
はじめに
この記事は CyberAgent Developers Advent Calendar 2025 6日目の記事です🤶
こんにちは! 技術政策管轄CA Dev Platform Bucketeerチームの黒田( @knkurokuro7
)です。
Bucketeerとは、CA発のフィーチャーフラグマネジメント・A/BテストプラットフォームOSSです。
Bucketeer OSS化の始まりについてはこちらの記事を参照してください。
これまでBucketeerのローカル開発環境はMinikube(Kubernetes)ベースで構築されていましたが、この度新たにDocker Composeによる環境を追加しました。
Minikube環境は本番に近い動作を確認できる反面、Kubernetesの知識が必要だったり、VM起動によるリソース消費が大きかったりと、ちょっとした動作確認には少しヘビーでした。
さらに、「docker compose up一発で全部起動できたら楽なのに」という声もあり、Docker Compose対応に取り組むことにしました。
ただ、これが単純にDockerコンテナを並べて「はい、おしまい」とはいきませんでした。
BucketeerはGoogle Cloud Pub/Subを使ったイベント駆動アーキテクチャを採用しており、これをDocker Compose環境でどう再現するかが課題でした。
また、gRPC・gRPC-Web・RESTという3つの通信方式を1つのエントリーポイントで処理する必要もありました。
本記事では、この2つの課題をどう解決したかを紹介します。
アーキテクチャ比較
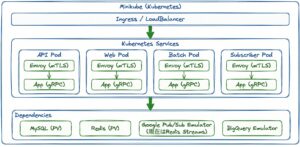
まず、両環境のアーキテクチャを図で比較してみましょう。
- Minikube(Kubernetes)環境
- Docker Compose環境
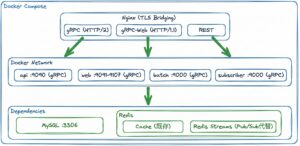
主な違いとしては、メッセージング部分と、サービスディスカバリー部分です。
それぞれ詳しく説明します。
1. Redis Streamsによるメッセージング
Minikube環境では、Google Cloud Pub/Sub Emulatorを使っていました(現在は、Redis Streamsに移行済み)。
本番と同じインターフェースで開発できるのは便利ですが、Docker Compose環境では、Redis Streamsを採用しました。
Google Cloud Pub/Sub EmulatorもDocker Compose環境で使えますが、追加のコンテナが必要になります。また、既存システムでキャッシュとして使っており、導入コストの低さとリソース効率の良さから、Redis Streamsを採用しました。
FNVハッシュによるメッセージ分散
Redis Streamsの実装では、16パーティションを使い、FNV-1aハッシュでメッセージを均等に分散しています。
FNV-1a(Fowler-Noll-Vo 1a)は、高速でシンプルな非暗号化ハッシュ関数です。任意長の文字列やバイト列を固定長のハッシュ値に変換し、ハッシュ値の分散が均等なため、パーティション分割に適しています。
// pkg/pubsub/redis/stream_publisher.go
// calculatePartition computes the partition index for a given key.
func (p *StreamPublisher) calculatePartition(key string) int {
hasher := fnv.New32a()
_, err := hasher.Write([]byte(key))
if err != nil {
// Should not normally error.
p.logger.Error("Error hashing key", zap.Error(err), zap.String("key", key))
return 0
}
return int(hasher.Sum32() % uint32(p.partitionCount))
}
処理の流れはこうです。
- メッセージIDを
fnv.New32a()でハッシュ - ハッシュ値をパーティション数(16)で割った余りを計算
- その余りがパーティション番号になる
同じメッセージIDは常に同じパーティションに行くので、同一キーのメッセージはパーティション内で順序が維持されます。
ストリームキーの形式
パーティションごとにRedisのストリームキーを生成します。
// pkg/pubsub/redis/stream_publisher.go
// getStreamKey returns the partitioned stream name
func (p *StreamPublisher) getStreamKey(id string) string {
partition := p.calculatePartition(id)
return fmt.Sprintf("%s-%d{stream}", p.streamBase, partition)
}
例えば、domainトピックのパーティション5ならdomain-5{stream}というキーになります。
{stream}というハッシュタグはRedis Cluster対応のためです。`XReadGroup`で複数ストリームを読み取る際、全キーが同じノードに配置されている必要があるため、固定のハッシュタグで全パーティションを同一ノードに配置しています。
Consumer Groupによるメッセージ読み取り
Redis StreamsのConsumer Groupは、複数のコンシューマ間でメッセージを分散する仕組みです。
Kafkaのconsumer groupと似た概念で、同じグループ内のコンシューマは異なるメッセージを受け取ります。
Pullerは起動時に全パーティションのConsumer Groupを作成します。
// pkg/pubsub/redis/stream_puller.go
// Pull reads messages from the stream and calls the handler for each message
func (p *StreamPuller) Pull(ctx context.Context, handler func(context.Context, *puller.Message)) error {
// ...省略...
// Create consumer groups for all partitions
for partition := 0; partition < p.partitionCount; partition++ {
streamKey := p.getStreamKey(partition)
// Check if the consumer group exists before attempting to create it
groupExists, err := p.consumerGroupExists(ctx, streamKey, p.subscription)
// ...省略...
// Only create the group if it doesn't exist
if !groupExists {
err := p.redisClient.XGroupCreateMkStream(streamKey, p.subscription, "0")
// ...省略...
}
}
// ...省略...
}
メッセージの読み取りはXREADGROUPコマンドで行います。
このコマンドは1回の呼び出しで複数のストリームからメッセージを取得できます。
ただし、この実装では1つのPullerが単一Goroutineで全パーティションを読み取り、メッセージは順次処理されます。
スループットを向上させるには、複数のPullerインスタンス(プロセス)を起動してConsumer Group内で負荷分散する必要があります。
// pkg/pubsub/redis/stream_puller.go
// Build streams argument for XREADGROUP
streams := make([]string, 0, p.partitionCount*2)
for partition := 0; partition < p.partitionCount; partition++ {
streamKey := p.getStreamKey(partition)
streams = append(streams, streamKey)
}
// Add the IDs matching each stream key (must have same number of IDs as keys)
for partition := 0; partition < p.partitionCount; partition++ {
streams = append(streams, ">") // ">" means only new messages
}
// Read from all partitions
streamResults, err := p.redisClient.XReadGroup(
ctx,
p.subscription,
p.consumer,
streams,
p.batchSize,
p.blockTime,
)
XREADGROUPの引数形式は[key1, key2, ..., keyN, id1, id2, ..., idN]です。
例えば["stream-0{stream}", "stream-1{stream}", ">", ">"]のように、まずストリームキーを並べ、その後に対応するIDを並べます。
>はConsumer Group専用のID指定で、「まだこのグループに配信されていないメッセージ」を取得します。
滞留メッセージのリクレイム
ワーカーがクラッシュすると、処理中だったメッセージが宙に浮いてしまいます。
これを「滞留メッセージ(stale messages)」と呼びます。
Redis Streamsでは、Consumer Group内で処理中のメッセージは「pending entries list」に記録されます。
正常に処理が完了すればXACKで確認応答を送り、リストから削除されます。
しかし、ワーカーがクラッシュすると確認応答が送られず、メッセージが残り続けます。
これを解決するために、バックグラウンドで滞留メッセージを回収するrecoveryLoopを実装しています。
// pkg/pubsub/redis/stream_puller.go
// recoveryLoop periodically checks for stale messages and reclaims them
func (p *StreamPuller) recoveryLoop(ctx context.Context) {
ticker := time.NewTicker(30 * time.Second)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return
case <-p.done:
return
case <-ticker.C:
// Skip processing if we don't have a handler
if p.handler == nil {
continue
}
// Check each partition for stale messages
for partition := 0; partition < p.partitionCount; partition++ {
streamKey := p.getStreamKey(partition)
// Retrieve pending messages that have been idle longer than idleTime
pendingMessages, err := p.redisClient.XPendingExt(
ctx,
streamKey,
p.subscription,
"-", // Start
"+", // End
10, // Count
p.idleTime,
)
// ...省略...
if len(pendingMessages) == 0 {
continue
}
// Collect message IDs
messageIDs := make([]string, len(pendingMessages))
for i, pm := range pendingMessages {
messageIDs[i] = pm.ID
}
// Claim the messages for the current consumer
claimed, err := p.redisClient.XClaim(
ctx,
streamKey,
p.subscription,
p.consumer,
p.idleTime,
messageIDs,
)
// ...省略...
// Reprocess the claimed messages
p.reprocessClaimedMessages(ctx, claimed, streamKey)
}
}
}
}
処理の流れを図で示すとこうなります。
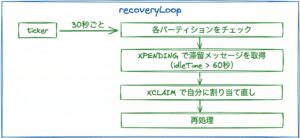
ここで注意したいのは、チェック間隔と閾値は別設定であるという点です。
- チェック間隔:30秒(
time.NewTicker(30 * time.Second)) - 閾値:60秒(
defaultIdleTime = 60 * time.Second)
30秒ごとにチェックして、60秒以上未処理のメッセージを回収します。
この設計により、一時的な遅延と本当の滞留を区別できます。
2. Nginxでのルーティング
Bucketeerは以下の3つの通信方式をサポートしています。
| 通信方式 | 用途 | HTTPバージョン |
|---|---|---|
| gRPC | サービス間通信、SDK | HTTP/2 |
| gRPC-Web
(今後REST移行予定)
|
ブラウザからのAPI呼び出し | HTTP/1.1 |
| REST | REST API(gRPC-Gateway経由) | HTTP/1.1 |
Minikube環境ではEnvoyがこれらのルーティングを処理していましたが、Docker Compose環境ではNginxで実現する必要がありました。
Docker Compose環境にはKubernetesのようなサイドカーやサービスディスカバリーの仕組みがないため、単一のリバースプロキシとしてNginxを使います。
ここで問題となるのは、gRPCとgRPC-Webでは処理方法が異なることです。
- gRPC:
grpc_passディレクティブでHTTP/2プロキシ - gRPC-Web:
proxy_passディレクティブでHTTP/1.1プロキシ
同じURLパス(例:/bucketeer.account.AccountService)に来たリクエストを、Content-Typeによって振り分ける必要があります。
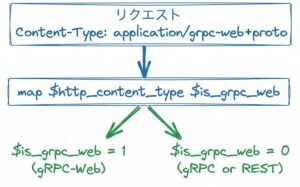
mapディレクティブで通信方式を判定
Nginxのmapディレクティブを使って、リクエストのContent-Typeから通信方式を判定します。
# docker-compose/config/nginx/bucketeer.conf
# Map to detect gRPC-Web requests
map $http_content_type $is_grpc_web {
~*application/grpc-web 1;
default 0;
}
この設定で、Content-Type: application/grpc-webを含むリクエストは$is_grpc_web = 1、それ以外は$is_grpc_web = 0になります。
判定結果は変数に格納されるので、後続のlocationブロックで参照できます。
リクエストごとに1回だけ判定が実行されるので効率的です。
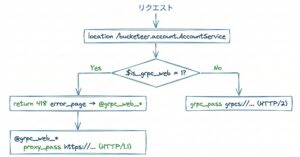
418エラーページで内部リダイレクト
Nginxのifディレクティブには制限が多く、ifの中でgrpc_passやproxy_passを切り替えることはできません。
そこで、error_pageを使った内部リダイレクトというテクニックを使います。
# docker-compose/config/nginx/bucketeer.conf
# gRPC/gRPC-Web service routes (backend handles both protocols)
location /bucketeer.account.AccountService {
if ($is_grpc_web = 1) {
error_page 418 = @grpc_web_account;
return 418;
}
grpc_pass grpcs://web_account_backend;
grpc_connect_timeout 15s;
grpc_send_timeout 15s;
grpc_read_timeout 15s;
}
location @grpc_web_account {
proxy_pass https://web_account_backend;
}
処理の流れはこうです。
/bucketeer.account.AccountServiceにリクエストが来る$is_grpc_web = 1なら、error_page 418で@grpc_web_accountにリダイレクト@grpc_web_accountでproxy_pass(HTTP/1.1)として処理$is_grpc_web = 0なら、grpc_pass(HTTP/2)として処理
418は「I’m a teapot」として知られるステータスコードです。
実際のエラー処理に使われることはないので、内部リダイレクト用に流用しています。
タイムアウトはサービスの特性に応じて調整しており、通常のAPIは15秒、バッチ処理は1時間(3600秒)に設定しています。
CORS設定
gRPC-Webはブラウザから呼ばれるため、CORS(Cross-Origin Resource Sharing)の設定が必要です。
# docker-compose/config/nginx/bucketeer.conf
# CORS headers for gRPC-Web support
add_header 'Access-Control-Allow-Origin' '*' always;
add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, PUT, DELETE, PATCH' always;
add_header 'Access-Control-Allow-Headers' 'Content-Type, x-grpc-web, authorization, grpc-timeout' always;
add_header 'Access-Control-Allow-Credentials' 'true' always;
add_header 'Access-Control-Expose-Headers' 'Content-Length, Content-Encoding, grpc-message, grpc-status, grpc-status-details-bin' always;
# Handle preflight OPTIONS requests
if ($request_method = 'OPTIONS') {
return 204;
}
ポイントは以下の3つです。
x-grpc-webヘッダーを許可:gRPC-Web特有のヘッダー- gRPCステータスを公開:
grpc-message、grpc-statusなどをブラウザに返す - プリフライトリクエストの処理:ブラウザが事前に送るOPTIONSリクエストに204で応答
TLS BridgingとHTTP/2の有効化もNginxで行い、バックエンドへはgrpcs://で暗号化接続しています。
まとめ
本記事では、BucketeerのDocker Compose対応で実装した2つの設計を紹介しました。
- Redis Streamsによるメッセージング
- Nginxでのルーティング
なお、本記事で紹介した設計はローカル開発環境での再現を目的としたものです。
本番環境で同様の構成を採用する場合は、Redis Streamsのスループットの限界や、Nginxの細かい設定など、追加の検討が必要になります。
こっちの方がいいじゃないかとか、これってどういうことだろうとかあればissueやPRをお待ちしております!
BucketeerのGitHub Issues
最後まで読んでいただき、ありがとうございました。