

目次
この記事で学べること
- AI エージェントが自律的に分析できるデータ分析基盤の設計思想
- Protocol Buffers を起点としたスキーマ駆動開発
- Dataform によるパイプライン管理と Dataplex によるデータ品質の担保
- Devin を活用した分析自動化の実装方法
想定読者
- データ分析業務の効率化に興味があるエンジニア・データアナリスト
- AI エージェントの実務活用を検討している方
- データ分析基盤の設計・運用に携わっている方
はじめに
株式会社 WinTicket でデータエンジニアをしている山田瑠奈(@___ryamaaa)です。
WINTICKET では、競輪・オートレースのインターネット投票サービスを提供しており、日々膨大なデータが蓄積されています。現在、データマネジメントチームでは、AI-Ready なデータ分析基盤を整備し、AI によるデータ分析業務の効率化を目指しています。
本記事では、どんな設計思想でデータ分析基盤を構築し、どのように AI エージェントを実装しているのか、現在の取り組みを紹介します。
データ分析の課題
WINTICKET では、データを活用した意思決定が日常的に行われています。一方で、分析に必要なドメイン知識が個々のメンバーに属人化しており、事業部メンバーで分析を完結できるのは 3〜4 名に限られていました。以前はデータ分析への依頼が多く発生していましたが、回答までに数日かかることも多く、データ活用のスピードがボトルネックになっていました。
取り組み:SQL 研修
この課題に対し、2025 年 3 月に事業部内で2日間の SQL 研修を実施しました。
事前に Progate で SQL の基礎を学んでもらい、研修では BigQuery の使い方やデータマートの構造を説明しました。実際のビジネス課題を題材にした問題集も作成し、データの説明や SQL のノウハウも改めて整備しました。
研修によって SQL を書けるメンバーは増え、一定の成果がありました。しかし、自力で分析を完結できるメンバーは依然として限られていました。研修参加者からは次のような声が上がりました:
- 「SQL は書けるようになったが、どこにどんなデータがあるのかわからない」
- 「このカラムが具体的に何を意味しているのか、誰に聞けばいいのかわからない」
- 「どのテーブルを JOIN すればいいか、どんな集計が適切かわからない」
これらの声から、SQL の構文を学ぶだけでなく、メタデータやドメイン知識へのアクセスが重要だと実感しました。ドキュメントを整備しても情報が散在していると探すのに時間がかかり、結局詳しいメンバーに聞く方が早いという状況は変わりませんでした。
解決策: AI-Ready なデータ分析基盤の構築
この状況を打破するため、AI エージェントを活用したアプローチに着目しました。AI が理解しやすい形でメタデータやドメイン知識を集約し、AI が自律的に情報を参照しながら分析できる環境を構築すれば、「詳しいメンバー」の役割を AI が担えるようになります。AI が必要な情報を自動で収集して分析できれば、データサイエンティストやビジネスメンバーはより戦略的な業務に集中できます。
データ分析基盤システム全体像
データパイプラインの構成
WINTICKET では、以下のようなデータパイプラインでデータを処理しています:
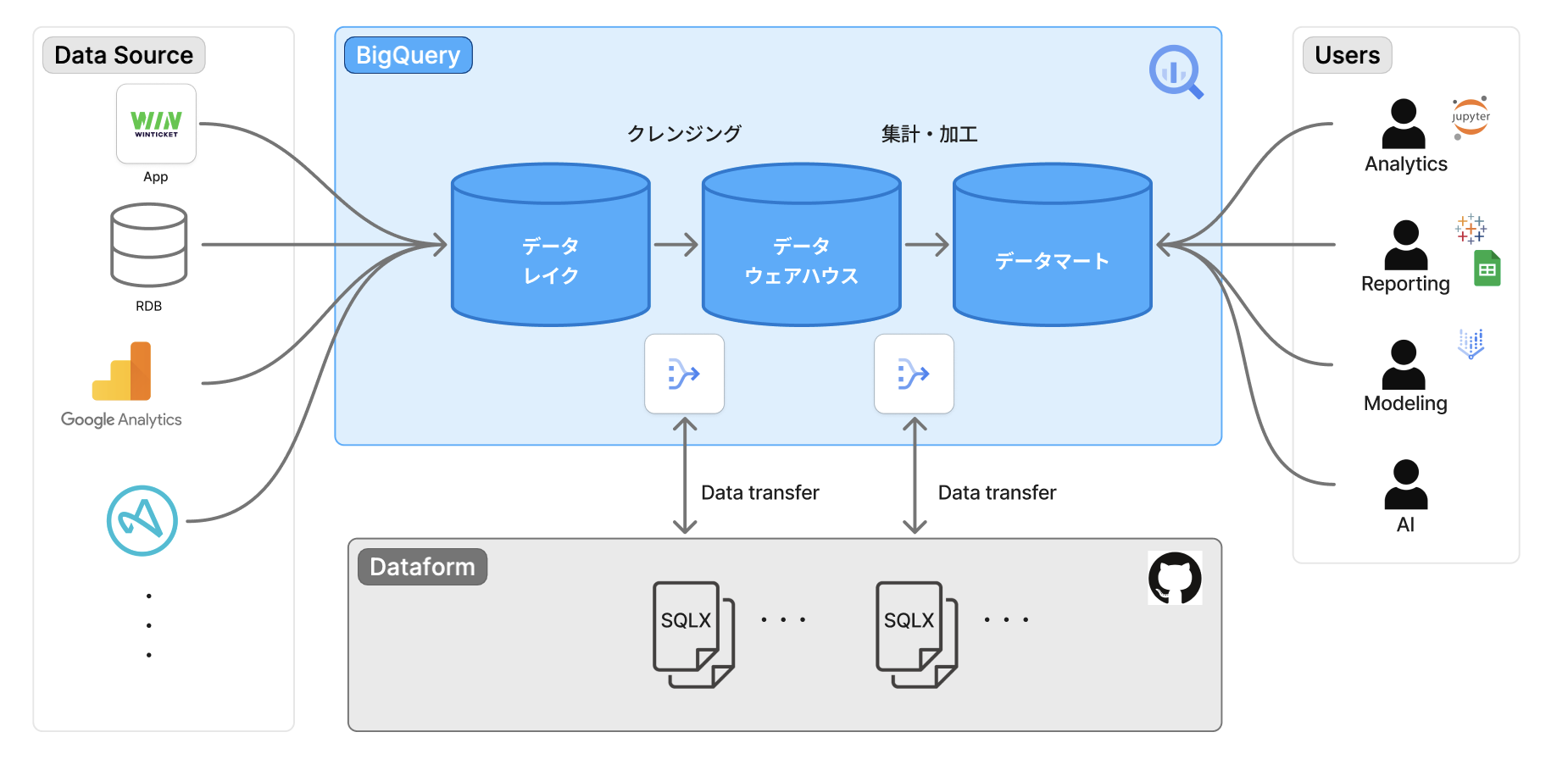
アプリケーションから送信されたイベントデータや RDB のマスターデータは、Data Lake → Data Warehouse → Data Mart の3層構造で段階的に変換・集計され、最終的に様々な用途で活用できる形になります。このパイプライン全体を支えているのが、次に説明する Protocol Buffers によるスキーマ管理です。
Protocol Buffers によるスキーマ管理
WINTICKET では、Protocol Buffers でイベントスキーマを定義し、スキーマレジストリで一元管理しています。
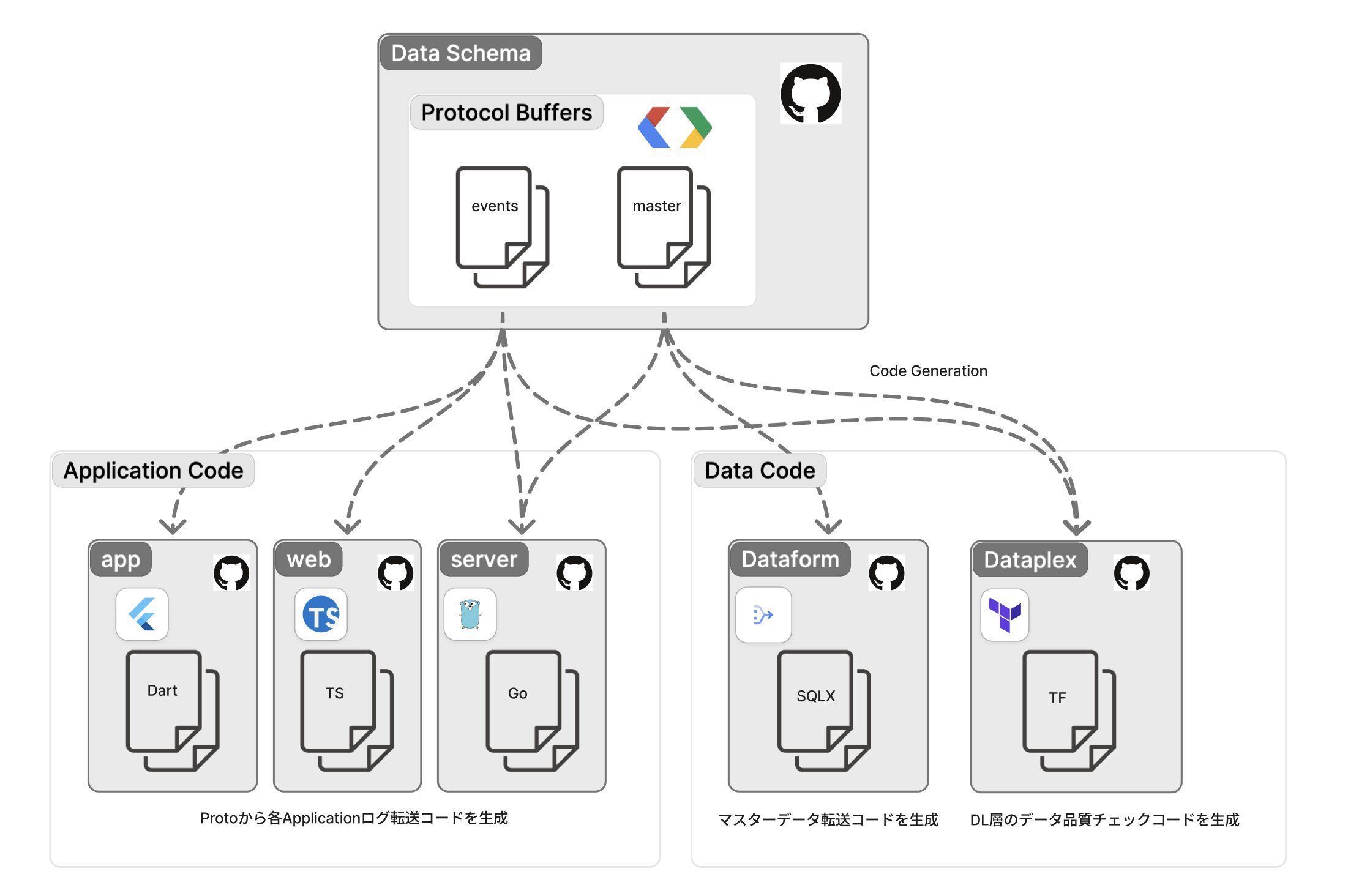
Protocol Buffers を Single Source of Truth として、以下のコンポーネントを自動生成しています:
- アプリケーションコード: ログ送信コード(Dart、TypeScript、Go など)
- ETL 処理: RDB マスターデータの抽出・変換処理
- Dataplex 品質ルール: Data Lake 層のデータ品質チェック定義
この仕組みにより、スキーマ定義・アプリケーション・データウェアハウス・データ品質管理の一貫性が保たれ、定義の二重管理を排除しています。
// 投票イベントの例
message BetEvent {
string bet_id = 1 [
(options.field_description) = "投票ID"
];
string user_id = 2 [
(options.field_description) = "ユーザーID"
];
string race_id = 3 [
(options.field_description) = "レースID"
];
int64 bet_amount = 4 [
(options.field_description) = "投票金額(円)"
];
string race_category = 5 [
(options.field_description) = "競技種別",
(options.allowed_value) = {
value: "keirin"
description: "競輪"
},
(options.allowed_value) = {
value: "autorace"
description: "オートレース"
}
];
}
Dataform によるデータパイプライン管理
WINTICKET では Dataform を使って、Data Lake 層(生データ)→ Data Warehouse 層(クレンジングや共通的な変換処理)→ Data Mart 層(分析用)の 3 層構造でデータ変換パイプラインを管理しています。
Dataform のリポジトリは以下のように階層化しています:
dataform-repository/
├── definitions/
│ ├── datalake/ # Data Lake 層の変換定義
│ ├── datawarehouse/ # Data Warehouse 層の変換定義
│ │ ├── event/ # イベントデータ
│ │ ├── master/ # マスターデータ
│ │ └── ...
│ ├── datamart/ # Data Mart 層の集計定義
│ │ ├── fact/ # 集計済ファクトテーブル
│ │ └── dimension/ # 集計済ディメンションテーブル
│ ├── assert/ # データ品質チェック
│ └── ...
└── ...
Dataplex によるデータ品質管理
Dataplex で Data Lake 層のデータ品質チェックを自動化しています。
前述の Protocol Buffers で定義した BetEvent を例に、自動生成される品質チェックルールを紹介します:
# BetEvent の品質チェック(Protocol Buffers から自動生成)
resource "google_dataplex_datascan" "bet_event_quality" {
data_scan_id = "bet_event_quality_check"
execution_spec {
trigger {
schedule {
cron = "TZ=Asia/Tokyo 0 9 * * *"
}
}
}
data_quality_spec {
# Protocol Buffers の定義から自動生成されるルール
# user_id: 必須フィールド(required)の非NULL チェック
rules {
dimension = "COMPLETENESS"
column = "user_id"
non_null_expectation {}
}
# bet_amount: int64 型の範囲チェック(負の値を許容しない)
rules {
dimension = "VALIDITY"
column = "bet_amount"
range_expectation {
min_value = "0"
}
}
# race_category: allowed_value で定義された enum 値チェック
rules {
dimension = "VALIDITY"
column = "race_category"
set_expectation {
values = ["keirin", "autorace"] # Protocol Buffers の allowed_value から生成
}
}
}
}
品質に問題がある場合は Slack に通知する仕組みを作っており、誤ったデータで分析するリスクを減らしています。
これらの品質チェックルールは、Protocol Buffers の定義から自動生成しています。スキーマに定義された field_description や allowed_value といったメタデータを解析し、対応する Dataplex のルールを生成することで、スキーマ定義とデータ品質管理の一貫性を保っています。スキーマを更新すれば品質チェックルールも自動で更新されるため、定義の二重管理や不整合を防げます。
AI-Ready なデータ分析基盤の構築
前述のデータ分析基盤を、AI が活用しやすい形に整備していきました。AI が自律的に分析を進めるには、データの意味を理解する、適切なテーブルを選べる、ビジネスコンテキストを把握できる、という3つの要素が必要です。
メタデータの充実でデータの意味を理解可能に
AI がデータの意味を正しく把握できるよう、Protocol Buffers と Dataform でメタデータを整備しました。
Protocol Buffers でのスキーマ定義
Protocol Buffers でイベントスキーマを定義する際、各フィールドに field_description を記述し、enum 型のカラムには allowed_value で取りうる値とその説明を定義しています(前述のコード例を参照)。
Dataform でのメタデータ強化
Dataform では、config ブロックで全カラムに description を付けることをルール化しました。各 .sqlx ファイルには、SQL の定義と一緒にテーブルやカラムの説明を記述しています。
config {
type: "table",
description: "投票イベントテーブル",
columns: {
bet_id: "投票ID",
user_id: "ユーザーID",
race_id: "レースID",
bet_amount: "投票金額(円)",
race_category: "競技種別(keirin: 競輪, autorace: オートレース)"
}
}
SELECT ...
AI エージェントは GitHub 上の Protocol Buffers や Dataform リポジトリを参照し、どのテーブルがどんな処理を経て作られているか、各カラムが何を意味するかを把握します。
データ構造の明確化で適切なテーブル選択を可能に
Data Warehouse 層には、マスターデータとイベントデータを合わせて100個以上のテーブルがあります。その中から分析に適したテーブルを選ぶのは、人間でも迷うことが多くあります。
Data Mart 層に主要な集計処理ロジックを集約し、ファクトテーブル(ユーザー行動:投票、課金などのトランザクション)とディメンションテーブル(ユーザー属性・レース情報などのマスター)に分けて整理しました。主要な分析は Data Mart 層で完結できるようにしています。
テーブル利用の優先順位
階層構造を活かし、分析では集計済みの Data Mart 層から優先的に利用するという方針を定めています。AI も同様に、まず Data Mart 層のテーブルを探索し、必要に応じて Data Warehouse 層を参照します。
ドキュメントの体系化でビジネスコンテキストの理解を可能に
Dataform リポジトリ内に docs/ ディレクトリを作成し、ドキュメントを体系的に整備しています:
dataform-repository/docs/
├── architecture/ # データ構造の設計思想
│ ├── overview.md # 全体アーキテクチャ
│ └── datamart-layer.md # Data Mart層の設計方針
├── features/ # 各テーブルの詳細設計
│ ├── datamart/
│ │ ├── fact/ # ユーザー行動集計
│ │ └── dimension/ # ユーザー属性・レース情報
│ └── ...
├── business-domain/ # ビジネスドメイン知識(用語集、コーディング規則など)
└── operations/ # 運用手順
各テーブルの設計意図、ビジネスロジック、使用上の注意点などを記載しています。特に business-domain/ には、競輪・オートレースのビジネスモデルや投票種別(3連単、2車単など)といった WINTICKET ならではのドメイン知識を蓄積しています。
AI はこれらを参照し、データの背景にあるビジネスコンテキストを把握します。単なるテーブル定義だけでなく、「なぜこの集計が必要なのか」「どういう場面で使うべきか」といった判断もできるようになります。
AI エージェントの実装
これらのデータ分析基盤と、AIエージェントの Devin が連携することよって分析自動化の仕組みを構築しています。以下の図は、Slack からの依頼が Devin を経由してデータ分析基盤とやりとりし、分析結果を返すまでの全体像です:
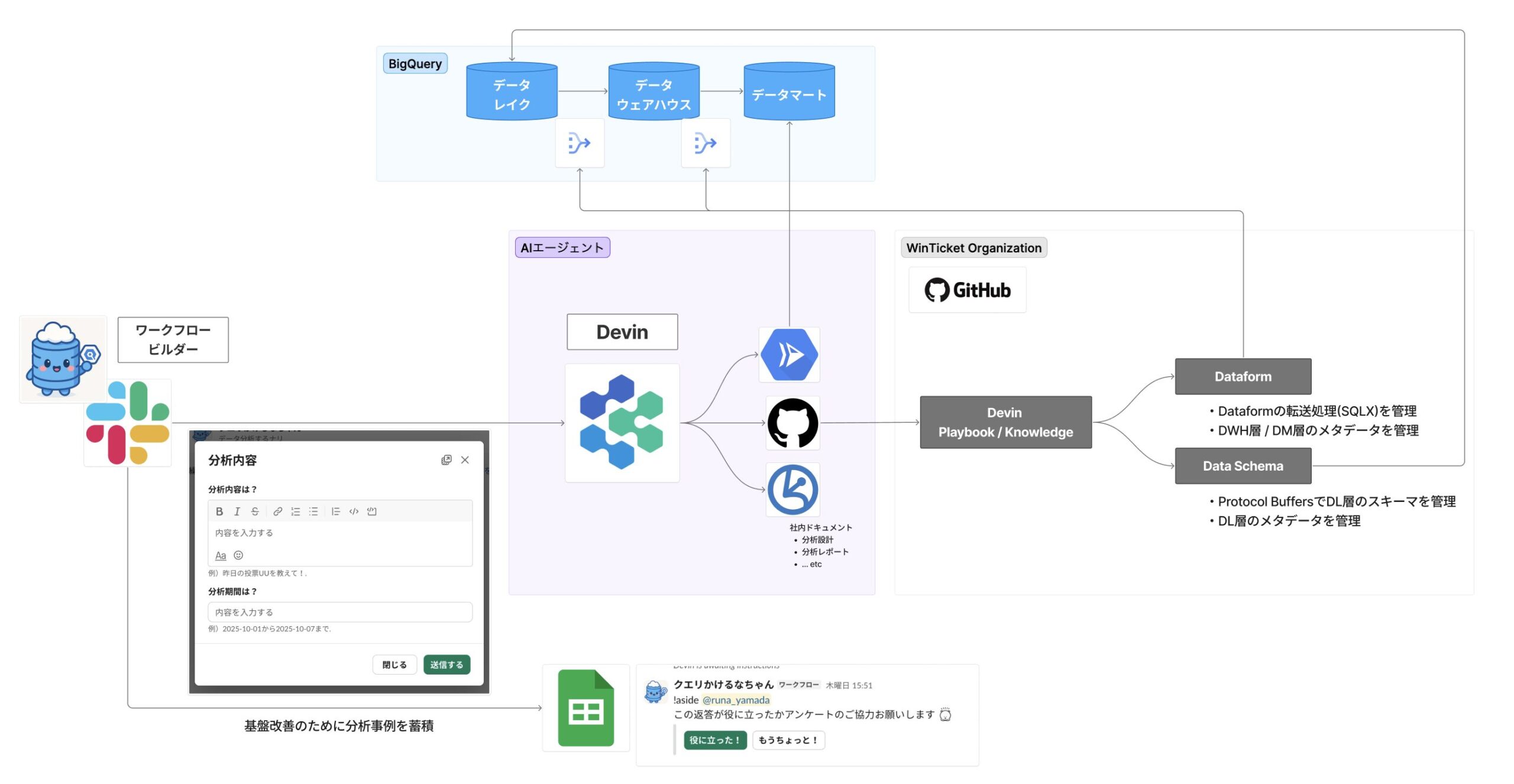
なぜ Devin を選んだのか
データ分析の自動化を実現するため、いくつかのアプローチを検討しました。
検討したアプローチ:
| アプローチ | メリット | デメリット |
|---|---|---|
| フレームワークで自作 (LangChain、ADK など) |
・自由度が高い ・独自要件に対応可能 |
・開発・運用コストが大きい |
| エディタ支援 (Cursor など) |
・個人の作業効率化に有効 ・導入が簡単 |
・ビジネスメンバーが使いづらい ・分析事例が組織に蓄積されにくい |
| Devin | ・開発・運用コストが少ない ・Slack から気軽に依頼できる ・分析事例が組織に蓄積される |
・カスタマイズの自由度が低い ・サービス利用料がかかる |
WINTICKET のデータマネジメントチームは少人数で運用しているため、開発・運用コストを抑えつつ、ビジネスメンバーが気軽に依頼でき、分析事例が組織に蓄積されるという点を重視し、Devin を選択しました。また、既に他のチームで Devin の導入が進んでおり、WINTICKET内にナレッジが蓄積されていたことも大きな決め手になりました。先行チームの知見を活用することで、データチームでも導入をスムーズに進められると判断しました。
Playbook と Knowledge による分析ワークフローの定義
Devin では、Playbook と Knowledge を組み合わせて使います。
- Playbook: 分析の手順や実行すべきタスクを定義(「何をすべきか」)
- Knowledge: ドメイン知識やベストプラクティスなどの参照情報を管理(「知っておくべきこと」)
GitHub リポジトリでの管理
Playbook と Knowledge は、WINTICKET 全体で GitHub リポジトリにて一元管理しています:
devin-repository/
├── playbook/
│ └── data_analysis.md # データ分析の手順を定義
├── knowledge/
│ ├── data_datasets.md # データセットの説明
│ ├── data_domain_knowledge.md # ドメイン知識(払戻ロジック等)
│ └── data_sql_best_practices.md # SQL ベストプラクティス
...etc
データ分析用の Playbook(data_analysis.md) には、以下を定義しています:
- Devin の役割と責務
- 分析の回答フォーマット
- 運用ルール(ヒアリング、実行前確認、監査性の確保など)
- 参照すべき Knowledge ファイルの指定
Knowledge ファイル には、以下の参照情報を管理しています:
- data_datasets.md: 推奨テーブル、データ階層構造
- data_domain_knowledge.md: 競輪・オートレース特有のビジネスロジック
- data_sql_best_practices.md: SQL のコーディング規約、パフォーマンス最適化のノウハウ
Playbook が「何をすべきか」を指示し、Knowledge が「どのように実現するか」の参照情報を提供することで、Devin は適切に分析できます。
Devin は Knowledge で指定された情報に加え、GitHub 経由で Dataform リポジトリ(前述の business-domain/ や各テーブルの定義)も参照します。Knowledge が「どのテーブルを優先すべきか」といった分析の方針を示し、Dataform リポジトリが「各テーブルの詳細な仕様」を提供することで、両者が補完し合っています。
Slack Workflow と Macro による依頼の構造化
WINTICKET では、Slack の Workflow Builder を使って分析依頼を受け付けています。ユーザーがフォームに「分析内容」と「分析期間」を入力すると、Devin Macro がその情報を適切な Playbook パスとともに Devin に送信します。
この例では「過去に、どの選手がだれとラインを何回組んだのか知りたい。そのようなデータはありますか?ない場合、それを推測する集計方法は何かありますか?」という依頼が来ています。
フォームで入力項目を決めることで、分析内容や期間といった必要な情報が漏れなく Devin に渡り、精度の高い分析が可能になります。
Devin による分析の流れ
依頼を受け取った Devin は、以下のように自律的に分析します:
- Playbookの参照: Macro で指定された Playbook から、分析に必要な情報を取得
- 関連テーブルを検索: GitHub の Dataform リポジトリ や Protocol Buffers のスキーマ定義を参照し、選手情報、レース結果、ライン情報などのテーブルを特定
- SQL を生成・実行: 上記フローで得た情報を基に SQL を自動生成し、BigQuery で実行。エラーがあれば修正して再実行
- 結果を Slack に返信: 見やすい形式で整形し、分析結果を報告
- 分析事例を記録: 今回の分析パターンを記録し、次回の精度向上に活用
実際に、先ほどの「選手間のライン組み合わせ分析」の依頼に対して、Devin は以下のような分析結果を返してきました:

Devin は、データの存在を確認した上で、「最も頻繁にラインを組んだ選手ペア TOP 10」というわかりやすい形で結果をまとめています。データがあることの説明と、具体的な選手名・期別・出走日までを含めた詳細な分析結果を返しています。
また、この分析自動化の仕組みを 2025 年 9 月下旬に導入して以降、10 月だけで 100 件近い分析依頼が処理されており、導入直後から活発に活用されています。
Knowledge の継続的な更新
分析完了後、Slack の同じスレッド内で !data_update_knowledge マクロを実行すると、Devin は以下を自動で行います:
- 分析事例の記録: 使用した SQL、実行時間、スキャン量、使用テーブルなどを
data_devin_analysis_cases.mdに記録 - 知見の抽出と追記: 分析から得られた新しいドメイン知識やベストプラクティスを適切な Knowledge ファイルに追記
- PR の自動作成: 更新内容をまとめた PR を作成し、データサイエンティストチームにレビューを依頼
この仕組みにより、分析のたびに Knowledge が蓄積され、Devin の精度が継続的に向上していきます。
目指す成長サイクル
ここまで説明してきた Protocol Buffers、Dataform、Dataplex、そして Devin を組み合わせることで、最終的には以下のサイクルで継続的に成長する仕組みを実現したいと考えています:
- WINTICKETメンバーが自然言語で質問: 誰でも気軽にデータ分析を依頼
- AI がデータ分析: メタデータを参照し、品質保証されたデータで分析
- 知見が蓄積される: 分析パターンやベストプラクティスを Knowledge に追加
- 分析を可視化: よく使われる分析を特定
- データ分析基盤が進化: 需要の高い分析を自動データマート化
このサイクルを回すことで、データ分析基盤と AI エージェントが共に成長していく世界を目指しています。
まとめ
本記事では、WINTICKET における AI-Ready なデータ分析基盤の構築と、AI エージェントによる分析自動化の取り組みを紹介しました。
Devin を実際に運用してみて実感したのは、これまでデータ分析基盤で地道に積み重ねてきた取り組みが、AI エージェントの精度向上に直結しているということです。Protocol Buffers でスキーマを定義し、Dataform で全てのテーブルとカラムに説明を付けてきたこと。Data Mart 層で集計定義を統一してきたこと。これらの積み重ねがあったからこそ、Devin は適切なテーブルを選択し、ビジネスロジックを理解し、SQL を生成できるようになってきています。まだ改善の余地はありますが、データ分析基盤の整備が AI の精度に貢献していることを感じています。
データ分析基盤の整備は目立たない作業が多く、効果も見えづらいものです。しかし、AI エージェントを通じて、これまでの地道な取り組みが確実に効果を発揮していることがわかりました。
WINTICKET のデータ分析基盤構築はまだ道半ばですが、「AI がデータを活用しやすい環境」という明確なゴールに向けて、一歩ずつ進んでいます。同じような課題を抱えているチームの参考になれば嬉しいです。
WINTICKET では、データエンジニアを積極採用中です。データ分析基盤の構築や AI 活用に興味がある方は、ぜひカジュアル面談でお話ししましょう。