
この記事はKubeCon + CloudNativeCon Japan 2025特集 Blog 7日目の記事です。
今回は新卒2年目の私が KubeCon の参加に至った背景とともに、特に興味深く感じた 2-Node Kubernetes: A Reliable and Compatible Solution というセッションをセッションスピーカーが公開している論文とを合わせてご紹介します。
目次
- 自己紹介
- KubeCon の参加に至った経緯
- Extended Raft Algorithm について
3.1. コンセンサスアルゴリズムと Raft の導入3.2. Raft で HA 構成を実現するのに必要な node 数3.3. より少ないコストで HA 構成を実現するためのアプローチ
3.4. Extended Raft Algorithm が具体的にどのように機能するか
3.5. 2 node + witness と 3 node の可用性比較
3.6. カスケード障害
- まとめ
自己紹介
こんにちは、株式会社AJA の SSP Division でソフトウェアエンジニアをしている、サイバーエージェント2024新卒の石上敬祐(@kei01234kei)です。
普段の業務では広告配信サーバの開発、運用に取り組んでおります。
内定者時代も含め、私がこれまでに担当した仕事の一部を Developers Blog でご紹介しているため、もし興味がありましたらぜひご覧ください 🙂
KubeCon の参加に至った経緯
2024年の年末から個人的な興味により Kuberenetes の GitHub リポジトリを watch するようになりました。その中で、 kubelet で動く item の reflector に起因する issue があり、興味が湧いた自分はこの issue を深ぼりました。この中で、Kubernetes コンポーネントを動かす node への負荷を減らすための興味深い実装たちを目にし、このような最適化を考え、そして実装している Kubernetes メンテナの方と交流をしたいと思ったのが KubeCon の参加に至ったきっかけです。
Extended Raft Algorithm について
コンセンサスアルゴリズムと Raft の導入
複数のサーバが協調して一貫した状態を維持するにはデータの取り扱い方法を決めておく必要があります。例えば、3台のサーバA、B、Cがあります。これらのサーバが同じデータベースの内容を保持している場合を考えてみましょう。
クライアントからデータの更新要求が来た時、どのサーバが更新を受け付けるのか、他のサーバにはいつどのように変更を伝播するのか、ネットワーク障害でサーバ間の通信が一時的に途絶えた場合はどう対処するのかといった問題が生じます。
もしこれらの問題に対する明確なルールがなければ、サーバA、B、Cが異なるデータを保持してしまい、システム全体の整合性が失われてしまいます。また、複数のクライアントが同時に異なるサーバに更新要求を送った場合、どの更新を優先すべきかも決められません。
こういった、「複数のサーバが強調して一貫した状態を維持するための取り決めに関するアルゴリズム」を コンセンサスアルゴリズム といいます。
Raft はこのコンセンサスアルゴリズムの1つです。
本記事の中で Raft の説明をしていると記事の量が膨大になってしまうため、Raft の説明は本記事の対象外としたいと思います。
しかしながら、Raft を学ぶことができるおすすめのサイトを私からお伝えするとしたら以下の2つかなと思います。
- https://raft.github.io/raft.pdf
Raft の論文です。Raft をしっかり学びたい方はこちらを読むとよいかと思います。 - https://qiita.com/torao@github/items/5e2c0b7b0ea59b475cce
Raft の解説記事です。文章はもちろん、図を用いた説明がとてもわかりやすいです。素晴らしい記事だと思います。
Raft で HA 構成を実現するのに必要な node 数
Raft では一定数の node の障害を許容する HA 構成を作るには、最低3台の node が必要です。
node の数が1台と2台の場合、ログのコミットに必要な node の過半数はそれぞれ1台と2台で、1台の node の障害も許容できないです。
しかしながら、node 数が3台の場合、ログのコミットに必要な node の過半数は2で、1台の node の障害を許容できており HA 構成を作れている状態になります。node 数が4台、5台… の場合も同様に一定数の node の障害を許容できる状態であり、HA 構成を作れている状態です。
つまり、先にも述べたように Raft では一定数の node の障害を許容する HA 構成を作るには、最低3台の node が必要なのです。
しかし、予算制約のあるユーザにとってはより少ない node 数で HA 構成を実現できれば嬉しいという話があります。
より少ないコストで HA 構成を実現するためのアプローチ
クラスタ内の1台のサーバをコスト効率の良いエンティティに置き換えることを考えます。例えば、node が2台のクラスタにおいて、そのうちの1台の node に障害が発生した場合にも、クオーラムを維持できるようにそのエンティティが機能すればよいのです。
(クオーラムとは、「分散システムで合意形成や意思決定を行うために必要な最小限のエンティティ数」のことです。例えば、node が2台のクラスタにおいて、クオーラムの維持に必要なエンティティの数は2です。このとき、クラスタに属する1台の node に障害が発生してしまった場合、クオーラムを維持できなくなるわけですが、今回提案されている「別のコスト効率の良いエンティティ」が「クオーラムの維持に必要なエンティティ」の役割を担ってくれる場合、エンティティの数は2になり、クオーラムを維持することができます。)
このようなエンティティを witness と読んでおり、Raft の前身である Paxos では witness を共有ストレージとして実装できます。これは安価でほとんどのユーザで広く利用可能なためハッピーというお話です。
論文該当部分
In the Paxos algorithm, a witness can be implemented as shared storage, which is not only inexpensive but also widely available to most customers.
引用: https://raw.githubusercontent.com/joshuazh-x/extended-raft-paper/refs/heads/main/main.pdf
Raft でも witness をアルゴリズムに組み込むための努力がされてきたのですが、これまでに提案された研究や実装は全て witness としてスタンドアロンのサーバーを必要としており、Paxos アルゴリズムにおける共有ストレージと比較して、デプロイの複雑さを増し、コスト効率を低下させるものでした。
論文該当部分
However, all existing research and implementations necessitate a standalone server as a witness, adding to deployment complexity and reducing cost-efficiency compared to shared storage in the Paxos algorithm. Additionally, the witness must participate in log replication when it needs to conform to a quorum with other servers (when some servers are down), implying that its low-configuration hardware could potentially become a performance bottleneck in such scenarios.
引用: https://raw.githubusercontent.com/joshuazh-x/extended-raft-paper/refs/heads/main/main.pdf
そのため、共有ストレージを witness として使うことができる Extended Raft Algorithm が今回提案されたのです。
Extended Raft Algorithm が具体的にどのように機能するか
ここからは、フォロワー(下画像B)がダウンした場合の状況で Extended Raft Algorithm がどのように機能するかを議論していきます。
この状況において、リーダー(下画像A)が B からの投票なしに、過半数の票(ここでは2票)を獲得することができたらよいよね、というお話です。リーダー(下画像A)が B からの投票なしに、過半数の票(ここでは2票)を獲得することができたら、B に障害が発生してもログをコミット可能なことがわかるからです。
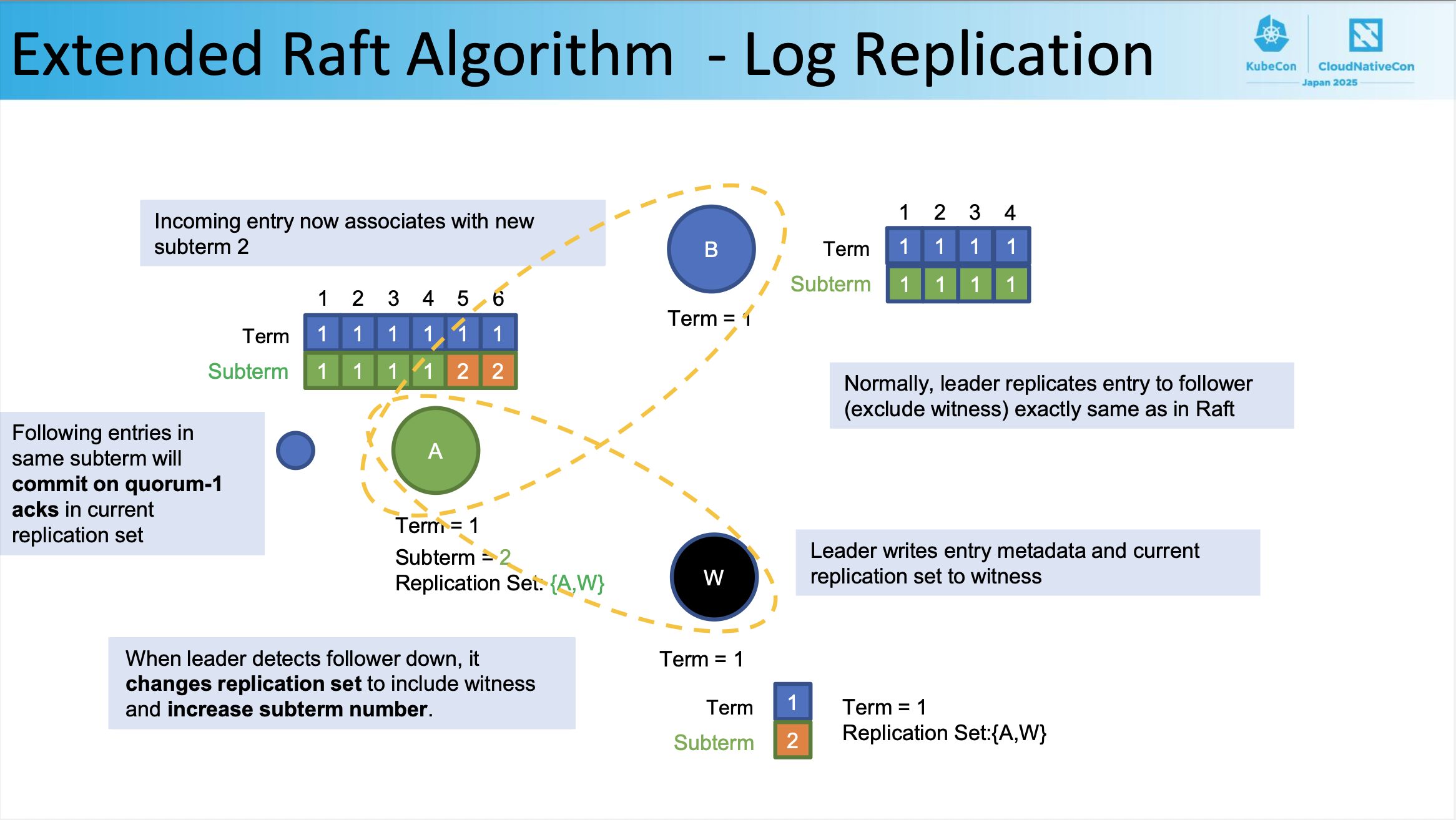
まず、リーダーがフォロワーのダウンを検出すると、 witness を含むようにレプリケーションセットを変更し、サブターム番号を増加させます。
When leader detects follower down, it changes replication set to include witness and increase subterm number.
ここでの「レプリケーションセット」とは「リーダーがクオーラム計算に使用するエンティティの集合」という理解をしていただければと思います。上画像の例では、リーダー A がフォロワー B のダウンを検出する前のレプリケーションセットは {A, B} だったのですが、リーダ A がフォロワー B のダウンを検出したことによりレプリケーションセットが {A, W} になりました。)
レプリケーションセットがどのように決定されるかの正確な定義はこちらをご覧ください
1. When a regular server becomes a leader, its replication set is initialized to all regular servers RegularServer in the leader’s configuration.
2. If all servers in RegularServer are reachable from the leader, leader changes its replication set to RegularServer, i.e., ∀s ∈ RegularServer : s ∈ Reachable =⇒ ReplicationSet’ = RegularServer
3. Leader swaps one unreachable regular server inside its replication set with the reachable regular server or witness outside, i.e.,
∃x ∈ ReplicationSet, y ∈ Server \ ReplicationSet :
∧ x ∈ Unreachable
∧ ∨ y ∈ Reachable
∨ y = witness
⇒ ReplicationSet’ = Server \ {x}
引用: https://raw.githubusercontent.com/joshuazh-x/extended-raft-paper/refs/heads/main/main.pdf
そして、リーダーはエントリのメタデータと現在のレプリケーションセットを witness に書き込みます。
Leader writes entry metadata and current replication set to witness
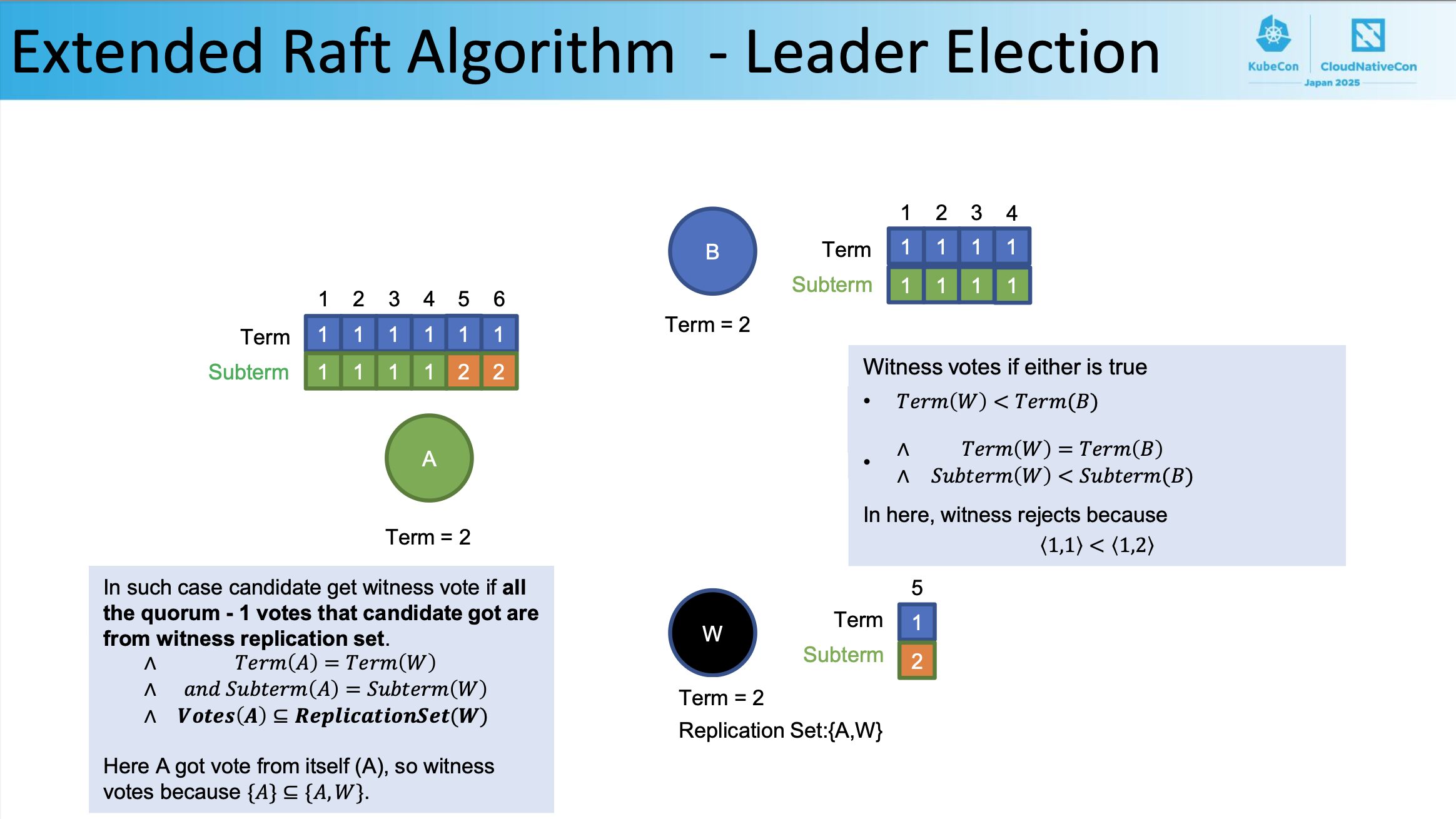
そして、𝑇𝑒𝑟𝑚(𝐴) = 𝑇𝑒𝑟𝑚(𝑊) かつ 𝑆𝑢𝑏𝑡𝑒𝑟𝑚(𝐴) = 𝑆𝑢𝑏𝑡𝑒𝑟𝑚(𝑊) かつ 𝑽𝒐𝒕𝒆𝒔(𝑨) ⊆ 𝑹𝒆𝒑𝒍𝒊𝒄𝒂𝒕𝒊𝒐𝒏𝑺𝒆𝒕(𝑾) の条件を満たし、候補者が受け取ったクォーラム – 1票がすべて witness レプリケーションセットからのものであれば、候補者は witness 票を獲得します。
ここで A は次の条件を満たしています。
- 自身(A)から投票を得ている(クォーラム – 1票を得ている)
- 𝑇𝑒𝑟𝑚(𝐴) = 𝑇𝑒𝑟𝑚(𝑊)
- 𝑆𝑢𝑏𝑡𝑒𝑟𝑚(𝐴) = 𝑆𝑢𝑏𝑡𝑒𝑟𝑚(𝑊)
- {𝐴} ⊆ {𝐴, 𝑊}である(自身は witness レプリケーションセットの部分集合である)
よって、witness は A に投票します。
In such case candidate get witness vote if all the quorum - 1 votes that candidate got are from witness replication set.
∧ 𝑇𝑒𝑟𝑚 𝐴 = 𝑇𝑒𝑟𝑚 𝑊
∧ 𝑎𝑛𝑑 𝑆𝑢𝑏𝑡𝑒𝑟𝑚 𝐴 = 𝑆𝑢𝑏𝑡𝑒𝑟𝑚 𝑊
∧ 𝑽𝒐𝒕𝒆𝒔 𝑨 ⊆ 𝑹𝒆𝒑𝒍𝒊𝒄𝒂𝒕𝒊𝒐𝒏𝑺𝒆𝒕(𝑾)
Here A got vote from itself (A), so witness votes because {𝐴} ⊆ {𝐴, 𝑊}.
A は自身の票と witness による票の合計2票を獲得し、票数がレプリケーションセットの過半数に達したためログをコミットし、処理を先に進めることができます。
つまり、node が2台の場合でも B のダウンを許容できている、ということです。
以上が2台の node で HA 構成を実現するアプローチになります。
2 node + witness と 3 node の可用性比較
こちらのページを見る限り、2 node + witness は 3 node で同等の可用性を提供できていることがわかります。つまり、2 node + witness では 3 node と比較すると(node のコストが支配的である場合)コストを1/3に抑えながら3 node と同等の可用性を実現できているみたいです。
ただし、2 node + witness の構成の場合、次に述べるカスケード障害に陥る状況が存在することは理解しておく必要があります。

カスケード障害
KubeCon のセッション内では話されていませんでしたが、セッションの元になっている論文にはカスケード障害に関する記述(4.3 Cascading Failures)があるためこちらも紹介しておきます。
Extended Raft Algorithm にはクラスターがリーダーなしの状態に陥ってしまう状況が存在します。
1. Aがシャットダウンされる
2. Bがリーダーになる
3. Bが新しいエントリをコミットする(そのためwitnessに状態を書き込む)
4. Aが起動する
5. Bが新しいコミットされたエントリをAにレプリケートする前にシャットダウンされる
例えばこの状態の時、witness の状態が、4で起動された node A よりもよりも新しい状態にあるため、witness は A に投票することができません。そのため、node A は過半数の票を獲得することができずリーダーになることができないため、クラスターがリーダーなしの状態に陥ってしまいます。
ただ、そもそもこの問題はクラスターの維持に使う node 数を削減し、代わりに witness を使うことが原因で発生しているものです。つまり、コストを削減するトレードオフとしてクラスターがリーダーなしの状態に陥ってしまうケースが発生することは理解しておくべきです。
しかしながら、「このケースが発生するのは非常に稀」とも論文内で述べられているため、この稀なケースを許容する代わりにコストを削減するか、この稀なケースを許容せずに今まで通りのコスト感でシステムを構築するかは皆様の開発チーム内で議論をしてみるとよいかと思います。
まとめ
いかがでしたでしょうか?
本記事では Raft を拡張した Extended Raft Algorithm をご紹介しましたが、こちらのアルゴリズムは執筆時点では設計のレビュー段階にあります。
https://github.com/etcd-io/raft/issues/133
そのため、このアルゴリズムが実際に etcd に取り入れられることがまだ決まっているわけではないですが、もし etcd に取り入れられることになった場合、本記事で解説したことが皆様のお役に立てば嬉しいです。
なお、本記事では Raft を理解していることを前提としている記事のため、本記事を読むための準備として Raft を学ばれた方もいると思います。
Raft については、etcd だけでなく、TiDB や CockroachDB といった分散DBや Apache Kafka といった分散メッセージキューソフトウェアでも使われております。技術選定といったこれらのソフトウェアを分析される際に Raft の知識は役に立つことでしょう。
長くなりましたが、ここまで読んで頂きありがとうございました。
KubeCon + CloudNativeCon Japan 2025 特集 Blog
- KubeCon + CloudNativeCon Japan 2025 現地参加を最大限に活かす!現役エンジニアが注目するポイントと歩き方
- KubeCon + CloudNativeCon Japan 2025 1 日目参加速報
- KubeCon + CloudNativeCon Japan 2025 2 日目参加速報
- 生成 AI マーケットの不確実性に立ち向かうためのクラウドネイティブ技術
- 若手だけじゃない!ベテラン層だって活躍したい
- Cloud Native とサイバーエージェントのこれまでとこれから
- 2 node で HA 構成を実現する Extended Raft Algorithm 〜入社 2 年目 AJA 所属〜 (👈 この記事)
- Kubernetes SIG Node に Deep Dive する 〜入社 1 年目 CIU 所属〜
- Kubernets を活用したインフラ基盤運用の安定化について 〜入社 2 年目 CIU 所属編〜
- テナント志向で考える、マルチクラスタ・マルチクラウド運用 〜入社 1 年目 ABEMA 所属〜
- Argo CD x Cluster Inventory で実現するマルチクラスタ運用の新境地 〜入社 2 年目 ABEMA 所属〜