
目次
- はじめに
- 背景
- Bandit / Contextual Bandit アルゴリズムとは?
- レコメンドシステムの設計
- 報酬計算とユーザーセグメント
- おわりに
- 出典
はじめに
こんにちは、執筆を後回しにしすぎて新卒2年目になってしまった株式会社 AbemaTV Product Growth Backend チームの @reimei_dev です。普段は ABEMA のレコメンドシステムや新機能の開発などを行っています。
先日 Contextual Bandit アルゴリズム を用いたレコメンドシステムの開発に携わり、このシステムの導入により、ホームおよびジャンルページにおけるユーザーの試聴時間を一定量改善することに成功しました。
今回は、バックエンドエンジニアとしてシステム全体の設計から携わったこの取り組みについてご紹介します。
背景
ABEMA では、モジュール内のコンテンツの並び順を最適化するために、従来より Bandit アルゴリズムを利用していました。しかし、既存のシステムには以下のようないくつかの課題が存在していました。
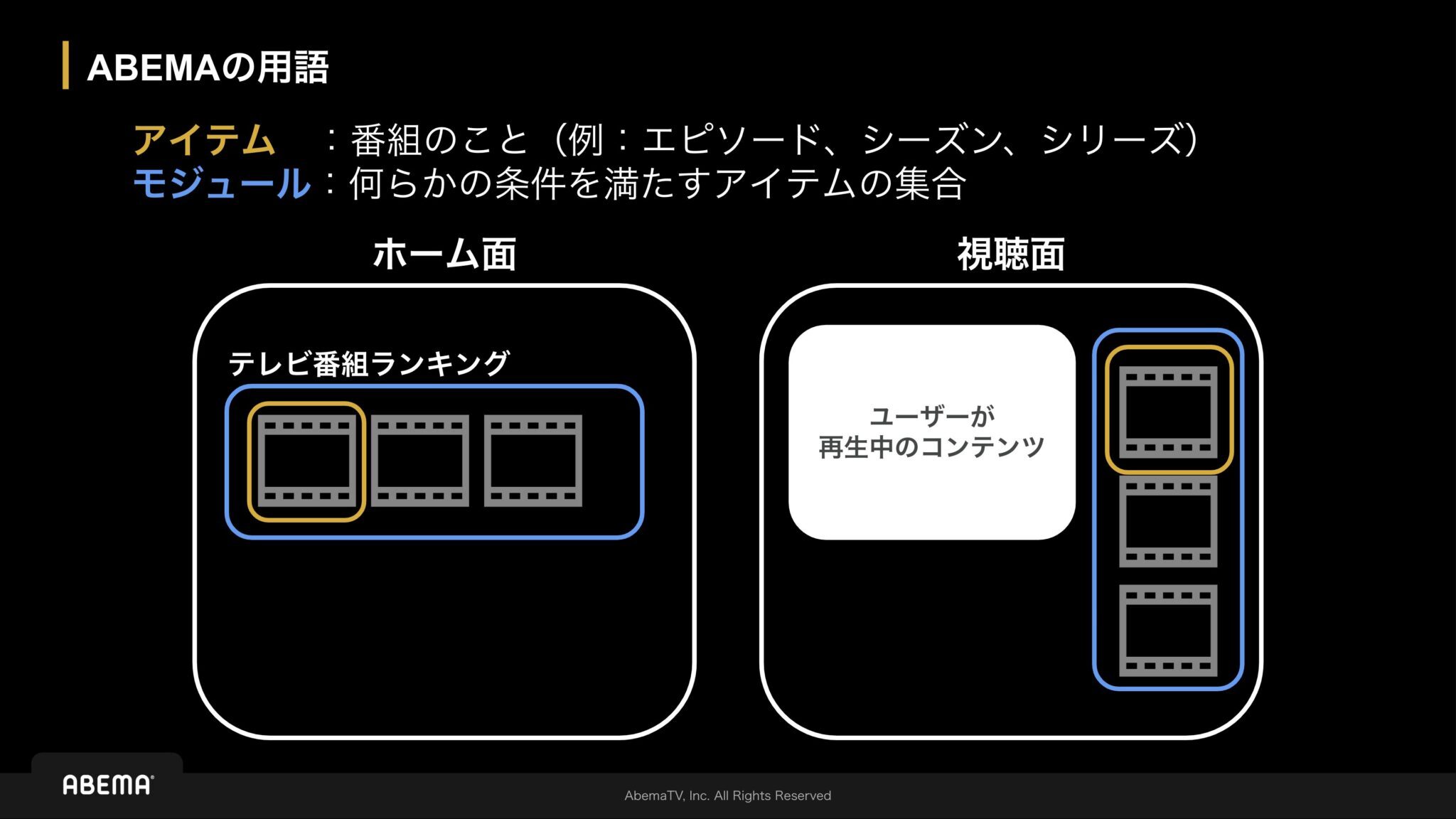
(ABEMA 独自の用語については以下の 「ABEMA の用語」に関する画像を参照してください)
- 報酬集計の課題: 本来異なるモジュール同士に表示された同一アイテムのアクションに対する報酬は別々に反映させる必要があります。ただ、既存のシステムでは異なるモジュールに表示された同一アイテムに対するアクションを同じものとして報酬に反映されてしまっていました。つまり、本来モジュール内の結果を元に良いコンテンツをレコメンドすべきところ ABEMA 全体の中で良いコンテンツがレコメンドされるようになっていました。
- ユーザー属性の表現力: 以前は「40代男性ドラマ好き」といった属性の組み合わせでユーザーを表現していましたが、「ドラマもアニメも好き」といったように、ジャンルなど一つの属性内で複数の好みを持つ場合には柔軟に対応できていませんでした。その結果、多様な興味を持つユーザーへの最適な推薦が難しい状況でした。また、属性が一部重なる「40代男性ドラマ好き」と「40代男性アニメ好き」も別々のセグメントとして学習していたため、データの効率的な利用ができていませんでした。
- 手動ターゲティング: どのユーザーセグメントにレコメンドするかというターゲティング設定を手動で行っていたため、運用に手間がかかっていました。
これらの課題を解決するため、本プロジェクトでは Contextual Bandit アルゴリズム を採用し、より高度なパーソナライズと効率的な学習を目指したレコメンドシステムの構築を行いました。また、このレコメンドシステムの推薦精度を担保しつつ高負荷なトラフィックを捌くことができる設計にしており、これを実現しました。
Bandit / Contextual Bandit アルゴリズムとは?
Bandit アルゴリズム(Multi-Armed Bandit)
Bandit アルゴリズム(Multi-Armed Bandit)は、複数の選択肢の中から、どれを選ぶと最も高い報酬が得られるかを学習しながら探索していく手法です。限られた試行回数の中で、過去の経験から最適な選択肢を活用(Exploitation)しつつ、より良い選択肢が存在する可能性も考慮して新しい選択肢を試す(Exploration)という、「探索と活用」のバランスを取りながら学習を進めます。
また、このアルゴリズムはウェブ広告の表示選択やECサイトのレコメンドエンジンなどに幅広く活用されています。
Contextual Bandit アルゴリズム
Contextual Bandit アルゴリズム は、Bandit アルゴリズムを拡張して「文脈(コンテキスト)」を扱えるようにしたものです [1][2]。 ユーザーの年齢、性別などのユーザー属性(ユーザーコンテキスト) を考慮することで、「特定のコンテキスト下ではどの選択肢が最適か」を学習します。単純な Bandit アルゴリズムでは、誰に対しても同じ選択肢を提示する可能性があるのに対し、Contextual Bandit アルゴリズムでは、ユーザーの状況に応じて推薦内容をパーソナライズすることが可能になります。
一方で Contextual Bandit アルゴリズムを採用すると既存システムよりも特徴量が多くなり今までよりも計算コストが増加してしまうというデメリットがあります。
また、本プロジェクトで Contextual Bandit アルゴリズムを採用した理由は前述したパーソナライズによる推薦精度の向上というメリットを享受できる点にあります。ABEMA では、ユーザーの属性を考慮して各番組が好きそうかのスコア付けを行い、そのスコアに基づいて推薦する順番を決定します。また推薦結果に対するユーザーの反応(視聴、クリックなど)はフィードバックとしてシステムに反映され、継続的にモデルが改善されます。
一方計算コストが増加するというデメリットについては事前の検証によって有効な特徴量を把握できており、ABEMA へ導入しても十分なパフォーマンスを維持できる見込みが立っていたため、このアルゴリズムを採用しました。
レコメンドシステムの設計
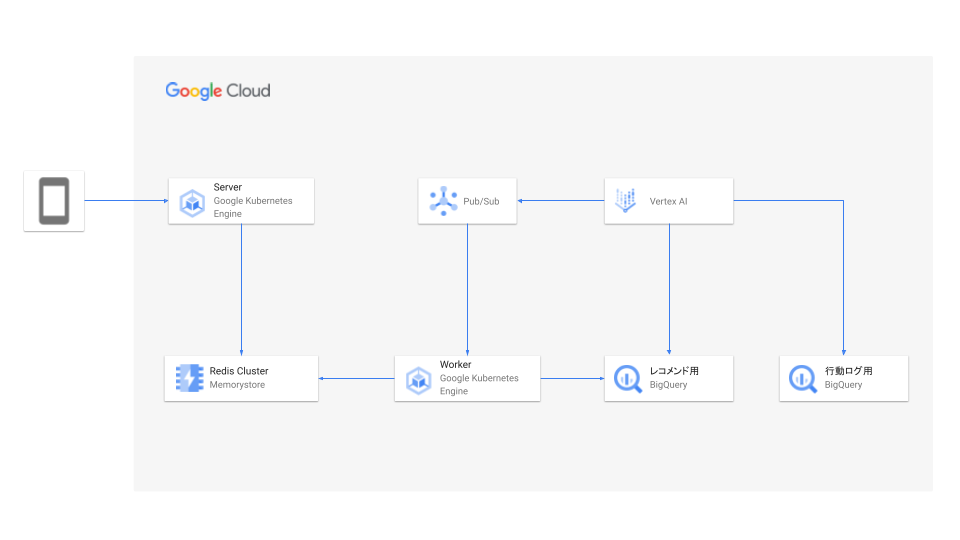
前述の課題を解決し、Contextual Bandit アルゴリズムを効果的に機能させるために、以下のようなシステムを設計・実装しました。本システムは Pub/Sub と Memorystore for Redis Cluster (以後 Redis Cluster) を境界として、大きく三つのコンポーネントに分かれています。
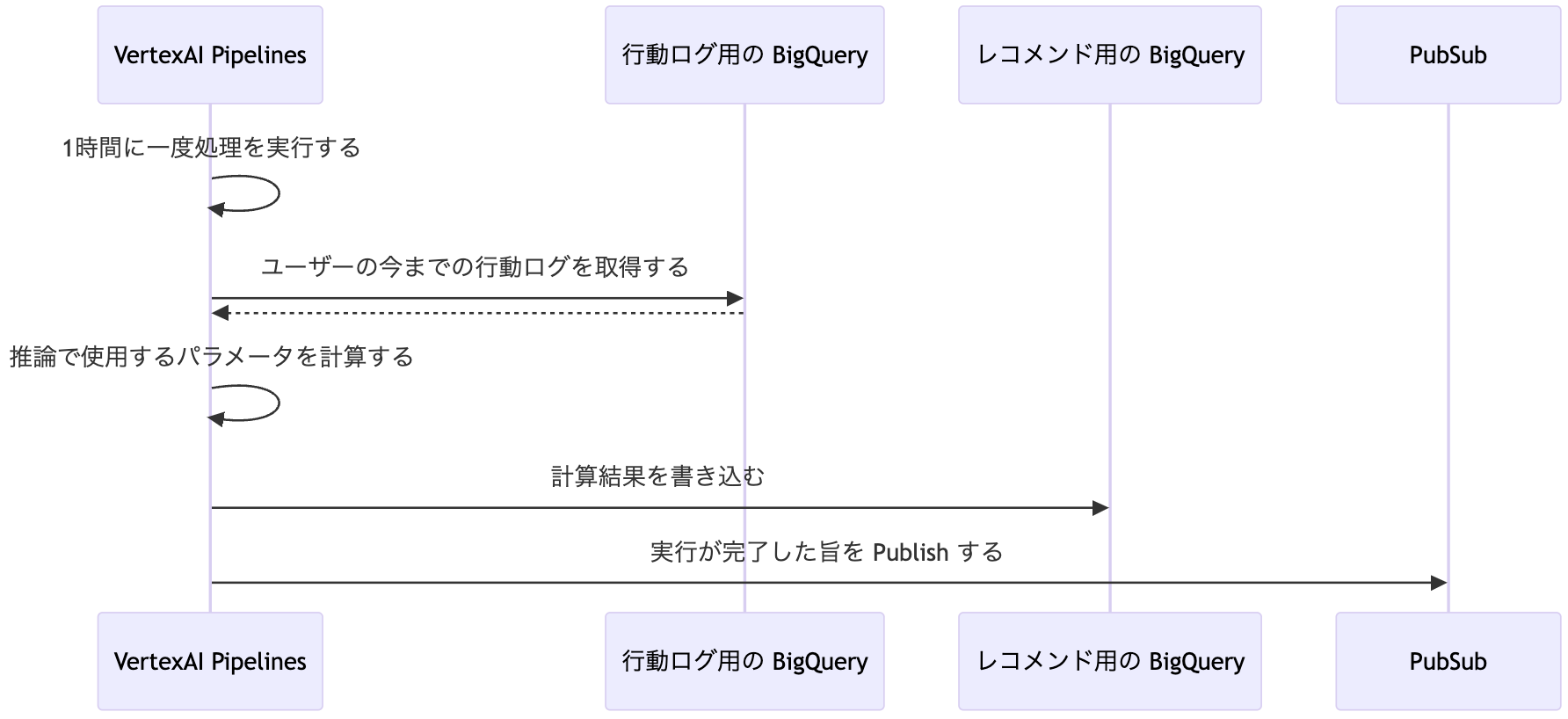
モデル学習
モデル学習については、Vertex AI Pipelines を起点として実行されます。報酬データに基づいて Contextual Bandit モデルのパラメータが計算され、レコメンド用の BigQuery テーブルに書き込まれます。
また、詳細な処理フローや機械学習モデルに関する説明は、機械学習編の記事で解説される予定です。
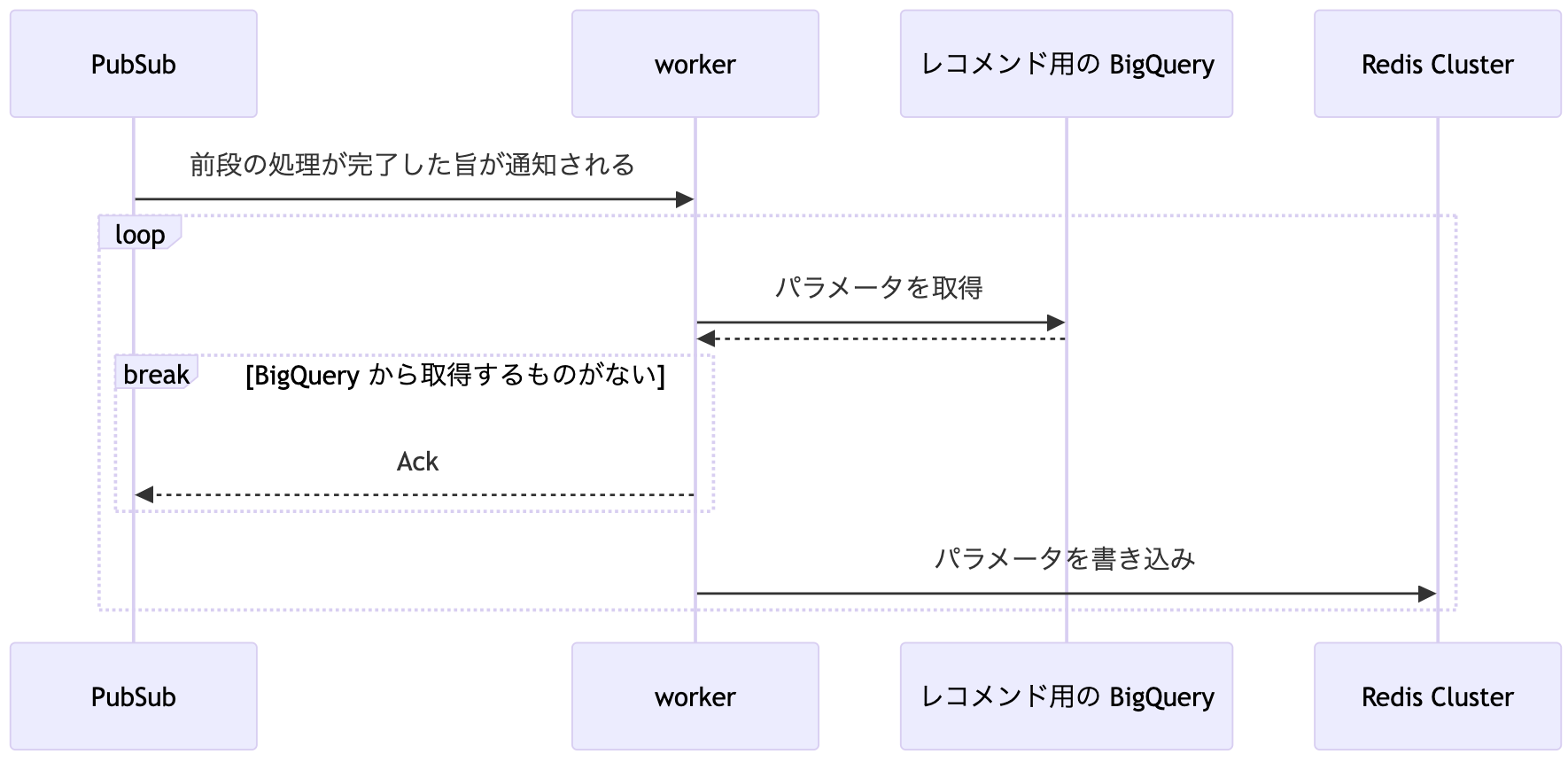
Redis Cluster への書き込み
BigQuery に格納されたレコメンド用のパラメータを高速に参照することを可能にする Google Cloud の Redis Cluster へ転送する処理を行います。
また、Redis Cluster を採用した主な理由は以下の通りです。
- 高いパフォーマンス: 大量のリクエストを処理するために、インメモリキャッシュによる高速なデータアクセスが不可欠であるため
- 高可用性(HA): HA 構成によりシステム全体の可用性を高めるため
- 安全なスケール: Redis インスタンスの Ring Hash と比較して、より安全にシステムをスケールアウトできるため
余談ですが、通常 BigQuery からデータを取得する際は、イテレーターを使用することで内部的にページネーション処理が自動で実行されます。ただし、この機能を使用する際コードの責務分離を考慮すると、BigQuery に関する処理側で全件を一度に取得する必要が出てくる場合があります。今回参照するテーブルのデータ数はかなり多いかつ今後も増えていく可能性があるため自作のページネーションツールを作成してコードの責務分離も担保しつつ一定数のデータのみを取得できるようにしています。
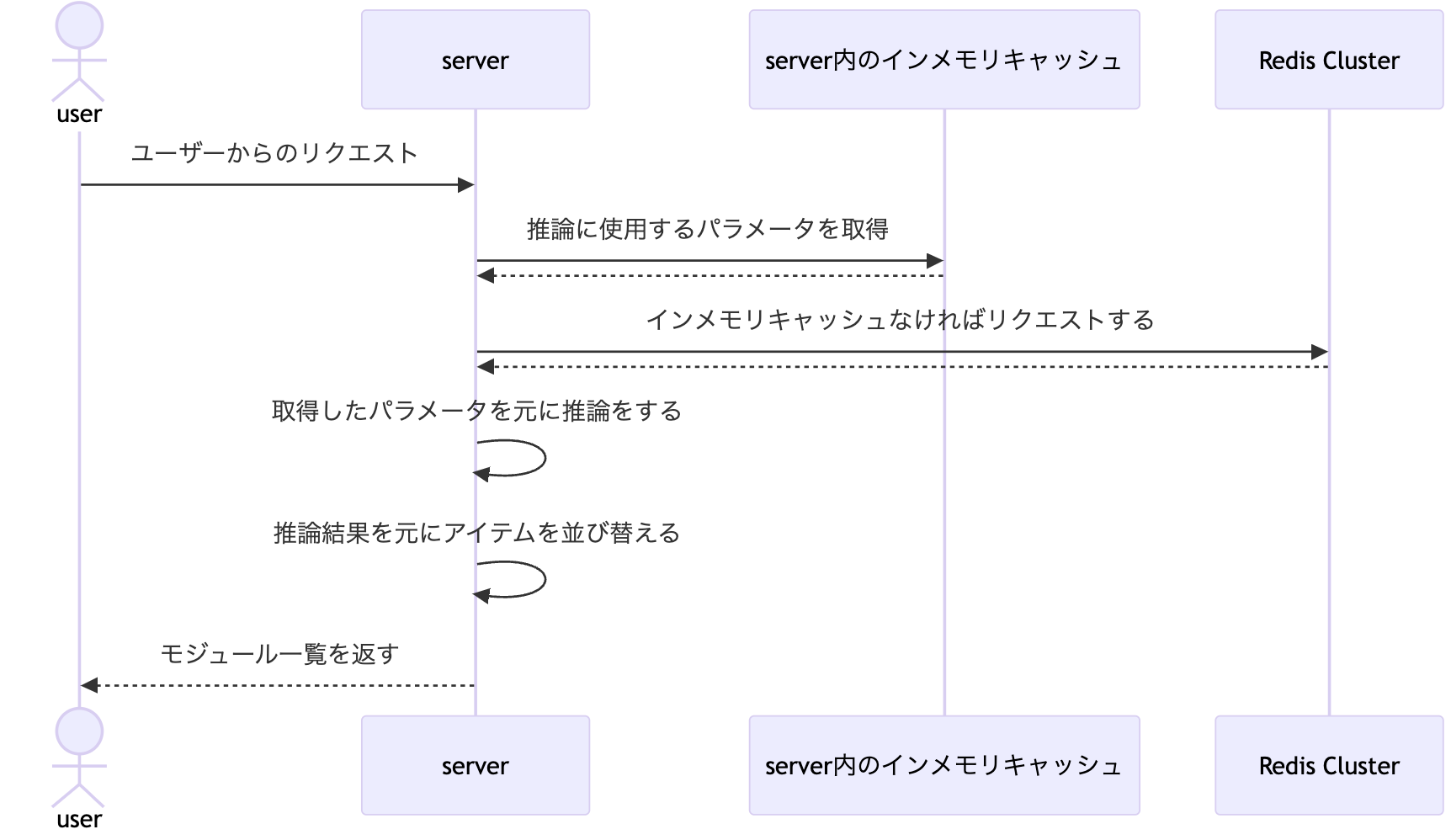
ユーザーリクエスト
ユーザーからのレコメンドリクエスト処理は、以下の流れで行われます。
大量のリクエストに耐えるために Redis Cluster を採用しましたが、さらにパフォーマンスを上げるためにサーバー内にもインメモリキャッシュを設置した多段キャッシュの構成をとっています。そして、インメモリキャッシュのライブラリには既存のアルゴリズムと比較してパフォーマンスの高い S3-FIFO アルゴリズムが使用されているかつ TTL(Time To Live) を設定できる maypok86/otter を採用しました。
また、サーバー内のインメモリキャッシュにデータがなくなり Redis Cluster にアクセスするタイミングでキャッシュスタンピードが発生して Redis Cluster への負荷が上がらないように Go の singleflight を介してアクセスすることでリクエストをまとめるようにしています。
まとめ
新しいシステムでは、モジュール内のアイテム単位で報酬計算を行うように変更しました。これにより、異なるモジュールに表示された同一アイテムでも、報酬が互いに影響し合う問題を解消しました。
また、ユーザーの属性についても、単一の組み合わせだけでなく、複数の属性を個別に考慮し、リクエスト時のユーザー属性に合わせて最終的な評価値を計算する仕組みを導入しました。例えば、「40 代」かつ「男性」かつ「アニメ好き」かつ「ドラマ好き」といった複数の属性を組み合わせて評価を行うことができます。これにより、これまで捉えきれなかった多様な興味を持つユーザーに対して、よりパーソナライズされた推薦が可能になります。さらに、類似した属性を持つユーザーセグメント間(例:「40 代男性アニメ好き」と「40 代男性ドラマ好き」)で、共通する属性(「40 代男性」)に関する報酬情報を再利用できるため、学習効率が向上することが期待されます。
おわりに
本記事では、Contextual Bandit アルゴリズムを用いた新しいレコメンドシステムのバックエンドアーキテクチャについて紹介しました。このシステムの導入により、学習データの効率的な活用や、手動ターゲティングの不要化による業務効率化が期待されます。
また、今後機械学習エンジニア・データサイエンティスト目線での記事も公開する予定ですのでご期待ください。
最後に今回の取り組みにあたっては、プロジェクトのメンバーであった以下の方々の協力が欠かせませんでした。
それぞれの強みを活かすことでプロジェクトを推進することができました。ありがとうございました!
出典
- [1] Lihong Li, Wei Chu, John Langford, and Robert E. Schapire. 2010. A contextual-bandit approach to personalized news article recommendation. In Proceedings of the 19th international conference on World wide web (WWW ’10). Association for Computing Machinery, New York, NY, USA, 661–670. https://doi.org/10.1145/1772690.1772758
- [2] Olivier Chapelle and Lihong Li. 2011. An empirical evaluation of thompson sampling. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS’11). Curran Associates Inc., Red Hook, NY, USA, 2249–2257. https://dl.acm.org/doi/10.5555/2986459.2986710