
・はじめに
初めまして!
慶應義塾大学総合政策学部4年の安 柏勳(アン ポウシュン)です。私は2025年9月3日から1ヶ月間「CA Tech JOB」インターンシップにデータ基盤エンジニアとして参加しました。
・参加部署、部署の紹介
私は今回グループITにある DPU (Data Product Unit) という部署に配属されました。この部署では、各事業部で蓄積された大量のデータを効率的に活用できるようにするためのシステム基盤の開発や運用を行っています。
・取り組んだテーマの背景
DPU では現在、Kubernetes(以下、k8s)上にクラスタを構築し、データ処理エンジンとして Apache Spark を用いてクエリ処理を行っています。Spark は汎用性やエコシステムの成熟度に強みがある一方で、ワークロード特性によってはディスク I/O が発生しやすく、結果として一部クエリの応答時間が伸びるケースが確認されています。こうした点を踏まえ、更なる性能最適化や他方式の検討余地について整理を進めています。
そこで、In-memory 処理中心で高速なクエリエンジンである Trino があります。Trino も選択可能にし、インタラクティブなユースケースをサポートするという対策案が出てきたので今回は Trino 中心に実運用に向けて色々な調査を行ってきました。
・クエリエンジンとは
先ほど出てきたクエリエンジンなのですが、データベースやデータストアへのクエリを実行し、必要なデータを取り出すためのソフトウェアのことを指します。
今回扱う Spark, Trino はいずれも「分散処理エンジン」で、大規模なデータを複数のデータソース(RDB, KVなど)を横断してクエリを実行できます。分散アーキテクチャにより耐障害性を備えており、モダンなデータ分析・基盤構築で注目されています。
・インターン期間中の目標
- Spark, Trino の性能比較
- DPU 運用中の k8s クラスタ上で Trino を追加し、Spark とデータ共有を実現
- ベンチマークデータを用いて Spark, Trino の性能を比較し、特徴を分析する
- マルチテナント環境の実現性検証
- ResourceGroup と Trino-Gateway を活用し、リソース制限、リソース分離、可用性、そして動的ルーティング更新手法を検討
- 実用性評価、課題整理
- 本番環境導入に向けた技術的課題と運用上の考慮点の明確化
- Spark/Trino の使い分け指針の策定
・使用した技術
分散処理エンジン:Trino, Apache Spark
メタデータ、カタログ:Polaris Catalog
ストレージ:MinIO, MySQL
インフラ:Kubernetes
インフラ構成記述フォーマット:Yaml
使用した言語:SQL, Java
・実際に取り組んだ業務の流れ
まず、Trino を k8s クラスタ上で構築し、Polaris Catalog を通じて Spark と同じデータを参照できるようにしました。
Polaris Catalog とは、REST API を通じて Iceberg テーブルのメタデータを管理するサービスです。図で表すと以下のような構成が考えられます。
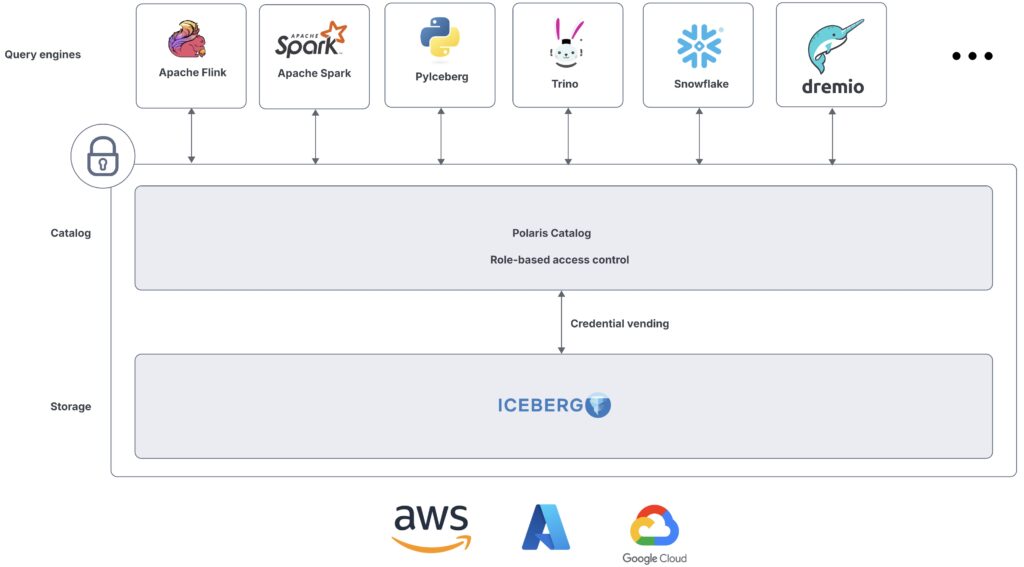
https://polaris.apache.org/releases/1.1.0/
それからベンチマークデータセットである TPC-H のデータ(Scale Factor 1)をストレージにアップロードし、ベンチマークデータを用いて性能比較を行いました。
22個のサンプルクエリから5つを選出し、実行時間、そしてピークメモリを計測しました。
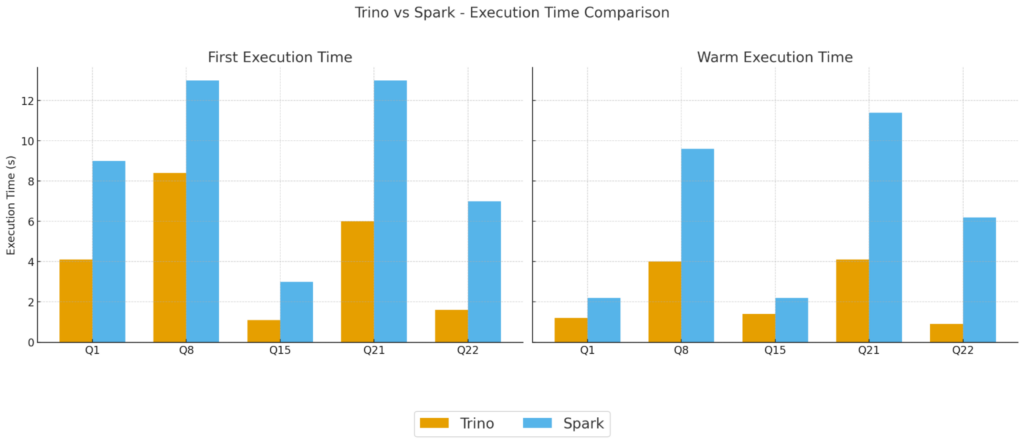
図1. Trino vs Spark の実行時間。(左辺)立ち上げ時。(右辺)その後の5回の平均値
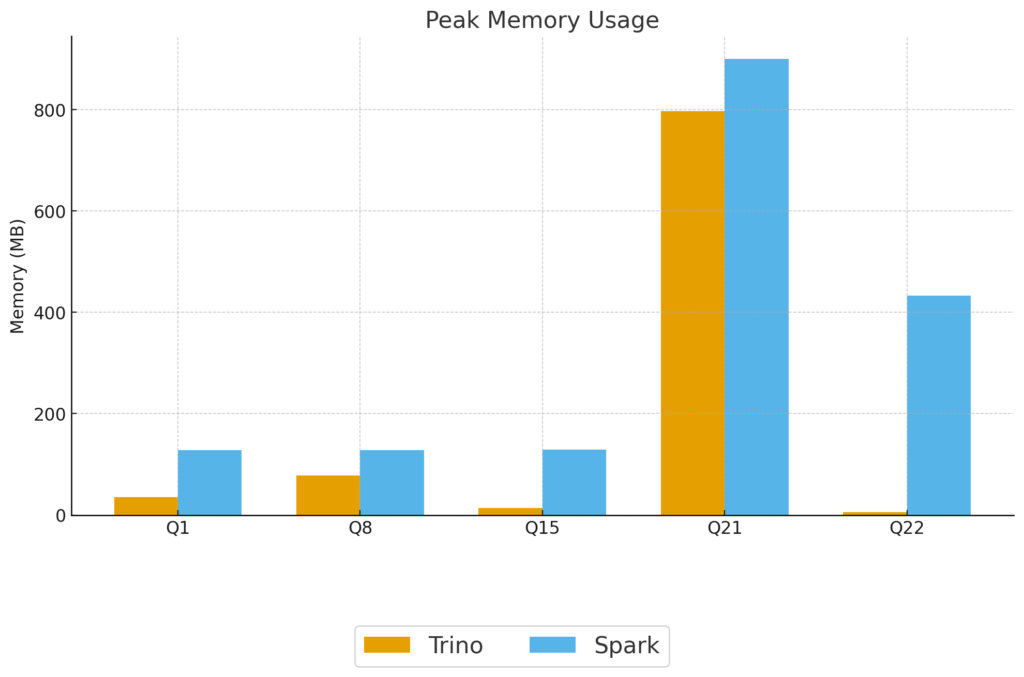
図2: Trino vs Spark の使用ピークメモリ
これらを踏まえて、TPC-Hにあるサンプルクエリを用いて以下の特徴をまとめました:
| 目的 | Spark | Trino |
| 軽量クエリが主流 | ⚪︎ | |
| ロングクエリが主流 | ⚪︎ | |
| スキュー、誤差耐性が欲しい | ⚪︎ | △ |
| 複数データソースに横断したクエリ | △ | ⚪︎ |
| メモリを厳格に制限したい | ⚪︎ | ⚪︎ |
Spark, Trino の特徴が分かり、使用場面によって効果的に使い分けることができると確認できました。
ただ、今回使用したデータセットのサイズは小さいので、Spark のよさをフルで出せるようなワークロードではなかったと思います。よりサイズが大きなデータセットを用いてさらに検証を進めていく必要はあると考えます。
次に、実運用を想定し、以下の検証を行いました:
- ノイジーネイバー
- アクセス制限
ノイジーネイバーとは、同じリソースを共有している他ユーザーがリソースを過剰に使用し、自分のサービスが劣化する現象を指します。
DPU で開発している分析環境で Spark はグループ単位でクラスタを払い出すことでノイジーネイバーを回避していますが、Trino でもそういったことが可能なのかを確認するために、ResourceGroup と Trino-Gateway を用いて検証しました。
ResourceGroup はクラスタ内でのリソース(使用可能メモリ、CPU時間、並列実行可能クエリ数など)をグループごとに分け、ユーザーのグループによって使えるリソースを制限する設定です。図にすると以下のようになります:
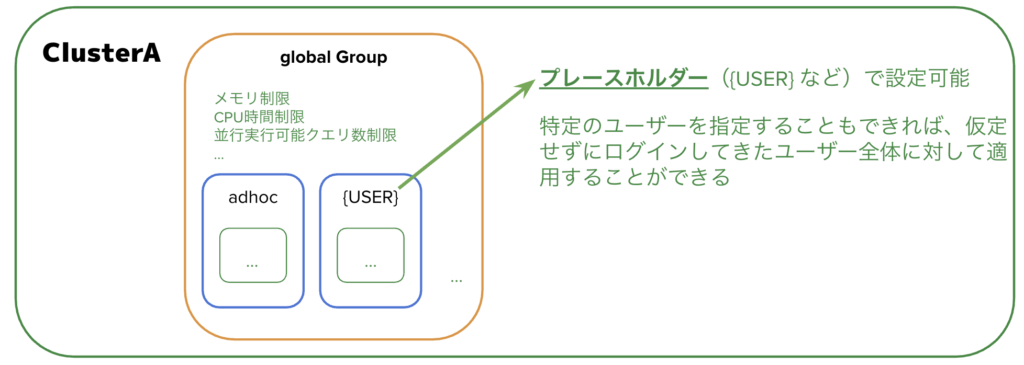
プレースホルダーを用いることで、特定ユーザーを仮定せずに全体に対して設定を適用できるので柔軟な変更が可能になります。
クラスタ内で複数の異なるグループを設定し、それぞれ異なるリソース使用量を割り当てることで、リソース制限が可能であることを確認できました。
クラスタ内でのリソース制限ができると分かったので、次は Trino-Gateway を用いてクラスタ単位でのリソース制限を確認しました。
Trino-Gateway は複数の Trino クラスタ向けのロードバランサー、プロキシサーバー、ルーティングゲートウェイであり、これを用いるとクラスタを透過的に増加可能で、自動ルーティングでユーザーは単一URLに接続すればクラスタにアクセスできるので便利なサービスです。
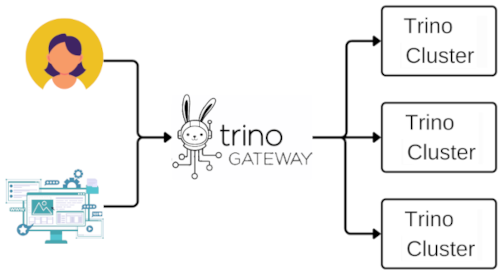
https://trinodb.github.io/trino-gateway/
Trino-Gateway を用いることで、クラスタごとに異なる資源(異なるコア数、ワーカー数、メモリ容量など)を与え、クラスタ単位によるリソース制限が可能であると確認しました。
さらに、それぞれのクラスタに対して独自の ResourceGroup を適用できるので、ResourceGroup と Trino-Gateway 両者を併用することでより柔軟で実用向けな構成ができると分かりました。
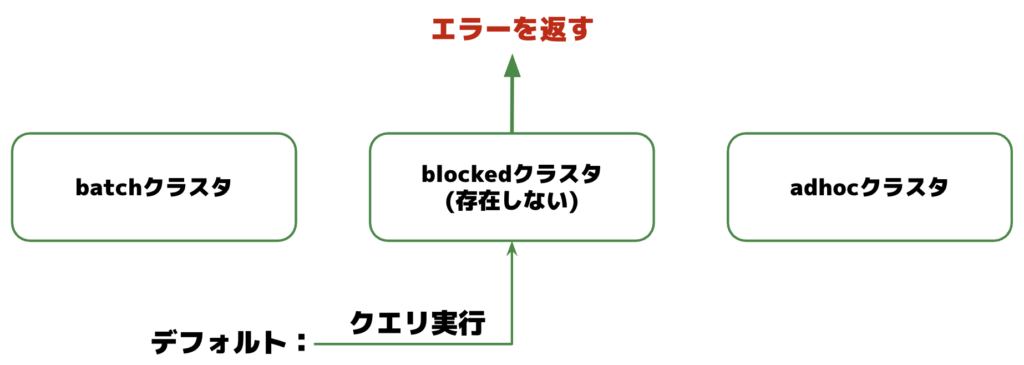
それだけでなく、クラスタごとに異なるカタログ設定をしたり、そもそも存在しないクラスタをデフォルトのルーティング先に設定することで、ユーザーがアクセスできるデータソースを制限することもできます。
イメージ図:
まとめ
・ノイジーネイバー回避は ResourceGroup と Trino-Gateway によって対処することができます。
・Trino-Gateway を用いるとカタログ粒度でのアクセス制限ができると検証しました。
・ResourceGroup と Trino-Gateway を組み合わせることで柔軟で実用的な構成が実現できることを確認しました。
ただ、残っているタスクもたくさんありまして、クラスタ内でのアクセス制限に関しては未完成です。
それだけでなく、Trino-Gateway において存在しないクラスタへアクセスした際に返ってくるエラーメッセージが単純でなぜエラーになったのか分かりにくいです。より詳しいエラーに関する情報をユーザーに返すようにエラーハンドリングも取り組んでいく必要があります。
・技術的な学び
自分の研究でも Trino などを使っていますが、深いアーキテクチャや最適化方式について知らないまま使用しておりました。今回の機会を通じ、Trino を大規模システムに組み込む際に必要な設定や要件について詳しくなっただけでなく、Trino の詳しい構造、構成について細かい粒度で理解を深めることができました。
それだけでなく、実際にDPUで使われいているデータレイクの構成を研究でも活用していきたいと思い、インターン期間中で得た知識や、トレーナーの涌田さんに質問して獲得した知見を用いて自分でデータレイクを構築することができ、より一層高度な研究ができると思います。
さらに、Yaml や Java についてコードリーディング、そしてハンズオンを通して理解度が格段に上がり、知らない言語に対する抵抗が少なくなりました。
・エンジニアとしての学び
開発では Kubernetes(k8s)上でシステムを構築していたため、クラスタを操作する kubectl や、管理・監視ツールである k9s にはほぼ毎日触れていました。システム構築がうまく進まないときには、ログをひたすら確認したり、構成ファイルを精査・再適用したりすることが多々ありました。
そこで学んだのは、いかに「やみくもに手を動かさずに」問題を解決するかという姿勢の重要性です。作業を始める前に、うまくいかない原因について仮説を立て、その仮説を検証する形で行動する必要があると実感しました。すぐに AI に頼ったり、手当たり次第に操作したりすると、かえって深い学びを得られず、結果的に時間を多く浪費してしまう場面が少なくありませんでした。
また、コミュニケーションを積極的に取る大切さにも気づきました。問題に直面して自分だけでは解決策を導けないときは、トレーナーや周囲の先輩に積極的に質問・相談・報告することが非常に重要です。知らないことは、どれだけ考えても「知らないまま」なので、知っている人から早めに吸収することの価値を学びました。
さらに、ミーティングや報告会などの場では、自分なりの考えを明確に持ち、それを躊躇せず共有する姿勢が大事だと感じました。たとえその考えが間違っていても、提示していればその場や後ほどフィードバックを得られます。逆に、伝えずに終わってしまうと学ぶ機会が減り、貴重な時間を無駄にしてしまいます。
・終わりに
短い期間でしたが、最初から最後までとても濃い時間を過ごすことができ、用いた技術やシステムの詳細について詳しく知ることができました。
トレーナーの涌田さんやメンターの大内さん、そして DPU に所属されている様々な方々に助けてもらいながら過ごした1ヶ月間で、本当にお世話になりました。ありがとうございました。