
AI事業本部 アドテクディビジョン SREグループに所属している平田聡一朗と申します。SREグループではAI事業本部 アドテクディビジョンを中心に、他事業部も含めたインフラ構築およびSRE支援を担当しています。
本記事では、DynalystにおけるAmazon EMRからSnowflakeへの移行によって実現したコスト最適化の事例について紹介します。
移行に取り組んだ背景
Dynalystでは広告主が広告配信の効果を確認できる管理画面を提供しています。この管理画面ではAmazon S3に保存された膨大な量のログデータをEMRで集計し、その結果をAmazon RDSに保存することで、広告主が広告効果を可視化できる仕組みになっております。
しかし従来の集計処理システムには以下の課題がありました。
- 集計処理時には計算処理用のAmazon EC2(コアノード)が複数台起動しますが、大量のログを処理するには高スペックなインスタンスが必要でコストが高くなってしまいます。
- コスト削減のためにスポットインスタンスを使用すると、インスタンスの中断により処理が失敗するリスクがあります。
- 毎時実行される集計処理の完了に1時間以上かかるため、広告主がリアルタイムに近い形で広告効果を確認できません。
- チーム内にEMRの知見が十分でなく、インシデント発生時の原因特定や対応に時間を要していました。
移行前の詳細なアーキテクチャについては後述しますが、S3に保存されたログデータはすでにSnowflakeにもロードされています。Snowflakeにはマイクロパーティションなど高速なクエリ処理を実現するさまざまな機能が備わっており、EMRで行っている集計処理を同等のクエリとしてSnowflake上で実現できれば、これらの課題を解消できる可能性があります。こうした背景からSnowflakeへの移行を検討することになりました。
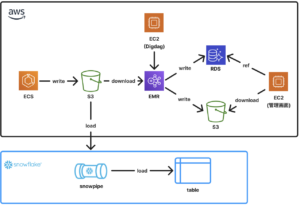
移行前のアーキテクチャ
以下に移行前のアーキテクチャ概要と構成図に示します。
- アプリケーション(ECS)のログはS3に保存されます。
- 集計処理はEC2にデプロイされたDigdagから定期的にEMRを起動することで実行されます。
- EMRはS3に保存されたログを利用し、複数のステップに分かれた集計処理を順次実行します。
- 集計結果はRDSまたはS3に出力されます。広告主はEC2上の管理画面を通じてRDSのデータを参照し、広告配信の効果を確認できます。また管理画面からS3に出力されたファイルをダウンロードできます。
- S3に保存されたログはSnowpipeを通じてSnowflakeのテーブルにも同期されます。
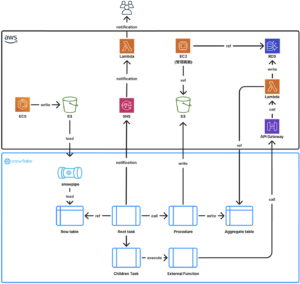
移行後のアーキテクチャ
以下に移行後のアーキテクチャ概要と構成図に示します。
- S3に保存されたログはSnowpipeを通じてSnowflakeのテーブル(Raw Table)にも同期されます(移行前と変更無し)。
- Taskは単一のSQLステートメントしか実行できない制約があるため、分析処理はProcedureとして定義し、TaskからはProcedureを呼び出す(Call)形で実行します。
- RDSで作成しているテーブルと同じ構造のテーブル(Aggregate Table)をSnowflake上にも作成し、Procedureで得られた分析結果はMERGE INTOクエリを利用してAggregate Tableに書き込みます(最終的にRDSにデータを同期する必要がありますが、その方法については後述します)。S3への出力はCOPY INTOクエリを利用して行います。
- EMRでは複数ステップに分けて順次処理が行われていましたが、Snowflake移行後もこれを再現するため、各ステップを1つのTaskとして定義し、Task間に依存関係を設定することで順番に処理が実行されるようにします。また最上位のRoot TaskにのみCronを設定し、Child TaskはRoot Taskとの依存関係により自動的に実行されるため、個別にスケジュールを設定する必要はありません。
- 分析処理の結果はAggregate Tableに保存され、これを読み取ってRDSに書き込むアプリケーションはLambda関数としてデプロイされています。Snowflake側の処理が完了した最後のTaskで、External Functionを実行してLambdaをAPI Gateway経由で呼び出すことで、RDSへのデータ同期を実現しています。
- 集計結果はRDSまたはS3に出力されます。広告主はEC2上の管理画面を通じてRDSのデータを参照し、広告配信の効果を確認できます。また管理画面からS3に出力されたファイルをダウンロードできます(移行前と変更無し)。
- Root TaskにNotification Integrationを設定しており、Taskの処理に失敗した場合はSNS経由でLambdaを実行し、開発者へ通知が送られます。
以下に移行後のアーキテクチャについて補足します。
- Snowparkを導入しなかった理由。
- SnowparkはSnowflakeの処理エンジン内でSQL以外のプログラミング言語(python, java, scala)を利用してコードを実行できるフレームワークです。Apache Sparkに似た記法で開発でき、Snowpark Migration Acceleratorを利用することで、Apache Sparkからの移行も比較的スムーズに行うことができます。
移行前はApache Sparkを利用していたため、Snowparkの導入も検討しました。しかしSnowparkの利用には特定の前提条件を満たす必要があり、現状のアプリケーションは条件を満たしておりませんでした。また前提条件を満たすための改修には多大な工数がかかると見込まれたため、Snowparkの導入を見送ることにしました。
- SnowparkはSnowflakeの処理エンジン内でSQL以外のプログラミング言語(python, java, scala)を利用してコードを実行できるフレームワークです。Apache Sparkに似た記法で開発でき、Snowpark Migration Acceleratorを利用することで、Apache Sparkからの移行も比較的スムーズに行うことができます。
- Raw Tableを参照しAggregate Tableへ書き込む分析処理に関して、Procedureではなくdbtを導入しなかった理由。
- dbt(data build tool)とはデータウェアハウス上でデータを変換するツールです。Procedureの代替としてdbtを利用して分析処理を構築することも可能です。しかし今回は以下の理由によりdbtの導入を見送ることにしました。
- チーム内におけるdbtの運用実績がなくノウハウが不足していた。
- 今回の移設でリネージやドキュメントなどの機能は必須ではなかった。
- クエリのバージョン管理はTerraformでも代替可能であった。
- dbt(data build tool)とはデータウェアハウス上でデータを変換するツールです。Procedureの代替としてdbtを利用して分析処理を構築することも可能です。しかし今回は以下の理由によりdbtの導入を見送ることにしました。
工夫した点
1. Serverless Task導入
Snowflakeのコストは主に以下の3要素から構成されます。
- コンピューティングリソース
- 仮想ウェアハウスコンピューティング
- サーバレスコンピューティング
- クラウドサービスコンピューティング
- ストレージリソース
- データ転送リソース
通常Taskを作成する際はウェアハウス(コンピュートリソース)を指定する必要がありますが、以下の課題がありました。
- ワークロードの変動によりログ量が一定でないため、ウェアハウスのサイズを固定するとコスト効率やパフォーマンスの最適化が難しい。
- ウェアハウスを利用した場合はTaskの実行時間が60秒未満でも最低60秒分の料金が発生してしまう。
これらの課題を解決するためにServerless Taskを導入しました。Serverless Taskは実行時のワークロードに応じて自動的に最適なウェアハウスのサイズに調整される機能です。1秒単位で課金されるため短時間で完了するTaskでも無駄なコストが発生しません。利用方法も非常にシンプルで、Task作成時にuser_task_managed_initial_warehouse_sizeオプションを指定するだけでServerless Taskとして動作します。このオプションは初回起動時のウェアハウスのサイズを設定するものですが、以降の実行では状況に応じて自動的にサイズが調整されます。
CREATE OR REPLACE TASK {Task Name}
schedule = 'using cron 5 * * * * *'
user_task_managed_initial_warehouse_size = 'LARGE'
as
call {Procedure};下記コマンドを実行しServerless Task においてウェアハウスのサイズが自動的に調整されているかを確認しました。
SELECT
q.WAREHOUSE_NAME,
q.WAREHOUSE_SIZE,
DATEDIFF('second', q.START_TIME, q.END_TIME) AS EXECUTION_TIME_SECONDS
FROM
"SNOWFLAKE"."ACCOUNT_USAGE"."TASK_HISTORY" t
LEFT JOIN
SNOWFLAKE.ACCOUNT_USAGE.QUERY_HISTORY q
ON
t.QUERY_ID = q.QUERY_ID
WHERE
t.NAME = {Task Name}
AND t.DATABASE_NAME = {Database Name}
ORDER BY
t.SCHEDULED_TIME ASC;
実行結果は以下のとおりで、Serverless Task を複数回実行することでサイズが最適化されていることが確認できます。

ただしServerless Task の利用にはいくつかの注意点があります。前述のとおりServerless Task は実行時の負荷に応じて自動でウェアハウスのサイズを調整しますが、サイズが小さくなった場合処理に時間がかかることがあります。Task にはデフォルトで60分のタイムアウト制限が設定されており、これを超えると処理が失敗してしまいます。
Task単体ではタイムアウトに達していなくても、依存関係を持つ一連のTaskの合計処理時間が60分を超えた場合、次のスケジュールで実行されるはずのTaskが起動しないという問題も発生しました。これらの課題に対応するため、処理時間が長くなると予想されるTaskについては、Serverless Taskではなく通常のウェアハウスを利用しサイズを固定することで安定した実行を実現しています。
2. SnowflakeからRDSにデータ同期するLambdaアプリケーション実装
前述の通り管理画面からRDSを参照して広告主が管理画面から広告配信効果を確認するためには、Snowflakeに書き込まれた集計データをRDSへ同期する必要があります。しかしSnowflakeはRDSと直接同期する機能が提供されていません。そのためembulkなどのツールやAWS Glueも検討しましたが、以下の理由から導入を見送りました。
- embulkを利用する場合はEC2などのインフラリソースの構築・運用が必要
- チーム内にこれらのツールに関する十分な知見がなく運用負荷が高くなると判断
これらの理由から自作のデータ同期アプリケーションを構築することにしました。
AWS Lambda Extension の活用
このアプリケーションはGo言語で実装されており、処理フローはまずLambdaの初期化を行います。具体的にはAWS Parameters and Secrets Lambda Extensionを利用し、Secrets Managerに登録したSnowflakeおよびRDSの接続情報を取得し、各データベースへの接続を初期化します。
AWS Lambda ExtentionとはLambdaに拡張機能を持たせるための仕組みです。今回利用したAWS Parameters and Secrets Lambda Extensionを利用することで、Secrets ManagerやSystems Manager Parameter Storeに保存された情報をキャッシュしAPIコール数を削減できるため、コスト削減やレスポンスの高速化といったメリットが期待できます。ただし、今回のバッチ処理は1日に数十回程度の実行でありAPI呼び出し回数も限定的です。そのため正直なところ、Extentionを利用した場合とSDKを利用した場合で実際の差はそれほど大きくなかった可能性もあります。
LambdaではGoランタイムが用意されていないため、カスタムのコンテナイメージを利用してLambdaを構築する必要があります。まずはExtentionのバイナリを取得するために、AWSが提供しているダウンロード用のURLを確認し、ローカルにダウンロードします(利用するExtentionのバージョンは公式ドキュメントから参照できます)。
# Extensionダウンロード用のURLを表示
$ aws --region ap-northeast-1 lambda get-layer-version-by-arn --arn 'arn:aws:lambda:ap-northeast-1:133490724326:layer:AWS-Parameters-and-Secrets-Lambda-Extension-Arm64:12' --query 'Content.Location' --output text
https://awslambda-ap-ne-1-layers.s3.ap-northeast-1.amazonaws.com/snapshots/133490724326/AWS-Parameters-and-Secrets-Lambda-Extension-Arm64...
# Extensionダウンロード
$ curl -o ext-ps.zip "https://awslambda-ap-ne-1-layers.s3.ap-northeast-1.amazonaws.com/snapshots/133490724326/AWS-Parameters-and-Secrets-Lambda-Extension-Arm64..."ダウンロードしたExtentionはDockerfileにコピーし解凍します。解凍後のファイルをLambda用のベースイメージ(public.ecr.aws/lambda/provided:al2023)の/opt/extensionフォルダに配置することで、Lambda実行時にExtentionを有効化できます(詳細は公式ブログを参照してください)。
シークレットの取得はExtentionにより起動されるローカルサーバーにリクエストを投げることで行います。認証にはLambda 実行環境で自動的に付与される AWS_SESSION_TOKEN を利用し、HTTPヘッダーの X-Aws-Parameters-Secrets-Token にこのトークンの値を設定します。取得されたシークレットはJSON形式で返され、その内容を SecretString フィールドに格納します。これをsnowflakeSecret構造体にマッピングして扱います。
package main
import (
"context"
"encoding/json"
"fmt"
"net/http"
"net/url"
"os"
)
type snowflakeSecret struct {
Account string `json:"account"`
User string `json:"user"`
}
func fetchSecret(ctx context.Context, secretId string) (*snowflakeSecret, error) {
u := "http://localhost:2773/secretsmanager/get?secretId=" + url.QueryEscape(secretId)
token := os.Getenv("AWS_SESSION_TOKEN")
if token == "" {
return nil, fmt.Errorf("AWS_SESSION_TOKEN is not set")
}
req, _ := http.NewRequestWithContext(ctx, http.MethodGet, u, nil)
req.Header.Set("X-Aws-Parameters-Secrets-Token", token)
res, err := http.DefaultClient.Do(req)
if err != nil {
return nil, err
}
defer res.Body.Close()
var resp struct {
SecretString string `json:"SecretString"`
}
if err := json.NewDecoder(res.Body).Decode(&resp); err != nil {
return nil, err
}
var secret snowflakeSecret
if err := json.Unmarshal([]byte(resp.SecretString), &secret); err != nil {
return nil, err
}
return &secret, nil
}キーペア認証でのSnowflake接続
前述の通りSecret ManagerにはSnowflakeへの認証に必要な情報を登録します。Snowflakeではパスワード認証やOAuthなど複数の認証方式が提供されていますが、2025年11月までにパスワードベースの認証方法が廃止される予定です。
参考:https://www.snowflake.com/en/blog/blocking-single-factor-password-authentification/
そのため今回の実装ではキーペア認証を採用しSnowflakeに接続することにしました。まずはこちらのドキュメントを参考に公開鍵と暗号化された秘密鍵をローカル環境で作成します。
# RSA方式の秘密鍵生成
$ openssl genrsa -out snowflake_key 4096
# 公開鍵生成
$ openssl rsa -in snowflake_key -pubout -out snowflake_key.pub
# 秘密鍵の暗号化
$ openssl pkcs8 -topk8 -inform pem -in snowflake_key -outform PEM -v2 aes-256-cbc -out snowflake_key.p8作成した公開鍵をSnowflakeユーザーに紐付けるために、以下のコマンドをSnowflake上で実行します。
CREATE OR REPLACE USER '<User Name>' DEFAULT_ROLE = '<Role Name>' DEFAULT_WAREHOUSE = '<Warehouse Name>' TYPE = SERVICE RSA_PUBLIC_KEY = '<Public Key>';
ローカル環境で以下のコマンドを実行し秘密鍵をバイナリ形式でSecret Managerに登録します。なおバイナリ形式で登録されたデータは自動的にBase64エンコードされます。
$ aws secretsmanager create-secret --name '<Secret Name>' --secret-binary fileb://snowflake_key.p8
後はアプリケーション内でSecret Managerから秘密鍵を取得し、パース処理を実行することで、キーペア認証を用いてSnowflakeに接続することができます。
// パース処理前の秘密鍵はBase64エンコードされているため、引数privateKeyBytesは事前にデコードしておく必要がある
func parsePrivateKey(privateKeyBytes []byte, passphrase string) (*rsa.PrivateKey, error) {
// PEM形式のデータをデコード
privateKeyBlock, _ := pem.Decode(privateKeyBytes)
if privateKeyBlock == nil {
return nil, fmt.Errorf("failed to decode PEM block")
}
// PEMブロックのタイプを確認
if privateKeyBlock.Type != "ENCRYPTED PRIVATE KEY" {
return nil, fmt.Errorf("unexpected PEM block type: %s, expected: ENCRYPTED PRIVATE KEY", privateKeyBlock.Type)
}
// パスフレーズ付きPKCS8形式の秘密鍵をパース
privateKey, err := pkcs8.ParsePKCS8PrivateKey(privateKeyBlock.Bytes, []byte(passphrase))
if err != nil {
return nil, fmt.Errorf("failed to parse private key: %v", err)
}
// パースした秘密鍵がrsa.PrivateKey型であるか確認
rsaPrivateKey, ok := privateKey.(*rsa.PrivateKey)
if !ok {
return nil, fmt.Errorf("invalid key type: %s, expected: *rsa.PrivateKey", reflect.TypeOf(privateKey))
}
return rsaPrivateKey, nil
} SnowflakeからRDSへのデータ同期
ここまでの設定でSnowflakeおよびRDSに接続する準備が整いました。あとはSnowflakeから必要なデータをフェッチし、RDSにバルクインサートすることで、両者のデータを同期することができます。アプリケーションの構成としては、リポジトリ層でSnowflakeからのデータ取得およびRDSへのデータ書き込み処理を定義し、サービス層ではそのリポジトリ層の関数を呼び出して処理を実行します。
LIMIT := 1000
OFFSET := 0
for {
// Snowflakeから取得
data, err := snowflakeRepo.Select(ctx, executionTime, LIMIT, OFFSET)
if err != nil {
snowflakeRepo.Rollback()
break
}
if len(data) == 0 {
break
}
// RDSへの書き込み
err = mysqlRepo.Upsert(ctx, data)
if err != nil {
mysqlRepo.Rollback()
break
}
OFFSET += LIMIT
} 非同期で Lambda を呼び出すための設定
Lambdaの実行方法としては、Snowflake上でExternal Functionを実行し、API Gateway経由でLambdaを呼び出すという機能があります。この機能を利用し集計処理が完了したタイミングでExternal Functionを実行し、SnowflakeからAuroraにデータを同期させます。
ただしExternal Functionの実行中はウェアハウスがアクティブな状態となるため、Lambdaからのレスポンスを待っている間もコストが発生します。そのため同期的にLambdaを実行すると処理時間分のコストがかかってしまうため、非同期でLambdaを呼び出す構成にしました。SnowflakeのベストプラクティスでもExternal Functionからリモートサービスを呼び出す場合は非同期処理が推奨されています。
Lambdaを非同期で呼び出すには、以下のようにAPI Gatewayとアプリケーションの設定が必要です。
- Lambdaプロキシ統合を無効化します。具体的には
aws_api_gateway_integrationリソースのtypeをAWS_PROXYからAWSに変更します。
resource "aws_api_gateway_integration" "lambda_integration" {
...
type = AWS- URL リクエストヘッダーに
X-Amz-Invocation-Typeを追加し、その値に'Event'を指定します。
resource "aws_api_gateway_integration" "lambda_integration" {
...
request_parameters = {
"integration.request.header.X-Amz-Invocation-Type" = "'Event'"
}- Snowflakeから送信されるリクエストボディをJSONオブジェクトとしてマッピングさせるために、以下のマッピングテンプレートを追加します。
resource "aws_api_gateway_integration" "lambda_integration" {
...
request_templates = {
"application/json" = <<EOF
{
"body": $input.json('$')
}
EOF
} - Snowflakeが認識できるレスポンスボディの構造にマッピングするために、以下のマッピングテンプレートを追加します。
resource "aws_api_gateway_integration_response" "lambda_integration_response" {
...
response_templates = {
"application/json" = <<EOF
{
"data": [
[0, "success"]
]
}
EOF
} - アプリケーション側ではリクエストボディのデータ構造をJSONオブジェクトとして定義しておくことで、そのJSONオブジェクトから外部関数の引数を取得できます。これによりLambdaはSnowflakeから渡された引数を利用して同期処理を実行できます。
// リクエストボディのデータ構造を定義
type RequestBody struct {
Body struct {
Data [][]interface{} `json:"data"`
} `json:"body"
}
...
// リクエストボディから引数の値を取得
arg := request.Body.Data[0][1].(string)3. SnowflakeリソースをTerraformで管理
TerraformではSnowflakeリソースを管理するためのプロバイダーが提供されております(2025年04月23日にGA版がリリースされております)。
前述の通り今回の移設ではdbtの導入を見送っているため、集計処理用のクエリについてはTerraformでバージョン管理する必要があります。具体的には、snowflake_procedure_sqlリソースを利用して対象となるデータベースやスキーマの指定、および分析処理で使用するクエリの内容を設定します。クエリについては別のファイルで定義することで、クエリのバージョン管理が可能になり、開発者は集計処理を変更したい場合、そのファイルを修正してterraform applyを実行するだけで反映できます。
Terraform Snowflake ProviderにはもちろんProcedureの他にもTaskやExternal Functionなど様々なリソースが用意されており、必要に応じてこれらのリソースもTerraformで管理できます。
resource "snowflake_procedure_sql" "sample" {
database = var.database
schema = var.schema
name = var.name
procedure_definition = templatefile("${path.module}/sample.json.tpl" # sample.json.tplにクエリの内容を設定する移設前後のコスト・処理時間・エラー率確認
コスト
Snowflakeではデータの処理や保存に対して利用した分だけ料金が発生します。この料金の単位をクレジットと呼びます。クレジットの単価は契約体系や利用するプラットフォームによって異なります。例えば以下の条件でSnowflakeを利用した場合、1クレジットあたりの単価は$2.85となります(単価はこちらから確認できます)。
- 契約体系:STANDARD
- プロバイダー:AWS
- リージョン:ap-northeast-1
こちらのページでWarehouseのサイズごとのクレジット消費量を確認できます。前述の通りServerless Taskはワークロードに応じてウェアハウスのサイズを自動調整します。しかし今回の移行時は移行後しばらくすると一定のウェアハウスのサイズで固定されていたため、以下のクエリでタスクの処理時間を算出し1ヶ月あたりのコストを、Task処理時間(秒) × クレジット消費量(秒あたり) × 1ヶ月のバッチ実行回数で求めました。
SELECT
AVG(DATEDIFF('second', QUERY_START_TIME, COMPLETED_TIME)) AS AVG_EXECUTION_SECONDS
FROM
SNOWFLAKE.ACCOUNT_USAGE.TASK_HISTORY
WHERE
QUERY_START_TIME >= DATEADD(day, -30, CURRENT_TIMESTAMP())
AND NAME = 'Task Name';またサーバレスを利用する場合、機能ごとにコストに対して係数が適用されます。2025/08時点ではServerless Taskを利用すると0.9の係数が適用されます。つまり前述のコスト計算式にこの係数を掛けることで、Serverless Taskにおける実際のコストを算出できます(通常のTaskには係数は適用されません)。
参考:https://www.snowflake.com/legal-files/CreditConsumptionTable.pdf
最終的にバッチ処理にかかるシステムコストを約60%削減することができました。
処理時間
処理時間に関しては前述のクエリで既に計測しております。移行前と比較すると最大で80%以上の大幅な処理時間削減を達成することができました。ここまで処理時間が改善した要因について、以下に考察します。
- EMRではS3に保存されたデータを一度ダウンロードして集計処理を開始します。そのためS3のデータ量が多い場合、ダウンロードだけで時間を要していました。一方で移行後はSnowflakeテーブルから直接データを読み込んで集計処理を行うため、ダウンロード処理が不要になったことが、処理時間短縮の一因と考えられます。
- Snowflakeではデータが挿入された順に自動でマイクロパーティションに分割・保存されます。バッチ処理では特定期間のデータのみを対象として集計するため、マイクロパーティションにより不要なデータのスキャンを避け効率的な処理が実現されたと考えられます。
エラー率
下記のクエリでタスクの失敗率を確認できます。もちろんクエリの内容に誤りがあればタスクは失敗しますが、前述の通りインフラ起因でバッチ処理が失敗することは無くなったため、再実行などの運用負荷は軽減できました。
またクエリの実行に失敗した場合に備えて、Taskの再実行手順をRunbookにまとめ、アラートメッセージに添付することで誰でも迅速に対応できる体制を整えています。
SELECT
NAME,
FLOOR(COUNT_IF(STATE != 'SUCCEEDED') * 100.0 / COUNT(*)) AS ERROR_RATE
FROM
SNOWFLAKE.ACCOUNT_USAGE.TASK_HISTORY
GROUP BY
NAME;まとめ
本記事では集計処理システムをEMRからSnowflakeに移行し、コストや処理時間の改善を実現した取り組みについて紹介しました。移行対象のバッチ処理が多く移行作業には時間を要しましたが、最終的には無事に移設を完了し、コストと処理時間ともに大きく削減できたことに達成感を感じております。移行作業に尽力してくれた開発メンバー、ならびにアーキテクチャーのレビューを行っていただいたSnowflakeサポートチームの皆様に感謝申し上げます。
なおDynalystではまだまだシステム運用に関する課題が多く残っている状況です。今後も運用負荷の軽減に向けて改善に取り組んでまいります。