
はじめに
この記事は CyberAgent Developers Advent Calendar 2025 3日目の記事です⛄️
こんにちは。全社データ技術局データインテグレーションチームの與田龍人です。
私たちのチームでは、社内のメッセージデータを、Amazon Kinesis Data Streams から Amazon Data Firehose を経由して AWS S3 Tables に取り込み、Iceberg 形式で蓄積しています。S3 上に配置されたファイル群を一貫したテーブルとして扱える Iceberg の仕組みは、流量の多いメッセージデータを扱ううえで非常に相性が良く、柔軟なスキーマ管理やスナップショットによるデータの安全性など、運用面での利点も大きいと感じています。
こうして蓄積したデータを社内の利用シーンに合わせて整形するためには、変換処理そのものを安定して管理できる仕組みが欠かせません。そのために私たちはデータ変換ツールである dbt を活用し、実行基盤として Snowflake を利用しています。一方でIceberg を dbt から扱う場合は、どのカタログを利用するかによって実現できる機能が変わります。S3 Tablesは基本的にGlue Catalogを利用しますが、dbt から AWS Glue Catalog を介して Iceberg テーブルを作成する構成では、テーブル定義自体は可能であるものの、増分処理に必要な incremental models が現時点ではサポートされていないという制約があります。
Table materialization in Snowflake Starting in dbt Core v1.11, dbt-snowflake supports basic table materialization on Iceberg tables registered in a Glue catalog through a catalog-linked database. Note that incremental materializations are not yet supported.
※引用 dbt公式ドキュメント: Snowflake × Iceberg統合設定より
そこで、この制約を踏まえながら、既存の S3 Tables を Glue Catalog 経由で参照しつつ、増分処理が必要な Iceberg テーブルの作成には Snowflake Horizon Catalog を用いるというマルチカタログ構成を実装したので、その概要を紹介します。
Icebergテーブルとは
ここで、Iceberg がどのようにデータを管理しているのかを軽く整理しておきます。Iceberg は S3 のようなオブジェクトストレージに置かれたファイル群を、一つのテーブルとして扱えるように設計されたオープンなテーブルフォーマットで、トランザクションの整合性を保ちながら大規模データを運用できる点が特徴です。スキーマの変更にも柔軟に対応でき、過去のスナップショットへ遡るタイムトラベルも備わっているため、運用しながらデータ構造を変換していくようなケースに向いています。
Iceberg がテーブルをどのように表現しているのかは、次の図を見るとイメージしやすいと思います。Iceberg Catalog にテーブルの最新状態へのポインタが記録され、その先にはメタデータファイルがあり、テーブルのスキーマやパーティション情報、どのスナップショットが有効なのかといった情報がまとまっています。メタデータファイルの下にはマニフェストリストがあり、そこからさらにマニフェストファイルがぶら下がっていて、実際にどのデータファイルがテーブルのどのスナップショットに含まれているのかがここで管理されています。最下層には Parquet のデータファイルが並び、Iceberg はこれらを直接スキャンするのではなく、マニフェストをたどることで必要なファイルだけを効率良く参照できるようになっています。
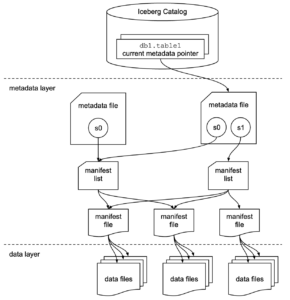
Iceberg のテーブル仕様の詳細は公式ドキュメントをご参照ください
全体の構成と概要
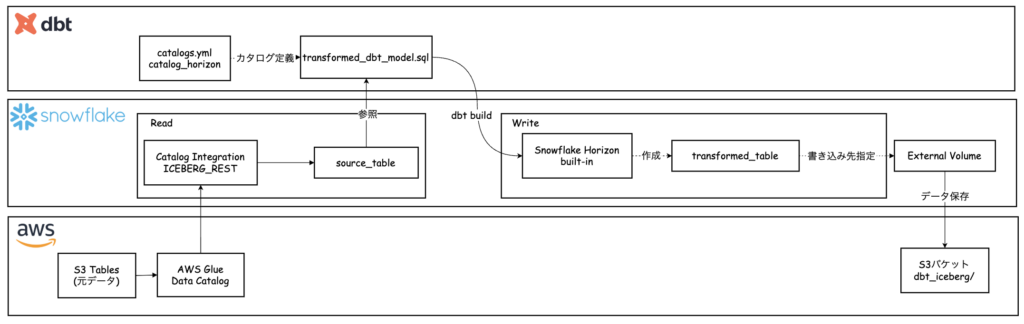
今回は、以下2種類のカタログを組み合わせた構成を採用しました。
-
元データ(AWS Glue管理): Glue の Iceberg Catalog に対して REST API で接続し、S3 上の既存テーブルを参照のみのカタログとして利用します。
-
変換データ(Snowflake Horizon管理): dbtで新規作成するIceberg テーブル用のカタログになります。
この構成により、既存のS3 TablesデータとAWS Glue Catalogを活用しながら、Snowflake 上で dbt による増分処理を用いたデータ変換パイプラインを構築できます。
dbt-snowflake adapterで対応しているiceberg materializationsの詳細についてはdbt公式ドキュメントから確認できます。
ここからは、このマルチカタログ構成をどのように構築していくのか、順を追って紹介していきます。
1: AWSリソースの準備
S3バケット
Icebergデータを保存するS3バケットを用意します。既存のバケット内に専用パスを作成します。
s3://example-iceberg-bucket/dbt_iceberg/IAMロールの作成
ロール名: SnowflakeIcebergRole(例)
Permission Policy(許可ポリシー)
このポリシーには、システム全体で必要な以下の権限が含めています。
- S3 Tablesの読み取り: 元データ(AWS Glue管理のIcebergテーブル)へのアクセス。
-
Glueの読み取り: Glueカタログのメタデータ参照。
-
Lake Formationの権限: データカタログへのアクセス制御。
-
S3への読み書き: dbtで作成するIcebergテーブルのデータ保存。
2: 元データの参照設定(AWS Glue管理)
S3 Tablesに保存されている元データをSnowflakeから参照できるようにします。
Catalog Integrationの作成
CREATE OR REPLACE CATALOG INTEGRATION s3tables_iceberg_rest_integration
CATALOG_SOURCE = ICEBERG_REST
TABLE_FORMAT = ICEBERG
CATALOG_NAMESPACE = 'iceberg_s3_tables_namespace'
REST_CONFIG = (
CATALOG_URI = 'https://glue.us-west-2.amazonaws.com/iceberg'
CATALOG_API_TYPE = AWS_GLUE
WAREHOUSE = '123456789012:s3tablescatalog/example-bucket'
ACCESS_DELEGATION_MODE = vended_credentials
)
REST_AUTHENTICATION = (
TYPE = SIGV4
SIGV4_IAM_ROLE = 'arn:aws:iam::123456789012:role/SnowflakeIcebergRole'
SIGV4_SIGNING_REGION = 'us-west-2'
)
ENABLED = TRUE;
各パラメータについて
-
CATALOG_SOURCE = ICEBERG_REST: Iceberg REST API経由でカタログに接続することを指定。 -
TABLE_FORMAT = ICEBERG: Icebergテーブルフォーマットを使用。 -
CATALOG_NAMESPACE: Glueカタログ内のネームスペース(データベース名に相当)。 -
CATALOG_URI: AWS GlueのIceberg REST APIエンドポイント。 -
CATALOG_API_TYPE = AWS_GLUE: AWS Glue Data Catalogを使用することを明示。 -
WAREHOUSE: S3 Tablesのバケット識別子。形式は{AWSアカウントID}:s3tablescatalog/{バケット名} -
ACCESS_DELEGATION_MODE = vended_credentials: Snowflakeが一時的な認証情報を発行する方式です。 -
SIGV4_IAM_ROLE: SnowflakeがAssumeRoleするIAMロールのARN。 -
SIGV4_SIGNING_REGION: AWS Glueが配置されているリージョン。
外部テーブルの作成(Catalog Linked Database 方式)
AWS Glue の Iceberg テーブルを Snowflake 上で参照するため、Catalog Integration を利用してcatalog-linked databaseを作成し、その配下に Iceberg テーブルを定義します。
CREATE DATABASE S3TABLES_LINKED_DB
LINKED_CATALOG = (
CATALOG = 'S3TABLES_ICEBERG_REST_INTEGRATION'
);
3: 変換データ用のExternal Volume作成(Snowflake Horizon管理)
dbtで作成するIcebergテーブル用に、SnowflakeからS3バケットにアクセスするためのExternal Volume設定を行います。
External VolumeとはIcebergテーブルのデータとメタデータを保存する外部ストレージの場所を定義するSnowflakeオブジェクトです。通常のステージとは異なり、Iceberg専用の管理構造を持ち、カタログメタデータとデータファイルの両方を管理します。
Storage Integrationの作成
まず、Snowflake が AWS S3 に安全にアクセスできるようにする Storage Integration を作成します。
これは、S3 への接続情報や IAM ロールを定義する「接続設定オブジェクト」で、External Volume を作成する上での前提条件となります。
CREATE OR REPLACE STORAGE INTEGRATION example_s3_integration
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::123456789012:role/SnowflakeIcebergRole'
STORAGE_ALLOWED_LOCATIONS = ('s3://example-iceberg-bucket/dbt_iceberg/');
各パラメータについて
-
TYPE = EXTERNAL_STAGE: 外部ステージタイプの統合を作成。 -
STORAGE_PROVIDER = 'S3': AWS S3を使用。 -
STORAGE_AWS_ROLE_ARN: SnowflakeがAssumeRoleするIAMロールのARN。 -
STORAGE_ALLOWED_LOCATIONS: Snowflakeがアクセス可能なS3パスのリスト。
External Volumeの作成
CREATE OR REPLACE EXTERNAL VOLUME example_external_volume
STORAGE_LOCATIONS =
(
(
NAME = 'example-s3-location'
STORAGE_PROVIDER = 'S3'
STORAGE_BASE_URL = 's3://example-iceberg-bucket/dbt_iceberg/'
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::123456789012:role/SnowflakeIcebergRole'
)
);
各パラメータについて
-
NAME: このストレージロケーションの識別名。 -
STORAGE_PROVIDER = 'S3': AWS S3を使用。 -
STORAGE_BASE_URL: Icebergテーブルのデータとメタデータを保存するS3パス。 -
STORAGE_AWS_ROLE_ARN: SnowflakeがAssumeRoleするIAMロールのARN。
4.Trust Policy(信頼ポリシー)の設定
IAM ロール SnowflakeIcebergRole に対して、Snowflake が発行した ExternalId を追加し、
Snowflake 側から安全にロールを引き受け(AssumeRole)できるように設定します。
ExternalId の確認
Catalog Integration と External Volume を作成すると、Snowflake によってそれぞれの ExternalId が自動的に発行されます。
以下のコマンドで値を確認します。
-- Catalog Integration の ExternalId を確認
DESC CATALOG INTEGRATION s3tables_iceberg_rest_integration;
-- External Volume の ExternalId を確認
DESC EXTERNAL VOLUME example_external_volume;
出力の以下の列を参照します。
API_AWS_EXTERNAL_ID(Catalog Integration 側)STORAGE_AWS_EXTERNAL_ID(External Volume 側)
これらの ExternalId は、Snowflake 側が AsssumeRole を行う際に使用する一意識別子で、
第三者による不正利用を防ぐためのセキュリティトークンとして機能します。
Trust Policy の設定
確認した ExternalId を、既存の IAM ロール SnowflakeIcebergRole の信頼ポリシー(Trust Policy)に追加します。
sts:ExternalId に両方の値を配列形式で指定することで、
Catalog Integration と External Volume の両方から同じロールを利用できるようにします。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::111111111111:user/snowflake-user"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": [
"SNOWFLAKE_SFCRole=1_xxxxxxxxxxxxx=",
"SNOWFLAKE_SFCRole=2_yyyyyyyyyyyyy="
]
}
}
}
]
}
設定の確認
信頼ポリシーを更新したら、Snowflake 側で接続が正常に行えるか確認します。
SHOW EXTERNAL VOLUMES;
DESC EXTERNAL VOLUME example_external_volume;
これらのコマンドでエラーが出なければ、Snowflake が IAM ロール SnowflakeIcebergRole を正常に引き受けられている状態です。
5: dbtプロジェクトの設定
Snowflake権限の付与
dbt が使用するSnowflakeロールに必要な権限を付与します。
-- External Volumeの使用権限
GRANT USAGE ON EXTERNAL VOLUME example_external_volume TO ROLE DBT_ROLE;プロジェクト構造
dbt_project/
├── dbt_project.yml
├── catalogs.yml
├── models/
└── transformed_messages.sql
└── sources.ymlcatalogs.yml(プロジェクトルートに作成)
dbtプロジェクトのルートディレクトリ(dbt_project.ymlと同じ階層)にcatalogs.ymlを作成します。
catalogs:
- name: catalog_horizon
active_write_integration: snowflake_write_integration
write_integrations:
- name: snowflake_write_integration
external_volume: example_external_volume
table_format: iceberg
catalog_type: built_in
adapter_properties:
change_tracking: true設定項目について
-
name: dbtモデルで参照する識別子。モデルファイルのcatalog_nameで指定する値。 -
active_write_integration: アクティブなwrite_integrationsを指定します。 -
external_volume: Snowflakeで作成したExternal Volumeの名前。ここで指定することで、このカタログを使用するテーブルが同じExternal Volumeを使用します。 -
table_format:iceberg固定。これによりIcebergフォーマットのテーブルが作成されます。 -
catalog_type: built_in: Snowflake Horizon(組み込みカタログ)を使用することを明示。外部カタログの場合はiceberg_restを指定します。 -
change_tracking: Snowflake StreamsでChange Data Capture(CDC)を利用可能にします。Icebergテーブルに対する変更(INSERT、UPDATE、DELETE)を追跡できるようになります。
sources.yml
version: 2
sources:
- name: raw_data
database: S3TABLES_LINKED_DB
schema: EXAMPLE_SCHEMA
tables:
- name: SLACK_MESSAGES_S3TABLES
description: "メッセージデータのソーステーブル"設定について
-
name: dbtモデルで参照するソース名。source('raw_data', 'SLACK_MESSAGES_S3TABLES')のように使用します。 -
database、schema: ソーステーブルが配置されているデータベースとスキーマ。 -
tables: ソーステーブルのリスト。ここで定義することで、dbtがテーブルの依存関係を自動的に解決し、データ系譜(lineage)を追跡できます。
6: dbtモデルの実行
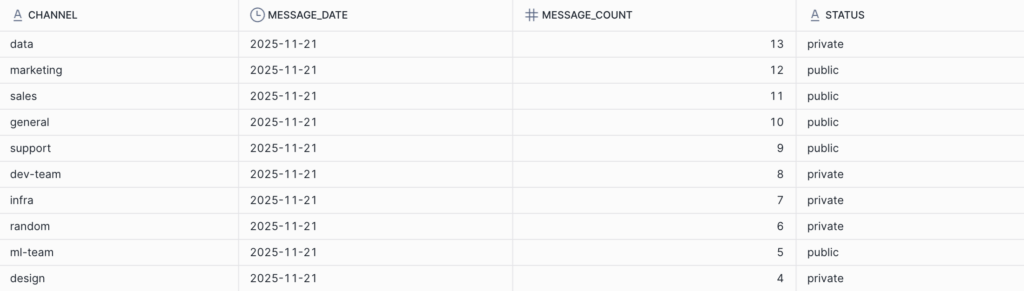
今回は、以下のようなチャンネルごとのメッセージ数を日次で集計する簡易的なincremental(増分)モデルを作成します。
{{ config( materialized = 'incremental', incremental_strategy = 'insert_overwrite', partitions = ['message_date'], catalog_name = 'catalog_horizon' ) }} select channel, date(event_time) as message_date, count(*) as message_count, status from {{ source('raw_data', 'SLACK_MESSAGES_S3TABLES') }} where channel is not null {% if is_incremental() %} and event_time >= ( select coalesce(max(message_date), '1900-01-01')::timestamp from {{ this }} ) {% endif %} group by channel, date(event_time), status
config 関数の設定
-
materialized='incremental': このモデルをテーブルとしてマテリアライズ。他のオプションとしてview、ephemeralなどがありますが、Icebergではtable、incremental、dynamic_tableがサポートされています。 -
incremental_strategy='insert_overwrite': 指定パーティションを新しいデータで丸ごと置き換える増分更新方式です。 -
partitions=['message_date']:ここでは日付単位で更新できるよう message_date をパーティションにしています。 -
catalog_name='catalog_horizon': catalogs.ymlで定義したnameを指定。この設定により、dbtは自動的にIcebergテーブルとして作成します。
この設定で、dbtは以下を自動的に行います。
-
External Volumeの使用(catalogs.ymlで指定した値)
-
BASE_LOCATIONの自動生成(
_dbt/{SCHEMA}/{MODEL_NAME}形式) -
CHANGE_TRACKINGの設定(catalogs.ymlで指定した値)
-
CATALOG = 'SNOWFLAKE'の指定(Snowflake Horizonを使用)
database、schemaは省略可能で、省略した場合はdbtのデフォルト設定(通常はdbt_project.ymlまたはprofiles.ymlで指定したターゲット)が使用されます。
作成したモデルを実行します。
dbt run --select transformed_messages成功すると、以下のような出力が表示されます:
1 of 1 START sql table model EXAMPLE_SCHEMA.transformed_messages ............ [RUN]
1 of 1 OK created sql table model EXAMPLE_SCHEMA.transformed_messages ....... [SUCCESS in 0.31s]テーブルの確認
作成されたテーブルを確認してみるとGlueカタログ管理のicebergテーブルからsnowflakeカタログ管理のicebergテーブルが作れていることが確認できました。
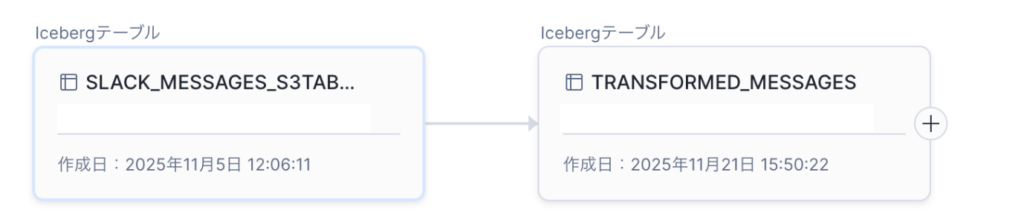
S3バケット内でのデータ構造
作成されたIcebergテーブルは、S3バケット内に以下のような構造で保存されます:
s3://example-iceberg-bucket/
└── dbt_iceberg/ # STORAGE_BASE_URL
└── _dbt/ # dbtのベースプレフィックス
└── EXAMPLE_SCHEMA/ # スキーマ名
└── transformed_messages.ABC123/ # テーブル名 + サフィックス
├── metadata/ # Icebergメタデータ
│ ├── 00000-a1b2c3d4.metadata.json
│ ├── snap-1234567890123.avro
│ ├── 1234567890123.avro
└── data/ # 実データ(Parquet)
├── 00000-0-abc123-data.parquet
├── 00001-1-def456-data.parquet
└── ...
ディレクトリ構成の詳細
ベースパス
dbtはデフォルトで_dbt/{SCHEMA_NAME}/{TABLE_NAME}というパス構造を採用しています。これには以下の理由があります。
-
環境分離:
_dbt/プレフィックスにより、dbt管理のテーブルと他のテーブルを明確に区別します。 -
スキーマごとの整理: スキーマ名ディレクトリにより、論理的なグループ化が可能。
-
一意性の確保: テーブル名にランダムサフィックス(例:
ABC123)を付与することで、テーブル再作成時の衝突を回避。
metadata/ディレクトリ
Icebergのメタデータファイルが保存されます。
-
metadata.json: テーブルスキーマ(カラム名、データ型)、パーティション情報、スナップショット履歴、テーブル統計情報を含む完全なテーブルメタデータ。
-
snap-*.avro: 各スナップショットのマニフェストリスト。どのデータファイルがそのスナップショットに含まれるかを記録します。
- .avro:スナップショット内のマニフェスト。実際のデータファイル(Parquetなど)の一覧を保持し、各ファイルのパス、サイズ、レコード数、列統計(下限・上限)などを記録します。
data/ディレクトリ
実際のデータがApache Parquet形式で保存されます。
-
列指向フォーマット: 分析クエリに最適化された圧縮形式で、特定のカラムのみを読み取る際に高速な検索が可能です。
-
ファイル命名規則: データファイルID、パーティション情報、一意識別子が含まれ、Icebergメタデータと紐付けられます。
-
スナップショット管理: Icebergのメタデータを通じて、どのファイルが現在のスナップショットに含まれるかが管理され、不要なファイルスキャンを回避できます。
-
タイムトラベル対応: 削除されたデータや古いバージョンのファイルも、
DATA_RETENTION_TIME_IN_DAYSで指定された期間保持され、過去の時点へのクエリが可能です。
Horizon Catalog で Iceberg Materialization を使う際に見えてきた制約
ここまで Iceberg Materialization の設定や動作を中心に紹介してきましたが、実際に普段利用しているリポジトリやjobに組み込んでみたところ、いくつかの不具合や制約に直面しました。
その中でも特に印象的だった事例を紹介します。
マスキングポリシーの制限
dbt では Snowflake のセキュリティポリシー(マスキングポリシーや行アクセス制御)をモデルレベルで管理するための拡張パッケージとして、dbt_snow_mask が公開されています。今回はこのパッケージを利用し、dbt モデル上でマスキングポリシーを自動的に付与できるかを試しました。
まず、status 列をもとに private な行を特定ロール以外に非表示にするシンプルなポリシーを以下のマクロで定義しました。
{% macro apply_row_access_policy_status_policy(node_database, node_schema, model_name) %}
CREATE ROW ACCESS POLICY IF NOT EXISTS {{ node_database }}.{{ node_schema }}.status_policy
AS (status string) RETURNS boolean ->
CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN', 'DEVELOPER') THEN true
WHEN status = 'public' THEN true
ELSE false
END;
ALTER TABLE {{ node_database }}.{{ node_schema }}.{{ model_name }}
ADD ROW ACCESS POLICY {{ node_database }}.{{ node_schema }}.status_policy
ON (status);
{% endmacro %}
しかし、このマクロを Iceberg Materialization(catalog_name='catalog_horizon')を指定したモデル で実行したところ、Snowflake 側で次のエラーが発生しました。
SQL Compilation error: The table TRANSFORMED_MESSAGES is an Iceberg table.
Iceberg tables should use ALTER ICEBERG TABLE commands.
このエラーは、Iceberg テーブルでは ALTER TABLE ではなく ALTER ICEBERG TABLE を使用する必要があるため、
dbt_snow_mask が内部で発行する ALTER TABLE ... ADD ROW ACCESS POLICY が Iceberg テーブルでは実行できないことが原因です。
そのため、マスキングポリシーや行レベルセキュリティを設定する場合は、
通常のマテリアライズ(materialized='table' や view)でモデルを出力する必要があるようです。
実際に catalog_name='catalog_horizon' の指定を外して実行すると、通常のテーブルとしてポリシーが問題なく適用されました。

job実行時のカタログ分岐エラー
またdbt Cloud job に関しても、通常の build job や test job を設定している場合にcatalog_name='catalog_horizon' を設定していると、以下のように実際に使用するカタログを見つけることができずに通常の job がエラーとなってしまうことが分かりました。
Catalog not found.
Received: CATALOG_HORIZON
Expected one of: INFO_SCHEMA, SNOWFLAKE
そのためIceberg Materialization を利用するモデルと通常テーブルを扱うモデルは、運用するリポジトリもしくはブランチなどを分けて管理する運用が必要になります。
今回の検証から分かるように Iceberg Materialization では通常のマテリアライズと比べて制約が多く、利用できない機能も多いため利用する際にはSnowflake側とdbt側で互いにどの機能が利用できるのか事前に公式ドキュメントやリリースノートを確認しておく必要があると感じました。
まとめ
今回の取り組みでは、Snowflake 上で Iceberg テーブルを扱うための仕組みを試しながら、dbt-snowflake adapter がどこまで実用的に使えるのかを確認できました。Snowflake Horizon では問題なくテーブルを作成できたものの、マスキングポリシーやカタログまわりなど、まだサポートが限定されている機能もあり、実装時には少し工夫が必要だと感じました。現状では GA 前の機能も多いため、実際に運用に組み込む際は、Snowflake と dbt の両方で対応状況を確認しながら進めるのが良さそうです。
一方で、Iceberg 自体は依然として魅力的なフォーマットであり、dbt_utils.surrogate_key など、データモデリングも使いたい基本的な機能は問題なく利用できます。今後のアップデートによって、より扱いやすく、実運用でも選択しやすい構成になっていくことを期待しています。
参考
Snowflake公式ドキュメント: Icebergテーブルの概要
Snowflake公式ドキュメント: Catalog-Linked Database(CLD)について
dbt公式ドキュメント: Snowflake × Iceberg統合設定