
目次
- はじめに
- ゾーン分散導入の背景
- Podゾーン分散実現のために行ったこと
- 効果
- まとめ
この記事で学べること
- KubernetesのtopologySpreadConstraintsを使用したPodのゾーン分散配置
- deschedulerを使用した既存Podの再配置方法
- マルチリージョン環境におけるCloud Load Balancingのリクエスト先の選択方法
想定読者
- Kubernetesを本番環境で運用している開発者
- Pod配置の偏りによる可用性やパフォーマンスの課題を抱えている開発者
はじめに
株式会社WinTicketバックエンドチームの谷口(@guchan_dayon)です。
WINTICKETでは、東京・大阪のマルチリージョン構成を採用しており、各リージョンにはそれぞれ3つのゾーンがあります。高可用性とトラフィック最適化の観点から、各ゾーンへの均等なPod配置が重要となります。
本記事では、Google Kubernetes Engine(GKE)での運用において、Podのゾーン分散を実現するために実施したこととその背景、得られた効果について紹介します。
ゾーン分散導入の背景
Podの偏在という課題
現在WINTICKETでは以下のようなアーキテクチャで運用しています。ユーザーからのリクエストはCDN(Fastly)、Load Balancer(LB)を経由し、Istio Ingressgatewayを通過した後に各マイクロサービス群へとリクエストが届きます。
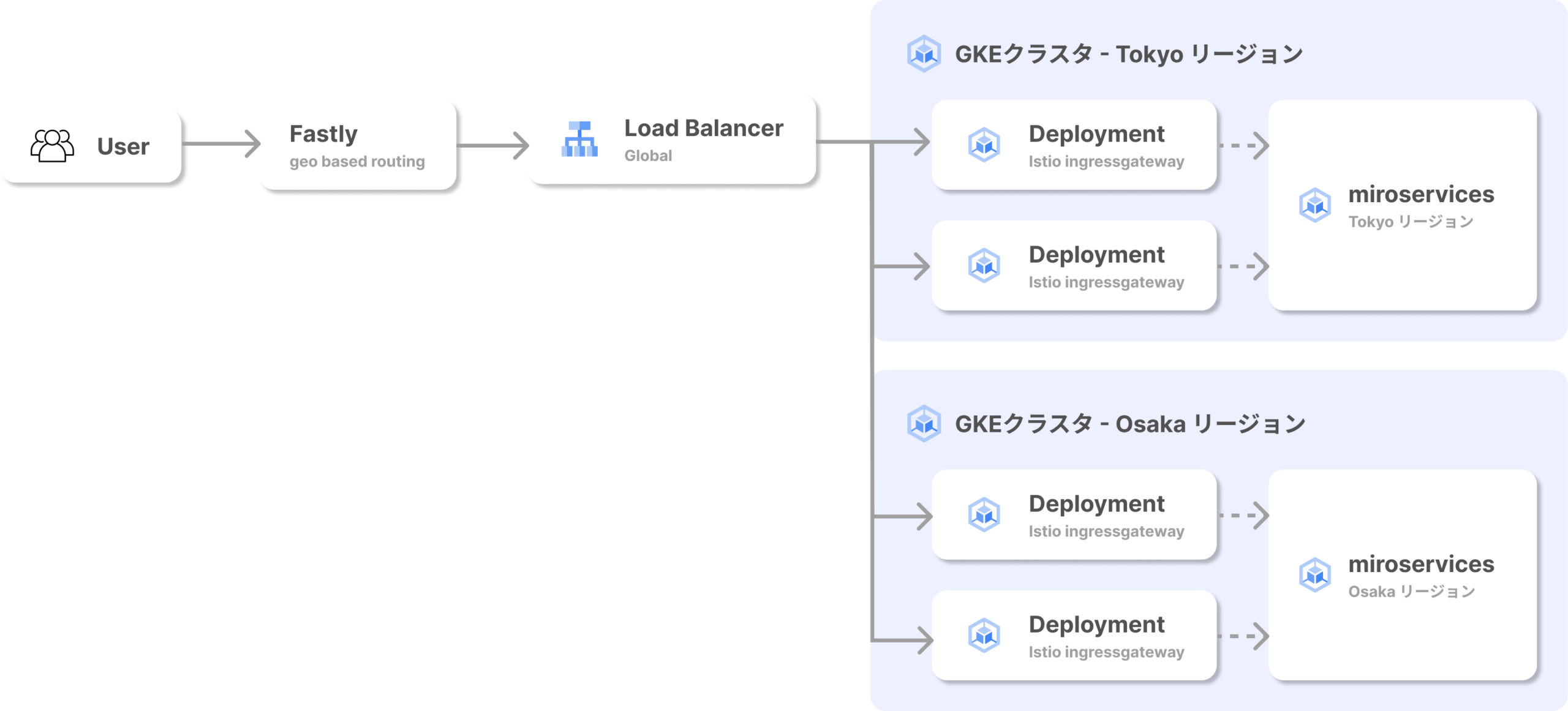
GKEクラスタを運用する中で、Istio IngressgatewayのPodが特定のゾーンに偏って配置されるという事象が発生していました。可用性の観点からPodはそれぞれのゾーンに均等に配置されるのが望ましいです。
また、パフォーマンス向上の観点から、ユーザーからのリクエストは、データベースとして利用しているCloud Spannerのリーダーリージョンが存在するTokyoリージョンへと優先的にトラフィックを流すような設定となっています。(インフラアーキテクチャの詳細や、Tokyoリージョンを優先的に選択している詳細な解説はこちらの記事で紹介しています)
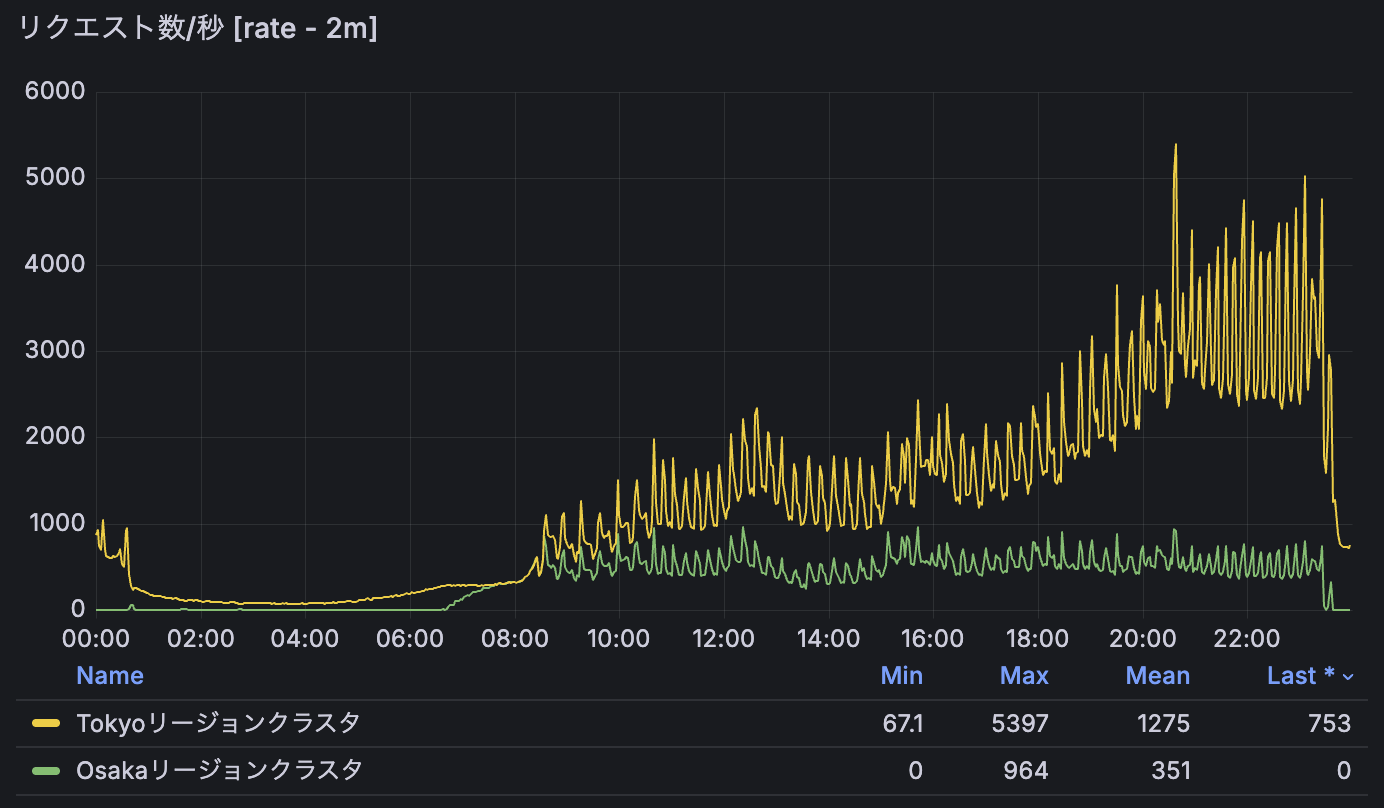
しかしながら、以下のようにOsakaリージョンへトラフィックが偏る事象が時折確認されていました。
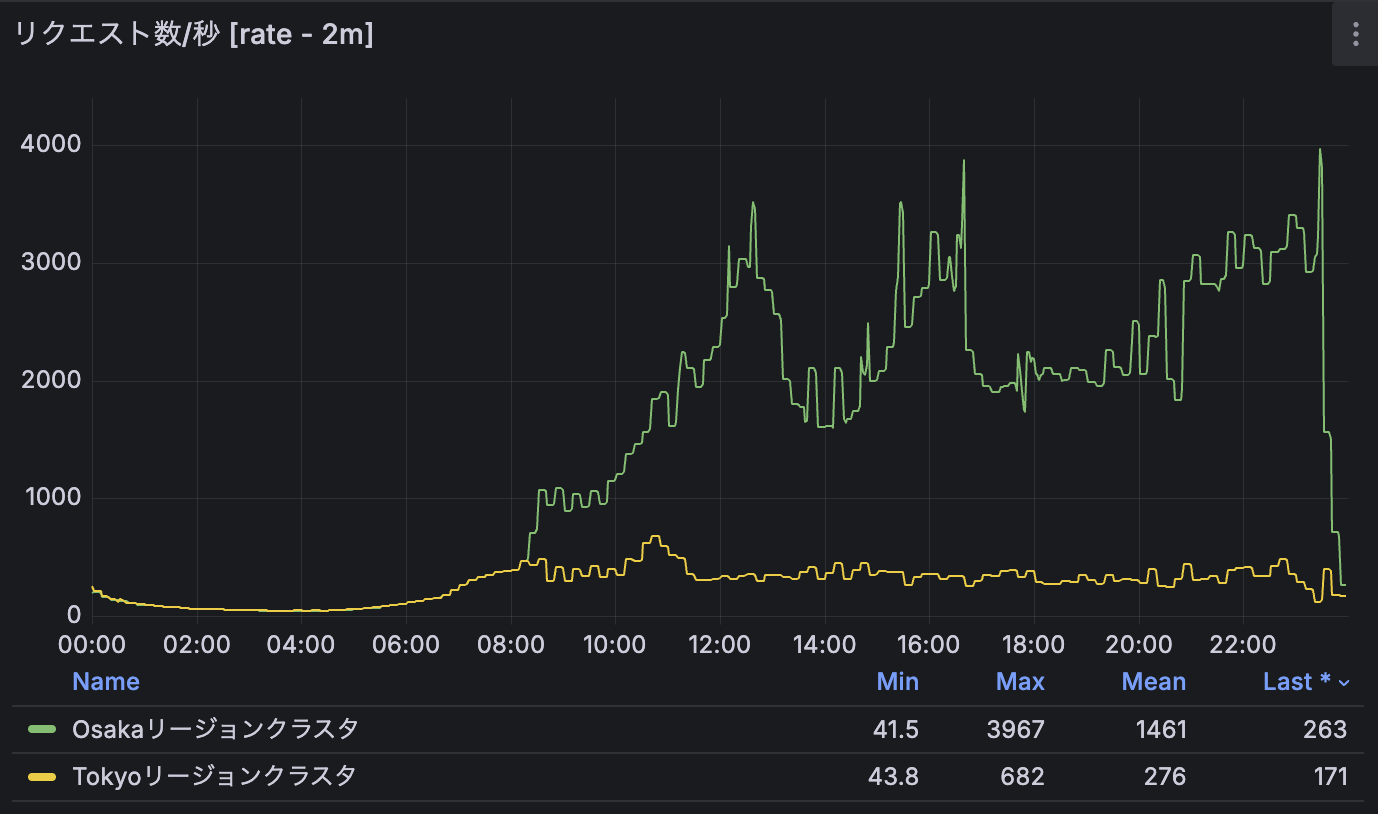
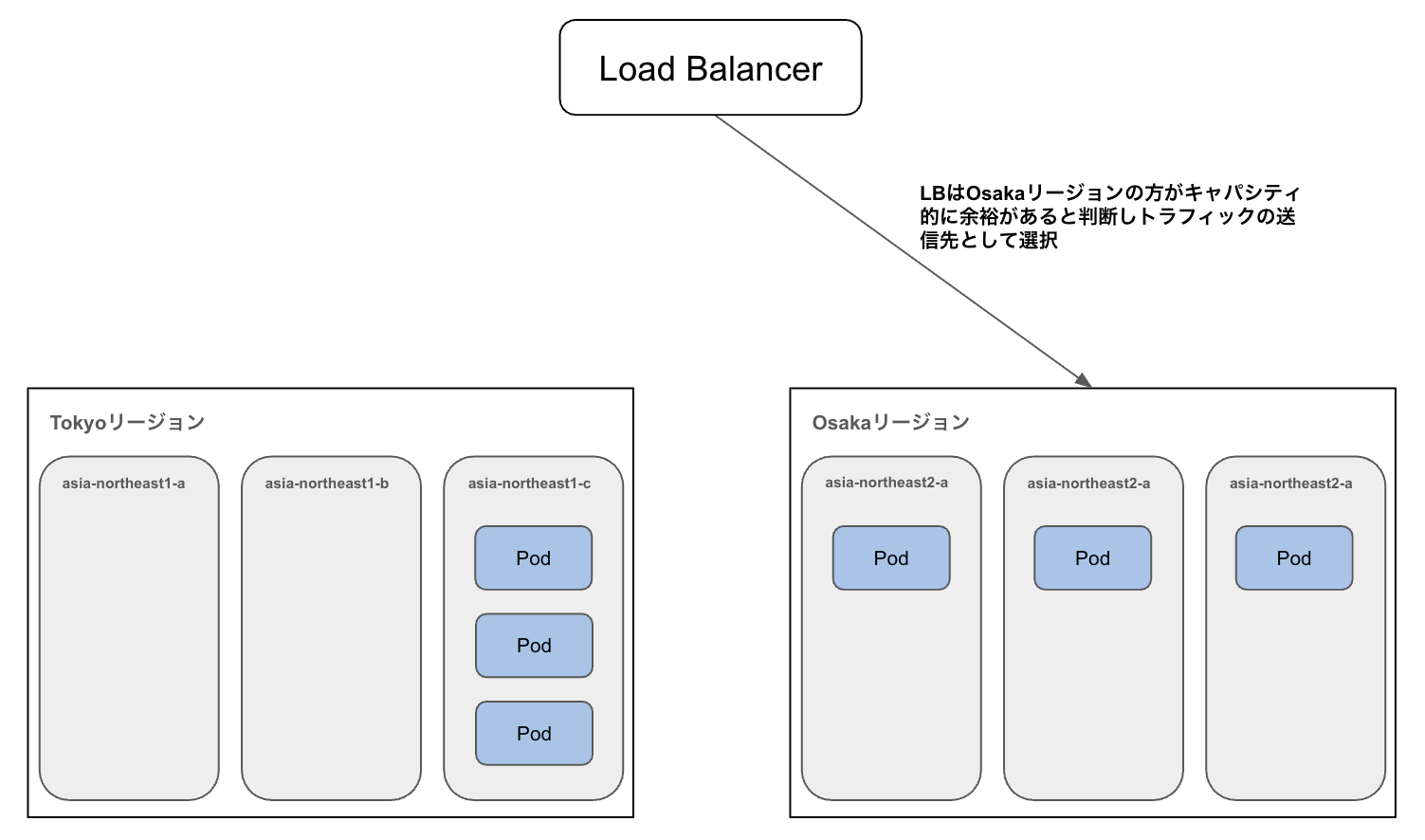
調査の結果、この事象が発生している間、TokyoリージョンのIstio IngressgatewayのPodが asia-northeast1-a および b に存在せず、c にのみ集中していた時間帯があることがわかりました。このようなゾーン間の偏りの発生により、Google Cloud のロードバランサの内部アルゴリズムが、東京リージョン全体のキャパシティを過小に見積もり、結果としてOsakaリージョン側のバックエンドへトラフィックを振り分けていました。
実際に、Google CloudのLBに関するドキュメントにも次のような記載があります。[参考]
容量がゾーン間で均等でない場合、使用可能なサービス容量に応じて負荷が分散されます。
Podゾーン分散実現のために行ったこと
Podのゾーン分散実現のために以下2つの導入をしました。
- topologySpreadConstraints の導入
- descheduler の導入
それぞれ詳細に解説します。
topologySpreadConstraintsの導入
topologySpreadConstraintsとは、リージョン、ゾーン、ノードを跨いでクラスター内のPodをどのように分散して配置するかを設定するための機能です。これを設定することで、設定したトポロジー領域(zone/region/nodeなどがある。今回はzoneを指す)で分散されてPodがスケジュールされます。実際には以下のような設定をしています。
実際の設定とその意味:
apiVersion: apps/v1
kind: Deployment
...
spec:
template:
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: { { .name } }
istio: ingressgateway
matchLabelKeys:
- pod-template-hash
maxSkew:
最も多く配置されたトポロジー領域と、最も少ない領域とのPod数の差の許容値。この値を超えないようにPodは配置されます。
topologyKey:
Pod をどのトポロジー単位で分散させるかを決めるキー。上記では、topology.kubernetes.io/zoneとすることでゾーン単位でPodが分散して配置されます。
whenUnsatisfiable:
分散条件を満たせないときにどうするかを指定します。
- ScheduleAnyway
- 条件を満たさなくてもPodをスケジュールする
- DoNotSchedule
- 条件を満たさない場合はPodをスケジュールしない
matchLabelKeys:
Pod に付与されているラベルキーの値をもとに、同一グループのPodをまとめて分散対象にするための設定。pod-template-hashを設定することで、同じ ReplicaSetに属する Pod ごとにゾーン分散の制約が適用されるようになります。
これはローリングアップデート時のPodの偏りを防ぐために利用します。
例えば、pod-template-hashで設定していないと下記のようにPodの偏りが発生してしまう可能性があります。
1. ローリングアップデート時、下記の状態ではどのゾーンにもPodが配置されているため、新しいPodのスケジュールはどのゾーンでも問題ない。
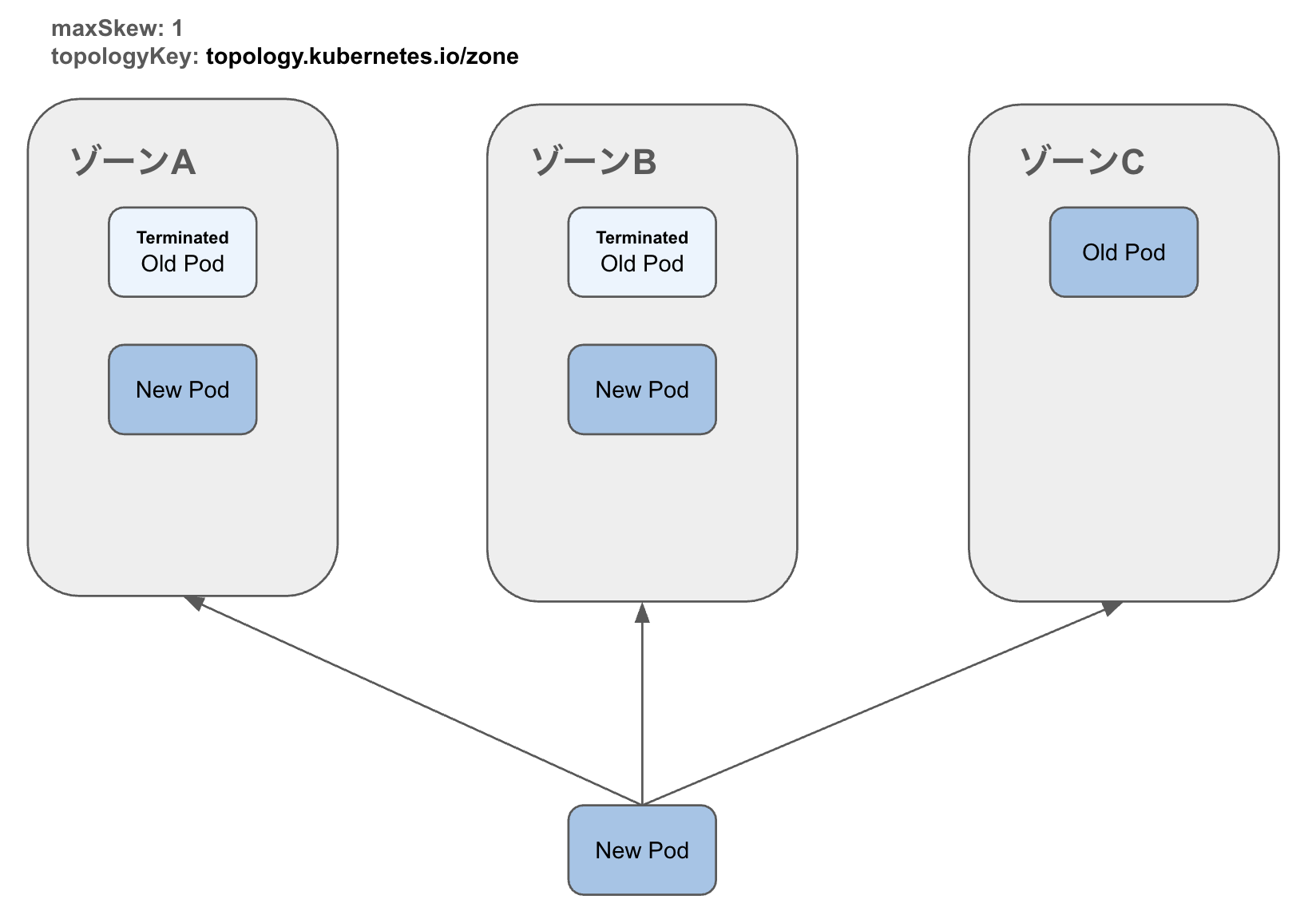
2. ゾーンBにPodがスケジュールされる
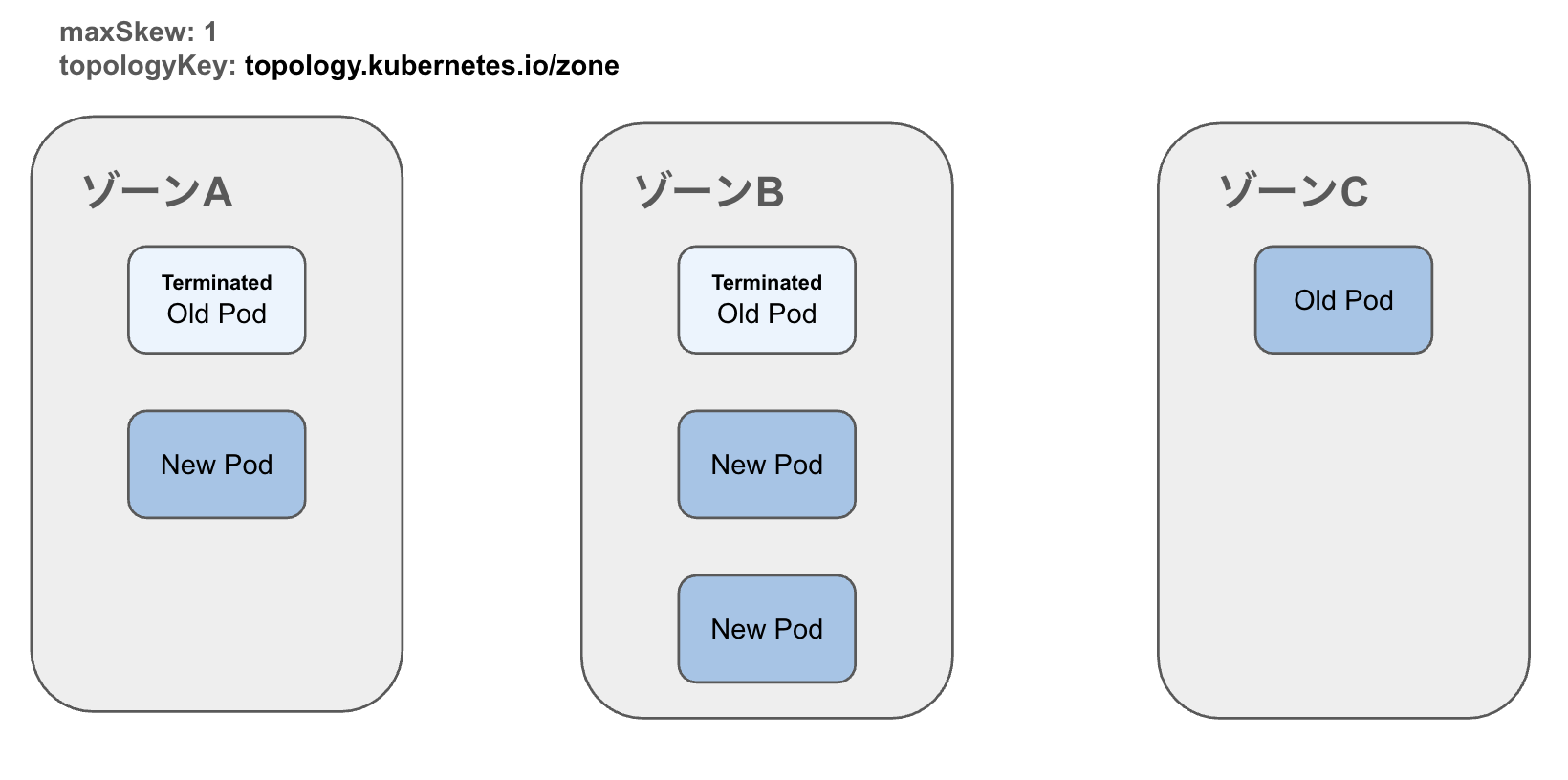
3. ゾーンCのPodは旧バージョンのためterminateされる
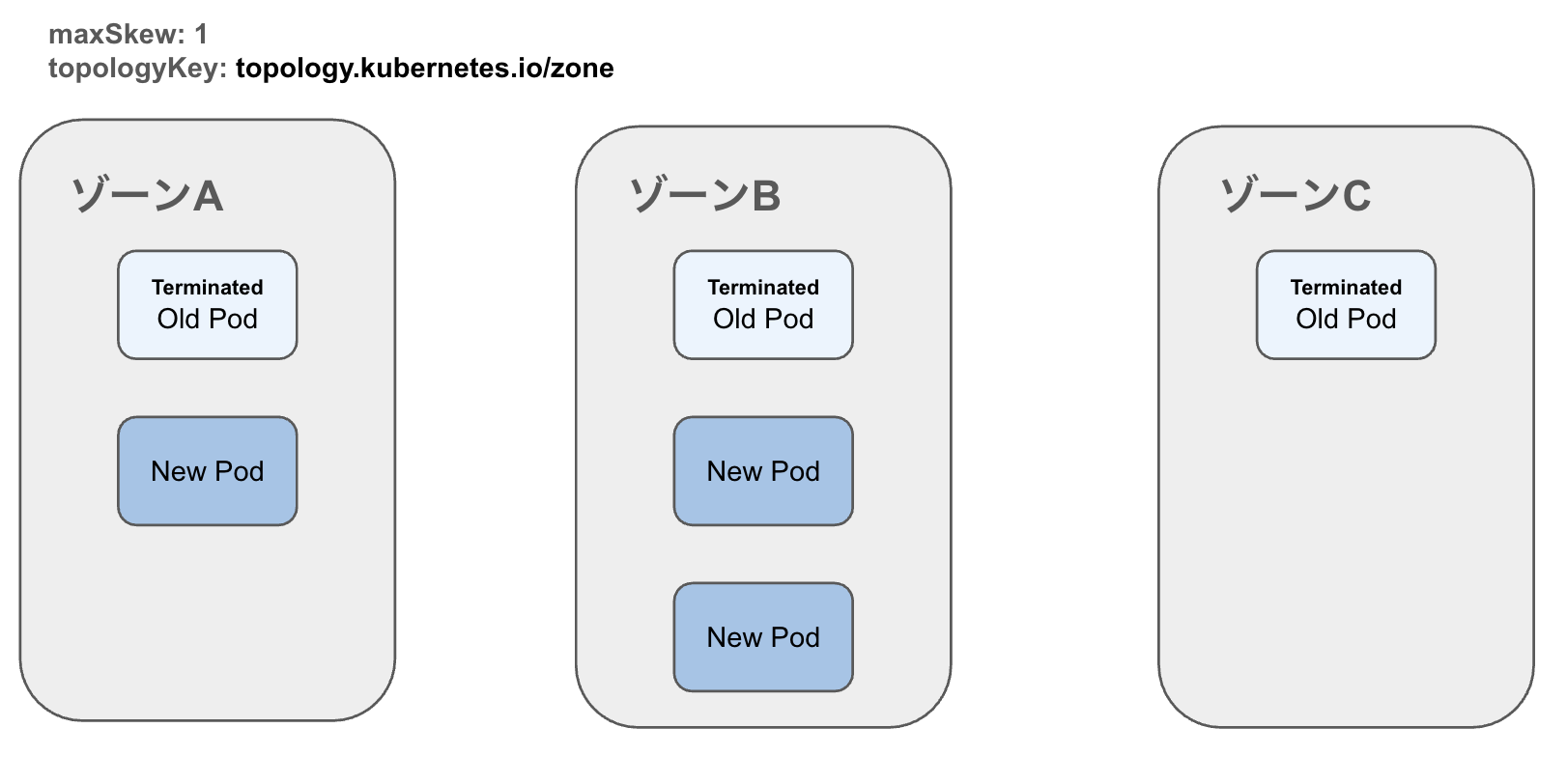
4. ゾーン間でPodの偏りが生じる
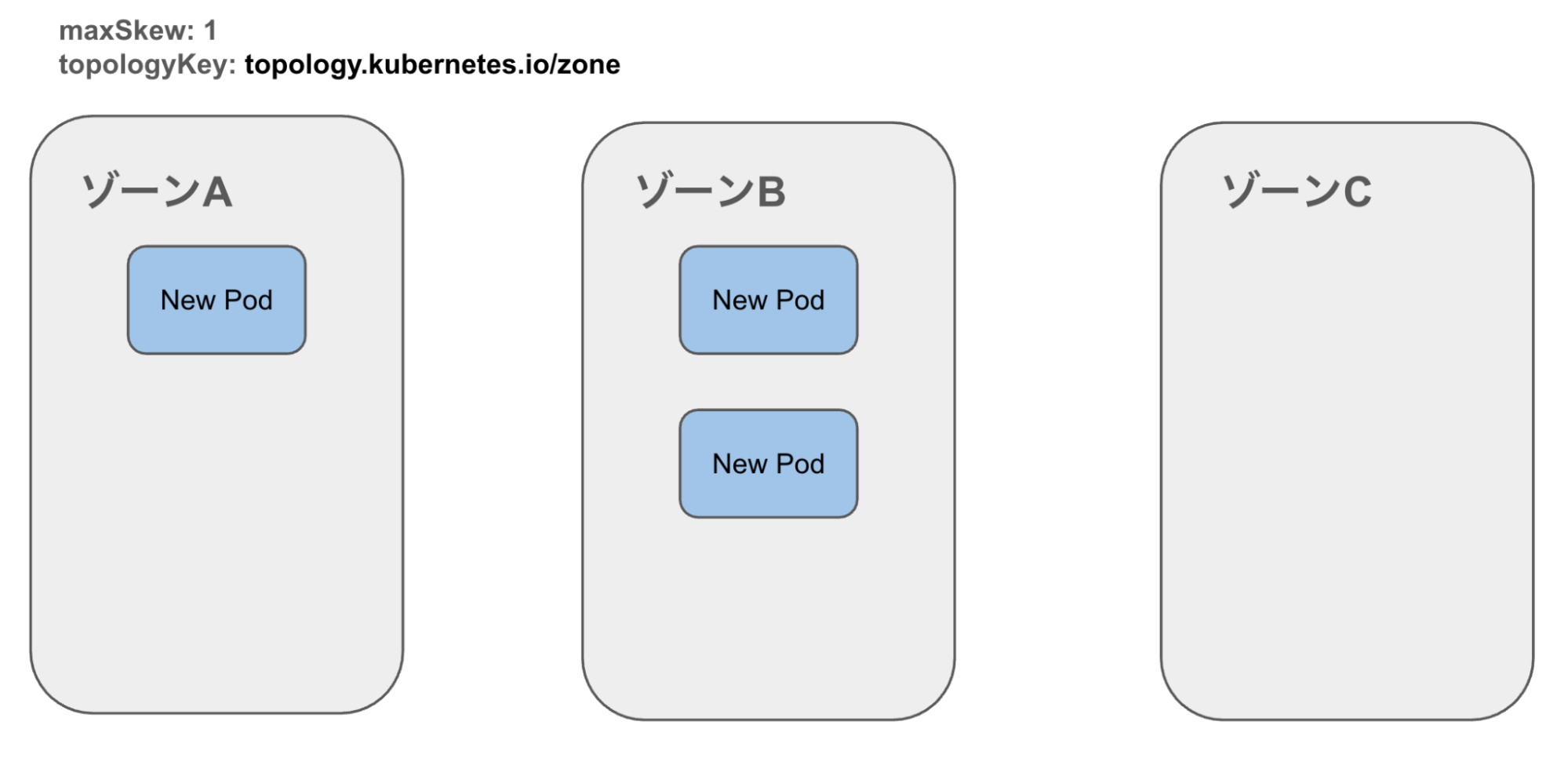
topologySpreadConstraintsは新規スケジューリング時のみ有効です。WINTICKETではHorizontal Pod Autoscaler(HPA)を導入しており、CPU利用率に応じて頻繁にスケールインがされますが、スケールインで生じたPodの偏りはtopologySpreadConstraintsでは再調整ができません。
そこで、deschedulerを導入し、定期的にPodの偏りを検出 → Evict(PodのTerminate) → 再スケジューリングすることで是正するようにしました。
deschedulerの導入
deschedulerは、すでに配置されたPodを評価し、設定した制約に違反しているPodをEvictすることで再スケジュールを促します。
実際の設定とその意味:
deschedulerは公式にHelm Chartsを提供しているため、Values Filesに以下のような設定を定義することで利用可能です。
deschedulerPolicy:
maxNoOfPodsToEvictPerNamespace: 1
profiles:
- name: default
pluginConfig:
- name: RemovePodsViolatingTopologySpreadConstraint
args:
constraints:
- ScheduleAnyway
- DoNotSchedule
plugins:
balance:
enabled:
- RemovePodsViolatingTopologySpreadConstraint
maxNoOfPodsToEvictPerNamespace:
1回の実行において namespace ごとに削除される Pod の数を制限し、deschedulerが過剰に作用するのを防ぎます。
profile:
ここにdeschedulerの振る舞いを設定します。
pluginConfig:
各プラグインに対して渡す個別のパラメータ設定を定義します。
上記の設定では、RemovePodsViolatingTopologySpreadConstraintプラグインに対して、constraintsをパラメータとして渡しています。
この設定により、topologySpreadConstraints.whenUnsatisfiableにScheduleAnywayまたはDoNotScheduleが指定されていて、分散制約を満たしていないPodを削除対象とします。
plugins:
実際に呼び出すプラグインを設定します。
上記の設定では、pluginConfigで定義した設定のもとRemovePodsViolatingTopologySpreadConstraintプラグインが実行されます。
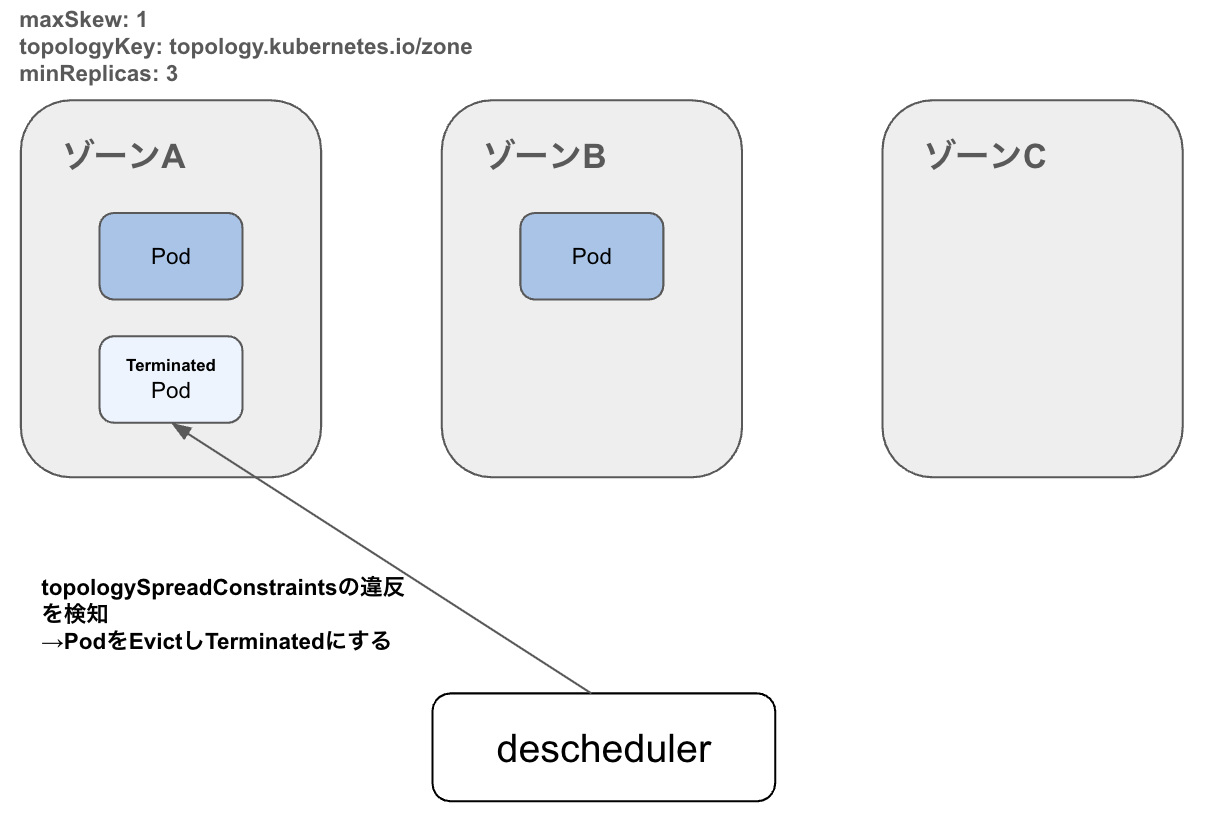
動作イメージ
1. Pod偏在を検出
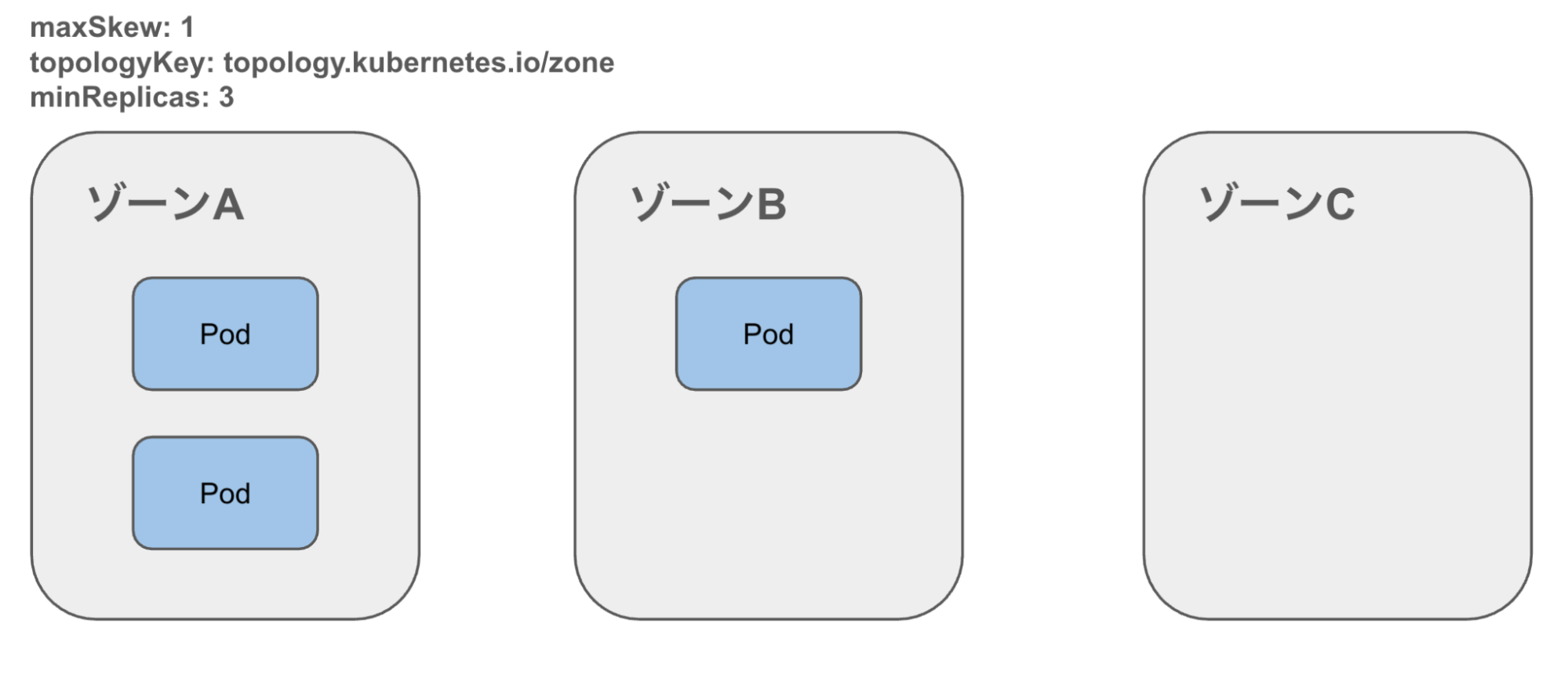
2. Evict
3. kube-scheduler が再配置
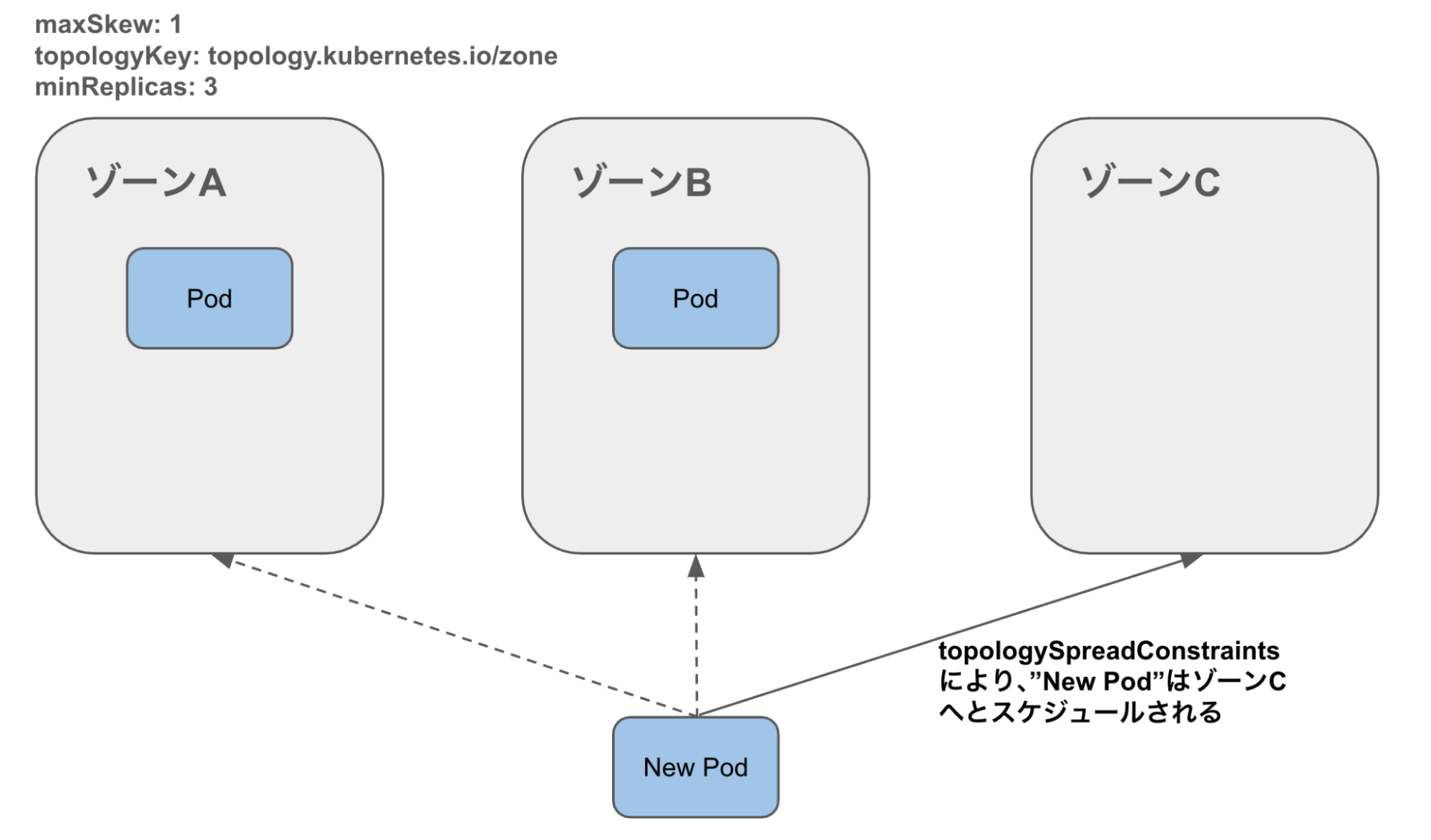
4. topologySpreadConstraints に基づいてゾーン分散される
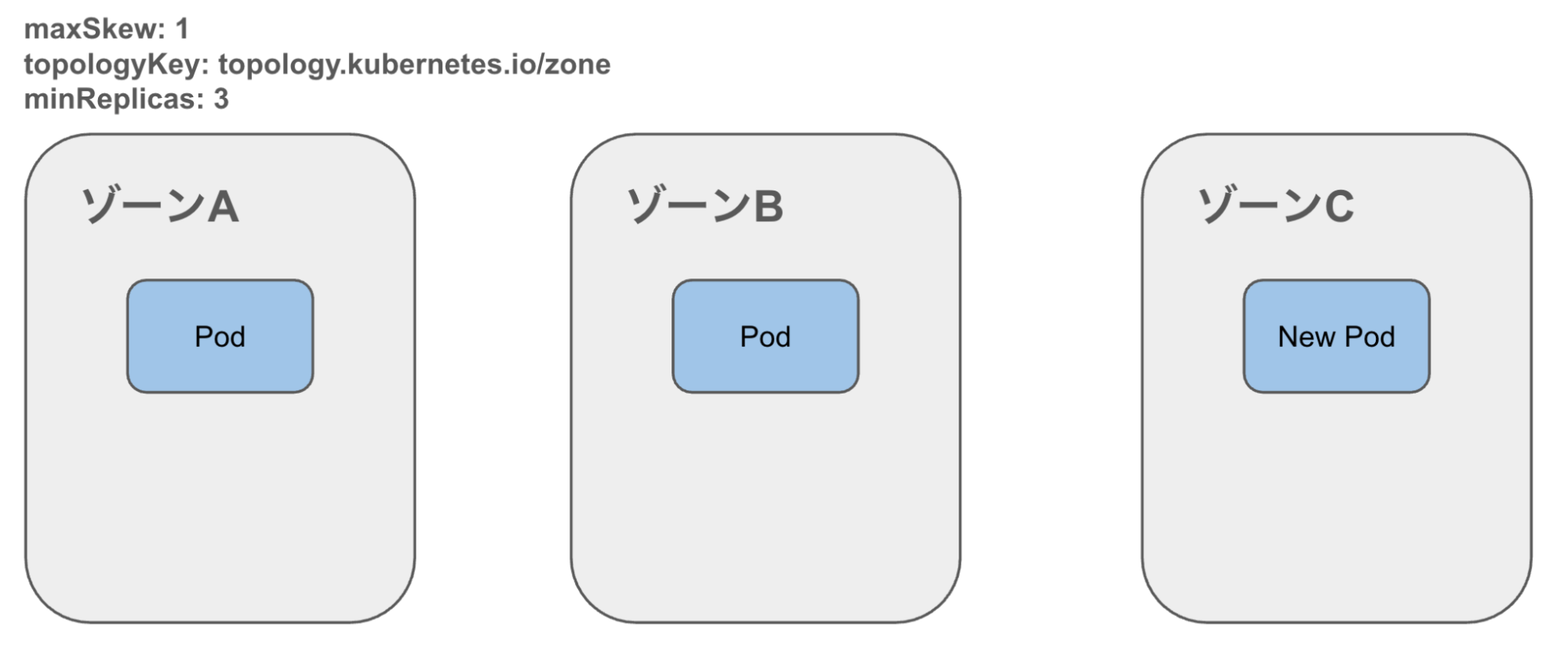
実際に本番環境にも導入し、deschedulerのコンテナログから以下のようにゾーン間に偏在したPodがEvictされるのを確認できました。

効果
Podのゾーン分散導入以降、「ゾーン分散導入の背景」で紹介した、ユーザーからのリクエストがOsakaリージョンへと優先的に流されてしまう事象は発生しなくなりました。
また、ゾーン分散を取り入れたことでゾーン障害発生時のダウンタイム発生のリスクを低減できると考えています。
まとめ
本記事では、GKEにおけるPodのゾーン分散を実現するために以下の2点を導入し、効果を得られたことを紹介しました。
- topologySpreadConstraints の導入
- descheduler の導入
これらの取り組みから得られた知見が、同じ悩みを抱える開発者の方々のお役に立てましたら幸いです。