
本記事は「KubeCon + CloudNativeCon Japan 2025特集 Blog 」の連載記事です。
今回は新卒2年目でプライベートクラウドのエンジニアとして働いている私から、KubeConの数あるセッションの中でも私が特に面白かったと感じている 「Safeguarding Your Applications Achieving Zero Downtime During Kubernetes Upgrades」について紹介します!
自己紹介
改めまして、株式会社サイバーエージェントのCIUという部署でIaaS基盤の開発・運用をしている、2024年新卒入社の近藤智文 (@tomokon_0314) と申します。普段の業務では、IaaS基盤のベースとなっているOpenStackやハイパーバイザー、またそれらを管理するKubernetesクラスタ等の運用・管理をしています。
CIUではデータセンターやハードウェアの選定・調達から、IaaS/PaaS/SaaS様々なサービスの開発まで一貫して行い、社内の様々なユーザーに提供しています。その中でも多くのサービスがKubernetesやその他のCloud Native技術を採用しており、今回私はCIUの若手として、Kubernetesを活用したインフラ基盤の安定運用における知見を得るためにKubeConに参加してきました。
なぜDown Timeが発生するのか
Kubernetesクラスタを安定して運用していくためには、定期的なアップストリームのバージョンアップに追従していくことが求められます。AWSのEKSやGoogle CloudのGKEといったクラウド基盤のマネージドなKubernetes control planeを使っている方であれば、それらのサービスにバージョンアップの諸々を丸投げできるのかもしれませんが、その裏でどのような仕組みが動いているのかを知ることは重要であり、いざという時に役立つことがあるかもしれません。
Kubernetesは非常に多くのコンポーネントから構成されており、コントロールプレーンであれば etcd、kube-apiserver、kube-scheduler、データプレーンでは kubelet、kube-proxy、container runtime など様々なものがあります。Kubernetesクラスタのアップグレードをするためにはこれらのコンポーネントをそれぞれ更新する必要があるため、当然その一つ一つについて更新時に一時的に停止する処理が行われ、Down Timeが発生してしまいます。
そのようなコンポーネントレベルのDown Timeを防ぐことは難しいため、アーキテクチャやアップグレードの手法を工夫することで、アップグレード時にユーザーに影響が出ないようにすることが求められます。
Down Timeを防ぐ魔法は存在しない
それではどのようにしてアップグレード時のユーザー影響を防ぐのでしょうか?
結論から言うと、Down Timeをなくす魔法のようなメソッドやツールなんてものは存在しません。安全なアップグレードは Observe、Analyze、Learn、Act のサイクルを地道に回していくことで達成できるのです。
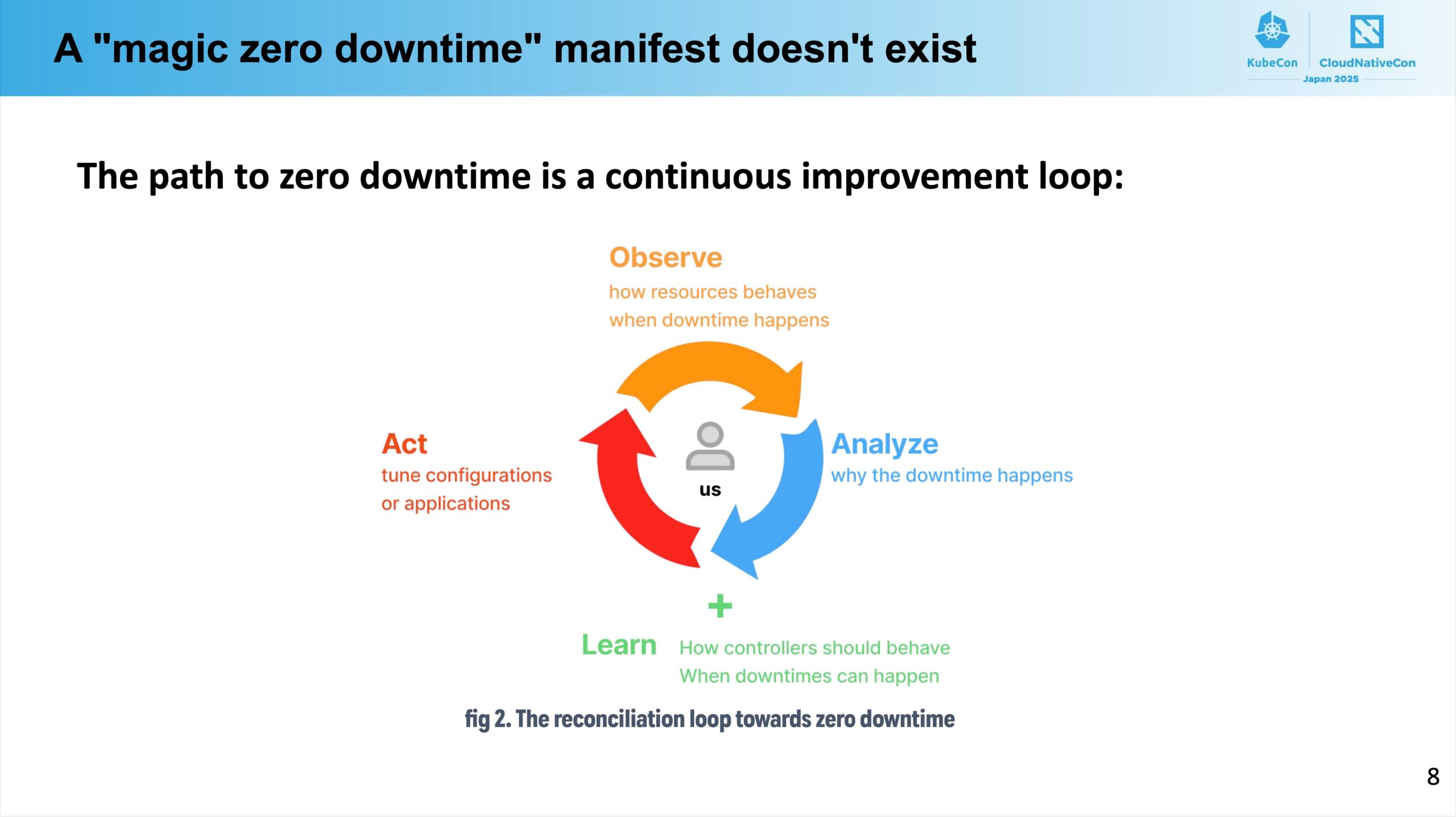
Observeは、どのようにしてDown Timeが発生してしまうのかを観察することを指します。まず思いつくのはこれはkubectlコマンドを使ってpodの状態を確認したり、各種メトリクスを確認することですが、これらの方法では継続的かつ網羅的にDown Timeやその原因となるイベントを確認することは難しいです。
そこで、このセッションでは kube-apiserverのaudit log が紹介されていました。audit logは一般的に使われる用語で、セキュリティの文脈やトラブルシューティングのために、システムに対していつ・誰が・何をしたのかなどを全て記録する機能です。全てのイベントを記録するため当然大量のログが出力されるので通常時は無効化しておくといった運用も多いですが、こちらを有効化することでDown Timeの原因となるようなエラーイベント等を網羅的に把握できるみたいです。
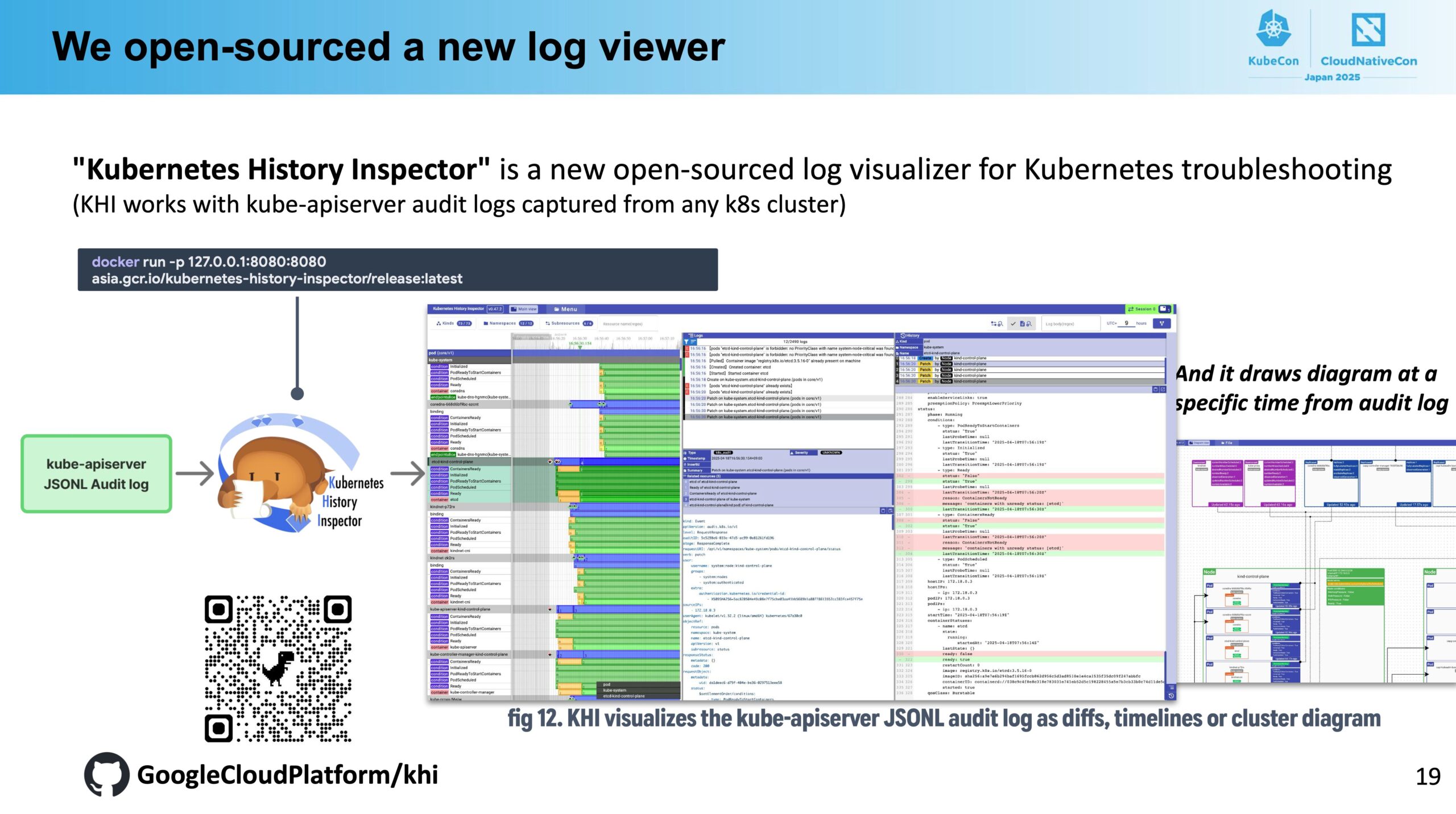
さらに、Googleが開発しているオープンソースのツールでKubernetesのaudit logをいい感じに可視化してくれる Kubernetes History Inspector (khi) も紹介されていました。
そのようなツールを駆使してDown Timeの原因を観察・分析し、それらを防ぐためのActに繋げていくことが重要である、と述べられていました。
コントロールプレーンのDown Time
Kubernetesのコントロールプレーンは基本的にHA構成となっているため、1台ずつローリングアップデートをすることができます。ところが、HAは1台のleaderとそれ以外のreplicasで構成されており、leaderを落とす際には新たなleaderを選出する必要があるため、その間のわずかな時間がDown Timeとなってしまいます。
例えばleader選出にRaftアルゴリズムを用いているetcdはleaderのダウンを検知するのに1秒、新たなleaderの選出にさらに1秒程度かかるそうです。etcdはwriteは全てleaderで処理されるため、leader不在の間はwriteが一切できなくなってしまいます。また、kube-apiserverはleaderが不在の間は500エラーを返すようになっていたり、kube-schedulerはpodのスケジューリングができなかったりなど、どのコンポーネントにおいても致命的な問題が生じてしまうようです。
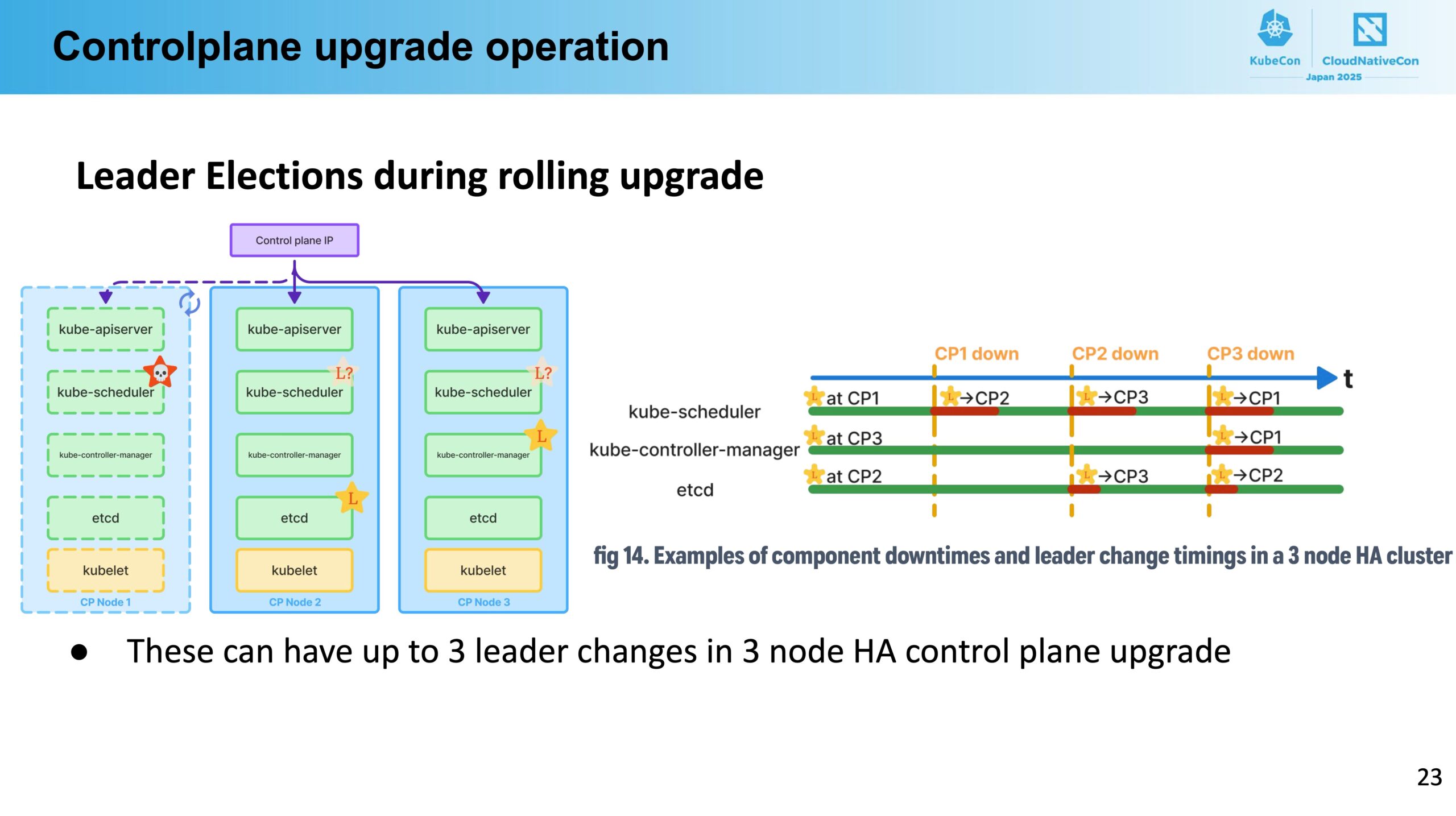
あとこちらはセッションの話ではなく自身の経験談ですが、kube-apiserverへの通信をDNSラウンドロビンで分散していたりしたら、アップデートを行うNodeを一時的にDNSのレコードから外すといった作業が必要になる場合もあります。他にも各々の環境固有の問題等はあるかもしれないので、ここで挙げられているもの以外にも、自組織では何がDown Timeになりうるのかをしっかりと観察・分析することが重要と言えます。
これらはあくまでコントロールプレーンのDown Timeの話なので、すでに動いているワークロードに直接的に影響が出てしまうわけではありませんが、非常にわずかな時間でもKubernetesのリソース更新等の操作が一切できなくなってしまうのは問題となりえます。Kubernetesクラスタに対して操作を行うCI/CDや何らかのアプリケーションでは、このような瞬断に対応できるようにリトライ処理を入れるなどの工夫が必要になりそうです。また、クラスタ管理側も普段のリクエストやイベントの特性を把握し、リクエストが多い時間を避けてアップグレードを行うといった配慮も必要になるかもしれません。
また、セッションを聞いていてローリングアップデート時のバージョンの混在は大丈夫なのかと気になって調べてみた所、同じコンポーネント同士や異なるコンポーネント間で動作が保証されているバージョンが公式に提示されているようでした。少なくとも1マイナーバージョンくらいの混在は大丈夫そうに見えますね。
Version Skew Policy | Kubernetes
データプレーンのDown Time
続いてはKubernetesのデータプレーンのNodeのDown Timeについてです。
Nodeアップグレード時には、そのNode上のpodを全てevictして他のNodeに退避させる必要があります。その際、主に二つのポイント、”PodDisruptionBudget (PDB)” と “Graceful Termination” が重要になってきます。
まずは PDB についてです。PDBはNodeからpodを安全にevictするための仕組みで、以下のようなマニフェストで使うことができます。
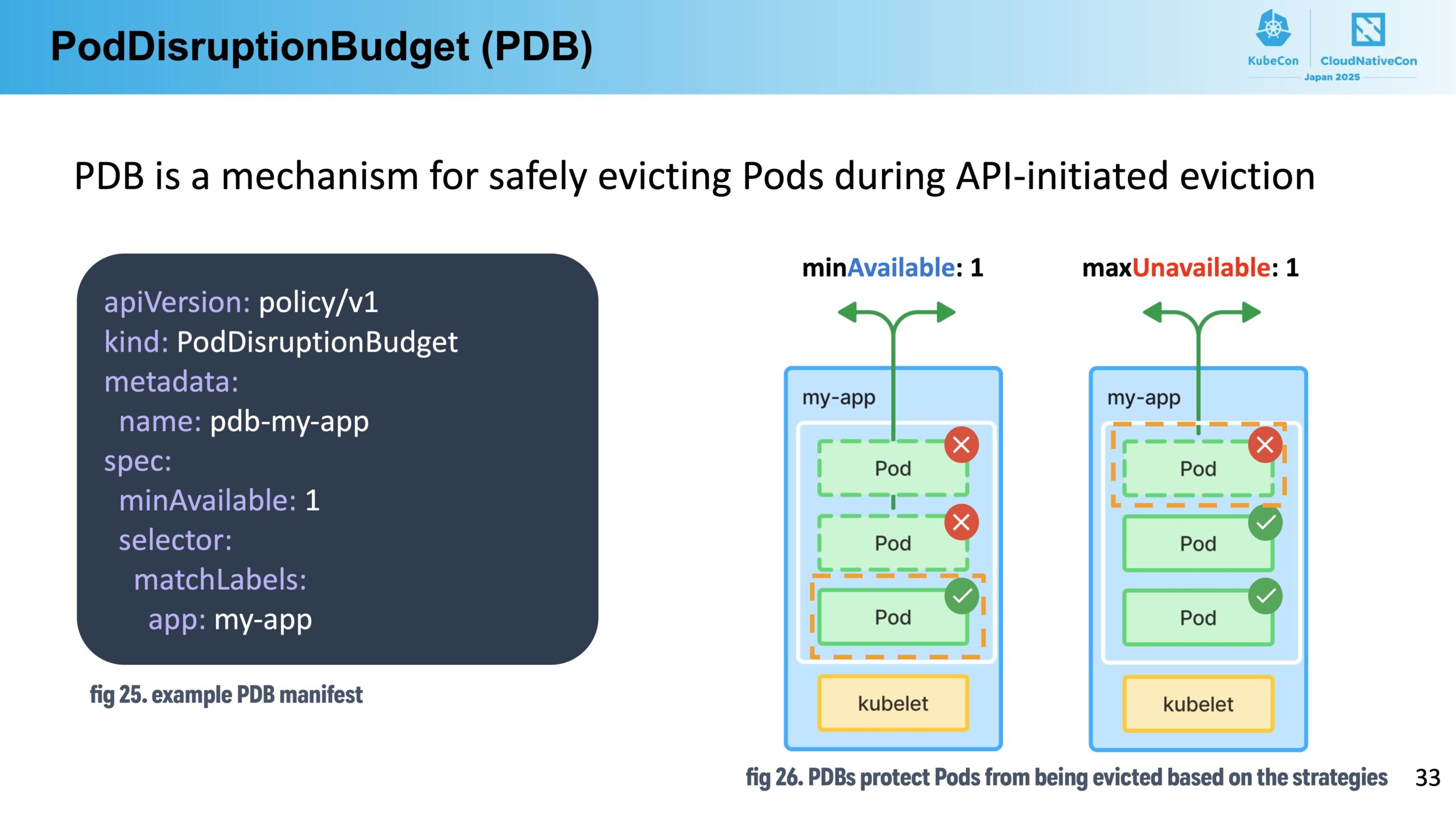
例えば minAvailable: 1 のようにセットすることで、あるアプリケーションのpodのreplicasの内、必ず1台以上はpodが稼働している状態を保つように、先にevictされたpodが起動してきてから次のpodがevictされるような仕組みになっています。具体的には、PDBを満たさないpodのevict操作に対して kube-apiserver が 429 Too many Requests エラーをクライアントに返してくれるみたいです。そのようなevictできるかどうかの状態管理もPDBリソースのStatusを利用して行われているみたいで、美しくできているなと感心しました。

しかし PDBをセットすれば万事解決かと言うとそう言うわけでもなく、PDBによってevictionがpendingされていても、evictがタイムアウトを迎えると強制的に対象Node上のpodが全てevictされてしまったり、podにReadiness Probeが設定されていないとそもそもPDBが正しくpodの情報を反映して動作しなかったりと、PDBを正しく利用していく上で考慮しなければならないことは多そうな印象でした。
続いて Graceful Termination についてです。
Kubernetesのpodを削除する際には、preStopを使ったりアプリケーション側でSIGTERMをハンドリングしてpodを安全に終了させることが求められます。例えばpreStopで一定時間sleepすることで、kube-proxyがserviceのルーティング先から削除されるpodを外すまで待ったり、WebサーバのアプリケーションがSIGTERMを検知して新規コネクションを受け付けないようにすることなどがよくあります。
ところが、preStopやアプリケーションのSIGTERMハンドリングが設定されていても、タイミングによってはDown Timeが発生してしまうケースが存在します。
1つ目はルーティング設定更新がcontainerのシャットダウンより遅くなってしまった場合です。
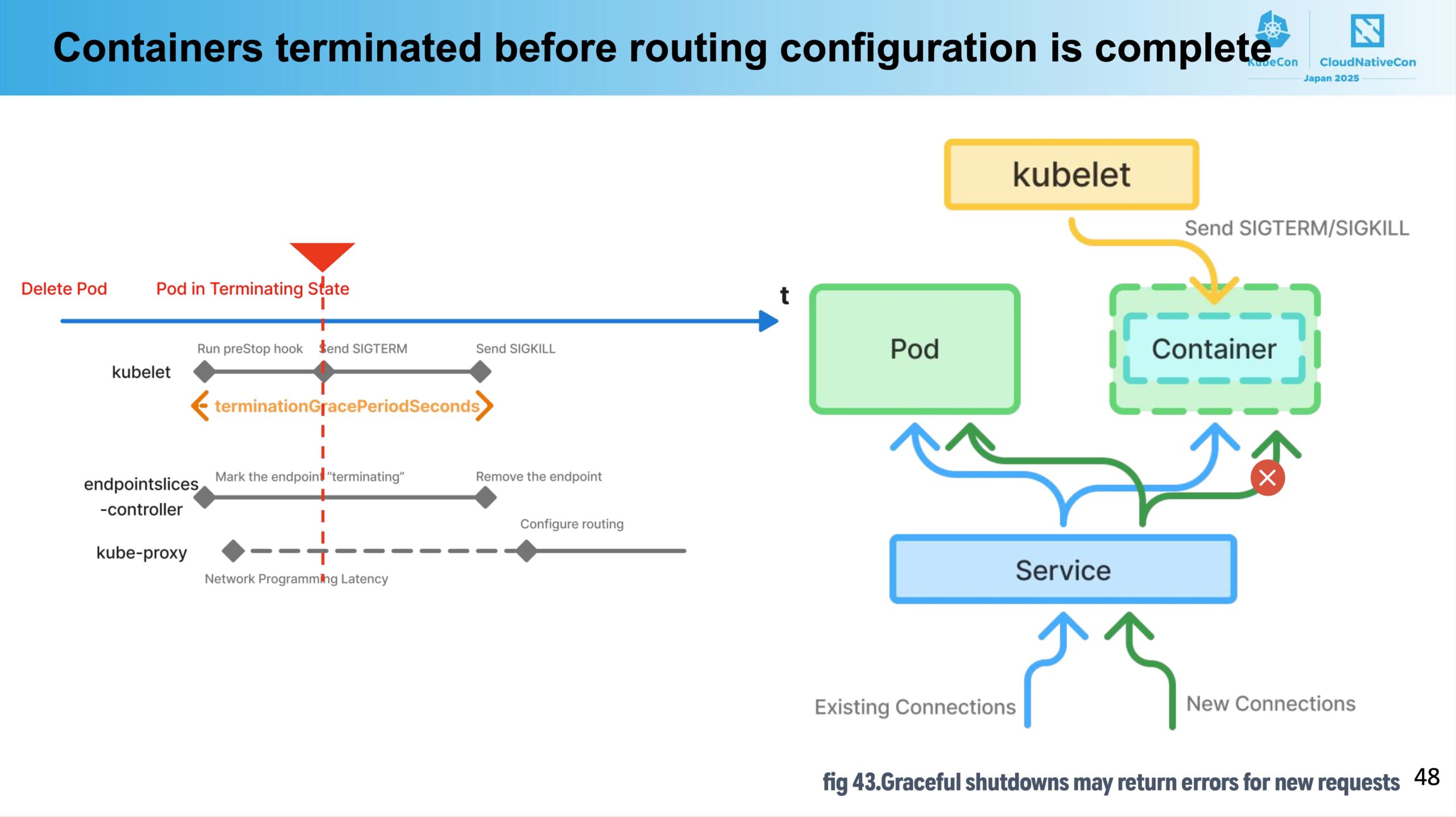
例えばpreStopを10秒に設定していたとしても、kube-proxyのルーティング設定更新が何らかの理由で 10秒+containerのgraceful shutdown より遅くなってしまうと、クライアントからのリクエストがすでに削除済みのpodのIPアドレスにルーティングされてしまい、リクエストが失敗してしまう可能性があります。
これを防ぐためにはpreStopでのsleepを十分に長い時間にしてあげれば良いのですが、長くしすぎると今度はpodの削除に時間がかかりすぎてしまい、メンテナンス時間の増大や、先ほど述べたようなevictのタイムアウトを超過してしまう危険性もあるため、必要十分な待ち時間にしてあげなければいけません。
それではどのようにして必要十分な待ち時間を知るのかという話になりますが、kube-proxyは kubeproxy_network_programming_duration というメトリクスを提供しており、これはkube-proxyがiptables等のルール更新にかかった時間を測ったものになります。この値を元に、preStopの待ち時間 + container shutdown の時間がkube-proxyのルール更新よりも後に終わるようにしてあげるのが良さそうです。
ただし、例えばiptablesではルール数に比例してルール更新時間が長くなるといった特性もあるため、同じ環境においても時間の経過によって適切な設定値が変わりうることも意識しておくことが大切になりそうです。
2つ目のケースは、conatinerのgraceful shutdownが終わる前にpodがterminateされてしまう場合です。
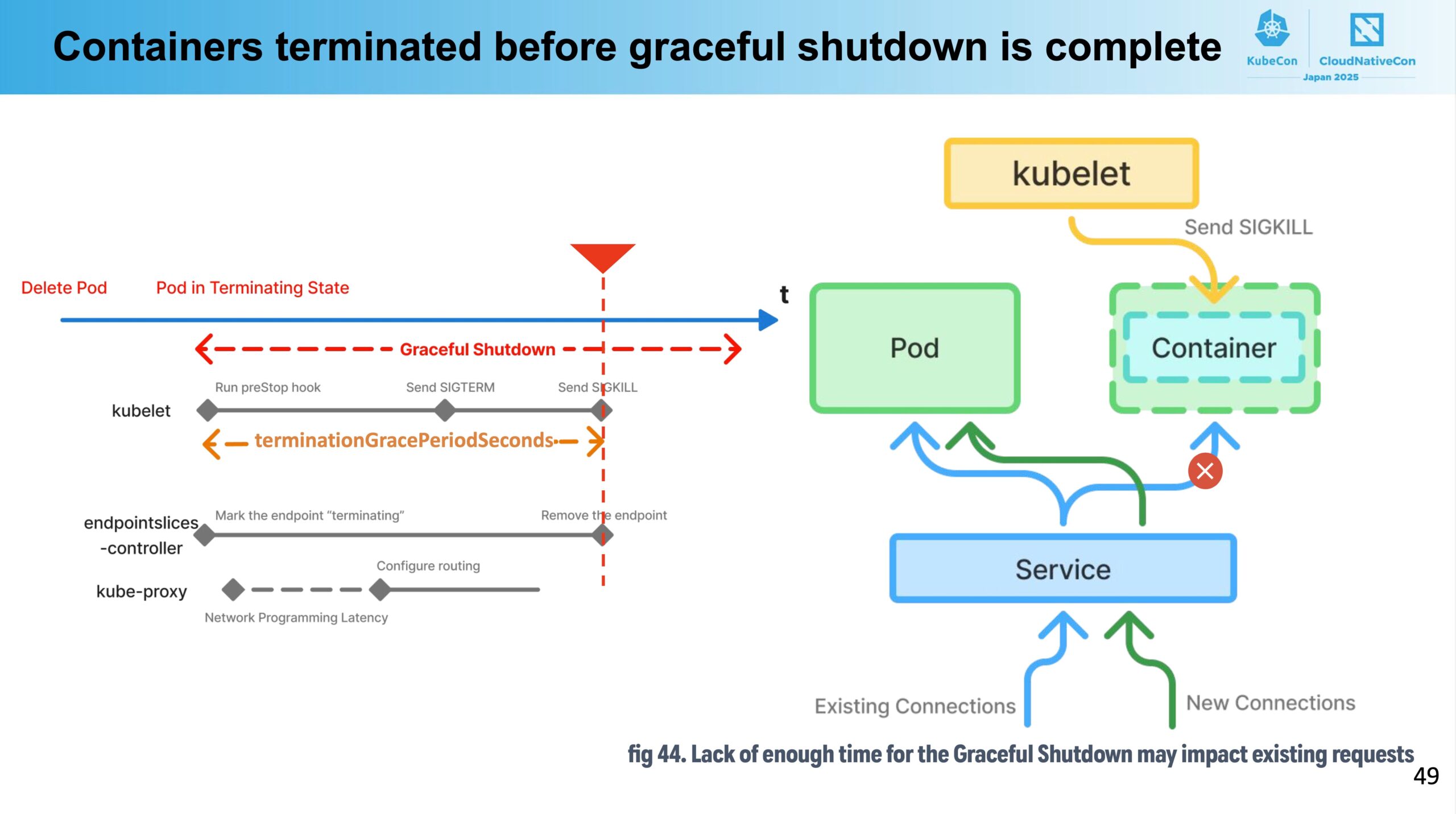
Node上でpodを管理するkubeletは、pod削除時にpreStopの処理が終わるとまずコンテナのメインプロセスに対してSIGTERMを通知します。アプリケーションは (ちゃんと実装されていれば) SIGTERMを検知してgraceful shutdownを行いますが、もしもこのshutdown処理に時間がかかってしまって終わらないままpodの “terminationGracePeriodSeconds” の時間を経過してしまうと、今度はSIGKILLが通知され、コンテナはgraceful shutdownを最後まで終わらせることができないままterminateされてしまいます。
これを防ぐためには、podのterminationGracePeriodSecondsを preStop + container garceful shutdown 時間より長い時間にする必要があります。podのpreStopやgraceful shutdownで何が行われているのか、またそれらが普段どの程度の時間がかかっているのか等を把握しておくことが重要になります。
まとめと感想
本記事では、Kubernetes Clusterアップグレード時のDown Timeを最小化するための技術的な工夫についてのセッションを紹介しました。メンテナンス時のユーザー影響を極力小さくするというのは、インフラ基盤を運用している組織にとっては避けて通れない関心事です。Kubernetesに限らず、Observe、Analyze、Learn、Actのサイクルを地道に回し、安定したインフラ基盤を提供し続けることを意識していきたいと感じました。
またKubeConに参加した個人的な感想として、様々なセッションや企業ブースでのコミュニケーションを通して技術的な学びや発見を得られたのはもちろんですが、世界で活躍する多くの日本人エンジニアの方々の姿を見てモチベーションがとても上がったというのが、参加した意義として非常に大きかったと感じています。このような機会を若手にも与えていただき、本当にありがたく思います。
それでは長くなりましたが、最後まで読んでいただきありがとうございました。
KubeCon + CloudNativeCon Japan 2025 特集 Blog
- KubeCon + CloudNativeCon Japan 2025 現地参加を最大限に活かす!現役エンジニアが注目するポイントと歩き方
- KubeCon + CloudNativeCon Japan 2025 1 日目参加速報
- KubeCon + CloudNativeCon Japan 2025 2 日目参加速報
- 生成 AI マーケットの不確実性に立ち向かうためのクラウドネイティブ技術
- 若手だけじゃない!ベテラン層だって活躍したい
- Cloud Native とサイバーエージェントのこれまでとこれから
- 2 node で HA 構成を実現する Extended Raft Algorithm 〜入社 2 年目 AJA 所属〜
- Kubernetes SIG Node に Deep Dive する 〜入社 1 年目 CIU 所属〜
- Kubernets を活用したインフラ基盤運用の安定化について 〜入社 2 年目 CIU 所属編〜 (👈 この記事)
- テナント志向で考える、マルチクラスタ・マルチクラウド運用 〜入社 1 年目 ABEMA 所属〜
- Argo CD x Cluster Inventory で実現するマルチクラスタ運用の新境地 〜入社 2 年目 ABEMA 所属〜