
Hi, I’m Nam! I’m currently working as a backend engineer intern at Hanoi DevCenter , specifically on the ABEMA team.
Our team maintains a large monorepo codebase shared across multiple microservices. One of my tasks during this internship was to help define a common structure for how we organize microservices in this big codebase. The goal was to make the code more consistent and easier to maintain. We also wanted to make it simpler for new developers to get started.
As an intern, contributing to this task was a learning opportunity. The key result was to capture foundational concepts around project structure, layering, and design philosophy without over-engineering things. We decided to base structure on Clean Architecture concepts – but we used them in a simple and practical way, while still applying useful ideas from Architecture. With guidance from my mentor, Nghia -san and Long -san, I help define service architecture standards and prototype them in an internal codebook.
We focused on organizing services into well-defined layers such as domain, use cases, interfaces, and infrastructure. For example, the repository layer, which acts as a boundary between your business logic and data sources. In Go, this layer often uses interfaces that abstract away the details of data access, allowing your core logic to remain independent of implementation specifics like databases or APIs.
In this blog post, I’ll share my experience of using Clean Architecture principles (applied practically, not strictly) – specifically focusing on how those philosophies help keep Go services clean and maintainable. I’ll also introduce go-arch-lint, a tool that helps enforce dependency rules and layer boundaries automatically. Whether you’re building a new service or refactoring a legacy one, understanding and enforcing good architecture can lead to faster development cycles, easier code reviews, more systems, and a more consistent experience for both current and future engineers.
1. Why Clean Architecture?
Before diving in, I’d like to briefly introduce what Clean Architecture is and why it matters.
Clean Architecture, introduced by Robert C. Martin (commonly known as Uncle Bob), is a design philosophy centered around the principle of separation of concerns. It organizes software into distinct, layered components to keep business logic isolated from concerns like frameworks, UIs, or databases. This separation makes code easier to understand, test, maintain, and scale over time.
Here are some core principles of Clean Architecture and why they matter in Go:
- Framework Independence: Your core logic shouldn’t depend on framework-specific code (eg, Gin, Echo, gRPC). Frameworks are implementation details, not architectural centerpieces.
- Testability: With logic isolated in usecase and entities, you can write unit tests without needing to spin up a database or a server.
- Database Independence: Swapping MySQL for MongoDB? No problem. Business rules remain unchanged because they don’t depend on database implementations directly.
- UI Independence: The UI layer (CLI, HTTP API, gRPC) can evolve freely without affecting your application’s core logic.
- External Tool Independence: Business rules remain unaware of external dependencies or tools (such as third-party libraries).

(source: Uncle Bob’s blog – The Clean Architecture )
Layers of Clean Architecture:
- Entities (Innermost): Contain the domain business rules, independent of any specific application. These are the core data structures and methods representing the fundamental concepts of the system.
- Use Cases : Application-specific logic lives here . They define how entities interact to achieve specific application functionalities and define how the app behaves for given inputs.
- Interface Adapters : This is where you convert external representations (eg, request JSON, database rows) to structures your application understands, and vice versa. It includes handlers, controllers, and repository interfaces.
- Frameworks & Drivers (Outermost): Consists of frameworks, databases, UI, and other external tools. These are the most unstable parts of the system and should be isolated from the core logic.
The Dependency Rule: A key rule in Clean Architecture is that dependencies must point inward. Inner layers (eg, use case and entity layers) must never know about or depend on outer layers (eg, frameworks or databases). For example, usecase (inner layer) can define a repository interface (outer layer) without knowing how it’s implemented. The actual implementation – for example, PostgreSQL adapter – lives in the outermost layer and fulfills the interface. This inversion of control keeps your core decoupled from external systems.
Thanks to Go’s simplicity interface system, implementing this structure becomes very natural. In the next part of this blog, we’ll look at how this architecture maps (not strict) to a typical Go project layout and how tools like go-arch-lint can help enforce these architectural guidelines across projects.
2. How to apply Clean Architecture in Go
Applying Clean Architecture in a Go project isn’t just about principles – it’s also about folder structure, naming conventions, and clear dependency rules that keep your application stable, testable, and easy to scale. One of the best practices is organizing your codebase based on responsibility and flow, rather than technical layers like “controllers” or “services.”
Here’s an example file structure of a well-organized Go project that follows Clean Architecture conventions:
root
├── cmd
│ ├── cli/
│ ├── main/
│ ├── server/
│ └── worker/
└── internal
├── entity/
├── handler
│ ├── adminapihandler/
│ └── userapihandler/
├── repository
│ ├── db
│ │ ├── postgresdb/
│ │ └── mongodb/
│ └── filestorage/
└── usecase
├── adminapi/
└── userapi/
cmd – Application Entry Points
The cmd/ directory contains the executable entry points for your application – such as a server, a background job runner, or CLI tools. Each subfolder corresponds to one executable and is responsible for bootstrapping that specific entry point.
Key responsibilities include:
- Dependency Injection (DI): Load config, instantiate implementation structures (eg, repositories, logging, DB connections), and wire them to the corresponding usecases.
- Lifecycle Management: Handle app start/stop events, HTTP/gRPC server start, worker processing loops, and graceful shutdown mechanisms.
According to Clean Architecture principles, this layer lives at the outermost ring – responsible for orchestration only, without containing any domain or business logic. This layer acts as the glue that ties the application together and prepares it for runtime execution.
Internal/entity – Core Business Models
Entities are the heart of your application. The entity package defines the domain objects representing real-world concepts (like User, Product, or Order) and embeds business rules or behaviors within them.
Key responsibilities include:
- Define domain entities: Each entity represents a core concept in your business and contains fields and methods that describe its state and behavior.
- Business Rule Encapsulation: eg, Order.CalculateTotal() or User.IsActive().
- State Validation: Construct only valid entities using constructor functions like NewUser(…) to guard against invalid creation.
type User struct {
Name string
Age int
Email string
}
func (u *User) IsAdult() bool {
return u.Age >= 18
}Tip: No JSON, DB tags, or references to external systems like GRPC models. Entities live in the innermost circle of Clean Architecture. They should have absolutely no dependencies on infrastructure, delivery mechanisms, or frameworks.
internal/usecase – Application Logic Layer
Usecases define the behaviors your system can perform from a user’s perspective – such as “RegisterUser” or “CheckoutCart.” Each usecase should coordinate domain logic, validate permissions, and persist operations through repository interfaces.
Key responsibilities include:
- Business Coordination: Combine multiple entities and repositories to execute business rules.
- Authorization: Check user roles or ownership.
- Data Mapping (DTOs): Transform inputs from handlers into meaningful domain objects, and vice versa for outputs.
Usecases depend only on entity and repository interfaces they define themselves. They never touch infrastructure logic. This keeps code clean and testable.
type userDBRepo interface {
GetUser(ctx context.Context, id string) (*entity.User, error)
CreateUser(ctx context.Context, user entity.User) (*entity.User, error)
}
type userUsecase struct {
userRepo userRepo
flagEvaluator featureflag.Evaluator
logger log.Logger
}
func NewUserUsecase(ur userRepo, fe featureflag.Evaluator, logger log.Logger) *userUsecase {
return &userUsecase{
userRepo: ur,
flagEvaluator: fe,
logger: logger.NewChildWithName("usecase"),
}
}
func (u *userUsecase) GetUser(ctx context.Context, id string) (*entity.User, error) {
...
}
Tip: Usecase input/output types (DTOs) should be defined inside usecase package, not in the handler. It will allow usecase define most convenience I/O types without concern about upper layer. It also prevents the usecase layer from depending on the handler layer.
internal/repository – Infrastructure and Persistence
The repository layer contains the logic for external systems like databases or external APIs. This layer lives at the outermost ring in Clean Architecture. It fulfills the interfaces defined by the usecase layer, encapsulating the actual implementation details of data fetching, storage, caching, or call external services etc.
Structural breakdown:
- postgresdb, mongodb – Technology-specific implementations.
- Other external services call
Key responsibilities include:
- Persistent Storage: Read/write data from PostgreSQL, Mongo, Redis, etc.
- Adaptation: Convert raw DB results or raw external services response into domain entities.
- Isolation: Infrastructure logic stays in this layer and never leaks into usecases or entities.
Tip: Keep implementation details isolated. Repositories should not expose raw SQL or raw api response in interfaces or contain domain logic.
internal/handler – Interface & Delivery Layer
Handlers are the system’s gateway – HTTP, gRPC, WebSocket, or CLI. These components are responsible for interpreting incoming requests, delegating them to the correct usecase, and returning appropriate responses.
Responsibilities include:
- Parsing & Validation: Route requests, parse payloads, and validate essential inputs.
- Usecase Calling: Transform external formats (JSON, gRPC) to internal DTOs and call the right usecase method.
- Response Formatting: Marshal usecase responses back to protocol-specific formats.
- Error Mapping: Convert system errors into protocol-compliant responses like HTTP 400 or gRPC error codes.
Each handler sub-package corresponds to an API segment, such as user-facing or admin endpoints. They are doing just translation – not logic.
Tip: Never bypass usecase logic by calling repositories directly from handlers. This breaks business workflows and tightly couples infrastructure to the domain.
In the next section, we’ll dive into how we’ve used go-arch-lint to validate this structure automatically – especially within a monorepo – and how it protects your team from architectural drift.
3. Why go-arch-lint?
Once we adopt Clean Architecture, the next challenge is enforcement – especially in larger teams or repositories with multiple services. Maintaining consistent structure becomes difficult without tooling support.
To solve this, we need an architectural linter: a tool that can monitor, enforce, and maintain the desired architectural rules across the entire codebase. The ideal tool should meet the following requirements:
- Enforce Architectural Boundaries : Prevent illegal dependencies and enforce structural policies to maintain separation between layers.
- Code Style Conformance : For monorepo, ensure all services follow a consistent folder structure and naming convention.
- Maintainability and Scalability : Avoid unnecessary complexity and allow teams to easily adopt or modify rules across multiple services – especially in monorepos – without needing extra configurations for every new service added.
3.1. What is go-arch-lint
This is how go-arch-lint introduces itself:
Golang architecture linter (checker) tool. Will check all project import path and compare with arch rules defined in yml file. Useful for hexagonal / onion / ddd / mvc and other architectural patterns. Tool can by used in your CI
go-arch-lint is a lightweight static analysis tool for Go projects that enforces architectural boundaries based on user-defined rules in a YAML config file. It’s designed to support various software design patterns, including Clean Architecture, Hexagonal Architecture, and Domain-Driven Design (DDD).
By integrating go-arch-lint with CI workflows, you can automatically detect violations where a certain layer (eg handlers) accidentally imports or depends on an internal repository package, or when a domain entity accesses infrastructure logic – thus catching design issues early and consistently.
3.2. Enforce Architectural Boundaries
At its core, the main advantage of go-arch-lint is its ability to enforce architecture boundaries by controlling package dependencies.
You can declare folder-level “components” such as handler, service, repository, and model, and define which components are allowed to depend on which. Components not listed under allowed dependencies are blocked, creating a strict whitelist mechanism.
You can also mark shared folders (like models or entities) as commonComponents – meaning they’re freely accessible from any layer.
Here’s a simple example configuration:
version: 3
workdir: internal
components:
handler: { in: handlers/* } # wildcard one level
service: { in: services/** } # wildcard many levels
repository: { in: domain/*/repository } # wildcard DDD repositories
model: { in: models } # match exactly one package
commonComponents:
- models
deps:
handler:
mayDependOn:
- service
service:
mayDependOn:
- repositoryThis configuration ensures that each layer depends only on its allowed inner layers and avoids outward or cross-layer dependencies. For example, handlers can rely on services, but not directly on repositories.
Code Style Compliance
Another subtle but powerful benefit of go-arch-lint is that it indirectly enforces consistent project structure and naming conventions across services – especially in monorepos .
In the YAML config, every Go file must belong to a declared component. By default, if a package isn’t matched by one of the component definitions, it results in an error. With this rule enabled, teams are indirectly guided to:
- Use the same folder names and organization across services (eg, all services should have handler/, usecase/, repository/ folders).
- Avoid scattering business logic into unapproved or incorrectly named directories.
This leads to better readability, easier onboarding, and a more maintainable standard across the entire monorepos .
You can relax this strictness with:
allow:
ignoreNotFoundComponents: true
But be mindful: disabling this check allows services to have arbitrary folder structures, reducing consistency across the repository.
3.4. Maintainability and Scalability
In large teams or monorepo setups with many services, architectural drift can easily occur: developers introduce new dependencies, place logic in the wrong layers, or create inconsistent project structures – all unintentionally.
go-arch-lint offers a scalable and low-friction way to protect architecture across services. Here’s why:
- No extra setup needed when adding new services : As long as a new service follows the existing folder structure, no additional configuration is required.
- Promotes shared architecture standards : Teams don’t need to reinvent the wheel for every new service – they simply follow existing declared layers.
- Easy to contribute: Because all rules live in a shared YAML file (go-arch-lint.yml), any team member can propose or contribute architectural changes,
- Lightweight and CI-friendly : go-arch-lint runs quickly and can be integrated into CI pipelines using tools like Reviewdog to leave inline feedback on pull requests.
Up next, we’ll walk through how to apply go-arch-lint in a monorepo setup, and how we combined it with yq and GitHub Actions to dynamically validate only modified services.
4. Real-world sample: go-arch-lint for clean architecture
After understanding the principles of Clean Architecture and why we enforce them with tools like go-arch-lint, the next question is: how do we put that into practice in a real-world Go project?
Let’s walk through how we use go-arch-lint in a monorepo setup to maintain architecture consistency, enforce strict layering, and enable teams to move fast without breaking structure.
4.1 Define Dependency Rules
To align with Clean Architecture, the first step in configuring go-arch-lint is to define dependency boundaries between components of your project. This is done using a YAML configuration file. At the top of the file, we specify the working directory from which to resolve component paths:
workdir: application-root-folderWe also strengthen control over external dependencies using:
allow:
depOnAnyVendor: false
This disables the use of random third-party packages unless they’re explicitly allowed. Under the vendors section, we introduce a curated list of permitted external packages (eg, go-chi, gjson, cloud.google.com/go), which helps improve security and consistency across services.
Next, we define components to align with repository layers:
components:
cmd: { in: cmd/** }
handler: { in: internal/handler/** }
usecase: { in: internal/usecase/** }
repository: { in: internal/repository/** }
entity: { in: internal/entity/** }
protogo: { in: protogo/** } # Go code generated for protocol buffer
pkg: { in: /pkg/** } # Common packages for this service
We declare shared components as commonComponents to make them accessible from any other layer (like any layer can depend on entity):
commonComponents:
- entity
- protogo
- pkg
The core of the config is in the deps section, defining which components can depend on which:
deps:
cmd:
anyProjectDeps: true # set true to allow depends on any packages
handler:
mayDependOn: # list of components
- usecase
usecase:
mayDependOn:
- repository
repository:
mayDependOn:
- repository
Lastly, we avoid false positives by excluding irrelevant files such as tests:
excludeFiles:
- "^.*_test\\.go$"
With this configuration, go-arch-lint becomes an automated architectural lint: preventing tight coupling between layers, banning unapproved packages, and maintaining a consistent and scalable project structure.
4.2. Build Github Actions: CI Automation in a Monorepo Setup
While go-arch-lint works great for single Go projects, it doesn’t directly support monorepos – where multiple services live under a shared repository. Since go-arch-lint expects a single workdir per config file, we needed a workaround to lint only services that have changed.
To solve this, we wrote a shell script that does the following:
- Determines the current Git branch.
- Compares against origin/main to find which service folders have changed within ./goservice/. (folder contains all services in monorepo)
- For each changed service:
- Updates the workdir field in a temporary copy of the config using yq.
- Runs go-arch-lint on that modified config.
- Uses reviewdog to send inline results back to GitHub via PR comments.
Here’s a snippet of the core logic:
trap 'rm -f "$temp_yaml"' EXIT # always delete the temp file on script exit
CURRENT_BRANCH=$(git rev-parse --abbrev-ref HEAD)
if [[ "${CURRENT_BRANCH}" != "main" ]]; then
for dir in $(find ./goservice -maxdepth 1 -type d | sed '1,1d' | sed 's@./@@'); do
if [[ -n "$(git diff --name-only origin/main "${dir}")" ]]; then
echo "go-arch-lint run ${dir}"
export ARCH_LINT_WORKDIR="${dir}"
# change the working directory to the service
"$BIN"/yq '.workdir=strenv(ARCH_LINT_WORKDIR)' ./goservice/.go-arch-lint.yml > "$temp_yaml"
env "$GO_ENV" "$BIN"/go-arch-lint check --output-color=false --arch-file="$temp_yaml" | reviewdog -efm="%m in %f:%l" -name=go-arch-lint -reporter=github-pr-review -fail-on-error=true -filter-mode=nofilter || exit 1
fi
done
fi
Makefile Setup
The Makefile ensures consistent dependency versions for lint tools. It installs and symlinks the binaries into a shared bin path, which allows smooth integration into CI and local environments.
GO_ARCH_LINT_VERSION := v1.11.9
$(BIN)/go-arch-lint-$(GO_ARCH_LINT_VERSION):
unlink $(BIN)/go-arch-lint || true
$(GO_ENV) ${GO} install github.com/fe3dback/go-arch-lint@$(GO_ARCH_LINT_VERSION)
mv $(BIN)/go-arch-lint $(BIN)/go-arch-lint-$(GO_ARCH_LINT_VERSION)
ln -s $(BIN)/go-arch-lint-$(GO_ARCH_LINT_VERSION) $(BIN)/go-arch-lint
YQ_VERSION := v4.40.5
$(BIN)/yq-$(YQ_VERSION):
unlink $(BIN)/yq-$(YQ_VERSION) || true
$(GO_ENV) ${GO} install github.com/mikefarah/yq/v4@$(YQ_VERSION)
mv $(BIN)/yq $(BIN)/yq-$(YQ_VERSION)
ln -s $(BIN)/yq-$(YQ_VERSION) $(BIN)/yq
.PHONY: lint-architecture-ci
lint-architecture-ci: ## go-arch-lint
lint-architecture-ci: $(BIN)/go-arch-lint-$(GO_ARCH_LINT_VERSION)
lint-architecture-ci: $(BIN)/yq-$(YQ_VERSION)
lint-architecture-ci:
bash ./scripts/go-arch-lint.sh "$(BIN)" "$(GO_ENV)"
GitHub Actions Integration
To bring it all together, we use GitHub Actions to run linting in a CI pipeline. Due to issues with the official go-arch-lint Docker image, we rely on a golang base image for now.
Below is a portion of the workflow:
lint-architecture:
runs-on: ubuntu-latest
timeout-minutes: 15
permissions:
pull-requests: write
checks: write
id-token: write
contents: read
container:
image: index.docker.io/golang@sha256:89a04cc2...
steps:
- name: Install deps
run: apt-get update && apt-get install --no-install-recommends -y git jq bash wget
- name: Install reviewdog
run: |
cd "$(mktemp -d)"
wget -q "https://github.com/reviewdog/reviewdog/releases/download/v0.15.0/reviewdog_0.15.0_Linux_x86_64.tar.gz"
tar -xvf reviewdog_0.15.0_Linux_x86_64.tar.gz
cp reviewdog /usr/local/bin/reviewdog
- name: Run architecture linter
run: make lint-architecture-ci
env:
REVIEWDOG_GITHUB_API_TOKEN: ${{ github.token }}
Final result: Reviewdog will leave a PR comment whenever go-arch-lint detects a dependency violation.
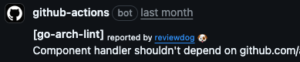
In the final section, we’ll wrap up with takeaways, lessons learned, and tips for teams adopting Clean Architecture and go-arch-lint in production.
5. Final Thoughts
Early in my internship, I thought clean code was mostly about naming things well and keeping functions short. But under the guidance of my mentor, I came to realize that architecture is the true foundation of both code quality and team scalability. A clean architecture isn’t just nice to have – it’s critical for long-term maintainability, testability, and happiness developer.
Here are some key takeaways from our journey:
Clean Architecture works especially well in Go: Thanks to Go’s simplicity and its strong support for interfaces, following clean architecture principles feels natural. Go can define clear boundaries and let interfaces abstract away implementation details.
Enforcement is essential: Designing the architecture is only half the challenge. Without enforcement, teams can unintentionally break boundaries over time – especially in large codebases with many contributors. go-arch-lint acts as a static safety net that catches these issues early, before they spiral into architectural drift.
A good folder structure makes a big difference: By structuring codebase on responsibility (eg, handler, usecase, repository, entity), it will improve clarity, enforce separation of concerns, and help new developers onboard and understand the codebase more easily.
Automate everything: Architecture rules are a team agreement – and CI is where that agreement should be validated. Rules violations are caught early at the pull request stage—improving code quality, accelerating development, and minimizing human error