスを開始しまして、国内最大級のマッチングアプリになっています。
もう一つが Koigramです。こちらは2024年の6月にサービスを開始しました、マッチもチャットも全員無料で利用することができるアプリです。
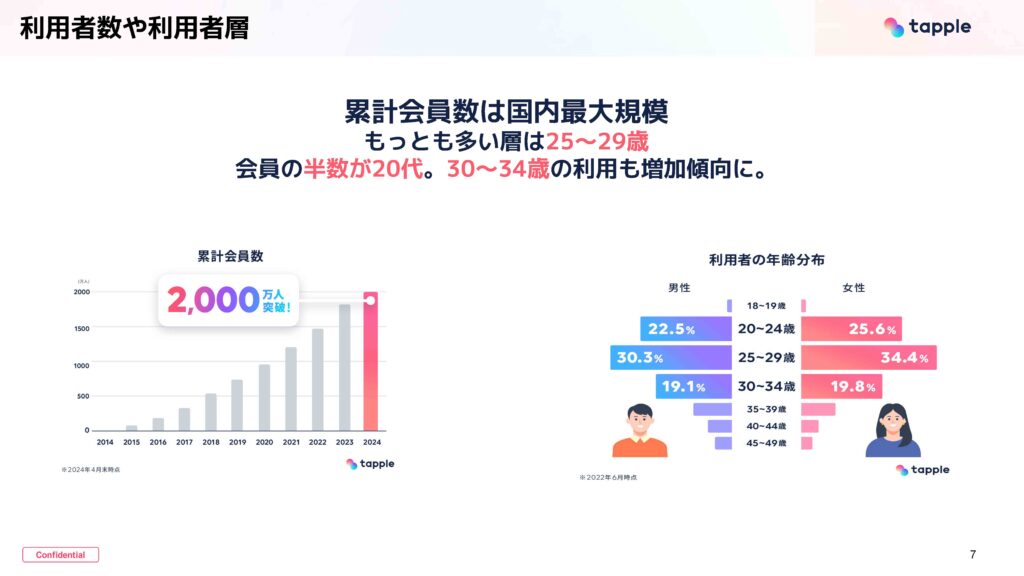
タップルの累計会員数は国内最大規模となっており、最も多い層は25歳から29歳です。会員の半数が20代ですが、30歳から34歳の利用も増加傾向にあります。

サービスの紹介は以上としまして、早速本題に入りたいと思います。今回話すことは、SQL Agentを導入するまでの過程、アーキテクチャ、最後に実装時の工夫ポイントになります。逆に話さないことは、タップルでの利用クエリや質問の内容です。
SQL Agentとは?
では次にSQL Agentとはどのようなものかを話していきたいと思います。
Agentと一言に言っても、最近では皆さんが感じるAgentのイメージが結構異なると思うので、最初にコンテキストを合わせたいと思っています。
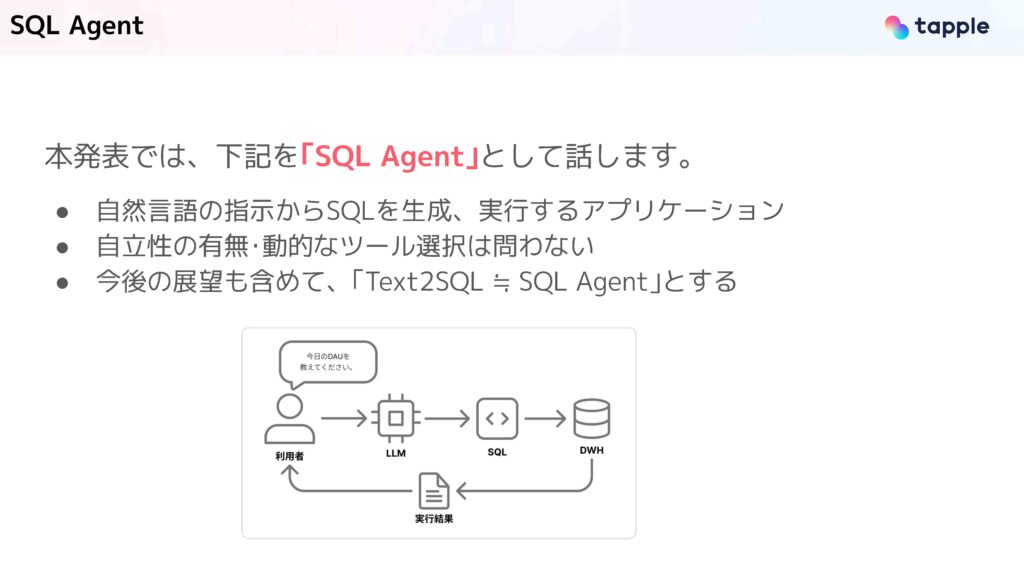
本発表では、自然言語の指示からSQLを生成して、それを実行するアプリケーションをSQL Agentと呼んでいます。ここでは、自律性の有無だったり、動的なツール選択の有無は問いません。今回は、今後の展望なども含めて Text to SQLの領域をSQL Agentとして話します。
こちらの図にあるように、利用者が「今日のDAUを教えてください」のようなメッセージを送ると、LLMがSQLを生成して、それをデータウェアハウスで実行し、結果を返すといった処理になります。
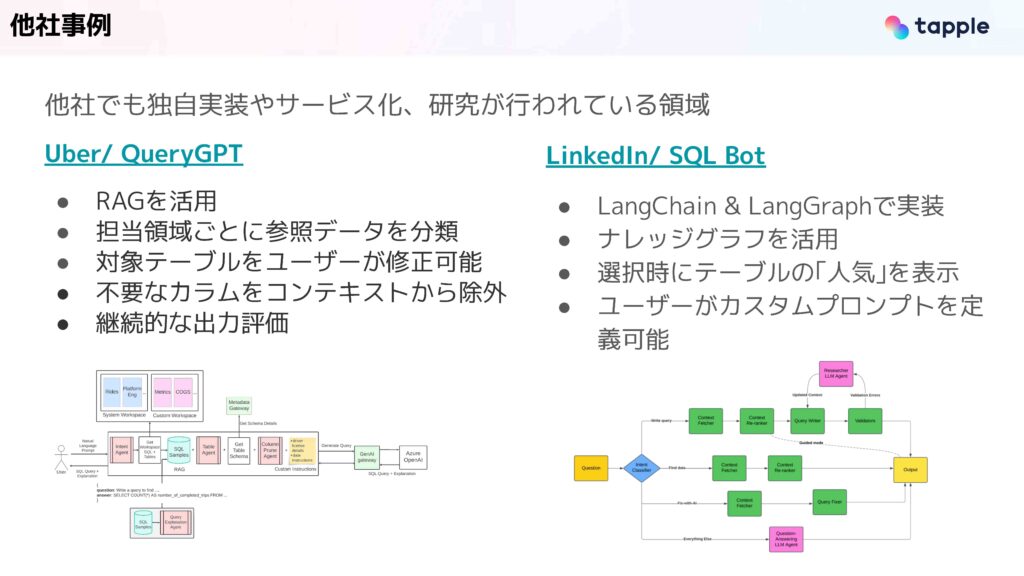
この領域は他社でもかなり盛んに研究や導入が行われています。例えば、UberではRAGの利用や担当領域ごとに参照するデータを事前に分類といった工夫をして、導入が行われています。また、LinkedInでは、LangChainとLangGraphを使って実装しており、ナレッジグラフだったり、選択時にテーブルの人気(よく使われるクエリ)を表示することで、品質を上げているということがブログで紹介されています。
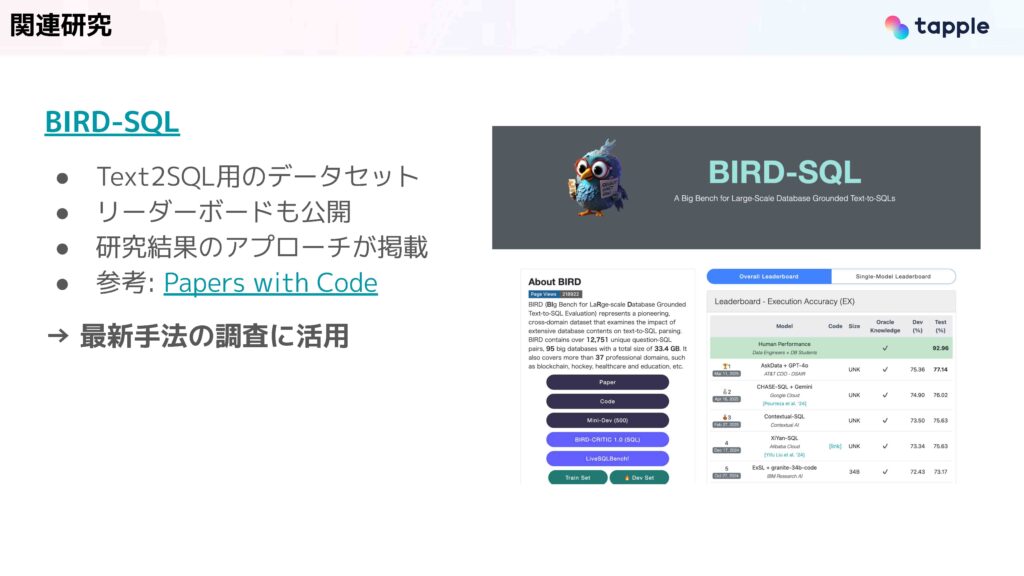
また研究も盛んに行われており、こちらのBIRD-SQLというものはText-to-SQLのベンチマーク用データセットになっています。リーダーボードなども公開されており、ここから各研究結果のアプローチに飛ぶことができます。我々もSQL Agentを開発する中で、最新手法の調査などにこれを活用しました。
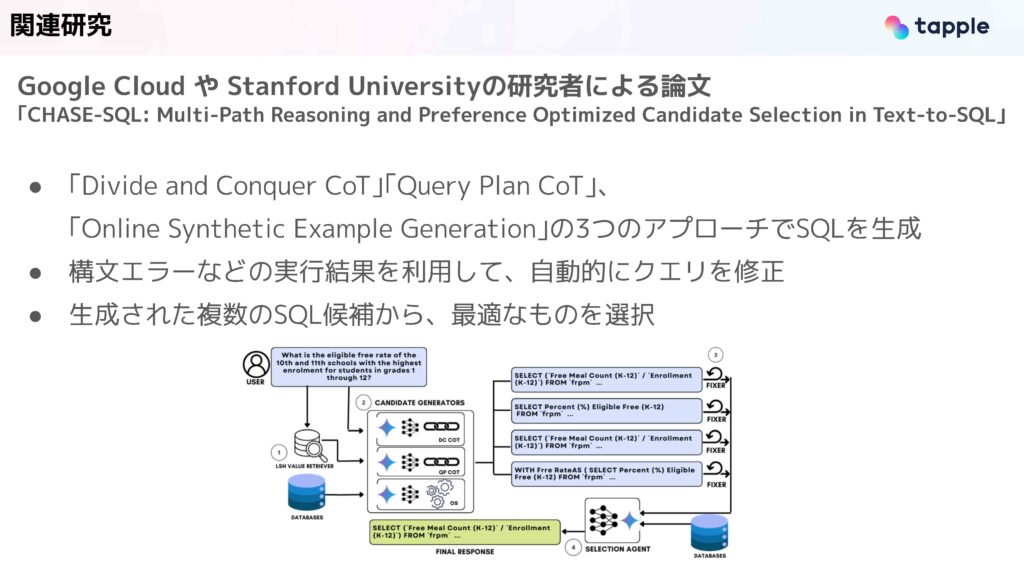
先ほどのBIRD-SQLにおけるリーダーボードの2位に入っているのが、このGoogle Cloudとスタンフォード大学の研究者が出している論文、CHASE-SQLというものです。こちらのアプローチを我々のSQL Agentでも活用したので紹介したいと思います。
こちらに記載の3つのクエリ生成戦略を活用してSQLを生成しています。具体的にはGeminiに異なるSQLの生成方法をプロンプトで渡して、同時に生成をかけます。そして、実行エラーなどを元に自動的にクエリを修正します。最終的に、複数のクエリ候補が出るので、その中から最適なものを返すといった処理が提案されています。
理想状態と検証で得た課題
では、我々がSQL Agentに取り組む上で、どのようなものを理想状態としたのか。また、複数の検証を行ったので、その中で得た課題について話したいと思います。

我々はSQL Agentを導入することで、ビジネス職の方などのSQLが書けない社員がデータ抽出と分析を実現できる状態を目指しました。これによってデータ活用のハードルを下げて、施策を打つ際だったり、意思決定をするときにデータに基づいて実行すること、そしてそのスピードを上げることを狙いとしています。

この理想状態を掲げた上で、Snowflakeを我々はデータウェアハウスとして使用しているので、まずはSnowflakeに搭載されている機能やSaaSの導入で実現ができないかを検証しました。検証したツールはここにあるSnowflakeのCortex Analyst、そしてCortex Copilot、最後にSaaSのWrenAIというものを検証しました。
結論として期待している品質を実現するようなツールを選ぶことはできませんでした。理由としては、複数のテーブルのJOINが含まれる複雑なクエリの品質がやはり低くなってしまうこと。加えて、Variant型のカラムに対応していなかったためです。これは、JSONがそのまま入っているようなものですが、これにより、JSONをパースしてクエリを記述することができなそうだと分かりました。

ここまでで話した、検証や既存研究、事例などから得られた知見として、3つほど紹介したいと思います。1つ目がアーキテクチャに関してです。これに関してはマルチモデルだったり、Reflection、RAGといったテクニックを駆使して品質の向上を行っていると分かりました。
2つ目はメタデータに関してです。こちらで一番重要なのは、テーブルやカラムの説明を充実させることです。このテーブルはどのような用途で使われるものなのか。各カラムはどのような意味があるものなのか。このような説明やSQLのサンプルを書くことは品質向上のために重要だとわかりました。
また、弊社だとマッチングアプリ独自のドメイン知識だったり、ビジネス上のKPIなどを加味してSQLを生成したいニーズがあります。LLMはそれらを学習していないので、コンテキストに入れてあげることが非常に重要です。また、テーブルの説明だったり、ビジネス知識を入れるということが必要なので、ロングコンテキストなモデルが重要であるとわかりました。
3つ目がテーブルとカラムのJOINや選択に関してです。参照可能なテーブルやカラム数が大規模になってくると、誤ったテーブルを選択してしまうことや、誤ったJOINをしてしまう課題があるとわかりました。また、Variant型を処理する際の生成難易度が高いというのは先ほど話した通りです。

これらを踏まえて、我々はツールを導入するのではなくて、独自に構築することを選択しました。

独自構築のメリットは一言で言うと、柔軟性と拡張性の実現です。まず、LLMを柔軟に選択することができるので、例えばOpenAIだったりGoogleだったり、Anthropicだったり、彼らが提供しているモデルから好きなものを選択し、複数を組み合わせて利用できます。最近はモデルの更新速度や精度向上がかなり早くなっているので、これによってリリース速度に追従して品質の向上が狙えると考えました。
生成フローもカスタマイズが自身でできます。例えばSaaSだったり、SnowflakeやBigQueryが提供している機能の場合には、裏側のロジックが隠蔽されています。一方で、独自構築することで、Reflectionやフォローアップの処理といったテクニックを任意で導入し、独自で評価と改善のループを回せると考えました。
また、出力形式もカスタマイズできます。SQLだけを出すのではなくて、各サブクエリではどのような処理を行っているのか、どのような意図でこの生成結果になったのかなども同時に出力ができます。
加えて、先ほど話したようにドメイン知識を注入できるのも利点です。また、WebアプリケーションやSlackBotなど様々な方法で提供できるというのもメリットだと感じています。
タップルでのSQL Agentへのアプローチ
では、より具体的にタップルのSQL Agentでのアプローチを話していきたいと思います。
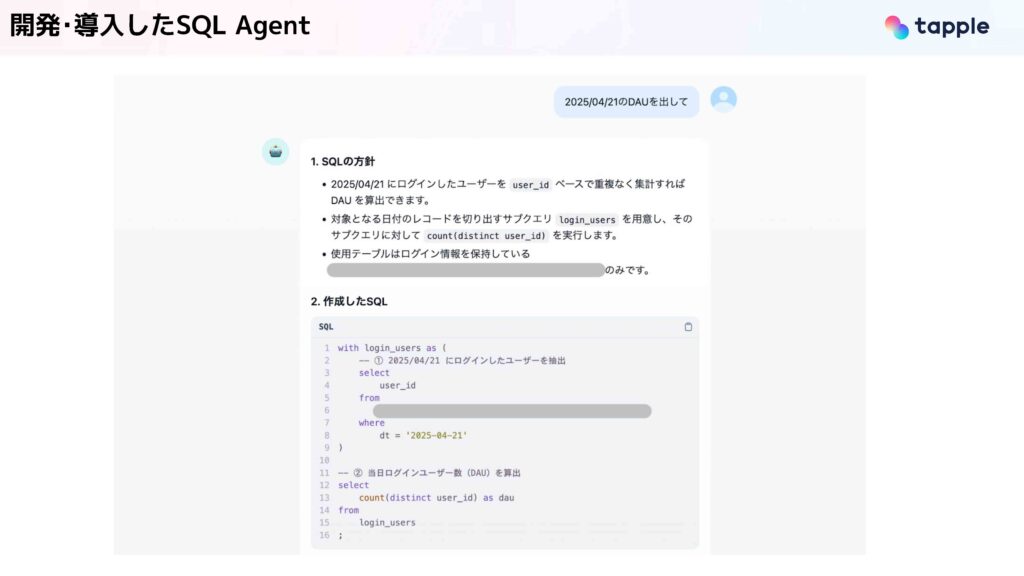
今回、開発・導入したSQL Agentの利用画面はこのようになっています。ユーザーが「2025/04/21のDAUを出して」のように指示をすると、SQLの構築方針と同時にSQLを出力してくれます。そして最終的には、このSQLを実行して実行結果を返却してくれます。
今回紹介したDAUのSQLは、そこまで複雑なクエリではないですが、もう少し複雑なものも扱えることが確認できています。

構築にはDifyのチャットフローを使っています。また、タップルで独自の用語だったり、ビジネス知識を渡しているので、細かく説明しなくても特有の単語を認識できます。
導入の際に意識して工夫したことは大きく分けて3つあります。
1つ目はアーキテクチャです。2つ目はメタデータ。最後はテーブルの選択とJOIN。この3つジャンルがあるので、1つずつ詳しく話していきたいと思います。
アーキテクチャ
1つ目がアーキテクチャです。

ここで意識したのは、最大構成で作るのではなくてシンプルな構成でまず始めるということです。これによって、素早く導入をして、本当にこのSQL Agentがビジネス上の効果、価値があるものかを知ること。そして、現状の課題を把握すること。これらの理解を深めることを最初に意識しました。
細かく説明していきます。まず、導入によって、理想的なフローを把握できると考えました。また、SQL Agentのニーズを把握できると考えました。これは、想定される質問を知ることも含みます。先ほどは、DAUを出す例を紹介しましたが、もしかしたらユーザーは既存のクエリを修正したいかもしれないですし、テーブルの定義やカラムの意味を質問をしたいかもしれません。これらの想定外の利用用途は導入するまではわからないので、まず使ってもらうことを意識しています。
また、品質向上のためにデータを集める目的もあります。
シンプルに作ることのデメリットとして、機能不足が発生する懸念がありますが、これはニーズに合わせて都度、既存研究や他社事例から必要なものを選択して、導入していけばよいと考えています。
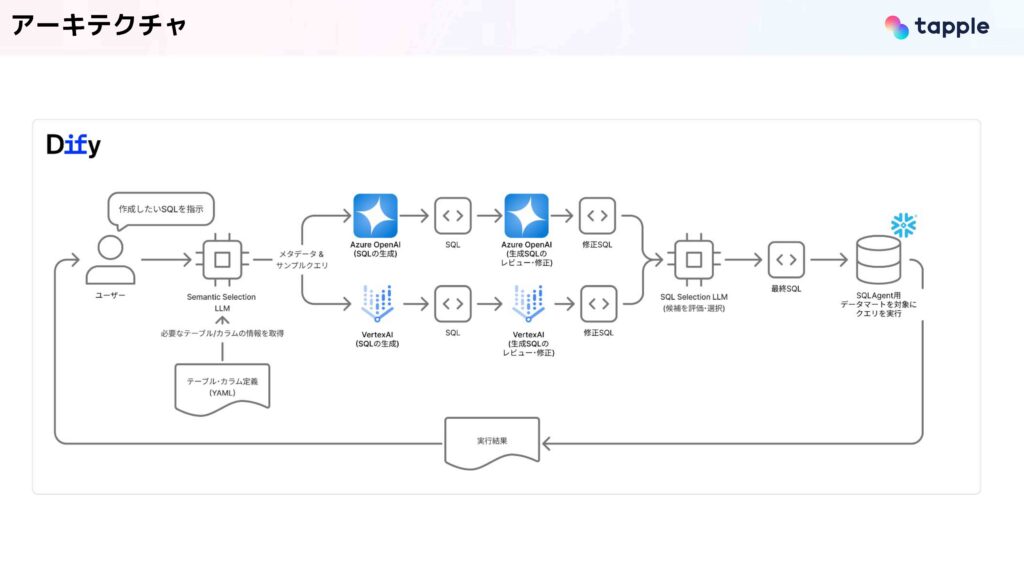
実際のアーキテクチャ構成はこのようになっており、次に重要なポイントを1つずつ話していこうと思います。

まず、Workflow Agentとして実装されており、先ほども話したようにDify上に構築しています。採用の理由はWebUIが付属することとローコードで作ることができるため、実装導入のスピードを上げられるからです。
また、LLMを使うところは、一つのLLMで全タスクをやらせるのではなくて、責務を分けるということを意識しています。大きく4つのLLMが動いており、一つ目は、必要なテーブルやカラム、サンプルクエリを選ぶモデルです。二つ目が、SQLの候補を生成するモデル。三つ目が、生成クエリをレビューして、それを修正するモデルです。四つ目が生成候補を比較して、最終結果を選択するモデルになっています。
 Workflow Agentは、事前定義されたロジックに基づいて、決定論的な動作をするようなものです。これは、右下に参考としてある、GoogleのADKというライブラリのドキュメントに基づく解釈です。一方で、LLM Agentは動的な推論と意思決定を自ら行うものになっています。
Workflow Agentは、事前定義されたロジックに基づいて、決定論的な動作をするようなものです。これは、右下に参考としてある、GoogleのADKというライブラリのドキュメントに基づく解釈です。一方で、LLM Agentは動的な推論と意思決定を自ら行うものになっています。

我々がWorkflow Agentを選択した理由は、まずシンプルなフローで最低限の生成を確実に実現する意図があります。これによって、今回SQL Agentを実現する上で、必要なツールと理想としている挙動の理解を深めることを目指しました。
これらがしっかり定義されていないと、動的な意思決定をLLM Agentにさせたとしても、最終的な評価が困難だと考えました。
また、今後、複雑な機能・処理を導入することになり、自律性が必要になれば、LLM Agentでも制御に移行していけばよいと考えています。
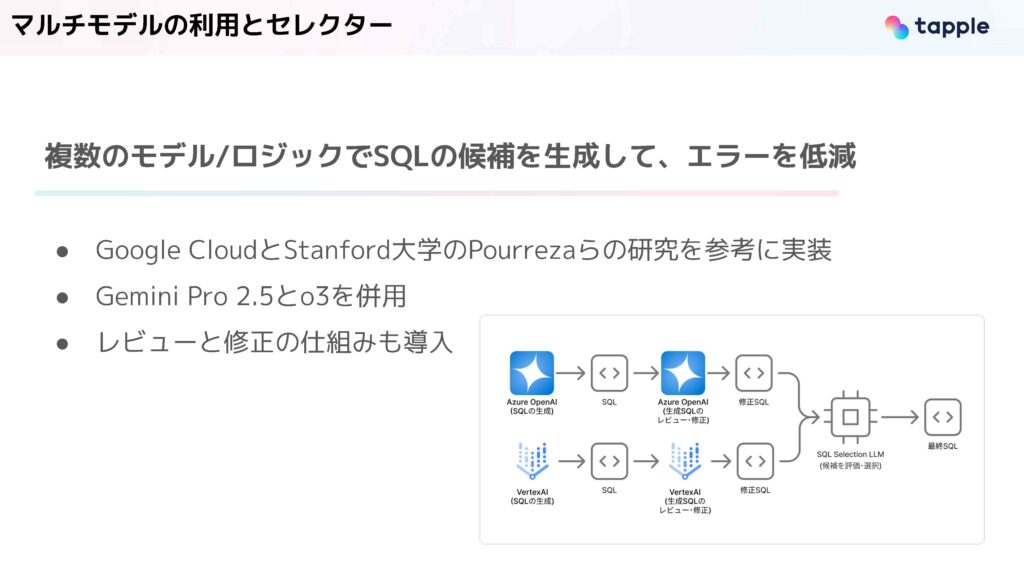
また特徴の一つとして、マルチモデルの利用とセレクターがあります。こちらは複数のモデルとロジックによってSQLの候補を生成し、エラーを軽減するアプローチです。これは冒頭に紹介しました、Google Cloudとスタンフォードの研究を参考に実装しています。
この図のように、まず、Azure OpenAIのAPIでSQLを生成します。これをレビュー・修正用のプロンプトを渡したLLMに入力して、修正SQLを作ります。この修正によって、構文エラーやテーブル参照の誤りを軽減しています。並行実行するもう一つのフローとして、Vertex AIのGemini APIを叩いてSQLを生成し、先ほどと同じく修正SQLを作ります。ここまでで、2つのSQLの候補ができるので、これらを評価・選択用のプロンプトを渡したLLMでどちらの方が品質が高いSQLなのか、我々の意図に沿ったものなのかを判断・選択させて、最終的な実行SQLを決定しています。
今回は、2つのモデルで同じSQL生成用のプロンプトを用いていますが、既存研究では、異なるクエリ構成戦略を表現したプロンプトを組み込んでいるので、今後、拡張していこうと考えています。
メタデータ
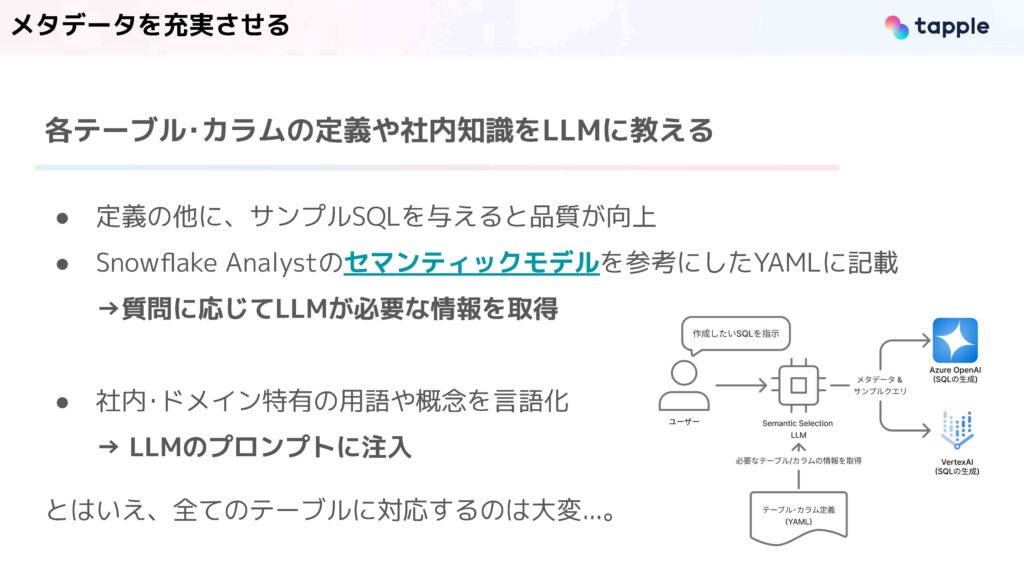 次にメタデータに関してです。メタデータはテーブルとカラムの定義だったり、社内の知識をLLMに教えるために非常に重要です。また、定義のほかにサンプルクエリを与えると品質が向上するとわかっており、我々はSnowflake Analystのセマンティックモデルを参考にして、YAMLに情報を記載しています。
次にメタデータに関してです。メタデータはテーブルとカラムの定義だったり、社内の知識をLLMに教えるために非常に重要です。また、定義のほかにサンプルクエリを与えると品質が向上するとわかっており、我々はSnowflake Analystのセマンティックモデルを参考にして、YAMLに情報を記載しています。
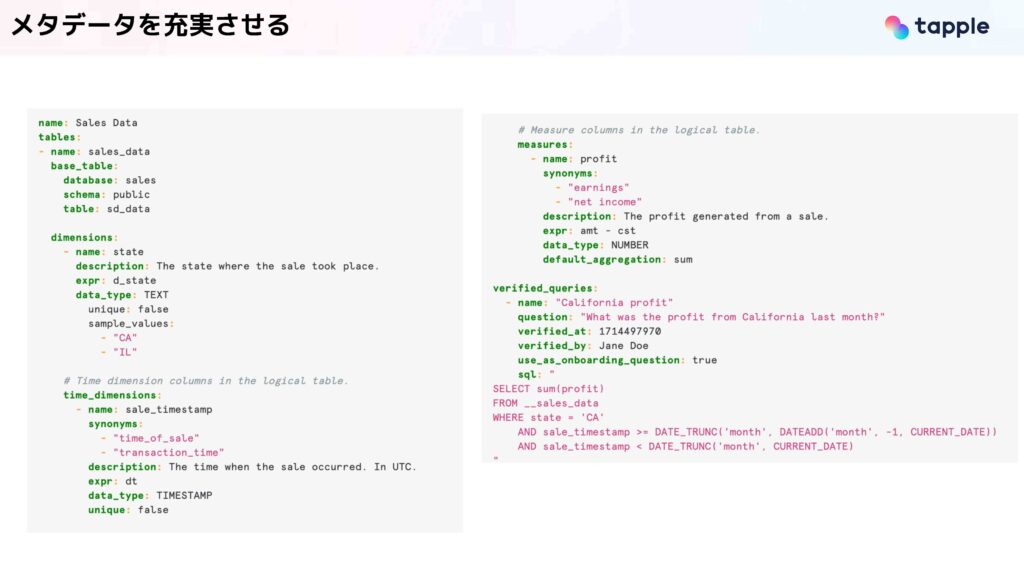
このようにして、各テーブル・カラムの説明とサンプルのクエリなどが書かれています。
一方で、社内独自の用語やドメイン特有の用語は、SQLを生成するLLMのプロンプトに直接注入をしています。
ただ、大量のテーブルを対象としたい時に、このYAMLに全ての定義を記載するのは非常に労力がかかります。そのため、対象とするテーブルにも工夫をしています。
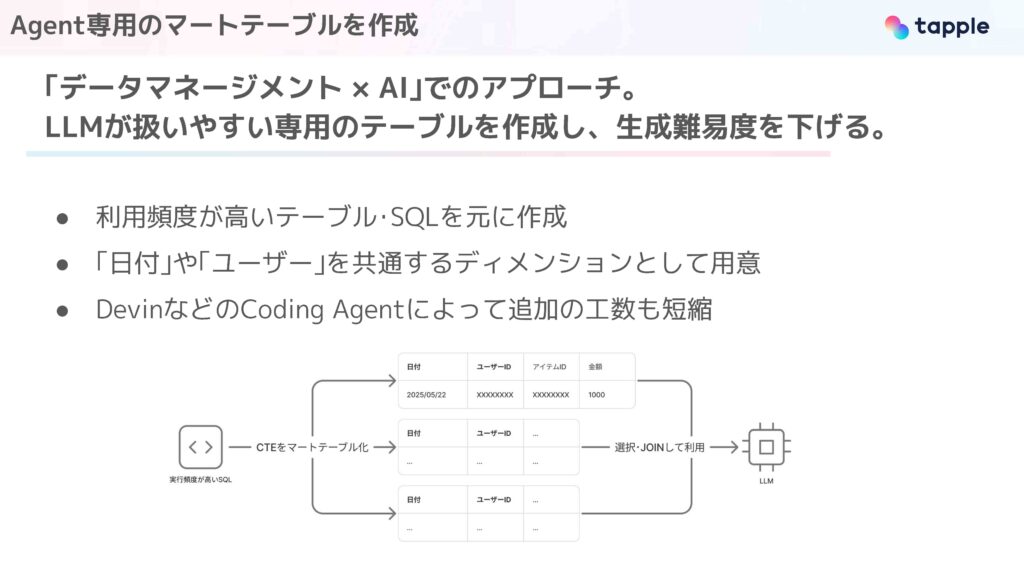
これはデータマネジメントとAI、この2つを掛け合わせたアプローチになっています。LLMが扱いやすい専用のテーブルを事前に作っておき、生成難易度を下げるようにしています。テーブルを絞っているので、先ほどのYAMLの記述量も最小限になります。
これら専用テーブルは、社内でのクエリの運用実績などから、利用頻度が高いSQLを元にして作成をしています。
イメージとしては、実行頻度が高いSQLがあったときに、これらのサブクエリをマートテーブルに落とし込んで事前に用意しておきます。Agentはこれらのテーブルを選択、JOINして使用します。
今後の展望
最後に今後の展望について話したいと思います。
今後は4つの軸で品質の向上を行っていきたいと考えています。1つ目はデータサイエンスの機能です。こちらは実行結果からシンプルな分析を行って、ユーザー側に結果だけではなくて、その数値から得られるインサイトを提案するような機能を考えています。

2つ目はSQLの品質向上です。今まで話したようなように、いくつかの工夫をしていますが、依然としてエラーの発生だったり、数字の誤りがあります。これを改善して、Agentの信頼性を上げていきたいと考えています。
3つ目は対象テーブルの拡充です。こちらは先ほど話したような専用のマートテーブルを拡充することになります。これは、DevinなどのCoding Agentの活用で、スピード感を持って充実させたいと考えています。
4つ目が評価についてです。収集している質問と生成されたSQL、実行結果、フィードバック、これらを元に継続的な評価を行って、品質の向上や信頼性を定量的に確認していきたいと考えています。
以上で発表を終わります。ご清聴ありがとうございました。