
はじめに
2026年に入社予定の井平淳也と申します。所属は京都大学大学院情報学研究科2年生で、普段は製薬プロセスにおける機械学習応用の研究をしています。今回は就業型アルバイト(内定者バイト)として、AI事業本部のDynalystという広告配信プロダクトで勤務していました。期間は2025年5月から6月の2ヶ月間で、データサイエンティスト(DS)のタスクを行っていました。
内定者バイトでは、Dynalystで運用されている機械学習モデルを対象とし、ハイパーパラメータを変更した際のモデル挙動の分析を行いました。
具体的なタスクは以下の2つです。
- 埋め込みベクトルの次元を変更した際のモデル挙動分析(本記事)
- ハッシングサイズを変更した際のモデル挙動分析
本記事では特に、「埋め込みベクトルの次元を変更した際のモデル挙動分析」についてご説明します。(以降、埋め込みベクトルの次元はkと呼称します。)
前提知識
プログラマティック広告とDynalyst
最近のインターネット上の広告は、見る人に合わせて内容が変わるようになっています。例えば、あなたが以前に見たことのある商品や、興味がありそうなゲームの広告が表示されることはないでしょうか。これは、広告が「決まったものを一律に出す」のではなく、「見る人ごとに最適な広告をその場で選んで表示する」仕組みになっているからです。このような仕組みの広告は、「プログラマティック広告」と呼ばれています。簡単に言うと、ネット上の広告スペース(=広告枠)がオークションのように自動で売買されていて、そのたびに「誰に、どんな広告を出すか」が瞬時に決まっているのです。オークションは約100ミリ秒の間に完了し、最も高い金額を提示した広告が表示されます。
この広告オークションで入札を行うのが、「DSP(Demand Side Platform)」と呼ばれるシステムです。DSPは、広告を出したい企業の代わりに、自動で入札し、広告を表示させる役割を担います。Dynalyst(ダイナリスト)は、DSPの一つです。
Dynalystは、特にスマートフォン向けのゲーム広告を得意としています。その中でも注力しているのが、「以前そのゲームをプレイしていたが、今はプレイしなくなったユーザー」に対して広告を出すことです。このように、過去に関心を示した人に再びアプローチする広告手法を「リターゲティング」といいます。リターゲティングは、「一度興味を持った人は、再びプレイしてくれる可能性が高い」という考えに基づいており、Dynalystの強みの一つとなっています。
プログラマティック広告の仕組みとDynalystの位置付けについて、以下の図1を参照しつつ詳細に説明します。図1の番号と、以下の番号は対応しています。
- ユーザーがウェブサイトなどのメディアを訪問します。ここで、メディアを訪問した際、最初から広告が表示されているわけではなく、広告枠のみが存在します。
- メディアは空の広告枠に対し、SSP(Supply Side Platform)に広告をリクエストします。SSPは、広告枠のオークション開催者のようなものです。
- オークション開催者であるSSPが、参加者であるDSPに対し、広告枠を出品します。
- DynalystをはじめとするDSPは、出品された広告枠に入札します。このとき、広告主から預かった広告もSSPに送信します。
- 最も高い額を入札したDSPが落札に成功します。図1ではDynalystの落札が成功しています。この場合、SSPはメディア側にDynalystの広告を送信します。
- メディアは受け取った広告を表示します。ユーザーは表示された広告に対し、アクションを取ります。(無視・閲覧・クリック・商品購入など)
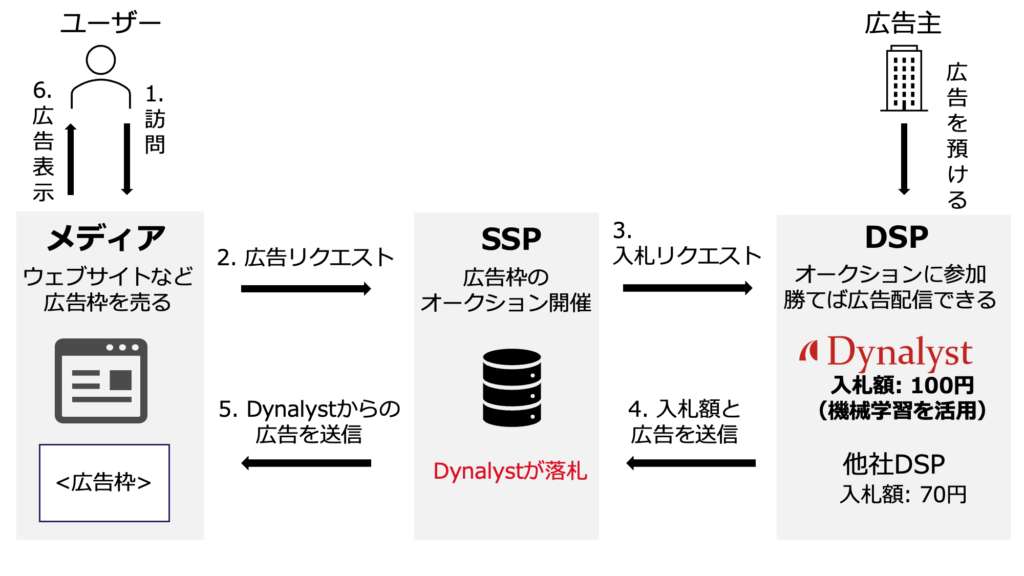
図1:プログラマティック広告の仕組み。DynalystはDSPであり、広告枠の入札を担当します。Dynalystでは、入札額の決定に機械学習を活用しています。
プログラマティック広告の各プレーヤーについてまとめると、以下のようになります。
- ユーザー:広告を見る
- メディア:広告を表示する
- SSP:広告枠を出品する
- DSP(Dynalystはここ):広告枠に入札する。
- 広告主:広告を出す
入札額決定と機械学習
Dynalystでは、広告枠の入札額決定に機械学習を使用しています。入札額の決定は、以下の手順で行われます。
- SSPからメディア情報とユーザー情報が提供されます。メディア情報はメディアIDや広告枠の位置など、ユーザー情報はユーザーの端末IDなどです。
- 機械学習を用いて、ユーザーが広告をクリックする確率(CTR)とクリックした後CVする確率(CVR)を予測します。CVとはコンバージョンの略で、ログイン、購入など、広告主がユーザーに行って欲しいアクションのことです。
3. CTRとCVRをもとに広告枠の入札額を決定します。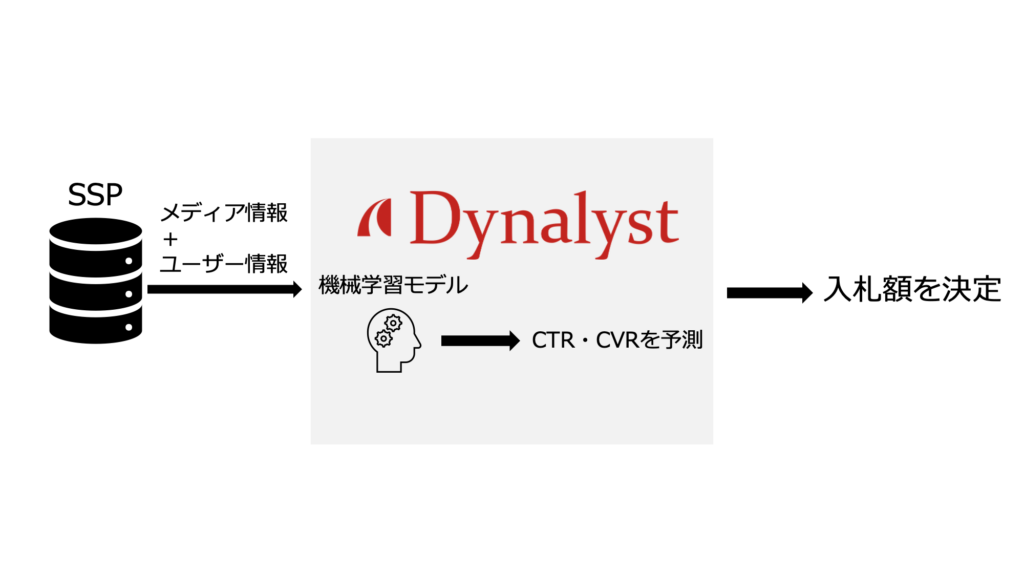
図2:入札額決定の手順。SSPからのメディア情報とユーザー情報をもとに機械学習モデルがCTR・CVR予測を行います。CTR・CVR予測に基づき、入札額が決定されます。
入札額の設定は、プロダクトのCPA(CV獲得にかかる費用)等の広告効果指標に影響します。入札額を高くし過ぎると、たとえ広告枠を落札できてもCPAが上昇し、逆に低く設定しすぎると、そもそも広告枠を落札できず、配信機会を失ってしまいます。よって、適切な入札額の決定が重要であり、そのためには精度の高いCTR・CVR予測が不可欠です。
機械学習モデル:FFM
Dynalystで主に運用されている機械学習モデルはField-aware Factorization Machines [1](FFM)です。FFMは大規模かつスパースなデータが得意なモデルです。推論速度と精度のバランスがよいことから、Dynalystで採用されています。
FFMの前身:FM
(本ブログでは数式が直接入力できないため、数式を含めた文章は全て画像で表示しています。)


FFM

背景
DynalystのFFMモデルは、埋め込み次元kが4程度の小さい値に固定されています。kを上げることでモデルの表現力が向上し、モデル精度の改善が見込まれます。モデル精度が改善することで、より適切な入札額が決定できるようになり、広告効果(CPAなど)の改善が狙えます。しかし、kを上げることで、メモリ使用量や推論速度への悪影響も予想されます。どれだけ精度が上がっても、メモリ不足やレスポンス速度低下を招くようでは運用上問題です。したがって、kを変更する際には、モデル精度だけではなく、メモリ使用量や推論速度への影響も含めて定量的に評価する必要があります。
これを踏まえて、本分析の目的を以下のように設定しました。
目的
- 埋め込み次元kの変更によるモデル精度・学習・推論への影響を定量的に評価する
- モデル精度の改善幅
- モデルサイズ、メモリ使用量、推論時間の悪化具合
- 定量評価を受けて、kを増加すべきか判断する
本検証は、ローカルにて複数のkの値でFFMを学習し、性能比較を行いました。
実験
データセット
実際のメディア情報、ユーザー情報とCV有無のデータを用いて実験しました。データセットの変数は、広告主ID、ユーザID、ユーザーの最終ログインからの経過時間、CV有無などでした。データセット中にCVしたユーザーは少なく、不均衡なデータとなっていました。
モデルと実験条件
実際にCVR予測に用いられているFFMモデルの1つを実験対象としました。なお、現状運用の埋め込み次元はk=4が用いられています。
本実験での埋め込み次元kの探索範囲は以下の値を用いました。
探索範囲: k ∈ {1, 2, 4, 8, 16, 32, 64, 128}
探索範囲が2のべき乗の理由:SIMD命令との相性がよく、並列処理の効率が上がるためです。
なお、k以外のハイパーパラメータ(学習率、正則化パラメータ、最大エポック数)は固定して実験しました。
広告主ID、ユーザーID、ユーザーの最終ログインからの経過時間などを説明変数とし、CV有無を予測する2値分類モデルを構築しました。
性能評価指標
モデル精度の評価指標はLoglossとAverage Precisionを用いました。

Average Precision
予測確率でデータを降順にソートし、各閾値での Precision(適合率)と Recall(再現率)をプロットします(Precision-Recall 曲線)。このPrecision-Recall 曲線の下側面積がAverage Precisionとなります。Precision-Recall 曲線とAverage Precisionの例は、以下の図3を参照してください。Average Precisionは、閾値を変えた時の平均的なPrecisionと言えます。また、不均衡データのモデル精度評価に適切であるとされています。
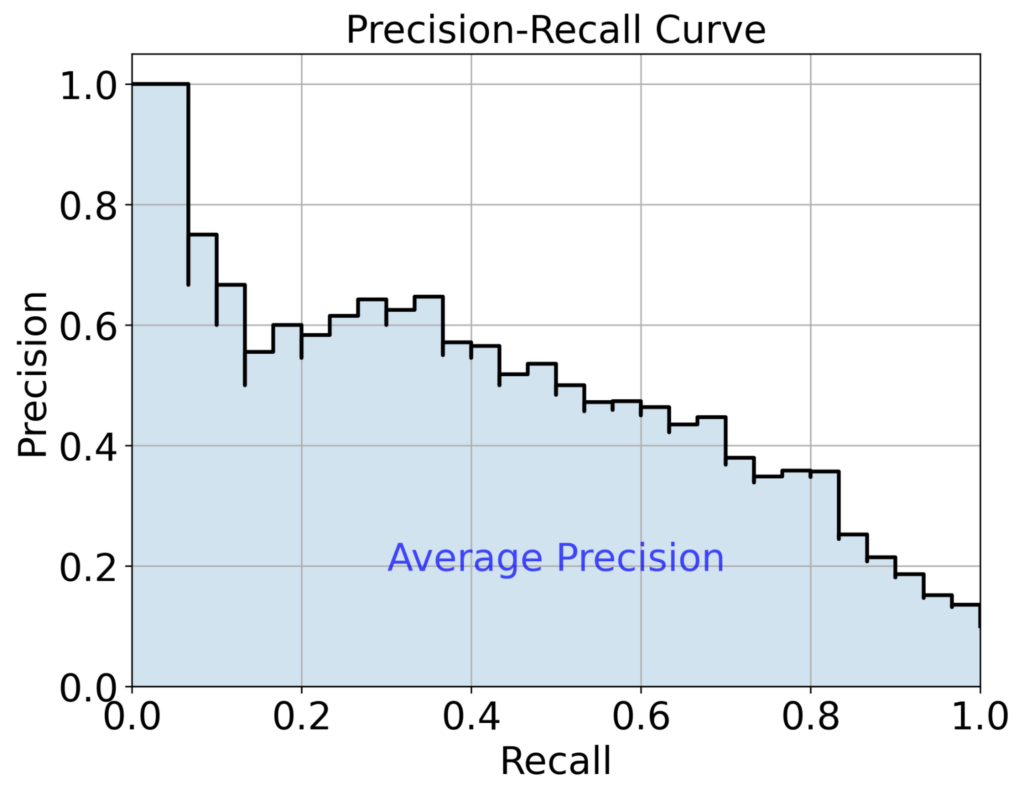
図3:Precision-Recall 曲線の例。曲線の下の面積がAverage Precisionです。
PrecisionとRecall:
Precision = 「正例予測のうち、本当に正例であった割合」
Recall = 「実際の正例のうち、モデルが正例と予測できた割合」
実験手順
以下の手順で実験を行いました。
- データ準備
生データを準備します。 - 前処理
生データのカテゴリ列をハッシング処理により数値列に変換します。
(なお、別タスクでハッシング処理に関する分析も行いました) - 訓練データとテストデータの分割
前処理後のデータを3:1に時系列分割し、訓練データとテストデータに分けます - 埋め込み次元 kの選択
kを以下の探索範囲から1つ選びます。
k ∈ {1, 2, 4, 8, 16, 32, 64, 128} - エポック数のチューニング
- バリデーションデータの準備
訓練データを9:1にランダム分割し、チューニング用訓練データとバリデーションデータに分けます。 - 最適なエポック数の決定
FFMをチューニング用訓練データで学習します。このとき、各エポックごとのバリデーションデータに対するLogloss(Val loss)を計算します。Val lossが最小になったエポック数を最適なエポック数として採用します。
- バリデーションデータの準備
- 本学習
訓練データを用いてFFMを学習します。この際のエポック数は、5(b)で最適化したエポック数を使います。 - 推論とモデル評価
学習したFFMモデルを用いて、テストデータに対する LoglossおよびAverage Precisionを計算します。 - 全kの値で実施
手順4-7を、探索候補すべてのkについて繰り返し実行し、各kにおける性能を記録します。
なお、各処理におけるメモリ使用量および処理時間を計測しました。
結果と考察
(グラフ縦軸の値は社外秘であるためマスクしています。)
モデル精度
結果:kを大きくするとモデル精度が悪化
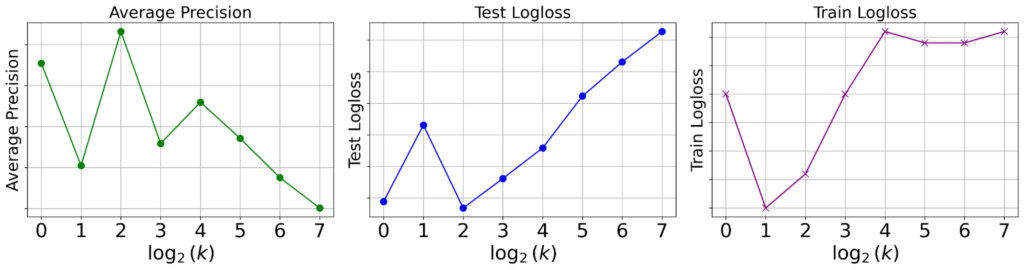
図4: 各kの値におけるモデル精度。現状設定である k=4 において、Average Precision, Test Loglossともに最高性能となりました。逆にkを上げていくと両者とも悪化しました。
現状の設定である k=4 において、Average Precision(AP)が最大になりました。逆にkを上げていくとAPは悪化しました。同様に、Test Loglossもk=4において最小となりました。当初の仮説では、kを上げることでモデルの表現力が上がり、性能が改善すると考えていたため、それに反する結果となりました。
考察:精度が悪化した理由
kの増加により精度が悪化した理由として、以下の仮説を考えました。
仮説1:正則化の効果が足りなかった
kが大きくなると、学習すべきパラメータ数が増えます。一般的にパラメータ数が増えるとモデルの表現力が上がり、過学習しやすくなります。過学習を抑えるためには、パラメータ数に応じて正則化も強くかける必要がありますが、今回は正則化パラメータを固定して実験してしまいました。これによって正則化の効果が足りず、kを大きくして逆に性能が下がってしまった可能性があります。対処法としては、エポック数だけでなく正則化パラメータもチューニング項目に加えることが考えられます。
仮説2:データ量が少なかった
kが大きくなると、学習すべきパラメータ数が増えます。一般的にデータ量が固定の状態でパラメータ数が増えると、モデル学習が難しくなります。これが原因で、kを大きくして性能が下がってしまった可能性があります。対処法としては、学習データ量を多くすることが考えられます。
モデルサイズ
結果:増加したが許容範囲
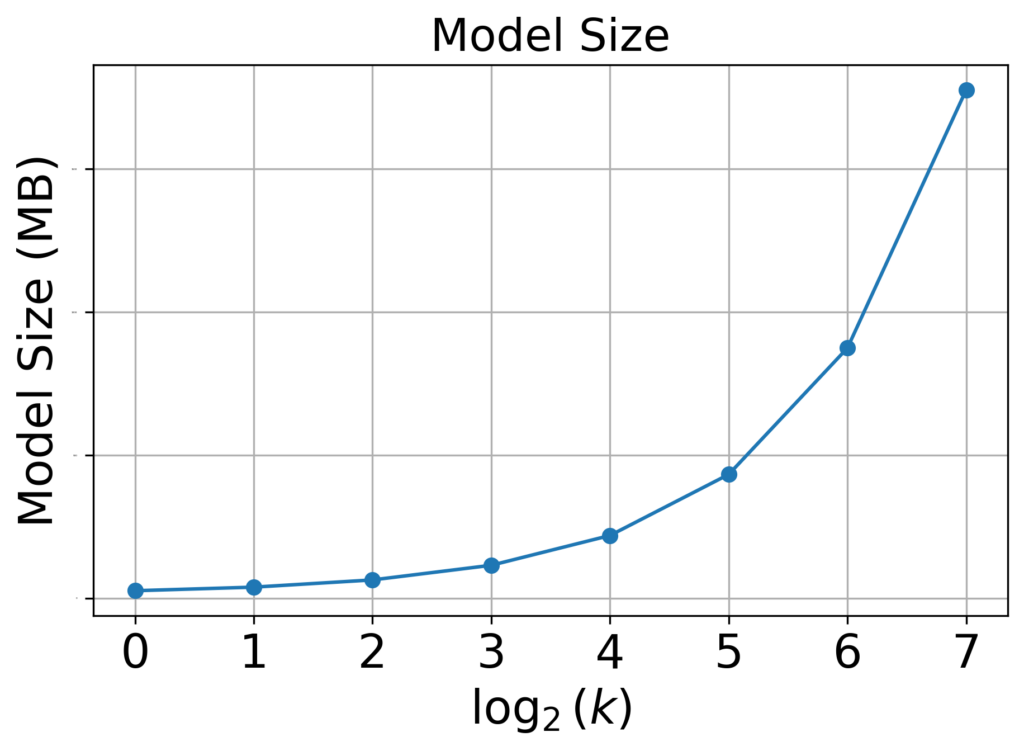
図5:各kの値におけるモデルサイズ。kを大きくすると増加しましたが、増加量は許容範囲でした。
kを大きくするにつれてモデルサイズも増加しました。しかし、推論サーバーのストレージを圧迫するほどではありませんでした。探索範囲最大値のk=128でも問題ない増加量だと考えています。
考察:モデルサイズが増加した理由
FFMのパラメータ数は「ハッシングサイズ x フィールド数 x 埋め込み次元k」で決まります。kが増えることでパラメータ数が増え、それに応じてモデルサイズも増加したと考えられます。FFMパラメータの詳細と具体例に関しては、以下の図6を参照してください。

図6:FFMパラメータの詳細と具体例。全体のパラメータサイズはハッシングサイズ x フィールド数 x 埋め込みベクトルの次元kになります。
最大メモリ使用量
結果:最大メモリ使用量は変わらない
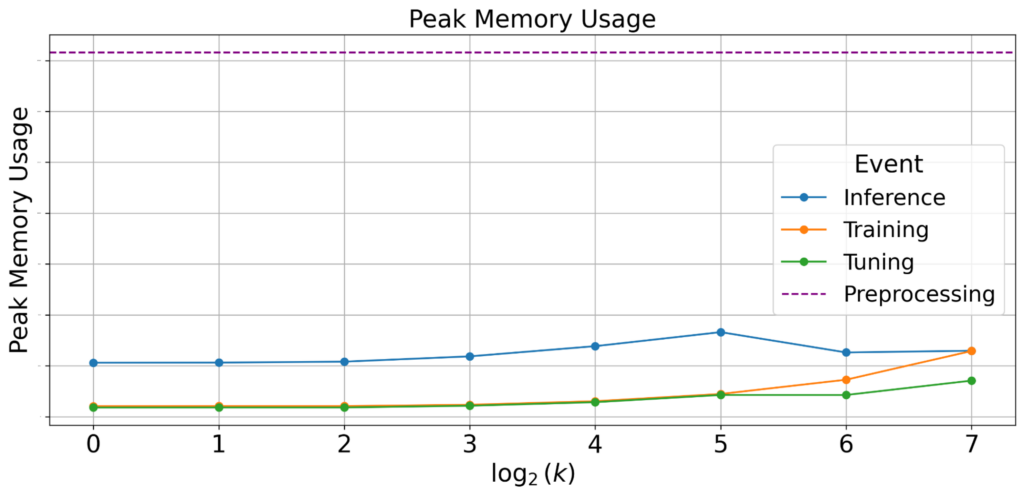
図7:各Eventにおける最大メモリ使用量。kが増えても最大メモリ使用量は変わりませんでした。
kが増えると、学習時とチューニング時における最大メモリ使用量が増加しました。しかし、前処理時の最大メモリ使用量が支配的になりました。kの大小は前処理の挙動に影響を与えないため、現実的なkの範囲では常に前処理のメモリ使用量がボトルネックになると考えられます。そのため、kを増加させた際の最大メモリ使用量は変わらないといえます。
学習・チューニング時間
結果:伸びたが許容範囲
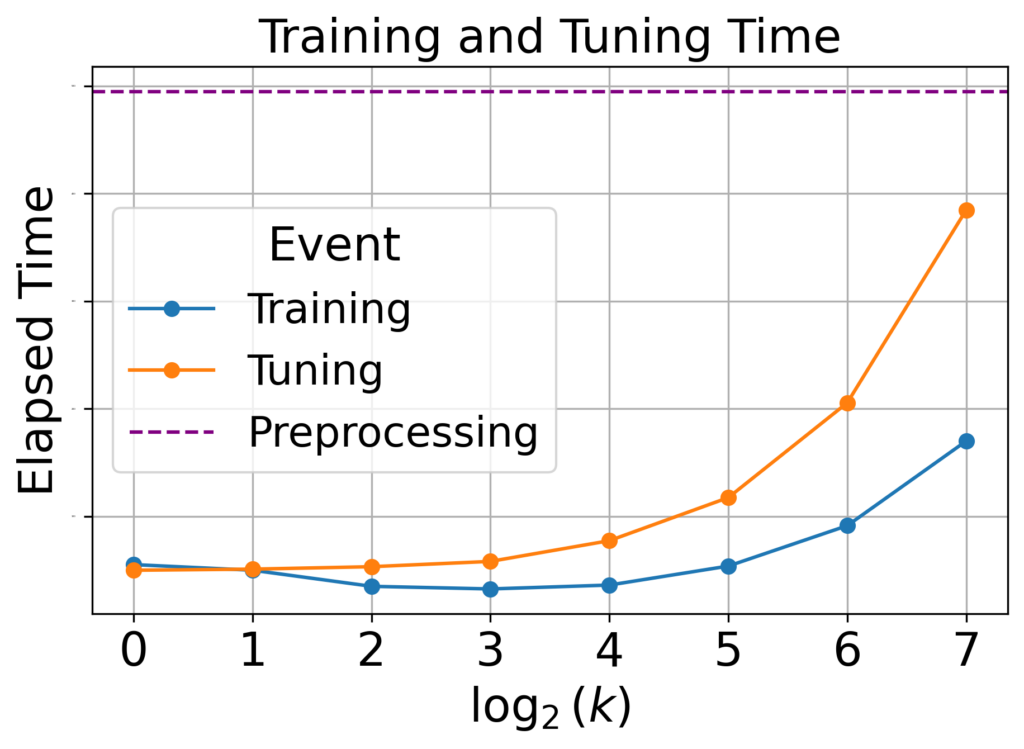
図8:各kの値における学習・チューニング時間。kが増えると増加しましたが、増加幅は許容範囲内でした。
kが増えると、学習時間とチューニング時間が増加しました。しかし、探索範囲最大値のk=128であっても、学習・チューニング時間は前処理時間より短く、許容範囲内といえます。
考察:学習・チューニング時間が伸びた理由
学習時間が増加した要因は、k の増加に伴い、学習すべきパラメータの数が増加したためであると考えられます。なお、kの増加によってパラメータ数が増加することは、「モデルサイズ」に関する考察からも確認できます。
推論時間
結果:悪化したが許容範囲
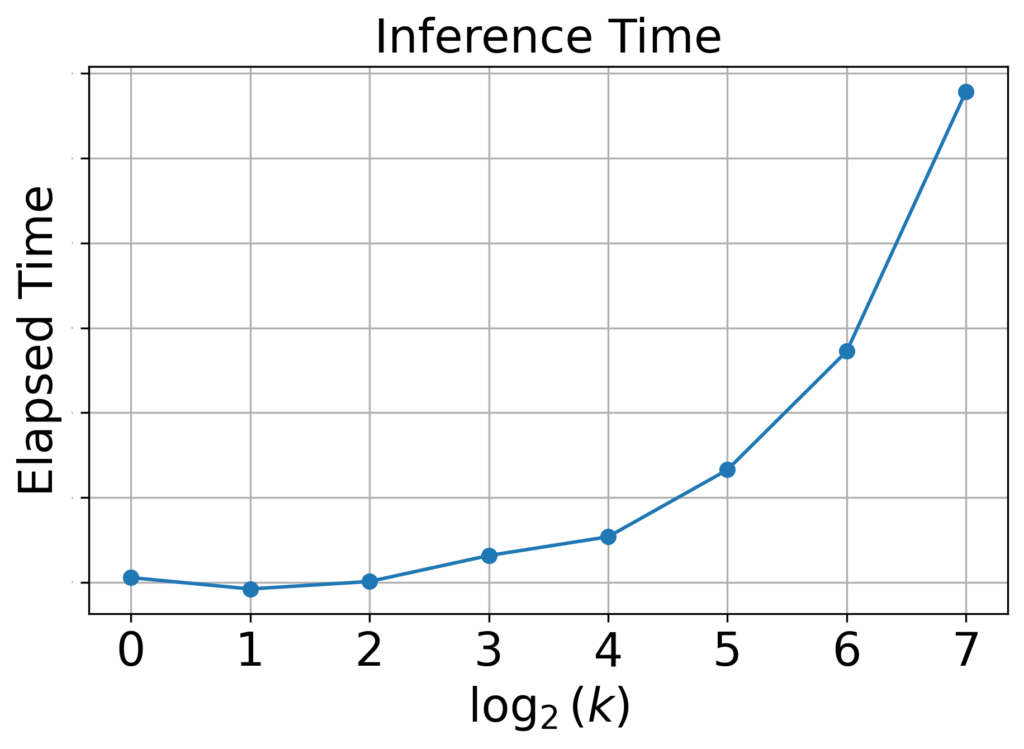
図9:各kの値における推論時間。kを増加させると推論時間は増加しましたが、増加幅は許容範囲内でした。
DSPプロダクトでは、入札リクエストを受けてからレスポンスを返すまでのトータルレイテンシーを100 ms以内に抑える必要があります。詳しい値は出せませんが、探索範囲最大値のk=128であっても、推論時間は依然として許容範囲内に収まることが確認できました。そのため、今回のkの探索範囲内では、入札レイテンシーの制約はクリアできると結論づけました。
考察:推論時間が悪化した理由
推論時間が増加した要因は、推論時の演算回数が増えたためだと考えられます。FFMの推論では、埋め込みベクトル同士の内積をとりますが、埋め込みベクトルの次元kが増加すると、内積時の加算乗算の回数が増えます。これにより、推論時間が増加したと考えられます。推論時間増加のメカニズムに関しては、以下の図を参照してください。

図10:FFMの推論時間増加のメカニズム。
結論
kを増加させたところモデル精度が悪化したため、kの増加導入は見送ることにしました。
モデル精度が悪化した理由として、正則化パラメータを固定してしまったからであると考察しました。また、kの増加に対してデータ量が足りなかった可能性もあります。
結果まとめ
- モデル精度:悪化した。
- モデルサイズ:増加したが許容範囲。
- 最大メモリ使用量:変化なし。
- 学習時間:悪化した(伸びた)が許容範囲。
- 推論時間:悪化した(伸びた)が許容範囲。
おわりに
学び
「分析の動機」の書き方
タスクの分析結果などは、プロダクト側の知見としてNotionにまとめていました。トレーナーの大塚さんに添削・FBをたくさんいただき、その中で「分析の動機」の書き方について、特に勉強になりました。
DSが分析を行う際、「なぜその分析を行うのか?」を説明する必要があります。ここで、単に「メカニズムが解明されていないから取り組む」のではなく、「ここを改善するとプロダクトにこのようなメリットがある」 というビジネス的な意義が必要になります。研究では「未知の問題を解き明かす」という動機でもいいですが、プロダクト起点の分析では「事業課題の解決」という動機付けが求められます。この2つを区別して考える視点を得られたのは、大きな収穫であったと考えています。
機械学習モデルの運用面
普段はモデル精度の向上を主眼に置いた機械学習の研究を行っており、運用面についてはあまり意識していませんでした。しかし今回、プロダクトで機械学習を使うためには、メモリ使用量や推論速度といった運用上の制約を考慮する必要があることを痛感しました。また、モデルの学習管理やバージョン管理、メトリクスの管理といった MLOps の基本的な知識・技術が不足していることも実感しました。今後は、個人開発などでMLOpsの勉強を進めていきたいと考えています。
スケジュール管理の重要性
トレーナーの大塚さんのスケジュール管理が勉強になりました。作業工数をしっかり見積もったうえで締め切りを設定されている姿を見て、普段の仕事でそこまで意識できていなかった自分に気づかされました。実際、普段よりも余裕を持って仕事を進められ、肉体的にも、精神的にもゆとりがありました。社会人として働く前に、スケジュール管理の重要性を理解できてよかったです。
反省
下調べの重要性
FFM の原著論文には、k を変えても Logloss の改善効果はほとんどなく、むしろ学習率や正則化パラメータの調整が有効だと記されていました。今回の実験ではデータセットが異なるものの、そもそもkを変更するアプローチ自体に限界があった可能性があります。この点に気づけたのは実験と分析を終えた後で、事前に原著論文をしっかり読んでおくべきだったと反省しました。
感謝
2ヶ月間という短い期間ではありましたが、トレーナーの大塚さん、DSマネージャーの清水さんをはじめとするDynalystの皆様には大変お世話になりました。心より感謝申し上げます。
参考文献
[1] Juan, Yuchin, Yong Zhuang, Wei-Sheng Chin, and Chih-Jen Lin. 2016. “Field-Aware Factorization Machines for CTR Prediction.” In Proceedings of the 10th ACM Conference on Recommender Systems, 43–50. New York, NY, USA: ACM. https://doi.org/10.1145/2959100.2959134.
[2] Rendle, Steffen. 2010. “Factorization Machines.” In Proceedings of the 10th IEEE International Conference on Data Mining, 995–1000. Sydney, Australia: IEEE Computer Society. https://doi.org/10.1109/ICDM.2010.127.