
| 💡 このドキュメントは、2025年7月の時点でPreview FeatureであるGoogle Cloud BigtableのMaterialized ViewおよびSecondary Indexに関する記事です。正式リリース後には内容が一部変更される可能性があります。 |
こんにちは。AbemaTV Platform Backendチームのユシンです。現在、ABEMA内ではBigtableを多様なサービスで活用しています。Bigtableの限界点を克服し、多様なワークロードを構成するためのBigtableの新機能であるMaterialized ViewとSecondary Indexを、ABEMA内で導入した事例をご紹介します。
Google Bigtable
Google Bigtableは、Googleが開発したフルマネージドの分散型NoSQLデータベースサービスで、ペタバイト(PB)規模の時系列・行列データに最適化されています。バックエンドエンジニアの視点から見たGoogle Bigtableの特徴を要約すると、以下の通りです。
- ペタバイト規模のNoSQL OLTP用データベース(ミリ秒単位の読み書きを提供)
- LSM Treeインデックスを使用(MemTableとSSTable)
- Key Range Partition
- Wide-Column
Google Bigtableは、LSM TreeとKey Range Partitionに起因する構成可能なワークロードが明確であるため、この2つの特徴について見ていきたいと思います。
LSM TreeとKey Range Partitionの構成説明
LSM TreeはMemTableとSSTableで構成される単純なデータベースで、単一キー(Google BigtableのRow Key)でソートされるSequential Scanに強みがあります。代表的な他のデータベースとしては、CassandraやHBaseなどがあります。大容量の書き込みに最適化された分散型データベースです。
LSM TreeとKey Range Partitionを動きを理解するための簡略化された図と説明です。
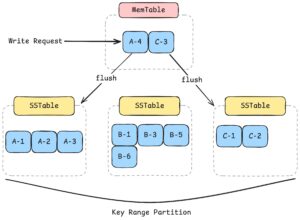
書き込みプロセスとデータ保存構造を簡潔に見ると、以下の通りです。
- まず、書き込みリクエストはMemTableに保存されます
- その後、データはrow keyによってKey Range Partitionされ、SSTableにソートされた形で保存されます
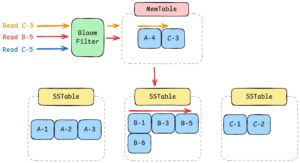
読み取りプロセスはもう少し複雑です。簡潔に図式化したプロセスは以下の通りです。
- すべてのLSM Treeの読み取りリクエストは、まずBloom Filterを経由します。Bloom FilterはRowKeyをハッシュ化して作成したデータ構造で、存在しないキーに対する性能改善が可能なデータ構造です。
Read C-3の場合、Bloom Filterを通過した後、まずMemTableを確認します。C-3データはMemTableに存在し、MemTableもSSTableと同様にソートされています。インメモリであるため、高速にスキャンしてデータを応答します。Read B-5の場合、Bloom Filterを通過した後、まずMemTableを確認します。B-5は既にストレージにFlushされているため、SSTableでスキャンを開始します。順次スキャンし、B-5はパーティショニングされた2番目のSSTableの3番目のインデックスで発見され、応答します。(実際には最も小さい単位、おそらくBlock単位でScanする可能性が高いです)Read C-5の場合、Bloom Filterからキーが存在しないという結果を受け取り、即座に応答します。(キーが存在するという結果を受け取ってからスキャンする場合もあります)
Bigtableの注意点と限界点
上記のようなLSM TreeとKey Rangeパーティショニングにより、Bigtableを使用する際には以下のような注意点があります。
- LSM Treeで効率的に読み取るためには、Key(BigtableのRow Key)を基準に読み取りリクエストを行う必要があります。行キーを指定しないとFull Scanで行われます。
- SSTableとKey-Rangeパーティションの組み合わせにより、分散とソートの両方が必要です。Multi-Node Key Range PartitionにおけるRead Hot Spot Nodeを防ぐため、まずRow keyに分散されたユニークキーが必要です。また、このUnique Keyと共にソートに使用される値がRow Keyに必要となります。一般的には
UniqueID#Timestampという形式になります。 - LSM Tree構造を読み取る際にはSequential Scanを行うため(SkipListなどが存在する場合もありますが)、基本的にソートがAscendingであれば、小さいキーを読み取る方が最も高いパフォーマンスを発揮します。SSTableの最後のインデックスに位置するデータを読み取ると、そのSSTable全体のSequential Scanが発生します。
- MemTableの存在により、最近書き込まれたデータに対する読み取り性能が高い可能性があります。
- すべてのリクエストはBloom Filterを経由し、Sequential Scanを行うため、Random Accessの性能は低くなります。100個のデータに対するSQLの
WHERE INのようなリクエストは、100回のBloom Filterへのリクエストが発生します。
つまり、Bigtableで採用されているLSM TreeとKey Rangeパーティションは、「Single-Column(Row Key)によるSequential Scan」を強制するという特徴があります。大容量の書き込みとCompactionに強みがあり、このような特徴から、GoogleはBigtableのUsecaseとしてIoT、広告、ログ収集などを挙げています。多様なフィルターやソートが要求される可能性がある場合は、Bigtableではなく、B-Treeを使用するPostgreSQLやMongoDBなど、他のデータベースをまず検討することをお勧めします。
事例: ABEMA Chatサービス
ABEMA ChatサービスのメッセージRow Keyは、hex#chatID#Timestampのような形式で保存されていました。Chatサービスの場合はキー範囲によるチャットメッセージのクエリを行っていたため、下記のような実装を使用していました。しかし、新しく登場した要求事項は、既存のRow Keyの2番目の引数を利用した最新順クエリが可能である必要がありました。これを簡単に表でまとめると以下のようになります。
| 区分 | 既存 | 要求事項 |
|---|---|---|
| ユースケース | _keyの範囲を利用したクエリ | ChatIDを利用した最新順クエリ |
| クエリ例 | WHERE _key IN (key range) |
WHERE ChatID = ? ORDER BY Timestamp DESC |
| RowKey Spec | hex#chatID#Timestamp |
chatID#Timestamp |
| RowKey 例 | 0036cfd5#unique-chat-id#2025-01-01T00:00:00 | chat_id:unique-chat-id,reversed_timestamp:8264310399 |
Google Bigtableの限界を克服する Materialized View & Secondary Index
これまで見てきたGoogle Bigtableの限界点は、「Single-Column(Row Key)によるSequential Scan」に起因します。多様なフィルターやソートの要件を実装するためには、Row Keyの柔軟な変更が求められます。Materialized ViewとSecondary Indexは、このようなRow Keyの変更をより簡便に実現してくれるGoogle Bigtableの新しいFeatureです。
Materialized View (具体化ビュー)
Materialized Viewは、一般的なViewとは異なり、実際に物理的なデータを持つViewを意味します。つまり、一つのMaterialized Viewは一つのテーブルと同一のデータとSLAを持つことになります(現在はPreview Featureであるため、SLAは保証されていません)。Materialized Viewを実装するためには、独自のデータプロセッシングパイプラインが必要となります。しかし、Google BigtableのContinuous Materialized Viewはこのような作業を単純にクエリで作成するのができます。
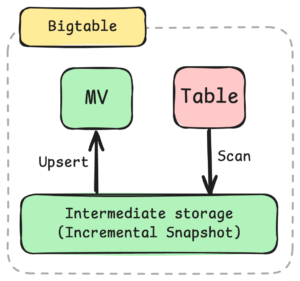
Google Bigtableは細かく紹介されてないですが、Intermediate StorageにScanしこのデータを利用してIncremental Updateをしていますと紹介されてます。おそらく絵のような構造だと慎重に推測してみます
Implementation
Materialized ViewはTerraformで定義でき、以下のように実装できます。
resource "google_bigtable_materialized_view" "name" {
materialized_view_id = "viewName"
instance = google_bigtable_instance.main.name
deletion_protection = true
query = "SELECT ..."
depends_on = [
google_bigtable_table.main
]
}
Materialized Viewの強み
- Managed Data Processing Pipeline : SQLを定義するだけでMaterialized Viewの作成が可能で、リアルタイムで同期されます。BigtableのMonitoringを通じて同期遅延時間を確認できます
- 既存テーブルを変更せずに新しいデータ構造を定義可能 : 既存のテーブルを変更することなく、新しい要件に対応する新しいデータ構造を定義することが可能です。
- Wide-Column互換 : 既存のカラムファミリーのTimestampのCellデータを同期可能です。
- Low-Priority Batch Job : Materialized Viewの同期プロセスは、低優先度のバッチジョブとして動作し、Read/Writeに影響を与えないと紹介されています。ただし、Materialized View作成クエリの負荷が深刻になる可能性については検討が必要です。
Materialized Viewの注意点
- 現在、1つのTableに1つのMaterialized Viewのみ作成可能 : 正式リリース版からはこの制限はなくなると嬉しいです。
- Materialized Viewのクエリ修正は不可 : 作成されたMaterialized Viewのクエリを修正することはできず、これは技術的にInitial Snapshot(Full Snapshot)処理がかなり難しい作業であるため、今後もサポートされない可能性が高いです。クエリを修正するためには、テーブルを削除して再作成するプロセスが必要です。
- Eventual Consistency : Materialized ViewはEventual Consistencyをサポートします。実際に動作確認したところ、MilliSecnod(ms)水準のNear Real-Time同期を確認しました。
上記の(1)番(2)番は、現状ではかなり致命的です。テーブル一つにつき一つのMaterialized Viewしか作成できないため、クエリの修正が必要な場合、稼働中のデータベースを削除して再作成する過程でダウンタイムが避けられません。新機能の開発では導入可能ですが、本番環境では修正が不可能な状況です。ただし、前述の通り、おそらく正式リリース版からはテーブルごとに一つのMaterialized Viewしか作成できないという制限はなくなる可能性が高いです。そうなれば、テーブル名を変更して新規作成するプロセスで、Materialized Viewのスキーマを変更できるようになるでしょう。
Secondary Index
Secondary access patterns: Continuous materialized views create an alternative representation of your data. This representation can be optimized for queries with different lookup patterns than those that you use in queries against the source table. For more information about these patterns, see Create a global secondary index.
Materialized Viewの基本的なコンセプトは、LSM Treeの長所を活かした集計(Aggregation)にあります。しかし、Materialized Viewのユースケースでも紹介されているように、Row keyを変更して多様な要件に対応可能なクエリを実現することも、Materialized Viewを通じて解決できます。一般的にMaterialized ViewはAggregation QueryとGROUP BYを要求しますが、集計を行わずにORDER BYを定義することで、Secondary Index Materialized Viewを作成することができます。以下は、Row Keyを変更するChat Bigtableでのクエリ例です。
SELECT
chat_id AS chat_id,
reversed(timestamp) AS reversed_timestamp,
_key AS key, -- 必須
table.addtional_data
FROM table
ORDER BY chat_id, reversed_timestamp, key
上記のクエリは、RowKeyに対して以下のような変換を処理します
| 変換前 | 変換後 | |
|---|---|---|
| RowKey Spec | hex#chatID#Timestamp |
chatID\x00\x01Timestamp |
| RowKey (_key) | 0036cfd5#unique-chat-id#2025-01-01T00:00:00 | unique-chat-id\x00\x018264310399 |
| Structured Row Key | chat_id:unique-chat-id,reversed_timestamp:8264310399 |
Secondary Indexの注意点
- ORDER BYの順序でStructured Row Keyが生成される : これはBigtableのもう一つのFeatureですが、
ORDER BYで定義された順序でStructured Row Keyが生成されます。Structured Row Keyは、SQLを利用した_keyカラムのクエリは不可能です。 - 区切り文字
\x00\x01でRowKeyが生成される : Googleのドキュメントに直接的な言及はありませんが、ORDER BYで定義された順序で区切り文字(delimiter)を含んだRow Keyが生成されます。このときに生成される区切り文字は\x00\x01です。このRow Keyを利用してReadRows演算が可能です。delimiterを変更するオプションはありません。 - 別のテーブルとして扱われる : BigtableのSecondary Indexは、他のデータベースのインデックスとは異なり、Materialized Viewとして生成されるため、完全に別のテーブルとして扱われます。Bigtableのgolang SDKの
TableAPIインターフェースを通じてテーブルのように使用できます。
Secondary Indexを利用したGolangの例
func ReadRowsRange(start int64, end int64) (string, string) {
const rowKeyDelimiter = "\x00\x01"
start := fmt.Sprintf("%s%s%s", params.ChatID, rowKeyDelimiter, start) // {chatID}\x00\x01{start}
end := fmt.Sprintf("%s%s%s\xff", params.ChatID, rowKeyDelimiter, end) // {chatID}\x00\x01{end}
return start, end
}
func List(client *bigtable.Client) {
var materializedView bigtable.TableAPI
materializedView = client.OpenMaterializedView(tableName)
start, end := ReadRowsRange(startTimestamp, endTimestamp)
read := func(row bigtable.Row) bool {
// ...
}
materializedView.ReadReadRows(
ctx,
bigtable.NeWRange(start, end),
read
)
}
費用
Storage – You are charged to store the data in the continuous materialized view and for intermediate storage. For more information, see Storage.
Compute – The ongoing syncing of the source table and the continuous materialized view requires CPU processing, and your clusters might need more nodes to handle the additional background work.
Materialized ViewとSecondary Indexを構成するためのコストは、主にストレージコストとコンピューティングリソースに分けられます。コンピューティングリソースは、既存のBigtableクラスタのリソースを使用するとドキュメントに記載されています。ストレージはMaterialized Viewのクエリによってコストが異なり、クラスタとノード数、ソーステーブルのデータ量によって変動します。ABMEAでは、テーブル全カラムをコピーしつつ新規キーを付与したテーブルを構築したため、既存テーブル容量比で約110%の追加ストレージ割り当てが必要となりました。
結論
Bigtableの新機能であるMaterialized ViewとSecondary Indexを利用し、既存のBigtableのデータ構造やデータを変更することなく、新しいデータ構造とデータを定義することで、少ない工数で多様な要件に対応することができました。まだPreview Featureであるため、実際に正式リリースされた際に仕様が変更される可能性があります。しかし、別途データ移行パイプラインを構築することなくLSM Treeの限界を克服し、少ない工数で運用し、多様な要件に対応できるという点は、強力な選択肢の一つとなり得るでしょう。
Reference
- https://cloud.google.com/bigtable/docs/continuous-materialized-views
- https://cloud.google.com/bigtable/docs/structured-row-key-queries
- https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
- https://www.cs.rochester.edu/courses/261/spring2017/termpaper/16/paper.pdf
- https://registry.terraform.io/providers/hashicorp/google/latest/docs/resources/bigtable_materialized_view