
この記事は CyberAgent Developers Advent Calendar 2025 15日目の記事です。
MG-DXでバックエンドおよびSREを担当している藤垣(@eiaou_f)です。
はじめに
「DBのコストが毎月徐々に上がっている…」
システムが成長するにつれて、このような悩みを抱えるチームは多いのではないでしょうか。私たちのチームでも同様の課題に直面していました。調査を進めていくと、フロントエンドからのポーリング処理がデータベースへ想定以上の負荷をかけていることが判明しました。
本記事では、ポーリング処理を廃止し、イベント駆動型アーキテクチャへ移行することで、この問題を解決した事例をご紹介します。結果として、秒間リクエスト数の50%削減、データベースコストの30%削減を達成することができました。
同様の課題を抱えている方にとって、少しでも参考になれば幸いです。
背景と課題
既存アーキテクチャの概要
私たちが運用している予約管理システムでは、薬剤師が最新の予約情報をリアルタイムで確認できることが重要な要件でした。この要件を満たすため、フロントエンドから30秒間隔でAPIをポーリングする実装を採用していました。
一見シンプルで分かりやすいアプローチですが、システムの成長とともに問題が顕在化してきました。
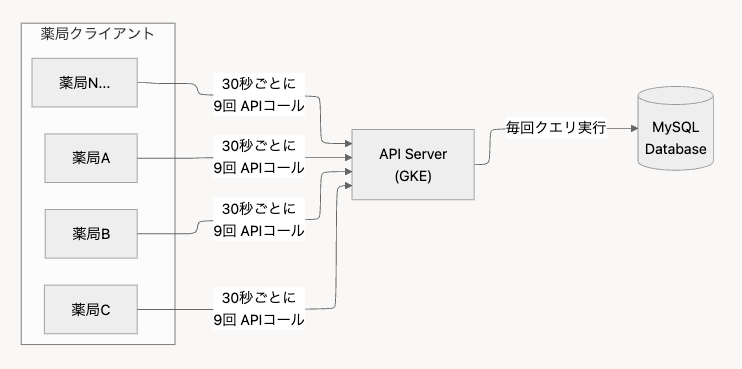
数字で見る問題の規模
予約に関するエンドポイントを実際に計測してみると、以下のような状況になっていました。
| 指標 | 数値 |
|---|---|
| ポーリング間隔 | 30秒 |
| 1回あたりのAPIコール数 | 9回 |
| 予約検索APIの秒間リクエスト数 | 約2,000リクエスト/秒 |
1回のポーリングで9回のAPIを呼び出していたのは、予約一覧、予約詳細、ステータス情報など、画面表示に必要な情報を複数のエンドポイントから取得していたためです。これに加えて、多数の薬局クライアントが同時にポーリングを実行するため、リクエスト数が膨大になっていました。
また、予約データは日々構造が複雑になっていき、検索のためにデータベースのテーブルにインデックスを張っても大きな負荷がかかる状況だったため、より本質的な問題の解決を行う必要がありました。
問題の本質:「無駄な」リクエスト
ポーリング方式の根本的な問題は、データに変更があってもなくても、定期的にリクエストが発生するという点にあります。
実際の運用データを分析してみると、興味深い事実が分かりました。予約データに変更が発生する頻度は、ポーリング頻度と比較するとかなり低いのです。つまり、大半のリクエストは「変更なし」という結果を返すだけで、実質的な価値を生み出していませんでした。
時間軸で見たポーリングの様子
[00:00] ポーリング実行 → 変更なし(無駄)
[00:30] ポーリング実行 → 変更なし(無駄)
[01:00] ポーリング実行 → 変更あり ✓
[01:30] ポーリング実行 → 変更なし(無駄)
[02:00] ポーリング実行 → 変更なし(無駄)
...
→ 実際に意味のあるリクエストはごく一部
この「無駄な」リクエストが継続的にデータベースへ負荷をかけ、インフラコストを押し上げる要因となっていました。
なぜこのタイミングで対処したのか
この問題は以前から認識していましたが、転機となったのは、あるプロジェクトで導入店舗数が倍増したことで、月次のインフラコストレビューでDBコストの上昇トレンドが明確になったことです。このまま放置すると、コストが許容範囲を超えることが予測されました。これを機に、本格的な対策に乗り出すことになりました。
解決策:イベント駆動アーキテクチャへの移行
設計思想
解決策を検討するにあたり、まず原点に立ち返って考えました。
「そもそも、なぜポーリングしているのか?」
答えはシンプルで、「予約データに変更があったことを知りたいから」です。であれば、変更があったときだけ通知を受け取れば良いはずです。
この発想の転換が、イベント駆動アーキテクチャへの移行を決断するきっかけとなりました。従来のプル型(ポーリング)からプッシュ型(イベント駆動)への転換により、不要なリクエストを根本的に排除することを目指しました。
全体像
新しいアーキテクチャの処理フローは以下のようになります。
- 予約データに変更が発生(イベント発火)
- イベント伝播用マイクロサービスがサブスクライブ
- マイクロサービスがFirestoreの薬局別ドキュメントを更新
- フロントエンドがFirestoreの変更を検知
- 必要な予約データをAPIから取得
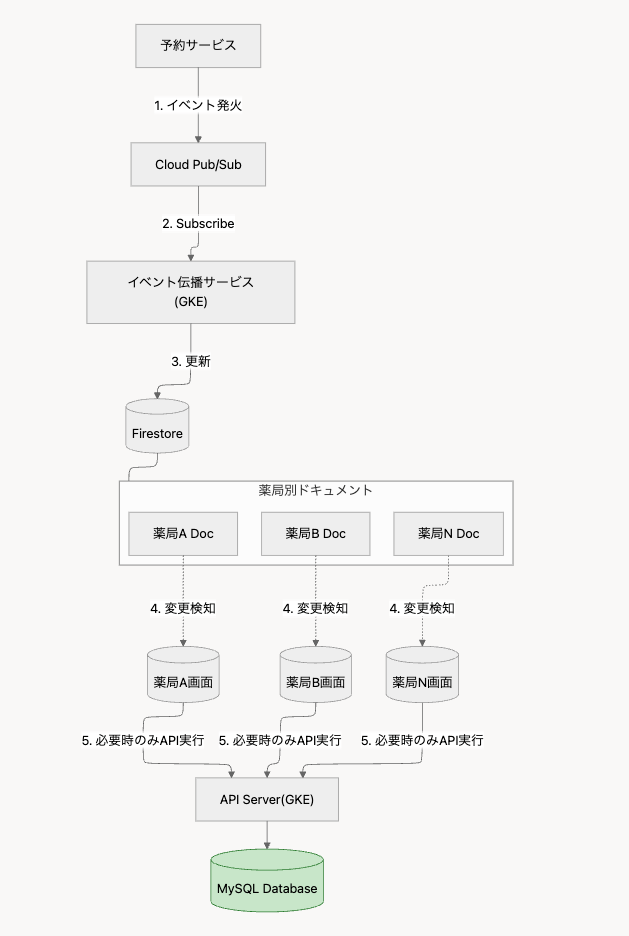
各コンポーネントの役割
予約サービス(イベント発行元)
予約の作成・更新・キャンセルなどの変更を検知し、イベントを発行します。既存の予約システムに最小限の変更を加える形で実装しました。
Cloud Pub/Sub
Google Cloudが提供するフルマネージドなメッセージングサービスです。イベントの非同期配信を担い、システム間の疎結合を実現します。
イベント伝播サービス
GKE上で稼働する軽量なマイクロサービスです。Pub/Subからイベントを購読し、Firestoreの更新を行います。このサービスを独立させることで、関心の分離と保守性の向上を図りました。
Firestore
薬局ごとのイベント状態を管理するリアルタイムデータベースです。各薬局に対応するドキュメントを用意し、イベント発生時にタイムスタンプを更新します。
フロントエンドクライアント
Firestoreのリアルタイムリスナー機能を使用して、自身に関係するドキュメントの変更を監視します。変更を検知したら、必要なデータをAPIから取得します。
技術選定の根拠
なぜFirestoreを選んだのか
リアルタイム通知の実現手段として、いくつかの選択肢を検討しました。
| 選択肢 | メリット | デメリット |
|---|---|---|
| WebSocket | リアルタイム性が高い | 接続管理が複雑、スケーリングが難しい |
| Server-Sent Events | 実装がシンプル | 同上 |
| Firestore | リアルタイム同期が標準、スケーラブル | 読み取りコストがかかる |
最終的にFirestoreを選んだ理由は以下の通りです。
- リアルタイム同期機能が標準装備:SDKを使うだけで、面倒な接続管理なしにリアルタイム同期が実現できます
- スケーラビリティ:Google Cloudのマネージドサービスとして、自動的にスケールします。クライアント数の増加に対して、インフラ側での対応が不要です
- 薬局ごとのドキュメント分離:各薬局が自身に関係するドキュメントのみを購読するため、不要なデータを受信することがありません
- 既存のGoogle Cloud環境との親和性:すでにGKEやPub/Subを使用していたため、同じエコシステム内で完結できる点も大きなメリットでした
なぜPub/Subを介在させるのか
「予約システムからFirestoreへ直接書き込めば、シンプルになるのでは?」という意見もあるかと思います。たしかに技術的には可能ですが、以下の理由により、Pub/Subを介在させる設計としました。
1. システム間の疎結合化
予約システムはFirestoreの存在を知る必要がなく、「イベントを発行する」という責務のみを持ちます。これにより、通知先の追加・変更が容易になります。
2. 信頼性の向上
Pub/Subはメッセージの永続化と再送機能を持っているため、一時的な障害が発生してもイベントが失われることがありません。
3. 監視のしやすさ
Pub/Subのメトリクス(未処理メッセージ数、処理時間など)を監視することで、システムの健全性を把握しやすくなります。
4. 将来の拡張性
現在はFirestoreへの伝播のみですが、将来的には分析基盤への連携、通知サービスへの連携など、イベントの配信先を追加する可能性があります。Pub/Subを介在させておくことで、これらの拡張が容易になります。
なぜCloud Tasksを使ったのか
スロットリング機構の実装には、いくつかの選択肢がありました。
| 選択肢 | 評価 |
|---|---|
| アプリケーション内のインメモリキャッシュ | Pod再起動で状態が失われる |
| Redis | 別途インフラ管理が必要 |
| Cloud Scheduler | 固定間隔のジョブ向けで、動的なスケジュールには不向き |
| Cloud Tasks | 動的なタスクスケジュールに最適、フルマネージド |
Cloud Tasksは「指定した時刻に1回だけHTTPリクエストを送信する」というシンプルな機能を提供しており、今回のユースケースにぴったりでした。また、フルマネージドサービスのため、キューの管理やスケーリングを意識する必要がありません。
実装詳細
1. イベント発行(Pub/Subへのパブリッシュ)
予約データに変更が発生したタイミングで、Cloud Pub/Subへイベントをパブリッシュします。
2. イベント伝播サービス(Subscriber)
GKE上で稼働するマイクロサービスがPub/Subからイベントを購読し、Firestoreを更新します。
3. フロントエンドにおける変更検知
フロントエンドでは、Firestoreのリアルタイムリスナー機能を使用して、ドキュメントの変更を検知します。
Firestoreのリアルタイムリスナーを使うことで、開発者は接続管理を意識することなく、変更検知のロジックに集中できます。
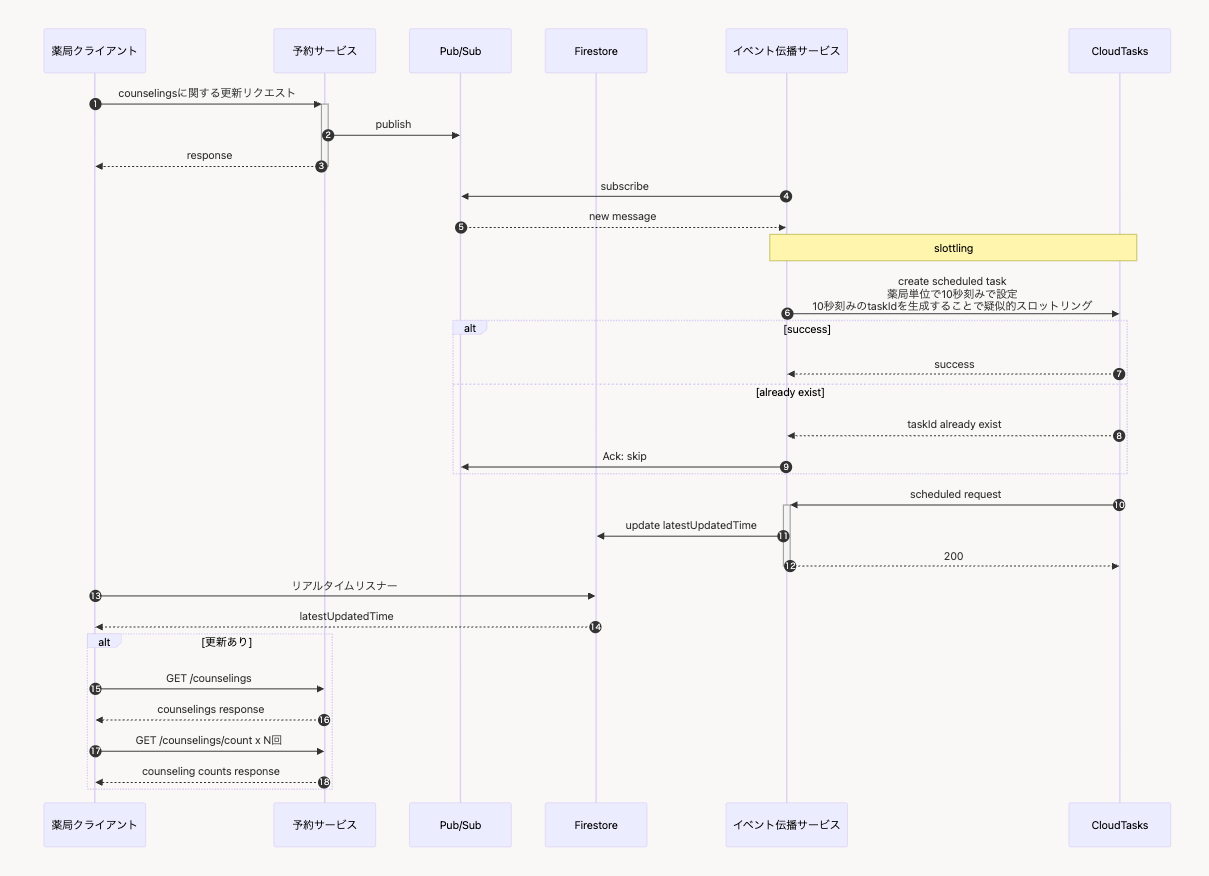
工夫したポイント①:Cloud Tasksによるスロットリング
課題:短時間に大量のイベントが発生するケース
イベント駆動アーキテクチャへの移行を進める中で、新たな課題が見えてきました。
予約の登録や更新、キャンセルなどが短時間の間に行われた場合に多数のイベントが発生します。これをそのままフロントエンドに伝播すると、以下の問題が発生します。
- 同じ薬局に対して数秒間で何十回もFirestoreが更新される
- フロントエンドが変更を検知するたびにAPIを呼び出し、結局大量のリクエストが発生
- せっかくポーリングを廃止したのに、スパイク時の負荷が改善されない
これでは本末転倒です。
解決策:Cloud Tasksを使ったスロットリング
この問題を解決するため、Cloud Tasksを使ったスロットリング機構を導入しました。
基本的なアイデアは、「一定時間内に発生した複数のイベントを、1回の通知にまとめる」というものです。
イベントの流れ(スロットリングなし)
[00:00.0] イベントA発生 → 即座にFirestore更新 → フロント検知 → API呼び出し
[00:00.1] イベントB発生 → 即座にFirestore更新 → フロント検知 → API呼び出し
[00:00.2] イベントC発生 → 即座にFirestore更新 → フロント検知 → API呼び出し
[00:00.3] イベントD発生 → 即座にFirestore更新 → フロント検知 → API呼び出し
→ 0.3秒で4回のAPI呼び出しが発生!
イベントの流れ(スロットリングあり:10秒間隔)
[00:00.0] イベントA発生 → 10秒後に実行するタスクを登録
[00:00.1] イベントB発生 → 既にタスクがあるのでスキップ
[00:00.2] イベントC発生 → 既にタスクがあるのでスキップ
[00:00.3] イベントD発生 → 既にタスクがあるのでスキップ
[00:10.0] タスク実行 → Firestore更新 → フロント検知 → API呼び出し
→ 1回のAPI呼び出しで済む!
実装の概要
Cloud Tasksで遅延実行を行い指定時刻にHTTPリクエストを送信することで実現しています。
type counselingEventDispatcher struct {
client *cloudtasks.Client
cfg config.CloudTasks
}
// Cloud Tasksに10秒後実行のタスクを登録
func (d *counselingEventDispatcher) Dispatch(ctx context.Context, event *domain.CounselingEvent, t time.Time) error {
body := d.convert(event)
httpRequest, err := d.client.CreateHttpRequest(taskspb.HttpMethod_POST, "/propagate", body, generateHeader(ctx, d.cfg))
if err != nil {
return errors.Wrap(err, "CreateHttpRequest")
}
task, err := d.newTask(event.PharmacyID, event.ChainID, d.dispatchTime(t), httpRequest)
if err != nil {
return errors.Wrap(err, "newTask")
}
if err = d.client.Dispatch(ctx, task); err != nil {
if status.Code(err) == codes.AlreadyExists {
return err
}
return err
}
return nil
}
func (d *counselingEventDispatcher) dispatchTime(t time.Time) time.Time {
jstTime := t.In(libtime.JST)
sec := jstTime.Second()
remainder := sec % dispatchInterval
nextSecond := sec + (dispatchInterval - remainder)
if nextSecond >= 60 {
return time.Date(jstTime.Year(), jstTime.Month(), jstTime.Day(), jstTime.Hour(), jstTime.Minute()+1, nextSecond-60, 0, jstTime.Location())
}
return time.Date(jstTime.Year(), jstTime.Month(), jstTime.Day(), jstTime.Hour(), jstTime.Minute(), nextSecond, 0, jstTime.Location())
}
func (d *counselingEventDispatcher) newTask(pharmacyID int, chainID int, scheduleTime time.Time, httpRequest *taskspb.HttpRequest) (*taskspb.Task, error) {
taskID, err := d.newTaskID(pharmacyID, scheduleTime)
if err != nil {
return nil, errors.Wrap(err, "newTaskID")
}
task := &taskspb.Task{
Name: fmt.Sprintf("projects/%s/locations/%s/queues/%s/tasks/%s", d.cfg.ProjectID, d.cfg.LocationID, d.cfg.QueueID, taskID),
MessageType: &taskspb.Task_HttpRequest{
HttpRequest: httpRequest,
},
ScheduleTime: timestamppb.New(scheduleTime),
}
return task, nil
}スロットリング間隔の調整
スロットリング間隔(10秒)は、システムの特性に応じて調整が必要です。
- 間隔が短すぎる場合:スロットリングの効果が薄れ、大量イベント時の負荷軽減が不十分
- 間隔が長すぎる場合:リアルタイム性が損なわれ、ユーザー体験が低下
私たちのシステムでは、以下の観点から10秒という値を採用しました。
- 通常の予約操作では、ユーザーが10秒以内に複数回更新することは稀
- 複数イベント発生時のイベント集約効果が十分に得られる
- ユーザーが体感する遅延として許容範囲内
実際の運用では、モニタリングの結果を見ながら調整を続けています。
このスロットリング機構により、複数イベント発生時でも安定したパフォーマンスを維持できるようになりました。
工夫したポイント②:徹底したテスト戦略
イベント発生ケースの網羅
今回のリアーキテクチャでは、「イベントが正しく発火されること」がシステム全体の動作に直結します。もしイベントの発火漏れがあれば、フロントエンドに変更が伝わらず、ユーザーは古い情報を見続けることになります。
これは従来のポーリング方式よりも深刻な問題になりかねません。ポーリングであれば最大30秒後には最新データが取得されますが、イベント駆動の場合は次のイベントが発生するまで更新されないからです。
そこで、イベントが発生するすべてのケースを洗い出し、網羅的にテストを行いました。
ケースの洗い出し
まず、予約データに変更が発生しうるすべてのパターンを整理しました。
| カテゴリ | 具体的なケース |
|---|---|
| 予約作成 | 処方箋事前送信予約、オンライン服薬指導予約、店頭受付 |
| 予約更新 | 日時変更、ステータス変更、患者情報変更、メモ追記 |
| 予約キャンセル | ユーザー操作、自動キャンセル、管理者操作 |
動作確認の実施
洗い出した各ケースについて、以下の観点で動作確認を実施しました。
- イベントが正しく発火されるか:Pub/Subにメッセージがパブリッシュされることを確認
- イベント内容が正しいか:薬局ID、予約ID、イベントタイプが正確に設定されていることを確認
- Firestoreが更新されるか:該当薬局のドキュメントが更新されることを確認
- フロントエンドが検知するか:画面上で変更が反映されることを確認
特に、既存コードに後からイベント発火処理を追加する形だったため、追加漏れがないかを入念にチェックしました。
リグレッションテストとの擦り合わせ
さらに重要だったのが、既存のリグレッションテストとの擦り合わせです。
私たちのチームでは、主要な業務フローをカバーするリグレッションテストを運用しています。今回のリアーキテクチャにあたり、以下の観点でテストケースを見直しました。
- 既存のリグレッションテストで、今回洗い出したイベント発生ケースがカバーされているか
- カバーされていないケースがあれば、新たにテストケースを追加
- イベント発火の確認を、リグレッションテストの検証項目に追加
この擦り合わせにより、テストの抜け漏れを防ぐとともに、今後の機能追加時にもイベント発火が正しく行われることを継続的に確認できる体制を整えました。
テストの成果
この徹底したテスト戦略により、本番リリース後のイベント発火漏れはゼロでした。
当初は「すべてのケースを網羅するのは大変そう」という声もありましたが、結果として、この工程に時間をかけたことが本番での安定稼働につながったと考えています。
導入結果
定量的効果
リアーキテクチャの結果、以下の改善を達成しました。
| 指標 | 改善前 | 改善後 | 削減率 |
|---|---|---|---|
| 予約検索APIの秒間リクエスト数 | 約2,000/秒 | 約1,000/秒 | 50% |
| DBコスト | 100% | 70% | 30% |
| ネットワークトラフィック | – | – | 大幅削減 |
特にDBコストについては、月次で見ると無視できない金額の削減となり、投資対効果として十分な成果が得られました。
定性的効果
数字に表れない部分でも、多くの改善がありました。
リアルタイム性の向上
従来は最大30秒の遅延がありましたが、イベント駆動への移行により、予約の変更がほぼリアルタイムで画面に反映されるようになりました。
システム安定性の向上
ポーリングによる定期的な負荷スパイクがなくなり、データベースへの負荷が平準化されました。これにより、システム全体の安定性が向上しています。
開発者体験の改善
イベント駆動のアーキテクチャは、各コンポーネントの責務が明確で、デバッグや機能追加がしやすくなりました。「このイベントがどこで発生して、どこで処理されるか」が追いやすいのは大きなメリットです。
運用上の考慮事項
成功要因
今回のリアーキテクチャがうまくいった要因を振り返ると、以下の点が挙げられます。
1. 段階的なリリース
いきなり全薬局に適用するのではなく、まずは一部の薬局から段階的に展開しました。これにより、想定外の問題があった場合の影響範囲を限定できました。
2. 監視体制の整備
以下のメトリクスを監視するダッシュボードを構築し、問題の早期発見に努めています。
- Pub/Subの未処理メッセージ数
- Cloud Tasksの実行遅延
- Firestoreの読み取り/書き込み数
- フロントエンドからのAPI呼び出し数
3. チーム内での知識共有
新しいアーキテクチャについて、設計の意図や運用方法をドキュメント化し、チーム全体で共有しました。属人化を避けることで、持続可能な運用体制を構築しています。
留意すべき事項
一方で、イベント駆動アーキテクチャ特有の注意点もあります。
イベント欠損への対策
ネットワーク障害やサービス障害により、イベントが正しく配信されない可能性はゼロではありません。この問題に対しては、Pub/Subの再送機能を活用(デッドレターキューの設定)を講じています。
順序保証の考慮
分散システムにおいては、イベントの到着順序が発生順序と一致するとは限りません。今回のケースでは、「最新のイベントがあったこと」を通知するだけなので順序は問題になりませんが、順序が重要な処理を追加する場合は注意が必要です。
Firestoreコストの試算
ポーリング廃止によるDB負荷軽減の一方で、Firestoreの読み取り・書き込みコストが新たに発生します。導入前に試算を行い、トータルでコストメリットがあることを確認しておくことをお勧めします。
私たちのケースでは、Firestoreのコストを加味しても、DB負荷軽減による削減効果の方が大きい結果となりました。
今後の展望
今回のリアーキテクチャは大きな成果を上げましたが、まだ改善の余地があると考えています。
スロットリング間隔の動的調整
現在は固定の10秒間隔でスロットリングを行っていますが、時間帯やイベント発生頻度に応じて動的に調整することで、さらなる最適化が可能かもしれません。
他システムへの水平展開
今回得られた知見を、他のポーリング処理を行っているシステムにも展開していく予定です。
まとめ
本記事では、ポーリング処理を廃止し、イベント駆動アーキテクチャへ移行した事例をご紹介しました。
達成した成果
- 予約検索APIの秒間リクエスト数の50%削減
- データベースコストの30%削減
- リアルタイム性向上によるユーザー体験の改善
技術的なポイント
- Cloud Pub/Subによるイベントの非同期配信
- Firestoreを活用したリアルタイム通知
- Cloud Tasksによるスロットリング機構
- イベント発生ケースを網羅した徹底的なテスト
「変更が発生したときだけ処理を実行する」というイベント駆動の原則に立ち返ることで、コスト最適化とシステム品質の向上を両立することができました。
ポーリング処理によるデータベース負荷やコスト増大にお悩みの方にとって、本記事が少しでも参考になれば幸いです。
技術スタック
- Google Kubernetes Engine (GKE)
- Cloud Pub/Sub
- Cloud Tasks
- Firestore
- MySQL
- Go