
はじめに
こんにちは、ABEMA の広告配信システム開発チームに所属している2025年新卒の戸田朋花です。
この記事は KubeCon + CloudNativeCon Japan 2025 特集 Blog 10 日目の記事です。
本記事では、2025 年 6 月に東京で開催された KubeCon + CloudNativeCon Japan 2025 に参加した際、特に印象に残ったセッション「Exploring Tenant-centric Strategies to Simplify Multi-cluster and Multi-cloud Complexities」について、レポートします。
また、昨日、私が第二新卒としてサイバーエージェントに入社した経緯についてのインタビュー記事が公開されました。もしご興味があれば、あわせてこちらもご覧ください!
サイバーエージェント独自の第二新卒採用~若手社員に赤裸々インタビュー~
KubeCon 参加の背景
2025 年 1 月に、CNCF が提供する 5 つの Kubernetes 認定資格(CKA、CKAD、CKS、KCNA、KCSA)をすべて取得し、Kubestronaut の称号を得ることができました。
コミュニティに参加する中で、周りの Kubestronaut の方たちが KubeCon に参加している様子を見て、自分も興味を持つようになりました。
ちょうどそのタイミングで日本で初めて KubeCon が開催されると知り、ぜひ参加してみたいと思いました。上司に相談したところ快く承諾していただき、参加できることになりました。
資格取得を通じて身につけた基礎的な知識を土台に、より実践的な事例や最新の動向を学び、Kubernetes への理解をさらに深めることを目的に、KubeCon に参加しました。
マルチテナント・マルチクラウド運用の課題
マルチテナント・マルチクラウドでの運用は、Platform Team と Developer の双方にとって複雑です。
Platform Team は、複数のベンダー、アカウント、リージョン、リソースタイプが存在する膨大なクラウドリソースを管理しなければなりません。さらに、ベンダーごとにクラウドリソースの API 仕様が異なるため、統一的な管理が難しいという課題があります。また、リージョンやゾーンなど環境ごとに設定が一貫していないケースも多く、例えば高性能な GPU サーバーをプロビジョニングしようとしても、リージョンやゾーンによっては特定の GPU サーバーが存在しない場合があり、それを把握した上で正確に設定する必要があります。
一方、Developer も複数のツールや各クラウドサービスごとの違いによって、リソース管理が煩雑化しています。たとえば Ingress の設定ひとつをとっても、環境や用途によって nginx、Traefik、AI Gateway などを使い分ける必要があり、それぞれのツールや API の仕様を理解しなければなりません。
テナント中心戦略のアプローチ
これらの課題を解決するために、次の 4 つの目標が掲げられました。
- ツールやクラウドプロバイダーの違いを吸収する抽象化レイヤーの導入
- クラウドリソースのプログラム的なテンプレート化
- API 駆動型のプラットフォームの実現
- スキーマに基づくリソース設定の自動検証と管理
この目標を実現するため、提案されたアーキテクチャは Pkl、Prow、Crossplane、ArgoCD という 4 つの主要コンポーネントで構成されています。
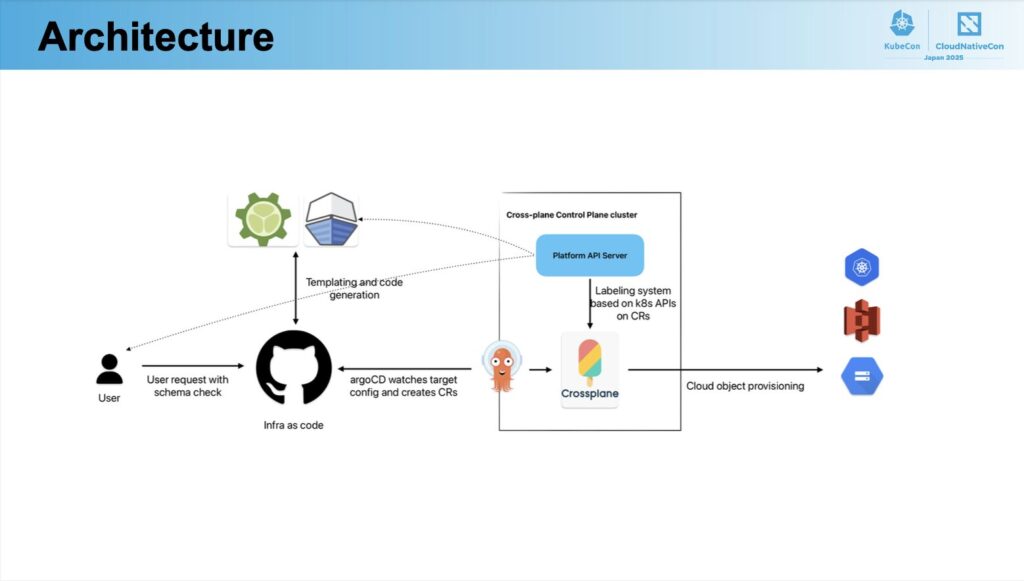
画像引用: https://static.sched.com/hosted_files/kccncjpn2025/b0/25-KC-Japan-Multi-Tenant-Multi-Cloud-v1.pdf
Pkl と Prow について知らなかったので、簡単に調べてみました。
Pkl
Pkl とは、configuration as code を実現する言語です。
YAML や JSON で記述するような設定ファイルを、Pkl から生成することができます。強い型システムを持つ Pkl でこれらの静的ファイルをテンプレート化することで、設定の再利用性や保守性を高めることが可能です。
Prow
Prow とは、Kubernetes ベースの CI/CD システムです。
Prow では、GitHub のイベント等を受け取り、job を実行することができます。また、ポリシーの強制、/foo スタイルのコマンドによるチャットオペレーション、自動 PR マージなどもサポートしています。
実際にインフラへ変更を加える際の流れは、以下の通りです。
- Developer が Pkl を使って必要なリソースを記述し、Git にコミットする。
- Prow が Git フローエンジンとして動作し、Pkl のスキーマ検証を行った上で、Crossplane の Claim などを自動生成する。
- 生成されたファイルをもとに Argo CD が実際の Crossplane リソースをデプロイする。
- Crossplane がリコンシリエーションフレームワークとして機能し、さまざまなリソースを望ましい状態に保ち続ける。
デモ
デモの内容はこちらに公開されています。
デモの内容を抜粋してご紹介します。
まず、以下のような内容を Pkl ファイルに記述します。
この設定では、「x-prod」という名前のバケットを AWS と Google Cloud それぞれの us-east-1 リージョンに作成することを要求しています。
buckets = new Listing<ResourceConfig.Bucket> {
new {
name = "x-prod"
region = "us-east-1"
}
}
このファイルをコミットし、プルリクエストを作成します。
プルリクエスト上で /codegen とコメントすると、新たな PR が自動生成され、以下のようにAWSとGoogle Cloud向けのファイルが出力されます。
# Code generated by kubecon-pr-generator. DO NOT EDIT.
apiVersion: s3.aws.upbound.io/v1beta1
kind: Bucket
metadata:
name: x-prod
spec:
forProvider:
region: us-east-1
providerConfigRef:
name: default
# Code generated by kubecon-pr-generator. DO NOT EDIT.
apiVersion: storage.gcp.upbound.io/v1beta1
kind: Bucket
metadata:
name: x-prod
spec:
forProvider:
location: us-east1
providerConfigRef:
name: default
このように、Developer はクラウドごとの違いを意識せず、リージョンやバケット名などの要件を宣言的に記述するだけで、複数クラウド向けの Kubernetes マニフェストを生成することができます。
この仕組みにより、クラウドごとの manifest の書き分けや API の違いによるミスを防ぎ、運用負荷やヒューマンエラーを大幅に軽減できると感じました。
終わりに
本セッションを通じて、クラウドごとに異なるリソース管理や設定作業の煩雑さを、宣言的な記述と自動化で大幅に簡素化できることを実感しました。
一方で、スキーマ設計は、かなり綿密に考える必要があり、相応の時間と学習コストが求められると感じました。また、すべてのユースケースにフィットするわけではなく、特殊な要件やクラウド固有の機能を使いたい場合は追加の対応が必要になるかもしれないと感じました。
今回紹介したセッションを通じて、大規模なシステムが実際にどのように運用されているのかを知ることができ、とても貴重な経験になりました。
このセッション以外にも面白い発表が多く、KubeCon に参加して本当によかったと感じています。
最後まで読んでいただき、ありがとうございました。
KubeCon + CloudNativeCon Japan 2025 特集 Blog
- KubeCon + CloudNativeCon Japan 2025 現地参加を最大限に活かす!現役エンジニアが注目するポイントと歩き方
- KubeCon + CloudNativeCon Japan 2025 1 日目参加速報
- KubeCon + CloudNativeCon Japan 2025 2 日目参加速報
- 生成 AI マーケットの不確実性に立ち向かうためのクラウドネイティブ技術
- 若手だけじゃない!ベテラン層だって活躍したい
- Cloud Native とサイバーエージェントのこれまでとこれから
- 2 node で HA 構成を実現する Extended Raft Algorithm 〜入社 2 年目 AJA 所属〜
- Kubernetes SIG Node に Deep Dive する 〜入社 1 年目 CIU 所属〜
- Kubernets を活用したインフラ基盤運用の安定化について 〜入社 2 年目 CIU 所属編〜
- テナント志向で考える、マルチクラスタ・マルチクラウド運用 〜入社 1 年目 ABEMA 所属〜 (👈 この記事)
- Argo CD x Cluster Inventory で実現するマルチクラスタ運用の新境地 〜入社 2 年目 ABEMA 所属〜