
はじめに
こんにちは!初めまして!
東京工科大学 学部2年の 広瀬エイトル(@Heitor_Hirose)です。
この夏、大学の休みを利用して2025年8月から2ヶ月間、株式会社サイバーエージェントの就業型インターンシップ に参加しました。配属されたAI事業本部では、LLMを活用したプロダクト「AI POS」の開発に携わり、LLMの挙動を監視・分析するためのObservability(可観測性)基盤をゼロから設計・構築する というミッションを担当しました。
実際に社内でインターン終了時に発表した資料は以下になります。
この記事では、2ヶ月間に行った技術選定からアーキテクチャ設計、構築までの過程を紹介します。具体的には、以下の3つの技術的な意思決定について深掘りしていきます。
LLM Observabilityツールの比較検討
Langfuse, Traceloop等を比較し、最終的に「Langfuse」を選んだ技術的理由
Langfuseのクラウドアーキテクチャの設計・構築
GCP (GKE) 上でLangfuseをセルフホスティングするための、インフラ設計について
ログ収集アーキテクチャの設計・構築
OpenTelemetry Collectorのゲートウェイ方式とサイドカー方式の比較と最終構成について
今後、ミッション型インターンシップを考えている方や、LLM監視の基盤構築に興味がある方の参考になれば幸いです!
プロダクト概要
私がインターン生として参加したプロダクトは 「AI POS(エーアイポス)」です。小売業界の現場が抱える膨大かつ複雑な POS(販売時点情報)データを、生成AI技術を用いて “誰もが使える形” に変える分析ツールです。
売上や前年対比、店舗別・商品別の傾向などを、人手による集計や専門ツールなしで、手軽にレポートとして受け取り、データに基づくビジネスの意思決定を素早く行えるようにします!
https://www.cyberagent.co.jp/news/detail/id=30939
LLM Observabilityツールについて
LLM Observabilityとは
LLM Observabilityとは、大規模言語モデル(LLM)の利用状況や挙動をリアルタイムに記録・監視・分析し、その品質や安全性を継続的に改善するための仕組みを指します。従来のアプリケーション監視がログ・メトリクス・トレースに着目するのに対し、LLMではプロンプトや応答、コスト、生成の一貫性や事実性といった新しい観測対象が加わります。これにより「なぜこの出力が得られたのか」を後から追跡し、改善や再現性の確保につなげることが可能となります。
参考
なぜLLM Observabilityは重要なのか
現在、LLM(大規模言語モデル)はエンジニアだけでなく、一般のユーザーにも広く利用され、私たちの仕事や生活に急速に浸透しています。しかし、その一方でLLMをビジネスで本格的に使うには、技術的な課題以上に、事業としての管理が求められています。
特に顧客にLLMエージェントを提供する上では、どのようにして**「回答の正確性、有用性、安全性」を維持し、規模拡大に応じて増加する「運用コスト」をどう把握するか。そして、個人情報や機密情報を扱う際の「コンプライアンス」**をどう遵守するか。これらの課題は常に重要になってきます。
そして、こららの課題に対応するためには、LLMアプリケーションの動作をリアルタイムで監視・分析できる基盤が極めて重要になります。例えば、レイテンシ、使用トークン数といった主要な指標を追跡することで、障害発生時にも問題の根本原因を迅速に特定し、回答の精度低下といった事態にも素早く対処することが可能になります。
IBM Think – Why is LLM observability important?
現在のプロダクトの問題点

現在のプロダクトは上記のようなマイクロサービスアーキテクチャを採用しており、以下のような課題が存在しています。
技術的な課題
- 複数のLLMプロバイダを使用しているため、コストや利用ログを集計することができていない
- それぞれのマイクロサービスで、目指すべき性能が担保されているかを継続的に評価できていない
- ログやメトリクスを収集・可視化する基盤が整備されていない
このような状況では、プロダクトの重要な部分となる生成AIを使用したエージェントの改善を行ったり、障害が発生した際の原因特定などが難しくなっていました。
そこで私がこのインターンで取り組むのは、これらの課題に対応できるObservabilityツールの選定と構築です。アプリケーションのログ収集・分析アーキテクチャを設計し、将来的なプロンプト改善やエージェント強化につなげられる基盤を整備することを目指しました。
LLM Observabilityツールの選定過程
技術選定において考えたポイント
- OpenTelemetryベースになっていること
OpenTelemetryを基盤としていることで、既存のアプリケーションに監視基盤を構築した際にも、LLMとアプリケーションを横断的に分析しやすくなる。 - Pythonでの開発体験が高いこと
現在のプロダクトではバックエンドの大部分がPythonで実装されている。そのため、多様なフレームワークに対応し、低コストで計装が可能なツールが望ましい。 - Observabilityツールとして機能アップデートが多いもの
LLM分野は日々進化しているため、頻繁にアップデートが行われ、新しい技術や要件に迅速に対応できる基盤が理想的である。
自分で挙げたものを共有する過程で以下の意見も出ました。
チーム内で挙がった観点
- データ保存先のサーバー所在地
サービスの特性上、顧客に関わる情報をやりとりすることになるため、保存先サーバーの所在地やセキュリティポリシーには十分な考慮が必要になる。 - 長期間ログが保有可能なツール
プロダクトは導入初期段階であり、収集したログの具体的な活用方法はまだ定まっていない。そのため、将来の分析や評価に応用できるよう、収集したログを長期間保持できることが要件となる
各ツールの比較・検討
上記の選定方針に基づき、各ツールの機能、実装体験、コストなどを比較しました。
比較対象ツール
比較する上で特に重要だったのが、現在プロダクトで使用している SmolAgents や LangGraph といった複数のLLMフレームワークへの対応です。調査したツールの多くは SmolAgents に直接対応しておらず、OpenTelemetryを介したデータ送信が必須となりました。
それぞれの比較結果が以下のようになりました。
Langfuse
総合評価 : 有力候補
評価ポイント :
- 高い開発体験の高さ
Python用の公式SDK が提供されており、現在のPythonベースのプロダクトに軽量かつ直感的に導入できる点 - 現状の課題に対して有効的
導入の検討をしているプロンプトのA/Bテストやバージョン管理機能が標準で備わっており、出力改善の実験要件にマッチしている点 - Self-Hostedオプション
OSSでありながら、Self-Hosted版でも機能制限がほとんどなく、クラウド版と遜色ない機能を利用可能になっている点
懸念点
- クラウド版のサーバー所在地
Langfuseのクラウド版が提供するサーバーは欧州または米国リージョンに限定されており、日本国内のリージョンを選択できない。サービスの特性上、顧客に関わる情報を取り扱う可能性がある本プロジェクトにおいて向かない。 - Self-Hostedを構築・運用するのが大変
公式ドキュメントで推奨されている構築方法では、PostgreSQLやRedisといった複数のリソースをKubernetes(k8s)上にセットアップする必要がない。このプロセスは公式提供のHelmチャートを利用することで大幅に効率化できますが、SaaS版とは異なり、k8sクラスタ自体の管理や、デプロイしたアプリケーションの継続的な運用(バージョンアップ、設定変更など)は運用者の責任範囲となる。
Arize Phoenix
総合評価 : 有力候補
評価ポイント :
- 高い開発体験の高さ
Langfuseと同く、Python用の公式SDK が用意されており、現在のプロダクトに軽量かつ直感的に導入できる点 - 現状の課題に対して有効的
導入の検討をしているプロンプトのA/Bテストやバージョン管理機能が標準で備わっており、出力改善の実験要件にマッチしている点 - OSSエコシステムの開発に積極的
Arize Phoenixを開発している Arize AI は LLM Observability向けの OpenTelemetry InstrumentationをOSSとして開発・運用をしています。これらの Instrumentation の一部は他のツールでも利用を推奨しており、LLM Observability業界に貢献しているように感じた。
懸念点
- OSSのSelf-Hosted版の機能制限
OSS版のSelf-Hostedでは多くの機能が制限されており、実質的にEnterpriseプランの契約が前提となるため、Langfuseと比べてコストが増加する。 - クラウド版のサーバー所在地
Arize Phoenixのクラウド版が提供するサーバーは欧州または米国リージョンに限定されており、日本国内のリージョンを選択できません。サービスの特性上、顧客に関わる情報を取り扱う可能性がある本プロジェクトにおいて向かない。
LangSmith
総合評価 : 見送り
評価ポイント :
- LangGraph, LangChainのエコシステムとの親和性が高い
LangChain社製であるため、同社が開発している LangChain や LangGraph との親和性が非常に高く、これらのフレームワークを主軸に使う場合に優良な選択肢となる。 - ダントツで良いUIの見やすさ
個人的な見解ですが、他のツールと比較してダッシュボードのデザインが分かりやすく、LLMの知識が浅いメンバーでも直感的に操作できると感じた。
懸念点
- クラウド版のサーバー所在地
LangSmithのクラウド版が提供するサーバーは欧州または米国リージョンに限定されており、日本国内のリージョンを選択するにはEnterpriseプランを契約して営業担当者にお問い合わせする必要があるかもしれない。 - 他のフレームワークとの相性
本プロジェクトでは複数のフレームワークを利用しているため、LangSmithがネイティブ対応していないものについては、OpenTelemetry形式でデータを送信する必要があり、その分の連携コストが発生する。 - 価格体系とのミスマッチ
ユーザー数だけでなく、トレースの保存期間によって価格が変動する料金体系になっている。長期間のデータ保存を要件とする本プロジェクトとは、価格体系の思想が合致なかった。
Traceloop
総合評価 : 見送り
懸念点・見送りの理由 :
- 価格体系とのミスマッチ
クラウドのFreeプランはデータ保持期間が24時間と非常に短く 、GCP上でSelf-Hosted版を運用するには非常に高価であるため、プロダクトを加味すると採用は現実的ではなかった。
(参考 : Google Marketplace – Traceloop)
採用したツール : Langfuse
LLMアプリケーションに関わるチームメンバー数名と話あった結果、Langfuseを採用することになりました。当初はLangfuseおよびArize Phoenixのクラウド版の利用も検討しましたが、ログデータを国内のサーバーで管理したいという要件から、セルフホストでの運用を選択いたしました。セルフホストを前提とした場合、非エンタープライズ版で利用できる機能がArize PhoenixよりもLangfuseの方が圧倒的に豊富であったため、今回の採用理由となりました。
クラウドアーキテクチャ設計・構築
AI POS Langfuse – アーキテクチャ図(一部省略)
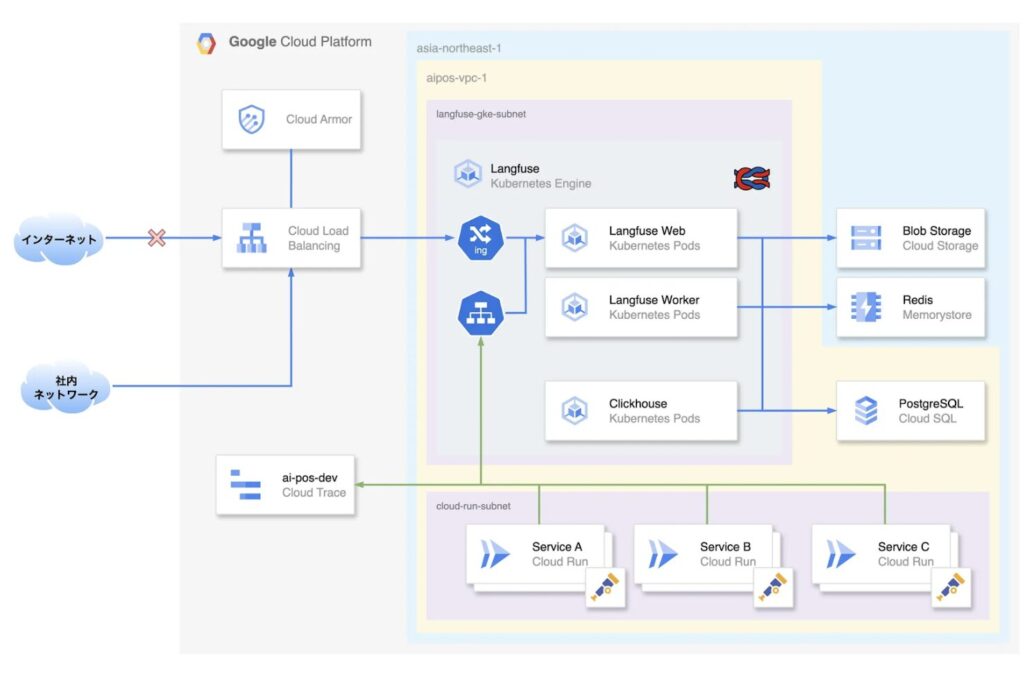
現在のAI POSは、全てのサービスをGoogle Cloud上に構築しています。この既存環境との整合性を考慮し、LLMアプリケーションの観測基盤であるLangfuseもGCP上に導入する方針で進めました。
LangfuseのGCPにおけるデプロイ方法を調査した結果、主な選択肢は Cloud Run と Google Kubernetes Engine (GKE) の2つでした。当初は両者を比較検討しましたが、以下の理由からGKE(Autopilot)の採用を決定しました。
- 常時稼働の必要性
Langfuse は観測データを継続的に収集・処理するため、安定して稼働し続ける基盤が求められます。Cloud Run でも最小インスタンス数を設定することで常時稼働に近い運用は可能ですが、Langfuseのアーキテクチャでは GKE の方がより適していると考えました。
Self-host Langfuse – Architecture
- 公式の推奨と将来性
Langfuseの公式ドキュメントでは、本番環境での運用においてGKE(または同様のKubernetes環境)の利用を推奨しています。将来的なアップデートでCloud Runの制約に抵触し、最新バージョンが動作しなくなるリスクを避けるため、推奨構成を選択しました。
Self-host Langfuse – Production-scale deployments
ログ収集アーキテクチャの設計・構築
現在のAI POSにはOpenTelemetryを使用したログ収集・加工基盤が導入されていなかったため、Langfuseを導入するタイミングで併せて構築することを提案し、構築しました。
当初は各サービスから直接OpenTelemetryの通信をLangfuseに対して送信する形を想定していましたが、せっかくの機会なのでOpenTelemetry CollectorをCloudRunのサイドカーとして設置し、そこからLangfuseおよびCloud Traceにデータを転送できるようにしました。上記のアーキテクチャ図において、緑色の線がOpenTelemetryを用いた通信経路を表しています。
OpenTelemetry Collectorとは
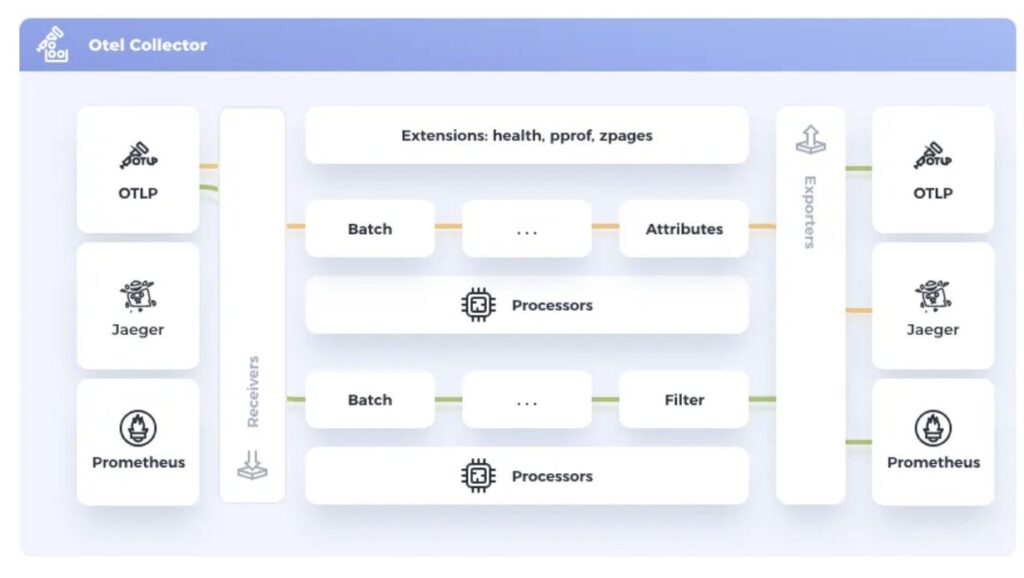
OpenTelemetry Collector(以下、Collector)は、アプリケーションから送られてくるテレメトリーデータを集約・加工し、様々な監視バックエンドへ転送することができる便利なコンポーネントです。それらの処理は、Receiver、Processor、Exporterという3つの主要な要素で構成されています。
Receiver (受信)
Receiverは、テレメトリーデータの入り口となる部分で、OpenTelemetryの標準プロトコルであるOTLP形式はもちろん、PrometheusやJaegerといった多様な形式のデータを受け付けるように設定できます。
Processor (加工)
主な役割は、不要なデータを除外するフィルタリング、個人情報を保護するマスキング、転送効率を上げるバッチ処理、サンプリング機能などを通じて、データを整形・最適化することができます。
Exporter (送信)
Exporterは、加工済みのデータを指定された監視バックエンドへ送信する出口の役割を担います。今回のようにCloud TraceやLangfuseに送信するの他、Datadogなど様々なサービスに対して出力することができます。
OpenTelemetry Collectorの構築方法について
主に、Collectorを活用したログ基盤の構築方式は2種類あります。
エージェント型 : 各サービスコンテナのサイドカーとして、専用のCollectorを構築する方式。

ゲートウェイ型 : ロードバランサーを介し、複数の共有Collectorへログを集約する方式。

それぞれにメリットとデメリットがありますが、今回はエージェント型を採用しました。主な理由は、Cloud Run 環境との親和性が高い点にあります。サイドカーとしてデプロイすることで、Cloud Run のインスタンス数に応じて Collector も自動的にスケールするため、リソース管理が容易になります。また、Collector の処理が増えてサイドカーでの対応が難しくなった場合でも、ゲートウェイ型へ移行しやすいという点がありました。
CloudRunのサイドカー機能を利用したCollector
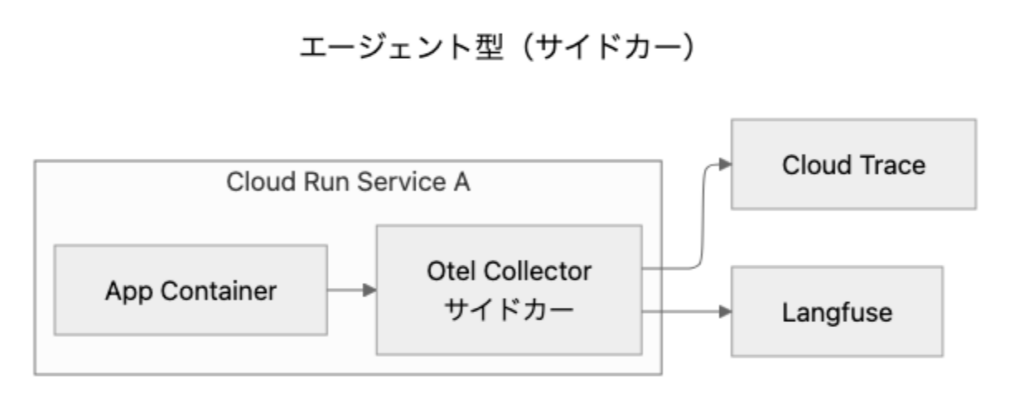
Cloud Runは基本的に1つのサービスにつき1つのコンテナで実行されますが、サイドカー機能を使用することにより、複数のコンテナを同時に実行できるようになります。これにより、Collectorを今まで構築されているサービスに対してマルチコンテナの設定をし、アプリケーションのOpenTelemetryの設定をすることで簡単にエージェント型が導入できるようになっています。
参考1 : https://cloud.google.com/stackdriver/docs/instrumentation/opentelemetry-collector-cloud-run?hl=ja
参考2 : https://cloud.google.com/run/docs/tutorials/custom-metrics-opentelemetry-sidecar?hl=ja
まとめ
今回のLangfuse、OpenTelemetry Collector, Cloud Traceの導入により、サービスごとに異なるLLMやフレームワークが利用され、コストやパフォーマンスなどの全体像が不明瞭だった課題を解決する基盤を構築しました。私のインターン期間で全てのマイクロサービスに導入するには至りませんでしたが、今後のプロダクト改善の礎となる重要な第一歩を築けたと思います。私が作成した様々な基盤が今後のプロダクトの改善に繋がると嬉しいです!
最後に
今回のインターンでは、Terraformを初めて触り、GKEやGCPの設定にもまだ慣れていなかったため、多くの場面で苦戦しました。そのたびに社員の方々に助けていただき、なんとか乗り越えることができました。当初掲げていた目標をすべて達成することはできませんでしたが、参加前と比べて得られた知識や経験は本当に大きなものとなりました。
最初は「わからない」の連続で戸惑うことも多かったのですが、その分学びが多く、振り返ればとても充実した時間でした。また、美味しいご飯をたくさん食べられたことも良い思い出です。二ヶ月間のインターンはあっという間に過ぎ、夏休みを短く、そして楽しくさせました。
技術的な実務だけでなく、社員の方々とのランチを通じて様々なお話を伺えたことや、キャリアに関する情報を得られたことも、とても貴重な機会でした。
一緒にランチに行ってくださった社員の皆さま、不適切なスケジューリングをしてしまった私に根気強くアドバイスをくださった村脇さん、そして助けてくださったAI POSのチームの皆さま、ありがとうございました。