
この記事は Datadog Advent Calendar 2025 11日目の記事です🎄
ABEMAの広告配信システム開発チームでバックエンドを担当している黒崎 ( @kuro_m88 )です。
今年DatadogのVectorを本番環境に導入したため、その事例を共有します。
DatadogのRust製オブザーバビリティデータパイプラインVectorとは?
Vector自体はDatadogのサービスではないため、Datadogユーザの中でも初めて聞いた人は多いかもしれません。
元はTimber Technologies社が開発していて、2021年にDatadogが同社を買収し、DatadogのCommunity Open Source Engineering teamが開発するソフトウェアとなりました。
https://www.datadoghq.com/blog/datadog-acquires-timber-technologies-vector/
オブザーバビリティデータパイプラインとは、オブザーバビリティデータ(メトリクス、ログ、トレース)を変換、集約、フィルタ等し、各種出力先に転送するパイプラインです。
Vectorはドキュメントが非常に充実していて、興味を持った方はひととおり読んでみるのをおすすめします。
https://vector.dev/docs/
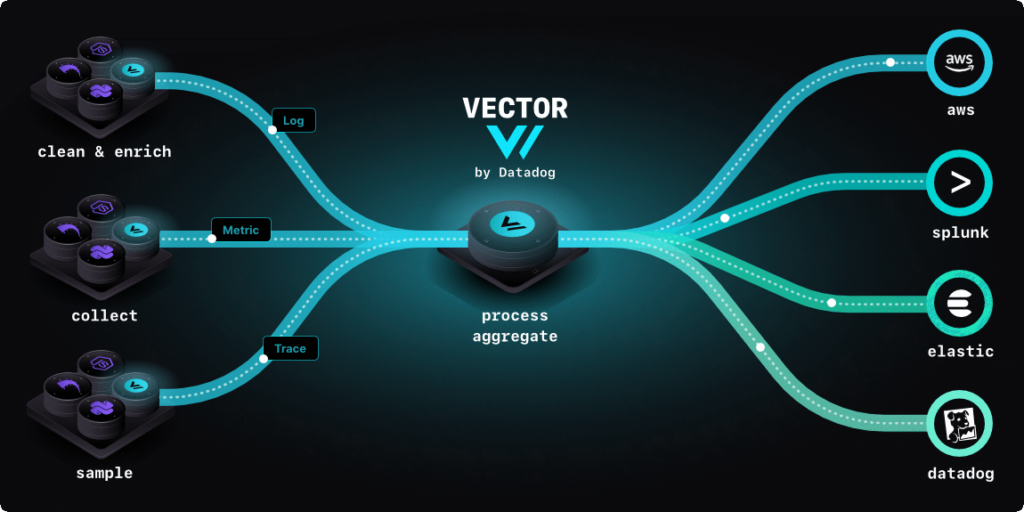
基本的なコンセプトとしては、Soruces(入力), Transforms(変換), Sinks(出力)の流れで流れてくるオブザーバビリティデータを処理する流れです。それぞれ対応している入出力や変換方法の一覧をみていただくと非常に幅広くカバーされていて、多くのユースケースがカバーできそうなことがわかります。
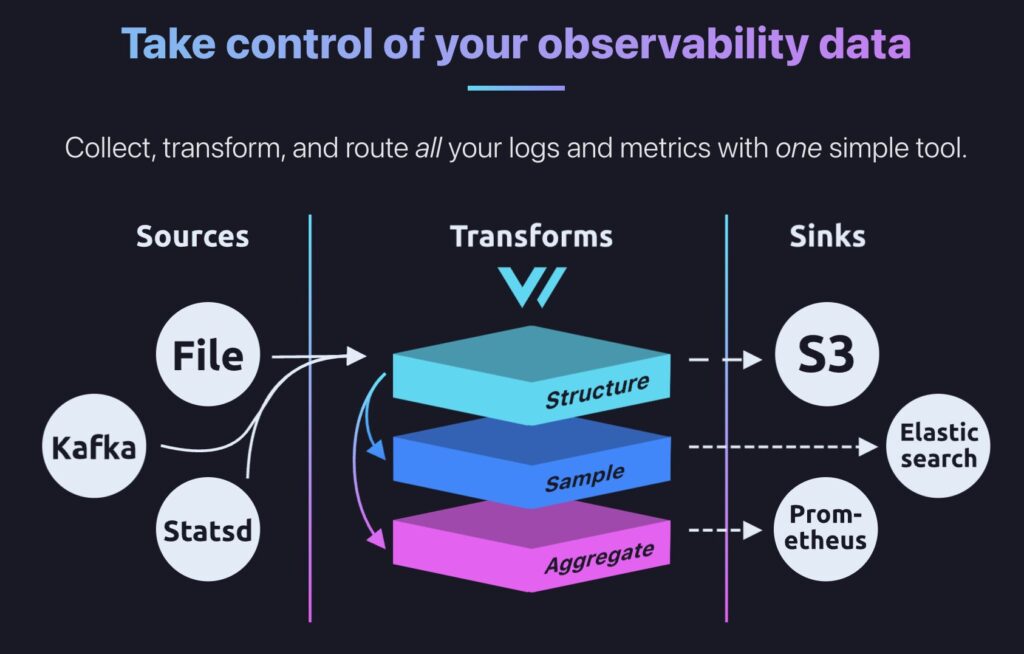
必要なソフトウェアとしてはVectorというワーカーのみで、デプロイ方法もアプリケーションコンテナのサイドカーにする方式、コンテナクラスタ等のノードで起動する方式(KubernetesでいうDaemonSet)、複数ノードのデータソースからのデータを集約して処理するアグリゲーター方式があります。今回はdatadog-agentをデータソースにしたかったため、アグリゲーター方式を採用しました。
https://vector.dev/docs/setup/deployment/roles/
ソフトウェアはRustで書かれており、検証環境では1つのワーカーで3000req/s程度のオブザーバビリティデータの入力に対して、シンプルな処理であれば0.1 vCPU, メモリ30MB程度の消費で済んだ程度には軽量でした。ただし、このリソース消費量は特にTransformsで記述する処理の負荷や複雑度、バッファリング量によってかなり変動があるので、運用しながら必要なリソース割り当てを見極める必要があります。
ログ転送といえばFluentdが有名ですが、Vectorはそれに比べると後発ということもあり、運用に役立つメトリクスが充実していたり、パフォーマンスや可用性に気を配られていたりする印象を受けました。
Datadog Observability Pipelines
DatadogにはObservability Pipelinesというサービスがあります。Web UIでデータパイプラインを組むことができ、入力、フィルタ、変換、出力が直感的に設定できます。
https://www.datadoghq.com/product/observability-pipelines/
結論からいうとこちらは採用せず、素のVectorを自分たちの環境にデプロイして運用することにしました。その背景を共有します。
Observability Pipelines Workerというコンテナを自分たちの環境にデプロイして利用するのですが、ログ出力や設定方法等から察するに内部ではVectorのようなものが動いているように見えることから、Observability PipelinesはVector + DatadogのWeb UI経由でのRemote Configができるマネージドサービスのようなものだと理解しました。
検証してみて一番いいなと思ったのはフィルタの設定をするときにリアルタイムでログを流し、適用結果を確認しながら運用できる仕組みでした。この機能はOSS版のVectorにはないので、Observability Pipelinesを採用する場合のメリットとなりそうです。
UIでポチポチ設定が組めるとはいえ、本番運用を見据えるとterraformでIaC(Infrastracture as Code)をしたくなります。
terraform providerを使った構築を検討していたところ、optionalであるはずの設定が存在しない場合にエラーが起きてしまうのが判明したため、プルリクエストを上げてみました。
observability_pipeline: Fix nil dereference when sources/processors/destinations are unset in pipeline config #3137
この問題が解決されれば使えるかと思いつつAPIドキュメントを読んでいたところ、今日時点ではAPI自体がpreviewのようで、申請しないと使えないようでした。実際にこのAPIを叩いてみるとエラーが返却されます。ということで、いずれにせよterraformを使った運用はまだ厳しそうなことがわかりました。
https://docs.datadoghq.com/api/latest/observability-pipelines/
そして一番の決め手になったのが料金体系です。
料金ページによれば、Datadog Logsの取り込み料金が$0.10/GBに対してObservability Pipelinesの取り込み料金が$0.095/GB発生するようです。
https://www.datadoghq.com/ja/pricing/?product=observability-pipelines#products
https://www.datadoghq.com/ja/pricing/?product=log-management#products
ここでいうObservability Pipelinesの取り込み料金とはObservability Pipelinesのワーカー(自分たちでホストするリソース)へのデータ入力(取り込み)で、後段でDatadog Logsへログを取り込むと二重に費用が発生してしまいます。
また、Observability Pipelinesで不要なログを大量にフィルタして必要なログのみDatadog Logsへ転送することでコスト削減も狙っていたのですが、Observability Pipelines自体の料金があるため、全量転送してからDatadog Logs側でexclusion filterを書くだけの場合よりトータルコストが高くなってしまいそうです。
vCPUあたりの価格体系もあり、30TB/月以上の利用だとこちらも推奨されるようでしたが、Datadog Logs自体導入しはじめで転送量が読めないため検討しませんでした。
また、後述しますが検討を進める過程で素のVectorのほうが現時点は設定の表現力に柔軟性があったため、前述の問題がなかったとしてもVectorを採用していたかもしれません。
VRL(Vector Remap Language)
Vector用のオブザーバビリティイベントを変換したりフィルタしたりするための専用言語としてVector Remap Language(VRL)があります。
既存の言語や簡単な条件式のみにしなかった理由はVectorのブログに書かれています。
https://vector.dev/blog/vector-remap-language/
主な特徴としてはイベントの変換やフィルタに特化し、文法もシンプルにしているためLuaやJavaScriptよりも高速で、型付けがありコンパイルができるため静的に構文エラーが検出でき、テストコードも書けるようになっています。
エラーの表示も直感的です。
error[E103]: unhandled fallible assignment
┌─ :1:5
│
1 │ . = parse_common_log(.log)
│ --- ^^^^^^^^^^^^^^^^^^^^^^
│ │ │
│ │ this expression is fallible
│ │ update the expression to be infallible
│ or change this to an infallible assignment:
│ ., err = parse_common_log(.log)
│
= see documentation about error handling at https://errors.vrl.dev/#handling
= learn more about error code 103 at https://errors.vrl.dev/103
= see language documentation at https://vrl.dev
文法は個別に紹介はしませんが、かなりシンプルかつ内蔵の関数もあるのですぐに使い始められると思います。型とエラーハンドリングが前提になっているため、考慮漏れが発生しにくいのが好印象です。
https://vector.dev/docs/reference/vrl/
現在本番稼働しているVectorの設定ファイルはVRLが大半を占めていますが、400行弱あります。これだけ行数が多いと記述ミスで実行時エラーが多発しそうなきがしますが、vector validateコマンドで構文の整合性が検証できるので検証時含めそのレベルのミスはあまり起きませんでした。
最終的な本番構成
最終的にVector導入後のオブザーバビリティパイプラインは以下の図のような構成になりました。
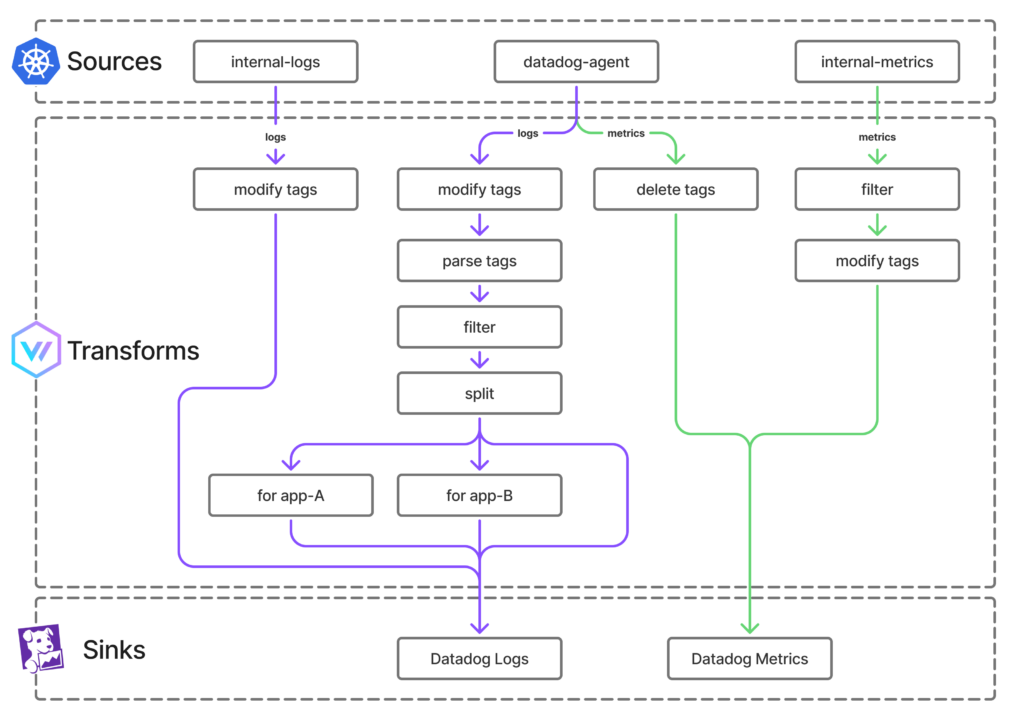
GKE(Google Kubernetes Engine)上で動いているアプリ(Pod)たちのログやメトリクスの転送を目的としており、Vectorはアグリゲーターとして稼働させています。本番クラスタ内ではVectorのPodは常時数個稼働しています。
Kubernetes向けにはHelm Chartが用意されています。
https://github.com/vectordotdev/helm-charts/tree/vector-0.48.0/charts/vector
データソースはdatadog-agentから各コンテナのログを入力しています。Vectorに直接アプリケーションコンテナの標準出力等を接続しせずにdatadog-agentを経由させることでkubernetesのメタデータから事前にdatadog関連のタグが生成されて付加された状態でVectorにデータが転送されます。
Vector自体のメトリクスやログはinternal-logsやinternal-metricsとして表現されていて、それもDatadogにそのまま転送できるのは便利ですね。
前述の400行弱あるVectorの設定ファイルの大半はTransforms層のVRLが占めていて、明らかに不要なタグを削除することでDatadog Metricsの課金を抑制したり、事前にログのタイムスタンプ関連のフィールドをパースしてフォーマットを正規化するなどしてDatadog Logsで扱いやすく変換したりしています。
Datadog Logs側でもルールを記述するとDatadogにログが転送された後に変換やフィルタができますが、事前に処理できるものは処理してからDatadogに送ることでDatadog側の設定がシンプルになること、VRLのほうがプログラマブルに処理しやすいことはメリットだと感じました。
特定の条件にマッチするログを捨てるVRLはこのようにかけます。複雑そうに見えますが、流れてきたログの評価結果が特定の条件(捨てたい条件)にマッチしたらfalseとなって捨てられ、そうでなければtrueになって捨てられないようにしています。
datadog_logs_filter:
type: filter
inputs:
- datadog_logs_parse_tags
condition:
type: vrl
source: |-
# Exclude vector own stdout
!(get!(%custom_metadata.tags, path: ["kube_namespace"]) == "datadog" &&
get!(%custom_metadata.tags, path: ["kube_container_name"]) == "vector") &&
# Exclude vector-haproxy info logs
!(get!(%custom_metadata.tags, path: ["kube_namespace"]) == "datadog" &&
get!(%custom_metadata.tags, path: ["kube_container_name"]) == "haproxy" &&
!starts_with(to_string(.) ?? "", "[")) && # Except for access logs, starting with "[" (e.g "[WARNING]")
# Exclude image-package-extractor
!(get!(%custom_metadata.tags, path: ["kube_namespace"]) == "kube-system" &&
%datadog_agent.service == "image-package-extractor") &&
# Exclude gke-metadata-server
!(get!(%custom_metadata.tags, path: ["kube_namespace"]) == "kube-system" &&
%datadog_agent.service == "gke-metadata-server") &&
# Exclude proxy-agent
!(get!(%custom_metadata.tags, path: ["kube_namespace"]) == "kube-system" &&
%datadog_agent.service == "proxy-agent") &&
# terminate conditions
true
若干マニアックな話になってしまいますが、Datadogのタグは同じキーが複数定義できることから内部表現上はkey/value構成になっておらず、ddtagsという文字列にカンマ区切りで表現されています。
VRLだと以下のように書くことでこれをパースし、後段のtransformerで扱いやすくします。
datadog_logs_parse_tags:
type: remap
inputs:
- datadog_agent.logs
source: |-
# parse ddtags
tags = {}
for_each(split!(%datadog_agent.ddtags, ",")) -> |_index, tag| {
kv = split(tag, ":")
if length(kv) > 0 {
key = kv[0]
value = null
if length(kv) > 2 {
value = join!(slice!(kv, start: 1), separator: ":")
} else {
value = kv[1]
}
tags = set!(value: tags, path: [key], data: value)
}
}
%custom_metadata.tags = tags
ログに関しては途中で特定のアプリ向けの設定を書けるようにしました。例えばArgo Workflowのログに特化した設定です。
ログのseverityやタイムスタンプ、エラーのスタックトレースをDatadog Logsの形式に合わせています。
datadog_logs_argo:
type: remap
inputs:
- datadog_logs_split_route.argo
source: |-
if is_object(.) {
if !is_nullish(.level) {
%datadog_agent.status = .level
}
ts = .timestamp || .ts
if is_float(ts) || is_integer(ts) {
ts, err = from_unix_timestamp(to_int(to_float!(.ts)*1000*1000), unit: "microseconds")
if err == null {
%datadog_agent.timestamp = ts
del(.timestamp)
}
}
if !is_nullish(.error) {
msg = del(.error)
.error.kind = "WorkflowError"
.error.message = msg
}
if !is_nullish(.stacktrace) {
.error.kind = "WorkflowError"
.error.stack = del(.stacktrace)
}
}
これらの変換を経たのちにDatadog LogsやDatadog Metricsとして転送しています。
以下の画像はDatadogで作ったVectorのダッシュボードです。ある日の本番環境の様子ですが、だいたい秒間2万イベントくらい処理しているのがわかります。
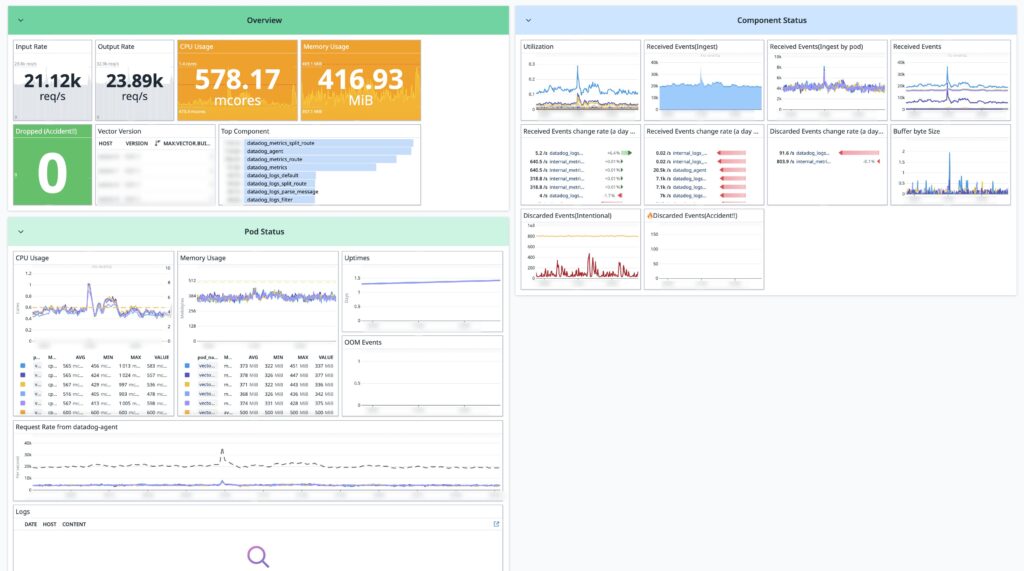
リソース消費はtransformerで書いた内容によって負荷傾向が変わるので他の環境での参考にはならないとは思いますが、現在は冗長化の意味もかねて4Podで構成しており、それぞれおおよそ0.5 vCPU、メモリ500MB前後の消費で推移していそうです。パイプラインのコンポーネントごとにメトリクスが取れるので急に負荷が高くなったりしてもどのコンポーネントが原因なのかすぐ確認できます。
最初はkubernetesのサービス(L4 LB)としてクラスタ内にエンドポイントを提供していたのですが、Podごとのメトリクスをみるとコネクションの偏りがみられたので、haproxy(L7 LB)を経由させています。helm chartにhaproxyを利用するオプションがあるので有効化するだけ構成が変えられます。
余談
基本的には安定稼働してくれていて品質も高いソフトウェアだと思っていますが、検証過程で何度かVectorをクラッシュさせてしまいました。
デプロイするときに環境変数にDatadogのAPIキーなどシークレットが挿入されるようにするのですが、シークレットのリストア方法を誤ってしまい環境変数に文字ではないものや改行コードが混ざってしまい、それがバグを引き当ててしまったようでクラッシュしてしまいました。原因はログからすぐ判明し、プルリクエストを上げて取り込んでもらったので今は大丈夫です。
fix(config): prevent panic on non-UTF8 environment variables #23513
fix(datadog_common sink): prevent panic on invalid api key #23514

これにより人生初のRust開発をしたのですが、該当コードはわかっていたのでChatGPTにお願いしたらすぐに修正できました。便利な時代になりました。
それでは、2026年も可観測性の強化をやっていきましょう!🎄