
はじめに
こんにちは、2025 年新卒で ABEMA の広告配信システム開発チームに所属している戸田朋花です。
生成 AI を活用したアプリケーション開発では、「ハルシネーション」と呼ばれる問題がしばしば課題になります。これは、生成 AI がもっともらしく見える誤情報を自信満々に出力してしまう現象です。
こうした問題に対して、形式的な検証技術を応用し、ハルシネーションの発生を抑制する新しいサービス「Automated Reasoning checks」が先日 AWS 上で GA されました。
本記事では、この 「Automated Reasoning checks」を実際に試してみた内容を、検証結果とあわせてご紹介します。
Automated Reasoning checks とは
Automated Reasoning checks は Amazon Bedrock Guardrails の一つの機能として提供されています。
Amazon Bedrock Guardrails は、生成 AI アプリケーションにセーフティ機能を組み込むための仕組みで、ハルシネーションの防止や有害コンテンツのフィルタリングなど、さまざまな機能を提供します。
その中でも Automated Reasoning checks は、形式手法に基づいて LLM の出力を検証し、ハルシネーションを抑制する ことを目的とした機能です。
形式手法とは
形式手法とは、システムの設計・振る舞いを、厳密に決められた記号・構文を持ち、曖昧さのない言語 (形式的な言語) で記述し、その正しさを検証する手法です。
形式手法については、こちらの記事で詳しく解説しているので興味がある方はぜひ読んでみてください。
Automated Reasoning は形式手法の一つで、システムやプログラムの動作を数学的な証明により検証することを目的とするコンピューターサイエンスの分野です。
形式手法は強力な一方で、数学的知識が前提となるため学習コストが高く、実務での導入ハードルが高いという課題があります。
今回 GA された Automated Reasoning checks は、こうした課題を回避しながら形式手法の恩恵を受けることができるサービスになっています。
Automated Reasoning checks の利用の流れ
Automated Reasoning checks では、まずポリシーを作成します。
ポリシーとは、検証対象が満たすべき条件を形式的に記述したもので、複数のルールで構成されます。
ルールは検証のためのロジックで、if <premise>, then <claim>または<premise> is trueのように表現されます。
実際にこのポリシーを作成するための流れは以下のようになっています。
1. ポリシーの作成
まず、ポリシーを生成する元となるような、ビジネスルールを含むドキュメントをアップロードします。
それを元にポリシーが出力されます。
2. ポリシーのテストと修正
最初に生成されたルールは必ずしも正確とは限らないので、ルールが意図通りの振る舞いをするかを確かめるためにテストを作成します。
テストした結果、ルールが不適切だと分かった場合は、ルールやそのルールを構成する変数にアノテーションをつけることで、それをもとにルールの修正を行うことができます。
このプロセスを繰り返すことで、意図した内容のポリシーを作成することができます。
検証
実際に Automated Reasoning checks によるポリシーの作成を試してみました。
インシデント発生時の Sev の割り当てのシナリオで実際にポリシーを作成します。
1. ポリシーの作成
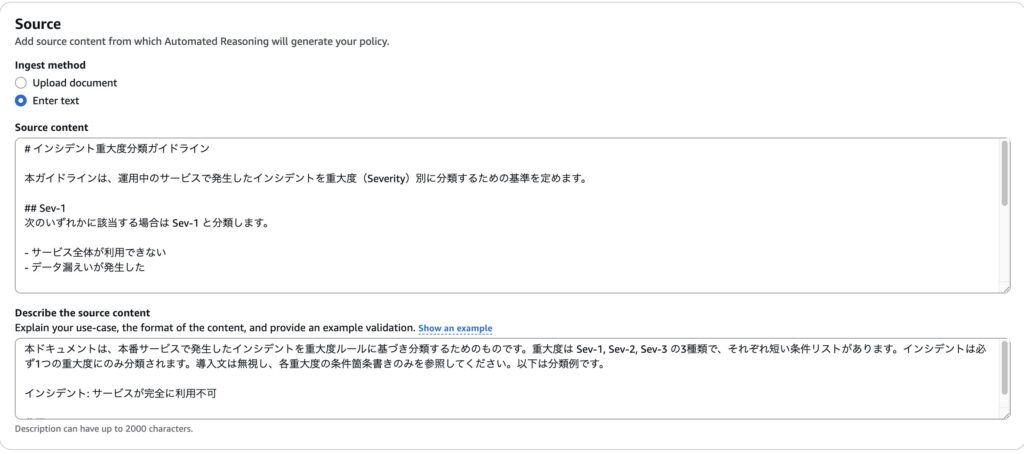
画像のように、ドキュメントを入力するだけでポリシーを作成することができます。
直接入力するのではなく、ファイルをアップロードすることも可能です。
今回入力したドキュメントは以下のようになっています。
Source content に入力した内容
# インシデント重大度分類ガイドライン
本ガイドラインは、運用中のサービスで発生したインシデントを重大度(Severity)別に分類するための基準を定めます。
## Sev-1
次のいずれかに該当する場合は Sev-1 と分類します。
- サービス全体が利用できない
- データ漏えいが発生した
## Sev-2
Sev-1の条件に該当せず、次のいずれかに該当する場合は Sev-2 と分類します。
- 全ユーザーの 30%以上 が影響を受けている
- 主要機能の 1つ以上 が完全に停止している
## Sev-3
Sev-1, Sev-2の条件に該当せず、次のいずれかに該当する場合は Sev-3 と分類します。
- 軽微な不具合があるが主要機能は利用可能
- 影響を受けるユーザーが全体の 5% 未満
Describe the source content に入力した内容
本ドキュメントは、本番サービスで発生したインシデントを重大度ルールに基づき分類するためのものです。重大度は Sev-1, Sev-2, Sev-3 の3種類で、それぞれ短い条件リストがあります。インシデントは必ず1つの重大度にのみ分類されます。導入文は無視し、各重大度の条件箇条書きのみを参照してください。以下は分類例です。
インシデント: サービスが完全に利用不可
分類: Sev-1
生成されたポリシーについて確認していきます。
上でも少し説明しましたが、Automated Reasoning checks で作られるポリシーは次の 3 つの要素で構成されています。
- Custom variable types
- ブール型でも数値型でもない変数の型
- 変数
- 自然言語ドキュメントにおける主要な概念で、各変数は 1 つ以上のルールに関係している
- ルール
- ポリシー内の変数がどのように関連しているかの記述
Custom variable types

SeverityLevel という型が定義されていることが確認できます。
変数
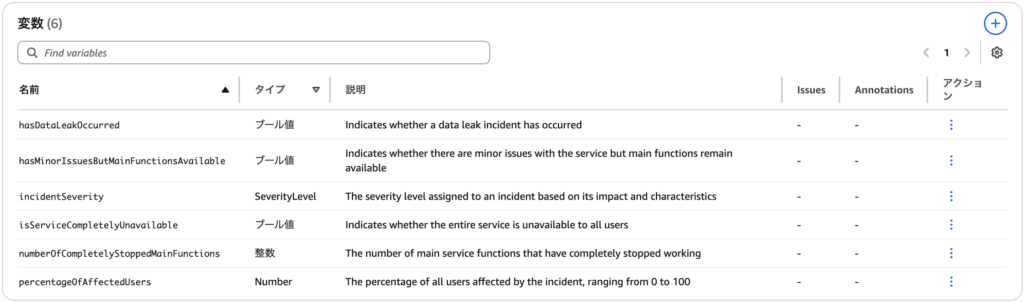
hasDataLeakOccurredなど、ドキュメントで記述した条件が boolean の変数として定義されていることが確認できます。
ルール
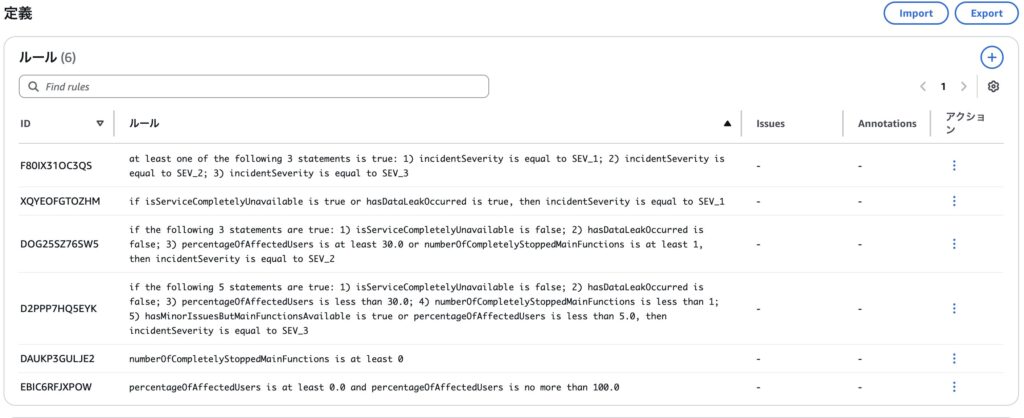
例えば、入力したドキュメント中の Sev-1 の条件の一つ「サービス全体が利用できない」は画像中の IDXQYEOFGTOZHM の if isServiceCompletelyUnavailable is true or hasDataLeakOccurred is true, then incidentSeverity is equal to SEV_1 というルールに含まれていることが確認できます。
2. テストの作成
定義されたポリシーをテストしてみます。 テストは手動で作成できるほか、ドキュメントをもとに自動生成も行なってくれます。自動生成をするために generate ボタンを押すと、画像のようなポップアップが出てきました。
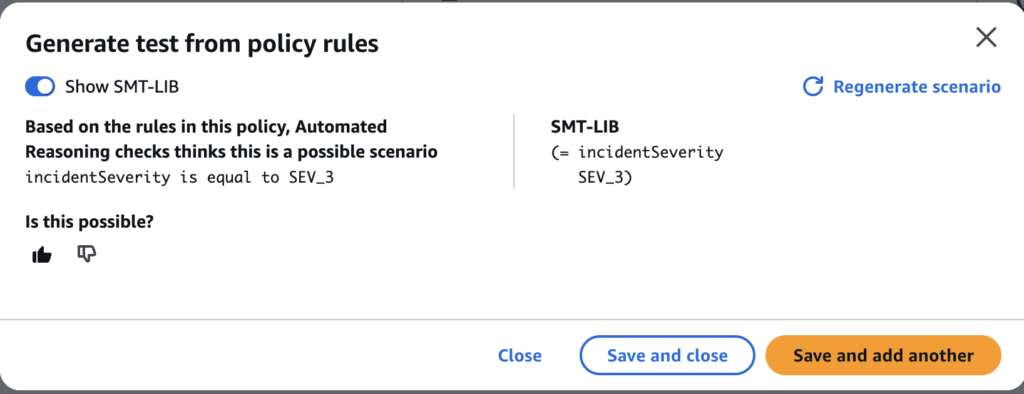
good ボタンをおすとテストのシナリオとして追加できます。
また、bad ボタンを押すとなぜダメなのか伝えることもできます。
自動生成したテストを画像のように修正しました。
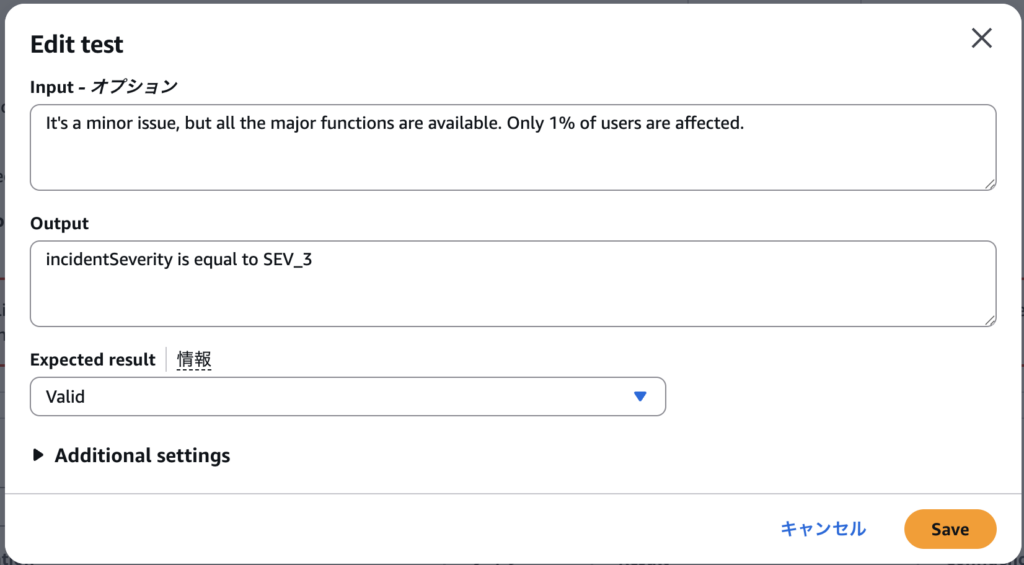
Sev-3 が判定されるような記述として、”It’s a minor issue, but all the major functions are available. Only 1% of users are affected.”という input を追加しました。
また、これは有効なものと判定されて欲しいので、Expected Result を Valid にしました。
3. テストの実行
実際に実行してみた結果が以下のようになります。
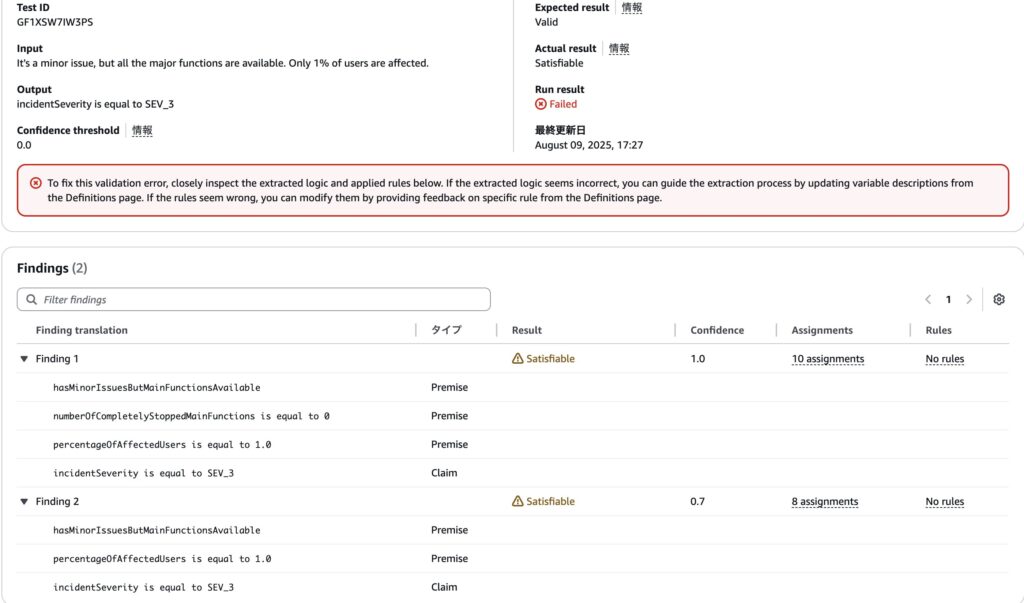
結果が Valid ではなく、Satisfiableとなっていてテストが落ちており、発見された変換(Findings)が二つに分かれてしまっています。
Satisfiableとは、追加の前提条件によってはこの主張が成り立つ場合と成り立たない場合があるということを意味しています。
4. 冗長な変換結果の修正
まずは複数の変換結果が出たことについて確認していきます。
一つ目の変換では”numberOfCompletelyStoppedMainFunctions is equal to 0″が存在します。
これは、停止した主要な機能の数が 0 個であるということで、この変数自体はドキュメントの中の「主要機能の 1 つ以上 が完全に停止している」という記述から生成されたと考えられます。
また、これとは別に、hasMinorIssuesButMainFunctionsAvailableという変換も存在します。これはドキュメント中の「軽微な不具合があるが主要機能は利用可能」という記述から生成されたと考えられます。
この二つの変数は互いに意味が重なっており冗長になってしまっています。
今回のシナリオで重要なのは停止した主要な機能が存在するのか、しないのか、という点であり、数は関係ありません。
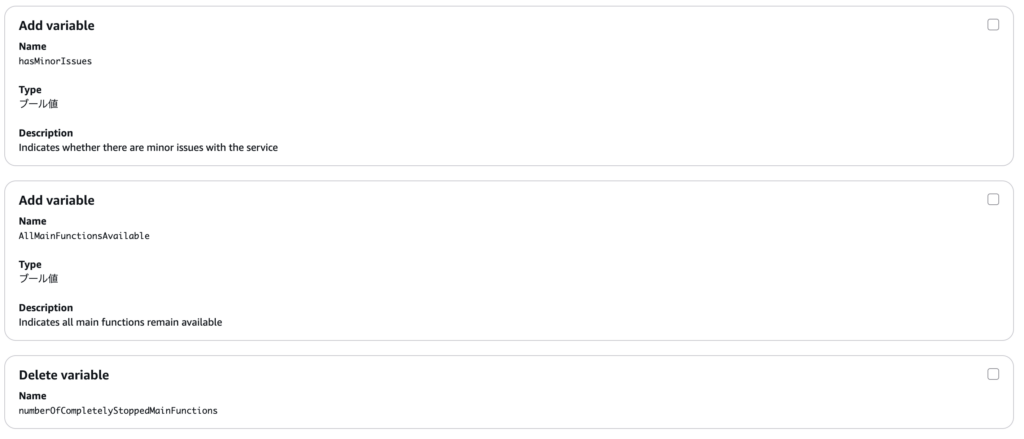
そこで、これらの変数を削除し、AllMainFunctionsAvailableと、hasMinorIssuesという二つの変数を追加し、これを元にルールを書き直しましょう。
これを反映するためにコンソールから追加や削除の操作を行うと、すぐに反映されず、画像のようなアノテーションが追加されました。
これを適用した結果は以下のようになっています。
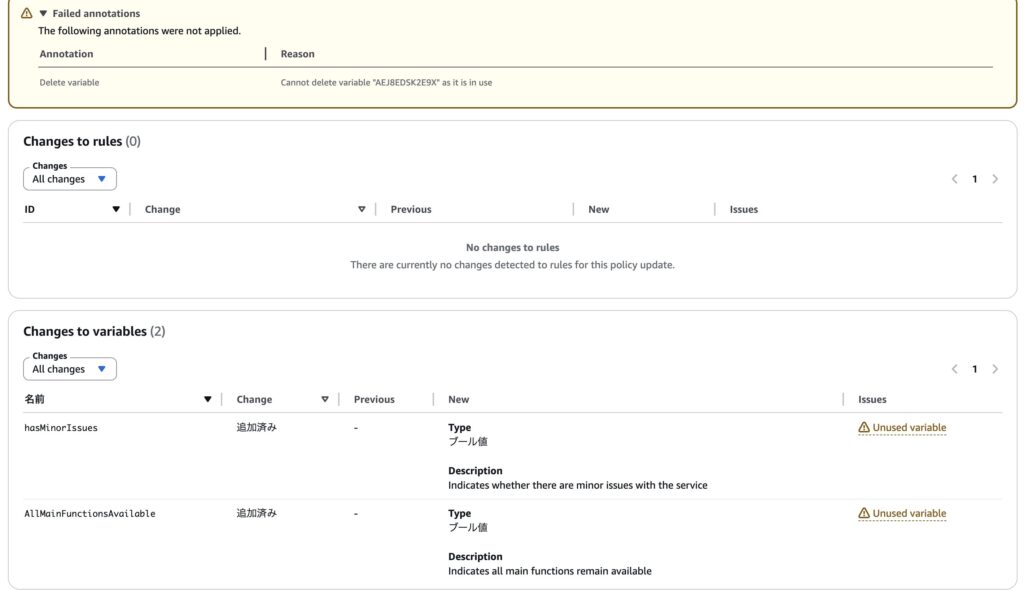
意図した変数が追加されている一方で、numberOfCompletelyStoppedMainFunctionsは利用中のルールがあるため、削除に失敗しました。
ルールの修正に移ります。ルールも同様に編集内容はアノテーションとして表現できます。以下のようなアノテーションを作成しました。
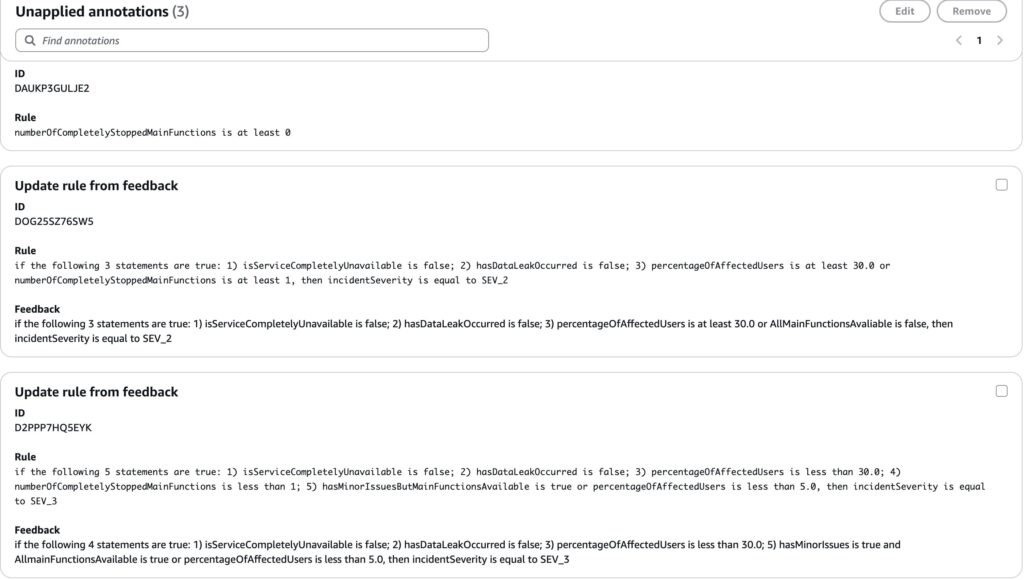
アノテーションを適応すると、以下のように変更内容がプレビューされます。

意図通りに新たに追加した変数を利用するようにポリシーが修正されていたので、変更を適応します。
テストを実行したところ findings が一つに絞られていることが確認できました。
5. 結果がSatisfiableとなってしまう問題への対処
次に、結果がSatisfiableとなってしまう問題に対処します。
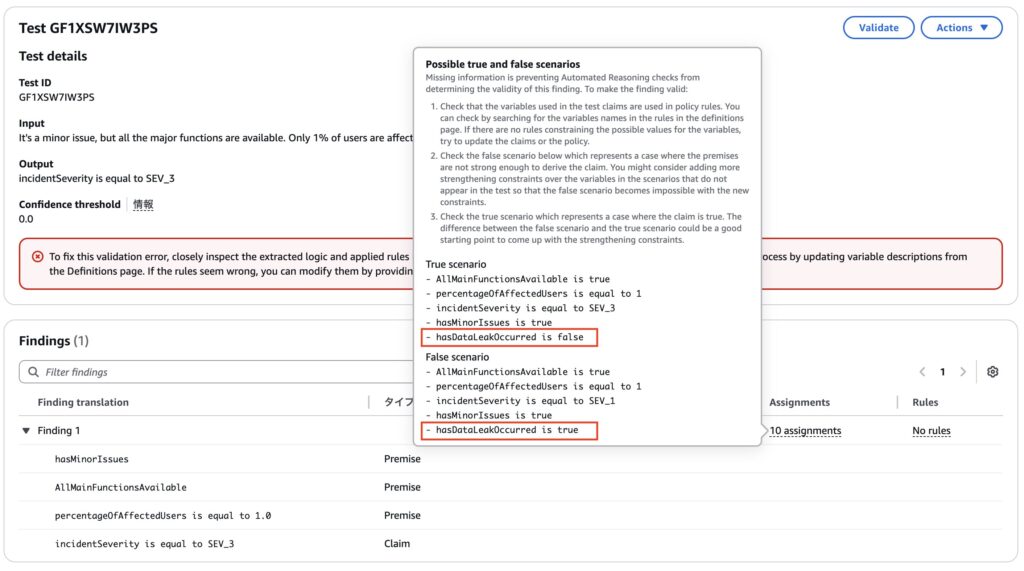
上の画像のように、Satisfiableと書かれている部分にカーソルを当てると解説が表示されました。
これによると、hasDataLeakOccurredの結果に影響されてこのシナリオの true/false が変わるため、Satisfiableになってしまっているようです。
暗黙的に「与えた input 以外のことは起きない」と考えてしまっていましたが、明示的に与える必要があるようです。
そこで、明示的に他には何も起きていないことを示すように input を修正しました。
The only two impacts of this incident are as follows: It is a minor issue, and the major functions remain available. Only 1% of users are affected. There is no data leak or any other major impact.
incidentSeverity is equal to SEV_3
これで実行したところ、結果はまだSatisfiableでした。
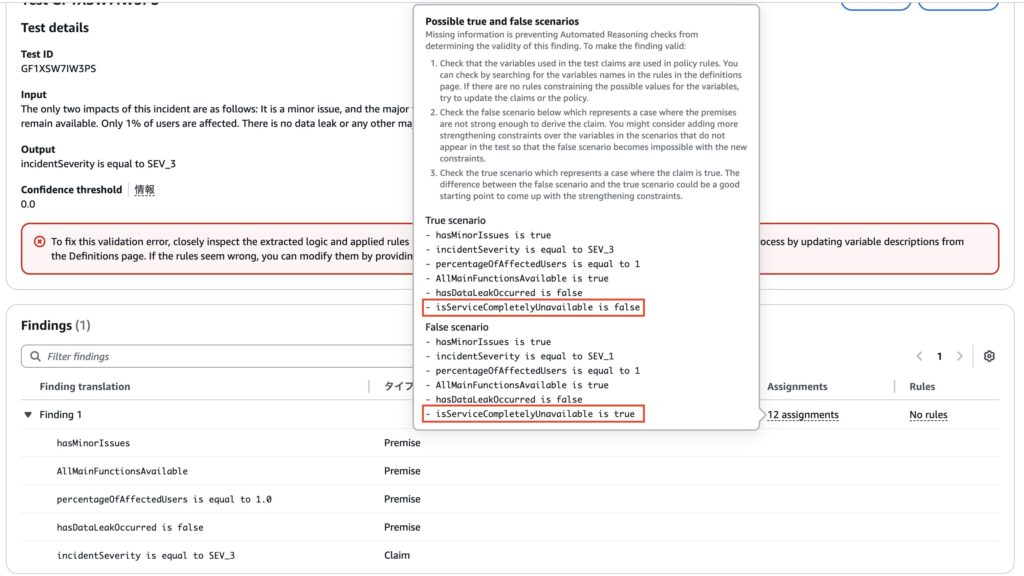
詳しくみてみると、今度はisServiceCompletelyUnavailableの結果に影響されてこのシナリオの true/false が変わるため、Satisfiableになってしまっているようです。
主要な機能が影響を受けていないのだから、サービスの利用は可能だと感じられますが、これも明示的に伝える必要がありました。
そこで、以下のようなルールを追加しました。

これを元にテストを実行したところ、無事に通過しました!
他にも何個かルールを追加していったところ、ここまでの修正が効いたのか、何もしなくても全て通過しました!
終わりに
今回、Automated Reasoning checks を使ったポリシー作成を一通り検証しました。
実際に試してみて、無意識のうちに暗黙の前提やルールをもとに検証してしまっている自分に気づかされました。
生成 AI を組み込んだアプリケーションに限らず、アプリケーションを開発するということは、機械が処理可能な形でビジネスロジックを表現することです。
自然言語から正確なルールを生成できるこの機能は、Amazon Bedrock Guardrails の一機能にとどまらず、幅広い応用可能性を秘めていると感じました。
一方で、実際の業務ロジックはより複雑であり、それらを網羅的かつ正確にルール化するには相応の工数が必要です。
活用にあたっては、こうしたルールベースの検証が有効に機能するユースケースを見極めることが重要そうです。
今回は時間の都合で統合まで検証できませんでしたが、もしこの仕組みで生成 AI の出力を厳密に制御できるなら、生成 AI 自体を活用できるアプリケーションの幅は大きく広がると感じました。
最後まで読んでいただき、ありがとうございました!