
はじめに
こんにちは、グループIT推進本部・DPU(データプロダクトユニット)にてデータ基盤エンジニアのアルバイトをしている大野元と申します。グループIT推進本部・DPUは各事業部やサービスで生成される大量のデータを効率的に活用するためのシステム基盤やプラットフォームの構築・運用を担っているチームです。
本記事では、アルバイトの中で取り組んだQdrantというベクトルデータベースのバックアップ・リストアAPI開発について、紹介します。
Qdrantとは
QdrantはRust製のオープンソース・ベクトルデータベースであり、ベクトル埋め込みに基づく高次元の類似検索に特化しています。ユーザの行動ログや画像・テキストなどを数値ベクトルとして保存・管理し、画像検索や自然言語処理、推薦システムなどに活用されます。
サイバーエージェントでの活用例
- 「CyChatSD」という社内向けチャットボットでRAG(Retrieval-Augmented Generation)を実現するベクトルデータベースとして利用しています。
Qdrantのアーキテクチャ
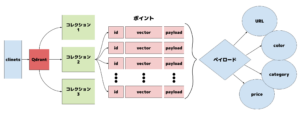
1. コレクションとポイントの構造
Qdrant では、「コレクション」と呼ばれる単位でデータを管理しています。これは RDB(リレーショナルデータベース)でいうところの「テーブル」に相当し、「ポイント」と呼ばれる個々のデータエントリ(レコード)を保持します。
各ポイントは「 id、vector、payload」の三つで構成されています。idは一意な識別子、vectorは数値の配列(ベクトル)であり、ベクトル検索の対象となるデータです。様々なデータソースから抽出された特徴量を表現しており、多様な情報から生成されます。さらにpayloadにはカテゴリ情報などの付加的な情報がJSON形式で保持されており、メタデータに基づくフィルタリングや絞り込みが可能です。
このような構造により、Qdrant はベクトル検索とメタデータ検索の両立を可能にしています。
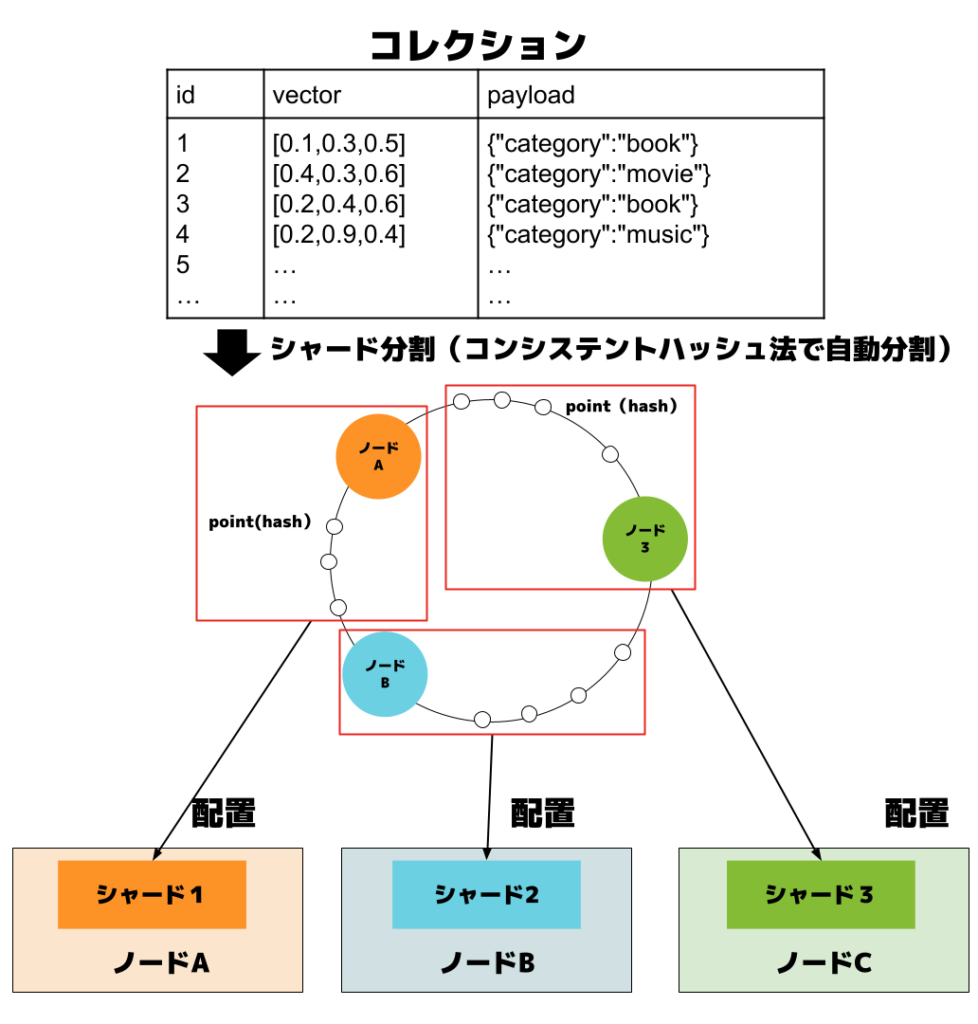
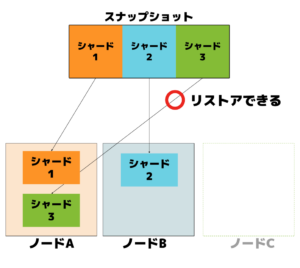
2. コレクションの物理データ配置とシャーディング
パフォーマンスの向上・可用性の確保・スケーラビリティの実現のため、Qdrantを分散モードで運用しています。Qdrant のコレクションは、自動的にコンシステントハッシュ法でシャードに分割されます。シャードとは、コレクションのデータを複数のセグメントに分割したものであり、分散処理やスケーラビリティを担保する重要な要素です。各シャードは異なるノードに配置されることで、並列処理が可能となり、全体としての処理性能が向上します。
Qdrantの運用におけるバックアップ
Qdrantを運用する上で、定期的なバックアップを実施することが必要です。バックアッププロセスではスナップショットを作成し、データの整合性を保ちます。障害が発生した際には、作成したスナップショットをリストアすることで、システムの迅速な復旧が可能となります。
用語の説明
- スナップショット
- 特定の時点におけるデータの状態を記録したもの。
- バックアップ
- データを保護するために、システムのデータをコピーして保存するプロセス。バックアップによりスナップショットを作成。
- リストア
- バックアップからデータを復元するプロセスである。リストアにより、データベースの状態をバックアップ時点の状態に戻すことができる。データの損失や破損が生じた際に、システムの運用を継続するために重要。
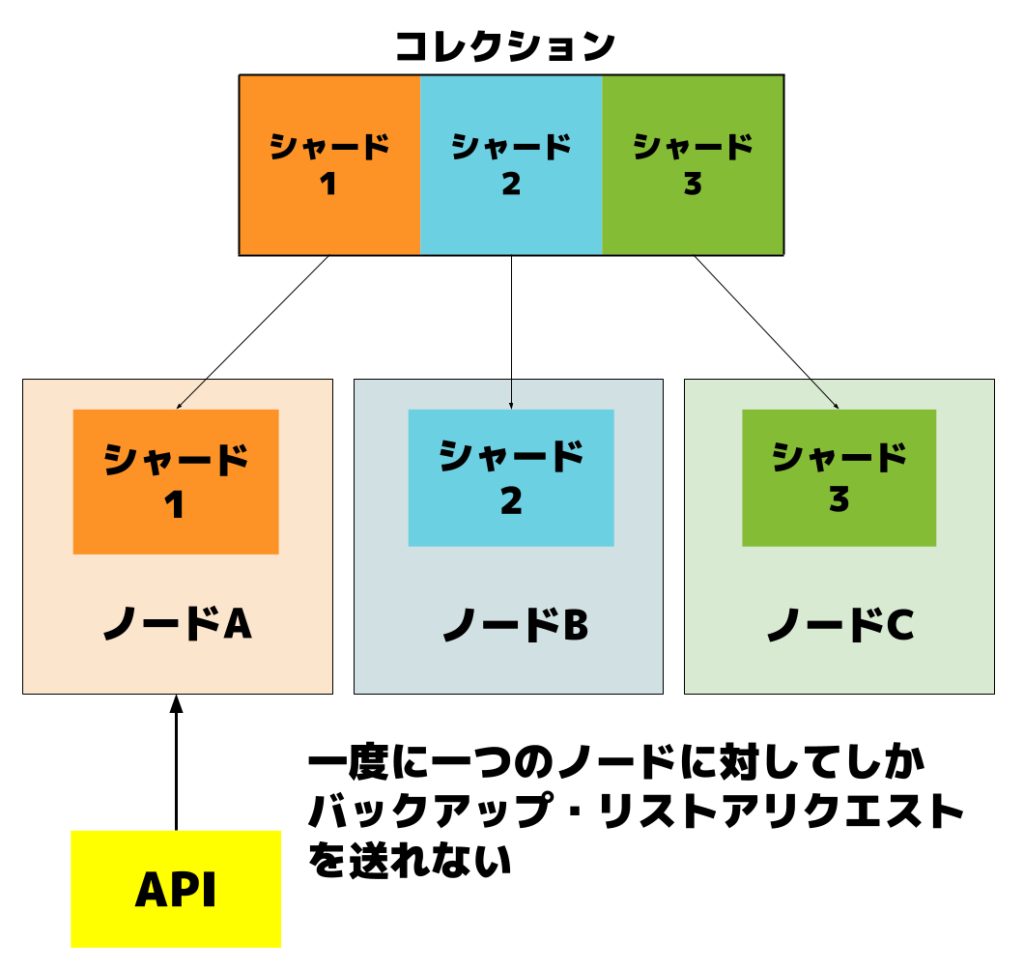
課題:ノード単位でしかスナップショットを取得・リストアできない既存API
Qdrant公式が提供するAPIは、スナップショットの取得および復元をノード単位でしか実行できない制限があります。これにより、以下のような運用上の課題が発生していました。
- ノードごとの手動対応が煩雑
-
- ノード数が多いクラスタでは、各ノードに対して個別にリクエストを投げる必要があり、運用負荷が高くなります。
-
- スナップショットの一貫性が保証できないため、障害時の復元が困難
-
- 同一タイミングで取得されたスナップショットをグループとして管理していないため、正しい組み合わせを手動で判断する必要があります。
-
タスクの目的:クラスタ全体を対象とした一貫性あるバックアップ/リストアの実現
上記の課題を解決するために、複数ノードに対して一括でバックアップおよびリストアを実行できるAPIを開発しました。このAPIは、以下のような機能を備えています。
- 複数ノードに対して一括でバックアップ・リストアリクエストを送信
- バックアップ時に同時に取得したスナップショットを同一グループとして管理し、リストア時にもノード全体への一括リストア対応が可能
このAPIを用いてバックアップ・リストア作業の効率化を図り、日常的な運用負荷の軽減します。また、グループ単位でのリストアを行うことで、ノード障害時の迅速な復旧対応を可能にし、サービスの可用性を向上させることを目的としています。
API設計概要
ここからは開発するAPI「バックアップサービス」について説明していきます。
バックアップサービスはSpring BootでのRESTfulなAPIとして作成し、Kubernetesで運用を行います。
バックアップサービスは以下のエンドポイントを提供しています。
| 機能 | エンドポイント | メソッド |
|---|---|---|
| 特定コレクションのバックアップ | /collections/{collectionName}/backups | POST |
| 全コレクションのバックアップ | /backups | POST |
| スナップショット一覧の取得 | /collections/{collectionName}/snapshots | GET |
| 特定スナップショットの情報取得 | /collections/{collectionName}/snapshots/{groupId} | GET |
| 最新スナップショットからのリストア | /collections/{collectionName}/restore | POST |
本記事では、「特定コレクションのバックアップ」と「最新スナップショットからのリストア」のエンドポイントについて紹介します。
スナップショットの保存
スナップショットの実体ファイルはS3互換のオブジェクトストレージに保存されます。
同時に取得したスナップショットを同一グループとして管理するために、取得したスナップショット情報をTiDBに保存します。TiDBとはMySQL互換の分散型データベースです。DPUで運用を行っており、ノウハウがあり、迅速に活用できるため選定しました。

テーブル設計
取得したスナップショット情報は、以下の2テーブルで管理しています。
- backup_groupsテーブル
- バックアップの「グループ」を一意に識別
- collection_nameとbackup_timeを主キーとして管理
- snapshotsテーブル
- 各ノードごとのスナップショットメタ情報を格納
- バックアップ名、作成元ノード、ファイルサイズ、作成日時などを記録
- 外部キーとして group_id を持ち、対応するグループと紐づけ
backup_groupsテーブルとsnapshotsテーブルは1:Nの関係です。スナップショット削除時には ON DELETE CASCADE を利用し、関連レコードの自動削除が可能です。

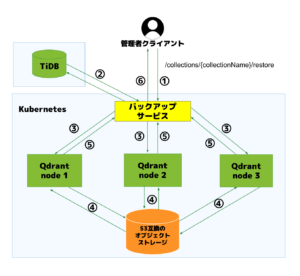
バックアップフロー概要
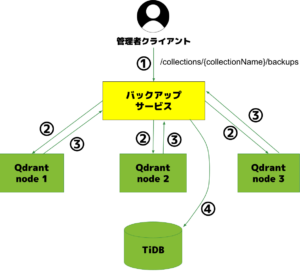
①クライアントが API エンドポイント /collections/{collectionName}/backups に対してバックアップリクエストを送信
②バックアップサービスが Qdrant クラスタ内の各ノードに対して並列でリクエストを送信
③各ノードがスナップショットを作成し、そのパスやメタ情報を返却
④APIがそれらの情報をグループ化(backup_group)しTiDBに保存
スナップショットの実体はS3互換のオブジェクトストレージに保存され、メタ情報はTiDBに集約されています。これにより、後続のリストア処理においても一貫性を保ちながら対応可能となります。
また、各スナップショットは group_id でひとまとまりとして backup_groups テーブルに関連付けられます。この構造によって、どの時点で取得されたスナップショット群かを正確に特定でき、正しい組み合わせでのリストアが実現します。
リストアフロー概要
①クライアントが APIエンドポイント /collections/{collectionName}/restore にリクエスト
クエリパラメータ
-
{dest}:リストア先のコレクション名を指定。指定しない場合は、スナップショット取得元のコレクションにリストア。指定したコレクションが存在しない場合は新たに作成される。{multiShard}:オプション。後ほど詳しく説明します。- ※ 通常はバックアップ時と同じノード数でリストアすることを推奨しますが、クラスタ構成が変更された場合やノード数が減った場合はtrueにしてください。
②APIが最新のバックアップグループとスナップショットを取得
③各ノードに対し、対応するスナップショットを使って並列でリストア処理を実行
④各ノードが指定されたスナップショットを用いて、リクエスト時に指定されたコレクションにリストア
-
- リストア先のコレクションにすでにポイントが存在していた場合は上書きされます。
⑤Qdrantノードから、APIに各ノードのリストア結果を返す
⑥APIがリストア結果を集約し、レスポンスとして返却
リストアにおける検証と課題
リストア処理に関しては、バックアップ取得時とは異なるノード構成でリストアを行った場合の挙動など、詳細な仕様の記載は確認できませんでした。
そのため、本タスクでは、ノードを入れ替えた場合やノード数が増減した場合にどのような結果になるかといったケースも含めて、実際の動作を検証しながら設計・実装を進めました。
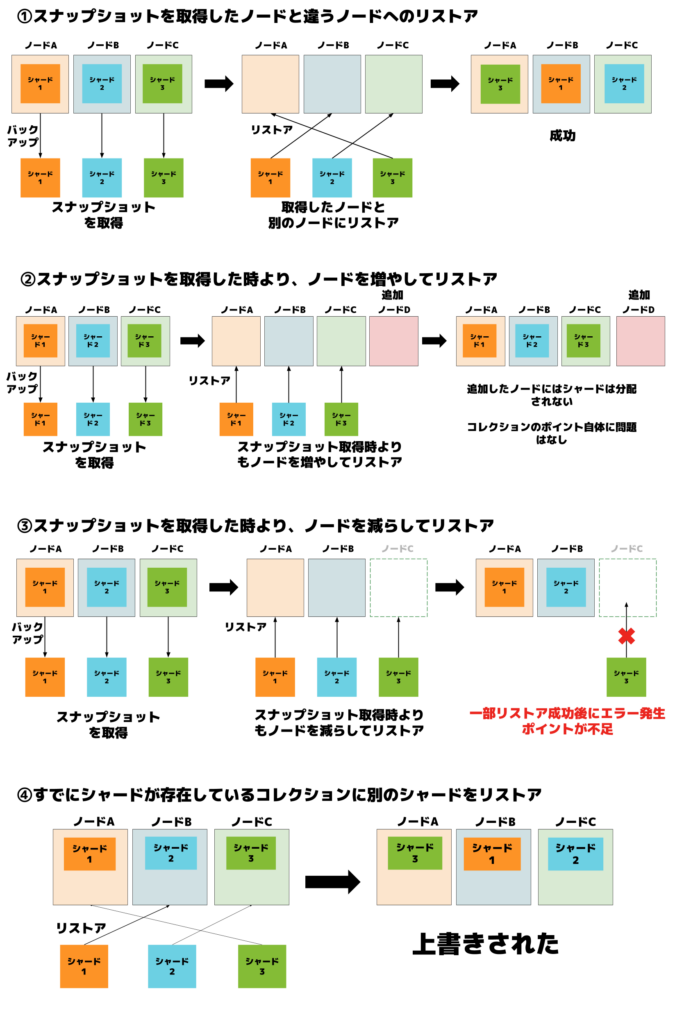
実施した検証パターンと結果
| パターン | 説明 | 結果 | 備考 |
|---|---|---|---|
| ①取得ノード ≠ リストアノード | スナップショットを取得したノードと別のノードにリストアを行う | 成功 | ノード変更でも対応可 |
| ②ノード数増加 | スナップショット取得時のノード数よりも、ノード数を増やしてリストアを行う | 成功 | 未割り当てノードが生まれるが影響なし |
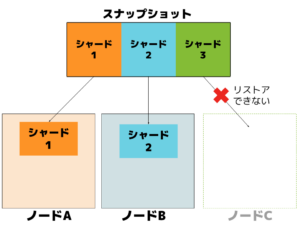
| ③ノード数減少(数が足りない) | スナップショット取得時のノード数よりも、ノード数を減らしてリストアを行う | 失敗 | 一部リストア成功後、ポイント不足でエラー |
| ④シャード配置の変更 | すでにシャードが存在しているコレクションに別のシャードをリストア | 成功 | 問題なし、正しく上書きされる |
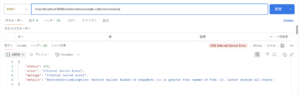
リストアを実行したときに、スナップショット取得時に比べてノード数が減少した場合は以下の図のように「スナップショットの数がpod数よりも大きいため、すべてのシャードをリストアできない」ということを知らせるエラーが発生します。
検証の中で確認された課題
- ノード数が減った場合 → シャード数を超えてしまいリストア不可
- ノード数が増えた場合 → 未割り当てノードが生まれる
- クラスタ再構成により不要シャードが残る可能性
なお、今回の検証では、社内向けチャットボット「CyChatSD」で利用している1GB未満のコレクションを対象としました。そのため、大規模なデータサイズや多数のポイントを含むケースについては十分な検証ができておらず、今後の実用化を見据えて検証範囲を拡張していく予定です。
複数のシャードを1つのノードにリストアするオプション機能の開発
検証を通して、取得したノードとは異なるノードにリストアしても、正常に復元できること、および複数のシャードを1つのノードに集約しても動作に問題が生じないことが確認できました。
これを踏まえ、リストア処理の柔軟性を高めるため、「複数シャードを1ノードにリストア可能にするオプション」を開発しました。
このオプションは、ノード数がスナップショット数よりも少ない場合に利用されることを想定しています。API呼び出し時に multiShard=true を指定することで有効となり、複数のシャードを1つのノードにまとめてリストアできるようになります。
この機能により、ノード数が一時的に不足している場合でも、全てのシャードをリストアすることが可能となり、緊急時の柔軟な復旧や、最小限のリソースでの検証といったケースに対応できます。
デフォルトではノード数がスナップショット取得時に対して減少していると、ノードが不足している旨の例外が投げられます。ノードの状態を確認して、必要な場合のみこのオプションを使用します。
ただし、複数のシャードが1ノードに集約されるため、リストア後のシャード再配置には注意が必要です。必要に応じて、手動での再シャーディングの検討も求められます。
まとめ
今回実施した内容
今回のタスクでは、Qdrantクラスタのスナップショット取得・復元を効率化・自動化するために、Spring Boot製のRESTfulなバックアップ・リストアAPIを開発しました。クラスタ内の各ノードに並列でリクエストを送信することで、一括でのスナップショット操作を可能にしています。
取得したスナップショットのメタ情報はTiDBに記録し、バックアップグループ単位で一元管理することで、リストア時の一貫性を確保しています。さらに、ノード数が不足する場合でも復元可能なmultiShardオプションを実装し、障害時や検証環境における柔軟な運用にも対応できるようにしました。
このAPIを導入することでできること
本APIの導入により、複数ノードへの一括バックアップ・リストアが可能となり、従来の手動オペレーションを排除して作業効率を大幅に向上させることができます。また、スナップショットをバックアップグループ単位で管理することで、復元時の誤操作を防ぎ、一貫性のあるリストアを実現しています。さらに、取得したスナップショットのメタ情報はTiDBに時系列で保存されており、モニタリングや運用計画に活用可能な情報資産として再利用が可能です。
今後の安定運用および機能強化に向けた取り組み
今後は、より安定した運用と機能拡充に向けて、以下の改善に取り組んでいく予定です。
まず、KubernetesのCronJobを活用したスナップショットの定期取得と自動削除機能を実装し、ストレージ運用の効率化と保守性の向上を図ります。
また、バックアップ処理中に中断された際にQdrant側に残る未参照スナップショットの検出・削除機構を整備し、不整合リスクを抑えるとともに、不要なストレージリソースの消費を防ぐことを目指します。
さらに、現状のAPIでは、ノードにシャードが配置されていない場合でも、コレクション・シャード設定情報のみを保持し、ポイントを含まない空のスナップショットが取得されてしまいます。このスナップショットをリストアすると、実際のポイントが存在しないため、シャードの状態がPartialになってしまい、手動で削除する必要があります。今後、バックアップ処理時にそのノードにシャードが存在しない場合はスナップショット作成を行わない、もしくはリストア処理時に空のスナップショットを除外するような制御を実装したいと考えています。
なお、バックアップ・リストア中に、データ更新があった場合は、シャードごとにデータの不整合が起こる可能性があるため、運用の中でデータ更新を停止する、もしくはバックアップ・リストア完了後にデータの整合性を確認するなどの対策が必要です。
おわりに
本記事では、アルバイトの中で行ったQdrantというベクトルデータベースのバックアップ・リストアAPIの開発について紹介しました。
このタスクを通じて、Qdrantのアーキテクチャや、Spring Bootを用いたAPI開発手法、kubernetesでの運用など多くのことを学ぶことができました。
開発の過程で、丁寧にご指導くださったDPUの皆様に深く感謝申しあげます。
今回の経験を今後のデータベース運用やデータ基盤の構築に活かしていきたいと思います。