
はじめに
この記事は、CyberAgent Group SRE Advent Calendar 2025 5日目の記事です。
AmebaLIFE事業本部 ピグパーティでバックエンドエンジニアをしている松岡です。
ピグパーティは、2015年にサービスを開始してから今年で10周年を迎えました。長くたくさんのユーザーにご利用いただく中で、プロダクトやチームの体制も徐々に変化してきました。当初は最適だったインシデント対応フローも、現在の規模や運用スタイルとは少しずつ合わない部分が出てきていました。
そこで今回、組織全体でインシデント対応フローを改めて見直したので、本記事では、「どのようにフローを再設計し、技術実装と運用改善を進めたのか」その具体的な取り組みをご紹介します。
課題
長寿プロダクトならではの課題
10年以上続くサービスには、積み重ねてきた歴史があります。ピグパーティも例外ではなく、メンバーの入れ替わりやプロダクト・組織の拡大を経て、運用の前提は少しずつ変化してきました。その中で見えてきた主な課題は次の通りです。
- インシデント対応フローの形骸化
- フローやガイドライン自体は存在していたものの、現在の組織規模やチーム体制とは合わない部分が増えており、アップデートの必要性が高まっていた。
- 対応の属人化
- ベテランメンバーは慣れで対応できる一方、新しいメンバーは「どこに何を記録すべきか」「誰に相談すればいいか」「次に何をすべきか」が分かりづらく、初動で迷いが発生しがちでした。また、そもそも「最後まで対応をやり切れる自信がない」という心理的ハードルも高く手を上げづらいという点もありました。
プロダクトと組織が成長する一方で、インシデント対応の仕組みはその変化に十分追従できていませんでした。こうした課題を解消し、いつ誰もが対応できるようにするため、インシデント対応フローを再設計するプロジェクトを進めました。
取り組み
インシデント対応フローの再設計にあたり、以下の4つを軸として進めました。
① ガイドラインの刷新
まず、メンバー間の解釈が揺れやすかった SEV とIC の役割を明確化しました。SEV (Severity) はシステム障害やインシデントの重大度を表す指標で、IC (Incident Commander) はインシデント発生時にその対応を統括する役割を担う人物を指します。
- どのレベルの障害で誰がICを担当するか?
- 補填の判断基準は?
- SEVごとの具体的な障害例は?
などをガイドラインとして整理したことにより、障害発生時に必要な判断が標準化され、メンバー間の認識ずれを抑える土台を築きました。
② フローの見直し
次に、過去のインシデントの振り返り内容や対応ログを分析し、ピグパーティの組織に適した「王道パターン」を抽出しました。これらをもとに、インシデント対応を以下の4つのフェーズに分解し、それぞれで取るべき具体的なアクションをチェックリストとして標準化しました。
フェーズ
| 状況整理フェーズ | 影響範囲の把握、SEV判定、IC決定 |
| 復旧対応フェーズ | 暫定対応の策定と実行 |
| 補填フェーズ | ユーザー補填の策定と実行 |
| 恒久対応フェーズ | 再発防止の策定とポストモーテム |
チェックリストは後述するNotionのテンプレートとして組み込み、経験の浅いメンバーでも迷わず次のアクションを判断できる形にしました。これにより、ICや対応担当者が入れ替わっても、一定品質の対応を再現できる体制を整えました。

③ 既存ツール (Notion) を活かした情報集約
弊社ではドキュメント管理にNotionを活用しています。新しいツールの導入は学習コストや運用負荷が発生するため、既存ツールを最大限活かす方針で刷新を進めました。
| 起票 | Notionフォーム機能を活用して、インシデントの概要や担当チームなどの項目を記入し回答する |
| チケット生成 | その回答から自動でNotionページが生成 |
| 現状整理の記入 | テンプレートに沿って最新情報を記入 |
| 振り返り | 復旧後に再発防止案をまとめて完了 |
これらをすべて1つのNotionページ構成に集約し、障害の起票 → 対応 → 振り返り → ナレッジ蓄積までをNotion上で完結できるようにしています。インシデント対応中も最新情報をNotionにまとめることで、途中で参加したメンバーでも最新情報をキャッチアップしやすい状態を実現しました。

④ Slack Botの内製化
障害報告が投稿されると同時に、インシデントチャンネルへの通知とWarroom(インシデント対応チャンネル)の自動生成を行うSlack Botを内製しました。インシデント対応のSaaSツールなどもありますが、学習コストや運用の柔軟性を考慮し、内製する方がメリットが大きいと判断しました。
技術実装
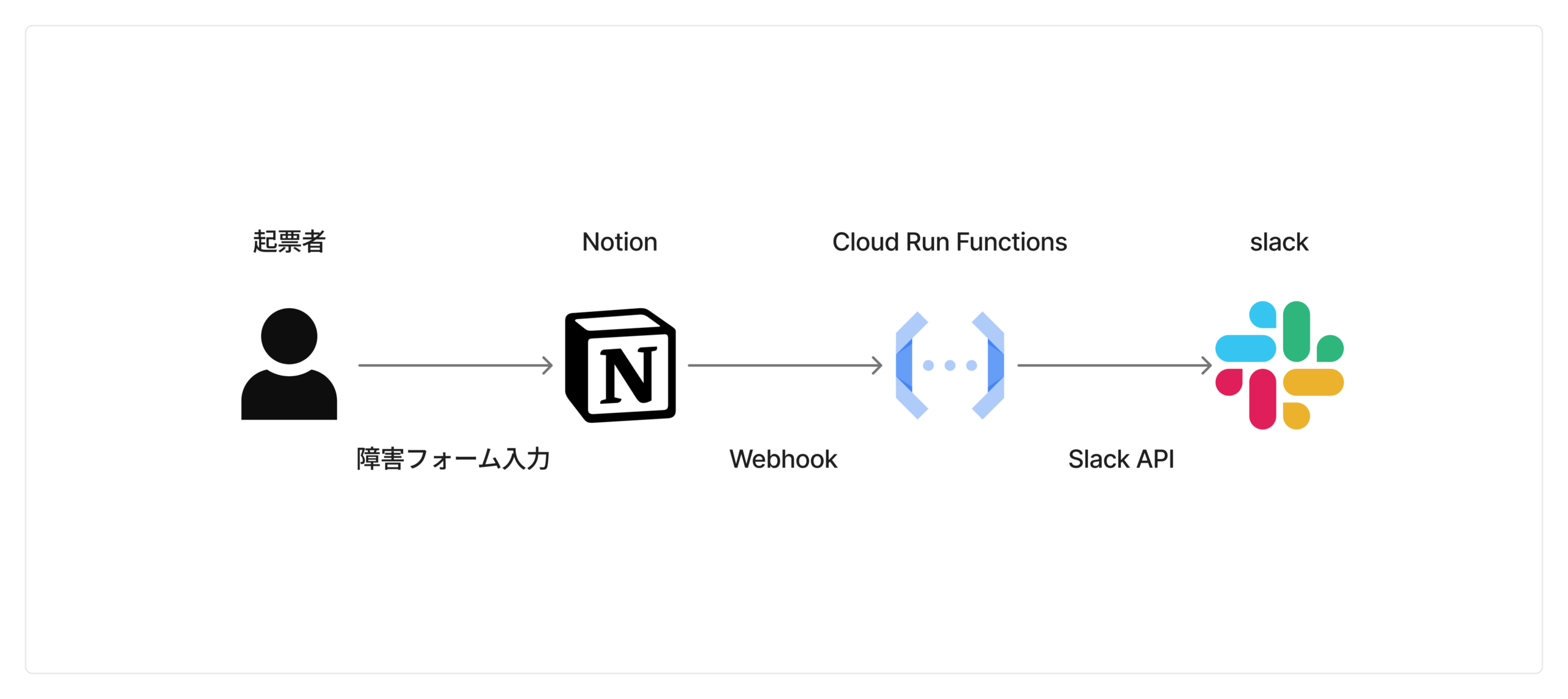
全体アーキテクチャ
障害起票からSlackでのWarroom作成までを自動化するために、Notion・Slack API・Google Cloudを組み合わせた構成を採用しました。起票の入口にはNotionフォームを使用しており、エンジニア以外のメンバーでもシンプルに障害報告できるようにしています。
この一連の処理を支える主要コンポーネントは以下の通りです。
- Notion:フォーム送信、チケット管理、Webhook
- Slack API (Bolt):通知・チャンネル作成・メンション付与
- Cloud Run Functions:Node.jsで処理を実装
- Terraform:Cloud Run Functionsのリソース管理
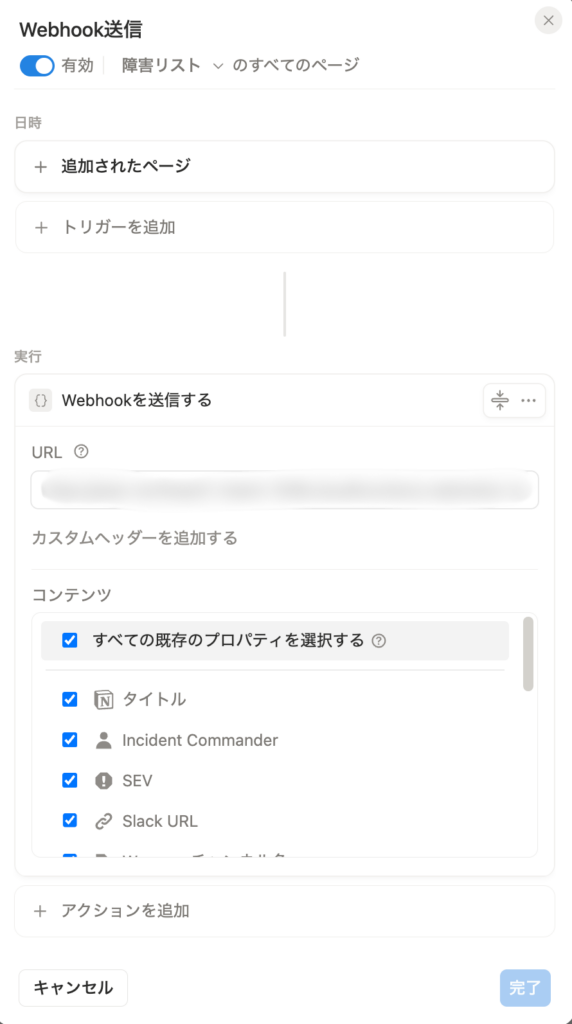
Notionオートメーション
Notionのオートメーション機能では、Webhookアクションが使用できます。フォーム送信内容はそのままデータベースに反映され、ページが追加されたタイミングでWebhookが自動的に発火します。WebhookはCloud Run Functionsに送られ、即座にSlack通知・チャンネル作成処理に繋げます。
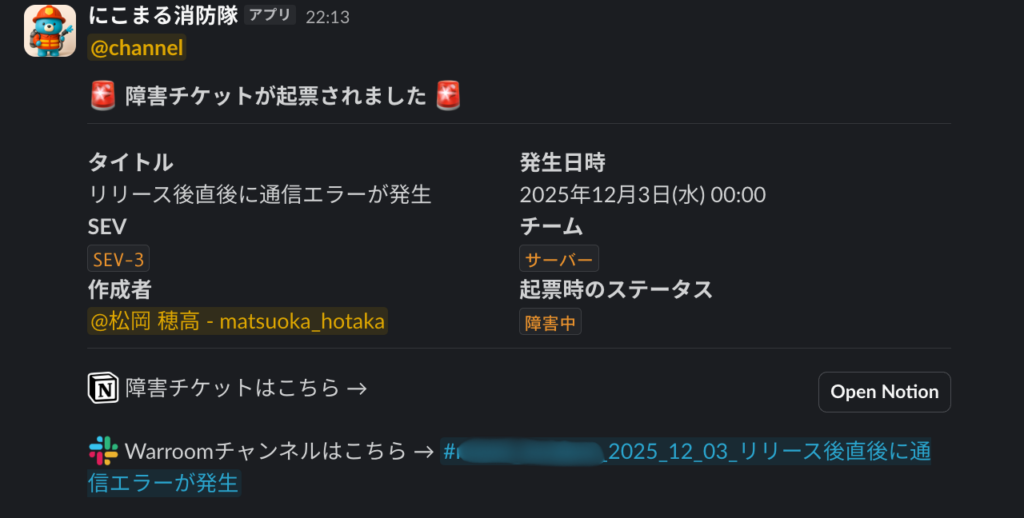
Slack通知
Cloud Run Functionsの処理を通じてインシデントチャンネルに障害報告が通知されます。また、インシデント通知と同時に、自動でWarroomが生成されるようになっています。
成果と変化
フローを刷新し、技術的な仕組みを整えたことで、チームに目に見える変化が生まれました。
若手メンバーの自走
最も大きな変化は、経験の浅いメンバーでも迷わずインシデント対応を進められるようになったことです。チェックリストにより「次に何をすればいいか」が明確になり、以前は「最後までやり切れるか自信がない」と感じていたメンバーも、自信を持ってICや対応担当を引き受けられるようになりました。実際に、新卒や最近ジョインしたメンバーが主体的にインシデント対応を進めるケースも増えました。
情報の透明性とナレッジ蓄積
すべての情報をNotionに統一したことで、「今何が起きているのか」「誰が対応しているのか」をチーム全体が把握しやすくなりました。途中参加のメンバーもNotionページを見るだけで最新状況をキャッチアップできます。以前は情報がSlackスレッドに埋もれてしまうこともありましたが、今は対応ログや振り返りがNotionに蓄積され、過去事例を参照して改善に生かしやすい環境が整っています。
心理的安全性の向上
「ミスを責める」のではなく「次にどう改善するか」にフォーカスする空気が生まれ、建設的な議論が増えました。チーム全体でカバーし合う文化醸成のきっかけにも繋がりました。
まとめ
今回、インシデント対応フローを見直し、ガイドライン整備・フローの見直し・Slack Botの内製化など、仕組みを大きくアップデートしました。これにより、誰でも迷わず初動に入れる再現性の高いフローが整い、現場からも「動きやすくなった」という声が少しずつ増えています。とはいえ、ルールやフローは作って終わりではありません。チームの成長やプロダクトの変化に合わせて、継続的にアップデートしていくことが何より大切だと感じています。
改善の余地はまだまだありますし、これからも現場の声を取り入れながら、より最適なフローへ育てていきたいと思います。