
はじめに
こんにちは。ABEMA の広告配信システム開発チームでバックエンドを担当している戸田朋花です。
ABEMA ではパーソナライズした広告配信ができるため、「ユーザー × 属性」がキーとなる高カーディナリティなデータに対する読み書きのリクエストが大量に発生します。
また全てのユーザーが全ての属性を持っているわけではないので、リクエストに対して実際にデータが存在しないことが多くあります。
その結果、読み取りのアクセスパターンとして「リクエストのカーディナリティがデータのカーディナリティを大きく上回る」状態になります。
ABEMA の広告配信サーバーには、このような性質のリクエストがピーク時には数千から数万 RPS で発生します。
データベースへ大量にリクエストが発生するとデータベースが高負荷となりシステム全体のボトルネックになります。
これを防ぐための一般的な方法として、キャッシュ用データストアを用意しキャッシュミス時のみデータベースへ問い合わせる構成が採用されます。
しかし、上で述べたアクセスパターンの場合キャッシュミスが頻発してしまい結局データベースへの負荷が高まってしまいます。
この状況下でデータベースへの負荷を削減するには、データの書き込み時に確率的データ構造である Bloom Filter を作成し読み取りリクエスト時に Bloom Filter を用いて事前にキーの存在判定を行うのが有効です。
本記事では、Bloom Filter の概要と Valkey 上で実現する場合の実践的な活用方法について紹介します。
Bloom Filter とは
Bloom Filter は「あるデータが特定の集合に含まれるか」を判定するために利用できるメモリ効率の良い確率的なデータ構造です。
通常は存在判定を行うにはすべてのキーを保持する必要がありますが、Bloom Filter では固定長の少ないメモリで実現できます。
例えば、1,000 万件のキーの存在判定を誤差率 1% で行う場合、必要なメモリはわずか数十 MB 程度です。
同じデータを全て保持する場合は 1 レコード 100byte とすると 1 GB のメモリが必要になるため、比較すると 100 倍近くメモリ効率が良いです。
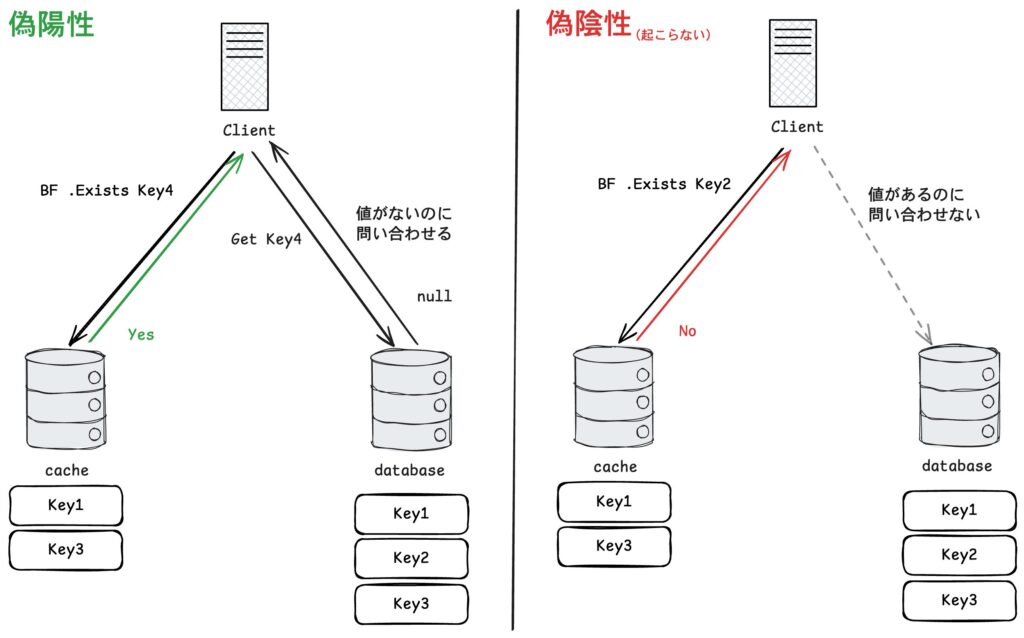
ただし、確率的なデータ構造なので厳密な答えは返さず「存在しないものを存在する」としてしまう偽陽性が発生する可能性があります。
一方で「存在するものを存在しない」としてしまう偽陰性は起こらない特徴があります。
そのため、存在しないものを除外するフィルタとして安全に使えます。
Bloom Filter の仕組み
Bloom Filter の実体はビット配列で、最初はすべて 0 に初期化されています。
キーを登録するときや確認する時は、複数のハッシュ関数を使ってビット配列の特定位置を更新・参照します。
キーの登録
Bloom Filter にキーを登録する際は、そのキーを複数のハッシュ関数に通してそれぞれの結果に対応するビットを 1 に設定します。
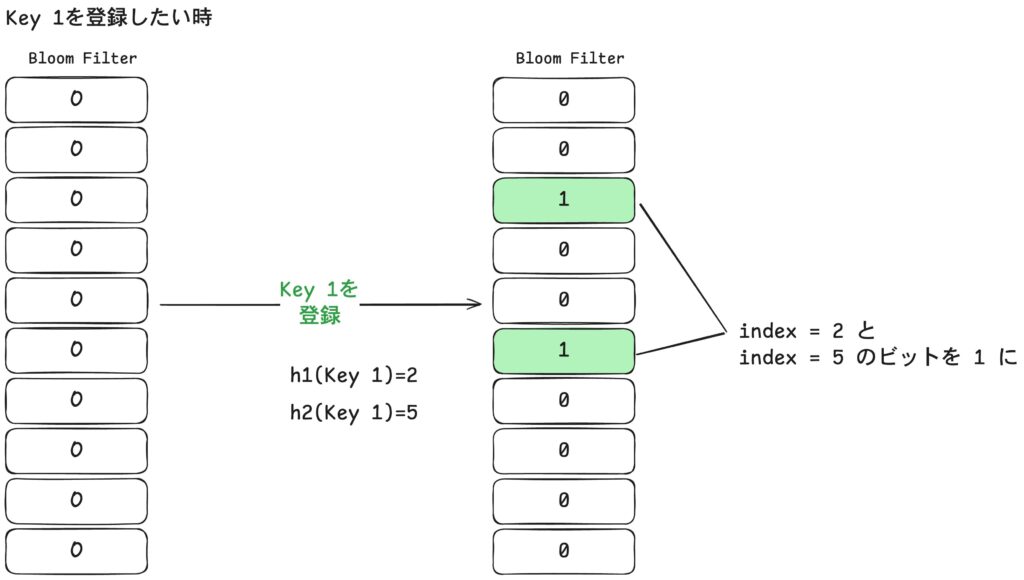
上の図では初期状態の Bloom Filter に Key1 を登録しています。
ハッシュ関数 h1 と h2 の出力がそれぞれ 2 と 5 だったため、index 2 と 5 のビットを 1 に設定します。
存在確認
特定のキーが登録されているか確認したいときは、登録時と同じハッシュ関数を使って対応するビットを調べます。
もしビットの中に 0 が 1 つでも含まれていれば、そのキーは Bloom Filter に登録されていないと判断できます。
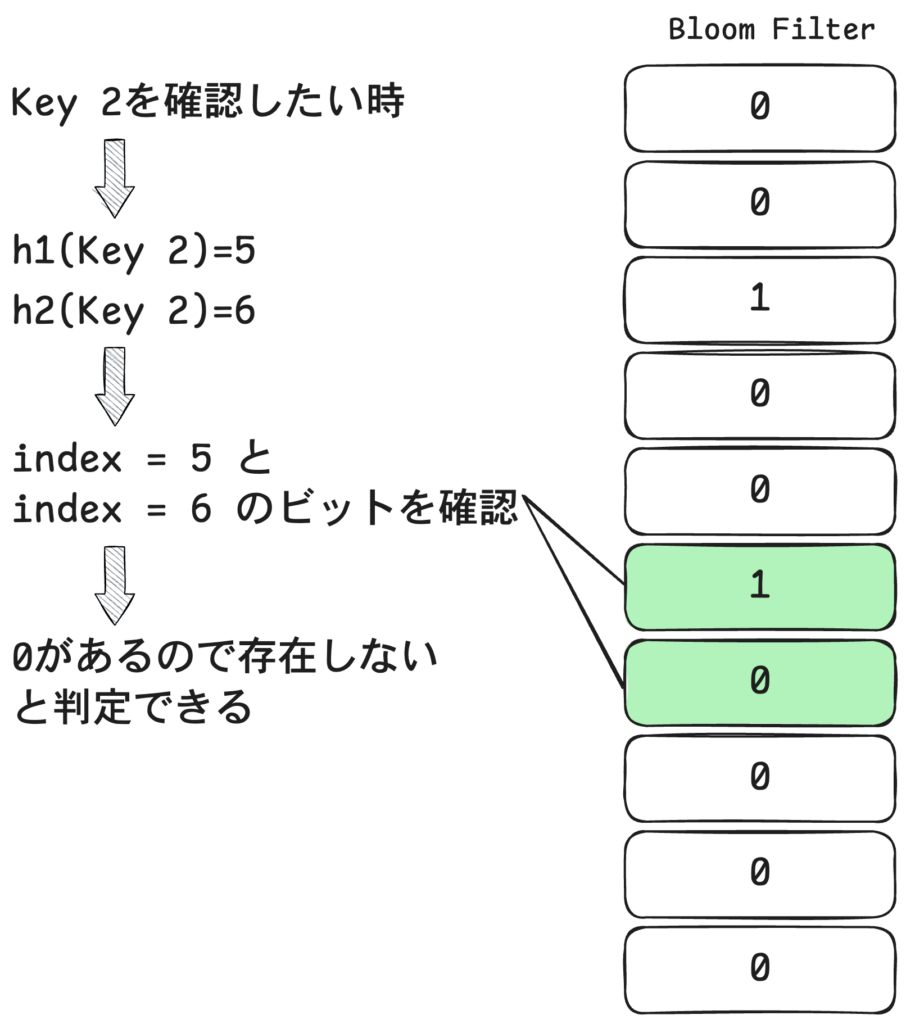
上の図では登録されていないKey2 の存在確認をしています。
Key2 に対してハッシュ関数を適用するとh1(Key2)=5, h2(Key2)=6 になります。
Bloom Filter 内の index 5,6 のビットを確認すると、index 6 が 0 なので Key2 は存在しないと判断できます。
一方ですべてのビットが 1 であっても実際に存在するとは限りません。
別のキーの登録によってたまたま同じビットが 1 になる場合があるためです。
これが偽陽性が起きる理由です。
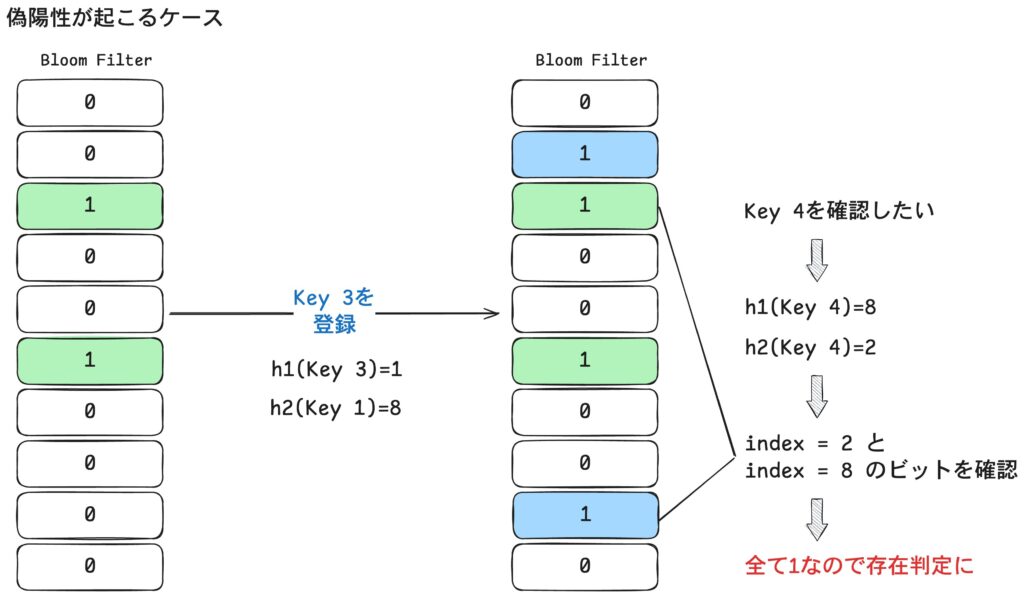
上の図では、Key1 に加えて Key3 を登録した後 Key4 の存在を確認しています。
Key4 のハッシュ結果 h1(Key4)=8, h2(Key4)=2 に対応するビットを確認すると、 偶然どちらも 1 になっていたためKey4 が存在すると誤って判断されます。
今回の例では簡単のためビット配列の長さを 10、ハッシュ関数の数を 2 個にしていますが、 実際に Bloom Filter を構築する際は格納予定のアイテム数と許容する偽陽性率をもとに最適なビット配列のサイズとハッシュ関数の数を決定します。
制約
このような仕組みで値を判定しているので単純な Bloom Filter では登録した値を削除できません。
複数の要素が同じビットを共有しているため、1 つの要素を削除すると他の要素の情報まで消えてしまうからです。
また登録されるキーが増えるほど 1 になるビットが多くなり異なるキーが同じビットを共有する確率が上がるため、偽陽性が発生しやすくなります。
Bloom Filter によるキャッシュでの存在判定
Bloom Filter の性質はキャッシュでデータベース上のデータの存在確認を行う用途に適しています。
値の書き込み
データベースに新しいデータを登録する際、Bloom Filter にも同じキーを登録します。
これにより Bloom Filter がデータベースに存在する可能性のあるキーを常に保持するようにになります。
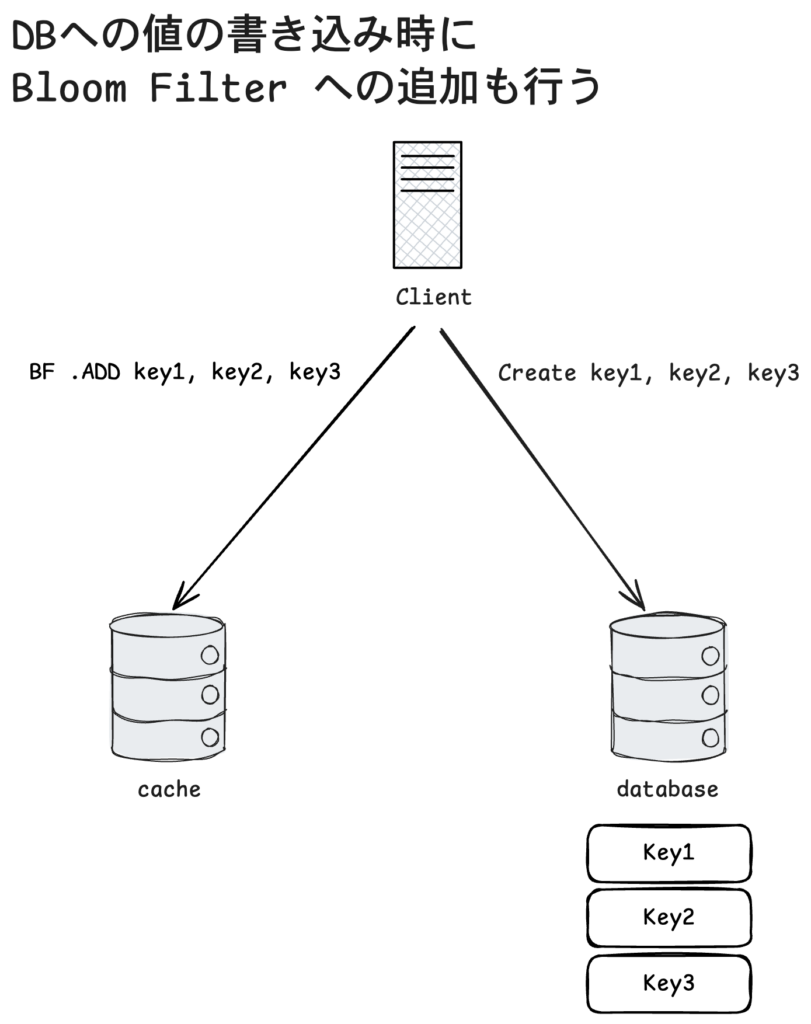
上の図ではクライアントが key1, key2, key3 をデータベースに書き込むと同時に同じキーを Bloom Filter に追加しています。
値の読み取り
キャッシュにキーが存在しなかった時、まず Bloom Filter に対して「データベースにそのキーが存在する可能性があるか」を確認します。
Bloom Filter が「存在しない」と答えた場合、そのキーは確実に存在しないのでデータベースに問い合わせる必要がありません。
一方で Bloom Filter が「存在するかもしれない」と答えた場合には実際にデータベースへ問い合わせを行います。
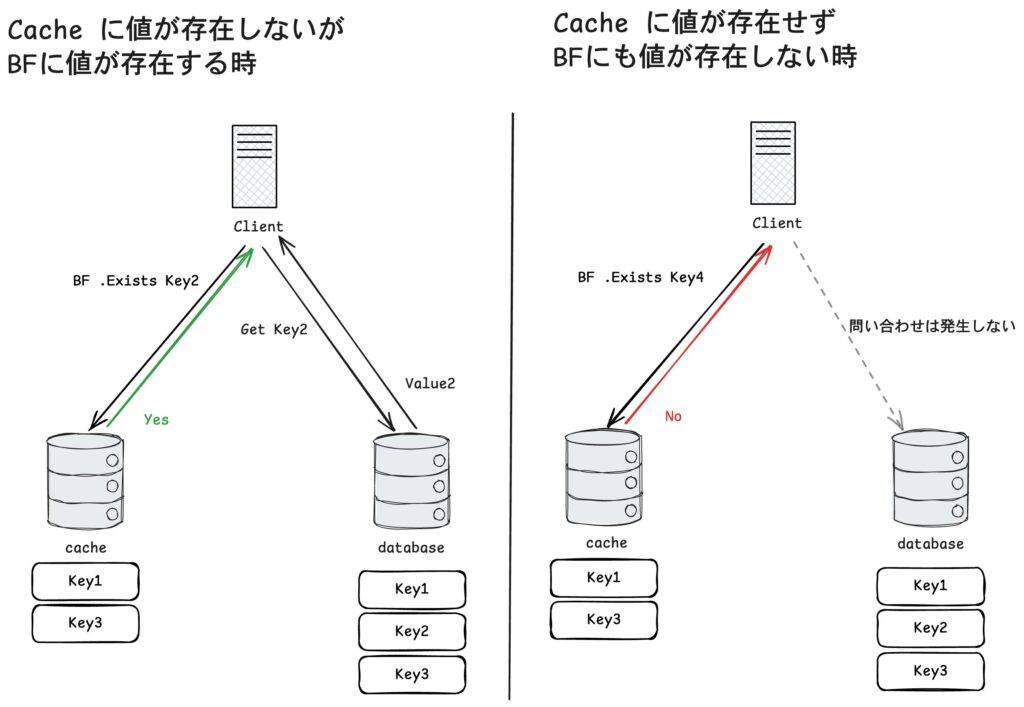
図の左ではキャッシュに Key2 がない場合でも Bloom Filter によりデータベースに存在する可能性があるのがわかったため、データベースへ問い合わせて値を取得しています。
図の右では Key4 が Bloom Filter にも存在しないためデータベースへの問い合わせを行っていません。
この仕組みにより存在しないキーに対する無駄な DB アクセスを防げます。
Bloom Filter は偽陰性が発生しないため、本当は存在するデータを「存在しない」と判定することはありません。
偽陽性は発生し得ますが余分な問い合わせが増えるだけで、Bloom Filter を使わない場合に比べれば問い合わせ総数は大幅に減らせます。
例えば全リクエストのうち実際にデータベースに値が存在する割合を 20% とします。
Bloom Filter の偽陽性率を 1% に設定した場合、存在しない 80% のリクエストのうち 1%(= 全体の 0.8%)が誤って存在すると判定されます。
したがってデータベースへ到達するリクエストは実際に存在する 20% + 偽陽性による 0.8% = 約 20.8% に抑えられます。
このように Bloom Filter を利用すれば安全にデータベースへのトラフィックを減らせます。
valkey-go を用いた Bloom Filter の利用
ABEMA では Google Cloud の Memorystore for Valkey をキャッシュとして利用しています。
Valkey にはモジュールを導入し機能を拡張できる仕組みがあり、Bloom Filter もvalkey-bloom モジュールを導入すれば利用できます。
しかし残念ながら Memorystore for Valkey ではモジュールの導入がサポートされていません。
そこで代替手段を調べたところ、Valkey の Go クライアントライブラリのvalkey-goで Bloom Filter の機能が提供されているのがわかりました。
valkey-go には valkeyprob パッケージ として Bloom Filter の実装が含まれています。
今回はその使い方を簡単にご紹介します。
bf, err := valkeyprob.NewBloomFilter(client, "bloom_filter", expectedNumberOfItems, falsePositiveRate)
if err != nil {
panic(err)
}
err = bf.Add(ctx, "hello")
if err != nil {
panic(err)
}
exists, err := bf.Exists(ctx, "hello")
if err != nil {
panic(err)
}
fmt.Println(exists) // true
NewBloomFilter では格納予定のアイテム数と許容する偽陽性率を指定して Bloom Filter を作成します。
作成後は Add や Exists メソッドを呼ぶだけで、値の登録や存在確認を簡単に実行できます。
では実際にどれくらいのメモリを使用するのでしょうか。
valkey-go では Bloom Filter を内部的に bitmap 型で保持しています。
bitmap 型は Valkey の文字列型をビット列として操作ができる仕組みです。
このサイズは次の式で計算されます。
func numberOfBloomFilterBits(n uint, r float64) uint {
return uint(math.Ceil(-float64(n) * math.Log(r) / math.Pow(math.Log(2), 2)))
}
この式に基づくと例えばアイテム数 1,000・偽陽性率 0.1% の場合は 約 1.8KB、アイテム数 10 億・偽陽性率 0.01% の場合は 約 1.8GB が必要になります。
Valkey の bitmap 型は最大で 512MB しか扱えない制約があります。
そのため数十億単位のアイテムを 1 つの Bloom Filter に格納できません。
この場合はキーの範囲等で Bloom Filter 自体を複数に分割すれば Bloom Filter を実現できます。
Sliding Bloom Filter
前述のように Bloom Filter は登録する値が増えていくとビット列の中で 1 の割合が高くなり、偽陽性率が上昇してしまいます。
データのライフサイクルが長い場合は問題になりにくいものの、短期間で大量のデータが生成される環境ではすでに無効になったキーのビットが残り続け精度が低下していきます。
この場合は一定期間ごとに Bloom Filter を交換する仕組みが有効です。
その代表的な方法が Sliding Window Bloom Filter です。
valkey-go の valkeyprob パッケージには、この Sliding Window Bloom Filter も用意されており通常の Bloom Filter と同様に利用できます。
sbf, err := NewSlidingBloomFilter(client, "sliding_bloom_filter", expectedNumberOfItems, falsePositiveRate, windowDuration)
err = sbf.Add(ctx, "hello")
if err != nil {
panic(err)
}
exists, err := sbf.Exists(ctx, "hello")
if err != nil {
panic(err)
}
fmt.Println(exists) // true
NewSlidingBloomFilter では通常の Bloom Filter と同様にアイテム数と偽陽性率を指定し、加えて保持期間を指定して Sliding Bloom Filter を作成します。
値の登録と確認は通常の Bloom Filter と同様にできます。
フィルター交換のロジック
valkeyprob の Sliding Bloom Filter では Bloom Filter を 2 つ用意し、ウィンドウを半分ずつ重ねながらローテーションさせることで古いフィルタを入れ替えます。
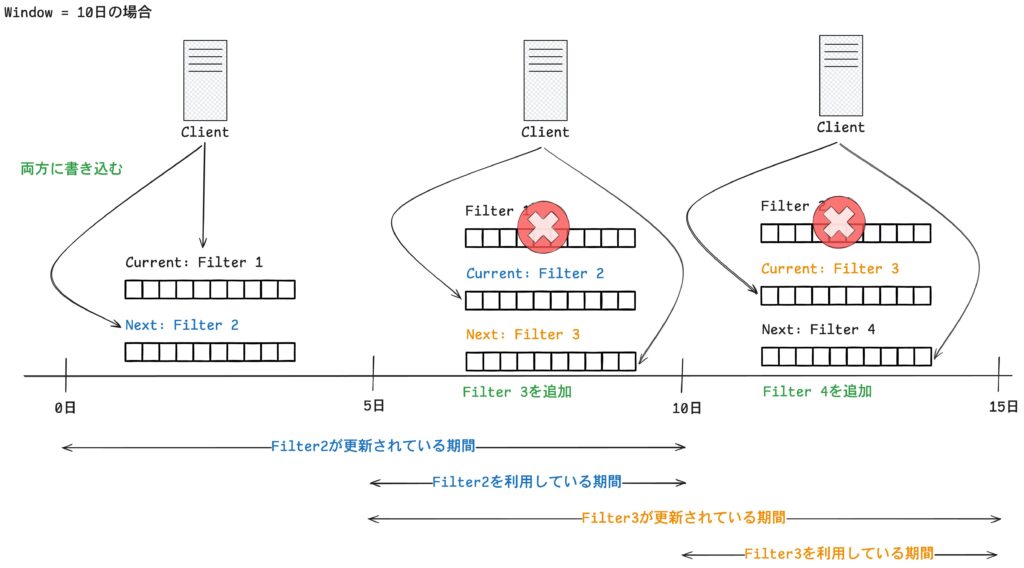
上の図は window が 10 日間の場合のローテーションの流れです。
0〜5 日の間
データを追加する時はCurrent(Filter 1)と Next(Filter 2)の 両方に書き込みます。
存在確認は現在のフィルタである Filter 1 に対して行われます。
5 日が経過した時点
ウィンドウの半分に達すると Filter 1 は破棄され Filter 2 が新しい Current に昇格します。
同時に新しい空のフィルターとして Next(Filter 3)が生成されます。
以降、10 日目までは存在確認は Filter 2 を用いて行われます。
10 日が経過した時点
Filter 2 が破棄され Filter 3 が Current に昇格します。
同時に新しい Next(Filter 4)が追加されます。
ここから先は Filter 3 を用いて存在確認が行われます。
Filter 3 は 5 日目に生成されたので、この時点で 0〜5 日の間に Bloom Filter に登録されていたキーは Filter 3 に含まれていません。
この仕組みによって各キーは追加されてから最大で 1 ウィンドウ分までしか保持されないようになっています。
終わりに
本記事では Bloom Filter の仕組みと活用方法を紹介しました。
リクエストのカーディナリティが高い場合、キャッシュミスによる無駄なアクセスがデータベースに負荷をかけてしまいます。
Bloom Filter を導入すると存在しないキーへの問い合わせを効率的に排除して安全にデータベースへの負荷を下げられます。
また長期間 Bloom Filter を運用することで偽陽性率が高まる問題に対しても Sliding Bloom Filter の活用により対応できます。
ABEMA の広告配信システムにおいても同様の仕組みを活用できる場面は多くありそうです。今後の運用改善の方法として積極的に検討していきたいと考えています。
最後まで読んでいただき、ありがとうございました。