
CA DATA NIGHTは、サイバーエージェントが主催するデータサイエンスに特化した技術者向けの勉強会です。機械学習、統計学、自然言語処理、コンピュータビジョン、情報推薦、検索、経済学など様々な専門分野のエンジニアやデータサイエンティストから技術・取り組みなどを紹介いたします。
今回は、急速に進化する生成AI/大規模言語モデル(LLM)の活用が、それぞれの現場でどのように根づいてきているのかに着目。コンテンツ領域におけるABEMAでのLLMレコメンドの実験・検証結果、マッチングアプリ「タップル」での自然言語からSQLを生成する社内エージェントの導入フロー、そしてCodeAgentとMCPを活用した企業内LLM運用の事例など、異なる切り口からのデータ・AI実践事例を技術者自身がご紹介します。
本記事は、2025年05月22日に開催した「CA DATA NIGHT #6 〜活用から実務へ──生成AI・LLMの“業務の入り口”を探る〜」において発表された「CodeAgentとMCPで実現するデータ分析エージェント」に対して、社内の生成AI議事録ツール「コエログ」を活用して書き起こし、登壇者本人が監修役として加筆修正しました。
村脇 光洋(AI事業本部/AI POSカンパニー/エンジニア)
2024年入社後、バックエンドエンジニアとしてAI事業本部のアプリ運用カンパニーに配属。その後、新規事業であるAI POSの開発チームに参画し、LLMを用いたデータエンジニアリングの半自動化や、データアナリシスエージェントの開発に従事している。
それではコードエージェントとMCPで実現するデータ分析エージェントというタイトルで、村脇の方から発表させていただきます。

最初に軽く自己紹介させていただきます。現在、サイバーエージェントのAI事業本部のAI POSカンパニーという部署で、今年の1月から正式に移動となり、バックエンドのエンジニアとして業務をやらせてもらっています。業務内容としては、POSということで小売業や小売業に対して商品を出しているメーカーさんに対してデータの分析を提供するSaaSの開発をしています。

今日の発表は3パートに分けて話せればと思っています。まずプロダクトの紹介という形で、現在取り組んでいるプロダクトの文脈を共有させていただき、そこから事例の紹介とより技術について深く話していければと思います。
プロダクトの紹介「AI POS」
まず、私たちが開発しているAIPOSというプロダクトについて軽くお話しします。
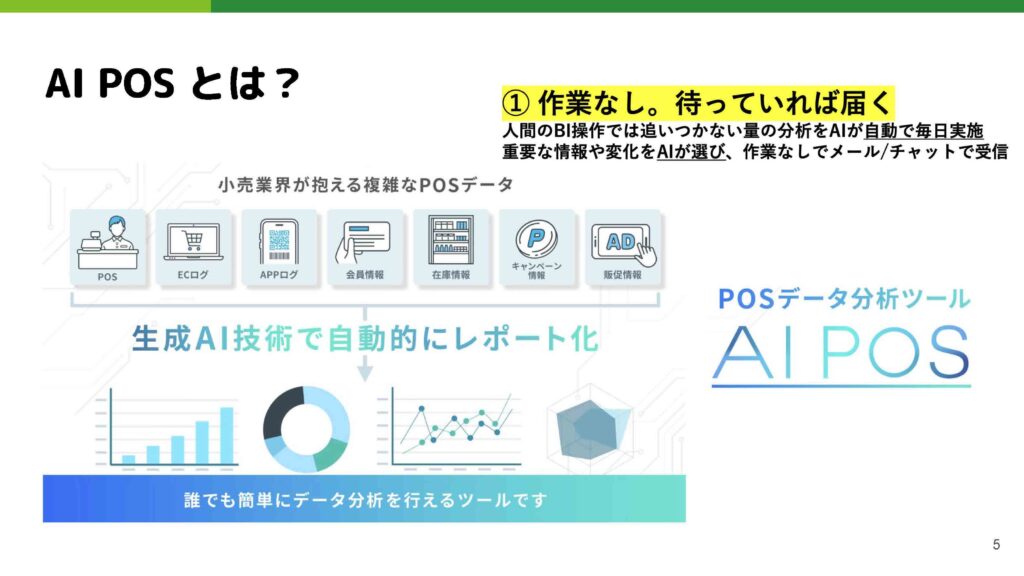
POSとは、データ領域に関わっている方であれば聞きなじみがあるかもしれませんが、基本的にコンビニやスーパーなどの小売業の決済データ、つまりレジで誰がいつどういうタイミングでどういう商品を買ったかという購買データのことです。AIPOSというプロダクトでは、そのPOSを筆頭としながら小売さんが提供しているECやアプリケーション、会員情報などをデータソースとして取り込み、それを分析するプロダクトになっています。

ユースケースとしては、チャットのようなUIで売上の推移などを深掘りしたり、メールレポートという形で、店長さんやメーカーの広報担当の方など様々なユーザーに最適な情報を届けたりしています。
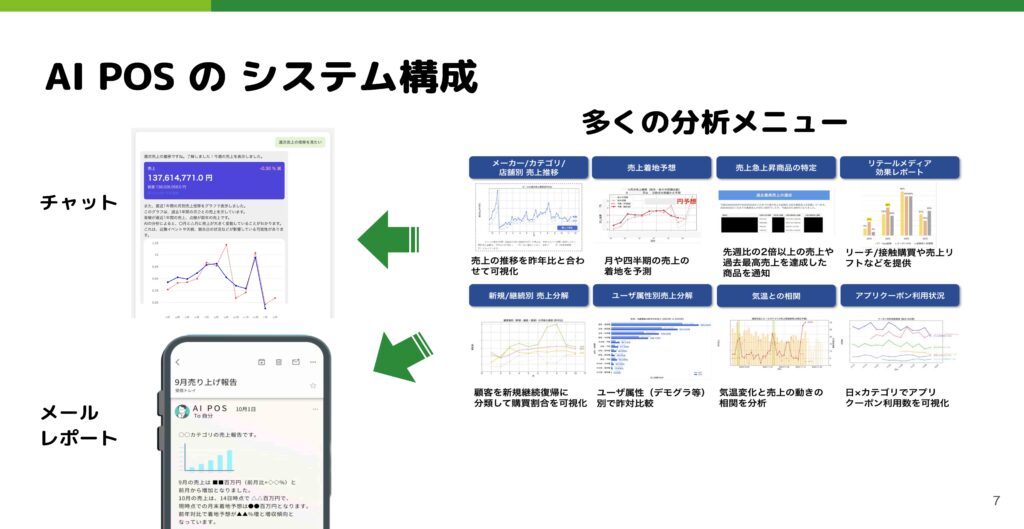
開発側の話になりますが、このチャットとメールの裏側では、共通して分析メニューという形で共通のサービスやシステムが動いています。ここでいろんな分析メニューを開発し、それをチャットやメールで適切なタイミングで出し分けるという大まかな構成になっています。

例えばチャットでユーザーさんが何かを質問した時に、直接LLMを使って分析をその場で返すということはこのプロダクトではしていません。売上の情報などはデータの正確性が求められるため、基本的に分析メニューは事前に開発者が品質担保したものを出しており、直接LLMで作り上げることはしていません。
それゆえに、この分析メニューの開発がサービスのメインコンテンツであり、一番のコアの価値になっています。ここを開発することは重要なポイントで、この開発の部分をLLMエージェントで高速化しようというアプローチを取っています。
分析コンテンツの開発速度を向上させるLLM活用
実際にどういうポイントでLLMを使っているのかについてお話しします。分析メニューを作る際には、大体3ステップで進めています。

- 分析エージェントを使って分析メニューのプロトタイプを作成
- Cursorを使って、設計パターンやプロダクトコードの構成を事前に定義し、プロトタイプの中途生成物を使ってプロダクションコードを作成
- 人間がチェックや修正を行い品質を担保
今日は1番目の分析エージェントの部分についてお話しします。

現在、チームで使用しているUIをお見せしながら、どのように活用しているかをご説明します。UIとしては非常に簡単なものになっており、エージェントのプロファイルを用意して、エージェントに事前に与えるプロンプトやツールをプリセット化しておき、チームで使い分けられるようにしています。
ツール群については後ほど詳しくお話ししますが、MCPなどでエージェント専用のツールも作っており、利用ケースに適したものを選択できるようにしています。「分析定義入力」の部分で実際に行いたい分析について記述して使用します。例えば、酒のカテゴリーの1週間の平均売価を前年比で可視化してほしいというようなプロンプトを入力します。

このエージェントはマルチステップで動作します。最初に、「酒カテゴリー」のように人間が入力した言葉が、システム内ではどのようなカテゴリーに対応しているのかを判断するため、まずカテゴリー一覧を取得して該当するカテゴリー情報を特定します。この時点では、内部的に保持しているカテゴリーIDや名称などを絞り込む処理が行われています。

その後、得られたカテゴリー情報をもとに、必要なデータを抽出するためのSQL文を作成します。画面では、左側に現在実行されているSQL文が表示され、右側にはそのSQLを実際に実行した結果として得られたテーブル形式の出力結果が並んでいます。これらの一連の流れを通じて、最初にカテゴリー認識と情報取得を行い、その後にSQLの生成・実行と結果の表示を行う、という手順で処理が進んでいきます。
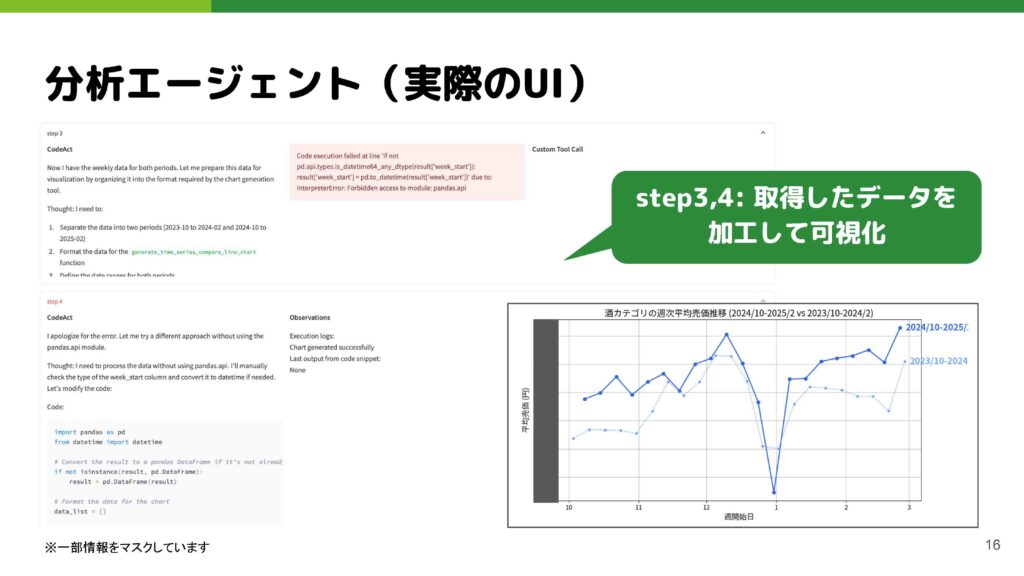
取得したデータをもとに、次は可視化のフェーズに移ります。エージェントは内部的にPythonのコードを自動生成して可視化を行います。なお、先ほどステップ3で記述ミスがありましたが、ステップ4ではそのミスがどこで発生したのかを判定し、分析を行うという流れになっています。

この導入効果としては、分析メニューの開発工数が導入前と比べて3分の1以下に圧縮できています。もちろん分析メニュー一つ一つの工数や内容は異なるため、定量的な意味合いは難しいですが、1週間で1人が処理できる開発工数を計測した結果です。
もう一つの利点は、開発前に最終アウトプットをエージェントに出させてみることで、分析メニューの方向性について議論できることです。分析のアイデアだけでは実際のデータを見ないと良し悪しが判断しづらいので、この点が良かったと思います。また、PMなど開発に直接関わっていないメンバーでも簡単に使えるという点も良かったと考えています。
分析エージェントの構成
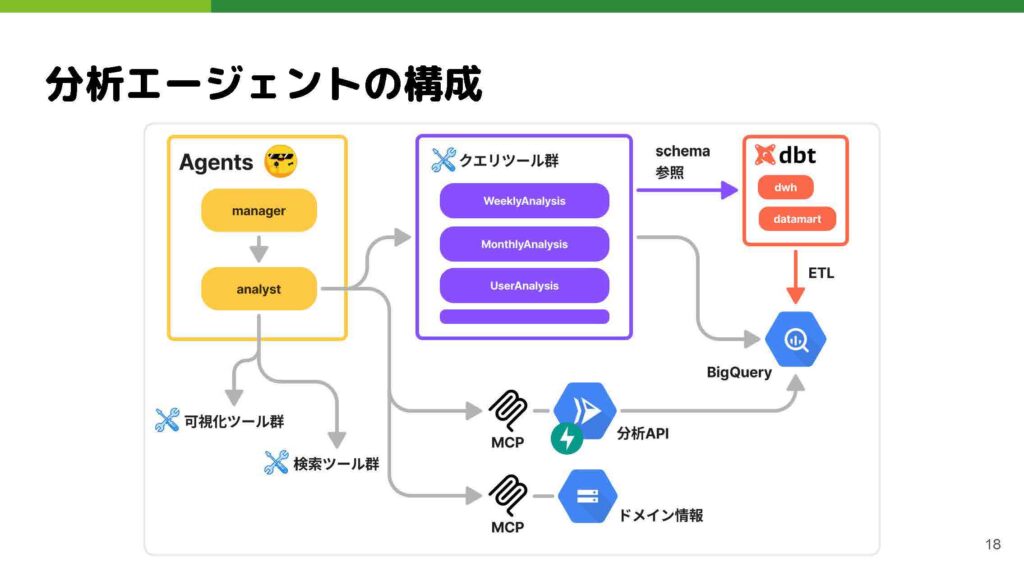
内部的なアーキテクチャについてお話しします。エージェントの部分はいわゆるマルチエージェントの構成を取っています。プロファイルで切り替えられるようになっているので、固定のエージェント群ではなくタスクによって変えています。
様々なツール群があり、分析APIやカテゴリ情報などのドメイン情報はMCPを使って接続しています。クエリツール群が特に重要で、SQLを実行する際に使用します。テーブル数が増えていくと、エージェントがユースケースに合わせて適切なテーブルを選択できるよう、用途に合わせたツールでテーブルを絞り、複数のツールに分解しています。
テーブルの情報については、スキーマ情報を参照するにあたってdbtというデータパイプラインツールを使って、事前にメタデータを各テーブルやカラムに注入しています。これにより、現在使用しているテーブル群の正確なスキーマ情報を使ってクエリを書くことができます。

この黄色いアイコンは、Hugging Face社が開発している「スモールエージェント」というエージェントフレームワークを示しています。私たちのチームでもこのフレームワークを利用しています。特徴としては、まず動作原理に「コードワーク」という仕組みを採用している点が挙げられます。発表タイトルにある「コードエージェント」も、このコードワークを活用したエージェントとして、スモールエージェント内で定義されています。
もうひとつの特徴は、最小限の機能であるためワークフローを組む仕組みが含まれていないことです。LangGraphやMastra、OpenAIのSDKなど、多くのフレームワークではワークフロー構築機能が備わっていますが、スモールエージェントではあえてその機能を省いています。
その他の機能については、他のフレームワークでも対応しているものが多いです。例えば、MCPに対応していることや、OpenTelemetryに準拠した監視が可能なこと、そしてLLMの切り替えが容易にできるといった基本的な機能が備わっています。
 Code Actについてお話しします。私が考えるスモールエージェントの最大の利点は、ツール同士を非常に簡単につなぎ込める点です。例えば、初期のころにOpenAIが提供していたファンクションコーリング機能と比べると、その違いは明確に感じられます。ファンクションコーリングではツールのインターフェースとしてJSONを使い、データの受け渡しにもJSON形式でやり取りするため、どうしても制約が多くなってしまいます。その結果、一つのツールを実行した後の出力結果を次のツールにそのまま引き渡したい場合に、形式の不一致などでうまくつながらず、処理が欠損してしまうことがあります。
Code Actについてお話しします。私が考えるスモールエージェントの最大の利点は、ツール同士を非常に簡単につなぎ込める点です。例えば、初期のころにOpenAIが提供していたファンクションコーリング機能と比べると、その違いは明確に感じられます。ファンクションコーリングではツールのインターフェースとしてJSONを使い、データの受け渡しにもJSON形式でやり取りするため、どうしても制約が多くなってしまいます。その結果、一つのツールを実行した後の出力結果を次のツールにそのまま引き渡したい場合に、形式の不一致などでうまくつながらず、処理が欠損してしまうことがあります。
また、先ほどの例でご覧いただいたように、データを可視化する際には一度形式を変換しなければならず、その変換が適切でないと期待どおりのグラフや表が得られません。その点、Code ActではJSONを介したやり取りを行わず、LLM(大規模言語モデル)に直接Pythonコードを記述させ、思考結果のアクションをコードとして表現させるアプローチを取っています。これにより、Pythonの柔軟な技術やライブラリをそのまま活用できるため、ツールごとの形式変換などの手間を大幅に削減し、スムーズにワークフローを構築できるようになっています。
先ほどの分析例をもとに説明します。先ほどのSQL実行結果を、一番下にある「result」という変数に格納します。resultはPandasのDataFrameです。
そしてステップ4では、この“result”を活用します。画面では小さくて見えにくい部分もあるかもしれませんが、“result”がPandasのデータフレームとして取得できるという利点を生かし、Python上でPandasの機能を使ってデータを加工し、その加工結果を可視化関数に渡す、という流れになります。LLMはPandasを使ったデータ加工を得意としているため、データ変換をLLM内部で暗黙的に行い、別のツールへ受け渡すのではなく、Pythonコードとして変換方法を明示させたほうが精度が高くなる、という元論文の主張をそのまま活かしたアプローチになっています。

LLM領域の技術選定
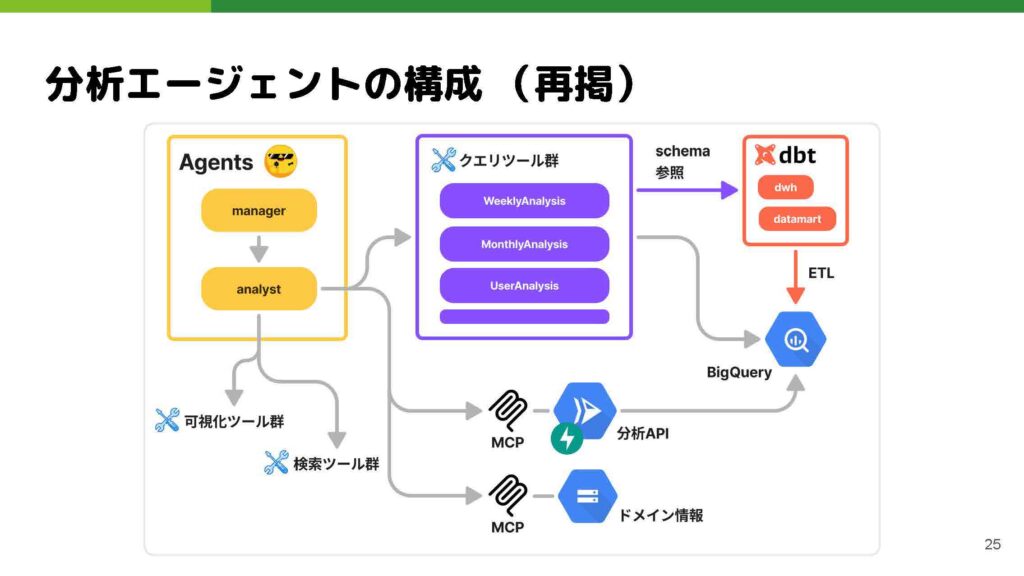
ではここから若干この話を抽象化というか一般化しながら、今回このようなツールを作るにあたって、技術選定としてどのような点を考えて選んだかを最後にお話しできればと思っています。

この先ほどの図についてなのですが、ご覧になっていくつか疑問を持たれた方もいらっしゃるかもしれません。たとえば、「そもそもこのツール定義はMCPを使わなくても実現できるのではないか」とか、先ほどスモールエージェントのところで軽く触れましたが「ワークフローを組めるようなフレームワークが多数存在しているにもかかわらず、なぜあえてワークフローを組めないフレームワークを選んでいるのか」といった点です。

これに対して、私たちのチームで考えているのは、ひとつにLLM(大規模言語モデル)関連領域の技術進歩が非常に速いという背景があります。

ご存知のとおり、モデル自体はすぐに更新されますし、エージェントやワークフローツールも次々と乱立している状況です。先ほど具体名を挙げただけでも複数ありますし、それ以外にも多くの選択肢が出てきていると感じています。また、MCP自体も最近注目を浴びていますが、そのほかにもLLM に対してドメスティックな情報やツールを与えて活用する手法が多く登場していると考えています。
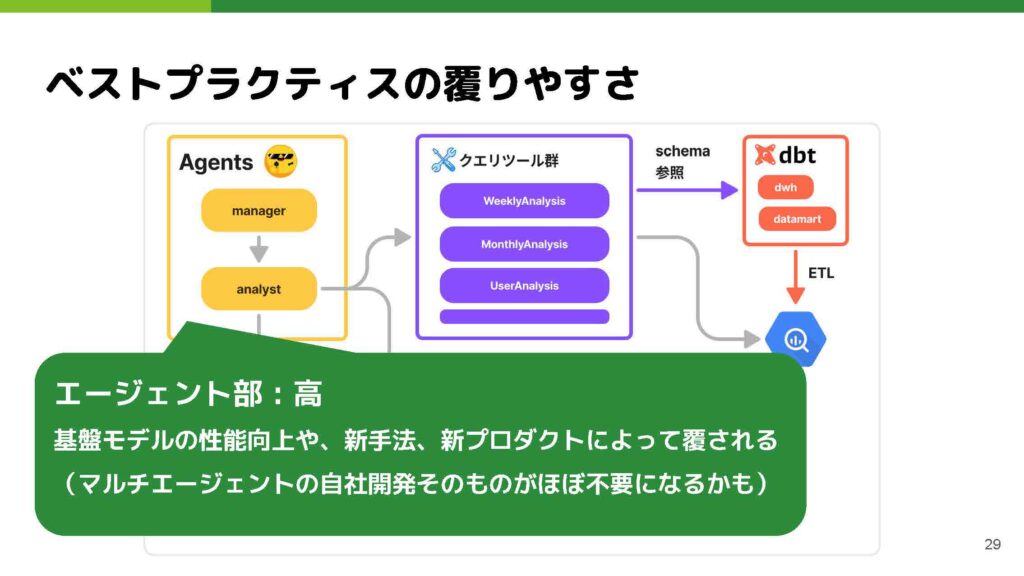
こうした状況下では、各領域のベストプラクティスがあっという間に覆ってしまう可能性が高いという意識がありました。
なかでも、エージェント部分はとくに変化が激しく、すぐに陳腐化してしまうリスクが大きいと考えています。たとえば、基盤モデルが性能を飛躍的に向上させた結果、かつては非常に複雑で最適化されたエージェントワークフローを構築していたとしても、最新モデルでは「そんなに複雑な処理をしなくても、一発で渡したほうが早く結果が出る」といった状況になることが起こりえます。
実際に、昨年私はLangGraphを使って似たようなツールを試作した経験がありましたが、基盤モデルの性能向上によってすぐにその前提が覆り、陳腐化したという感覚を持ちました。
また、Claude Desktop のようにエージェンティックな動作を標準で備えたアプリケーションや、基盤モデルを提供する企業からエージェント機能付きアプリケーションが続々リリースされる現状を考えると、自社でエージェント部分をゼロから開発することは、技術的負債になりかねないと判断しました。
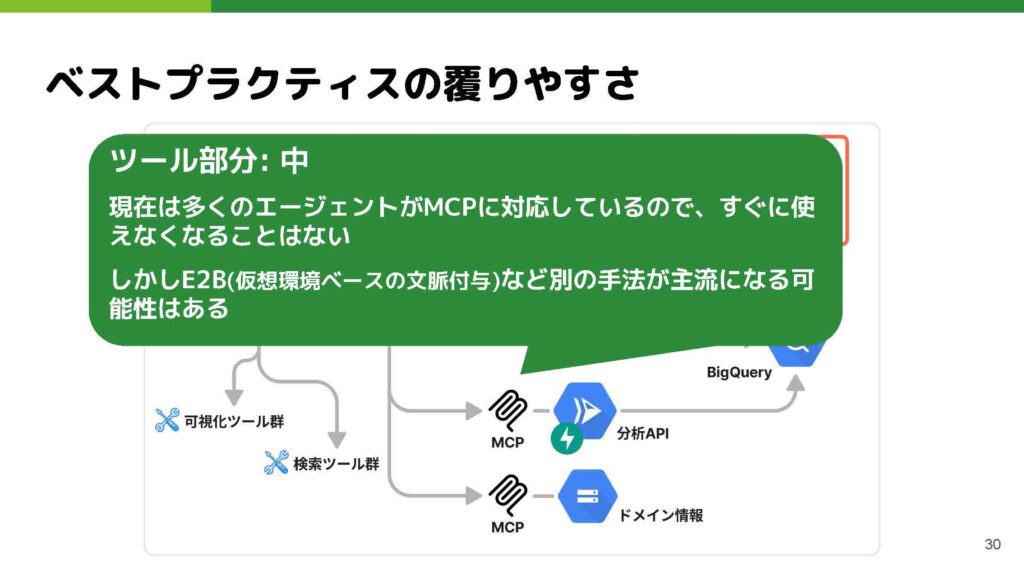 一方で、ツール部分の構築はエージェント部分と比べると覆りにくいと考えています。たとえば、分析API やドメイン情報をMCPで接続し、CursorやClaude Desktopなど各種エージェントを切り替えて自分たちのツール群を試す実験を容易に行える体制が整っていれば、エージェント部分を自由に乗り換えても対応しやすいでしょう。現在、多くのフレームワークやアプリケーションがMCPに対応しているため、急にまったく別の仕組みに乗り換えるようなことは起こりにくいと思います。ただし、最近では「仮想環境をLLMに渡し、その中であれば何をしてもよい」という形で、ツールを一括して渡す手法も登場しており、そちらが主流になる可能性もあると考えています。
一方で、ツール部分の構築はエージェント部分と比べると覆りにくいと考えています。たとえば、分析API やドメイン情報をMCPで接続し、CursorやClaude Desktopなど各種エージェントを切り替えて自分たちのツール群を試す実験を容易に行える体制が整っていれば、エージェント部分を自由に乗り換えても対応しやすいでしょう。現在、多くのフレームワークやアプリケーションがMCPに対応しているため、急にまったく別の仕組みに乗り換えるようなことは起こりにくいと思います。ただし、最近では「仮想環境をLLMに渡し、その中であれば何をしてもよい」という形で、ツールを一括して渡す手法も登場しており、そちらが主流になる可能性もあると考えています。
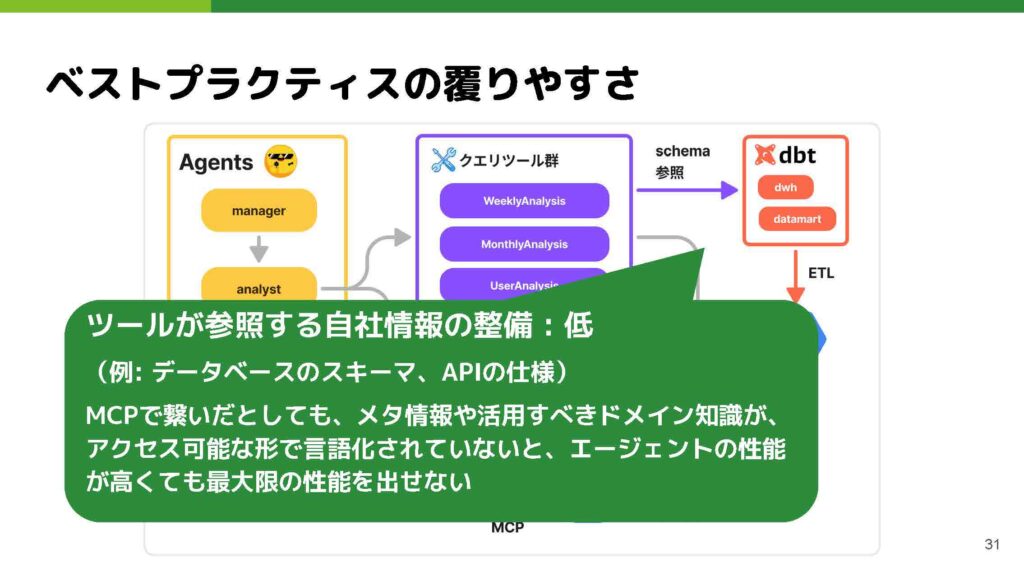
最後に、データマートやメタ情報の整備はもっとも覆りにくい部分だと考えています。現在、dbtなどを使ってデータマートを定義し、メタ情報を埋め込んでおくことで、たとえエージェントやツールの技術選定が変わったとしても、この領域を自社で整備しておかない限り、最新技術を最大限に活用できないのではないかと判断しています。

つまり、投資しなくても進歩していく領域、自社で投資しないと恩恵を受けられない領域と、その中間の3つに分け、それぞれに注力する技術領域をチーム内で分類しました。なるべく選択肢が変化しづらく、かつ自分たちが投資しなければ進化しない領域にリソースを集中する、というスタンスです。
まとめ

最後にまとめです。まず、SmallAgents という Code Act 論文ベースのエージェントを活用することで、特にデータ加工タスクを含むケースでは多くの利点があることを紹介しました。
次に、技術選定としては、メタデータ整備やそれをMCPや各種アプリケーションに接続する準備を優先すべきである、という方針を示しました。もちろんプロダクトやチームのフェーズによって最適解は変わると思いますが、私たちのチームではこのような形で技術選定を行いました。
以上で発表を終了します。ありがとうございました。